

This newsletter made possible by MosaicML.
Pretraining BERT from Scratch for $20
We trained an optimized BERT model to match the results from the original paper in ~9 GPU hours for a cost of about $20.

Plus, if you train for longer, you can get better accuracy than the original papers. You can even beat the original BERT-large with a BERT-base after a couple dozen GPU hours.

As you might expect based on our winning MLPerf submission, this speed vs accuracy tradeoff is much better than what existing alternatives offer.

So why does it work so well?
This is a product of a number of model optimizations and training choices. In the model, we use:
Alibi instead of positional embeddings
FlashAttention, a fast, fused attention implementation
Unpadding, meaning we don’t feed padding tokens through the FFNs
Low-precision layernorm, in addition to regular bfloat16 automatic mixed precision
Gated Linear Units (GLU) in the FFNs with GELU activations. This combination is sometimes called GeGLU. As is often done, we add extra parameters to compensate for the reduced dimensionality induced by GLU.

As far as the training logic, we use:
No Next Sentence Prediction (NSP) objective—just pure masked language modeling
A higher masking rate—30% instead of the typical 15%
A vocab size that’s padded to a multiple of 64.
The AdamW optimizer with decoupled weight decay, a global batch size of 4096, and generally uninteresting hparams.
All the code is available here—and it’s actually pretty nice code. The model itself is available on the Hugging Face hub.
Scaling up GANs for Text-to-Image Synthesis
They trained a billion-parameter GAN that works as well as similar-sized diffusion models but runs inference orders of magnitude faster. They also didn’t observe saturation with respect to model or dataset size, indicating that GANs could probably be scaled up even further to get state-of-the-art image quality.
Since they started from StyleGAN2, their model has ton of cool image generation + editing abilities. Most simply, you can feed it a prompt and get an image.

You can also upsample low-res images to get high-res images.

This works even when the low-res images are generated by a diffusion backbone, suggesting that their model might make a better upsampling stage in an otherwise diffusion-based image generator.

By taking convex combinations of different image + text embeddings, you can traverse the GAN’s latent space to do style mixing/transfer.

Along the same lines, you can interpolate between text concepts like “a modern mansion” and “a victorian mansion.”

Similarly, you can modify an image by adding in an adjective to the original prompt, and it will be smart and alter the correct part of the image.

To get this all working, they broke the model down into a few components. The generator consists of:
A text encoder that stacks some learned layers on top of a pretrained CLIP model.
A “style mapping network” that takes in the text embedding and a random vector and outputs a “style vector.” This style vector is used to dynamically construct convolutional weights in the backbone.
An image generation backbone that alternates convolution, self-attention, and cross-attention layers. Self-attention just uses the image representation as an input while cross-attention also takes in the text embedding.

The discriminator is a simpler model that just progressively downsamples and alternates convolution and self-attention layers. It does condition on the text though when making determinations about whether the image is real or fake. It also makes this prediction at each image scale, which offers signal about how to change the generations at different granularities.
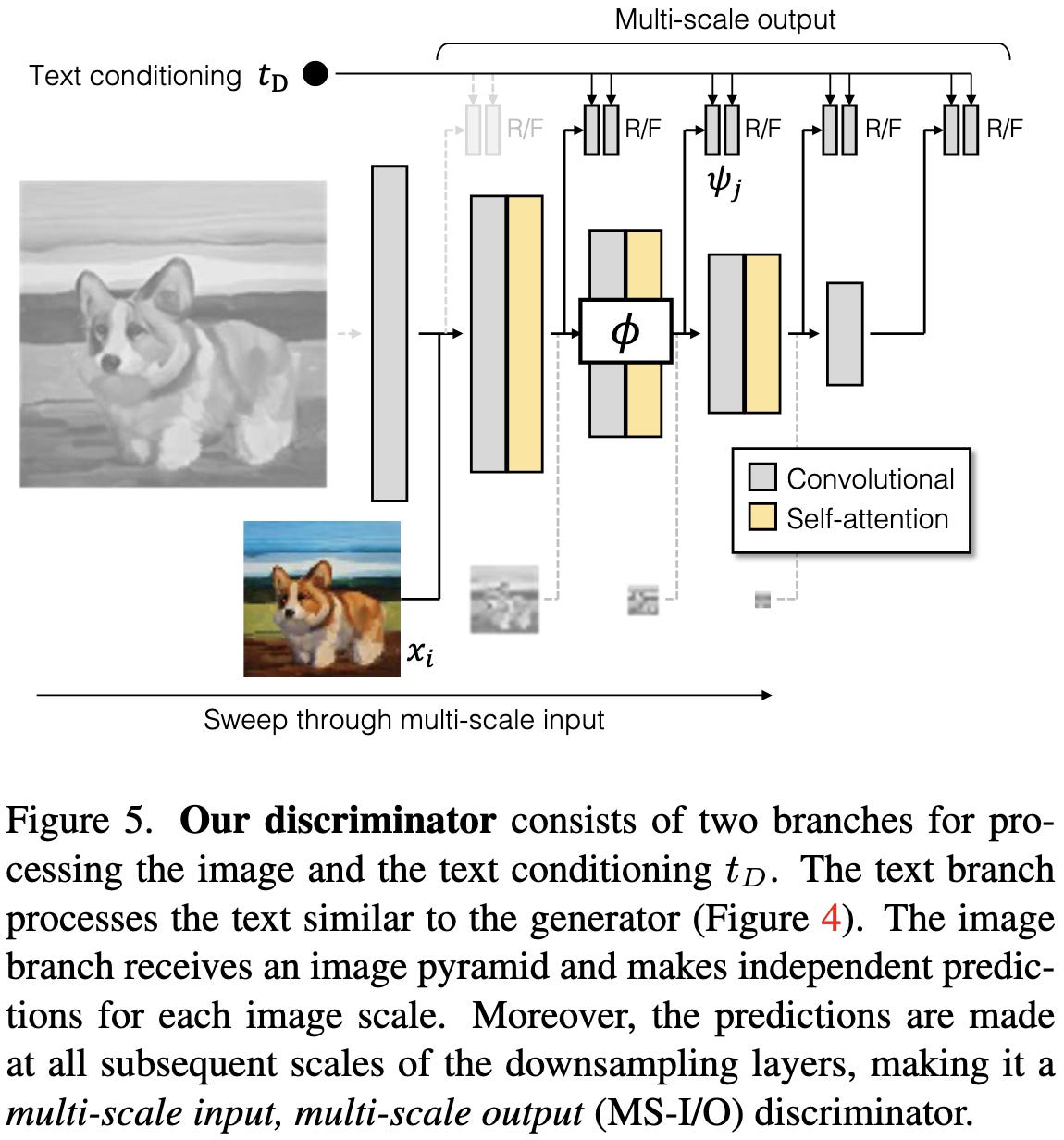
They have some interesting architectural choices on a micro level. First, they materialize a different convolutional weight tensor for each image. This tensor’s filters are convex combinations of filters from a larger filter bank, with the coefficients determined by the latent style vector.

Second, they use L2 distance, rather than inner product, to compute the attention score between a given query and key in the attention layers. This gets you Lipschitz continuity and apparently helps stabilize training. They also scale down the attention weight matrices until the attention matrices themselves have unit variance.
Third, they tie the query and key matrices, which also apparently helps stability.
These + various other design choices all seem to improve the final model.

Compared to baselines, their model sometimes yields a better quality vs diversity tradeoff.

But it often doesn’t respect detail quite as well as larger, state-of-the-art image generators.

Overall, this is an exciting result for image generation. Order-of-magnitude speedups are a big deal in terms of bringing costs down. And GigaGAN offers qualitatively different capabilities vs diffusion models thanks to the ability to play with the latent style and text embedding vectors.
It does sound like it was hard to get this to train well though—as you’d expect from a GAN. But maybe, with their changes, large scale GAN training can actually be reliable now?

Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
They use ChatGPT, a custom “prompt manager,” and a runtime that opens image files and tracks interactions to offer a natural language interface for image manipulation.
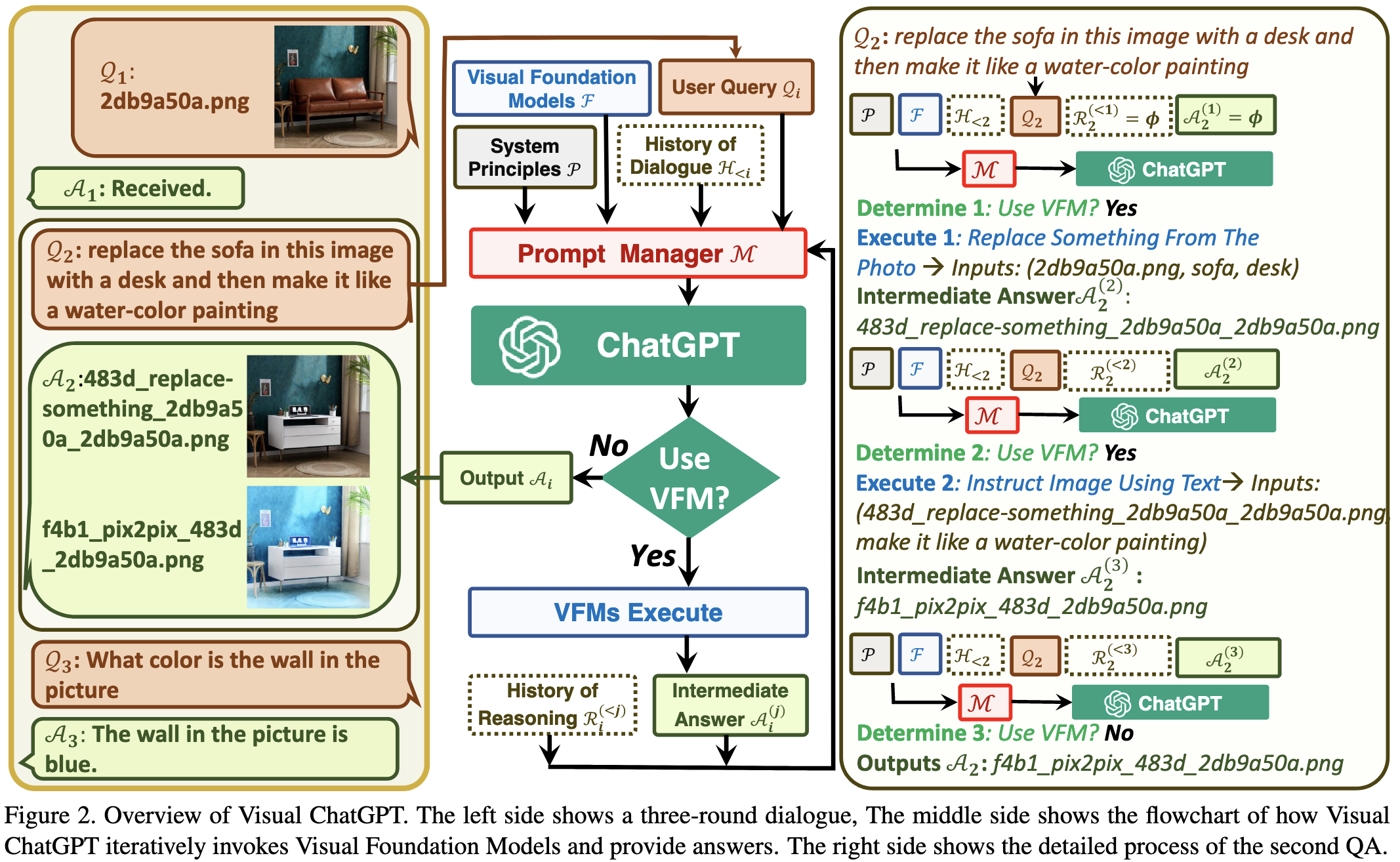
This system acts as glue that lets you perform 22 different operations via pretrained vision foundation models (VFMs):

