2022-4-10: Solving ImageNet, An actually great pruning paper, Per-class augmentation

Reproducibility Issues for BERT-based Evaluation Metrics
People have proposed various BERT-based alternatives to BLEU for natural language generation and machine translation. But it turns out that these often result in a reproducibility dumpster fire, thanks to undocumented preprocessing subtleties, missing code, and various other issues. This sometimes results in inflated results or handicapped baselines. Another paper for my pile of meta-analyses with disconcerting conclusions.
⭐ The Effects of Regularization and Data Augmentation are Class Dependent
Not a super novel result (see, e.g., Divya’s paper or Sarah’s paper), but a good empirical study that also explores L2 regularization. A few interesting findings:
The effects of different data augmentations depend much more strongly on the class than on the specific model (see below lines in first fig clustering mostly by color)

Even simple L2 regularization has significantly different effects on different classes. (2nd fig)

Pretraining with different augmentations has class-specific effects even for classes in downstream tasks (3rd fig)
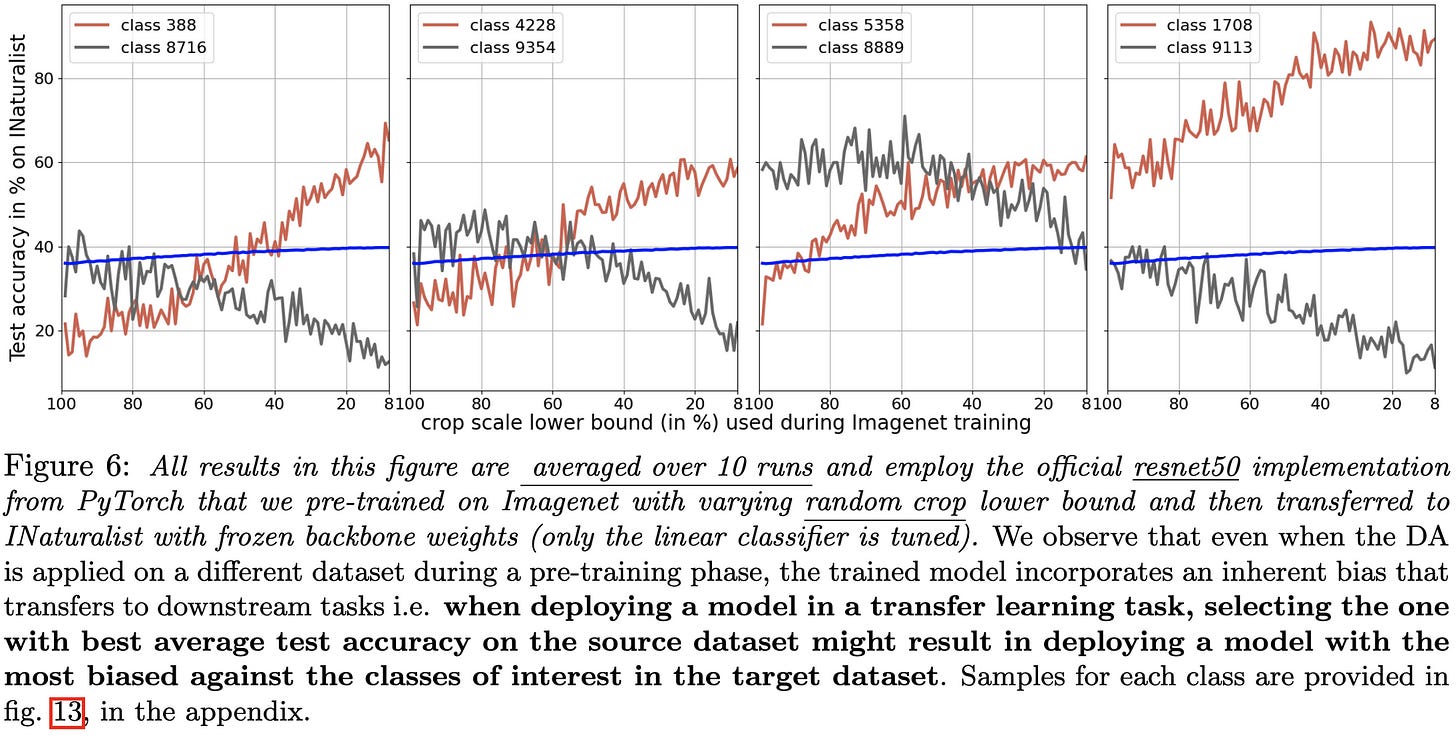
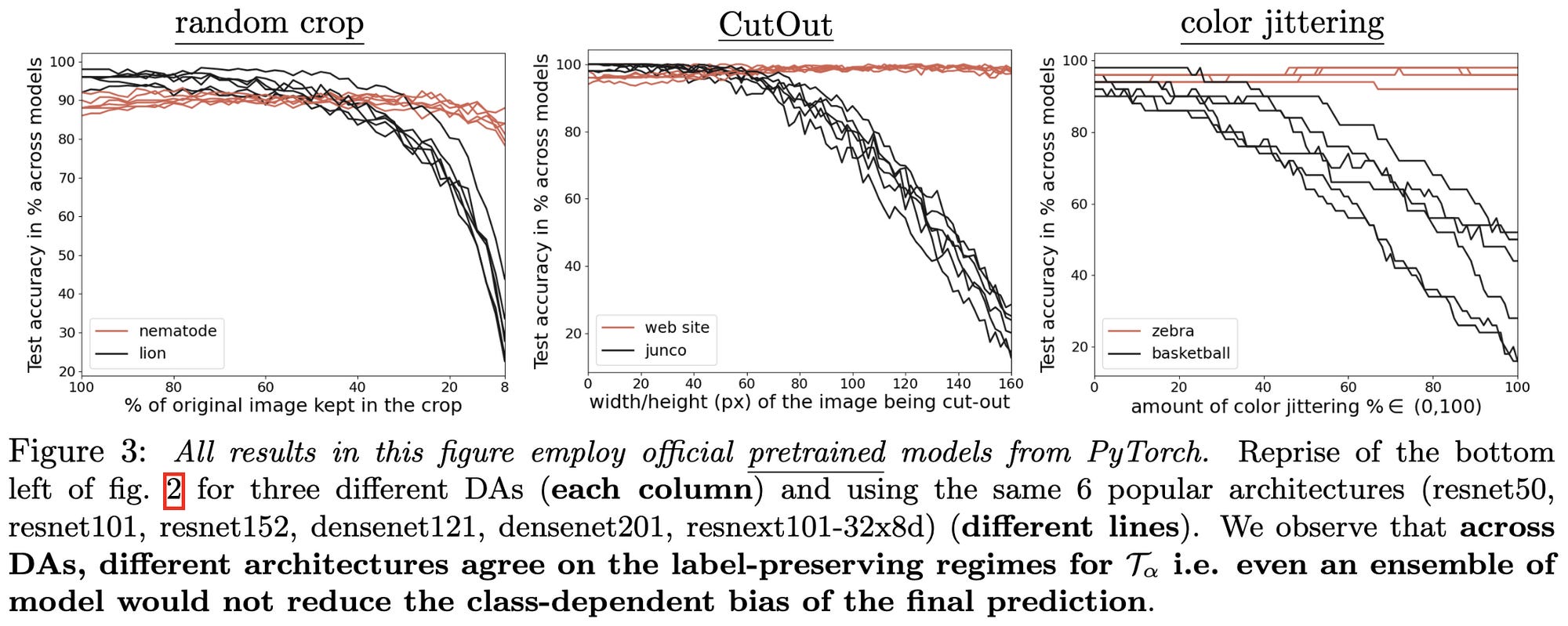
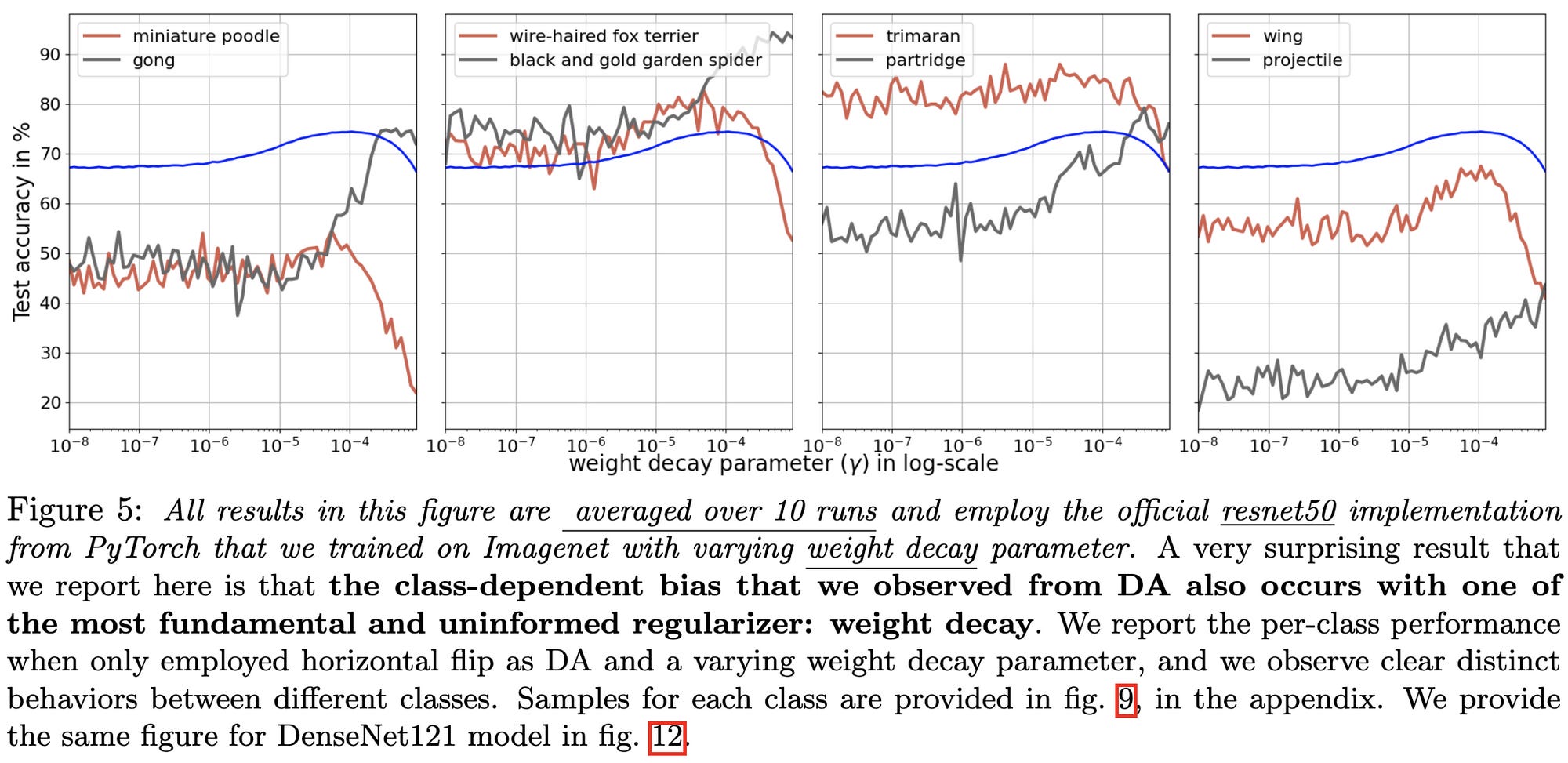

