
2022-5-28 arXiv roundup: OptFormer, Imagen, Thinking step by step, 23 other papers

Huge haul of papers this week thanks to last week’s NeurIPS deadline. If I counted correctly, there are 26 summaries in here. As always, this newsletter is made possible by MosaicML (and btw, we released Composer v0.7 this week! It has FFCV integration and lots of other goodies).
⭐ Towards Learning Universal Hyperparameter Optimizers with Transformers
They train a 250M param T5 on 750,000 past runs from Google’s internal hparam optimization service. Their “OptFormer” takes in metadata about the problem, a description of the hparams to be optimized, and a sequence of trials, where each trial is a set of hparam values and resulting metrics.


They have some domain-specific preprocessing to tokenize the inputs intelligently. In particular, they uniformly quantize all scalar hparams to 1000 different integer values, and ensure that each is represented as at most one token. (If you’ve ever seen a language model fail spectacularly at math, you know why this is important).

One of the clever things they do is turn the RL problem of sequentially choosing the hparams to try into supervised imitation learning + greedy selection. Concretely, they train their OptFormer to predict the next trial in the sequence (which was originally chosen by another HPO algorithm). But at test time, to generate an hparam suggestion, they sample 1000 completions and take the one with the highest predicted accuracy.
The model ends up really good at few-shot prediction of metrics given the metadata and trials-so-far for a given HPO job.

And, more importantly, it also works well for full HPO (especially when augmented with the Expected Improvement acquisition function).
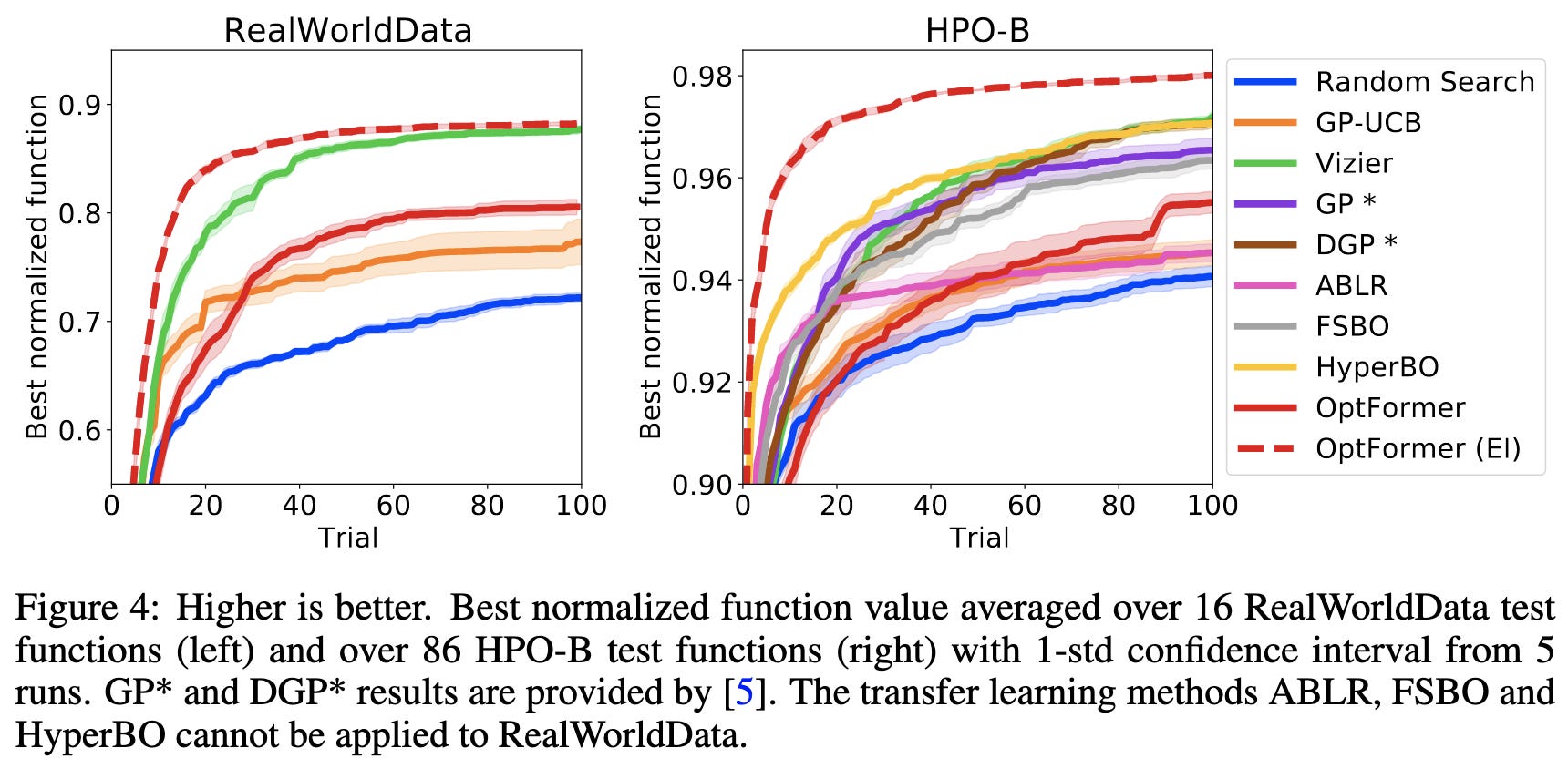
Their method doesn’t yet support joint constraints on hparam values or parallel search across multiple sets of hparam values, but these would be fairly straightforward extensions.
My conclusion is that this seems like just plain the right way to construct a good prior for hparam optimization. From a simple bias-variance perspective, we should expect a huge, trainable model to outperform simpler probabilistic models once there’s enough data. Suggests there will be future consolidation in hparam optimization, with just a few players who’ve trained a ton of models able to produce near-SOTA recommendations.
⭐ Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
The Imagen paper. They start with a frozen 11B-parameter T5-XXL to encode the text, then run that embedding through a 2B param text-to-image model, and then feed that 64x64 image through a couple O(100M) super-resolution networks to upsample it. They also introduce a dataset of image generation prompts, DrawBench, and have humans evaluate their sampled outputs compared to those of other image generation models.