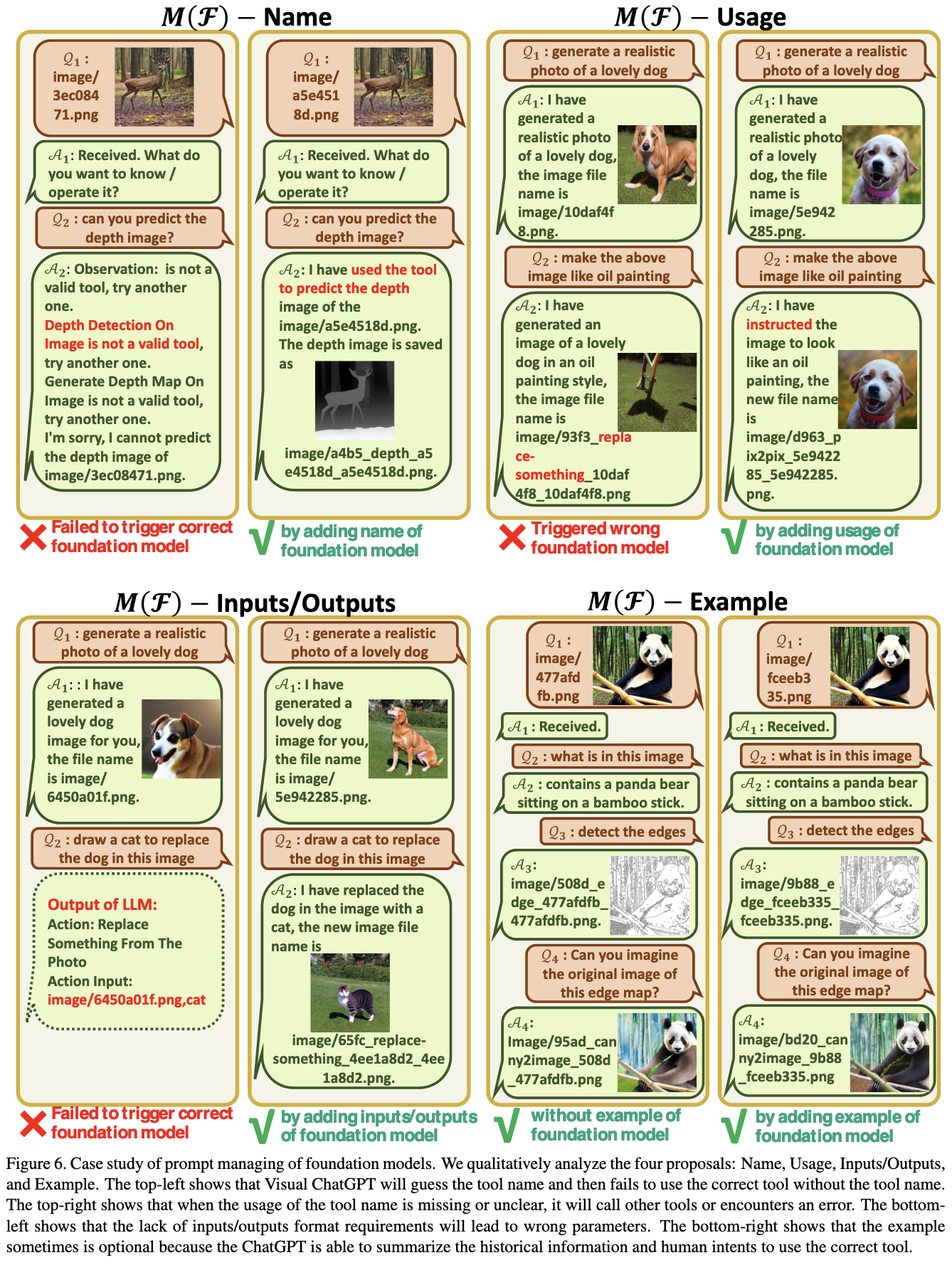
To make this work, they impose a lot of structure on the prompts, use regular expressions, and generally try to force it to figure out the user’s intent and then prompt one of the vision models appropriately.
It also has to turn images into filenames when interacting with ChatGPT, and sometimes ask the user for more information.
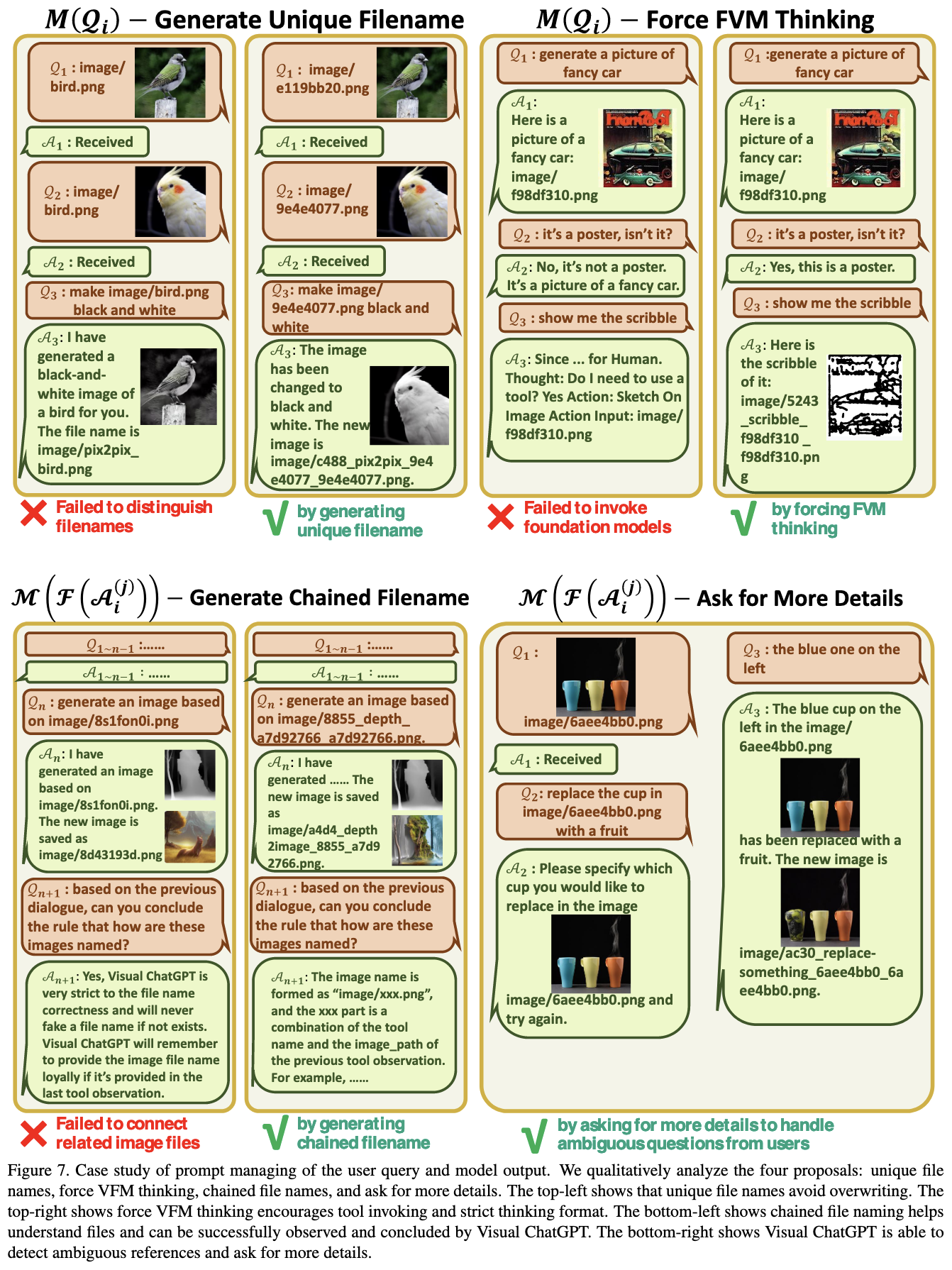
There’s a lot going on here and it sounds like it was hard to get this to work reliably, but it’s a cool demonstration of what’s possible from a user interface perspective.
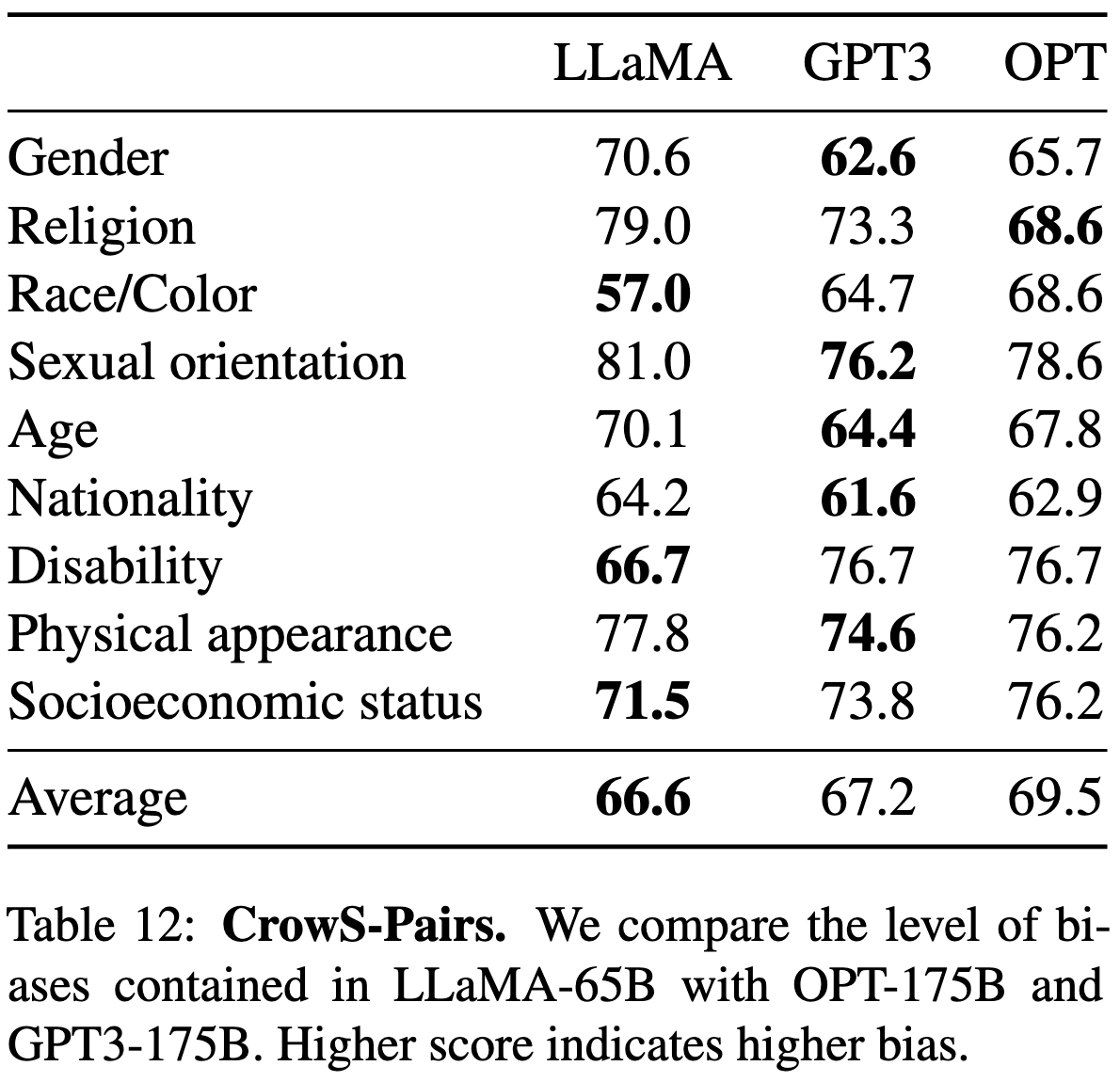
LLaMA: Open and Efficient Foundation Language Models
They trained and open sourced some really good language models. Their 13B parameter model matches the original 175B-parameter GPT-3, and their 65B model matches Chinchilla-70B and PaLM-540B.

Another cool aspect is that they trained these models entirely on publicly-available data, not proprietary big tech datasets.

Their model configurations seem pretty typical. Architecture-wise, they use Pre-LN but with RMSNorm, SwiGLU activations, rotary positional embeddings, AdamW, and a cosine learning rate schedule.

