
2023-4-2 arXiv roundup: LLMs improving LLM output, BloombergGPT, LLM opinions differ from humans

This newsletter made possible by MosaicML.
Thanks to Charlie Blake for the Twitter shoutout this week!
Training Language Models with Language Feedback at Scale
When talking to other humans, we tend to give feedback via language—not binary labels or numeric ratings. Can we get large text models to learn from this sort of free-form language feedback?

The answer is yes. To do this, they augment the initial model being trained with two other models: a refinement generation model and a reward model.
The idea is that:
The main model generates some output (“Bears are green.”)
A human writes feedback about that output (“No, bears are not green.”)
The refinement model generates a set of possible refinements (“Bears are brown”, “Bears are bears”, “Bears vary in color”)
The reward model scores each of these refinements
The highest-scoring refinement gets added, along with the original prompt, to a new dataset.
The main model is finetuned on the new dataset, using the chosen refinements as ground truth outputs.

A few components have to work for this overall algorithm to be helpful. First, can you use an existing LM as a refinement model? If we don’t get refinements that actually incorporate the feedback, we’re gonna have a bad time. Based on an example with easy-to-evaluate ground truth, it appears that sufficiently large pretrained models can do this.

Second, we need a decent reward model for ranking refinements. They find that just asking a pretrained model whether a given refinement incorporates the feedback works pretty well. It works even better if you ensemble the outputs from asking with a few different prompts.
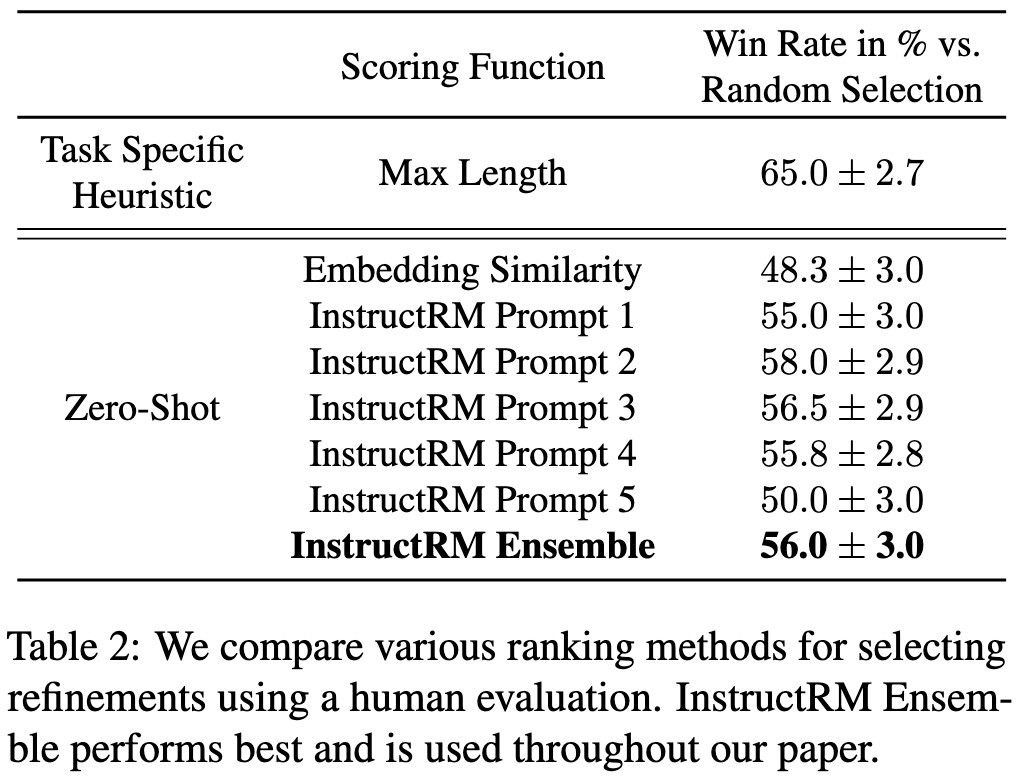
With these building blocks working, they find that they can summarize text better than the initial model as evaluated by humans.


Yet another example of using text models to generate more training data for text models—though there’s a human in the loop this time. It’s also just cool to see a simple method for incorporating way more detailed feedback.
Self-Refine: Iterative Refinement with Self-Feedback
Instead of just taking your language model’s initial output, have it iteratively suggest improvements to the output and then incorporate those suggestions.

To elicit the refined output, the feedback and previous outputs are appended to the prompt.


This is similar to various other approaches (and what people naturally do sometimes with ChatGPT), but having the refinement always, iteratively happen in such a simple way is different.

To elicit and incorporate refinements, you have to design sensible prompts for a given task. This isn’t too hard though.


Using self-refinement consistently improves output quality vs just taking the initial output.

Most of the gains from having one refinement iteration, but there’s still some benefit from using more iterations.

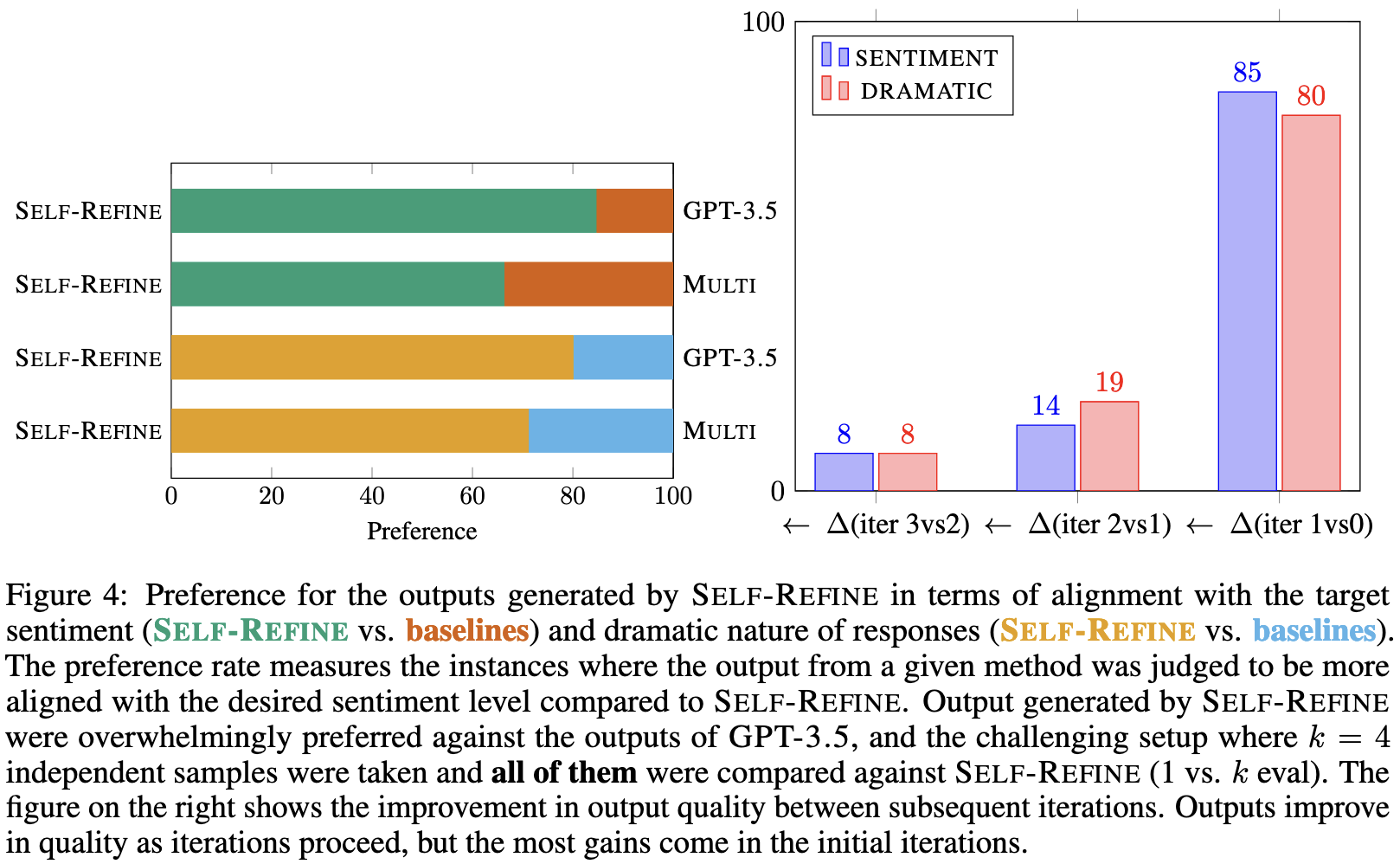
They also find that having informative feedback helps. If you constrain it to just say something like “something is wrong,” there’s less improvement in output quality.