Makes me think that a smart data augmentation module/API could yield large accuracy gains. Just figuring out which augmentations aren’t label preserving for each class and avoiding those would likely yield a ton of value.
Learning to Compose Soft Prompts for Compositional Zero-Shot Learning
Considers zero-shot learning for compositions of (attribute, object) pairs. E.g., you might see (young, tiger) and (big, dog) in the training data, but at test time have to identify (young, dog). They approach this by starting with pretrained image and text encoders, and then prompt tuning the representations for each attribute and object to get the image and text encoder to have high cosine similarity. Turns out this works really well when you can get a dataset with this structure—17.7% zero-shot accuracy lift vs CLIP. Though note that this is on tasks with at most 30k training samples, so the advantage would likely diminish for downstream tasks with more data.




⭐ Solving ImageNet: a Unified Scheme for Training any Backbone to Top Results
What if instead of having a unique training recipe for every model on a given dataset, we just had one recipe per dataset? Turns out you can do this; with a single set of augmentations and hparams, the authors manage to outperform the published numbers across a dozen diverse architectures. The caveat here is that distillation adds a lot of accuracy (see ablations below), so it might be the case that some models’ published recipes would be better than this recipe if distillation were added. A lot of useful experiments here, and they do seem to support the claim that you can construct a “pretty good” recipe for a given dataset and not worry too much about tuning it for a specific model.
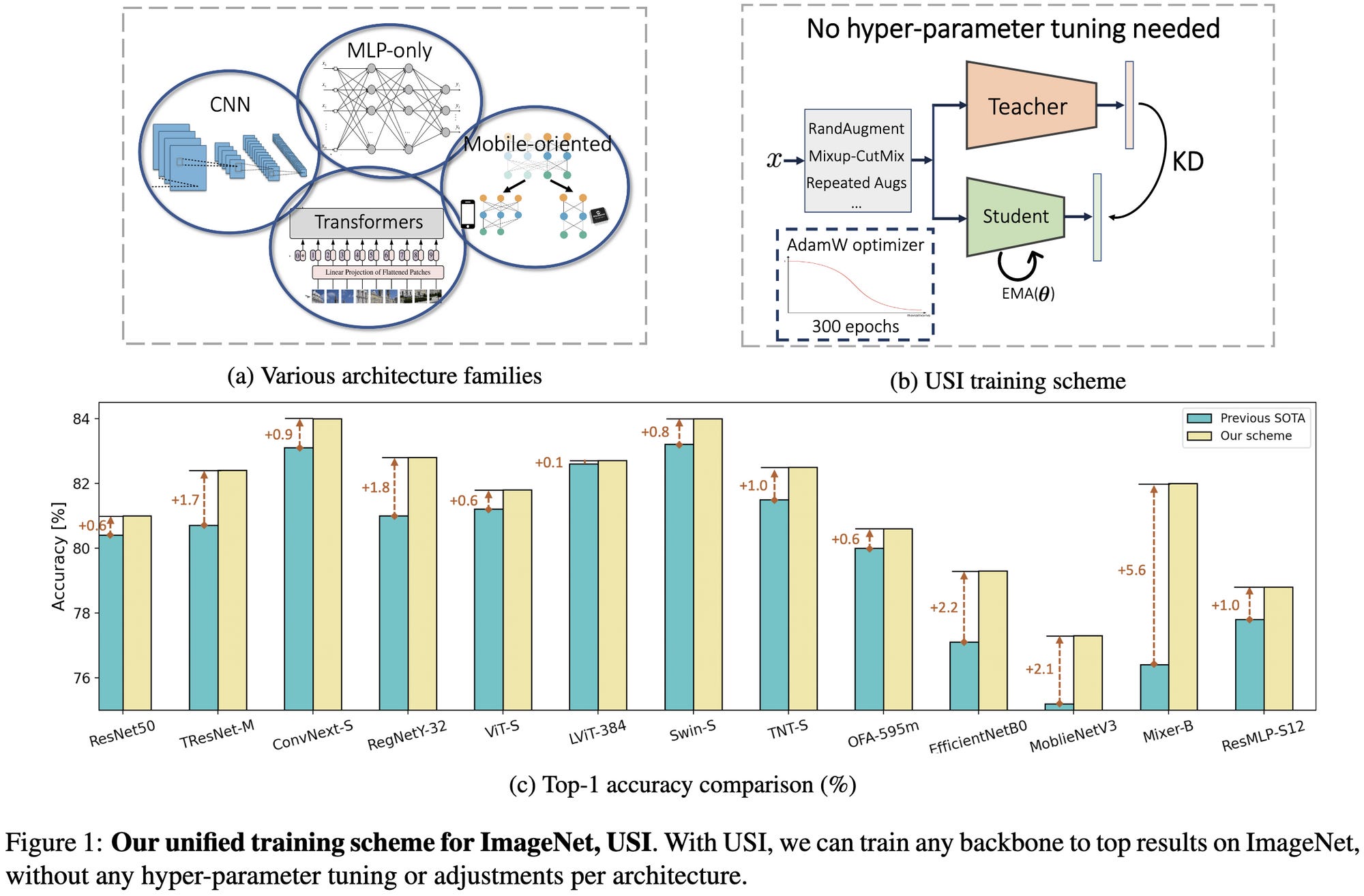


Knowledge distillation makes a huge difference. When doing a convex combo of original and teacher labels, going from ignoring the teacher to only using the teacher gets you +6.5% accuracy. And there’s no point messing with the temperature in the teacher softmax. Or even the teacher model, seemingly, provided that the accuracy is about the same.