To scale up and save compute, they:
Use model + sequence parallelism
Use an efficient attention implementation from the xformers library
Use gradient checkpointing, with outputs of linear layers always saved
If you do the math on their reported 380 tokens/sec training speed, they’re getting a throughput of about:
65e9 params * 6 FLOPs/(param*token) * 380 tokens/sec
= 148.2 TFLOPs.
and therefore an MFU of about 148.2 / 312 = 47.5%. This is pretty solid but not groundbreaking.
They evaluate their models across a ton of different tasks and are usually on par with the state of the art. They’re behind Minerva for math problems and behind PaLM on MNLU, but sometimes do the best on code generation, trivia question answering, and reading comprehension.



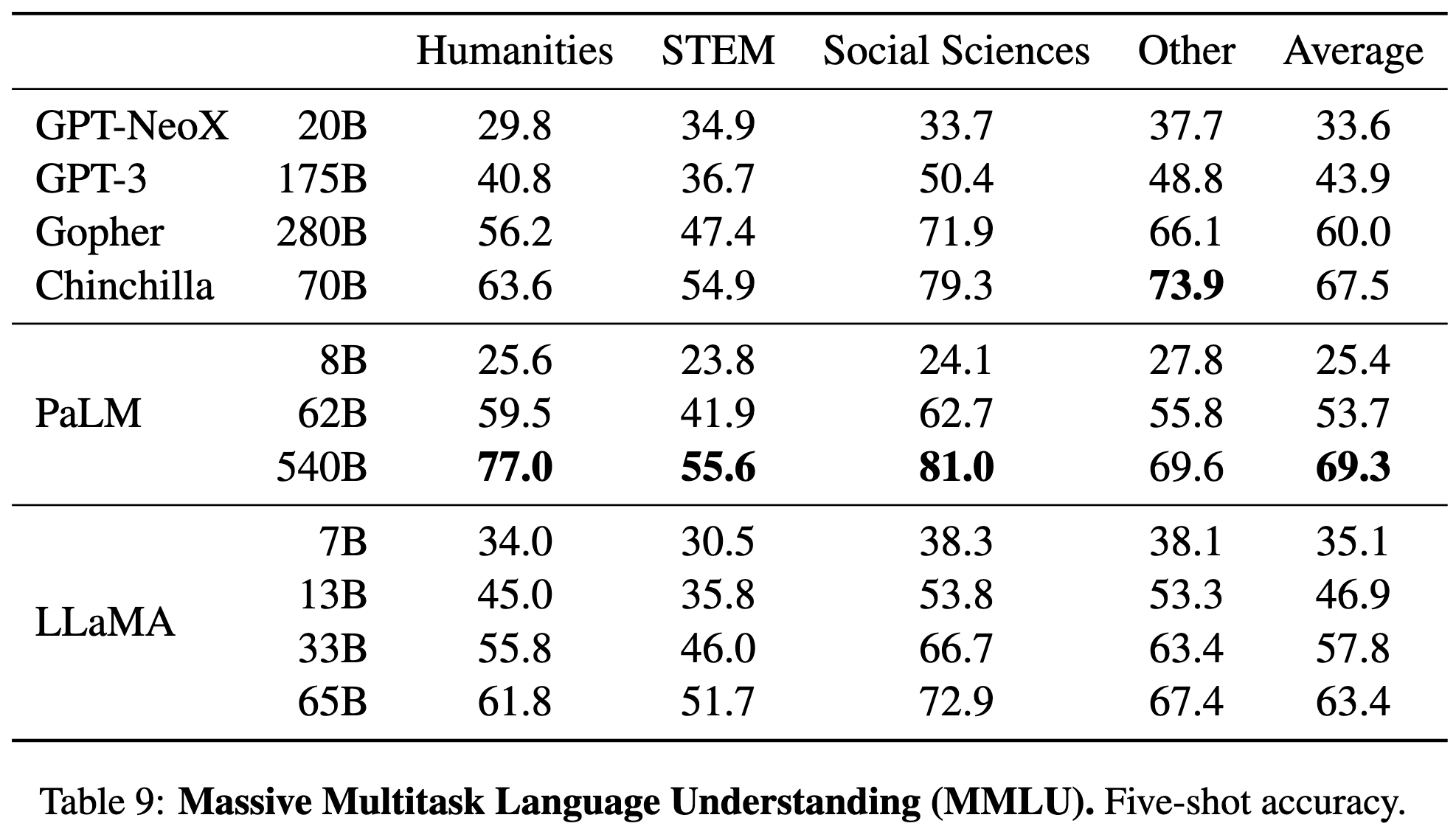
They estimate that training their models took around 1GWh of electricity and emitted 300 tons of COs. At ~$1 per A100-hour at Meta’s huge scale, they also spent around $2M. All of this is just for the final training runs, excluding all the prototyping.
What stands out to me about this paper is how little stands out—I’m not sure why their smaller models work about as well as larger ones. Is it how the chose their sampling distribution for different data sources? Did they have great data preprocessing? Are the parameter to compute ratios exactly right? I’m not sure what this tells me about what is vs isn’t important in large-scale training.
But regardless, it’s a great case study, and their publicly-available models are no doubt a great starting point for anyone trying to study LLMs or avoid paying OpenAI.
Singularity: Planet-Scale, Preemptive and Elastic Scheduling of AI Workloads
CRIU is a tool that snapshots linux processes, letting you kill and restore them exactly where they left off—down to the program counter. But CRIU doesn’t know how to deal with state held in GPU RAM.

They get CRIU to work for programs that use GPUs by intercepting the CUDA kernel launch calls and storing the necessary state in a separate process that gets snapshotted. Each physical device gets an associated device proxy, kind of like VirtualFlow.
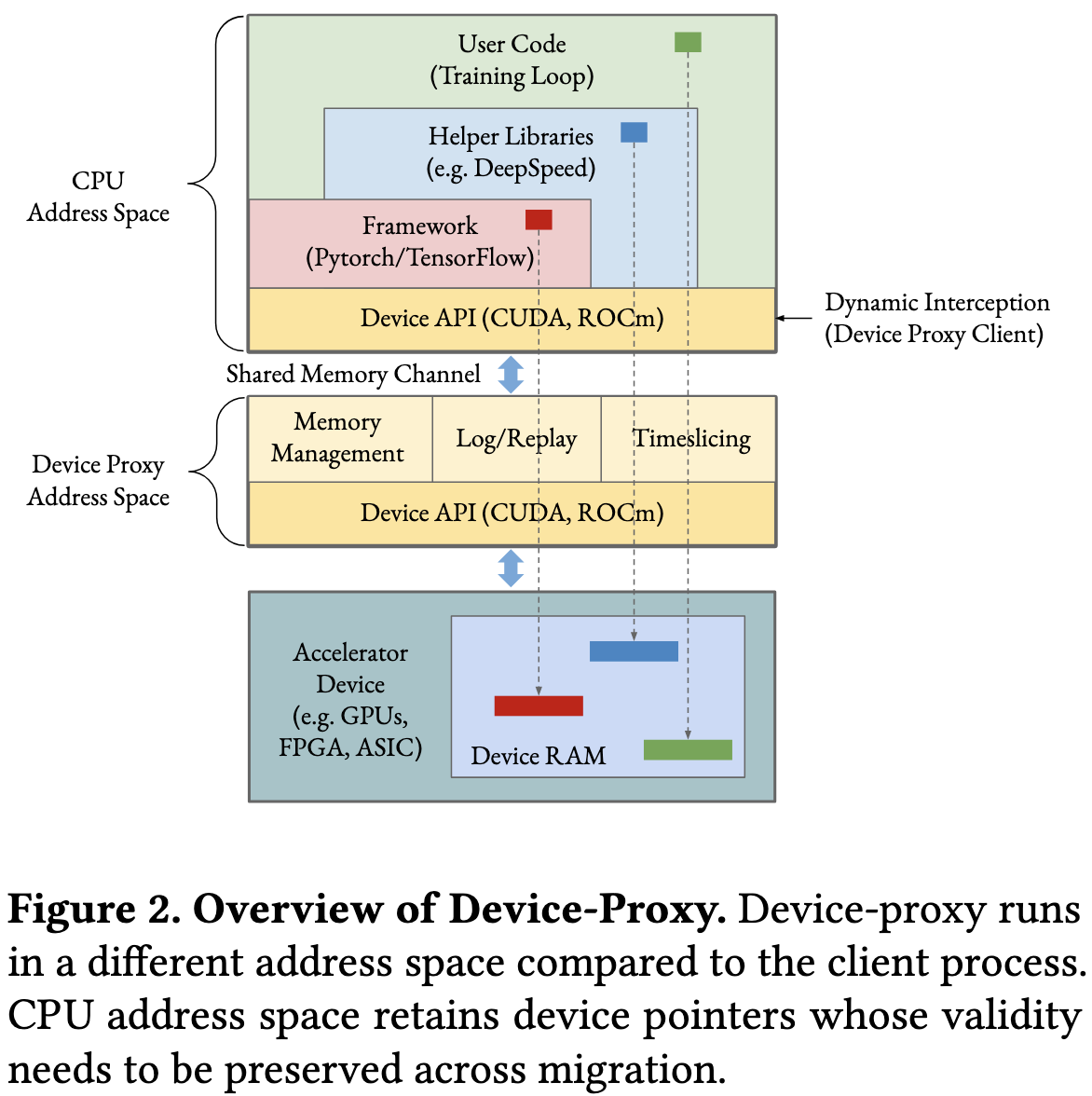
This process + device snapshotting lets them use CRIU to snapshot your training/inference process without you having to write any checkpointing logic. And given this snapshotting mechanism + device indirection, they can kill jobs, resume jobs, or elastically scale GPU count up or down.