They get extremely good results:

Besides the overall architecture, they also propose an “Efficient U-net” for the super-resolution models. They mostly add way more residual blocks at lower resolutions (8 instead of 3), scale the skip connections down by a factor of sqrt(2), and reverse the order of convs and {up,down}sampling in the {up,down}sampling blocks. This last change amounts to just doing more work at the lower resolution.
Super interesting work. It’s surprising that a frozen text encoder does so well, but makes sense that you can decouple the course generation task from the photorealism, addressing the latter with super-resolution networks. Also just a stunningly capable model—I mean, look at those images.

⭐ Large Language Models are Zero-Shot Reasoners
Prompt a model with “Let’s think step by step” at the end to get way better answers. Bonus points if you then re-prompt it with “Therefore the answer is” along with a format specification.
This is both super cool and immensely unsatisfying. It’s super cool because it’s a dirt simple, intuitive intervention that yields large improvements for tasks like math problems where some sort of reasoning is required.
But it’s also really unsatisfying because it suggests that we’re not getting the full performance out of our models. I.e., the model already had the requisite knowledge to solve the problem, but just didn’t actually do so until we specified the correct incantation. And who knows how much better it could still get with an even better incantation. My hope is that we’ll see a “double descent” phenomenon here, where extremely smart models figure out how to prompt themselves well, even though our current pretty smart models can’t.
Also, props to the authors for telling the story so well through their figures and tables. There’s nothing worse than a paper where the method is scattered across three different sections with important details embedded in the middles of various paragraphs.



Your Transformer May Not be as Powerful as You Expect
You’d probably assume that transformers, being seemingly more expressive than MLPs, would be universal function approximators. But you’d be wrong. At least with relative position encodings, there are continuous sequence-to-sequence functions that Transformers of any size can never approximate. The problem is that the attention matrix always ends up being right-stochastic, and you can construct a function that requires this to not be the case.

They propose a simple fix for this to make the transformers universal function approximators. This amounts to multiplying the attention matrix by a learnable Toeplitz matrix (i.e., a convolution).

