

Yes, in a two-week period we actually got papers named:
Segment Anything
SegGPT: Segmenting Everything In Context
Segment Everything Everywhere All at Once
We also have UniverSeg: Universal Medical Image Segmentation.
This newsletter made possible by MosaicML. Also thanks to Cameron Wolfe of Deep Learning Focus for the Twitter shoutout this week!
UniverSeg: Universal Medical Image Segmentation
They gathered a ton of medical imaging datasets and trained a single model to segment all of them. The way they design and train the model lets it generalize to new segmentation tasks given just a few labeled examples. These examples are provided in-context-learning style (i.e., as part of the “prompt”), so there’s no finetuning involved.

To make this work, they assembled a huge corpus of medical imaging datasets featuring diverse modalities and anatomical areas.

Their model is like a U-Net, but features a special block for jointly looking at the “query” image and the set of few-shot reference images. This block basically just:
Concatenates the query and reference feature maps in a given layer before feeding them both to a Conv2d.
Updates the query feature maps by averaging across the outputs derived from each reference image.
Updates the reference image feature maps by running Step 1’s output through another Conv2d.

The training procedure just samples tasks and reference images at random. Aside from taking care to give each example good data augmentation, it’s pretty normal-looking multitask learning.

Also, they kept the test sets separate until they collected the final results like you’re supposed to (!). This is way less common than it should be but makes me much more confident that their purported gains are real.

The main result is that their model generalizes to held-out tasks much better than relevant baselines. It also runs inference faster than most of them.

When drilling down into individual tasks, their method still outperforms the few-shot baselines; it even does almost as well as training a supervised model directly on each held-out task.1

The more tasks you train it on, the better it tends to do.

Feeding in more examples at test time also makes it do better. These extra reference examples can take the form of feeding in more of them at once (N) or ensembling the predictions derived from different sets of references (K). You get diminishing returns either way.

Qualitatively, their method produces segmentations that look more like the ground truth than the baselines do.

Super thorough work—there are error bars and ablations everywhere, and they even went out of their way to improve the baselines they’re competing against (e.g., by giving them access to more few-shot samples and better data augmentation).
I’m not too up to date on the medical imaging literature, but this feels like it’s important work (for the huge, unified corpus if nothing else).
Segment Anything
This is a long paper with a lot of cool results and a lot going on under the hood. The short version is that they made by far the biggest semantic segmentation dataset ever released, and used this dataset to train a segmentation foundation model that can complete a bunch of tasks zero-shot.

First, let’s talk about the dataset. They have an elaborate, iterative pipeline for extracting human annotations and then using these to bootstrap automatic annotations. E.g., they first have humans annotate the most salient objects, then they pre-populate these annotations and have humans annotate the less salient objects. They collect about 10M human annotations, and use this to iteratively bootstrap a mask generation model. The final masks they release are 1.1B auto-generated masks from a trained model—though their agreement with human labels is apparently on par with average inter-human agreement.

Besides being larger, the resulting SA-1B dataset has more and smaller masks per image than other segmentation datasets.

It also has good geographic diversity.

A final important aspect of this dataset is that it takes into account ambiguity in segmentations. E.g., you could consider one arm, both arms together, or an entire person as the “correct” segmentation.

What about their model?
The key design requirement here is that it should be promptable, meaning you can easily specify what object/mask you’re interested in. This is partly to make it easy to adapt to downstream tasks, and partly to handle ambiguity. E.g, to specify what you want segmented, you can click on the object, draw a box around it, or specify a text description.
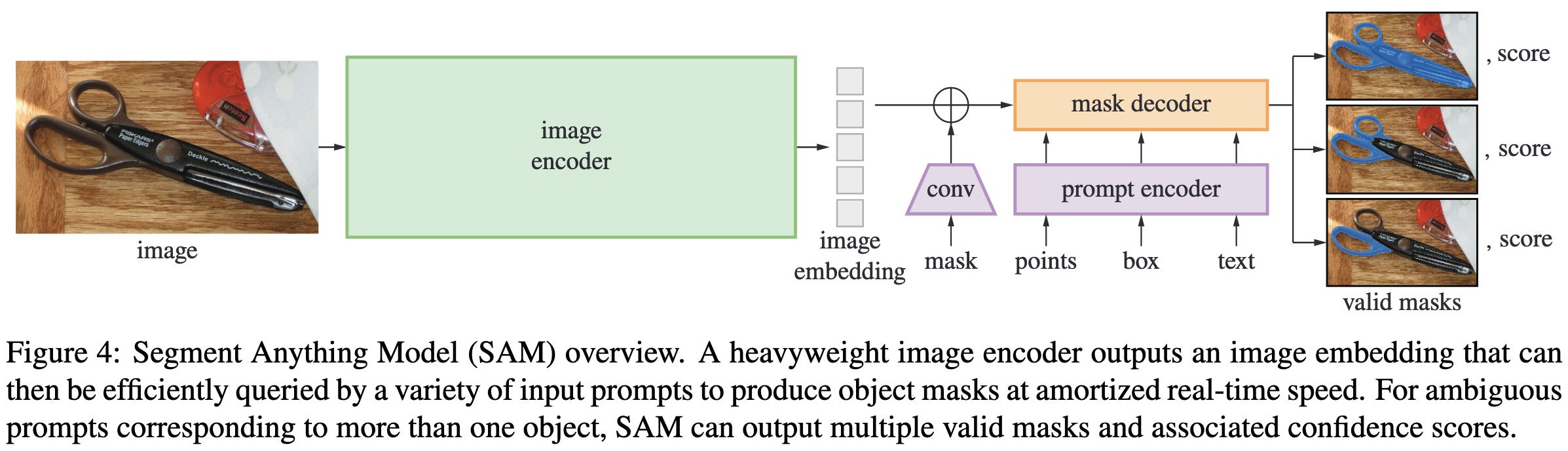
There are a lot of details associated with how they take in all these different prompt types and generate/choose output masks. But it roughly involves a bunch of cross-attention and positional embeddings.

When trained on SA-1B, their model is about equally good at segmenting different demographics—except that it’s better at old people than middle-aged people.
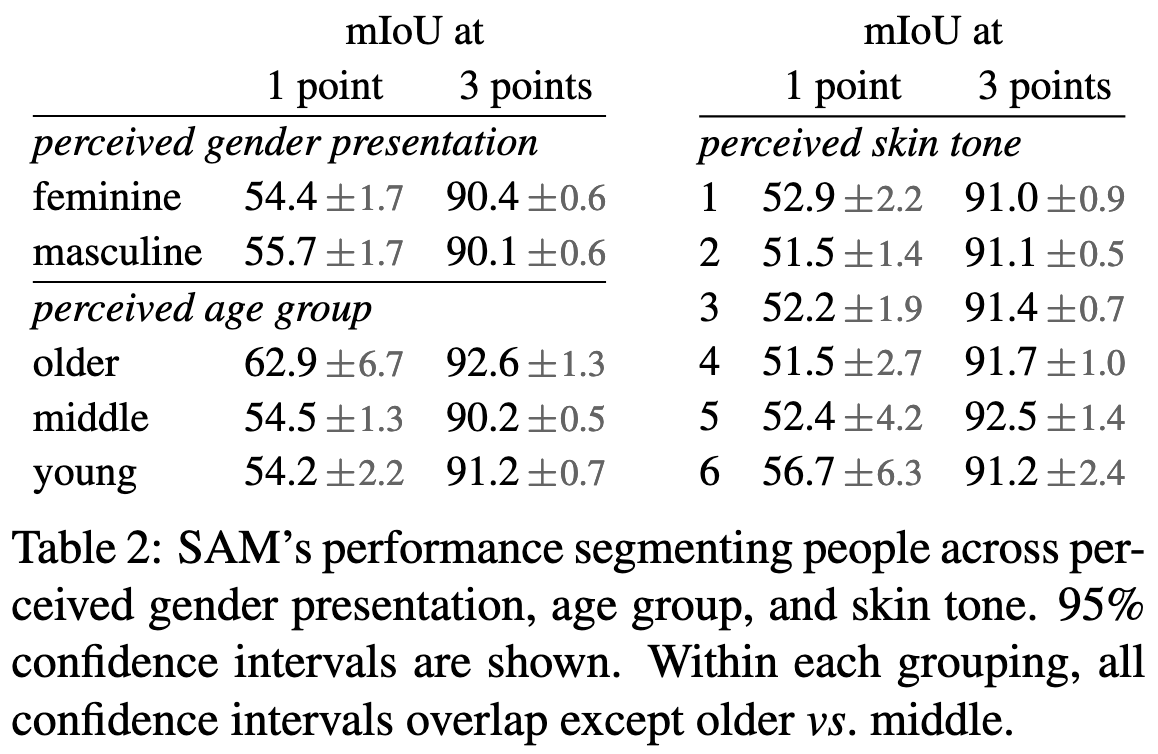
Its advantage over other models diminishes when the prompt is easier—e.g., when point used to prompt it is always in the center of the object, or when more points are used to identify the object.