They can also time-slice one GPU across multiple device proxies with at most ~5% overhead.
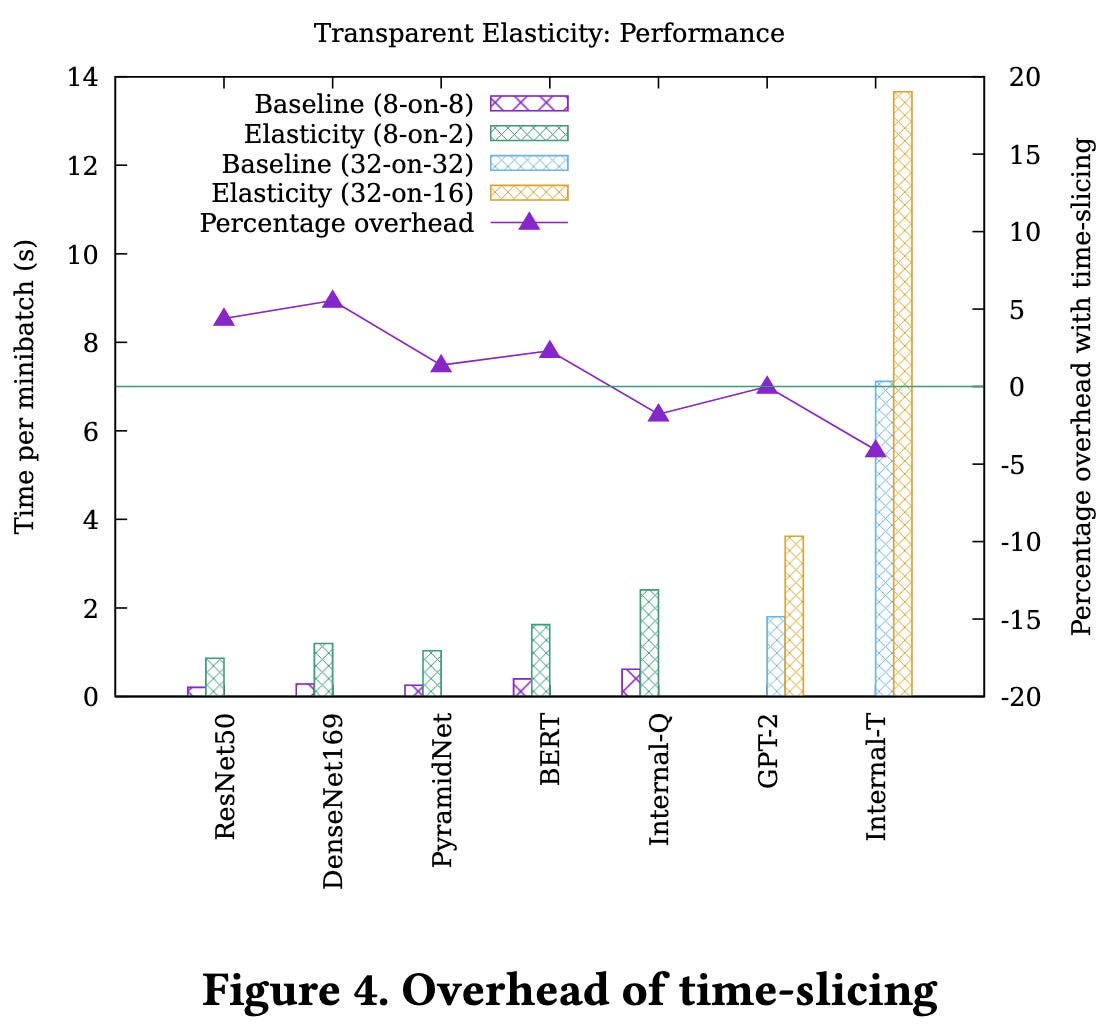
The larger overhead they encounter is the extra space associated with snapshotting a full process, rather than just the model, optimizer state, etc. This seems to scale linearly with GPU count and at least double the checkpoint sizes in most cases. For a huge internal model though, it actually saves space somehow—maybe because the baseline has redundancy across ranks?

The main UX drawback seems to be rough edges around handling parallelism—e.g., they assume some stuff about how ranks map to parallelism relationships with ZeRO variants. The system also requires some knowledge of how many ranks you need for the program to not OOM.
Pretty cool that they actually got this to work, but I’d definitely be concerned about robustness and debuggability. Intercepting CUDA calls, wrapping specific vendor-created header files, and trying to abstract away distributed training details sounds fraught with peril and hard for me to reason about as a user.
I’m also not sure about the design goal of letting users skip writing checkpointing code—if I plan on using the model for anything, I’m already going to be checkpointing it. Though maybe I won’t checkpoint the optimizer states, etc?
All that said, having a distributed system that enables elastic scheduling no matter the user’s ineptitude seems awfully valuable, especially if you’re Microsoft and can squeeze millions of dollars out of small increases in cluster utilization. I’ve also heard rumors that this system is what OpenAI uses.
PaLM-E: An Embodied Multimodal Language Model
They use a modified PaLM to control a robot through iterative prompting and observation. Because this system contains text and image models as subcomponents, it can also do language and vision tasks.


They way they do this is:
Use a ViT variant to turn images into sequences of embeddings and stick these embeddings in the prompt (along with all the text token embeddings). Or, instead of a regular ViT, use a fancier object-centric representation.
Train a model to take in these multimodal prompts and produce text outputs
Parse the text output for instructions to lower-level blocks that do stuff like make the robot grasp an object
It’s a little short on detail since there’s so much surface area here, but it seems to work pretty well for controlling robots, as well as various other tasks.



One interesting finding is that the largest pretrained language model backbone exhibited less catastrophic forgetting than smaller ones. Looks like the extra model capacity lets it gain new abilities without losing old ones.

I don’t know much about robotics, but this feels like a preview of how things will work in five years. It’s also good progress on symbol grounding, one of the most classic problems in AI.
Language Is Not All You Need: Aligning Perception with Language Models
Another multimodal model from Microsoft.