Also, consistent with the TIMM results, LeVit is awesome (at least on GPUs).


Pretraining Text Encoders with Adversarial Mixture of Training Signal Generators
Building on ELECTRA-style training to use multiple auxiliary models instead of just one. Main model is trained on replaced token detection (RTD), and auxiliary models choose token replacements to fool the main model. Uses backprop to choose mixing weights for replacement choices of the auxiliary models. But for efficiency, the three models are actually just one model, probed at three different depths. The intuition is that 1) the generators should get better over time, dynamically making the task more difficult, and 2) the trained weights should select the curriculum intelligently. Seems to yield ~1 point improvement on GLUE compared to other approaches. But given the extra compute to sample from the extra model, not sure this is a net win vs just training for longer.


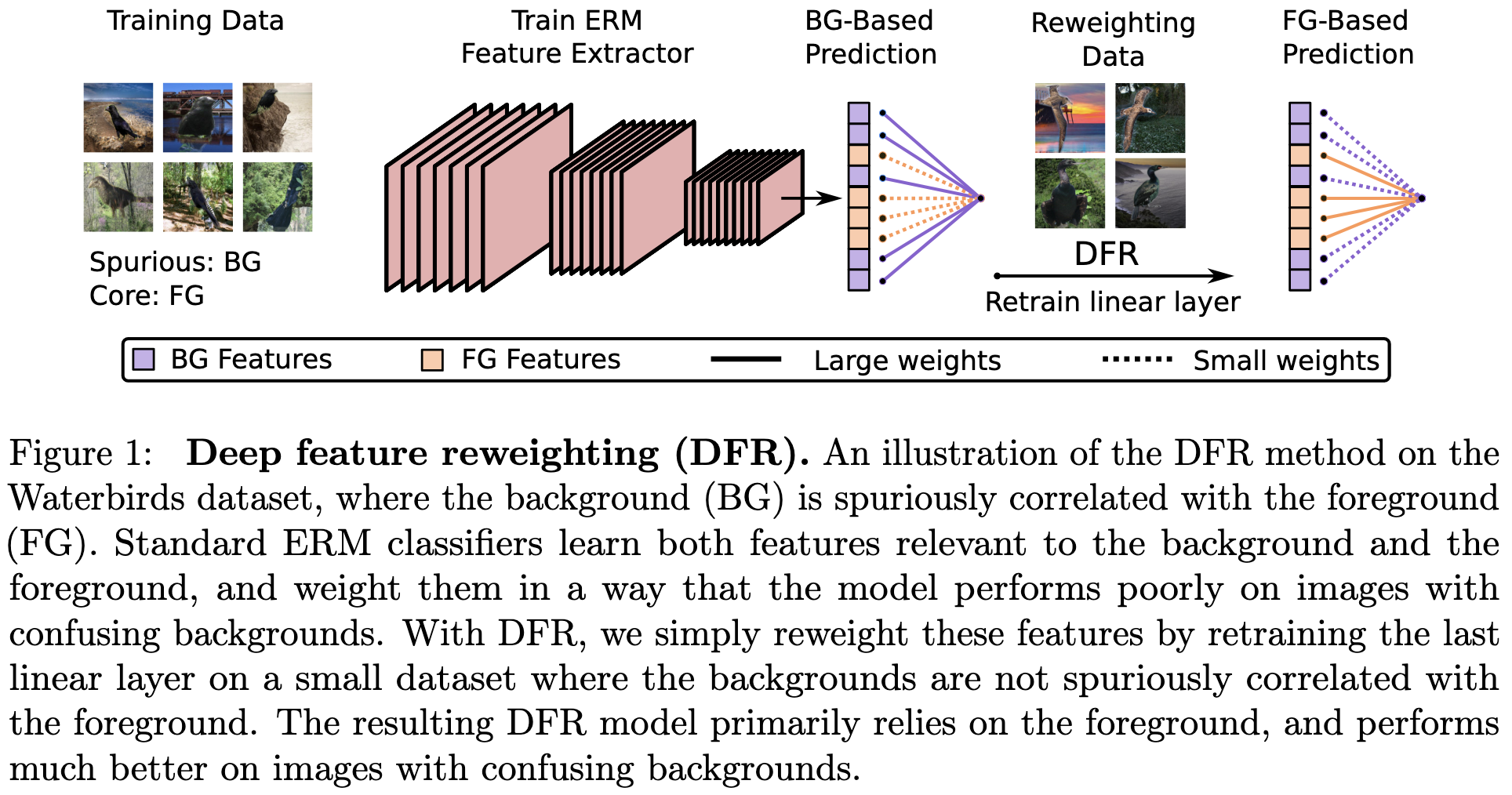
Last Layer Re-Training is Sufficient for Robustness to Spurious Correlations
The interesting underlying observation here is what they call “logit additivity”. Namely, that the overall image embedding can be well approximated by the sum of the embeddings for the foreground and background independently. And relatedly, that models still learn non-spurious features of their inputs, even when spurious features are largely responsible for the predictions. This is what enables reweighting samples to suffice for removing dependence on spurious features. Their approach seems to work well, although they need an auxiliary dataset where the spurious correlations aren’t present. In practice, they recommend collecting a group-balanced validation set and using it both to tune hparams and re-train the final layer.
Accelerating Backward Aggregation in GCN Training with Execution Path Preparing on GPUs
A bunch of systems optimizations for graph convolutional network training on GPUs. Biggest focus is message passing between vertices in the backwards pass, since this is the biggest bottleneck. Exploits the observation that you know the exact pattern of message passing ahead of time, so you can avoid warp divergence and optimize the data layout. It’s a detailed paper with various constituent algorithms, but worth digging into if you care about this problem.