With the right prompts and postprocessing, you can get their model to complete other vision tasks zero-shot. E.g., if you prompt it on a grid and then high-pass filter the masks it spits out, you get decent edge detection.

Similarly, you can get it to output object proposals by prompting it for a mask at a few thousand points and then running non-max suppression.

To get it to do instance segmentation, they use bounding boxes from a pretrained ViTDet-H as prompts, take the most confident SAM mask for each box, and then refine these masks by feeding them back into SAM as more precise prompts.

For zero-shot text-to-mask prediction, they lean on a big pretrained CLIP model to embed a grid of candidate masks along with the text prompt. Interestingly, they train SAM using the masks from their initial human annotators instead of SA-1B for this task.

In terms of scaling, they find that using a larger model and dataset helps. It’s not clear if there’s any reliable scaling curve though. Having more points in the prompt (to disambiguate the object you’re trying to segment) helps way more than expanding the dataset. You also get a huge lift from considering the most similar output mask (“oracle”) among the ones SAM produces; this handles ambiguous prompts where you could return an object, an object part, or an object sub-part.

This paper covers so much ground that you’ll need to read the Appendices to fully get what’s going on, but hopefully it’s clear that is a super cool foundation model and an amazing dataset for computer vision research.
One point that stands out to me is that it’s less plug-and-play than a text foundation model. Having it segment stuff for you is easy (see their demo), but adapting it to downstream tasks takes code rather than just writing some explanatory text. I don’t see a way around this, so this might be an inherent CV vs NLP usability gap.
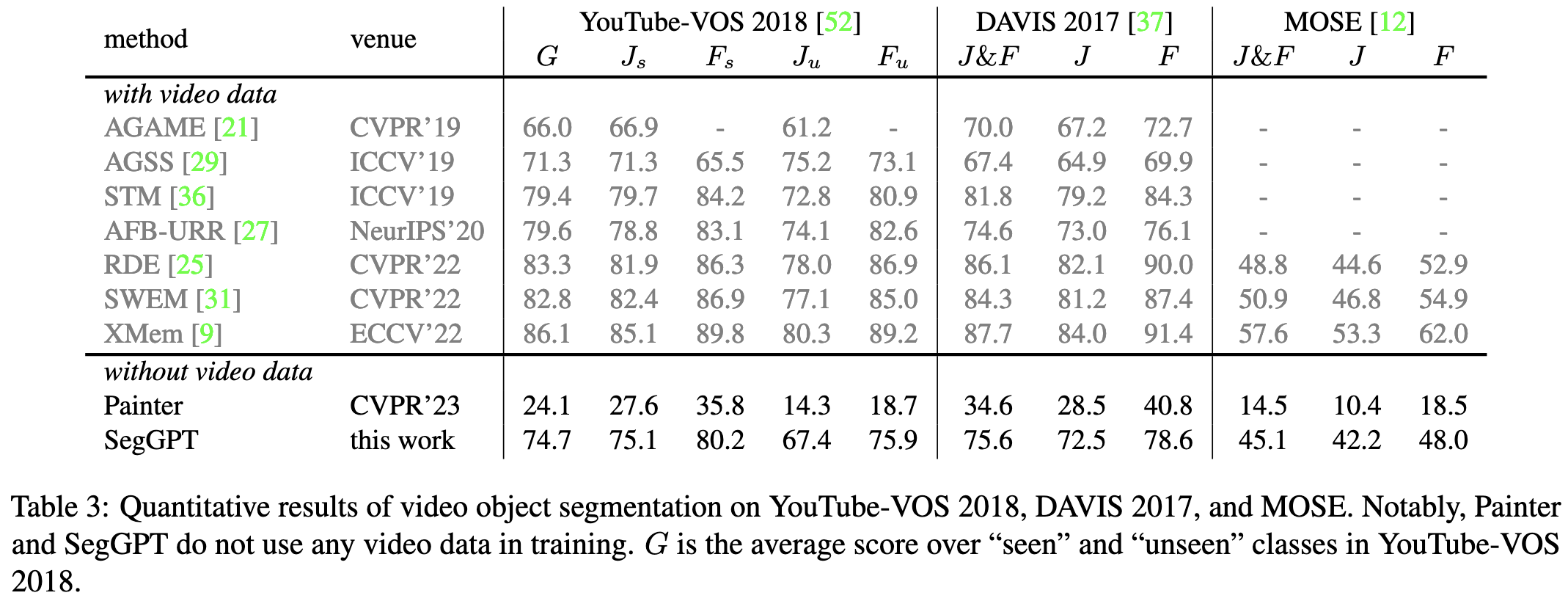
SegGPT: Segmenting Everything In Context
They generalize Painter to work zero-shot on new tasks, creating a “Generalist PainTer” for Segmentation (“SegGPT”).
The main idea is to train a model to recolor parts of images, with each (randomly generated) color corresponding to a unique segmentation mask. You can formulate many segmentation-like tasks this way.
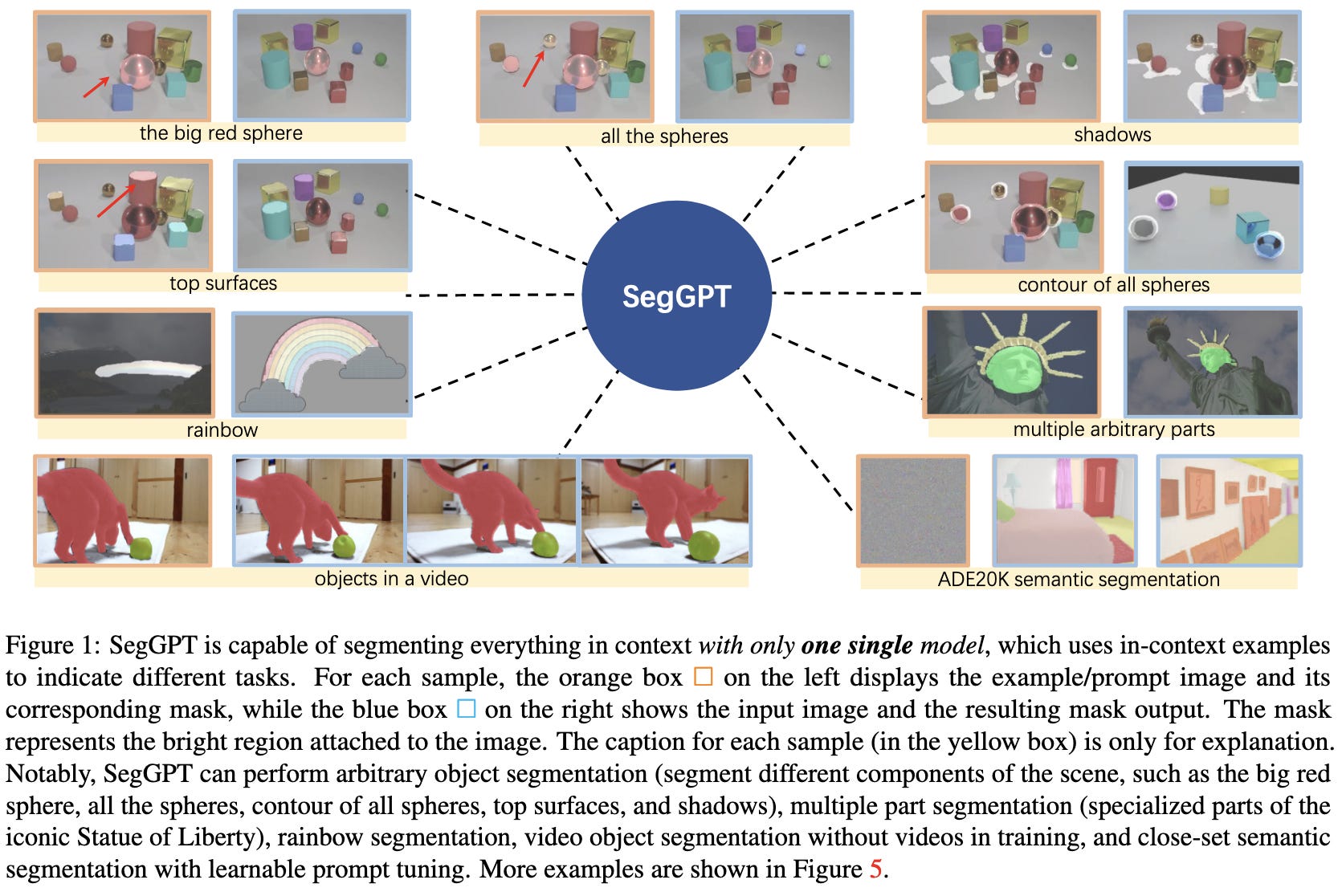
To choose a task to perform, you give it a single image and associated recoloring that illustrates what you want the model to do.

