


2023-5-28 arXiv roundup: 994 papers, beating RLHF with 1000 good examples, LoRA with way less RAM, Multi-epoch scaling

This newsletter made possible by MosaicML.
We got a bunch of interesting stuff this week, thanks in part to getting the most submissions of all time.1 Relatedly, be warned that I had to go through papers faster than usual this week and it’s more likely I made mistakes.

Dynamic Masking Rate Schedules for MLM Pretraining
Here’s one of the easiest deep learning wins you’ll ever see: instead of using a fixed masking rate during BERT pretraining, start with a masking rate of 0.3 and linearly decrease it to 0.15. Can reduce time-to-accuracy on downstream tasks by up to 1.89x.

LIMA: Less Is More for Alignment
They curated an extremely high-quality set of 1000 instruction-following examples and did supervised finetuning rather than RLHF or other fancy methods. The examples are stuff like wikiHow pages, helpful stack overflow answers, and highly upvoted posts + answers on hand-selected subreddits. They also wrote a couple hundred prompts and answers themselves.
Two aspects of their example construction stuck out to me:
They add new tokens to make explicit when the “user” vs the “assistant” is talking.
They do source-specific preprocessing, like removing text about “this article” for wikiHow, or links to other answers for StackExchange.

Supervised finetuning LLama-65B using their 1000 examples yields outputs better than Alpaca 65B, but not quite as good as GPT-4 or Claude.
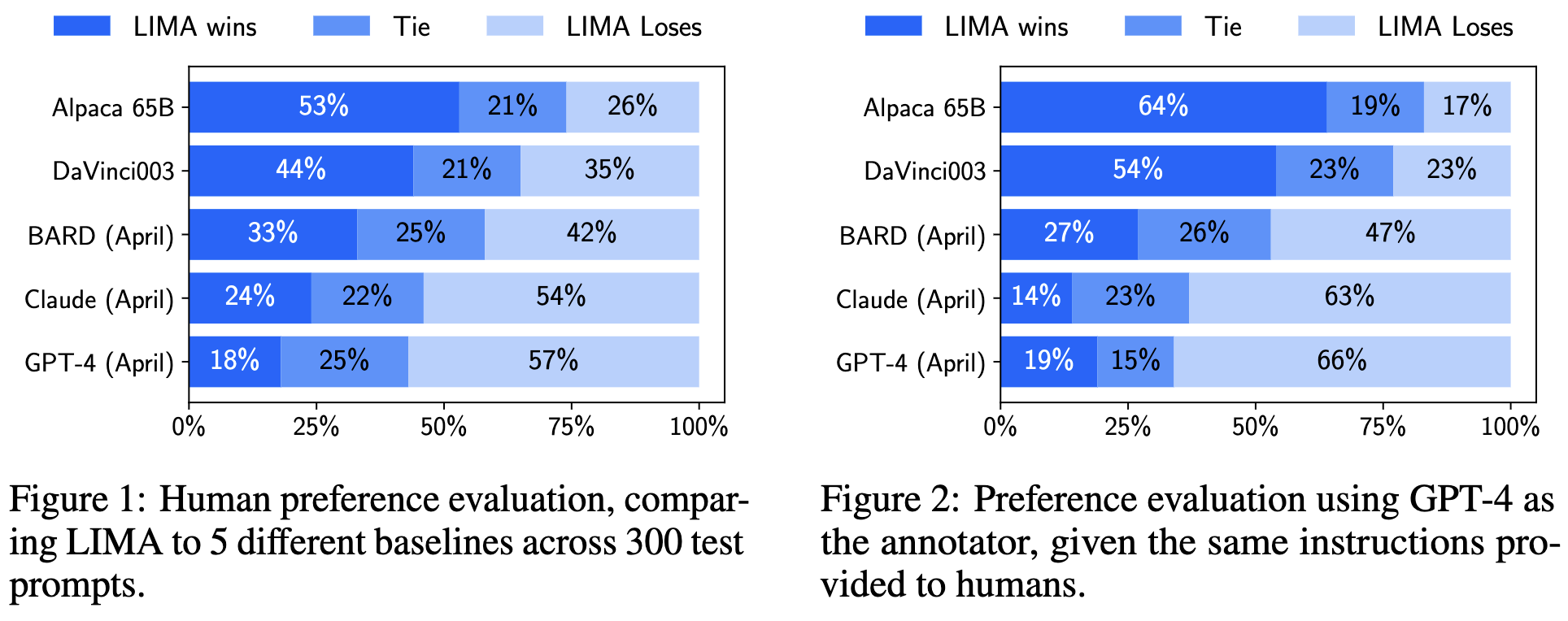
They suggest that this is evidence of their proposed “Superficial Alignment Hypothesis,” which claims that the model already has the knowledge it needs from pretraining and it just needs guidance on how to interact with users.

Further evidence of this is that scaling up the number of training samples didn’t improve generation quality for 7B models in their ablations.

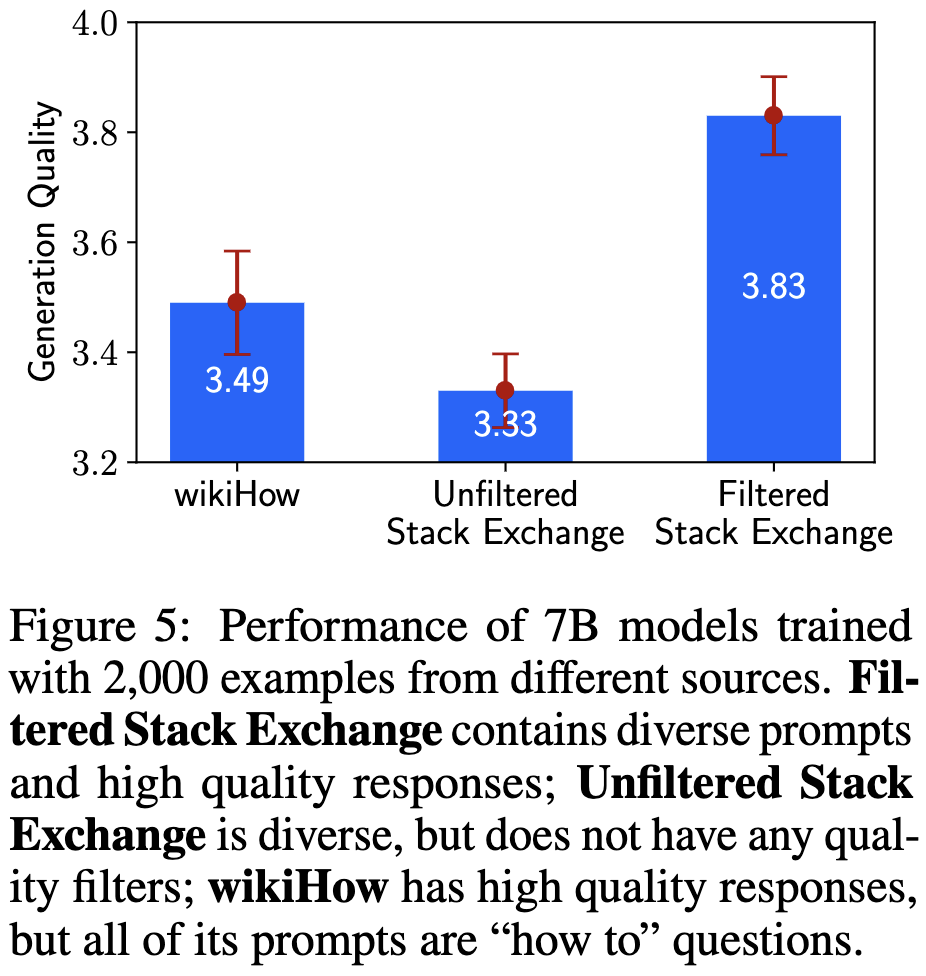
Further, you can get high variance in output quality depending on what you feed in, even with 2000 examples. See, e.g., the large gap between filtered and unfiltered StackExchange answers.
They also find that you get the model to go from single-turn instruction following to multi-turn dialog by adding just 30 examples of the latter to the 1000 initial examples.

These are pretty remarkable results, and the lack of returns to dataset scale are especially surprising. This bodes well for the economics of large language models—if you can just gather 1000 great examples instead of paying millions of dollars to human annotators, the cost of producing top-tier datasets (at least for instruction tuning) might plateau instead of growing indefinitely.
This does violate what almost always happens in statistics though, so it will be exciting to see what happens as others try to reproduce + extend these results. The Superficial Alignment Hypothesis could suggest a lot more emphasis on pretraining.
The CoT Collection: Improving Zero-shot and Few-shot Learning of Language Models via Chain-of-Thought Fine-Tuning
They released an instruction tuning dataset composed of 1.88 million chain-of-thought rationales for 1,060 prompt-dataset pairs.
Seems to be pretty high-quality according to various metrics.
To evaluate this more rigorously, they finetune FLAN-T5 on their dataset to get a model they call C2F2.
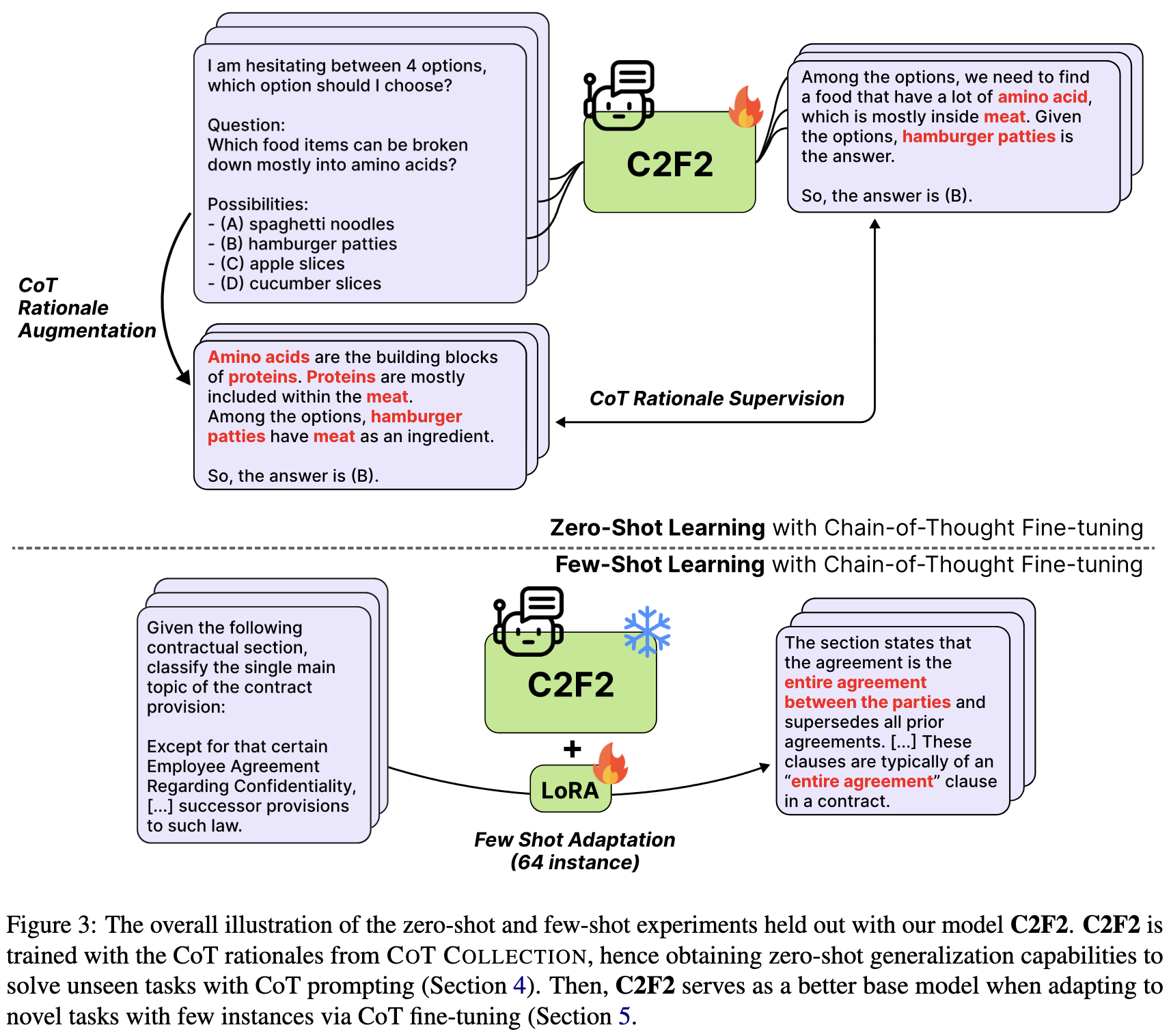
This model outperforms a variety of other T5 variants and GPT-3.

It also beats Claude and GPT-4 in some cases, despite having only 11B params.

I can’t wait to see comparisons between finetuning on this vs finetuning on the LIMA dataset. Do 1000 great examples beat 1.88 million good ones?
AlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback
They built a benchmark / eval framework for RLHF alternatives.

To make eval cheap and automated, they have LLM APIs provide feedback and rate outputs instead of humans. This seems to work pretty well.


Learning from human feedback seems to be a huge win for text models, so hopefully this will help with research on this front.
QLoRA: Efficient Finetuning of Quantized LLMs
They made LoRA take even less RAM. They do this with three changes.

First, they quantize the weights to 4 bits at rest and upcast them to 16 bits before each operation. To do this with minimal accuracy loss, they set their quantization bins based on the assumption that the weights are 0-mean Gaussians scaled down to the interval [-1, 1]. This is in contrast to the typical practice of spacing quantization bins linearly. The optimal bins use the empirical quantiles of the weights (in fact, you can solve for them exactly using dynamic programming); but imposing a distributional assumption simplifies your code a lot.