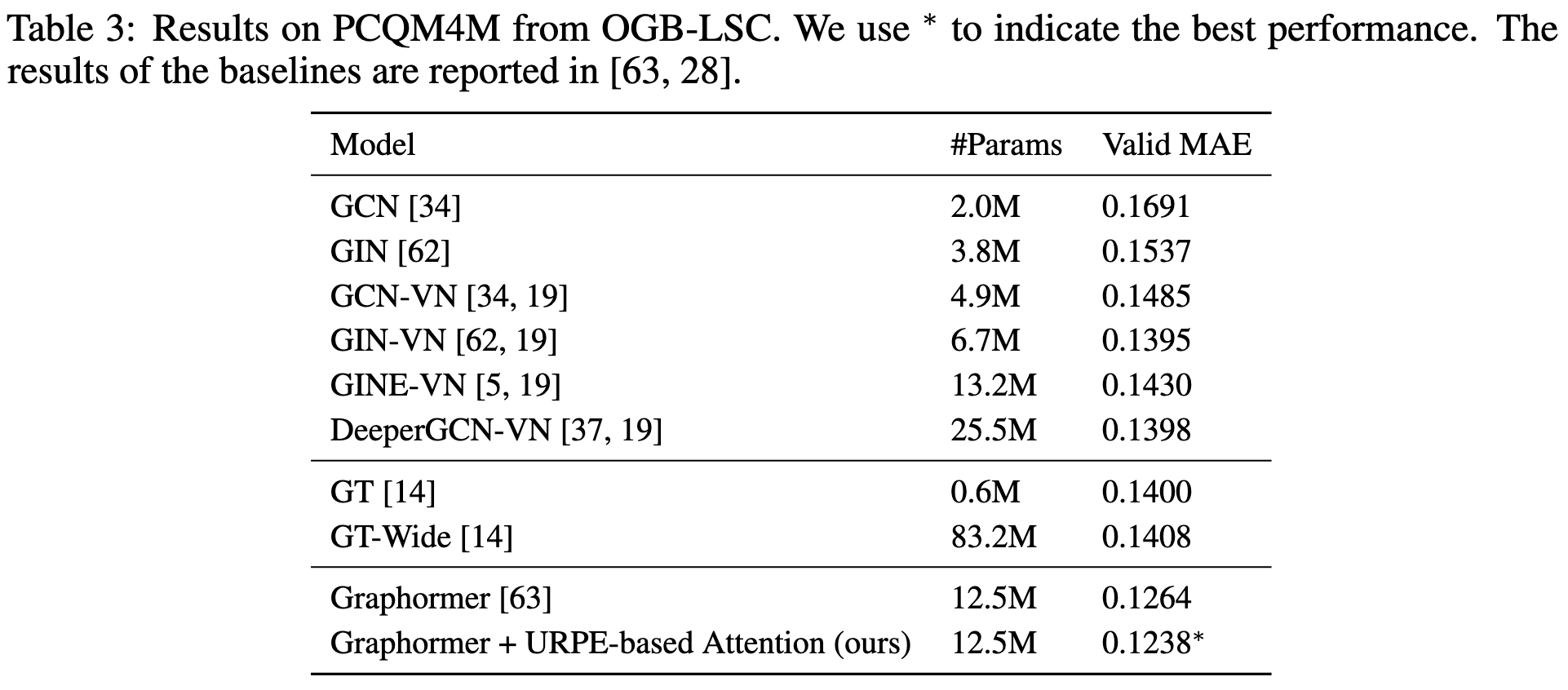
There’s some evidence that this addition can improve the quality-param count tradeoff:
Trainable Weight Averaging for Fast Convergence and Better Generalization
In stochastic weight averaging, we take a few snapshots of the model at different points near the end of training and then average them together. They propose to learn the coefficients instead of naively averaging.