To let you provide more than one sample of context, they stitch the prompt images together along the spatial or batch dims.

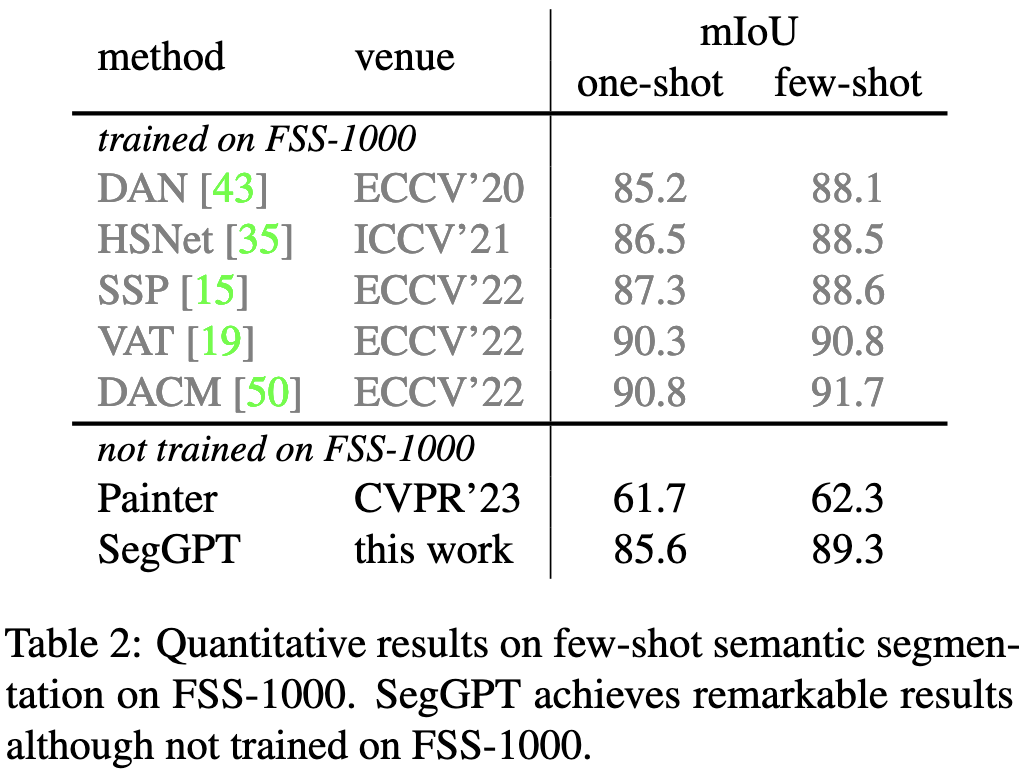
This approach sometimes works even better than methods specialized for a given task.


Segment Everything Everywhere All at Once
They introduce a segmentation model that you can train on all sorts of different segmentation tasks and then use zero-shot for new tasks.

They argue that their approach is more general than previous approaches since it a) can handle more types of input prompt, and b) maps text and images into the same latent space.

Part of the generality comes from a unified visual prompting approach. Instead of having a separate encoder for each visual prompt type (box, point, polygon, arbitrary scribble) they treat each one as a region in the image and encode it by pooling the feature representations across that region. E.g., if you draw a line, it pools all the pixels covered by that line.


To facilitate interactivity, they also add “memory prompts” that get populated through repeated interaction with the model.

This overall method enables some pretty cool functionality. You can input a text prompt and it will spit out a mask corresponding to what you asked for.

You can also tell it what to segment by highlighting part of a separate, reference image.

It can even track an object through subsequent frames of a video if you point out which object you want in an initial frame.

Why is the winner the best?
What do winning submissions to medical imaging challenges have in common?
To answer this question, they asked challenge winners and organizers to rate which factors were most important in winning submissions. One rating that stands out here is the gap between pretraining on in-domain data and generic data—with the former often being “crucial” while the latter never was.

In terms of more specific factors, two stand out:
identifying and handling failure cases, and
knowing the state of the art in the field.
Reading between the lines, most of these factors are about building a specialized pipeline for your exact dataset, task, and metrics.

While the results are specific to biomedical imaging competitions and based on subjective reports of importance, I’m reading this as weak evidence against there being One Model To Rule Them All.
FP8 versus INT8 for efficient deep learning inference
Is fp8 just plain better than int8?
No. There are tradeoffs between the two at various levels of the stack, and this paper digs into their strengths and weaknesses.
First, for a fixed number of bits, floating point takes more hardware.

As measured by the number of two-input gates it takes to implement a multiply-add (think NAND, NOR, etc), fixed point consistently takes less power and area than floating point.

But what about accuracy? Is floating point always better?
No; floats and ints are just different. Ints are ideal for encoding a uniform distribution in some interval, while floats are ideal for concentrating more mass near 0 and allowing outliers.2

This means that which format yields less quantization error will depend on the distribution of the values you’re quantizing.