The combination of this, Self-Ask, and similar work suggests that we need to rethink what inference means for LLMs. Instead of just having one output sequence per input that immediately gets returned, we might need a multi-step process where the output is fed back into the model. This could violate the assumptions of existing query batching and offer new optimization opportunities.
More generally, we need to characterize the inference vs quality tradeoff attainable with techniques like this. Are we better off using a 2x smaller model but having it generate two drafts of its output? Or are none of these techniques as good as just using the initial output from a larger model? I’d bet on the former more than the latter but we need to see tradeoff curves.
Language Models can Solve Computer Tasks
They propose “Recursive Criticism and Improvement” (RCI) to trade inference time for output quality, similar to Self-Refine above.1

This method consistently improves output quality across a variety of language tasks.

It also composes with chain-of-thought prompting; the two prompt structures together work better than either alone.

They also try using this approach on a benchmark of computer tasks wherein the LLM takes in HTML and has to output keyboard and mouse movement commands as text.

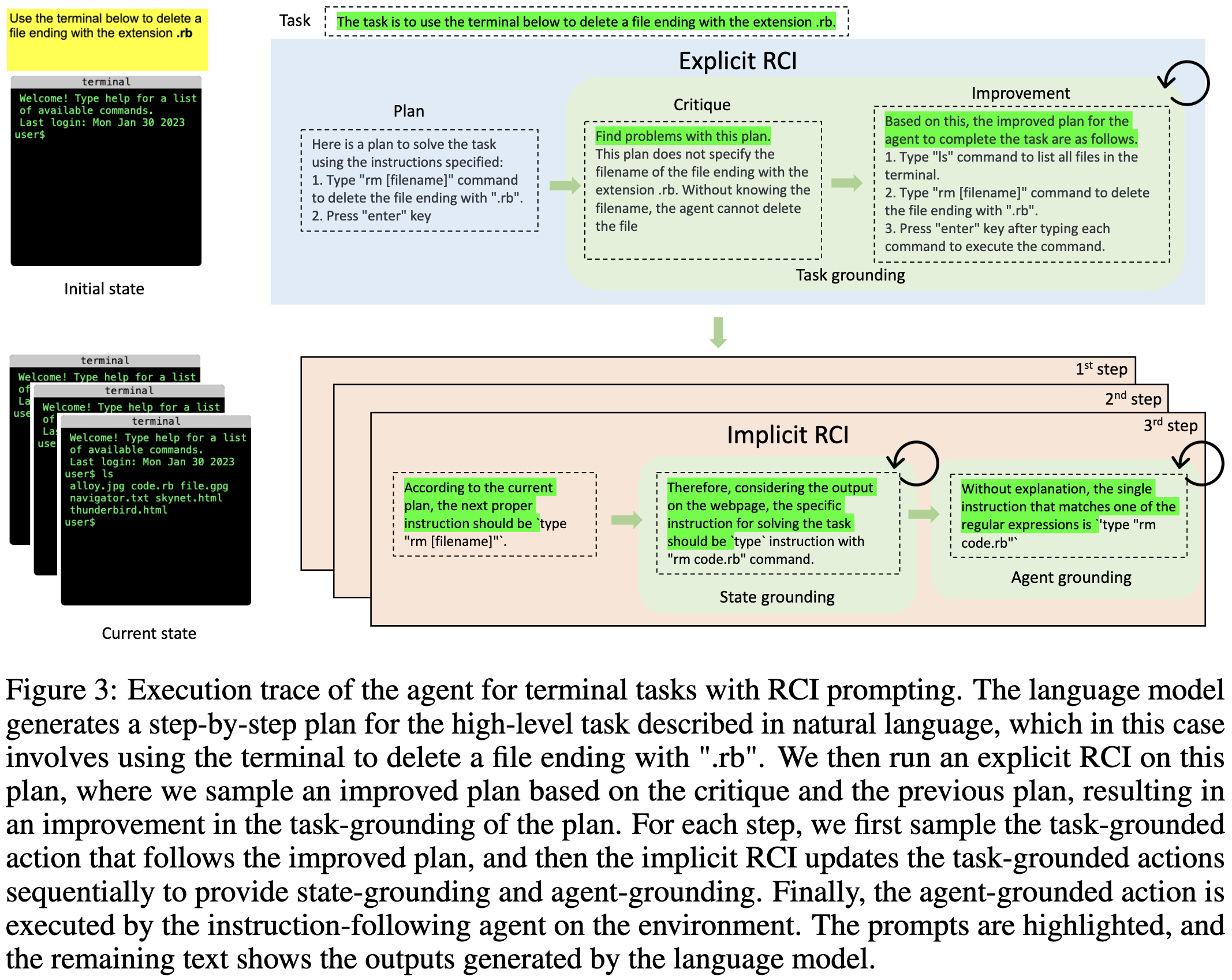
To get it to work, they design a multi-part prompt that helps the model figure out what it should do next based on the current HTML.

It doesn’t work quite as well as the best reported mix of RL and supervised learning, but it gets pretty close with far fewer examples.

