2022-4-24: Merging networks, Wall of MoE papers, Diverse models transfer better

⭐ Merging of neural networks
They present evidence that you’re better off training two copies of a model and then merging them than just training one copy for the same amount of time. Results only scale up to ResNet-18 on ImageNet for 150 epochs, and only like a 0.2% accuracy lift. Probably not worth the complexity if your alternative is a normal training workflow, but might be an interesting halfway point between fine-tuning only and training from scratch. Or even a means of parallelizing large-scale training.





My favorite result is this ablation: “We use the same number of epochs in all strategies. In our strategy, student, we use two-thirds of epochs to train teachers and one-third to train student (one sixth to find important neurons and one-sixth to fine-tune).” I don’t totally believe the accuracy lift when controlled for training time since the “big student” epochs should each be ~4x as slow. But it’s at least in the right ballpark.

FastDiff: A Fast Conditional Diffusion Model for High-Quality Speech Synthesis
They got diffusion models running way faster than real-time on a single GPU for speech synthesis. Like a couple other papers, they do this by greatly reducing the number of sampling steps. In their case, they do it with a learned noise schedule that increases the ELBO.

SpiderNet: Hybrid Differentiable-Evolutionary Architecture Search via Train-Free Metrics
Another paper doing NAS purely with proxy metrics, rather than actually training the proposed architectures. They use a combination of NTK stats from here and a Linear Region Count (LRC) statistic. They score networks based on their ranking in terms of these two stats relative to other models trained so far, with lower NTK stat and higher LRC being better. Kind of a clever way to make the proxy metric nonparametric. Their other big design goal is that they want less human engineering of the design space, so they have this evolutionary algorithm for mutating networks. Sadly, results don’t really demonstrate that it works—if anything, seems worse than existing methods in terms of final model efficiency and quality.

A Fast Post-Training Pruning Framework for Transformers
Given a trained transformer model, 1k-2k samples from the target distribution, and a resource constraint on the returned model in terms of FLOPs or inference latency. Generates a binary mask for what attention heads and filters to prune based on a block diagonal approximation to the hessian of the loss wrt binary masks for what element to keep. Interestingly, it’s block diagonal, rather than purely diagonal; it takes into account interactions of different heads within an MHA layer or different (groups of?) neurons in an FFN layer. Solved via greedily adding mask elements within each layer. After what to prune is chosen, they use linear least squares to try to restore the original outputs of each layer.






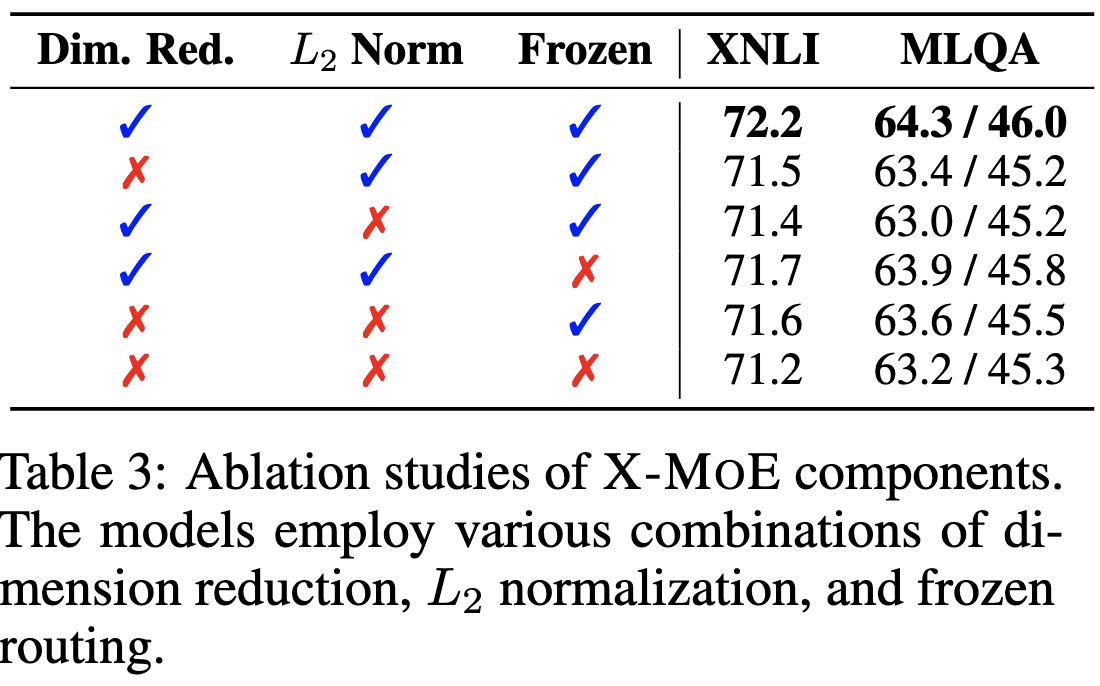
On the Representation Collapse of Sparse Mixture of Experts
They do simple math to show that the token representations tend to get driven towards a linear combination of the expert embeddings, which is probably much lower-dimensional than the full vector space. To fix this, they:
Project to a lower-dimensional space before computing token-expert affinities
L2 normalize across experts for a given token
Add a learnable softmax temperature, since L2 makes affinities too uniform
Add an auxiliary load balancing loss like in switch transformer
Freeze the routing parameters during fine-tuning.
Yields slightly higher model quality. Unclear if there’s significant extra time cost though. They show that not freezing the routing parameters results in tokens ending up getting routed totally differently across different randomly initialized fine-tuning runs. Makes me feel like we’re still probably not using MoEs that efficiently, and that there are more improvements to be had.