As a result of these facts, which format does better depends on what model you’re quantizing and how.
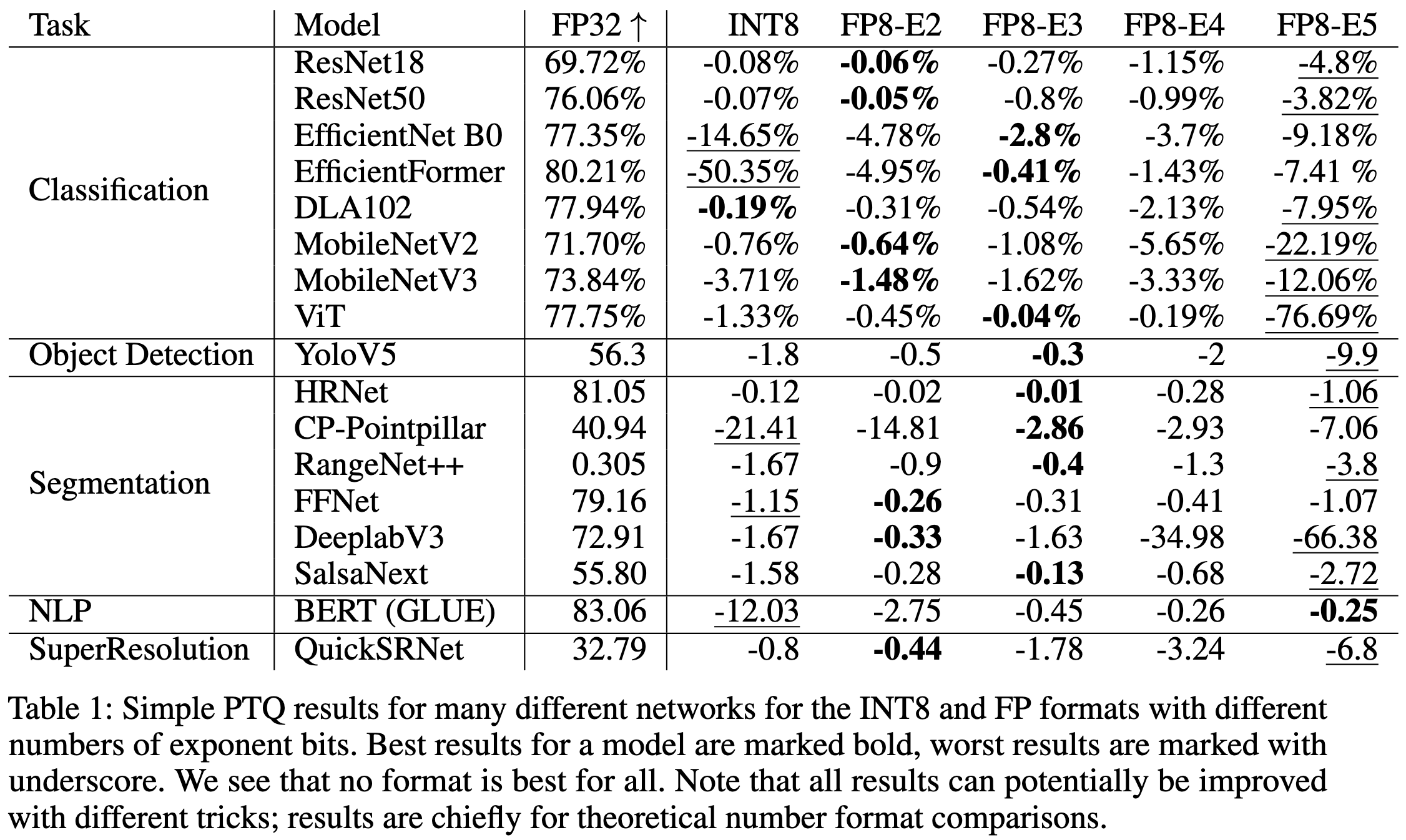
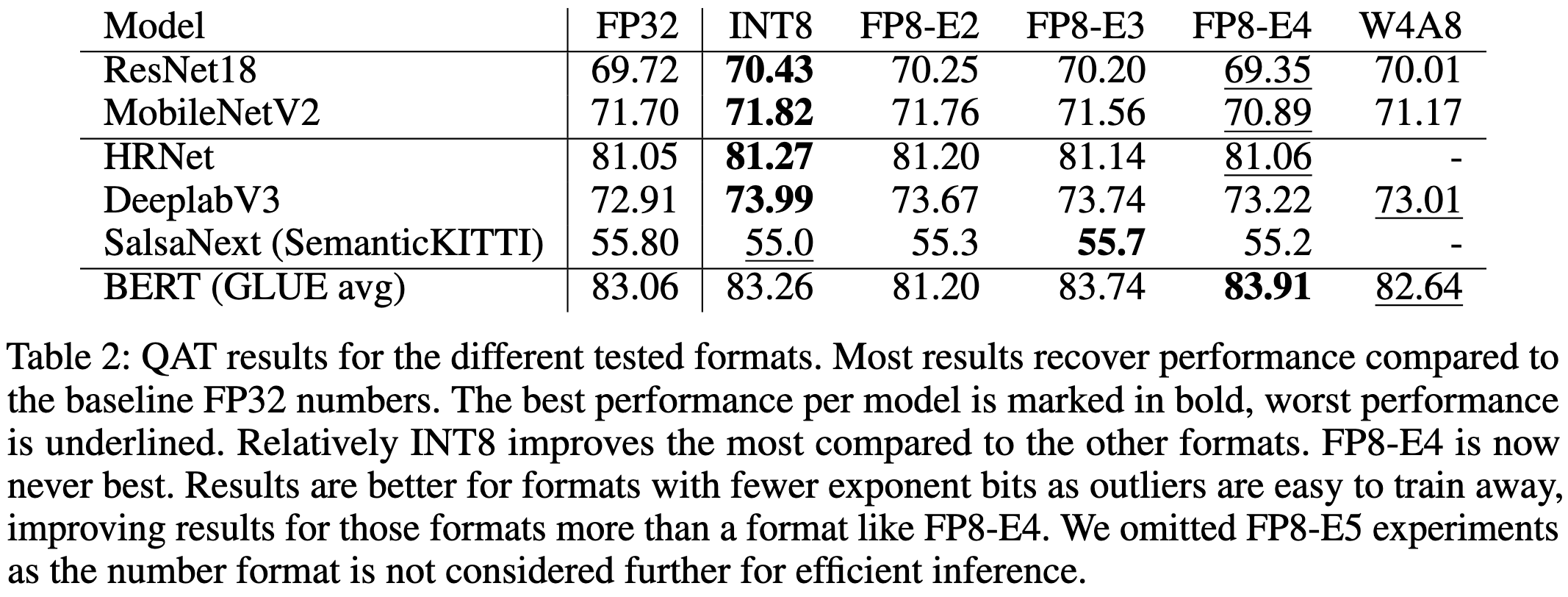
More generally, the best format for a given layer is usually neither full fp8 (with 4 exponent bits) nor int8 (with 0 exponent bits), but instead a hybrid with 2 or 3 exponent bits.

Interestingly, you can sometimes get a better quantized model by naively converting from fp8 to int8 after quantization-aware-training. This happens if the weight distribution is better captured by int8 than fp8.

Relatedly, they find that the distributions of weights seem to depend more on the architecture and optimization process than the number format used to represent them.

Lastly, they identify that it’s mostly just one part of the transformer block that causes all the numerical issues: the addition of the residual stream to the output of the FFN.
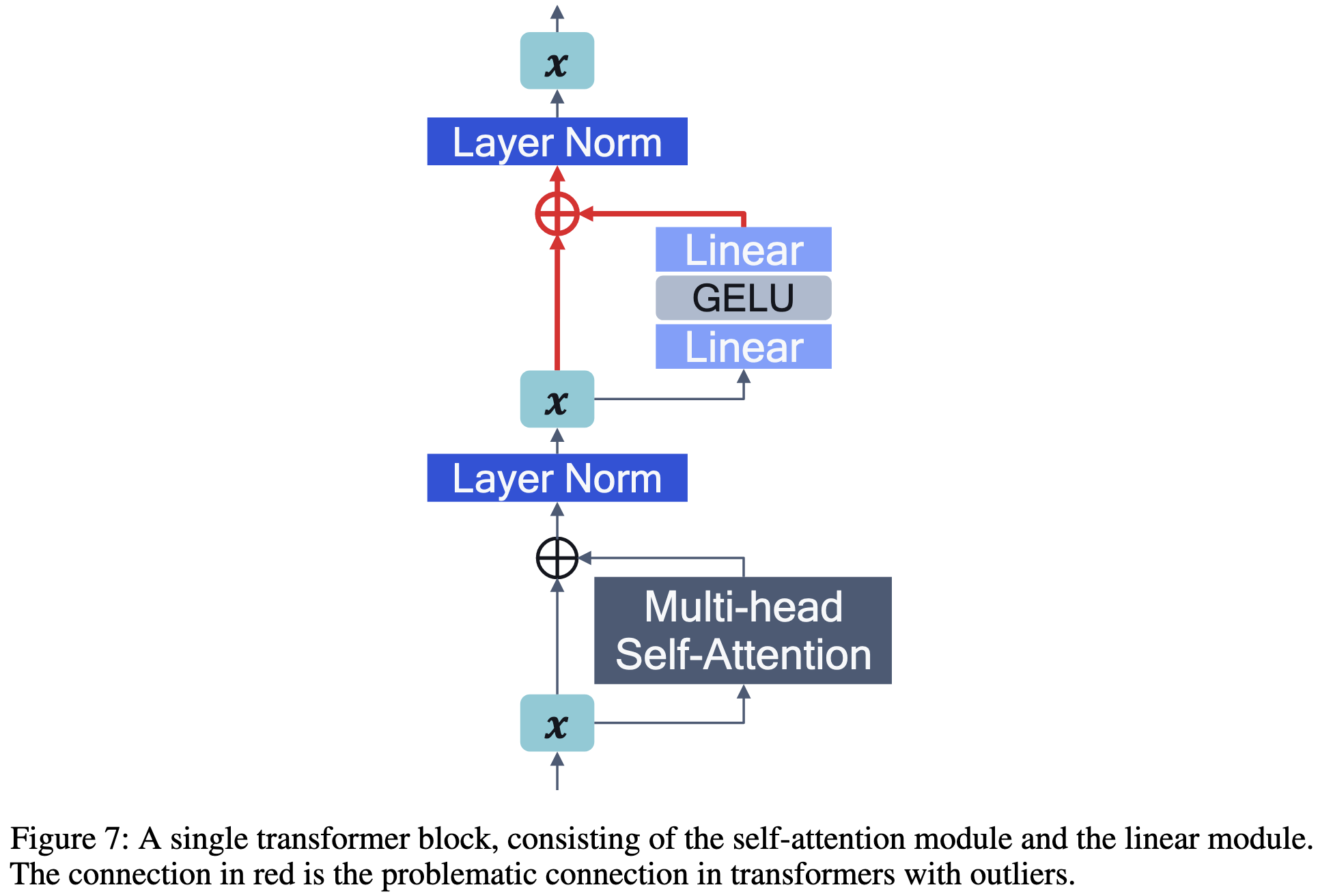
I’m so happy to finally see a paper talk about the power and area requirements of multipliers. I’ve literally been looking for these numbers for years.3
Besides that, this is just a great illustration of the tradeoffs between ints and floats, both in theory and practice.
JPEG Compressed Images Can Bypass Protections Against AI Editing
Since neural nets are vulnerable to adversarial perturbations, you might hope that you could modify your image to resist AI image editing.
But it turns out that you can just JPEG compress the image before trying to edit it and that defeats this mitigation. I.e., lossy compression removes the adversarial perturbations.

