
2022-5-15: T-Few, Task scaling, Gato

These summaries made possible by MosaicML. If you find them helpful, the best way to thank me is by checking out + starring Composer, our open-source library for faster model training.
⭐ Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning
Like most of Colin Raffel’s papers, this is exceptionally thorough and interesting. They consider the problem of few-shot learning without full fine-tuning. Avoiding full fine-tuning is desirable since it means we don’t have to have a giant, unique model for every task we care about. What they do instead is:

Multiply in learned, task-specific scales for the key matrices, value matrices, and hidden layers in FFN modules. These scales are pretrained on the multitask corpus used to train T0. Importantly, they also allow the same model to be used for different tasks, even within a batch, since task-specific multipliers can be used for each sample’s activations.

Divide the sequence log probabilities by the sequence lengths when ranking candidate responses at test time. They also add a length-normalized cross-entropy loss at training time (in addition to the normal cross-entropy loss).

Add in an “unlikelihood” loss that penalizes the model for predicting tokens from incorrect sequences. All three losses get summed together with no tuned weightings.




Together, these changes yield great results, outperforming even a human baseline:
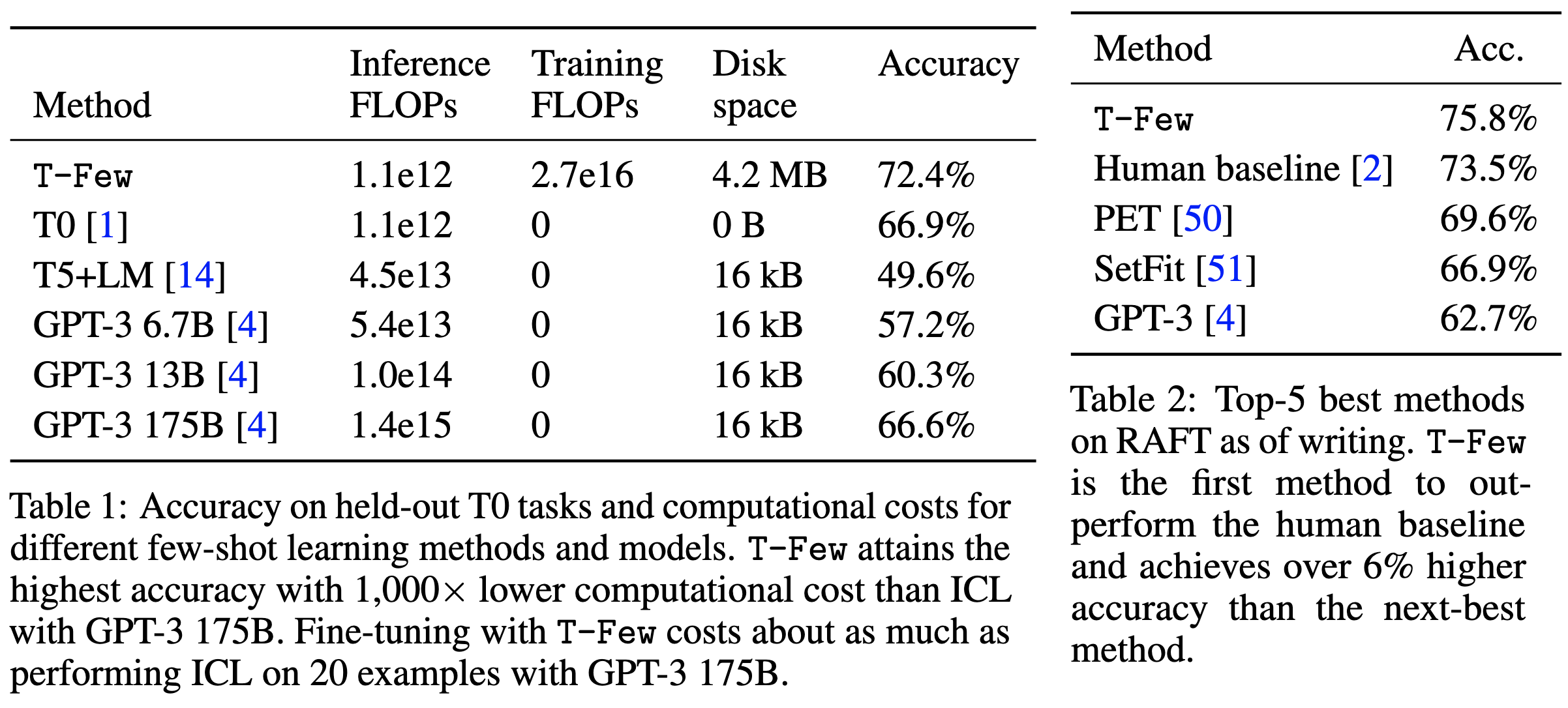