Between this paper, the last paper, and a lot of anecdotal experience, it’s pretty clear that asking language models to improve their own outputs is a real thing. And, encouragingly, it seems to be easy to get it to work (not some fiddly process that requires exactly the right hparams).
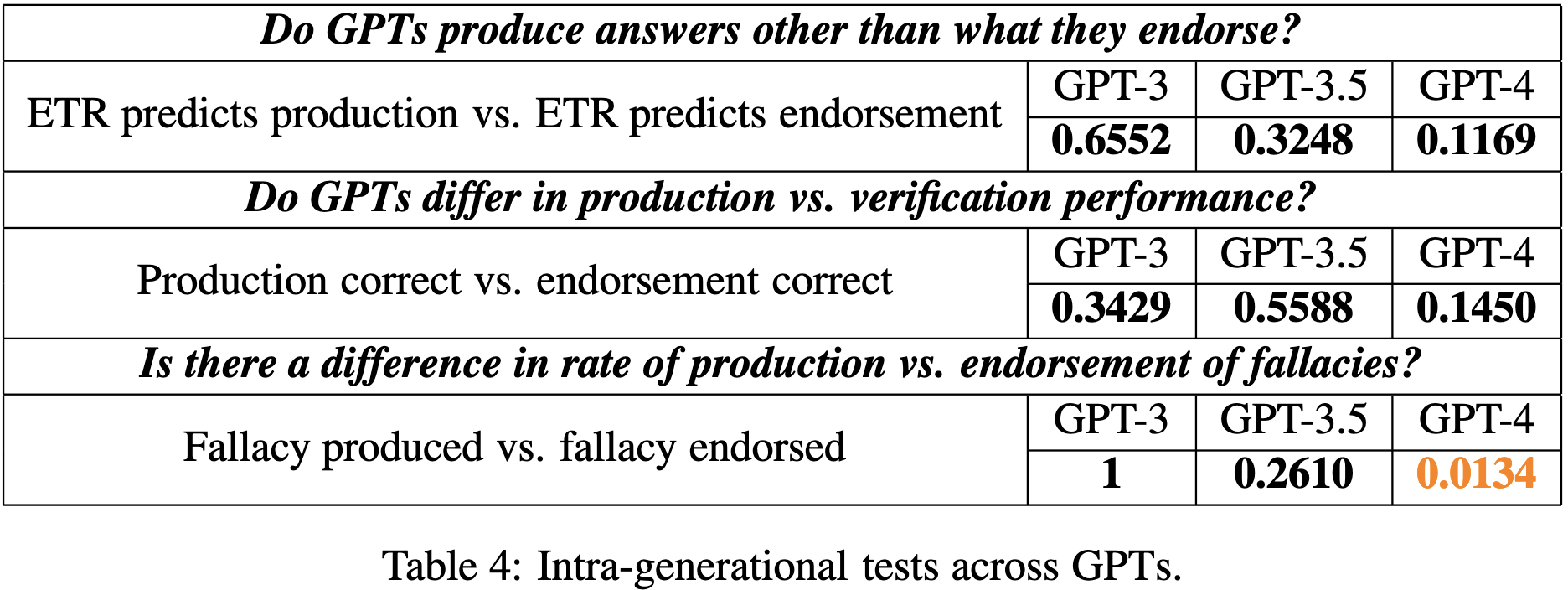
Humans in Humans Out: On GPT Converging Toward Common Sense in both Success and Failure
GPT-3.5 and GPT-4 make human-like reasoning errors more often than GPT-3 does.

Double Descent Demystified: Identifying, Interpreting & Ablating the Sources of a Deep Learning Puzzle
Double descent in deep learning usually refers to the phenomenon of test error initially dropping as your model grows, then increasing, then dropping again. What’s up with this?

They provide an approachable explanation, illustrated via ordinary least squares.

Roughly what’s going on is that, in the few sample regime, you end up with directions that barely vary at all in the training data and so yield grievously overfit parameters (think division-by-near-zero). This lack of variance gets worse as the number of samples approaches the data dimensionality, and then gets better afterward as we slowly learn the true singular values + vectors of our distribution.

The reason we end up with directions that have less and less variance as our sample count approaches the data dimensionality is the Marchenko–Pastur law; intuitively, each new sample contributes a new direction of variation, but the apparent magnitude of that variation diminishes as more samples are added. This is because we’re subtracting off the projection of this sample onto all the existing samples, which soaks more and more variance as the sample count grows.