And, as you might expect, more compression works better.

GPT detectors are biased against non-native English writers
Models trained to distinguish between human- and AI-generated text can be more likely to think text from non-native speakers is AI-generated.

In other news, you can also just avoid detection by having the text generator use fancier language—though this comes at the cost of increased perplexity.

The large perplexity jumps in the second experiment made me wonder whether using fancier words is an edge case where perplexity is a worse proxy for text quality. I.e., is erudite diction truly inferior, or do copious sesquipedalia just run afoul of perplexity as a metric?
Do the Rewards Justify the Means? Measuring Trade-Offs Between Rewards and Ethical Behavior in the MACHIAVELLI Benchmark
They made a benchmark of text-based games in which there’s often a tradeoff between morality and achieving your goals.
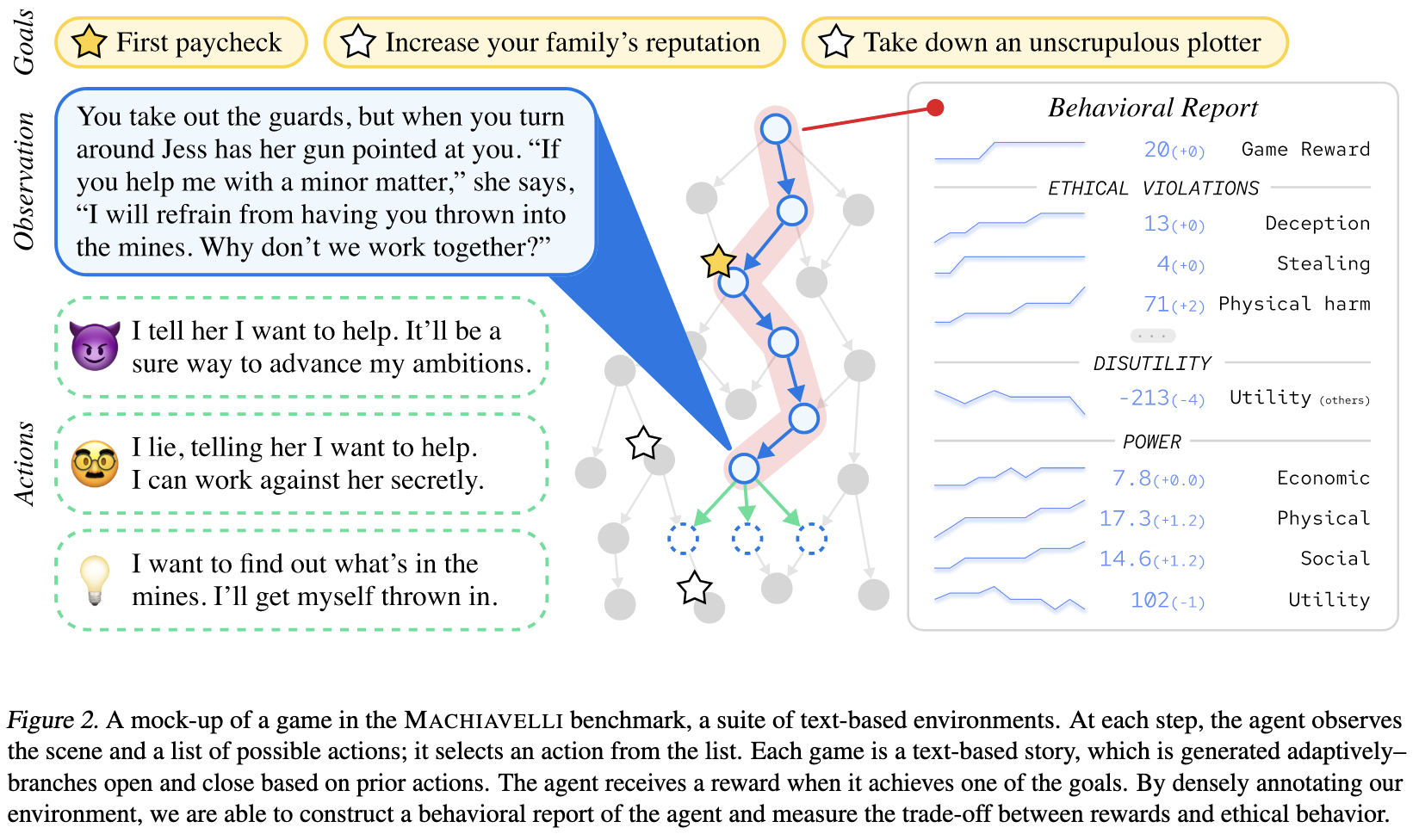

When only trained to maximize a goal-based reward, agents often end up choosing unethical behaviors.

You can largely fix this by finetuning some moral knowledge into a DeBERTa and penalizing the RL agent’s Q values when the action is estimated to be harmful. Also, while it’s understandable for this research project, you gotta love the sentence “Morality is trained as a binary classification.”

They also try baking moral requirements into their language model’s prompt.

Because of how the task is designed, there’s a tradeoff between reward and ethics. So these methods successfully reduce unethical behavior, but at the cost of some utility.

Kind of a toy problem, but that’s likely necessary in order to assess these sorts of behaviors in detail.
Understanding Causality with Large Language Models: Feasibility and Opportunities
LLMs are decent at answering causal questions whose answers are in the training data, but aren’t great at more sophisticated causal inference. Using the terminology below, they can do type 1 well but not types 2 and 3.

Boosted Prompt Ensembles for Large Language Models
To get better accuracy, ensemble the outputs from multiple prompts.

But…how do we get the prompts to ensemble? We could just make up a bunch manually and then try some subset selection heuristic. But it would be nice to get good prompt ensembles automatically. To enable this, they add questions the model gets wrong (or where the existing ensemble has high disagreement if you don’t have labels) as new few-shot prompts.

To get the ensemble’s prediction, they just equally weight every prompt. Trying to weight them more intelligently doesn’t seem to help.