Instead of directly optimizing the coefficients, they first construct an orthonormal basis that spans them all and then project the gradients onto this subspace. This ends up preconditioning using the subspace the weights are wandering around in.
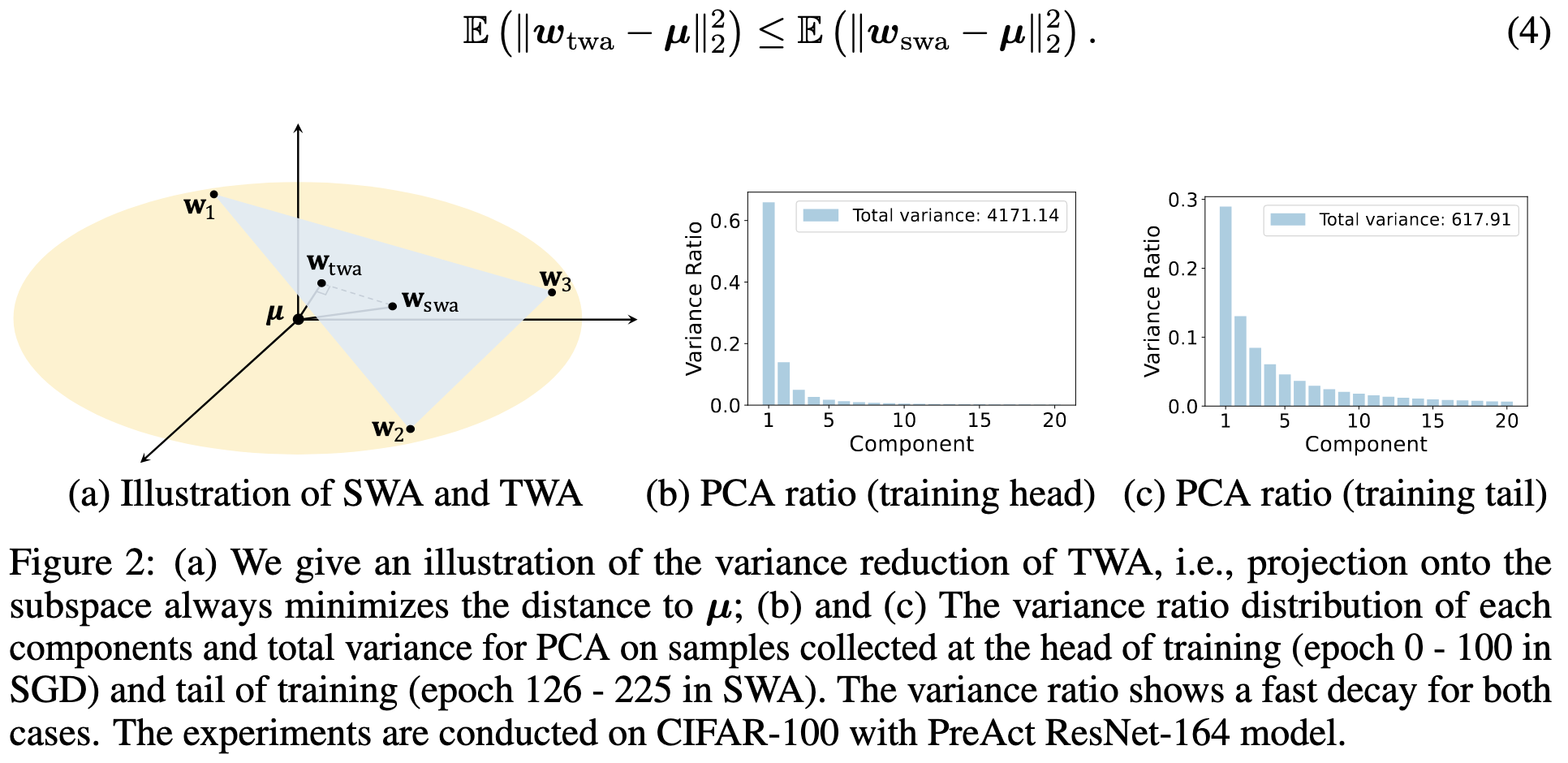
Small improvements over non-learned weight averaging, but found in carefully controlled experiments with identical initial models and code. The setup here is finetuning a pretrained torchvision model.

They report high absolute training speed improvements vs without any model averaging. What they’re doing here is using the accuracy lift that both SWA and their method yield to get away with training for less time. As we’ve seen in thousands of runs at MosaicML, shorter training with a correspondingly rescaled learning rate schedule is a ridiculously strong baseline for training speedup.

Selective Classification Via Neural Network Training Dynamics
Let’s say you want your model to reject inputs it’s likely to get wrong, rather than just handing you a bad answer. Current approaches to this impose restrictions on the model or loss function. What the authors propose to do instead is snapshot different versions of the model throughout training and check agreement between the different versions for a given test input. If the predictions are too inconsistent, reject the input. Often outperforms previous approaches for some selective classification benchmarks.


Fast Vision Transformers with HiLo Attention
Some of the attention heads are constrained to only look at small local windows (e.g., 2x2), while others use keys and values from a downsampled version of the input. This biases some heads to look at high-frequency information while others can only use low-frequency information.

They also propose a whole different family of architectures, that, among other changes, use 3x3 convs near the beginning instead of relative postition embeddings.