Here’s an illustration of this happening in 3D:
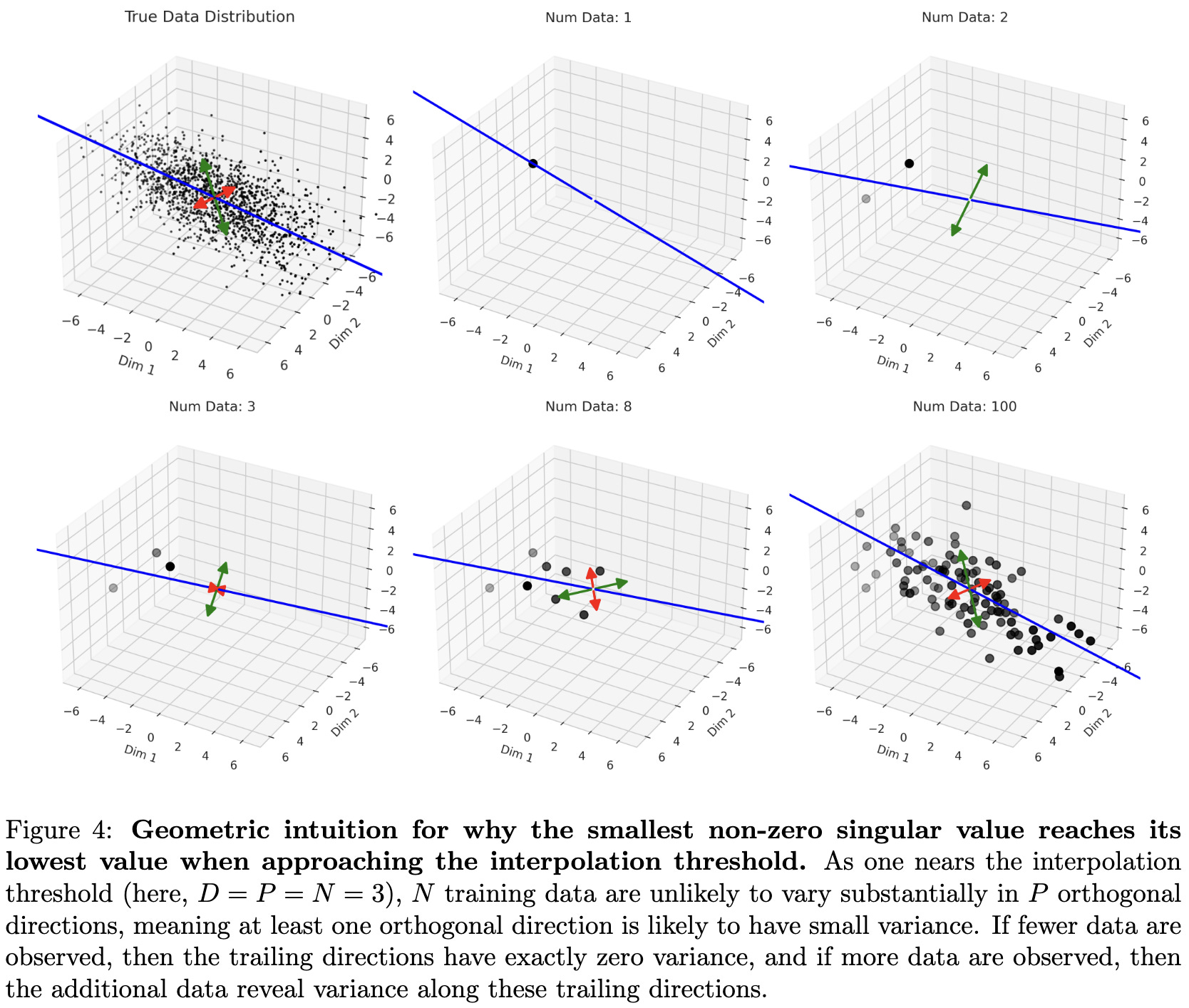
Pretty interesting. I still don’t fully understand what’s going on, especially in the deep learning case, but this definitely helped build intuition.
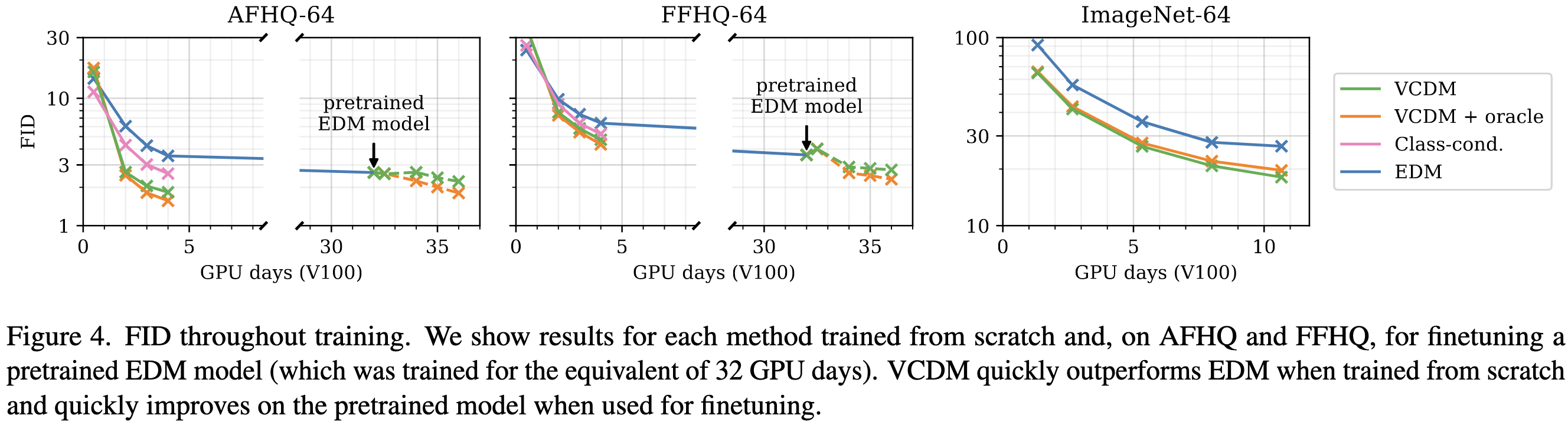
Visual Chain-of-Thought Diffusion Models
They improve unconditional image generation by essentially turning it into conditional image generation. Specifically, they first unconditionally sample a CLIP embedding from a smaller diffusion model, and then condition on this embedding when generating an image.
The intuition here is that coming up with a more specific prompt works better. E.g., “aerial photograph” vs “Aerial photography of a patchwork of small green fields separated by brown dirt tracks between them.”

This approach seems to beat regular unconditional image generation.
Whose Opinions Do Language Models Reflect?
They collected a dataset of American public opinions about various topics broken down by demographics. Using this dataset, they investigate how well language models’ implied opinions (as measured by output probabilities) line up with various demographics and the US populace as a whole.

The implied opinions of recent language models like OpenAI’s text-davinci-003 are more different from the general public than the opinions of any of the 60 demographics considered (see the .865 value near the left). Every model disagrees with humans more than Democrats and Republicans disagree about climate change (the bar above the table shows where various baselines fall in the 0-1 range).

Which groups’ opinions do models most resemble? It varies across models, but recent OpenAI models are most aligned with well-off liberals. Interestingly, they end up resembling shallow “caricatures” of these groups, with opinions like 99% support for Joe Biden.

They’re especially misaligned with the opinions of the elderly, widows, people who attend religious services regularly, and people who describe their race as “other.”