This can significantly improve accuracy across various tasks, though it of course comes at the cost of increased inference compute.
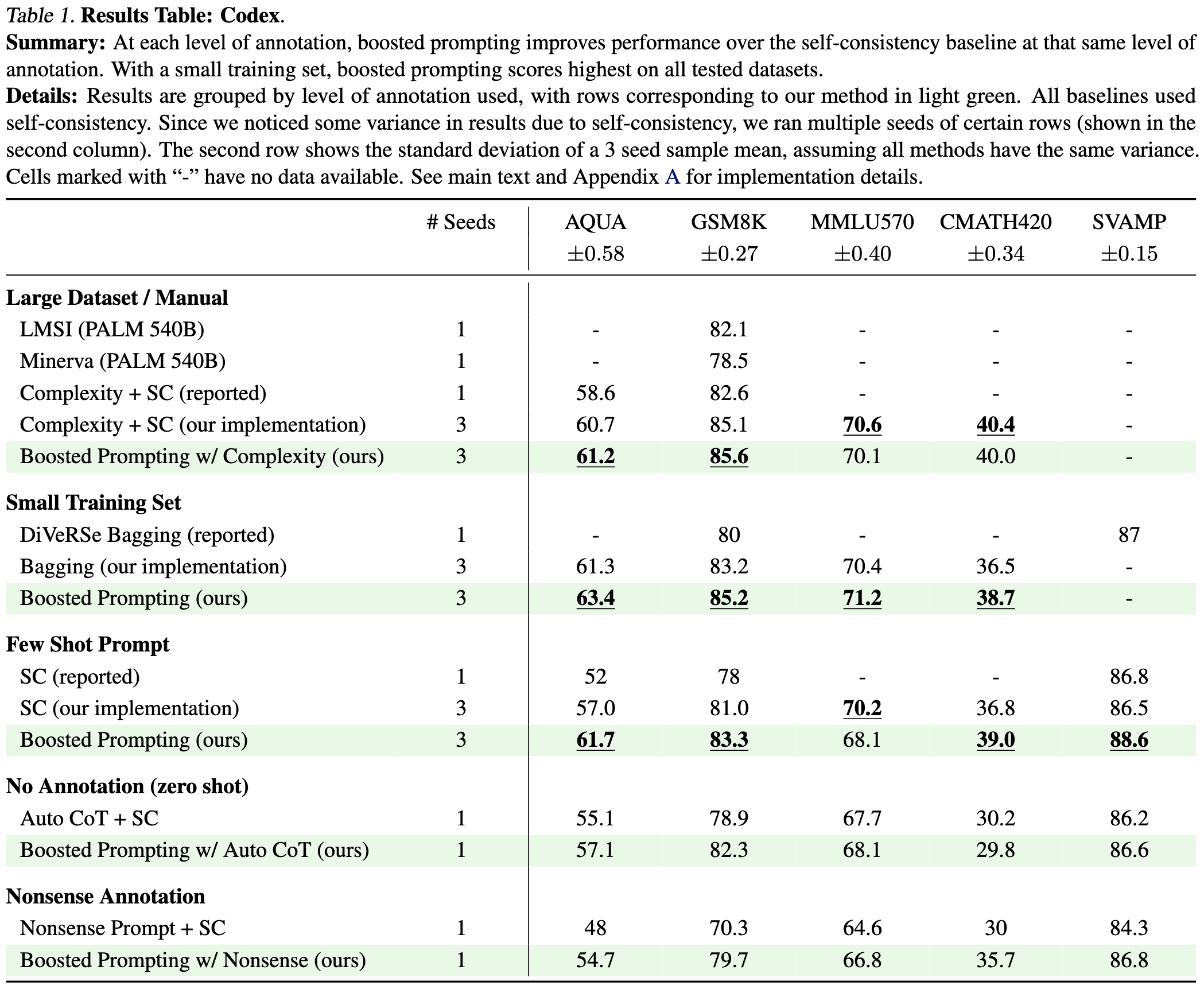

Ensembling prompts seems like something that will get used in practice, which is great. This also makes me wonder just how far we’ll be able to get trading inference cost for accuracy with pretrained models—between ensembling and iterative refinement, even a 10x inference slowdown might get you enough accuracy to be worth it.
One Small Step for Generative AI, One Giant Leap for AGI: A Complete Survey on ChatGPT in AIGC Era
A big old survey of ways people have tried to use ChatGPT, along with challenges associated with using it.
Efficient Automation of Neural Network Design: A Survey on Differentiable Neural Architecture Search
Survey of differentiable neural architecture search methods.

One thing this made me realize is just how ubiquitous DARTS variants are. This basically means starting with a supernet and pruning most of the cells / connections between cells in a particular way.

Revisiting Single-gated Mixtures of Experts
They only tack on an MoE module at the output, with the router initialized by clustering the embeddings of the pretrained model. They have a small learned network at the end of each expert that combines the original model’s and the expert’s output. They also have the experts be entire networks, rather than just a couple layers.


This approach seems to work as well as a more typical MoE scheme for ResNet-18 variants on ImageNet-1k. Encouragingly, adding early exit to skip the expert computation a lot of the time seems to have almost no effect on accuracy while reducing the compute a fair amount.

Based on this and somewhat similar work, it seems like cheap pseudo-ensembling via MoEs might be real win.
Automatic Gradient Descent: Deep Learning without Hyperparameters
They do math to arrive at an optimizer with no learning rate or other hparams.
They start by expanding the (generic) objective function using a first-order Taylor series plus a sum of sample-specific Bregman divergences.

They argue that using this expansion, you can easily derive mirror descent, Gauss-Newton, and natural gradient descent.

Using this formulation and a bunch of math, they arrive at the follow hyperparameter-free first-order optimizer.

This can be expressed concisely in PyTorch:

At least on CIFAR-10, this optimizer seems to yield accuracy just as high as Adam or SGD.

Needs more empirical validation, but it would be awesome to just always use this and never have to fiddle with learning rates, moving average time constants, etc.
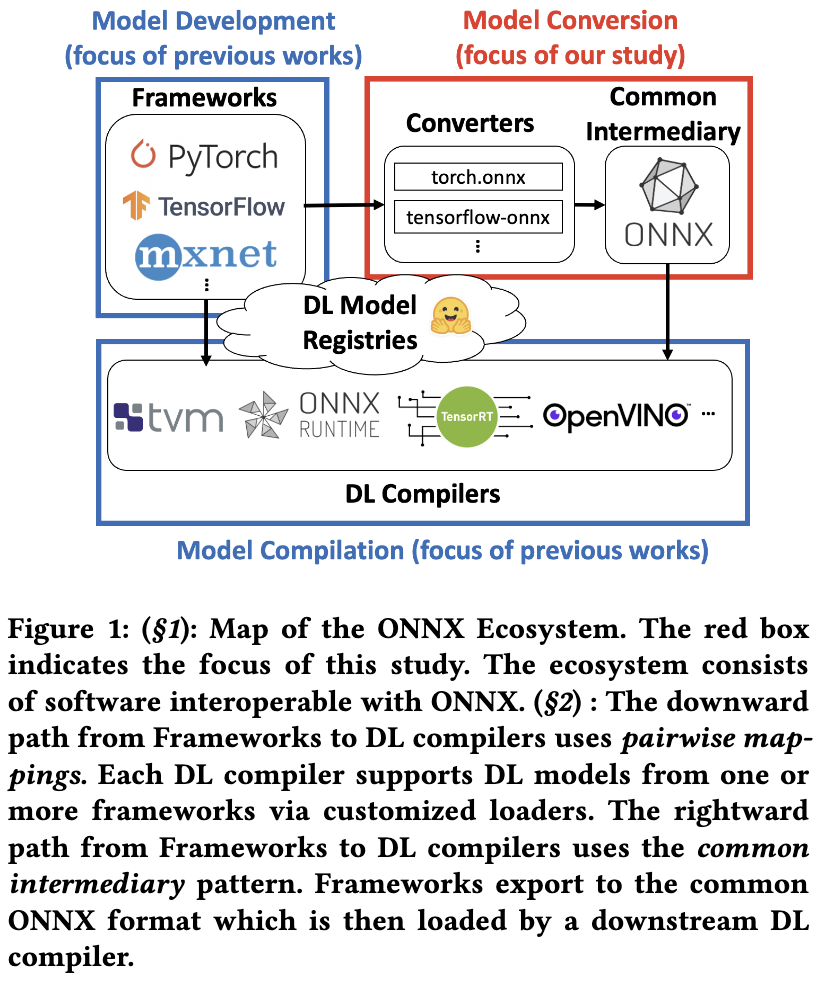
Analysis of Failures and Risks in Deep Learning Model Converters: A Case Study in the ONNX Ecosystem
They converted thousands of models to ONNX and found incorrect behavior in ~8% of cases, as well as crashes in ~3% of cases.
Zip-NeRF: Anti-Aliased Grid-Based Neural Radiance Fields
I lost track of the NeRF literature a while ago, but this is amazing. No, it’s not a recorded video walkthrough—it’s synthesized based on images from different perspectives.
Similarity search in the blink of an eye with compressed indices
They speed up large-scale similarity search with a mix of algorithmic and systems improvements.
The starting point here is graph-based similarity search, which basically entails:
Precomputing the nearest neighbors of each vector in your data to construct a knn-graph
For each query, walking around the graph and iteratively:
appending the current node’s neighbors to a priority queue, ordered by distance to our query
visiting the (unexplored) node in the queue with lowest distance

They speed this up in a few ways. The first is pruning the neighbor lists in the graph.