Beats Swin transformer by a decent margin in terms of {throughput, FLOPS, params}-accuracy tradeoff.



Inception Transformer
They got a better {FLOPS, params} vs accuracy tradeoff on ImageNet and various other computer vision tasks than some baselines, in exchange for having a custom block with various channel ratios that apparently “require rich experience” to set for a given task.


Towards Understanding Label Regularization for Fine-tuning Pre-trained Language Models
They find that distillation methods don’t have nearly as much of an advantage over simpler methods like label smoothing when fine-tuning a pretrained model. And in NLP, neither helps that much in absolute terms either—seemingly because of the more extensive pretraining.

Sparse Mixers: Combining MoE and Mixing to build a more efficient BERT
They added MoE to BERT but replaced the attention with alternate token mixing mechanisms. 1.65x training speedup at 0.7% higher average accuracy on SuperGLUE. Given that MoE usually yields a 3-5x or more speedup at iso accuracy, this is maybe a negative result for replacing attention with other mixing methods. Especially considering how many other design choices they introduced and tuned. That said, they did try just adding MoE to regular BERT and found that it diverged >75% of the time. So this is a positive result for mixing from a stability perspective.

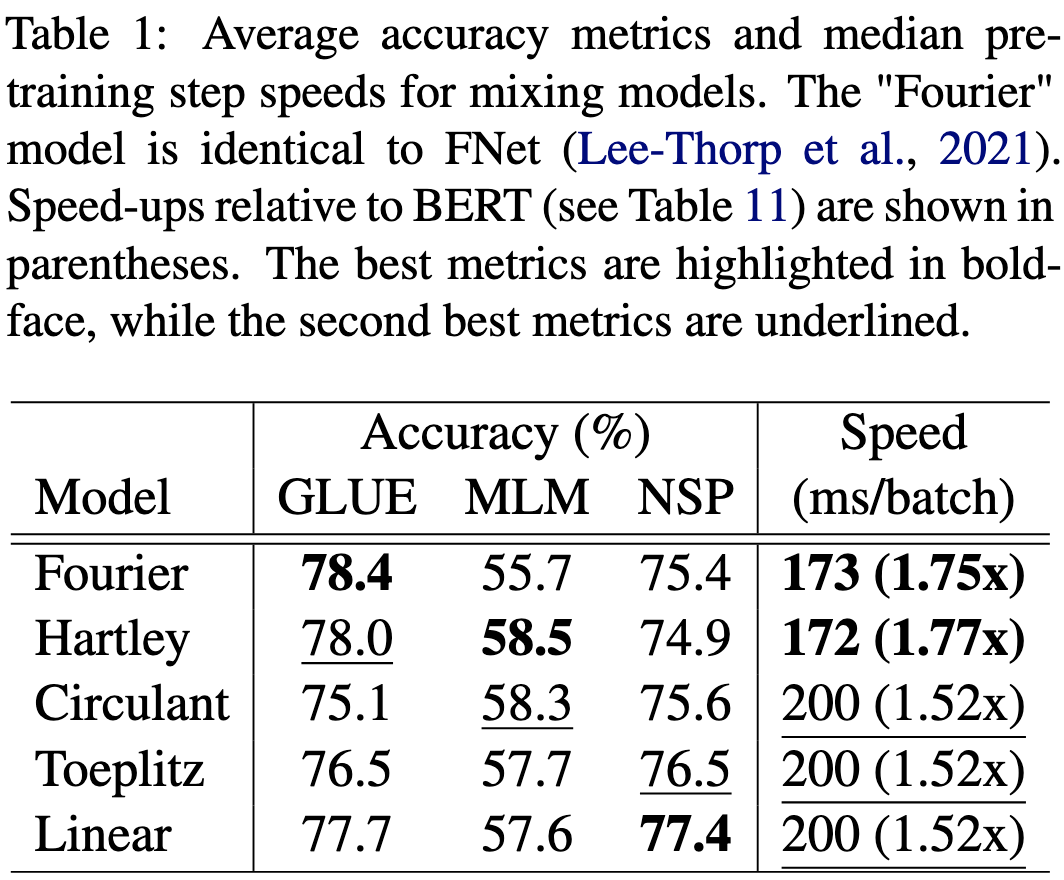
A *lot* of ablation experiments justifying the various design choices. E.g., they tried numerous approaches to mixing tokens:
Reproduced some claims in MoE papers. Top-k tokens for each expert, rather than top-k experts for each token, works better. And no returns to k>1 expert per token on average.