Second, they quantize the quantization scales. These scales are used to ensure weights all lie in the interval [-1, 1]. Storing low-bitwidth scales/exponents is pretty standard for block floating point formats (see, e.g., ZFP or my old time series compression work), but I actually haven’t seen deep learning people do it since Nervana in ~2014.
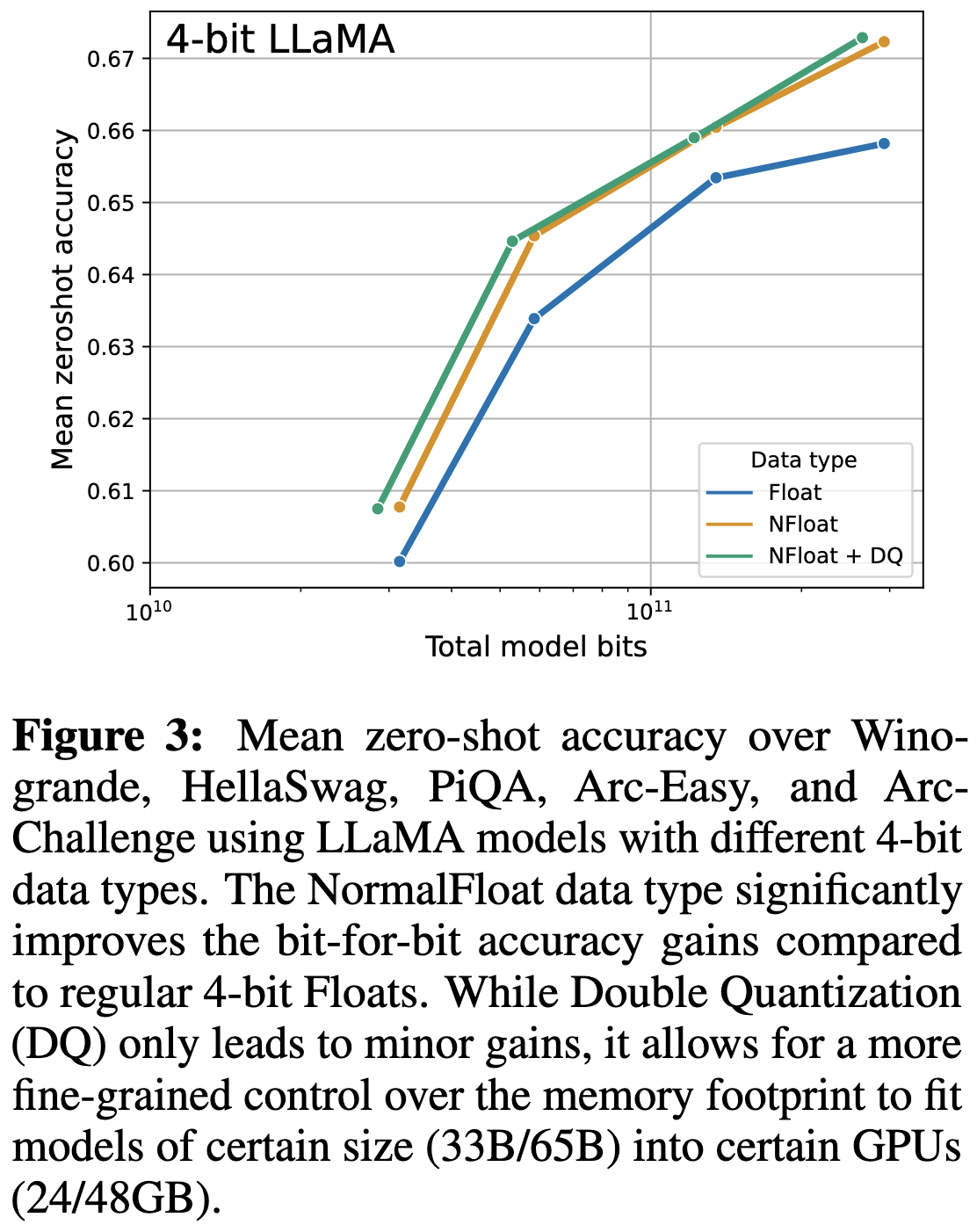
The third and most interesting aspect is paging optimizer states in and out of GPU RAM. Apparently you can get NVIDIA GPUs to transparently offload to CPU RAM the way your CPU RAM offloads to disk.
These changes together let them get the same accuracy as 16-bit finetuning with greatly reduced memory requirements.
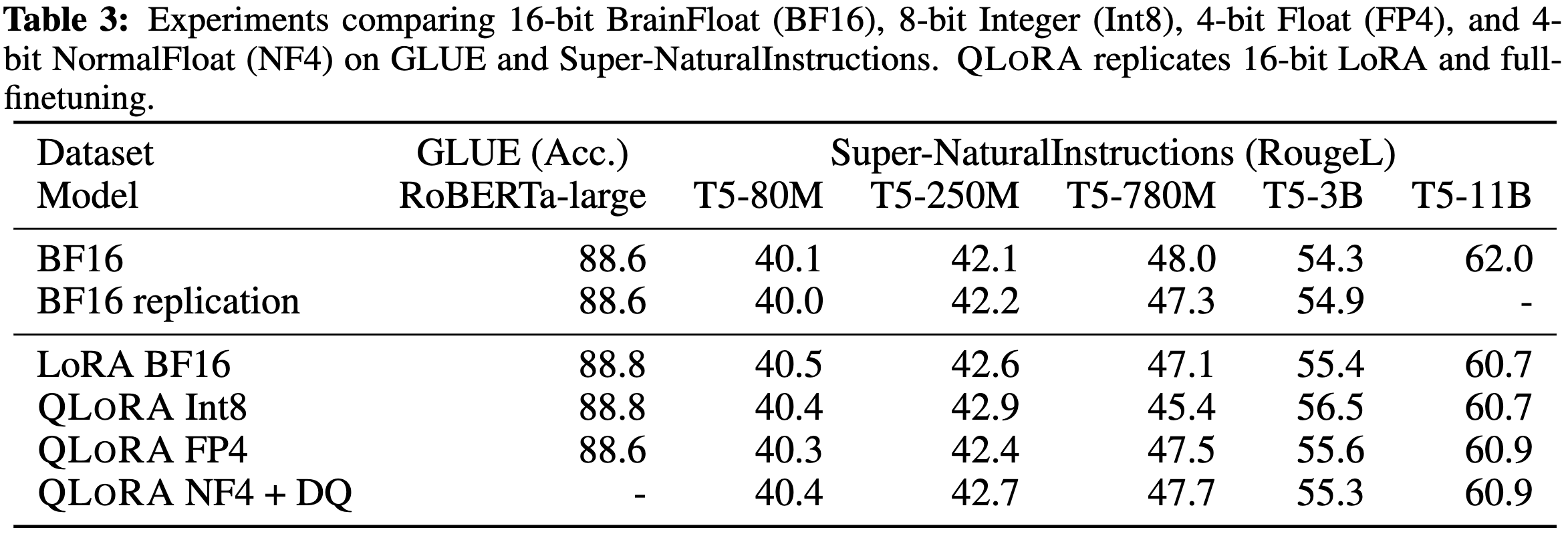

They also use this method to finetune LLaMA variants, obtaining the “Guanaco” model family. These models have great accuracy, rivaling alternatives at a given parameter count but using much less RAM thanks to the quantization.


Their largest models even outperform ChatGPT, according to human raters.