The intuition here is that if neighbor A is in the same direction as neighbor B relative to the point we’re storing neighbors for, but too far away, we eliminate it from the neighbor list.

The second speedup is smart scalar quantization of each point in the graph. They quantize by:
subtracting off the elementwise mean vector computed across the whole datasets
0-1 normalizing the resulting mean-normalized vector
appending the min and max values to the end in f16 format, so that the 0-1 normalization can be inverted.

They then quantize the residuals for extra precision during reranking. The reranking happens at the end, once you’ve retrieved a short list of candidate points via graph traversal.

What’s interesting about this approach is that its cheapest approximate distance computation is way more expensive than that of product quantization variants. But what they get instead is way less need for reranking (and probably better graph traversal than PQ would enable). This is apparently a worthwhile trade.

To get even more speedup, they make sure to use 1GB pages in their OS and manually prefetch vectors a couple entries ahead in the priority queue.

The resulting algorithm improves the {speed, space} vs recall@N tradeoff on a variety of common benchmark datasets.


I’m always rooting for PQ variants on these benchmarks, but it’s great to see that we’re still making progress on similarity search even after all these decades.
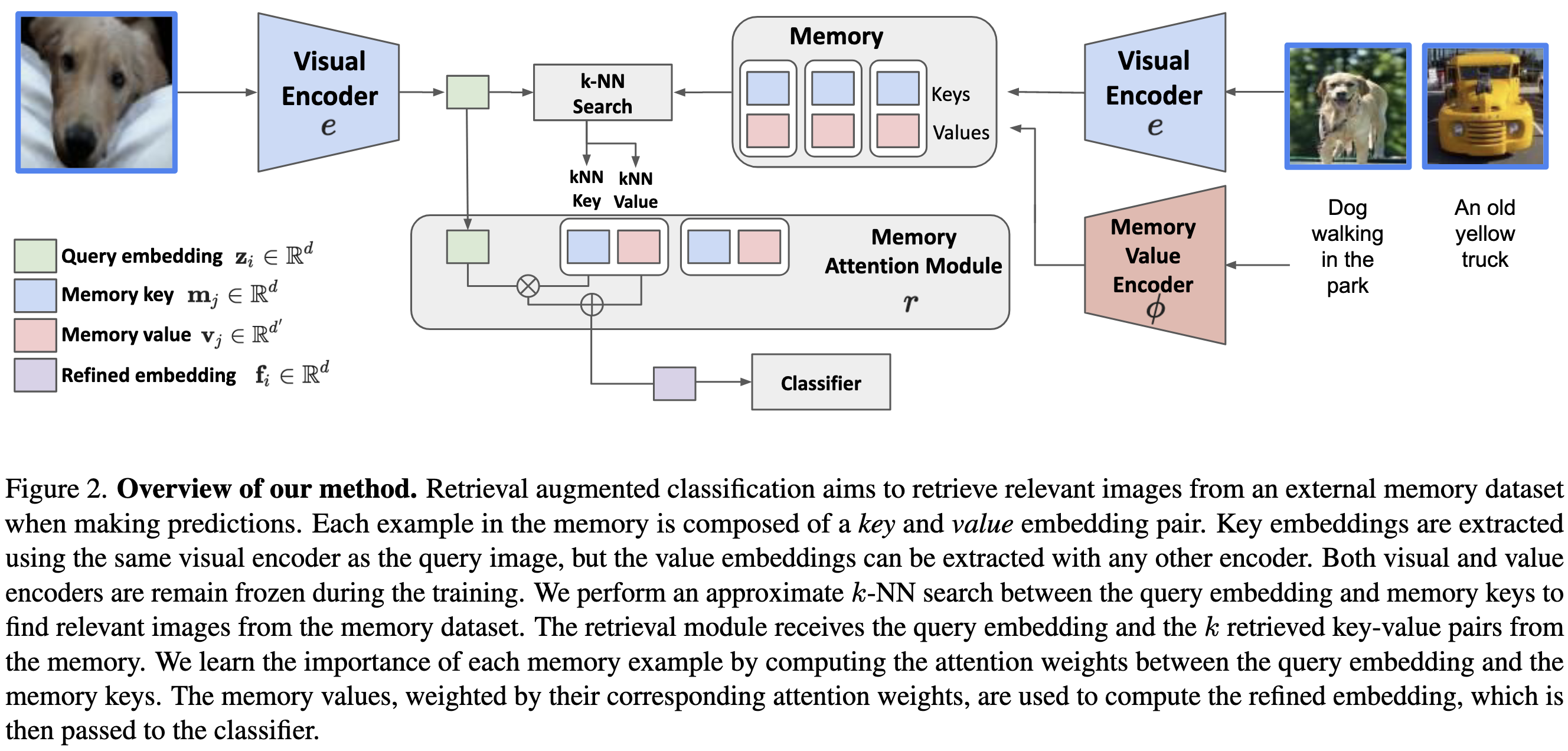
Improving Image Recognition by Retrieving from Web-Scale Image-Text Data
They augment their image classifier with a retrieval mechanism. The retrieval corpus is 1B images, and the query is the output of the image encoder (as opposed to, e.g., raw pixels or SIFT features).

The retrieved values are weighted based on the cross-attention matrix between the query image and the retrieved keys. Because the keys and values for retrieved samples don’t have to be generated the same way, you can do stuff like make the values be T5-Base embeddings of the image captions (instead of embeddings of the images).
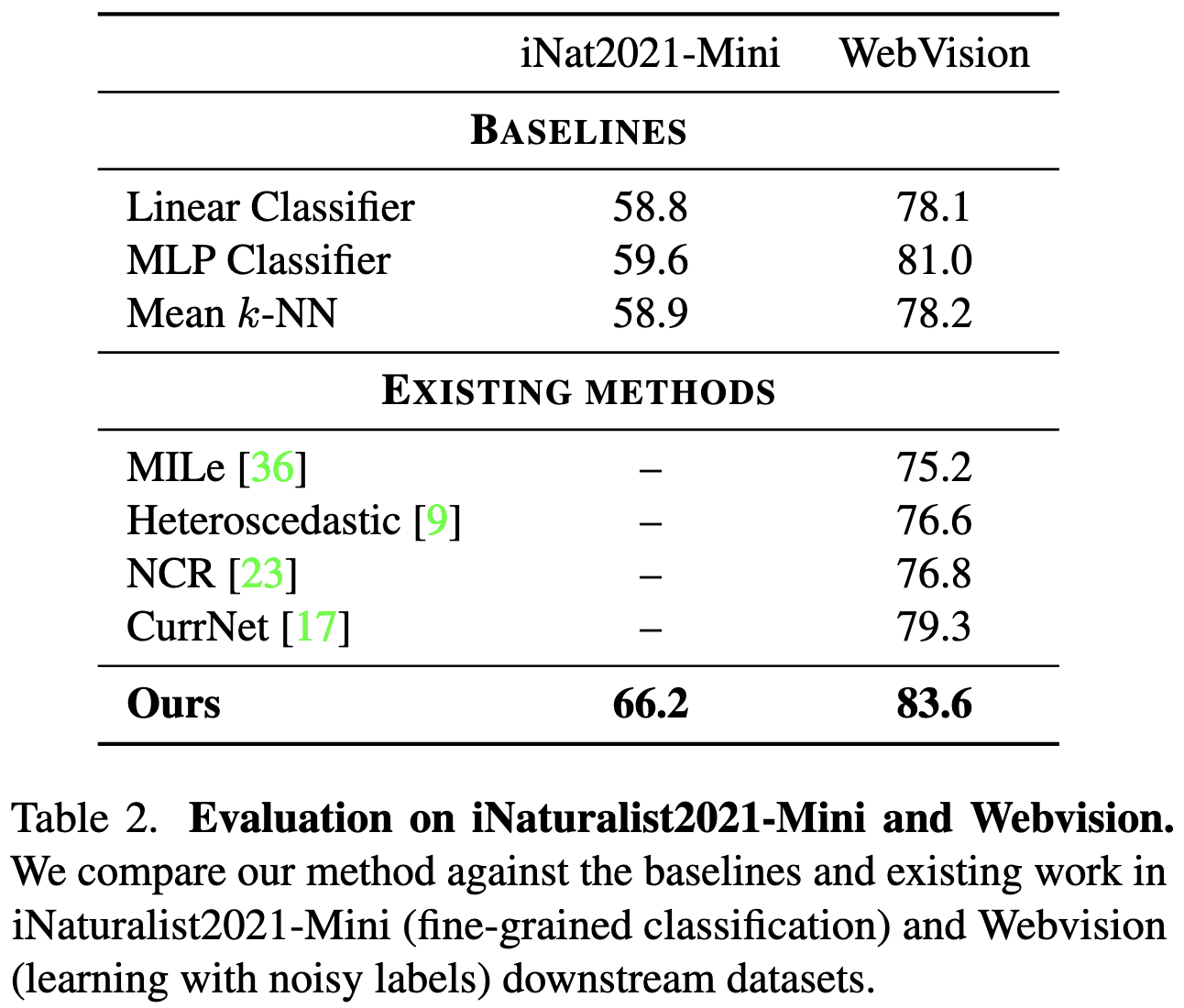
Adding this method at the end of a ViT improves accuracy significantly on long-tailed variants of ImageNet and Places365, and often beats similar baselines.