StableMoE: Stable Routing Strategy for Mixture of Experts
They observe that MoE routing assignments change a lot during training. This results in a train-test discrepancy, because the token was often fed to different experts during training than it was at test time. I would also argue you should want the experts to have disjoint and stable token distributions from just a regular old covariate shift perspective. They only make the routing trainable for like 10% of training, and then they freeze it, instead using a distilled model to directly produce routing assignments from word embeddings. The model can be anything but they got the best results with a CNN (not sure what they were convolving over, but I assume sequence axis).









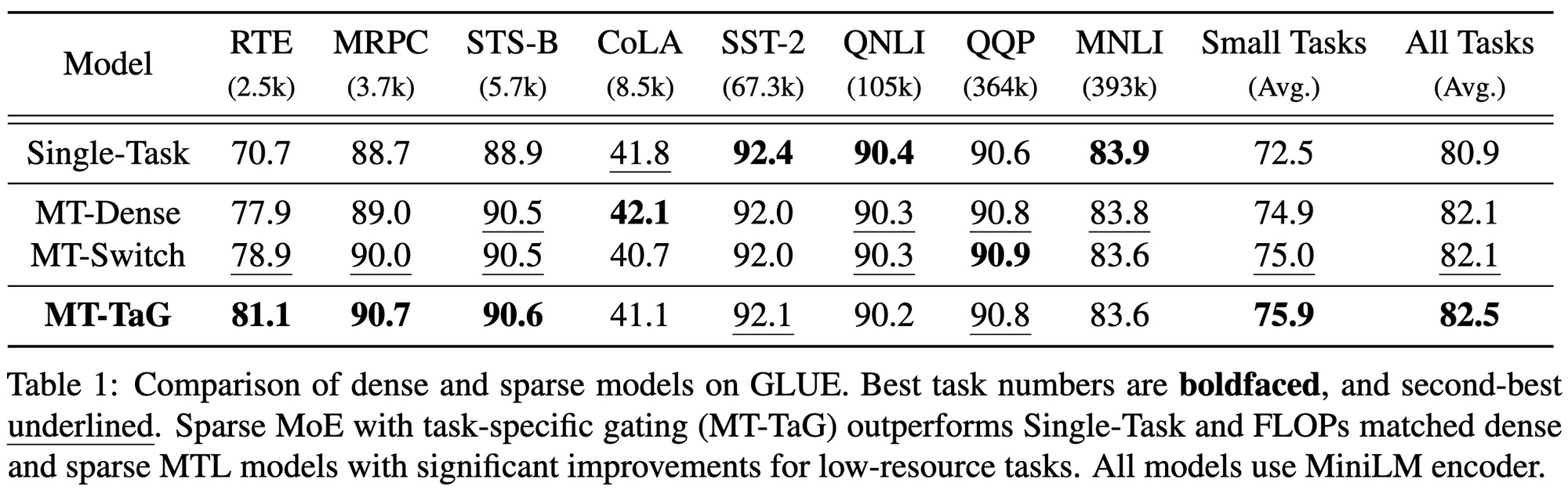
Sparsely Activated Mixture-of-Experts are Robust Multi-Task Learners
Top-1 softmax routing, but with a task-specific projection W to compute the expert affinities. Seems to yield ~1% better accuracy across various NLP tasks.