Cool work of immediate practical value.
Also convinces me we can go below 4-bit quantization if we’re willing to pay a bigger compute cost. There’s a compute vs space tradeoff in compression and 4-bit decoding with nonlinear bins is basically just a table lookup per parameter; with fancier numeric data compression schemes, we could probably go lower. E.g., if scalar quantization can do 4 bits with no accuracy loss, I’d bet that just throwing SZ at the problem could probably do 3 (and with hard error bounds).
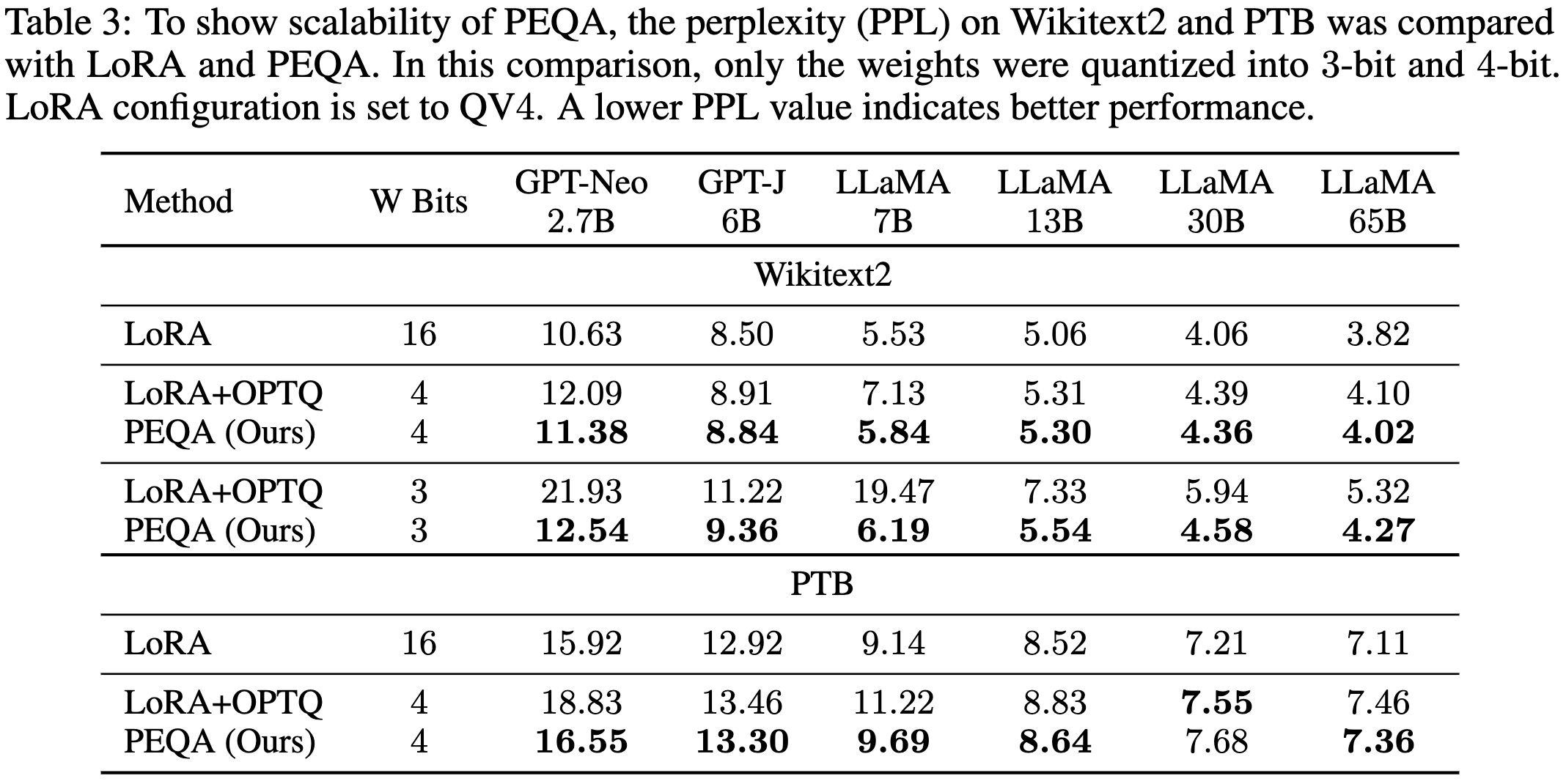
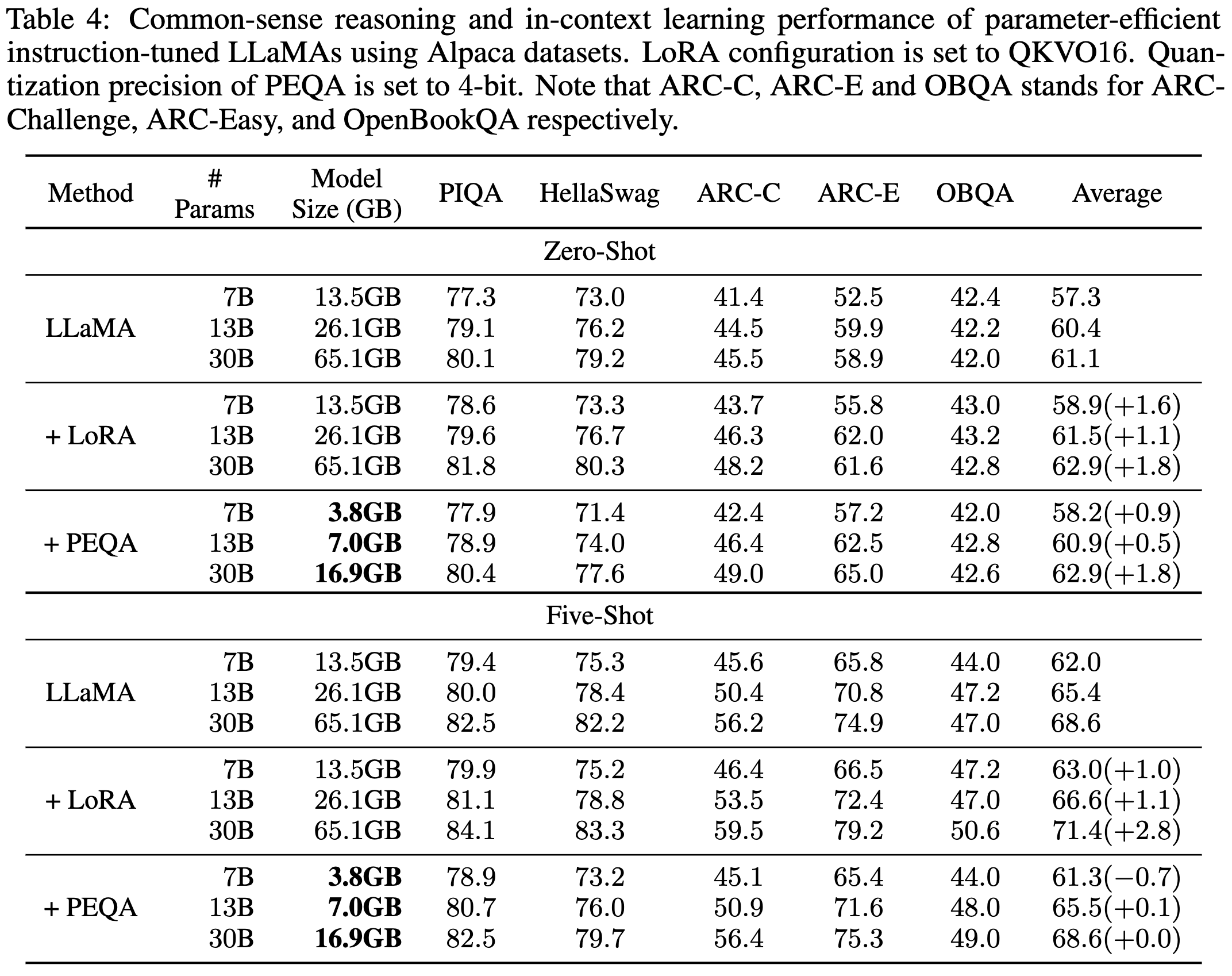
Memory-Efficient Fine-Tuning of Compressed Large Language Models via sub-4-bit Integer Quantization
They integer quantize the rows/columns of the weight matrices and then only tune the quantization scales. Seems like a pretty elegant approach if you can get away with only rank-1 updates.
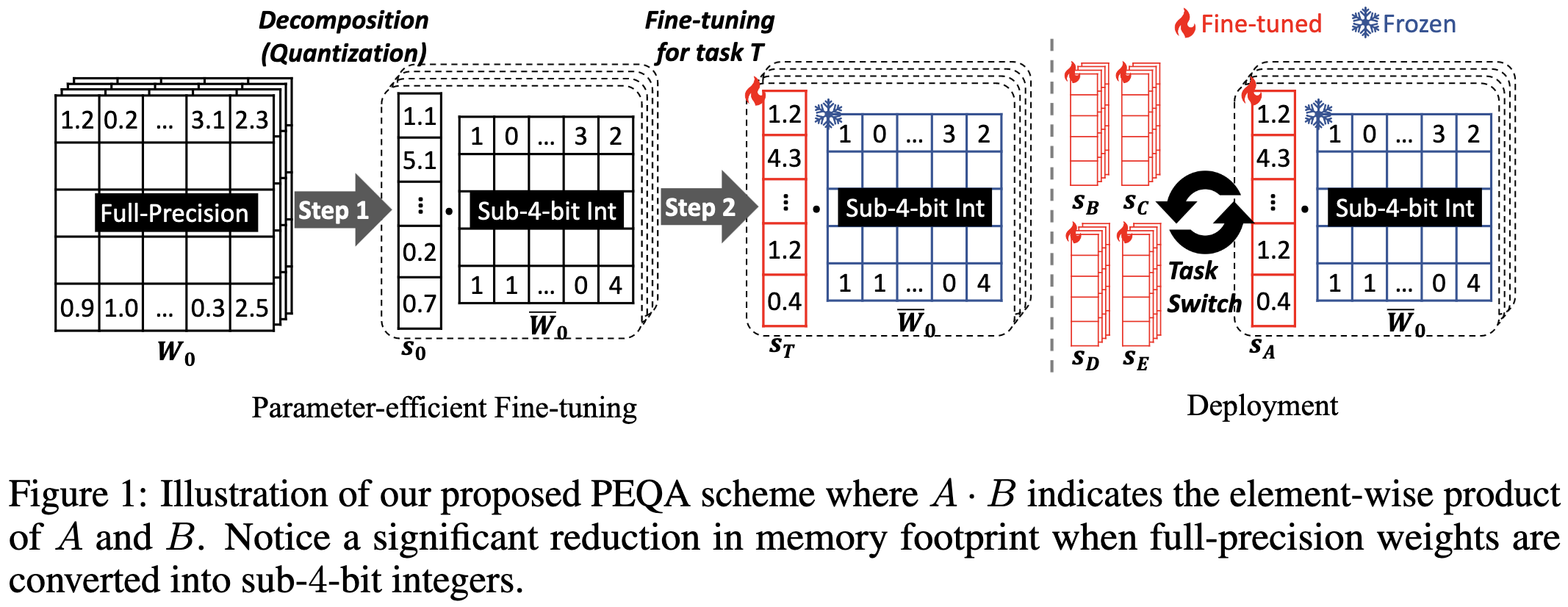
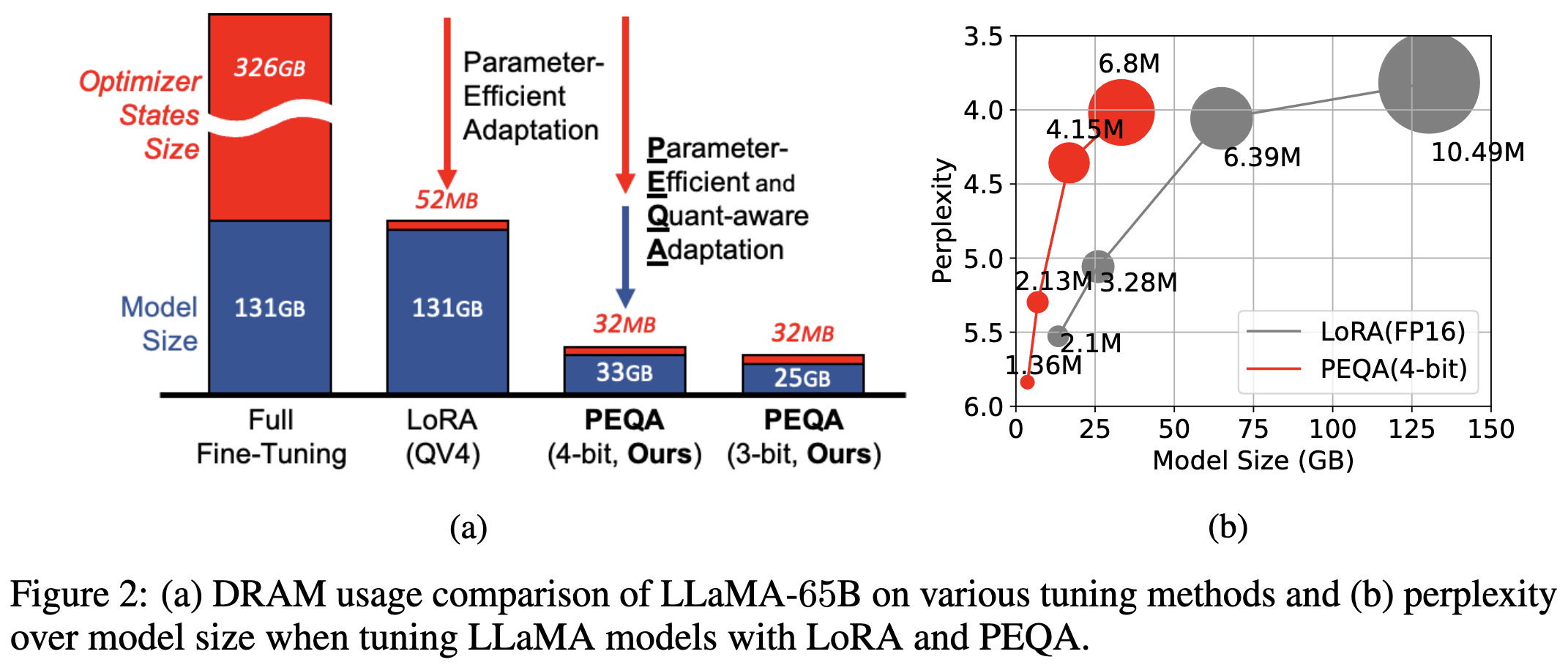
Unlike QLoRA (above), their goal isn’t to reduce RAM in exchange for some overhead. They’re trying to quantize the model to reduce both space and inference latency. Although they leave activation quantization to future work so I think (?) they don’t have wall-time speedups yet.
In terms of space vs accuracy, they do about as well as quantization-aware training and better than just applying post-training quantization to a LoRA-finetuned model.

READ: Recurrent Adaptation of Large Transformers
They do lightweight finetuning by training a neural net that takes in each layer’s input and returns a perturbation to the layer’s output.

This apparently works really well if you do it right. They have a much better {energy, memory} vs GLUE accuracy tradeoff than other methods.


They also have fairly low inference energy consumption and latency.

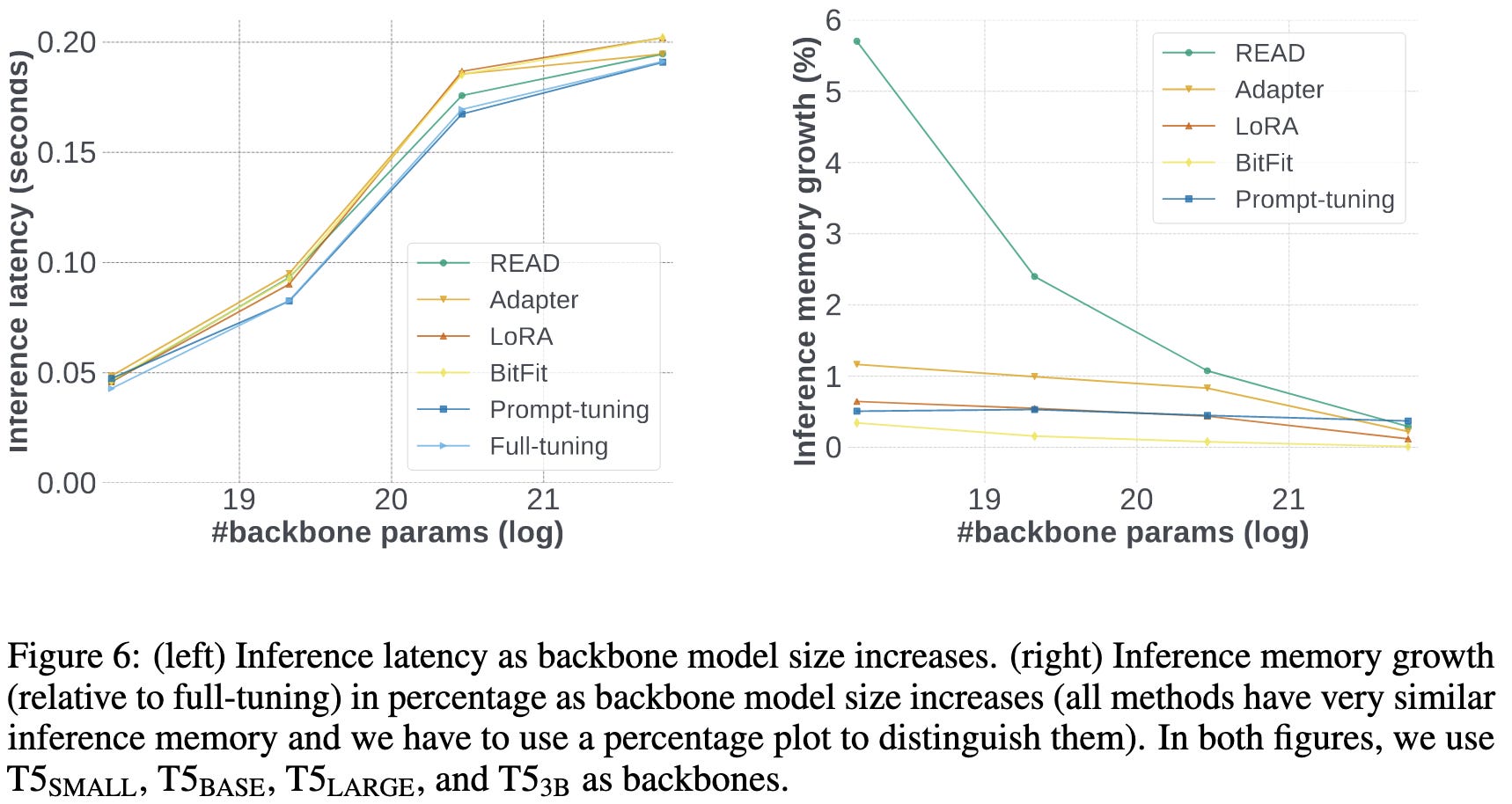
LoRA has a lot of traction, but maybe this is better?
Small Language Models Improve Giants by Rewriting Their Outputs
You can train a model to aggregate the outputs from different LLM APIs and do better than the individual APIs.