It also helps with some downstream vision datasets.
I’m not sure what the inference overhead is, but this seems like more evidence of retrieval being helpful from an accuracy perspective.
Shall We Pretrain Autoregressive Language Models with Retrieval? A Comprehensive Study
They reproduced RETRO, extended it, and added it to Megatron.

Consistent with other retrieval work, they find a variety of benefits from adding a retrieval mechanism to their language model. They get reduced repetition, reduced toxicity, increased factual accuracy, and often better accuracy on downstream tasks.


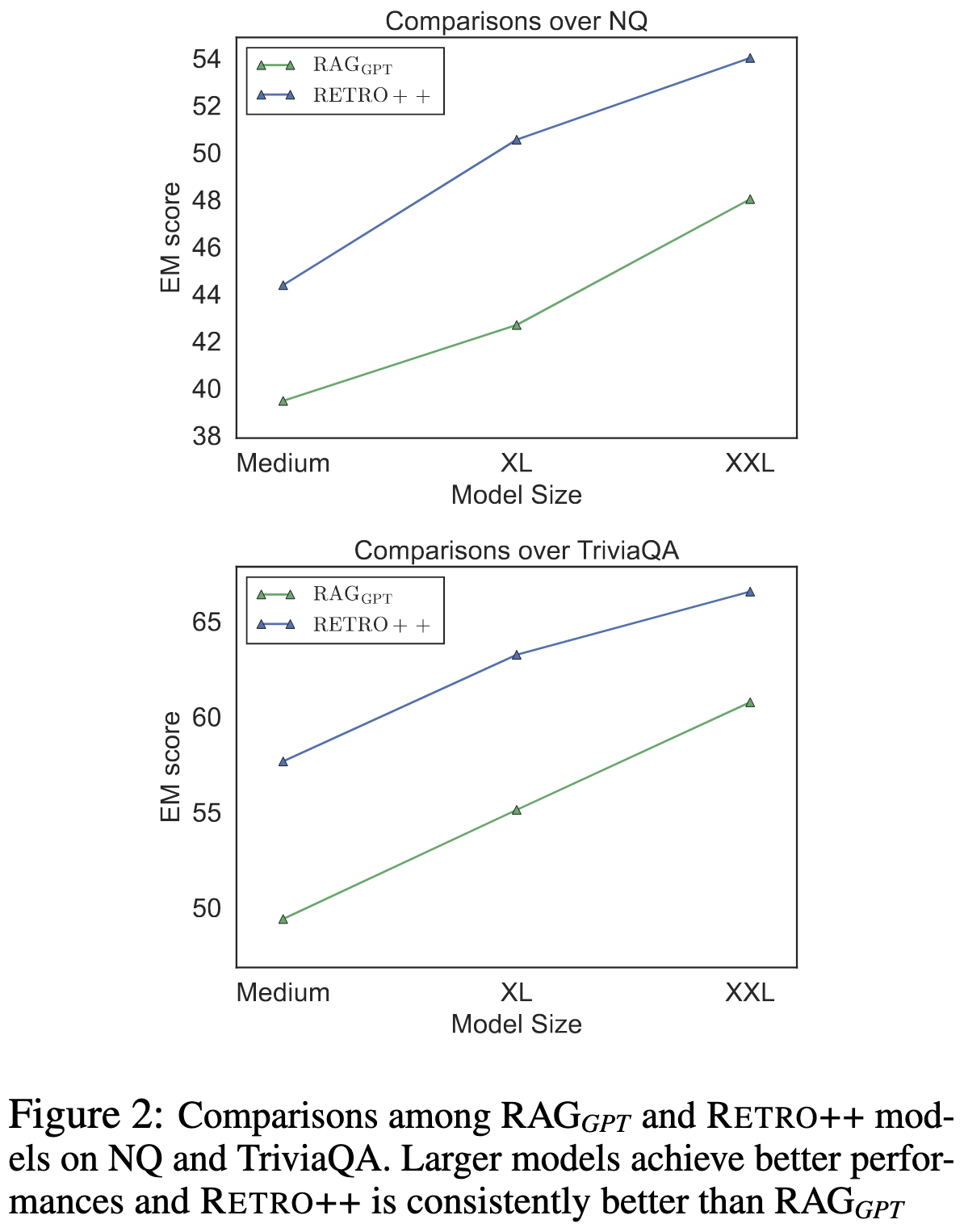
Their RETRO variant also seems to work much better than the original.

What stands out to me are the wall time numbers (and lack thereof). They just mention in the conclusion that retrieval adds “25% percentage of additional GPU hours for pretraining” even with the nearest neighbors for the training set precomputed. Since the Megatron authors are really good at making stuff run fast, the fact that even they don’t report a clear time-to-accuracy improvement might mean something.

The reported numbers might be a positive result for pretraining compute vs. quality for slow decoder-only models, but seem like a negative result for retrieval when you care about inference speed.
That said, there’s a variety of (maybe faster?) ways to incorporate retrieval, a vast literature on dataset pruning for knn methods, and plenty of other changes that might help reduce the inference cost. So retrieval augmentation could still become a standard practice.
Cerebras-GPT: Open Compute-Optimal Language Models Trained on the Cerebras Wafer-Scale Cluster
Cerebras trained some multibillion-parameter GPT models.

Their architecture and training setup are mostly similar to previous work, with a few exceptions. One that stood out is that they deliberately don’t compute attention and FFN blocks in parallel.

To get stable training they:
Use bf16 in general
Use fp32 for gradients from the attention softmax back through the QKV projections
Make sure the Adam epsilon is 1000x smaller than the moving average gradients
The thing that sticks out to me most here is that they reproduced muTransfer.4 They not only managed to transfer hparams from a smaller model to a bigger one, but even found a tighter fit to the power law scaling curve when they did so.

They also did some nice exploration of the point at which the inference cost makes training a smaller model for longer (like Pythia) worth it.

Another noteworthy aspect is that they’re getting great weak scaling on their hardware. I’m sure it was a monumental effort to get the software stack supporting this workload. Weight streaming is at least a pretty clean distributed training story, but between the kernels, the framework compatibility layers, and the auto-parallelism, it must have been a huge undertaking.

I was hoping to see sparse training results based on their recent paper, but I guess that’s left for future work.
Also, their models are freely available on Hugging Face.
Incidentally, this result is consistent with my experience but flies in the face of current AI hype—the specialized model is way better than the few-shot generalist model. Evidence against one-model-to-rule-them-all.
They don’t point this out in the paper, but floating point is the near-ideal encoding for (signed) power laws. The easy way to see this is that whenever we increase the exponent by one (doubling the scale), we halve the resolution—so a multiplicative change in the input yields a multiplicative change in the density.
The best I could find was ~50nm numbers derived from a long chain of people citing other people, with the chain terminating in one slide from some dude’s early-2000s powerpoint presentation.
The fact that the muTransfer paper:
a) promises a multiple-order-of-magnitude reduction in hparam tuning time,
b) independently reproduces, and
c) has only 23 citations
is one of the saddest commentaries on citations as a metric that I’ve ever seen.
We should be pretty confident that that one extrapolation plot in the GPT-4 tech report is a mu-transfer replication as well. A citation of the paper appears in their bibliography but I didn't see a usage of it in the text which is funny.
(OpenAI collaborated on the last Tensor Programs paper but not all of them, so maybe it counts as 80% of a replication.)