Training Language Models with Memory Augmentation
Good, organized thinking about three types of memory in sequence modeling; the memory can contain contents of 1) the same sequence, 2) the sequence’s whole surrounding document, or 3) an overall corpus (e.g., the whole training set).

One clever thing they do is construct batches of similar tokens by pulling sequences from the same document or from a retrieval system.
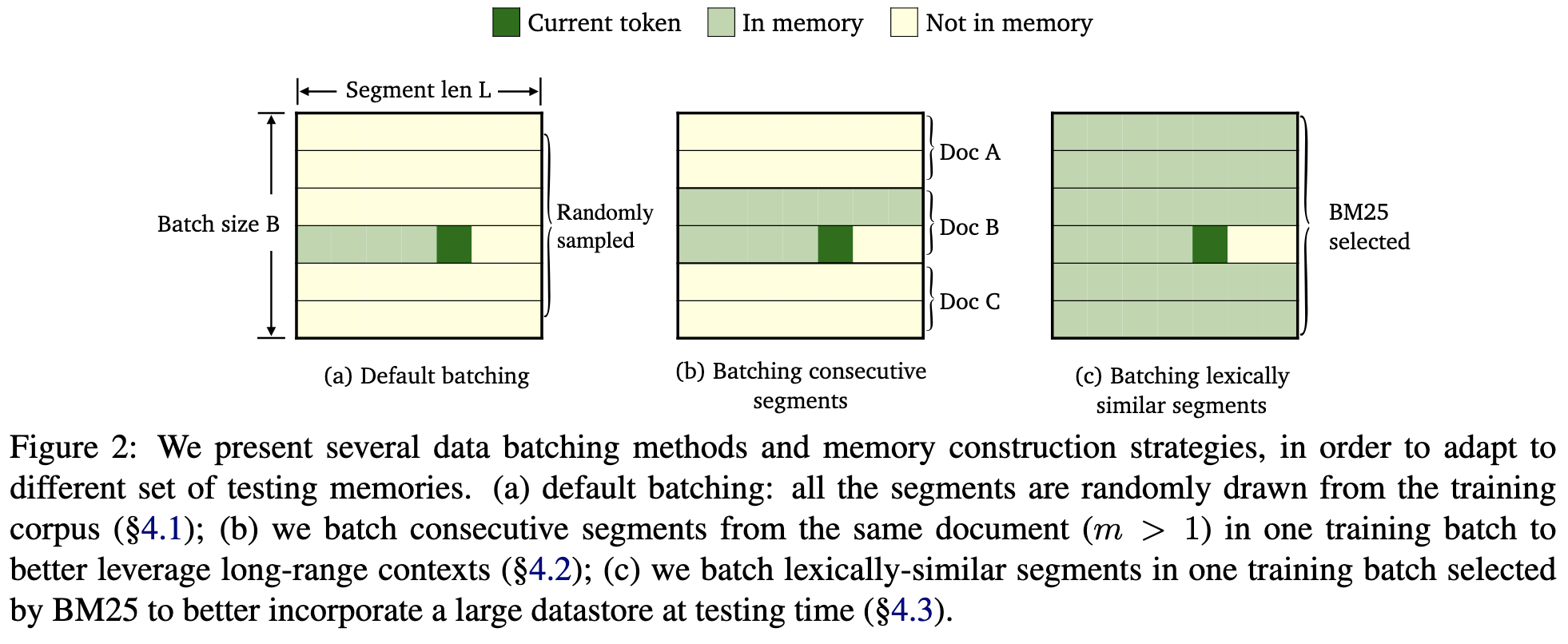
I have no idea how they avoid inference-time overhead but they claim they do. Maybe just a really high ratio of retrieval compute to GPU compute, allowing them to mask the retrieval latency (they use 32 cpu cores and only one 3090 GPU, and they might not even be using mixed precision).

They also claim to get a 1% lift from just using a different language modeling training objective, which requires the model to align the representations of the inputs to the final feedforward layers according to scaled dot product similarity.