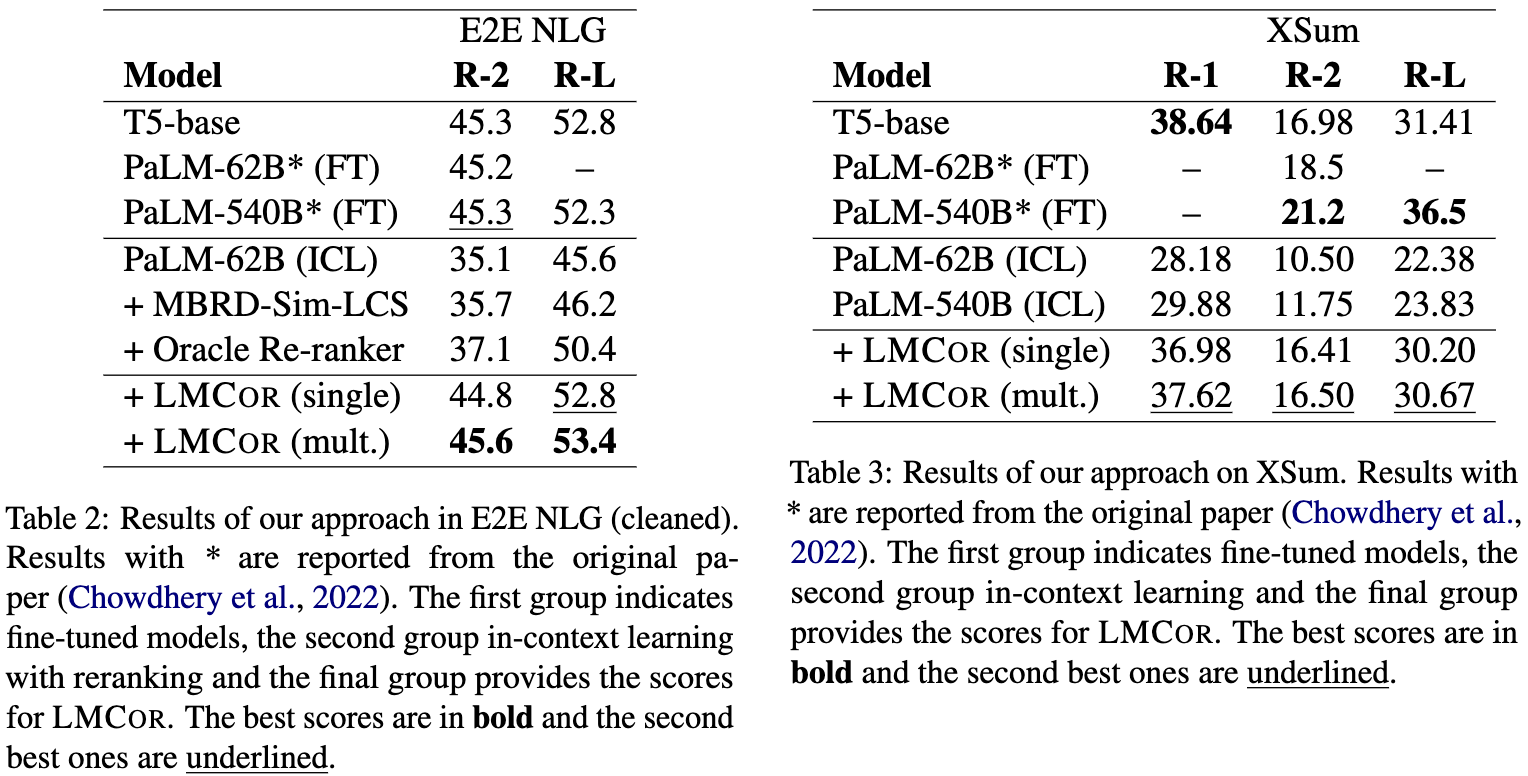
Having a corrector model of a given scale that takes in a 62B param PaLM model’s output works better than just having a fine-tuned T5 model of the corrector model’s scale. So finetuning crushes the generalist API on its own, but generalist API + corrector can get even higher accuracy (though with way more expensive inference).
A Survey of Safety and Trustworthiness of Large Language Models through the Lens of Verification and Validation
I’m always glad to see work on bringing decades of know-how from other fields to AI safety. And this is a great overview of different problems and approaches to solving them.
The paper is pretty long and dense, but they have a ton of fairly self-explanatory diagrams that give you the gist of what’s going on.


I especially appreciate their overview of formal verification methods for neural nets.

When are ensembles really effective?
Consider the disagreement-error ratio, which is the ratio of how often two classifiers in your ensemble disagree to how often they individually are wrong.

If this ratio is greater than 1, you’ll probably benefit from ensembling.

In fact, there’s a linear relationship between the disagreement-error ratio and the Ensemble Improvement Rate, which is basically the normalized error rate reduction from ensembling.

Nice to see such clean, widely-applicable theory—especially with empirical validation.
ToolkenGPT: Augmenting Frozen Language Models with Massive Tools via Tool Embeddings
They let a mostly-frozen LLM call external “tools” like mathematical functions by adding a learned token embedding for each tool. When the model generates a tool’s token, they stop and query it for arguments to the tool with a few in-context examples to help the model use it properly.
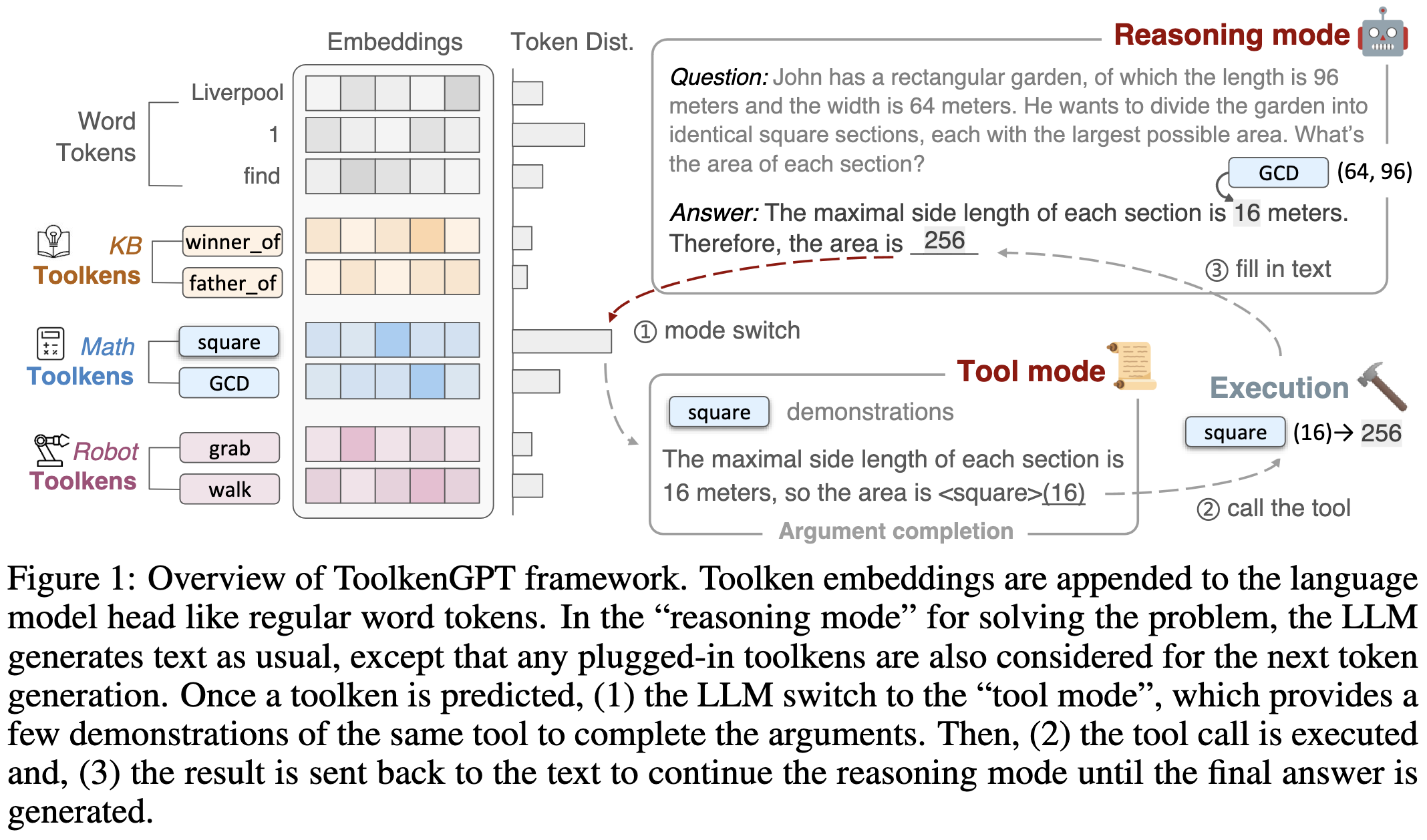

Adding this tool use helps a lot on certain tasks, like solving single- or multi-step math problems and answering questions scraped from Wikipedia. In the former case, the model can use math functions as tools; in the latter, it can query a knowledge base.


Tool use seems to be beneficial in narrow circumstances based on the evals I’ve seen in papers so far, but intuitively, it seems like it should be helpful in general—especially querying a knowledge base.
A Pretrainer's Guide to Training Data: Measuring the Effects of Data Age, Domain Coverage, Quality, & Toxicity
They pretrained a ton of models to evaluate the effects of different data pipeline choices.

They already have really good summaries of their findings, so I’m just going to highlight those instead of re-summarizing myself:




They also have a bunch of informative figures. I really like this breakdown of different properties for different document types. E.g., books are full of profanity, toxicity, and sexually explicit content, but are also some of the highest-quality data.
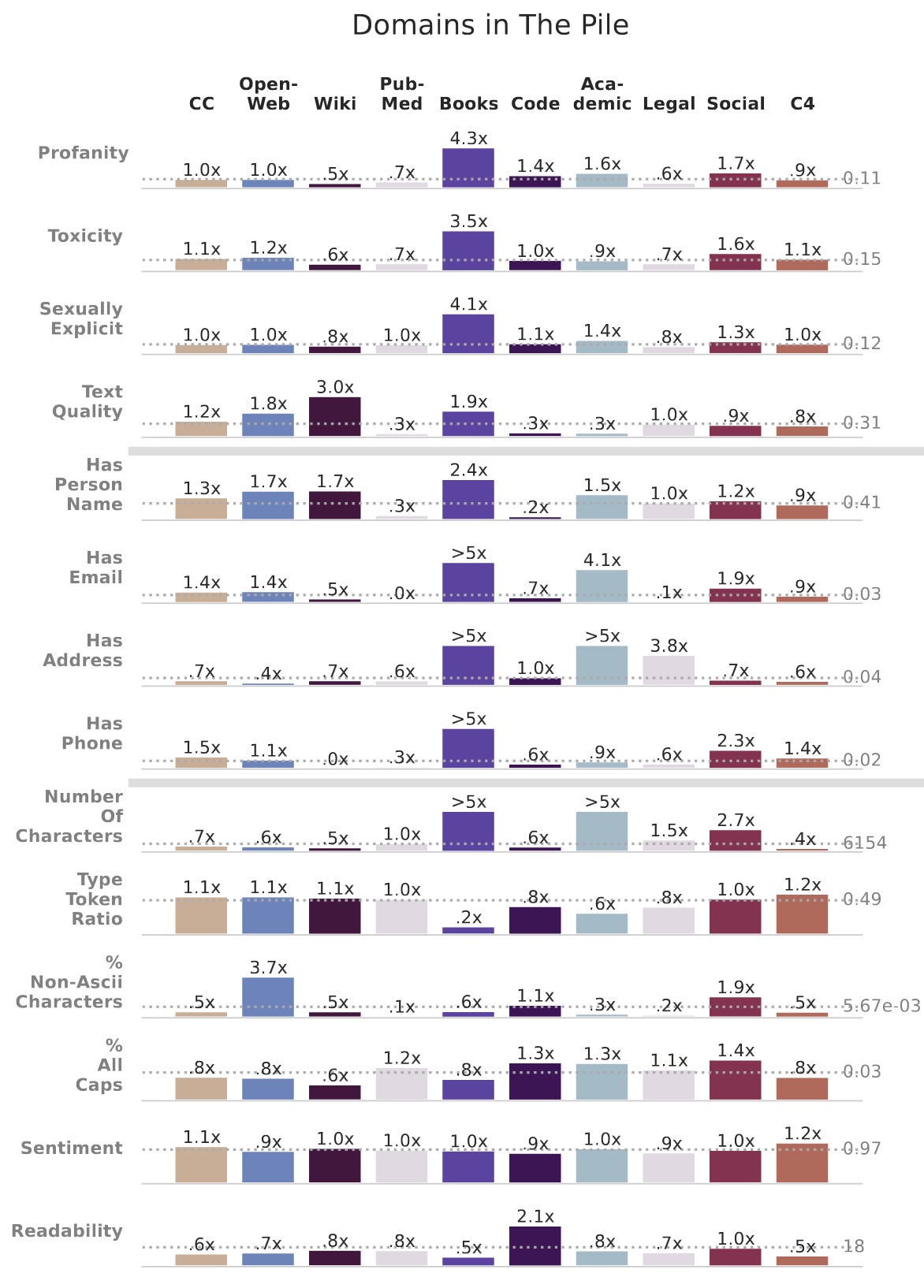
Perhaps for this reason, toxicity filtering can make the model do worse on downstream tasks.

There’s also smooth degradation from having your training and eval data generated/scraped during different years.

Definitely worth reading in detail if you care about pretraining text models.
To Repeat or Not To Repeat: Insights from Scaling LLM under Token-Crisis
What happens when you do multi-epoch pretraining of LLMs, instead of just making a single pass through the data?
With too much repetition, you get significant quality loss.