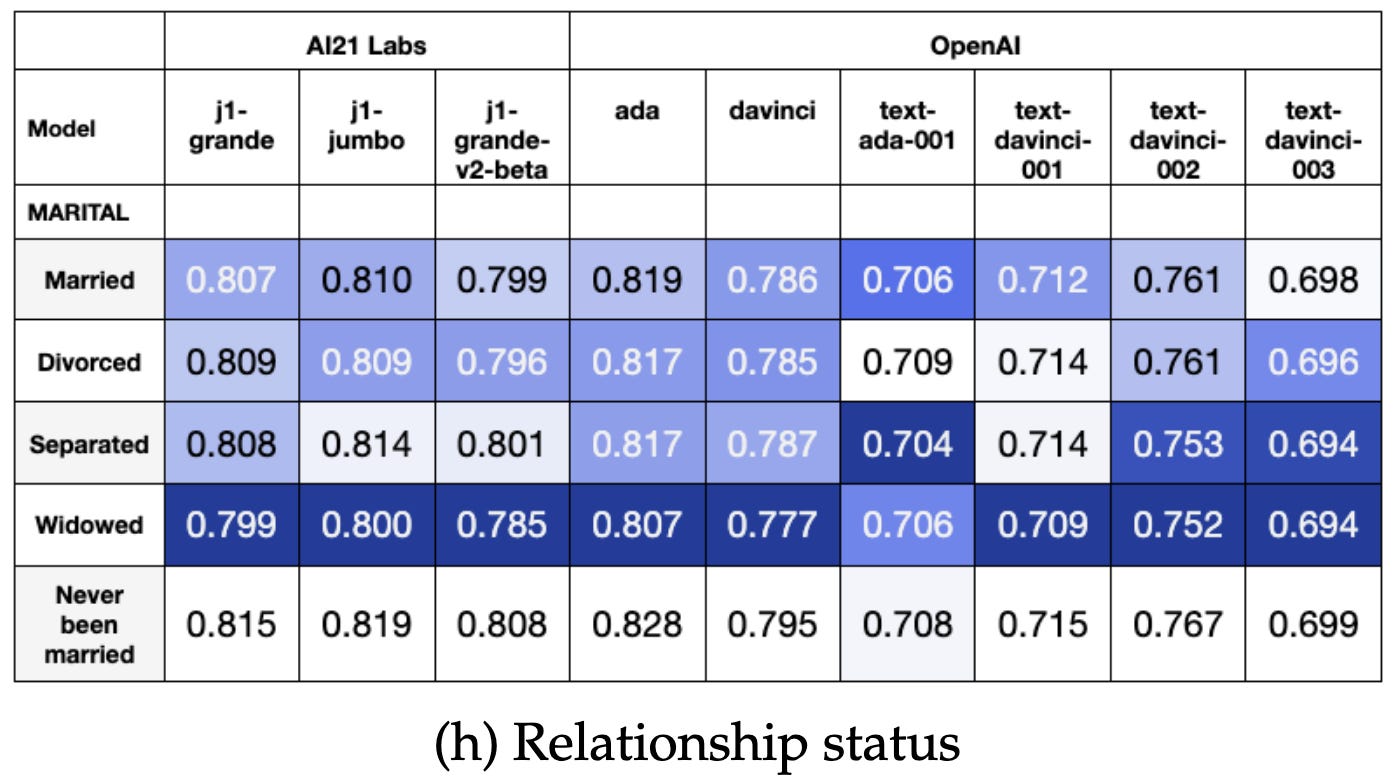
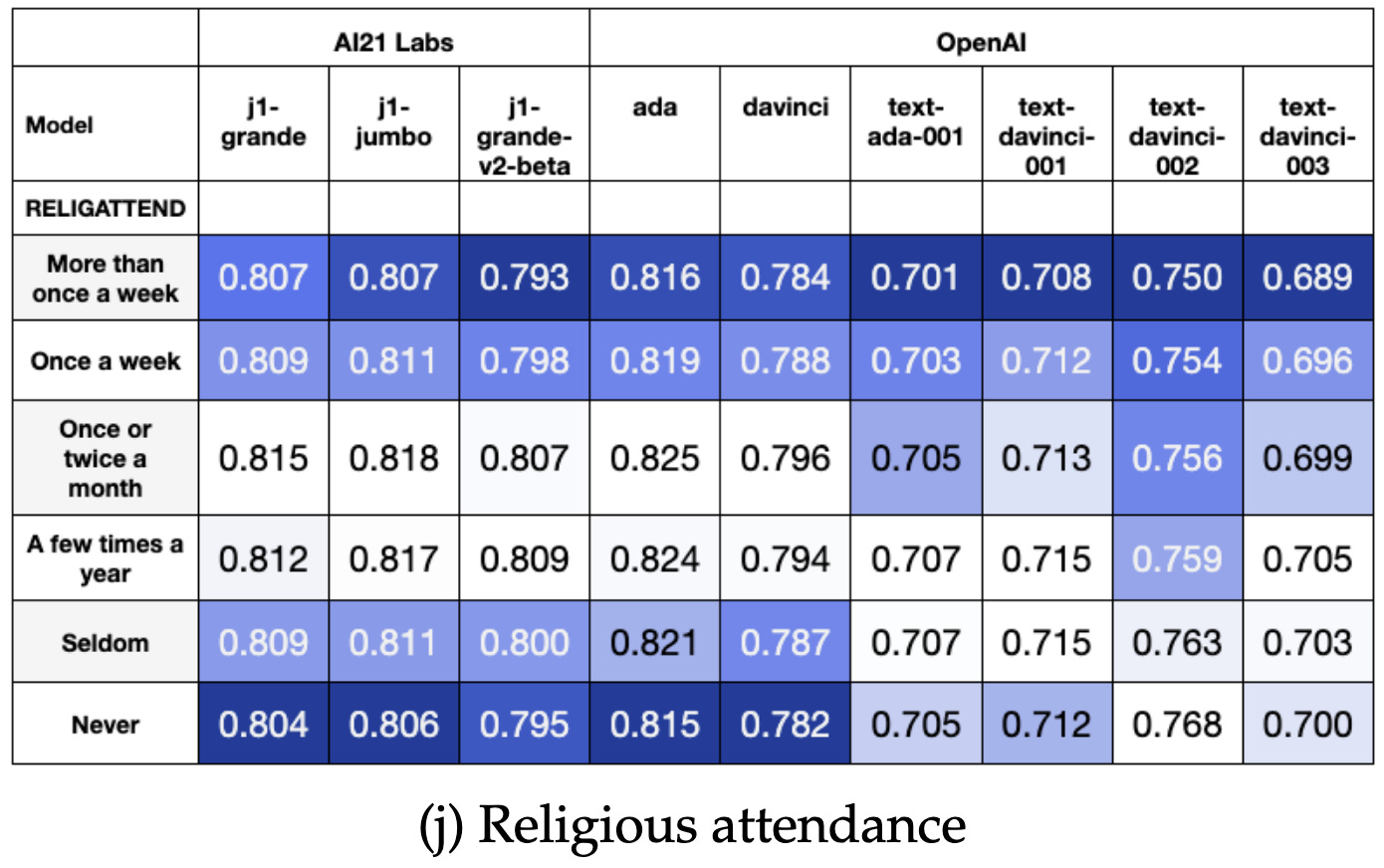

The models’ opinions don’t sync up super well with any one group though (note the lower values in this table compared to others). They’re mostly just weird.

If you try to “steer” a model by telling it to answer as if it were part of a given demographic, it does a bit better, but not great.

This is an awesome empirical study of phenomena that many people had observed empirically. Their dataset is also a great contribution that will hopefully make diagnosing biases easier in the future.
It’s also interesting that the models trained with RLHF were less aligned with human opinions.