What I’d really like to know is how generalizable some of their contributions are. E.g., should we always be adding length-normalized and unlikelihood losses? And what if I want to fine-tune a BERT rather than T0?
See also: Colin Raffel’s Twitter thread.
⭐ ZeroPrompt: Scaling Prompt-Based Pretraining to 1,000 Tasks Improves Zero-Shot Generalization
Instead of pretraining on language modeling and then fine-tuning on tens of tasks, they just train on ~1,000 tasks. And this apparently works ridiculously well. Lets them train with up to 30x fewer FLOPs.


Their datasets include a variety of different tasks but, sadly, are mostly proprietary.

Part of their performance also comes from careful prompt design, along with a genetic algorithm to optimize the prompt using a small validation set for each test task.

As shown in the first figure, consistently better results as they scale up the number of tasks. Though AFAICT this is also scaling up amount of data, so it’s unclear how much is from task diversity vs sheer data scale.

Reminds me a lot of the NLP from Scratch paper, which also ditched most of the LM pretraining and got a >10x speedup vs RoBERTa-Large at the same accuracy. Although that was kind of the opposite in that their approach was most desirable when you only cared about a few tasks.
This paper makes me strongly suspect we’re wasting most of our model capacity on language modeling itself. I’m also curious how their results would generalize to English, which has less consistent sentence structure and more arbitrary rules and exceptions.
⭐ A Generalist Agent
DeepMind trained a single model to control robots, play games, or output text. Two aspects of this are remarkable IMO:

The model is only 1.2B parameters, more than 100x smaller than GPT-3. These seem like awfully good results for a model that size. Though admittedly it’s usually not as good as specialized models for each task.

How short the method section is. There’s some amount of modality-specific preprocessing turning everything into tokens, maybe adding positional embeddings, and laying the tokens out in a particular order. But…this is not the sort of monstrous pile of hacks you see in a lot of multimodal or applied ML papers. Obviously there’s a ton of software under the hood, but I would expect a long list of tricks and workarounds.