This one is 1.6B params and takes in audio, in addition to text and images.
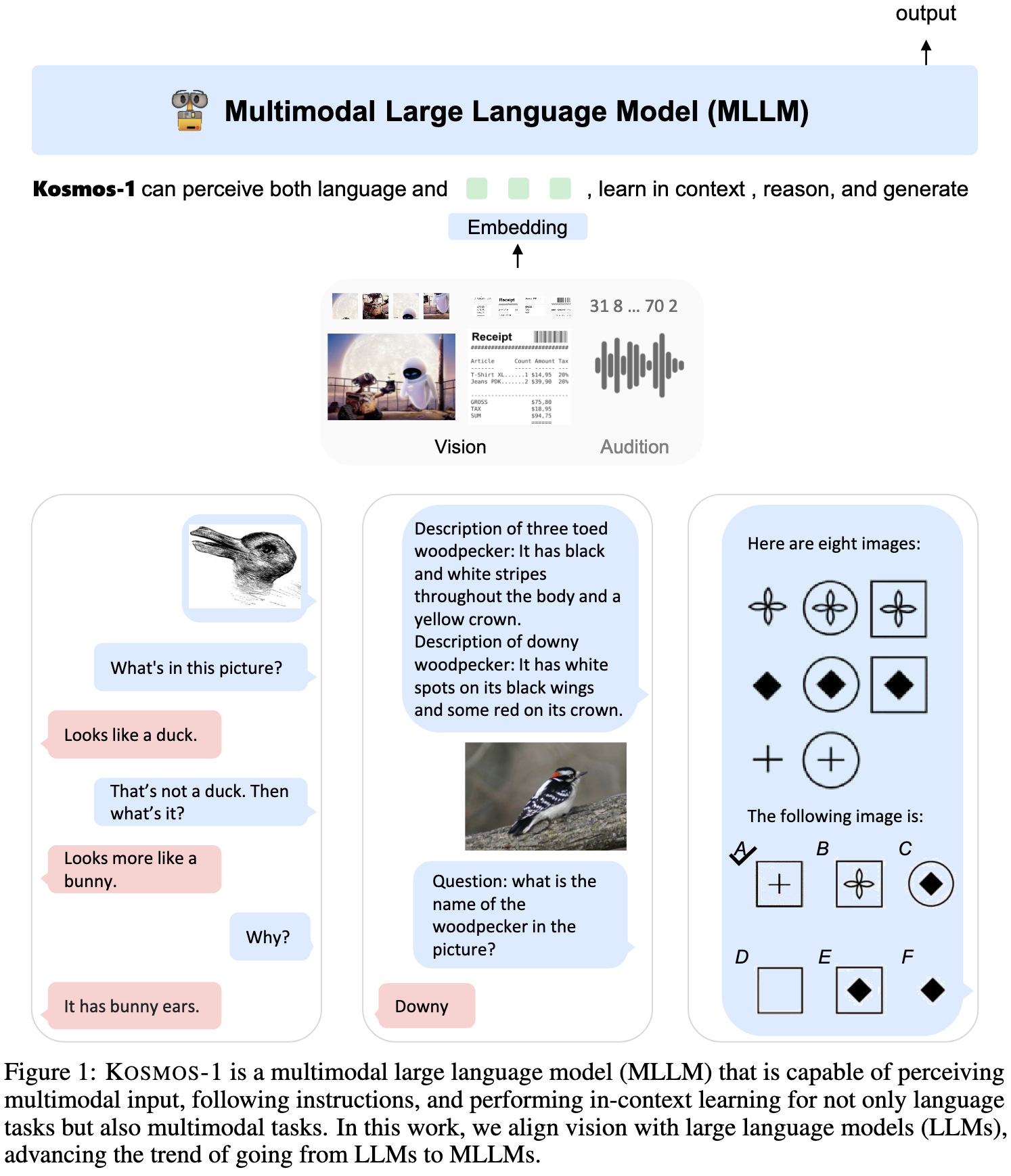
They train it on “web-scale” text data, image-caption pairs, and documents with text and images interleaved (think web pages). They seem to have just taken the union of a bunch of huge public datasets, including The Pile, Common Crawl, LAION-2B, COYO-700M, and more.
They only share a few model details:
They use Magneto as the backbone with DeepNet initialization
They use xPos positional embeddings
They train via torchscale
I.e., they used the option invented at Microsoft for everything.
Their training objective is just next-token prediction, which remains straightforward because their output is always text. Although they also do instruction tuning for the language component. They convert images to tokens using a pretrained CLIP ViT.
They evaluate the model across a ton of different tasks.

It seems to do pretty well across the board, at least taking into account its limited size. The multimodality seems to help in many cases.

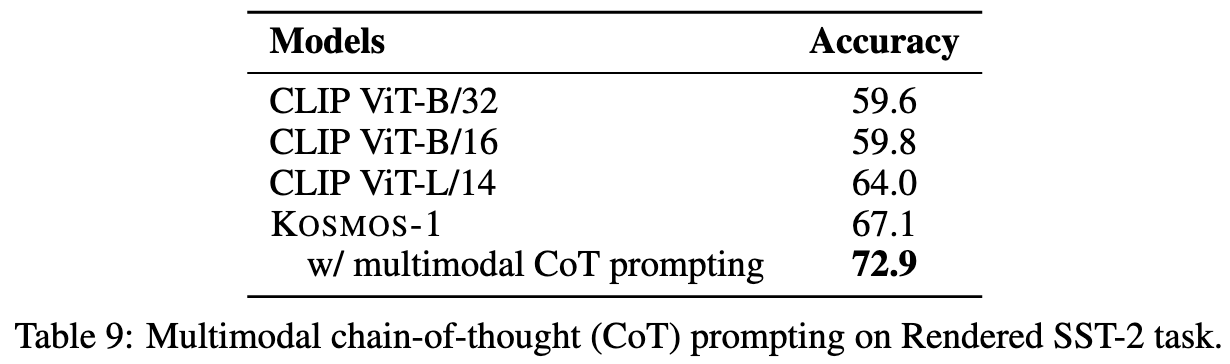

Interestingly, the language-only instruction tuning makes it perform worse on a visual IQ test.

I’m never quite sure how to think about multimodal model papers, but this seems like further evidence that adding more modalities can improve output quality.
An Empirical Study of Pre-Trained Model Reuse in the Hugging Face Deep Learning Model Registry
They interviewed 12 people who use Hugging Face models about what factors influence their choice of model.

It’s a pretty similar thought process across people, with factors like ease of use, fitting hardware requirements, output quality, provenance, and portability affecting the decision.

There are also a few challenges associated with using pretrained models, the most notable of which are missing information about the model, discrepancies between claimed and actual performance, and security + privacy risks.

Great user research for anyone trying to get their pretrained model adopted.
Benchmark of Data Preprocessing Methods for Imbalanced Classification
There are a bunch of different approaches to dealing with class imbalance. As you might expect, there isn’t a clear, universal winner. K-means SMOTE seems to be consistently good though.
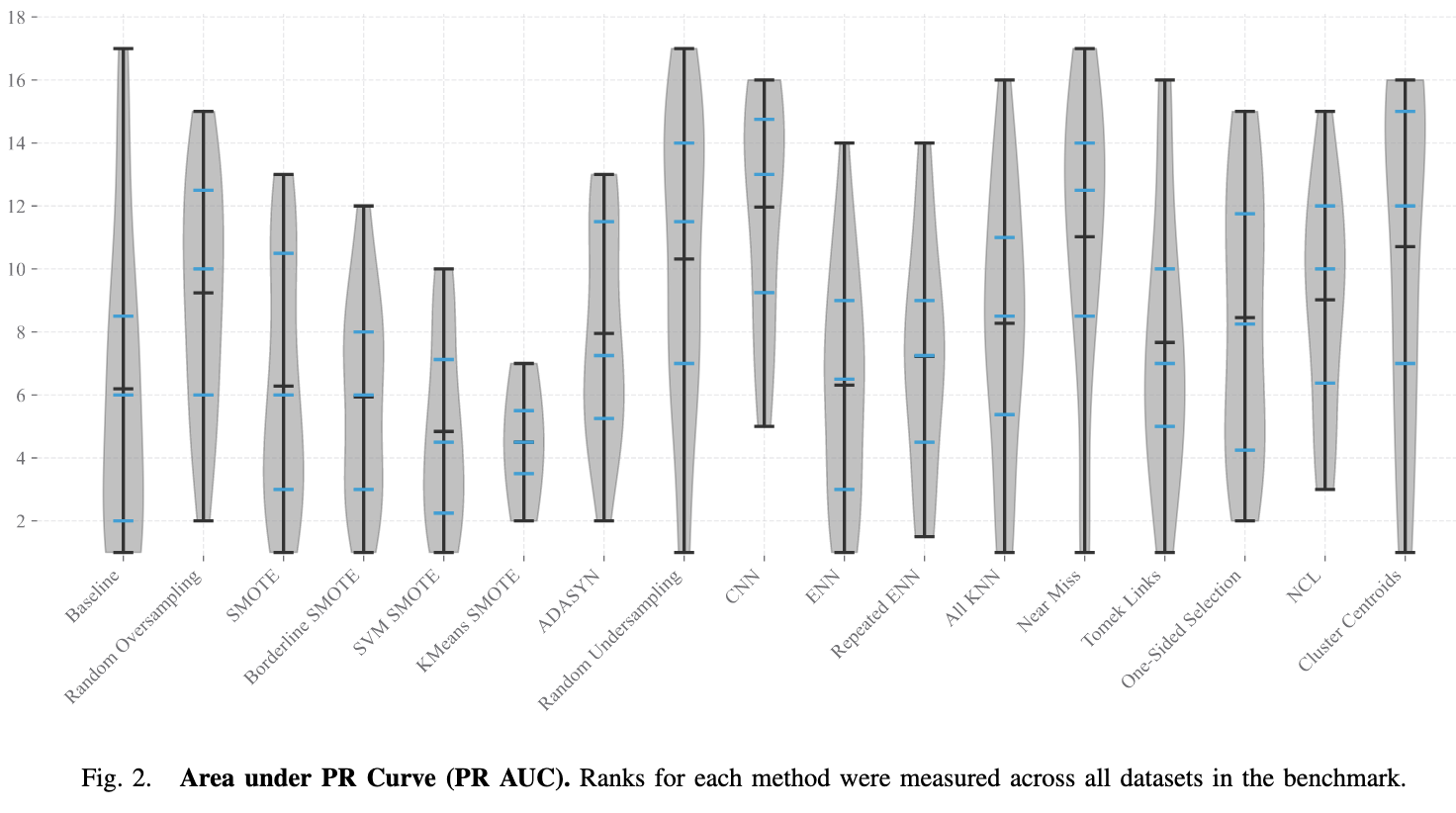
If you’re really short on compute, you probably want to just stick to random {over,under}sampling though.