This quality loss seems to be worse for models with more parameters,

but not clearly worse for models with more FLOPs.
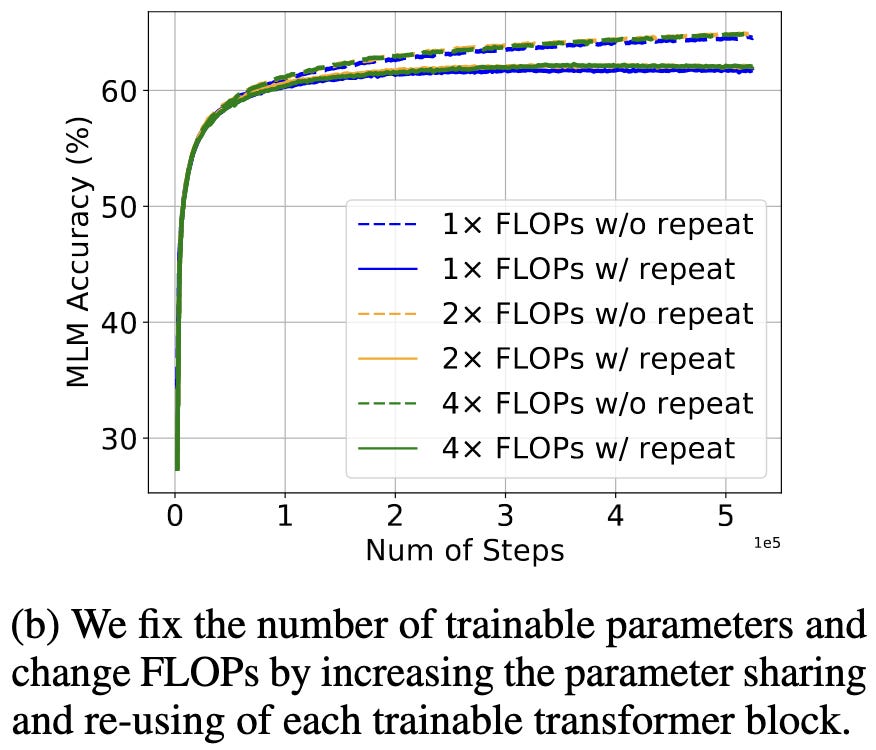
This quality loss for large models can be so bad that you’re better off using a smaller model after a certain amount of repetition (see the blue and orange curves crossing).
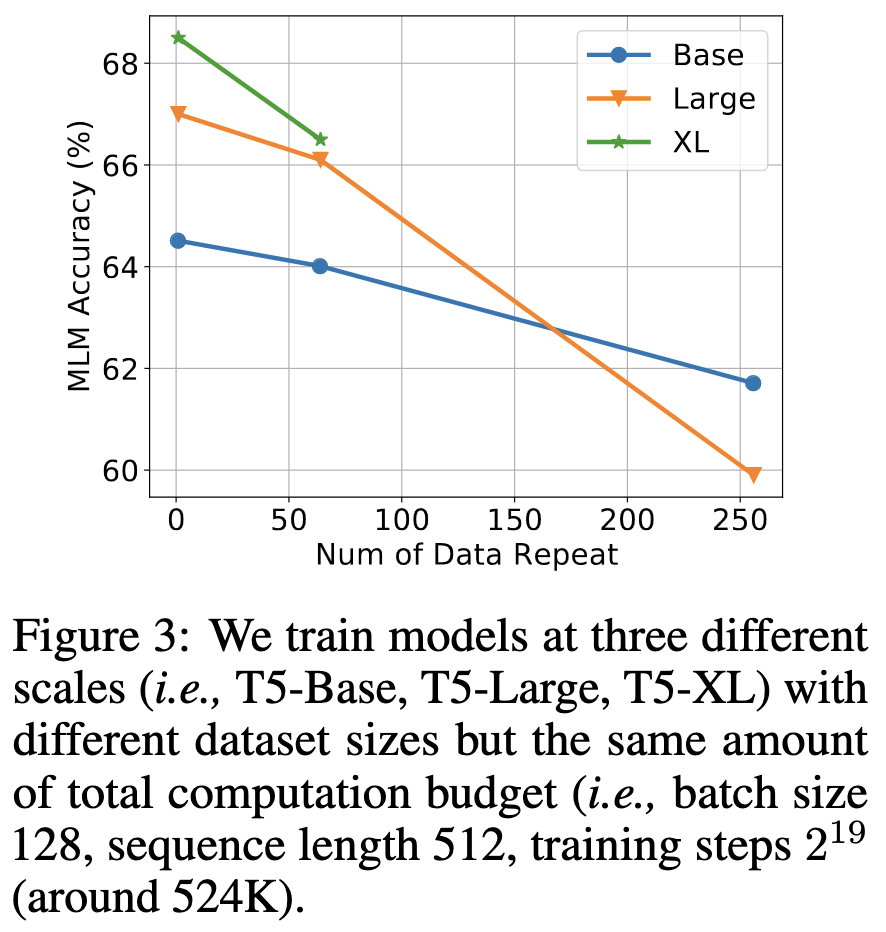
Using regularization techniques can partially mitigate the quality loss. Even if some technique doesn’t help in the single-epoch regime, it might help in the data-limited regime (see 2nd vs 4th rows).

Regularization seems to be especially important for larger models, consistent with what you’d expect from a classical ML perspective.

Because param count seems to determine the overfitting more than model FLOPs, they find that you can often tune hparams using parameter-matched mixture-of-expert models, which use way less compute than dense models.

A bunch of thorough experiments exploring a super important question.
Scaling Data-Constrained Language Models
They study how to scale up language model training when you only have so many unique tokens to train on. They find that you get diminishing returns from multi-epoch training, and eventually outright plateauing.

They quantify this by generalizing the Chinchilla scaling formula to incorporate diminishing returns from multiple epochs.

Concretely, they formulate an “equivalent” dataset size that has exponentially diminishing returns with the number of repetitions. R* is a learned time constant here.

This modified formula fits their results pretty well.

They also test a few strategies for pushing past single-epoch training with minimal accuracy loss. Just appending a bunch of Python code to your natural language dataset works pretty well, buying you roughly 2x as many epochs before severe accuracy loss.
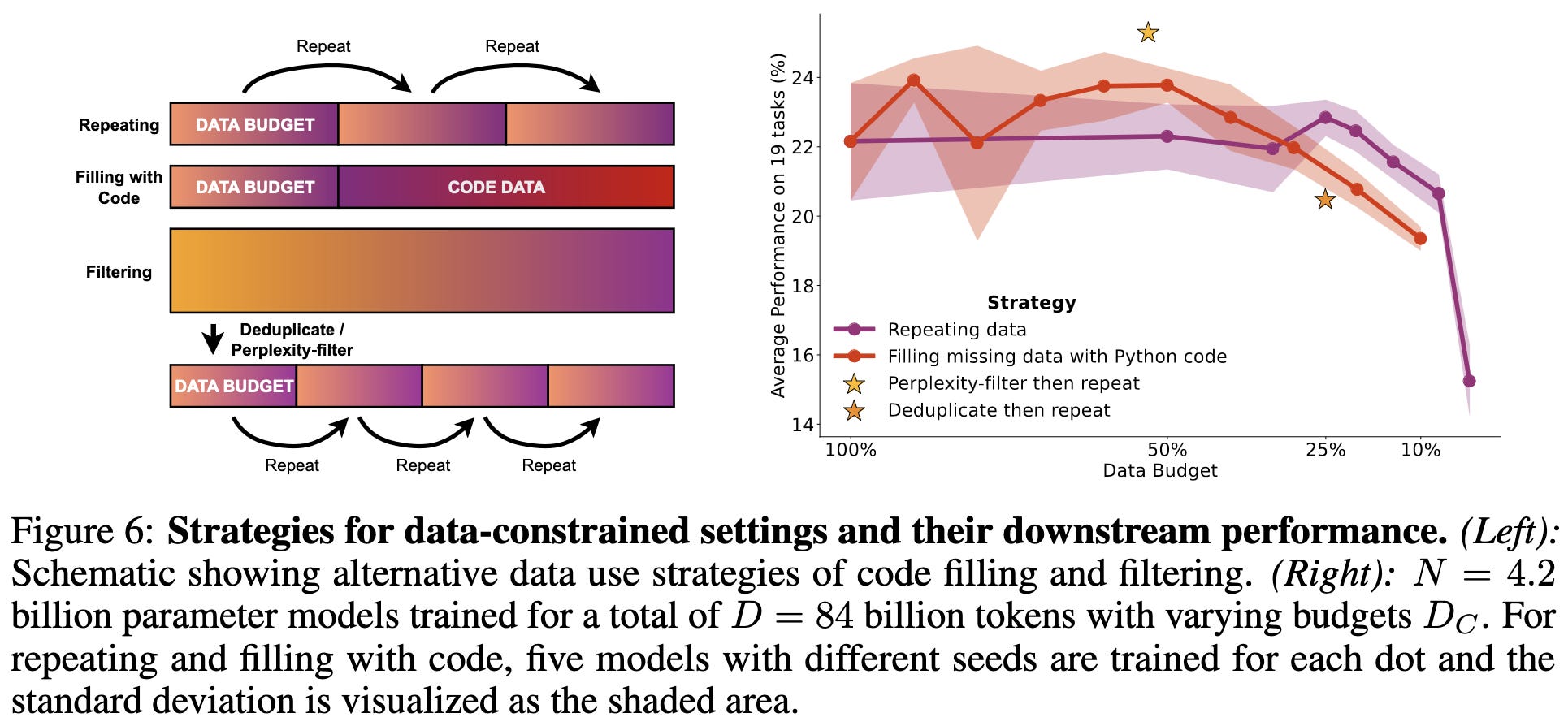
If you deduplicate your dataset up front, you don’t get any more resilience to multiple epochs, and your test loss is lower.
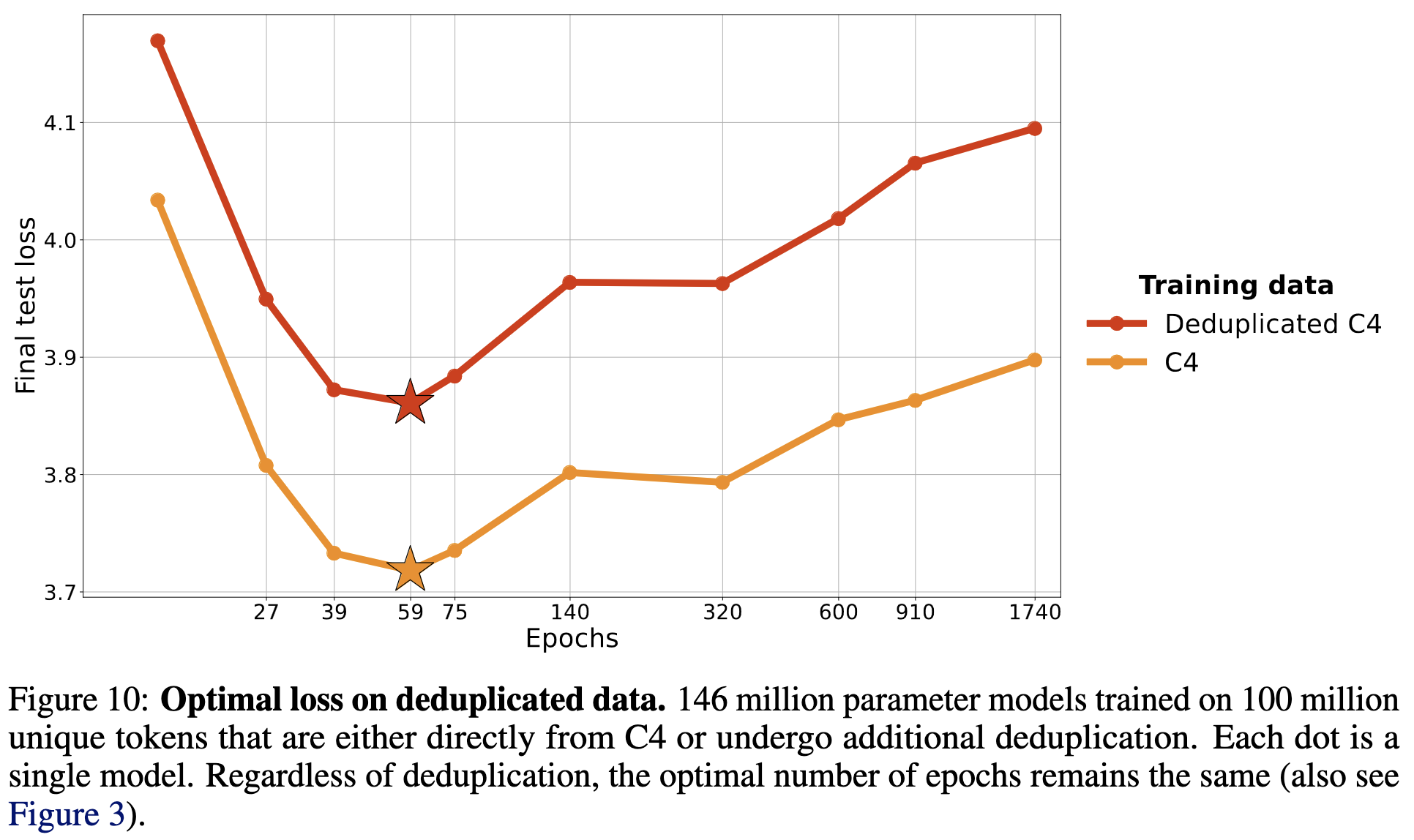
Overall, they find that you can train ~4 epochs with little decrease in marginal returns, and up to 8 if you pad your dataset with code.
Getting ViT in Shape: Scaling Laws for Compute-Optimal Model Design
Remember when EfficientNet came out and showed that jointly scaling up your image classifier’s width, depth, and resolution matters a lot? And then the OpenAI scaling paper came out and everyone concluded that “model shape” doesn’t matter?
Well, turns out “model shape” matters a lot, at least for vision transformers.
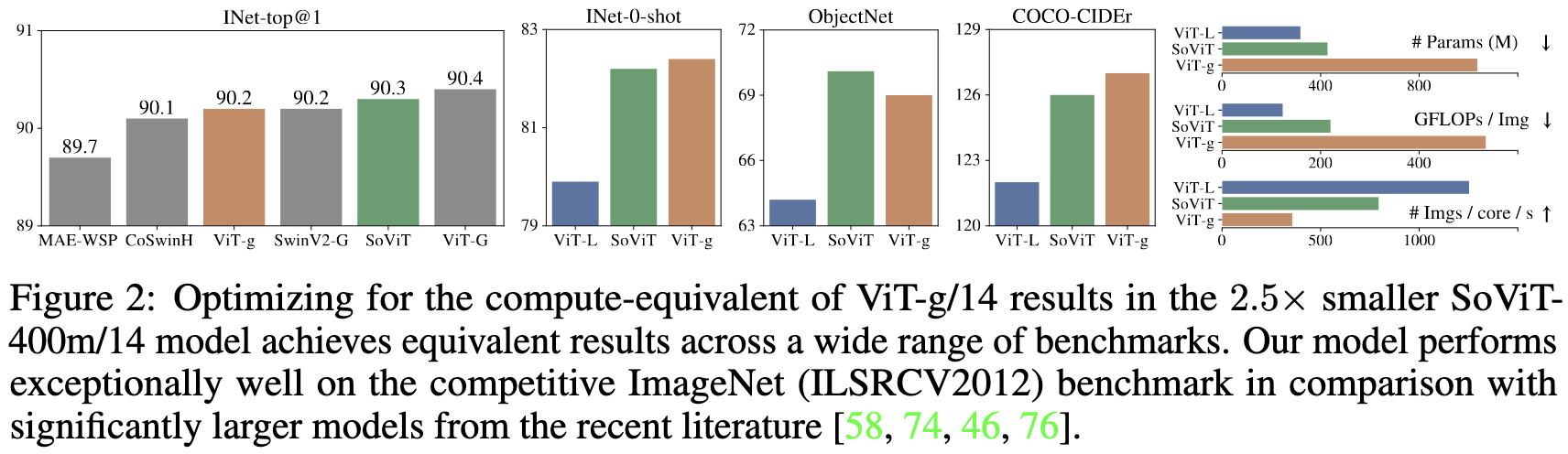
By constructing a more complex expression that reduces to power laws when holding various quantities constant, they can fit their measured model shape and task accuracy variables really well. To fit these curves, they grid search hparams on a tiny model first, and then run experiments to find the scaling constants by sweeping one variable (e.g., MLP width) at a time.
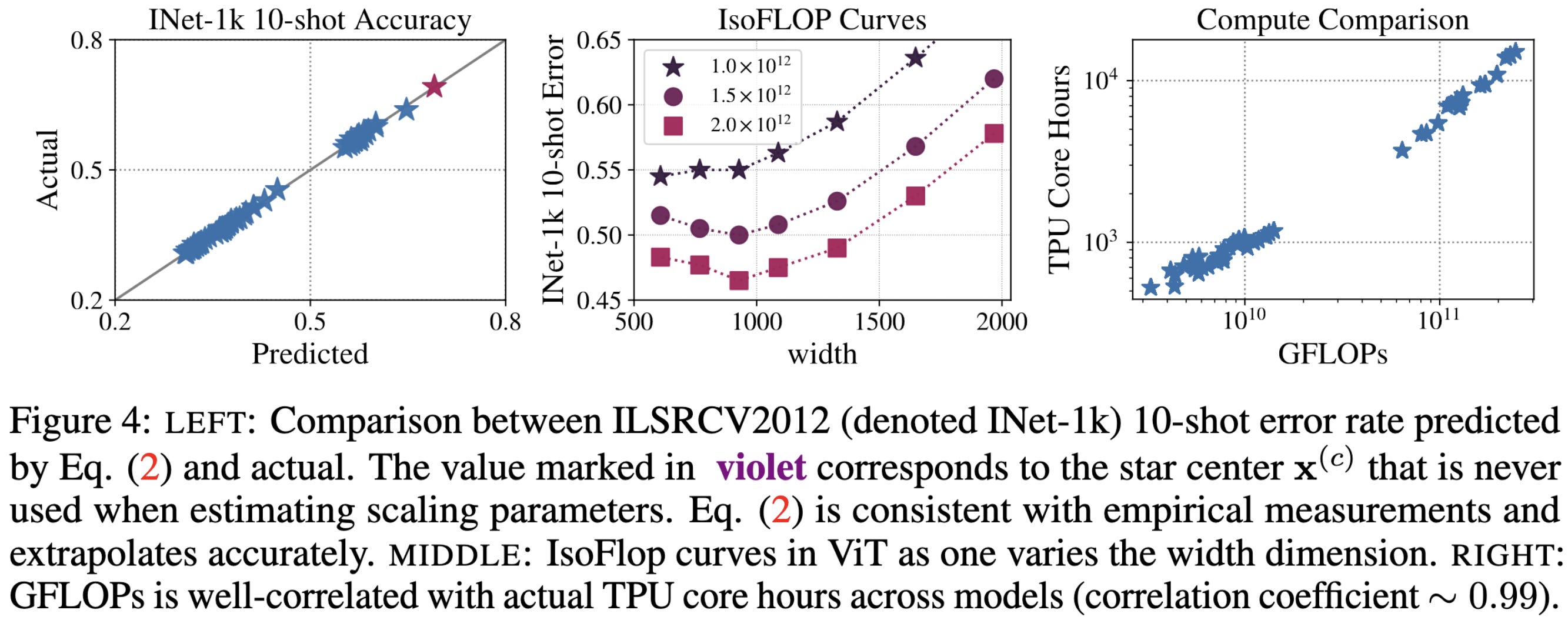
The ideal model shape varies across different tasks, and even across different numbers of finetuning examples though.