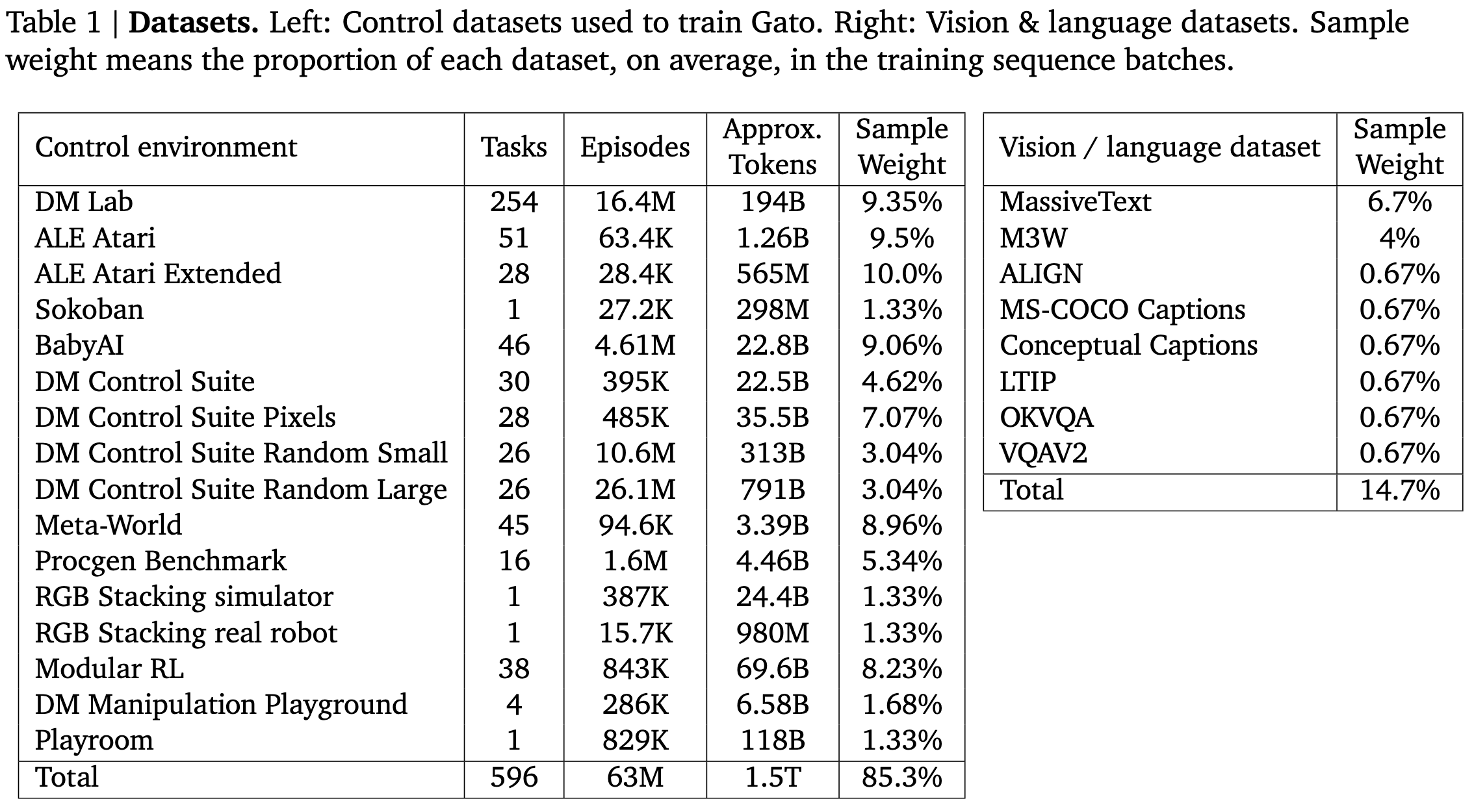
One subtle aspect of the method is that their RL-like tasks seem to be pure imitation learning. They do feed the outputs to an environment, but just sample from Gato autoregressively like it’s a language modeling task.

If you read the model card in the appendix, it really feels like controlling a robot was the main motivation. Also sentences like “we…purposely restricted Gato’s size such that it can be run in real-time on the real robot.”
Overall I’m definitely impressed by this, and it seems consistent with the results in the task scaling paper above.
See also: Eric Jang’s thread, Gwern’s take.
Distinction Maximization Loss: Efficiently Improving Classification Accuracy, Uncertainty Estimation, and Out-of-Distribution Detection Simply Replacing the Loss and Calibrating
Trying to improve both image classification accuracy and OOD detection. There are three different parts to their proposed method:
First, they propose a cutmix-like augmentation approach that combines 4 images into one image. Unlike cutmix, there’s no randomness in the proportions or locations of the mixing. It’s always just 4 tiles. Really similar to mosaic augmentation.

Second, they propose an alternative to cross-entropy that takes into account the average distance to prototypes (cols of the final linear layer) of all classes. The distance is euclidean distance with a learnable scale factor.