Finally, I really like this as a reminder than claims of “alignment”2 should always be answered with “alignment with whom?”
Foundation Models and Fair Use
They discuss relevant case law for hypothetical AI usage examples and perform experiments to investigate the extent to which models copy their training data verbatim.
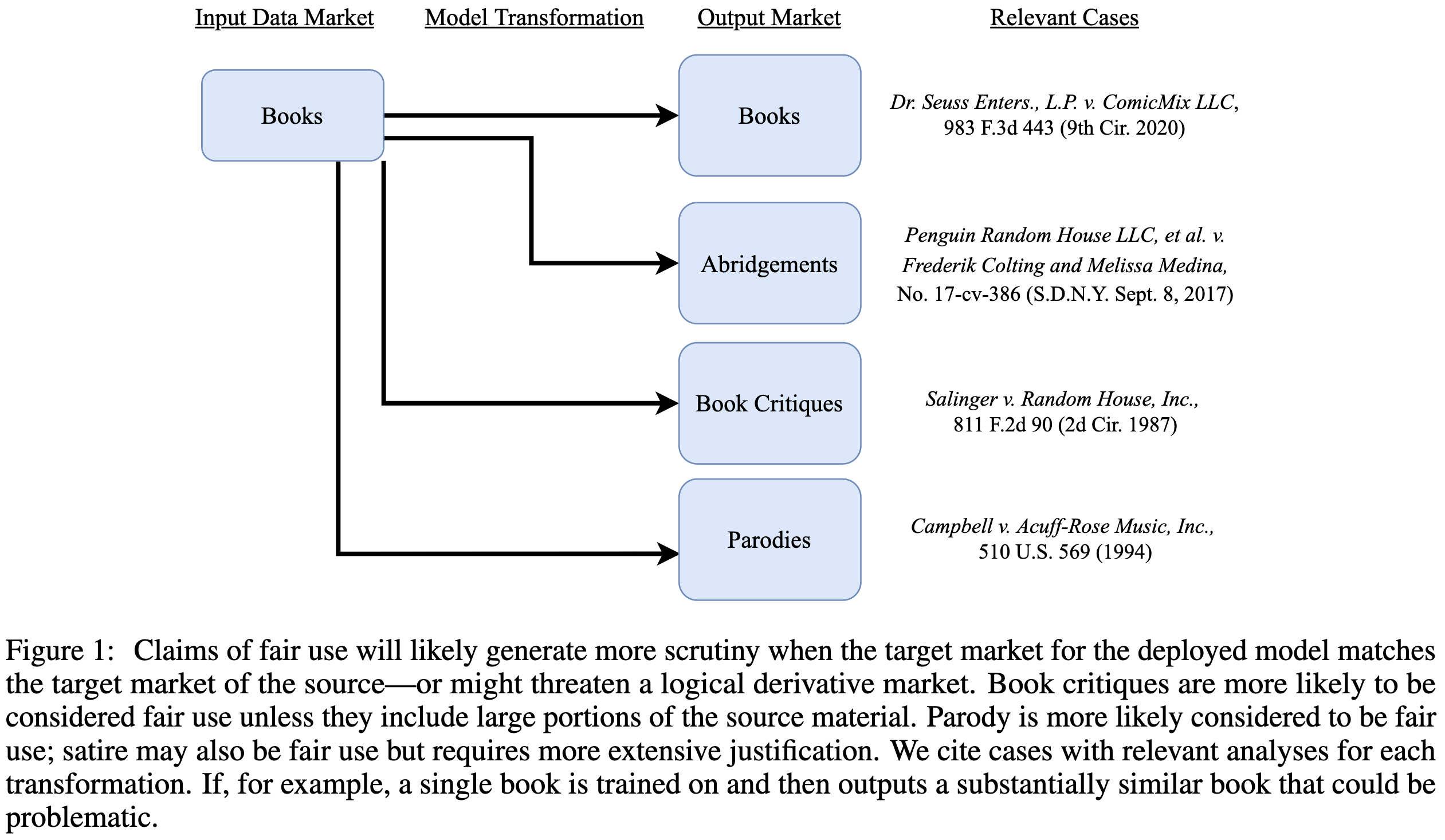
For example, they talk about what happens if an AI can recite a whole book to you or generate video game assets that resemble existing art.


In terms of experiments, they find that text models other than OPT-175B don’t usually memorize books exactly. Memorization is way more likely with popular books, though.

Similarly, code generation models produce code that might get flagged as plagiarism in a computer science class <1% of the time. And when they do, the code is usually not even structured identically to the matched code (what Moss measures), let alone copied verbatim. Unless the meanings of Moss thresholds have changed since I TA’d 6.0001 in 2016, this is…way less regurgitation than I was expecting.
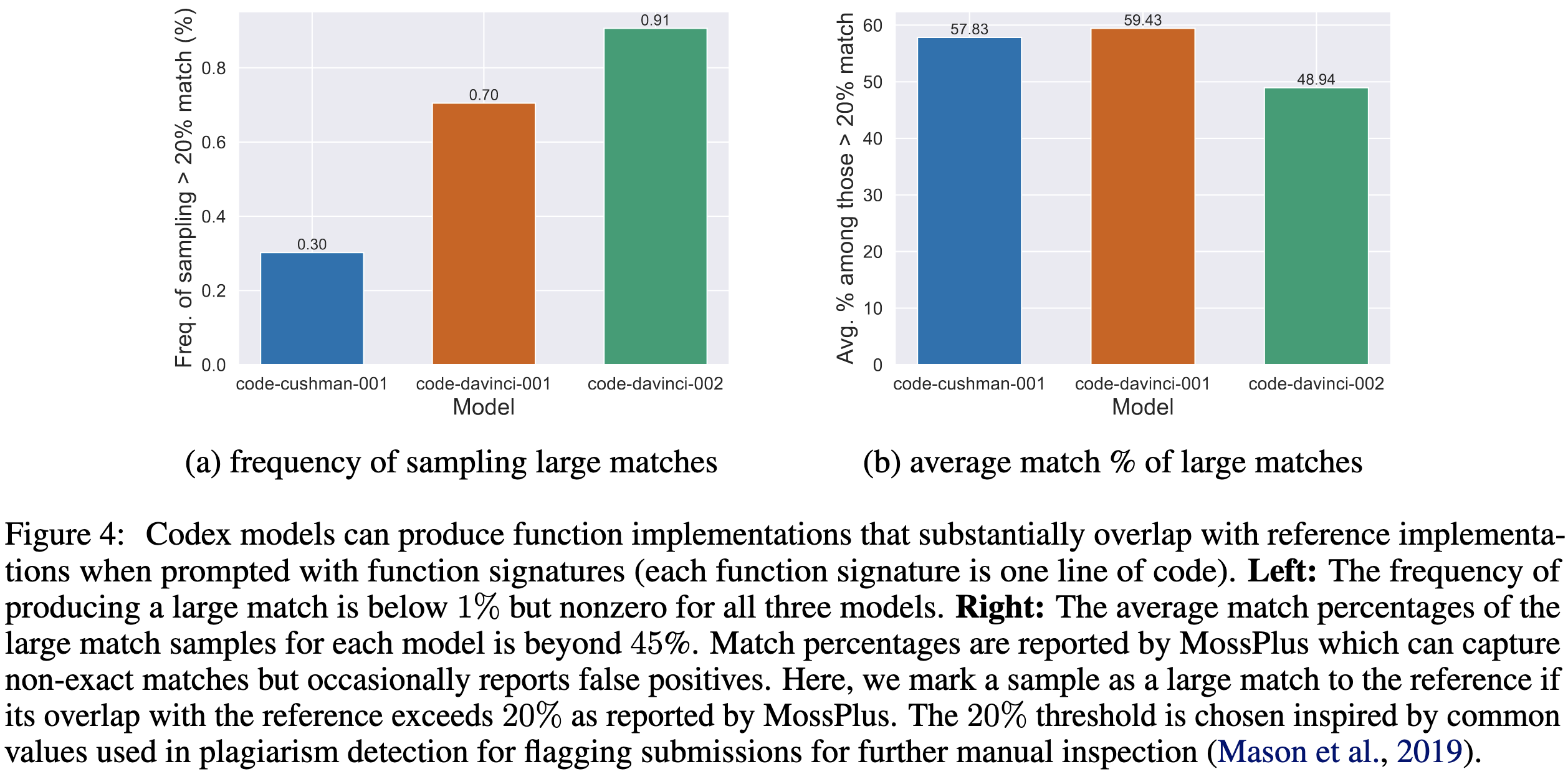
They also discuss technical mitigation strategies to help model outputs fall under fair use rather than infringement.