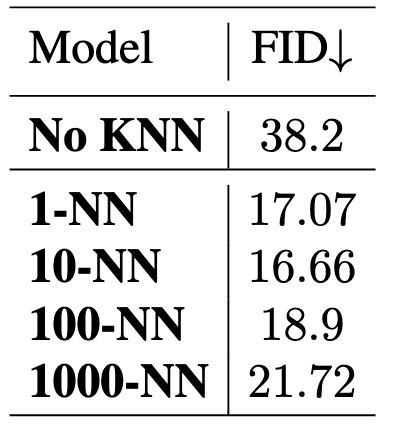
KNN-Diffusion: Image Generation via Large-Scale Retrieval
Adds a KNN component to VQ-Diffuser. Includes a VQ-based encoder-decoder network for images, a CLIP-based text-image encoder (so that both are embedded in the same vector space), a big old store of embeddings, and a diffusion model that conditions on a set of retrieved embeddings. To generate an image from text, you encode the text, retrieve the most similar image embeddings, and feed that as auxiliary input into your diffusion model. Similar to papers like RETRO, there’s a sweet spot regarding number of neighbors to retrieve; I suspect this stems from a tradeoff between coverage and relevance. No timing results AFAICT, but large enough quality improvements that this is probably a net win, assuming your KNN search is fast enough.



Perception Prioritized Training of Diffusion Models
What if, instead of weighting the loss at all times within the diffusion process equally, we downweighted the parts where the noise is nearly imperceptible? Turns out this works better.