Residual Mixture of Experts
Don’t have the MoE logic present during pretraining; only have it for fine-tuning. Worse accuracy but training runs a little faster, assuming the MoE added some overhead.


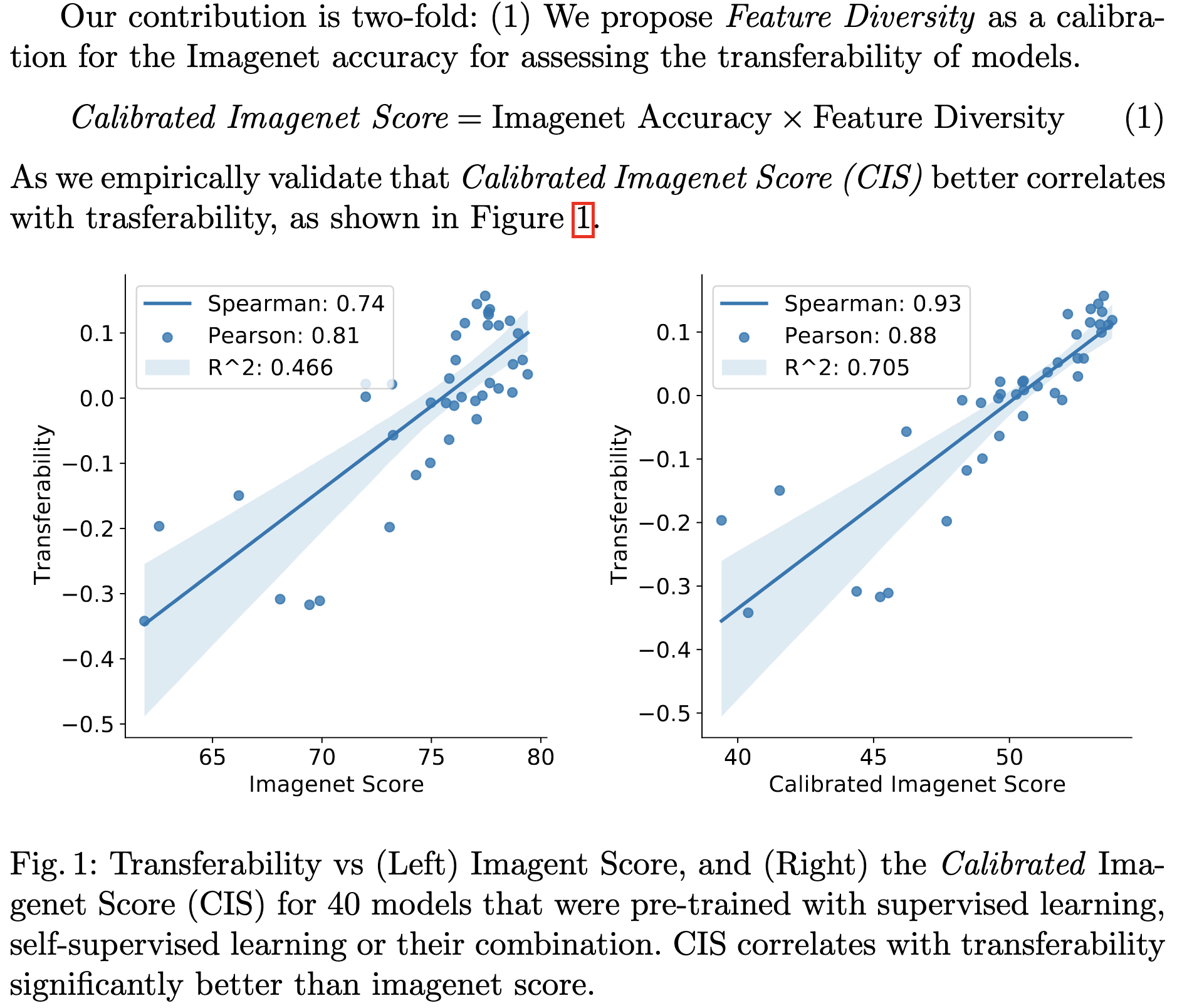
Diverse Imagenet Models Transfer Better
ImageNet accuracy tends to be a pretty good proxy for downstream task performance, but not a perfect one. In particular, self-supervised methods can yield models that perform worse on ImageNet but better on downstream tasks.
They find that multiplying the ImageNet accuracy times a “feature diversity” score yields a good predictor of downstream accuracy. Feature diversity based either on a clustering measurement or on AUC of cumulative explained variance as a function of principal component index; both worked similarly well.
They also propose a means of increasing feature diversity in self-supervised learning. Another paper suggesting that downstream task performance is predictable from even a simple set of features.