Lastly, they propose to extract a feature of the logits that’s a useful signal for OOD detection. The feature is the sum of the maximum logit and mean logit, minus the entropy of their proposed adjusted softmax distribution.
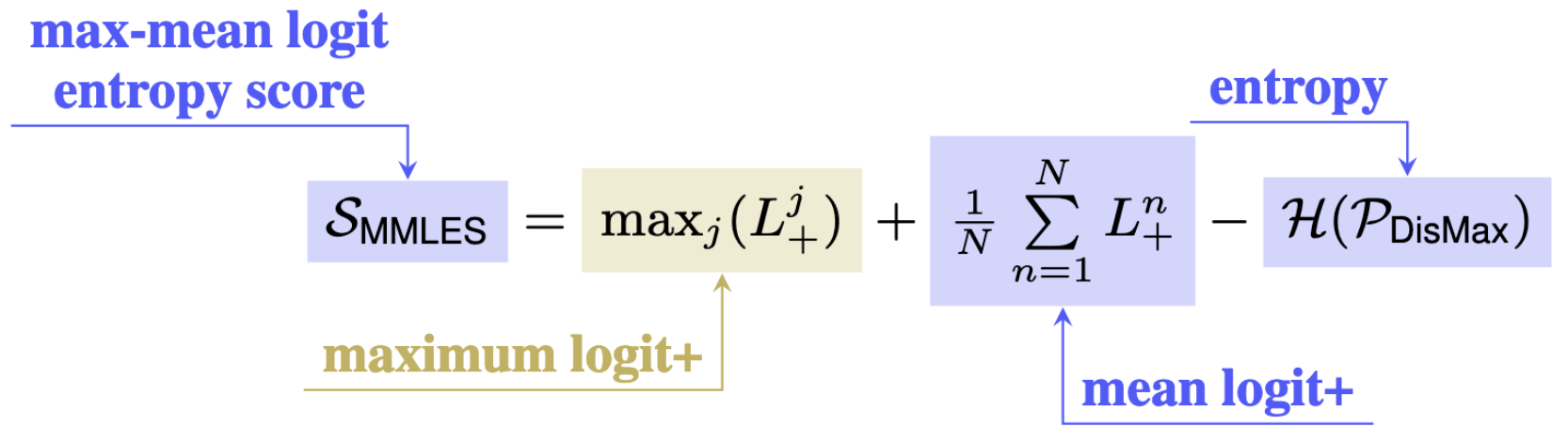