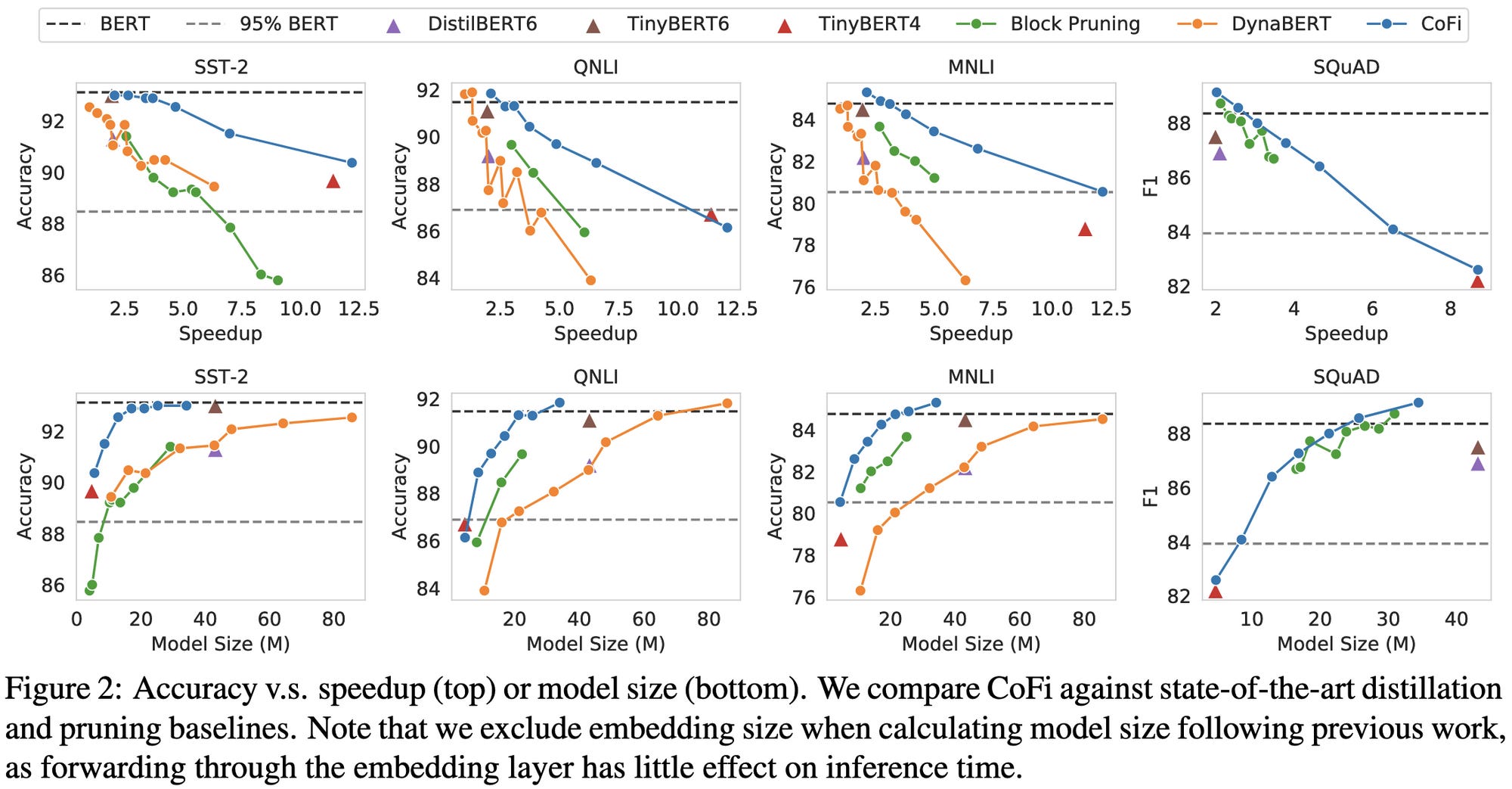
⭐ Structured Pruning Learns Compact and Accurate Models
Wow, this is the best pruning paper I’ve seen in a long time. 2.7x inference latency reduction on BERT base at the same accuracy. Uses structured pruning with self-distillation, where distillation happens not just at final outputs, but also at intermediate layers; i.e., modules within the student are trained to approximate the outputs of corresponding modules in the teacher, with “corresponding” chosen intelligently (not just based on assuming a fixed mapping). Basic pruning approach is trainable gating multipliers for each param, which gate values below a certain threshold zeroed out during inference. And many structured sparsity approaches all used at once: head pruning, feature pruning in embeddings, MHA and FFN, and full layer pruning. The tradeoff curves showing accuracy vs {speedup, model size} make me so happy.





⭐ Monarch: Expressive Structured Matrices for Efficient and Accurate Training
One of the papers we gave a spotlight award to at the Bay Area EfficientML meetup. They basically just swap out normal matmuls for pairs of block diagonal ones, with added (fixed) permutations between them. What’s surprising is that this 1) can preserve full accuracy at ~1.5-2x speedup for important training tasks, 2) also works as a form of sparsification for inference. To get full accuracy with sparse training, they need to convert to dense matrices for the last 10%. To convert a dense model to a sparse one, there’s a closed-form solution for approximating each dense matrix (albeit one that involves some heavy linear algebra). Pretty strong theoretical grounding; they show that their family of linear transforms, or products of them, include lots of existing structured matrices like convolutions, fastfood transform, ACDC, DCT, FFT, and more. The one thing I can’t figure out about this paper is where the permutations come from; will probably have to look at the source code to get all the details. Also note that they don’t say whether they use mixed precision—would pretty much nullify all these results if not.