Example mitigations include protecting training samples with differential privacy or filtering out infringing outputs (if we can detect them).

A great jumping off point for anyone serious about understanding AI and copyright law.
Token Merging for Fast Stable Diffusion
They merge tokens within blocks of their vision transformer to save compute while only slightly degrading image quality.

More precisely, they have learned merging and unmerging operators within each transformer block.

To merge and unmerge tokens, they first consider the approach of:
merging adjacent pairs of tokens by just averaging them
unmerging by just setting both tokens equal to the merged value


This simplistic approach already works okay, even when applied to off-the-shelf models with no training.

It seems to be crucial to merge the tokens, as opposed to just dropping some of them.

It turns out you can do better than this naive merging operation. In particular, sampling a token to merge into at random from each 2x2 patch works better than merging to downsample on a grid.

They also improve the speed vs quality tradeoff a bit by only merging tokens for self-attention modules, only merging in U-Net layers with high enough resolution, and by merging more tokens at earlier diffusion steps.

Overall, they get what seems to be a significant improvement to the {speed, RAM} vs FID tradeoff.

Visually, the accelerated generations also closely resemble the baseline generations.

Between their ablations, their overall results, and similar work, it seems like token merging actually works.
Also, the fact that it helped the most in high-resolution self-attention layers makes me wonder whether there are simpler alternatives; e.g., maybe we just shouldn’t be using (regular) attention at high resolutions?
BloombergGPT: A Large Language Model for Finance
You probably know Bloomberg from Bloomberg News. But their main business is selling the Bloomberg Terminal and related products. To help improve these products, they trained a custom 50B parameter model.

Their dataset consists of 700B tokens of generic text data and finance-related data like company news and SEC filings. They deduplicate the data and train on 569B tokens.
The model is a decoder-only causal language model based on the BLOOM codebase. The model is a bit larger than you’d expect from the Chinchilla scaling curves because they only have so much financial data, don’t want to change the ratio of general to financial data, and want to stick to a single epoch.

The hyperparameters are pretty standard. They use Megatron’s attention scaling for numerical stability, AliBi attention biases, and no dropout for most of training. They shard the model across 64 machines via Zero-3 and SageMaker Model Parallel, the combination of which gets them about 33% hardware utilization.

As you might expect, keeping the training on track required some manual intervention over the course of the 53-day run.


The resulting model does much better than existing alternatives on financial data.
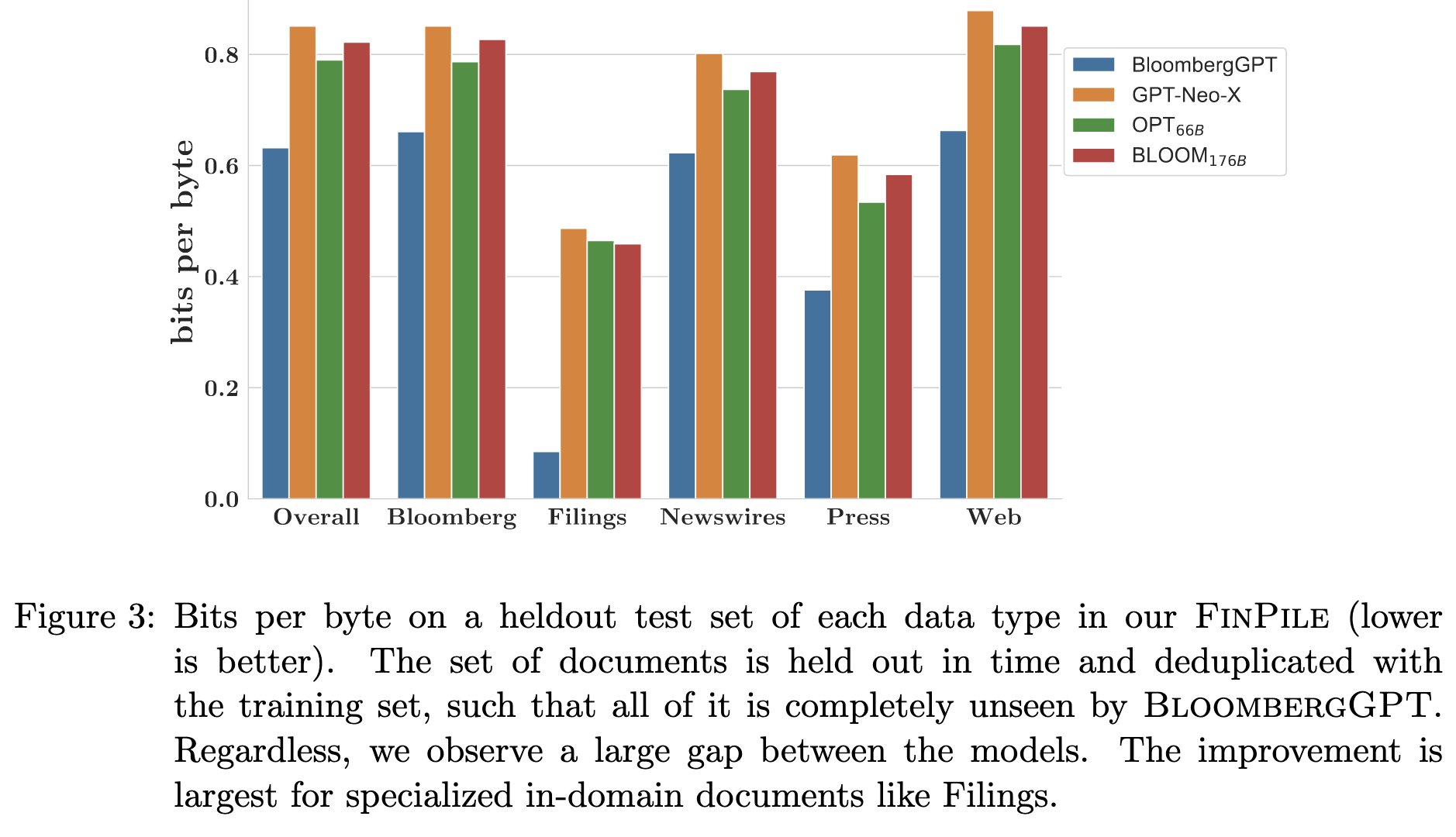
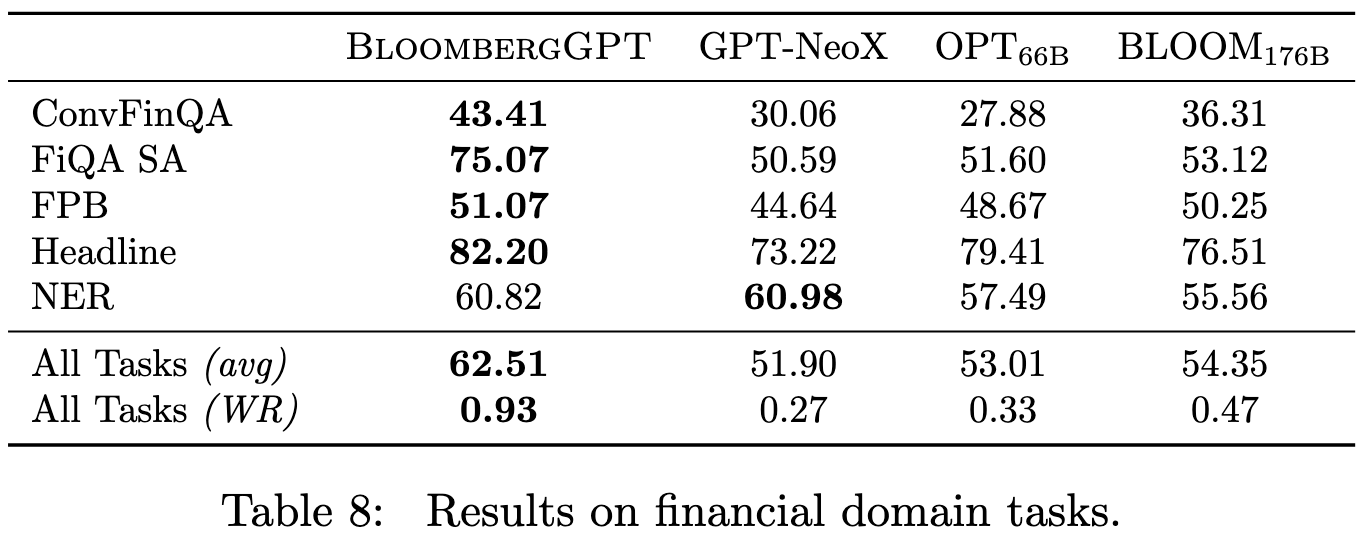