Seems like a big empirical win that might also generalize to other tasks and models.
Unified Embedding: Battle-Tested Feature Representations for Web-Scale ML Systems
Apparently doing feature hashing into a single shared table across all your categorical features works great, at least if you hash each feature to multiple buckets.

By “works great,” I mean improves the space vs recommender system AUC tradeoff.
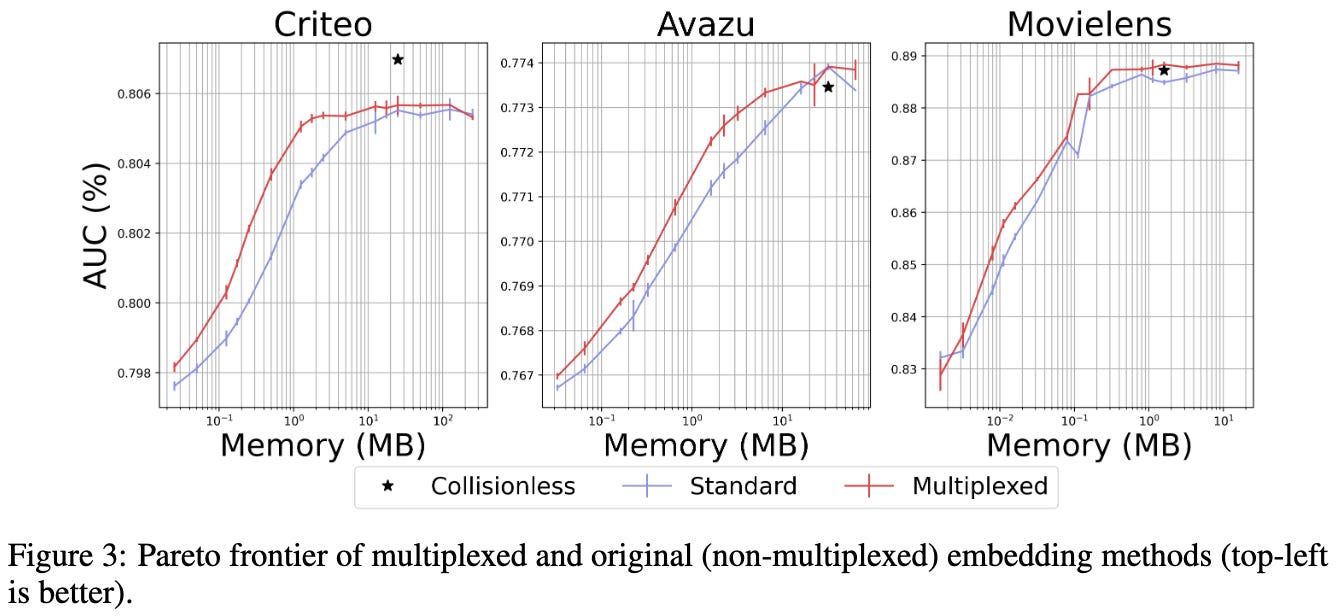
This holds not just for public datasets, but also for some internal workloads at Google.

Training Diffusion Models with Reinforcement Learning
What if you want to generate images optimized for something other than log-likelihood, like perceptual quality? Or even a measure like “compressibility” that’s not differentiable?

They propose to use RL to train diffusion models to maximize these other objectives. You just have to have a way of telling the model its reward for a given output.
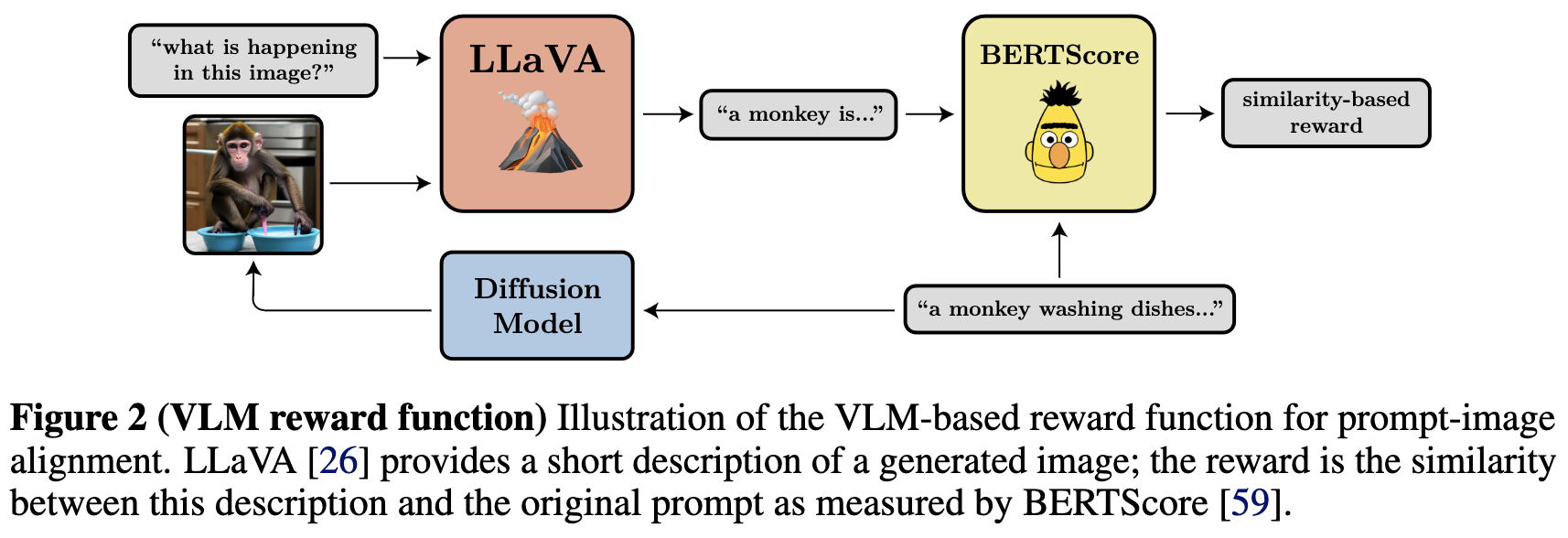
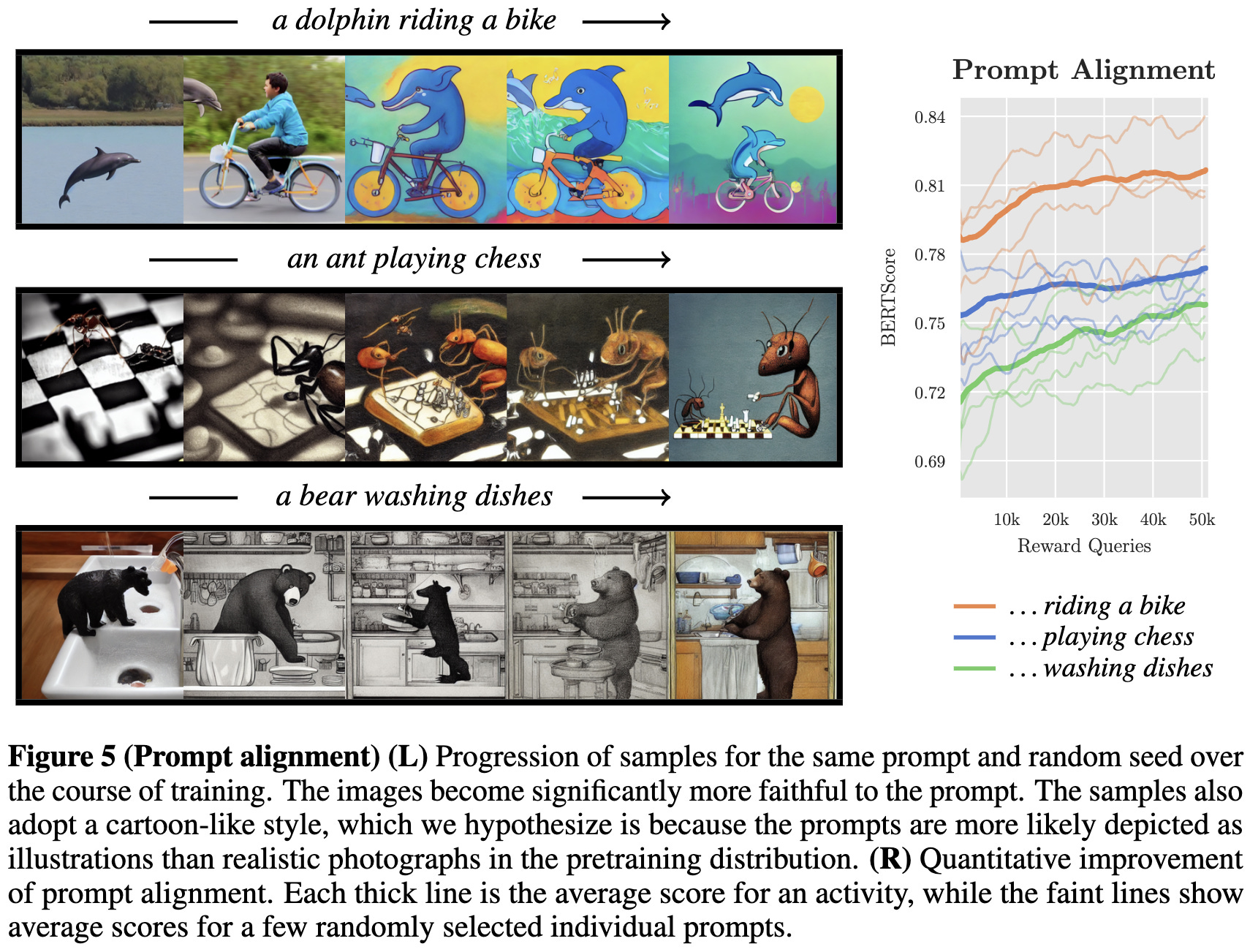
Seems to work pretty well.