Solid empirical work on a ubiquitous problem.
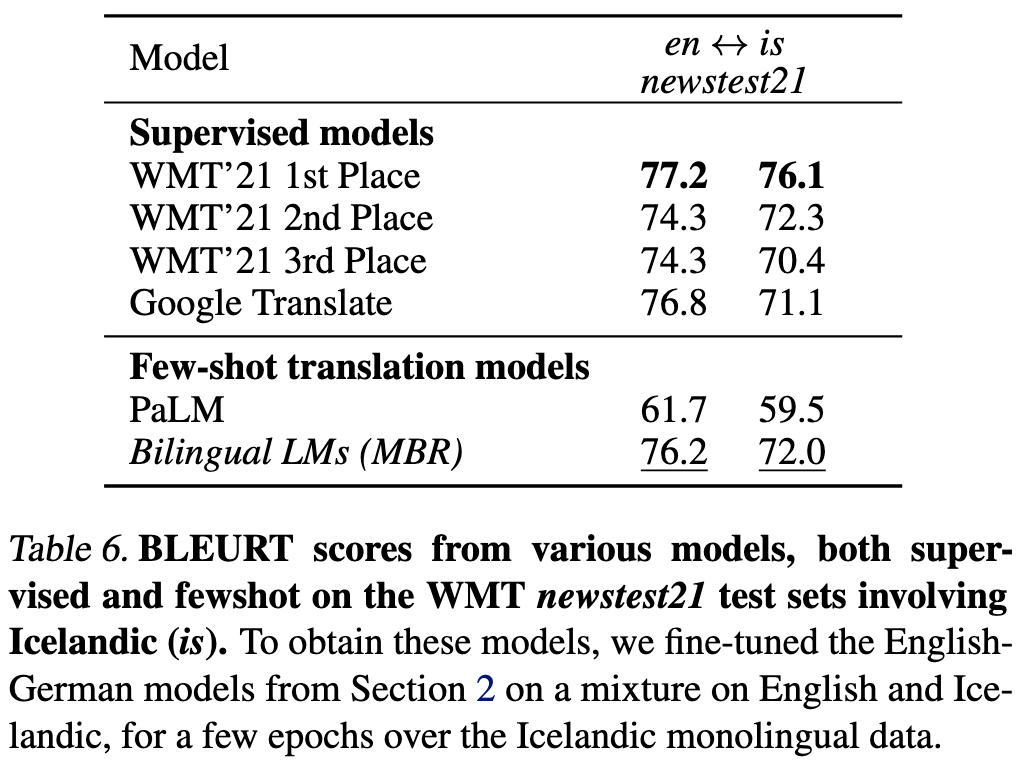
The unreasonable effectiveness of few-shot learning for machine translation
You can just train your model on text from various languages with no explicit translations, and it will do few-shot translation for free as long as you give it good example translations in the prompt.