DeepCore: A Comprehensive Library for Coreset Selection in Deep Learning
Nothing consistently beats random subsampling on ImageNet. Based partially on these results, I’m not convinced coreset construction makes any sense to combine with multi-epoch training; seems strictly better to train on the full dataset for fewer epochs. Unless maybe your “coreset” is most of the data but with mislabeled or numerically problematic samples thrown out.

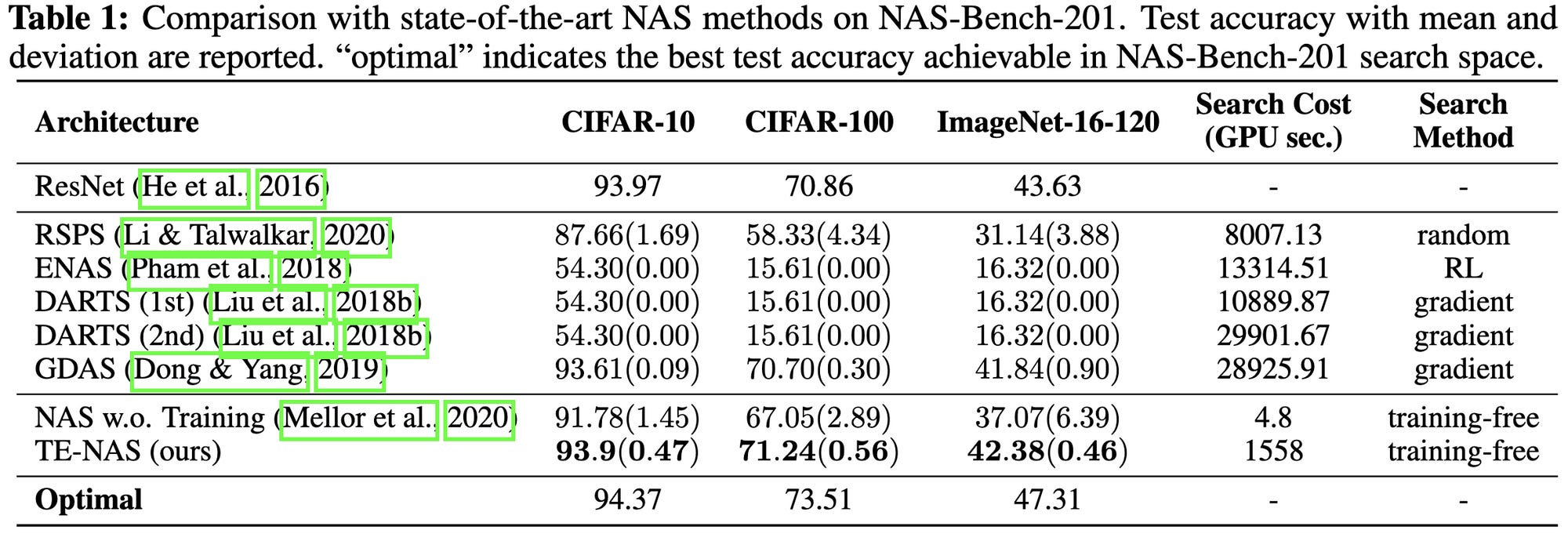
Neural Architecture Search on ImageNet in Four GPU Hours: A Theoretically Inspired Perspective
NAS paper from last year using NTK condition number and number of locally linear regions as a proxy for accuracy. Lets them do the NAS in 4 GPU-hours on ImageNet. Works better than alternatives at the time according to their NAS-Bench-201 results.



Beyond L1: Faster and Better Sparse Models with skglm
Designs "the first fast algorithm to solve generic sparse generalized linear models.” Including with non-convex regularization like L_p loss with 0 < p < 1. I’ll probably give this a try next time I need to train a serious linear model.