This improvement holds even though BLOOM-175B had access to way more training compute.

Relatedly, this paper is a gold mine of real-world use cases. Super valuable if you’re trying to understand how AI actually gets used in practice.






On academic benchmarks, BloombergGPT does about as well as other large models, despite half of its training data being focused on finance.

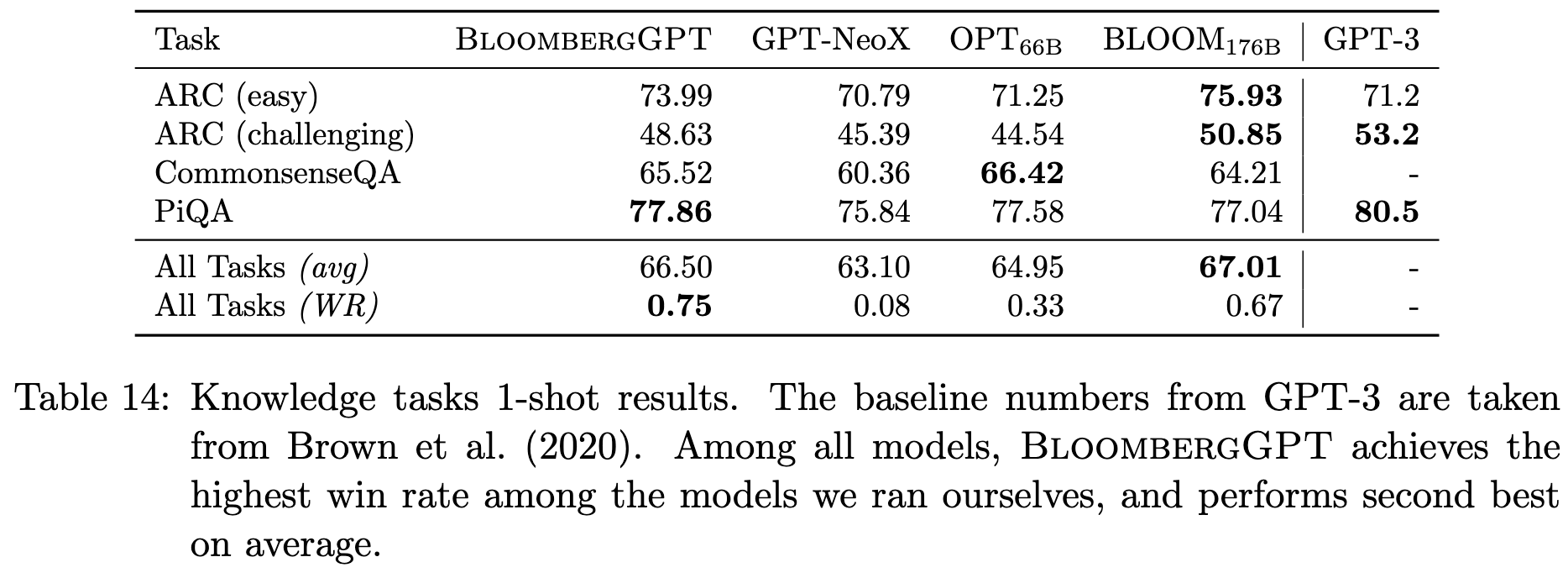

A great case study in making large language models useful for an enterprise.
It’s bizarre how often there are suddenly 2-4 independent papers on the same topic within about a week of each other. Maybe technological progress is more deterministic than we think. (And no, it isn’t plagiarism.)
I recently saw a product landing page describing their “aligned model.” I really hope the word “aligned” doesn’t get co-opted to just mean '“we did some instruction finetuning”.
HI, I am new to your newsletter, and I am very excited for the future.
I really think that you should do a compilation post on good papers that lays the foundation of MLAI these papers are good to start
1. A Comprehensive Survey on Pretrained Foundation Models: A History from BERT to ChatGPT https://arxiv.org/abs/2302.09419
2. Talking About Large Language Models https://arxiv.org/abs/2212.03551
3. Attention Is All You Need https://arxiv.org/abs/1706.03762
4. A Survey of Large Language Models https://arxiv.org/abs/2303.18223