Not sure what to make of this paper. They don’t compare to the memorizing transformer or RETRO, which have the best results I’ve seen so far for retrieval-augmented language modeling. And I’m not sure their lack of slowdown would scale to a more typical CPU to GPU compute ratio. But if their simple training objective change does reduce language modeling perplexity by ~1, that would be a nice and actionable win.
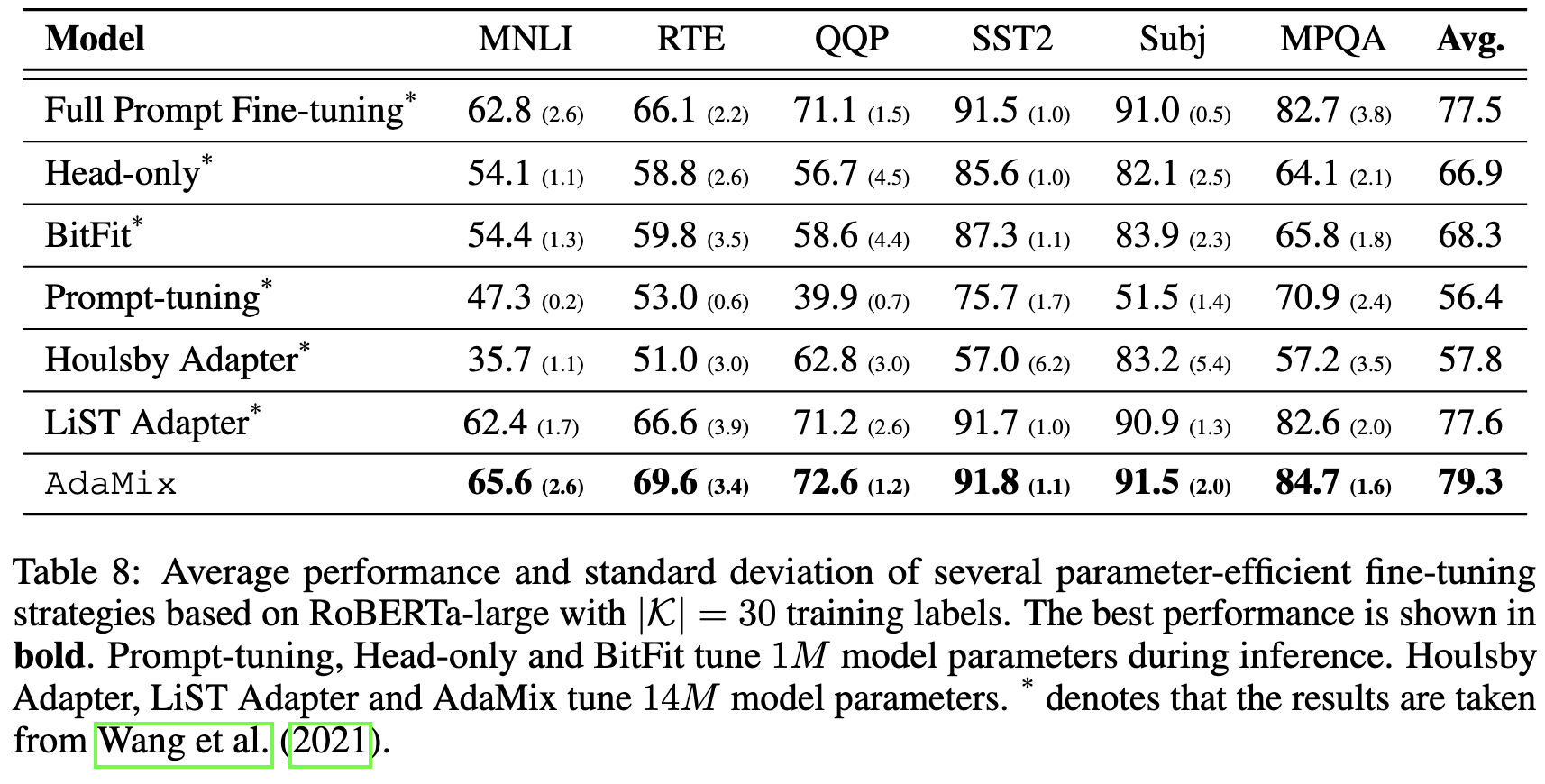
AdaMix: Mixture-of-Adapter for Parameter-efficient Tuning of Large Language Models
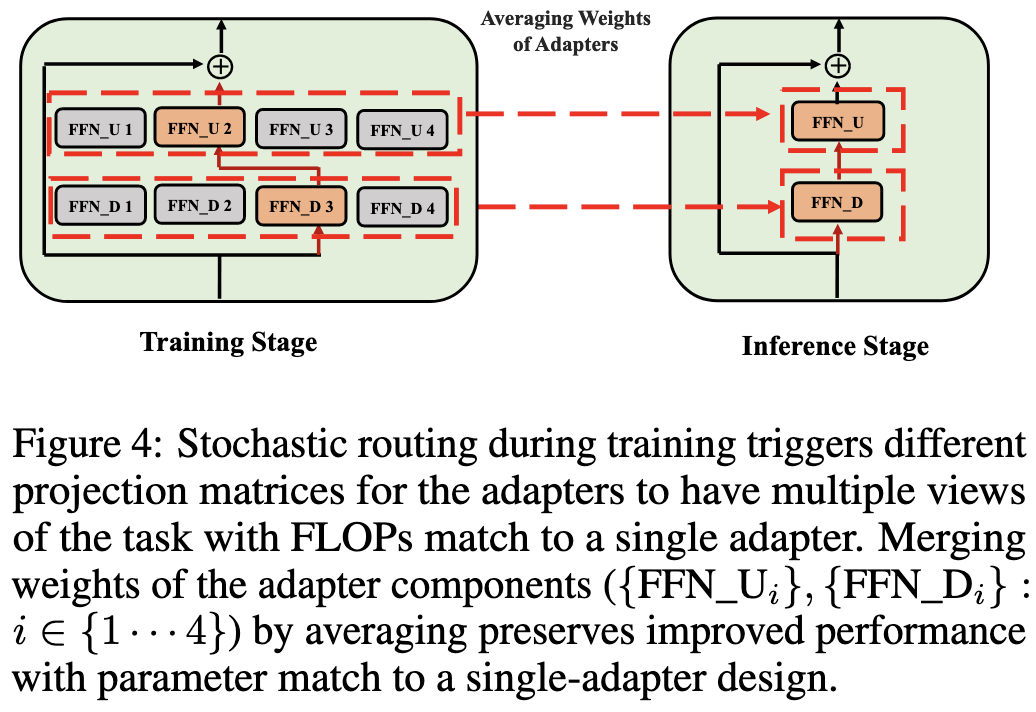
They add small MoE FFN “adapter” networks into each transformer block. But instead of attempting to route intelligently, they do random routing during training, and then average all the experts in a given adapter layer before test time. They also add a consistency loss to try to get different experts to be average-able. This looks to me like they’re just using MoE as a regularization method, rather than as a model capacity increase. They have some ablations showing they beat other MoE approaches, but the approaches considered are just {only using the first expert, keeping random routing but not averaging}, neither of which are what would do if trying to get MoE to work here. I’m not quite convinced this is what we should be using to fine-tune our models, but it is interesting that MoE-as-a-regularization scheme does something useful. Makes we wonder about whether this is specific to fine-tuning, in which you have less data, or if MoE-as-regularization would also help for pretraining.