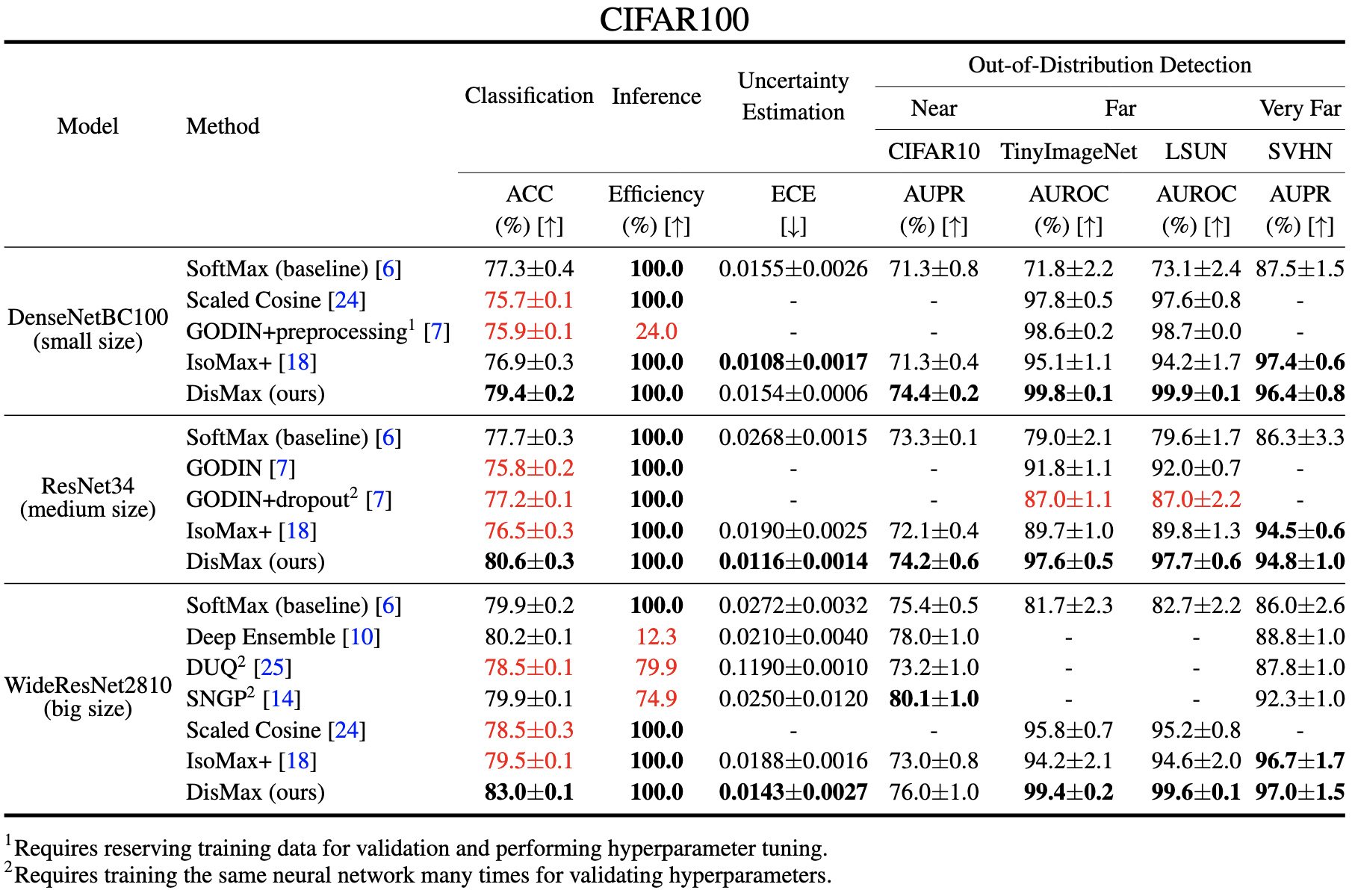
Pretty good results. Only evaluated on CIFAR-10 and CIFAR-100, but often yields a multi-percentage-point accuracy lift on CIFAR-100. I usually want to know how alternate loss functions compare to cross-entropy with label smoothing, but these are much larger lifts than the I’ve ever gotten from label smoothing on this dataset. Would love to see a comparison to cutmix though.
Also, props to the authors for beautiful equation annotations. I’m going to be copying their latex in the future.
Tiny Robot Learning: Challenges and Directions for Machine Learning in Resource-Constrained Robots
This paper points out that there are all sorts of interesting problems at the intersection of ML and resource-constrained robots. If you really want a challenge making your model “fast” or “efficient,” try coding it in pure C and deploying it on a device with 1KB of RAM.


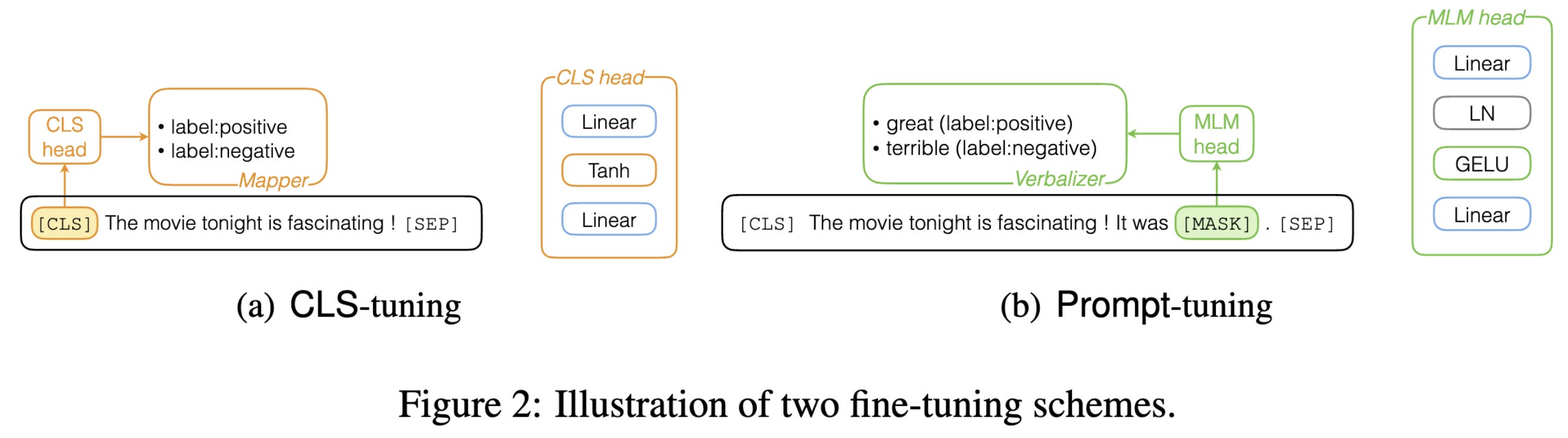
Making Pre-trained Language Models Good Long-tailed Learners
Finds that “prompt-tuning outperforms CLS-tuning by large margins across datasets in terms of F1 scores.” Doesn’t seem to be a product of coupling the classifier and backbone embeddings. Might be a product of CLS-tuning not resembling the MLM pretraining task as much. The structure of the output classifier seems to matter quite a bit; in particular, adding the prompt-tuning’s layernorm to the CLS-tuning head mostly closes the gap.