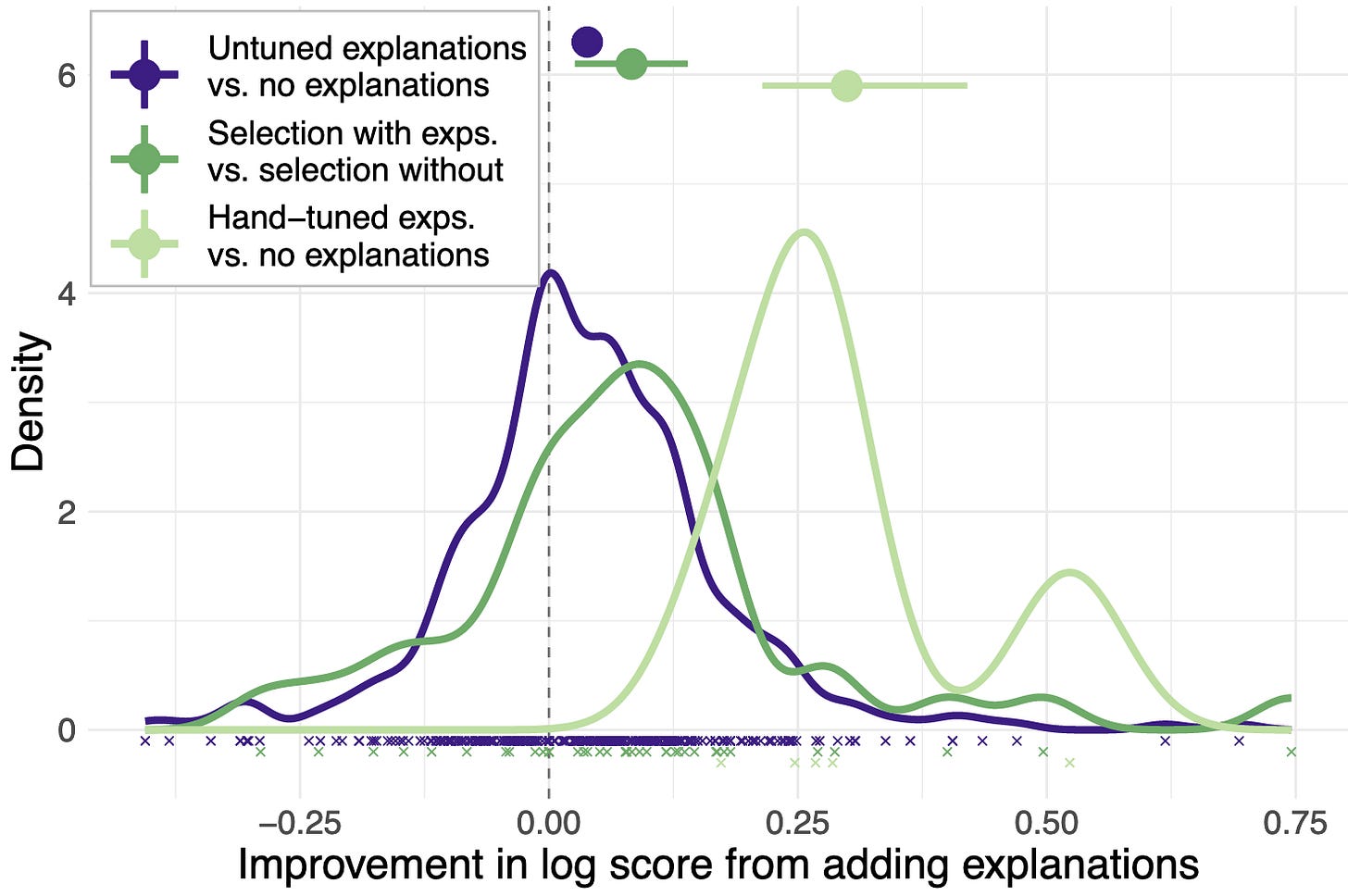
Can language models learn from explanations in context?

Several findings regarding giving models explanations within their few-shot prompts:
Large models benefit from explanations but small models don’t
Tuning (rephrasing) explanations based on a validation set can significantly improve performance. This was done manually, and entailed some mix of just plain messing around with the text, spelling out reasoning more explicitly or adding more natural language (e.g., for math problems).
Explanations help more than control text.