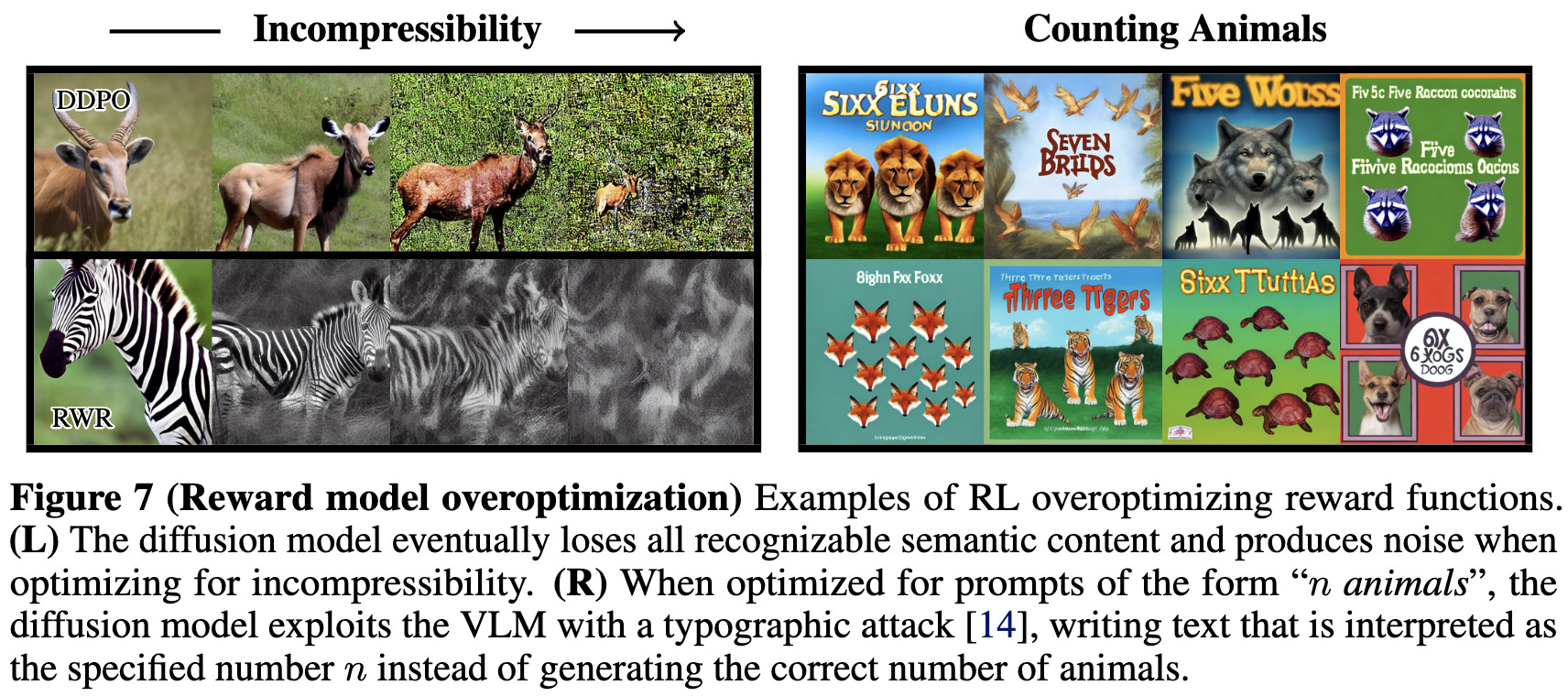
Though it does over-optimize occasionally.
Parallel Sampling of Diffusion Models
They break the serial dependencies across diffusion steps through Picard iteration, estimating the diffused image at each time step based on the estimated images at earlier time steps. This is more total operations but serial across iterations rather than across diffusion steps.
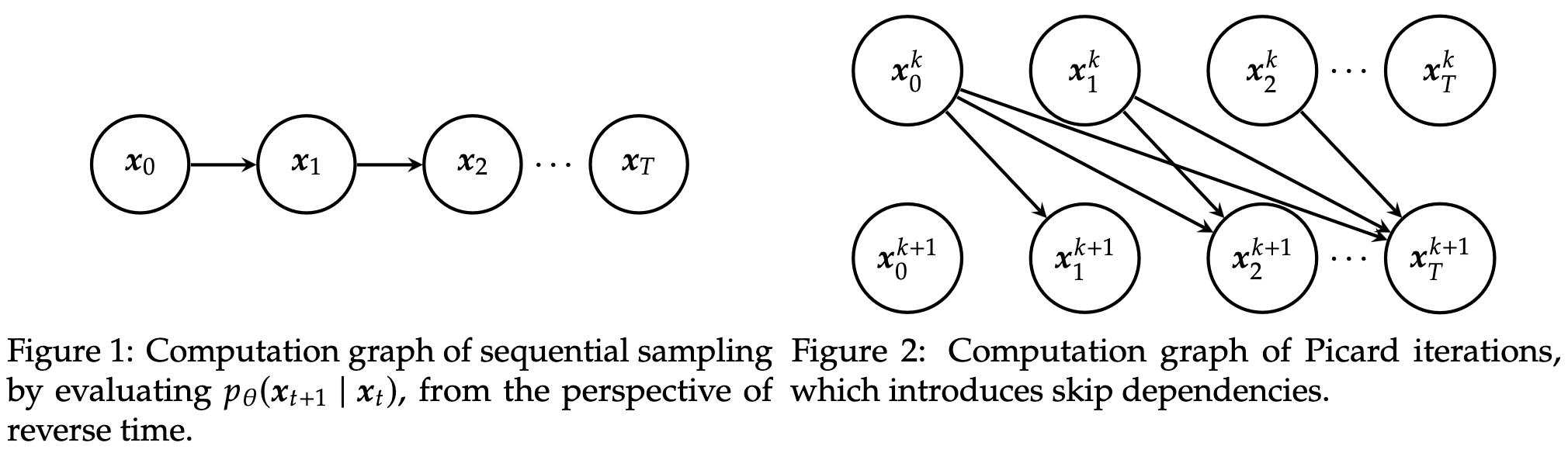
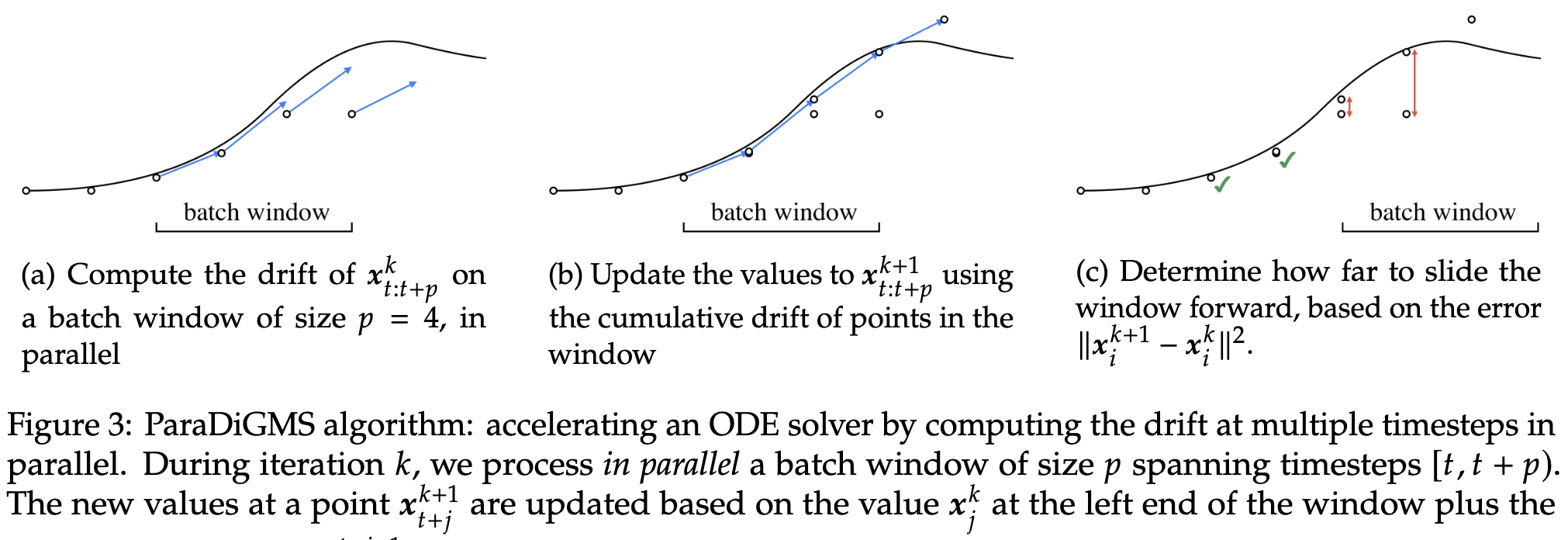
Still produces high-quality images and can speed up sampling up to 3x when using eight GPUs instead of one.


Enabling Large Language Models to Generate Text with Citations
They propose a benchmark for evaluating how well LLMs can generate citations supporting the claims in their output.

The benchmark uses three existing datasets that feature a wide variety of questions with factual answers.

What’s impressive here is that they came up with a decent way to automate the evaluation of citation correctness,

as well as citation quality.

Their citation evaluation method correlates well with human ratings of citation quality.
Seems really useful insofar as having to cite high-quality sources should be a good way to combat hallucinations.
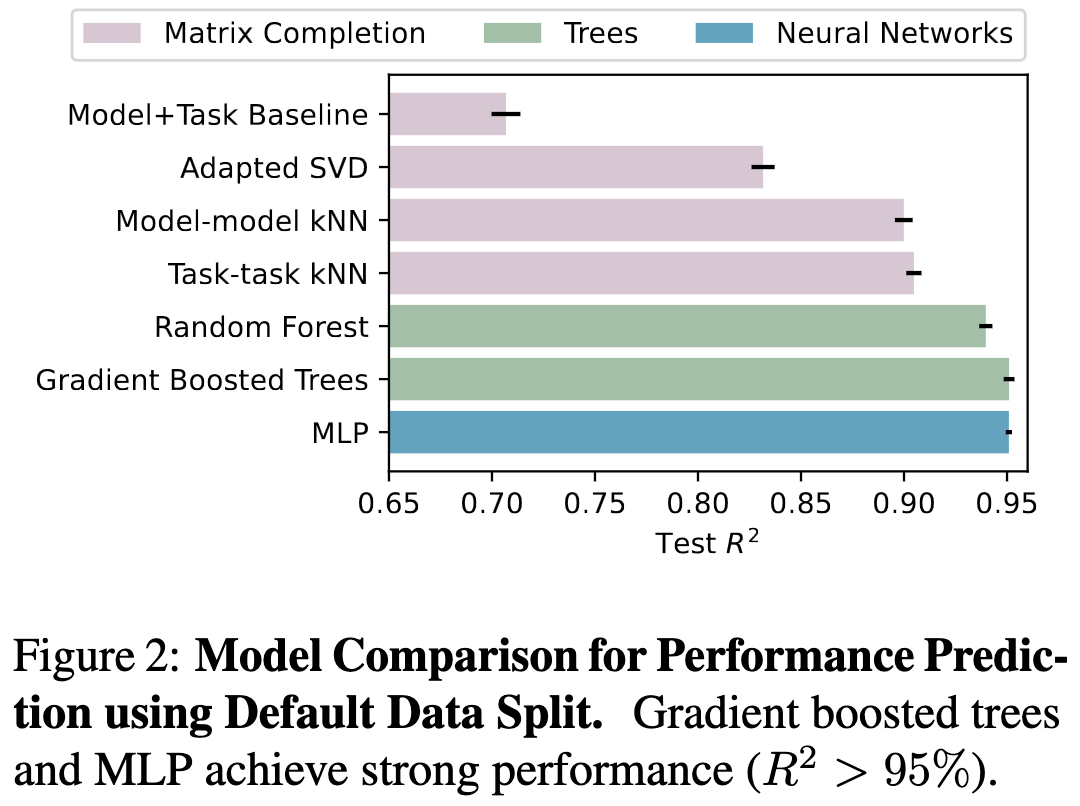
How Predictable Are Large Language Model Capabilities? A Case Study on BIG-bench
Performance on various tasks can be predicted pretty well based on performance on other tasks, especially if you condition on features like the model’s parameter count and how many ICL examples it gets to see.