Results of the NeurIPS'21 Challenge on Billion-Scale Approximate Nearest Neighbor Search
New large-scale public benchmark for similarity search and results for many of the approaches you might care about. Even if you don’t work on similarity search, it’s a valuable body of literature to learn from; people are much better about reporting full tradeoff curves, using the same datasets and metrics, and actually reporting wall time. And, neural compression aside, they’re just much better at constructing efficient representations—a 64d vector is tiny to most ML people, while a 64 byte vector is big in similarity search.



SmoothNets: Optimizing CNN architecture design for differentially private deep learning
The good news: new SOTA for differentially private training through a careful analysis of accuracy-privacy tradeoffs of different model components. The bad news: 73.5% accuracy on CIFAR-10 with eps=7.0, which is…not much privacy. I lost track of this literature a while ago but it seems like private ML still has a long way to go.

Building Machine Translation Systems for the Next Thousand Languages
Most ML work starts at a high level of abstraction where we get to just assume the existence of input tensors of particular shapes. This is one of those great papers that digs into all the messy details of data collection, data cleaning, accuracy debugging, and even empirical techniques like the “period trick” to get better performance. Highly recommend p33-34 for discussion of some of the non-obvious issues that native speakers helped them identify and debug (e.g., even the name of a language can be controversial or wrong).

PinnerFormer: Sequence Modeling for User Representation at Pinterest
How do Pinterest’s models represent users?
Not-too-surprisingly, each user gets an embedding generated by a transformer. The inputs and outputs are user actions though (e.g., saving a Pin), rather than text. The loss is based on predicting randomly sampled future positive actions—they ignore negative actions like hiding a Pin.
What I found most interesting were the engineering considerations. First, they wanted a single vector for each user. They previously had many vectors per user, created for different purposes, and it was a lot more data size and complexity. They also decided to update the user’s representation daily, rather than after every single action taken, since this is much easier.

And when they do update a user vector, they merge it with the previous one with intelligent fallback so that missing data doesn’t cause corruptions.

They get significant improvements in online evaluation metrics (read, “this made them a lot of $$”):

Reducing Activation Recomputation in Large Transformer Models
They improve Megatron-LM to need less GPU memory and run up to 30% faster. They do this with strong bread-and-butter systems work analyzing activation memory usage of each layer in a transformer block and exploring different parallelism schemes. They use tensor parallelism for the linear ops and sequence parallelism (sharding across the sequence dimension) for memory-bound ops like layernorms and dropouts. They’re also smart about which activations to save vs recompute.




Evaluation shows that they almost completely eliminate the overhead of activation recomputation, and end up with faster per-iteration times than regular gradient checkpointing.