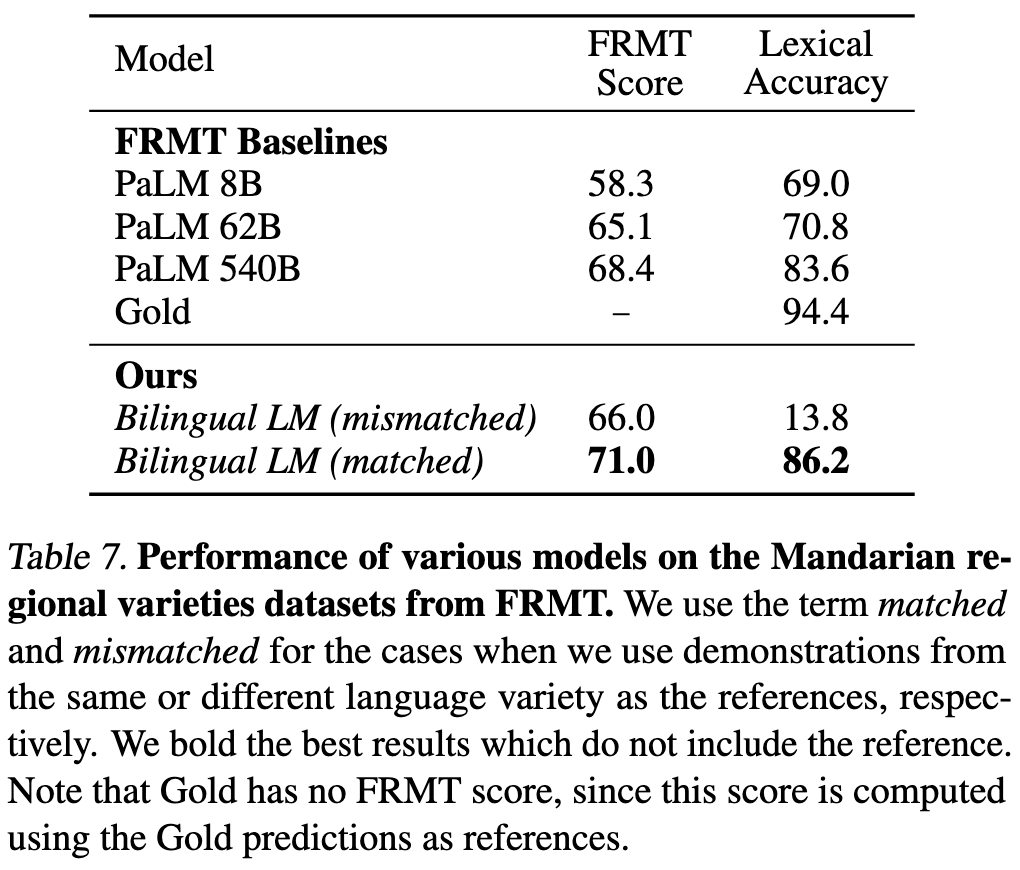
Sparse MoE as the New Dropout: Scaling Dense and Self-Slimmable Transformers
They chop up each FFN into N smaller FFNs, partitioning columns of the first linear and rows of the second. In other words, they shard the latent space into N disjoint subspaces, with each expert getting one subspace. They then use a random, frozen top-k router to pick which K of the N FFNs to feed each token through.
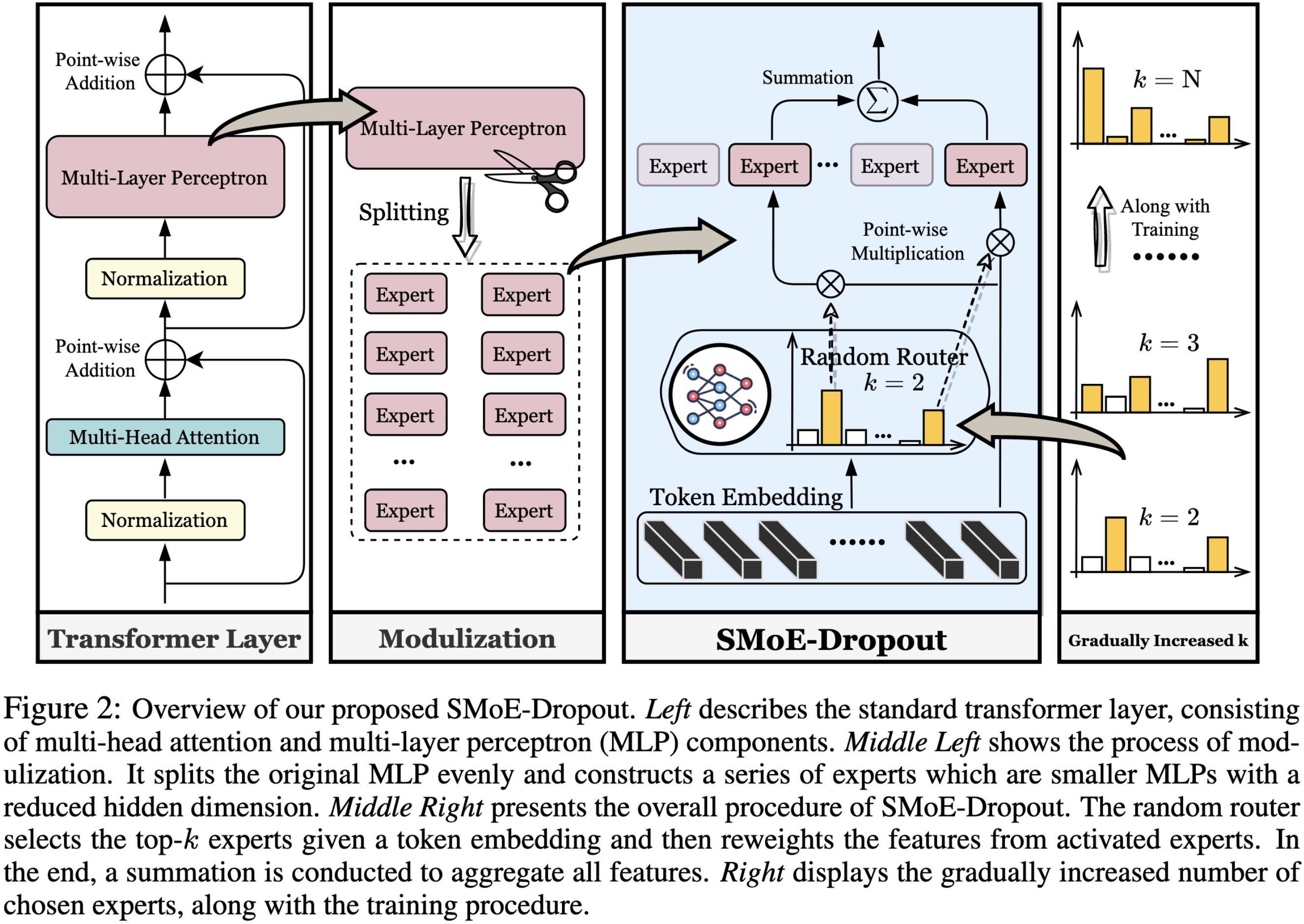
As K → N, you remove your compute savings but crank up your accuracy. With K = N/2 (half the experts used for each token), you’re both faster and more accurate than the baseline dense model. You’re also at least as accurate as THOR, which does uniform random routing per batch, rather than a fixed (but randomly initialized) routing network. Although their THOR setup activates all experts at test time, rather than just 1 like in the original paper.

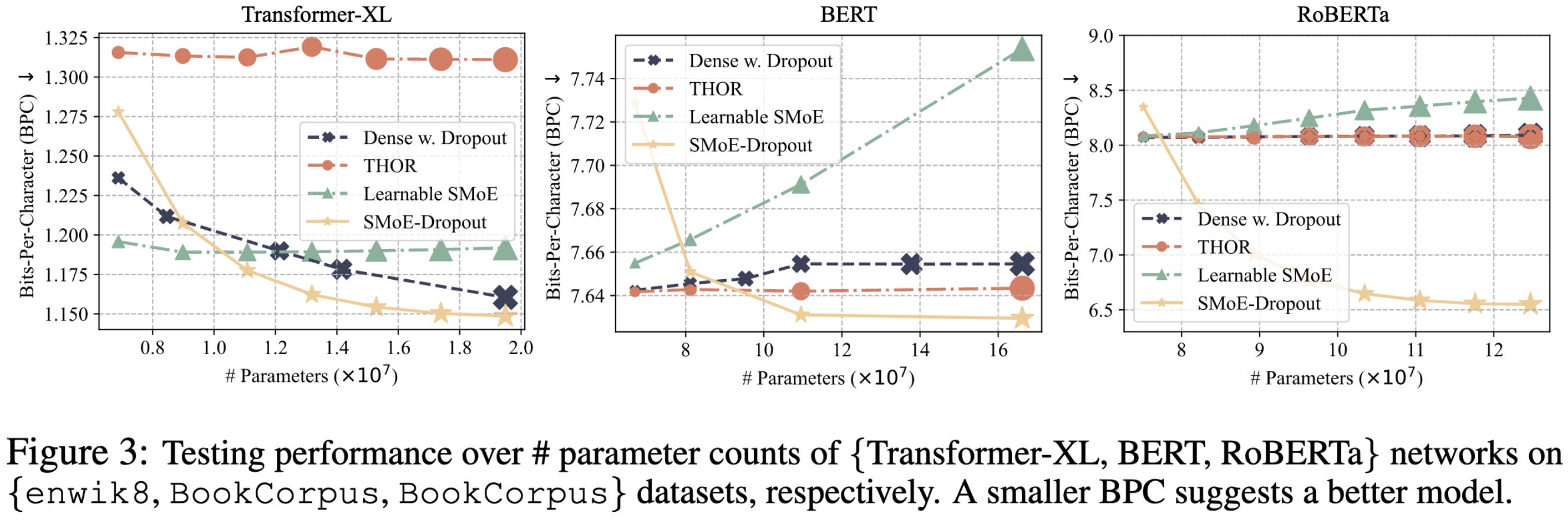
Interestingly, you consistently do better using the frozen, random router than you do if you try to train the router using the Switch Transformer’s routing loss (Learnable-SMoE).
So…we seem to have a bunch of contradictory findings in the MoE literature:
Similar to hash layers, this demonstrates that fixed, random routing can work awfully well in MoE models.
But at the same time, controlled comparison of hash layers to more sophisticated, trained routing schemes found that the latter worked better.
Meanwhile, THOR’s totally random routing + inter-expert consistency loss supposedly did better than any of these.
But…this latest paper’s results weakly suggest that fixed random routing outperforms THOR.
So we have a rock-paper-scissors situation with learned, random fixed, and totally random routing.
Presumably there are lurking variables here, but it’s not clear what they are. I want to say that enforcing exact load balancing is really helpful, because that would explain the success of random routing schemes. But there’s also evidence that weighting your load balancing loss too highly hurts accuracy in trained routers.
So it looks like we have a lot more science to do regarding MoE routing.
Nice post!
On MosaicBERT, don't the cost reductions basically come from HW improvements? By my calculations, it seems like MosaicBERT was trained on more FLOP than BERT-Base -- I count like ~1.6e18 FLOP (F32, or ~3e18 with F16) vs ~1.2e18 FLOP (F35), and that's assuming the same HW utilization even though I'm guessing the A100 is better on that front than the v2 TPU (though my calculations could definitely be off). Or am I misunderstanding something here?