Visual Attention Methods in Deep Learning: An In-Depth Survey
Overview of 50 attention variants. What I really like about this survey is that it actually explains all of them, including a diagram for almost all of them. I’m probably not gonna read this in detail, but likely will go back to it whenever I want a quick summary of an attention paper from 2021 or earlier.


Efficient Architecture Search for Diverse Tasks
Kind of a weird NAS paper where they have a mostly fixed conv architecture, and just want to optimize the filter sizes and dilations. They use FFTs to avoid the overhead of large kernel sizes and do some clever stuff with kronecker products to handle dilations efficiently. They also use the fact that convs are linear to mix different kernel options to make the choice of which one to use differentiable. More restricted scope than typical NAS, but lets them run the search much faster; typically less than 2x slowdown vs just training the unoptimized original CNN. Claims new SOTA on 7/10 tasks on NAS-Bench-360


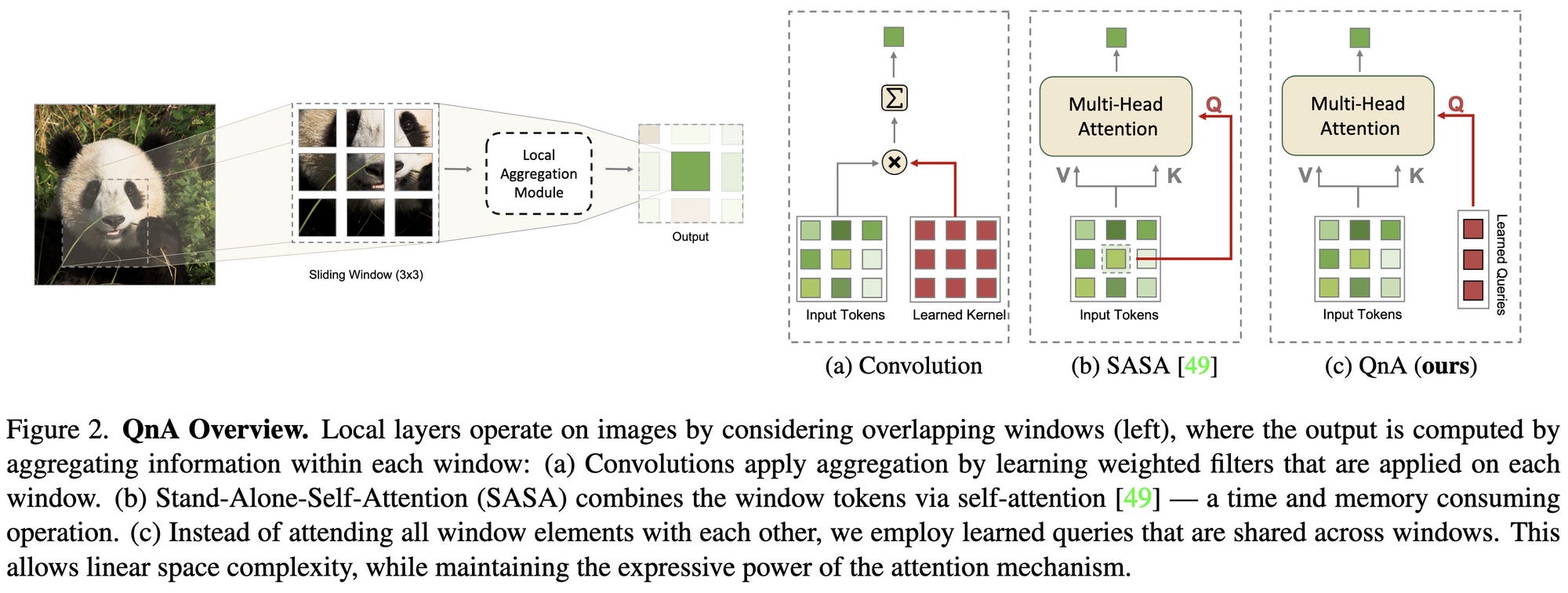
Learned Queries for Efficient Local Attention
Learned query matrix shared across all windows instead of a query matrix that’s a linear projection of the input tokens. But what’s weird is they then sum the attention matrices from all the queries to get one overall attention matrix. Their overall architecture uses a mix of their QnA modules and regular attention. Beats Swin transformer as measured in FLOPs, params, and training throughput, but so have a lot of papers recently (and by similar margins), so not sure what to make of this.