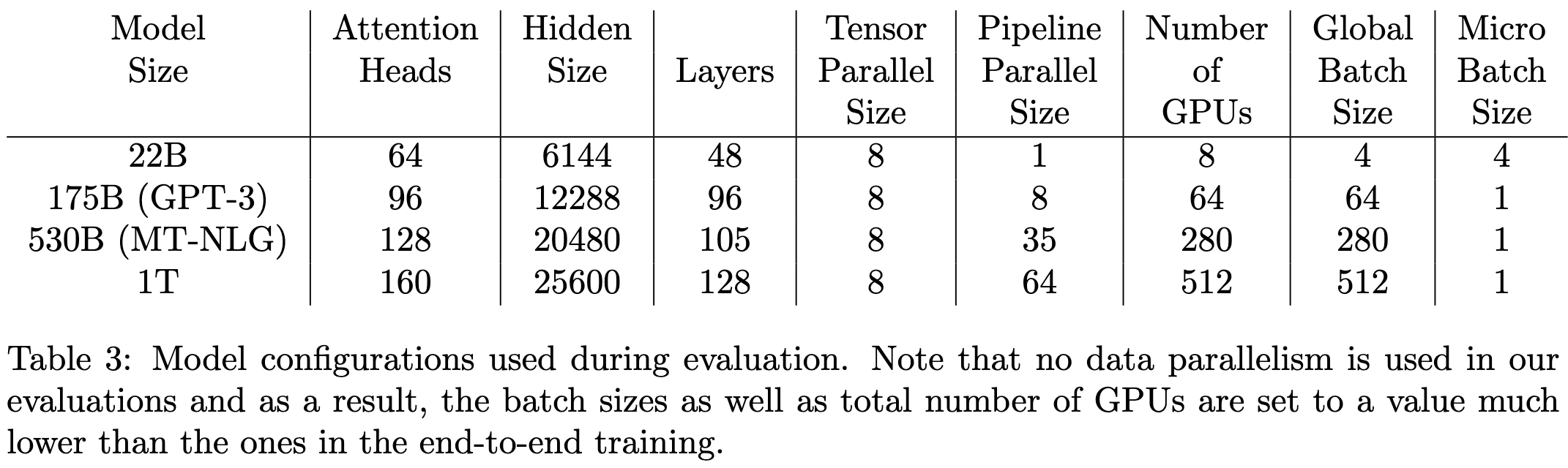
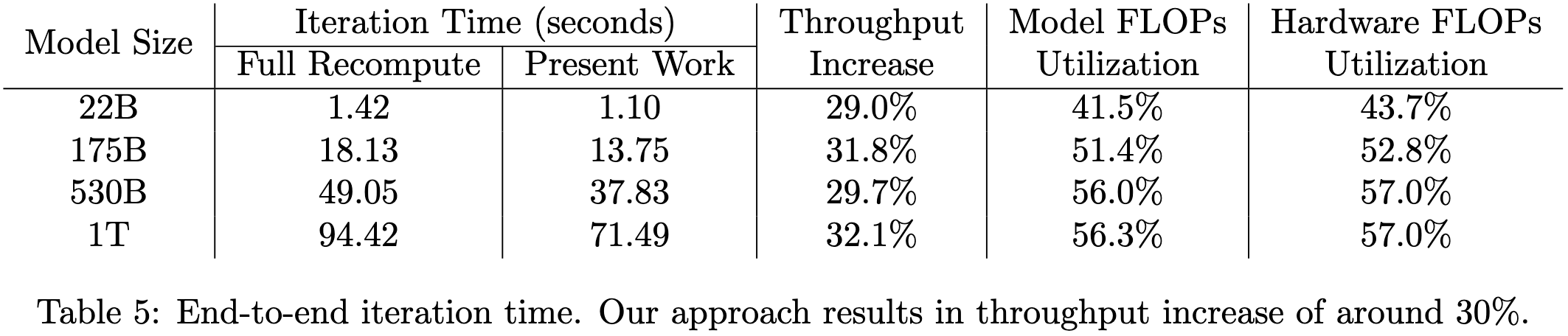
It’s so nice to see systems work like this that spans first-principles complexity analysis all the way to wall-time improvements on real workloads. Such a refreshing break from the vague intuition + FLOPs hacking underlying most claimed improvements in deep learning.