As with many machine learning problems, gradient boosted trees, random forests, and neural nets are the best estimators for predicting held-out task performance.
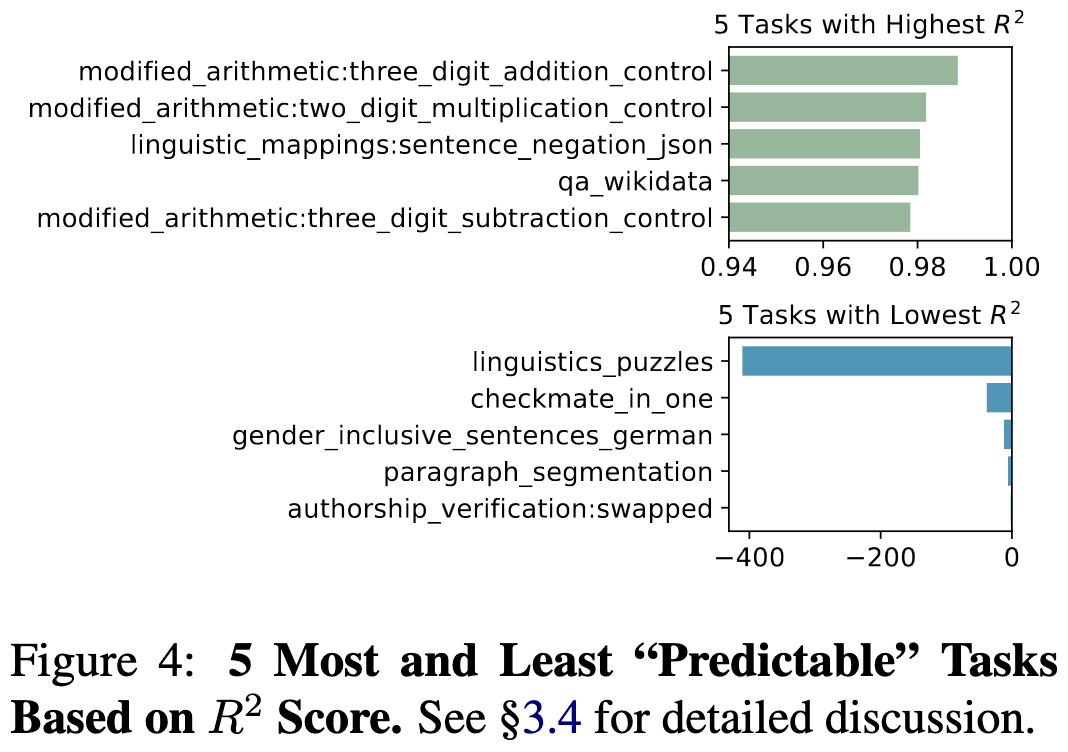
Tasks vary in how predictable they are. Some arithmetic, negation, and question answering tasks are the most predictable. Linguistics puzzles and checkmate-in-one are by far the least predictable.
You can use task subsets of different sizes as a noisy (but much faster) replacement for evaluating on all of BIG-bench. You can find a good subset by brute force trying a lot of them, using a greedy search, and more. A lot of methods work better than using the predefined BIG-bench Lite and BIG-bench Hard subsets.

Makes me think that, as the number of NLP benchmarks balloons, we’re going to have to start thinking about marginal information gain rather than just brute force evaluating everything ever.
Also interesting from the perspective of quantifying emergent capabilities, though I’m not sure what the lesson is on that front.
Adversarial Demonstration Attacks on Large Language Models
They figured out how to adversarially perturb in-context examples to make text models output incorrect answers. The limitation here is that, unlike with images, perturbed text is usually noticeable since it has different characters. Maybe you could generalize this to paraphrasing or only using unicode look-alikes?
Sharpness-Aware Minimization Leads to Low-Rank Features
The number of principal components it takes to explain 99% of the variance in activations at various points in the network decreases when you use SAM. This holds for small ResNets,
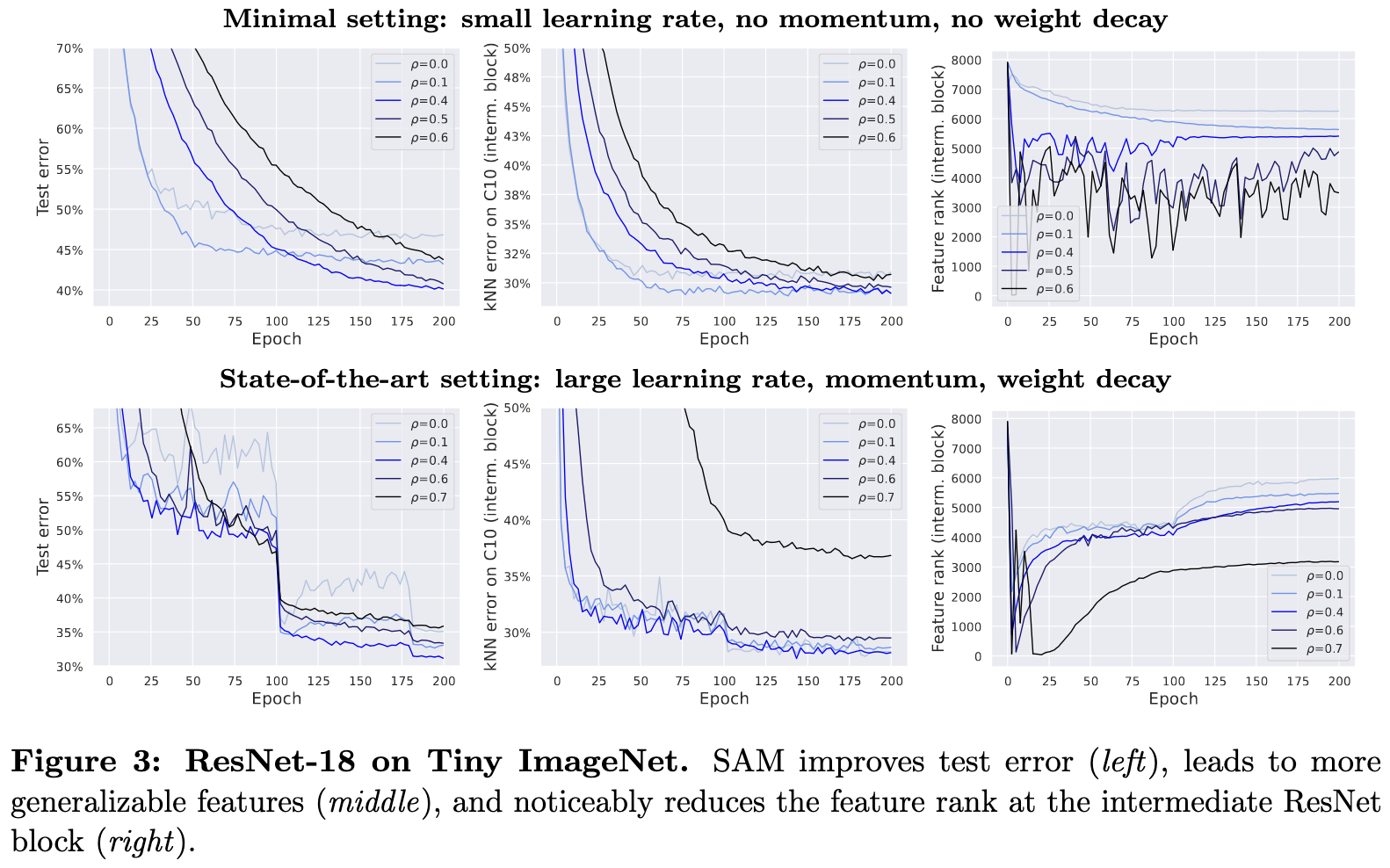
ViTs and MLP-Mixers,

and CLIP-like models. But, at least in this last case, it’s not that less rank is better. Instead, the most accurate models have neither the highest nor lowest ranks.

It doesn’t seem to be the case that low-rank features per se are causal though. Restricting rank directly doesn’t help.

SPRING: GPT-4 Out-performs RL Algorithms by Studying Papers and Reasoning
They used GPT-4 instead of reinforcement learning to play a crafting game. The approach has two parts:
Extracting a description of how the game works from the LaTeX source code of a paper that explains it.
Iteratively having GPT-4 take in a text description of the game state and then output text indicating what action to take.

To condense the explanatory paper into a suitable context, they use a three-step pipeline engineered for this exact purpose.

Given the game description, they play the game by iteratively:
Having a model map the last two frames to a textual description of the game state.
Feeding this description + the extracted game description into GPT-4, prompting it with a series of questions to guide it towards choosing a good action.
Parsing and executing the chosen action in the game.

These are the questions they ask to guide it towards choosing a good action:

Their method apparently beats all the existing baselines on this game except humans.

Interestingly, using GPT-4 instead of GPT-3.5 makes a big difference. This suggests that this LLM-as-subroutine approach could keep improving as LLMs get better. They also found that using their handcrafted pipeline of questions was important, as was letting the model read the paper.

GPT-4 was also much better than GPT-3 (or Claude or Bard) at extracting a textual description of the game. Although this could be an artifact of the method being designed around GPT-4’s quirks. It could even be the case that the above GPT-4 vs GPT-3.5 discrepancy is more a result of GPT-3.5 just being a different model than a worse one.
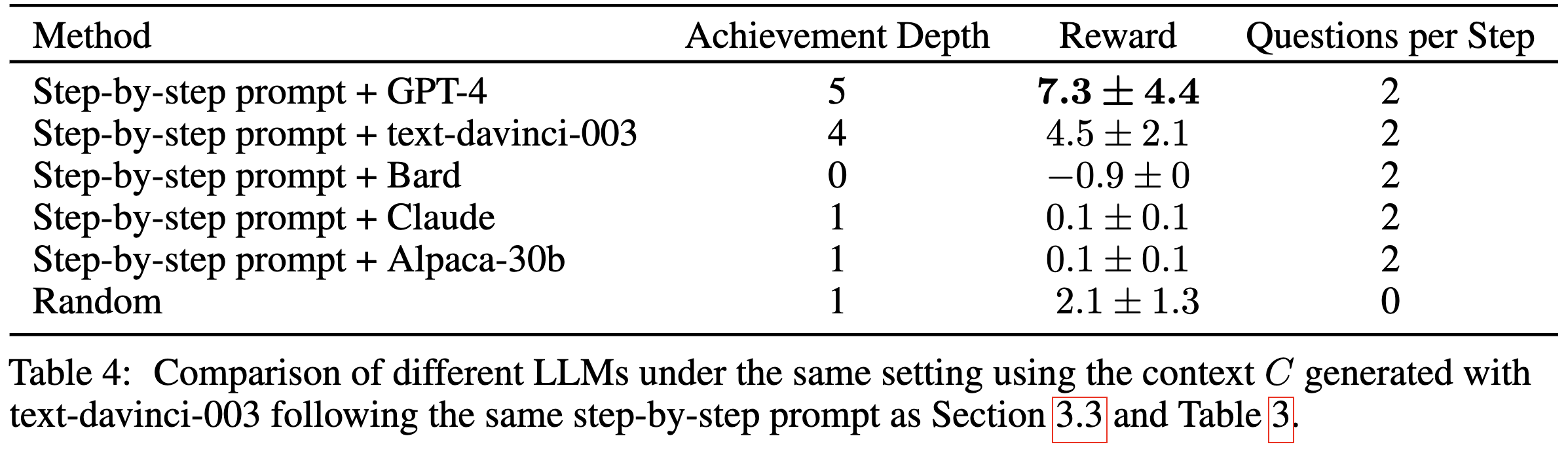
While it’s only one task, I’m reading this as good news for AI safety. It’s much easier to inspect, reason about, and control a program that uses LLMs as narrow subroutines than one that has RL agents solving problems end-to-end. Also seems like a bit more evidence against the orthogonality thesis in that the capabilities stem largely from problem-specific tailoring.
I’m not positive this is true, but I’ve been going through the new submissions almost every week since fall 2020 and am pretty sure this is the most I’ve seen.
I don't think the authors claim LIMA outperforms GPT-4, Claude, BARD. "responses from LIMA are either equivalent or strictly preferred to GPT-4 in 43% of cases"