DNNAbacus: Toward Accurate Computational Cost Prediction for Deep Neural Networks
They design features and train a model to predict training runtime and memory consumption on a single-GPU system. Gets within 10% on networks it hasn’t seen before and 2% for networks it has seen before. One non-obvious aspect is that their feature construction involves pairs of successive ops, rather than looking at each op in isolation.

Constrained Monotonic Neural Networks
If you want your model’s outputs to be monotonic functions of the inputs, run each scalar through two copies of your activation function, with the second one negated and fed a negated input. You also need to take the something resembling the absolute values of your weights.


Semi-Parametric Deep Neural Networks in Linear Time and Memory
They train a neural net to compress their dataset down to a fixed size and use the full attention mechanism to attend to the whole fixed-size dataset, rather than a retrieved subset. People have been working on dataset compression for decades so I’m not sure what to make of this specific approach; seems to be designed for genomics tasks in particular.

BabyBear: Cheap inference triage for expensive language models
Negative result showing that early exit at inference time for some NLP tasks has a large accuracy cost. The early exit model is an XGBoost classifier seemingly distilled from the large model’s predictions. I’m curious how approaches that reuse early layers of the full model could do, though, since they can have much lower overhead.


Informed Pre-Training on Prior Knowledge
They construct platonic ideal examples for MNIST and similar datasets, pretrain on these to zero training error, and then fine-tune on the real data. On MNIST and similar datasets, this leads to faster convergence and higher accuracy.

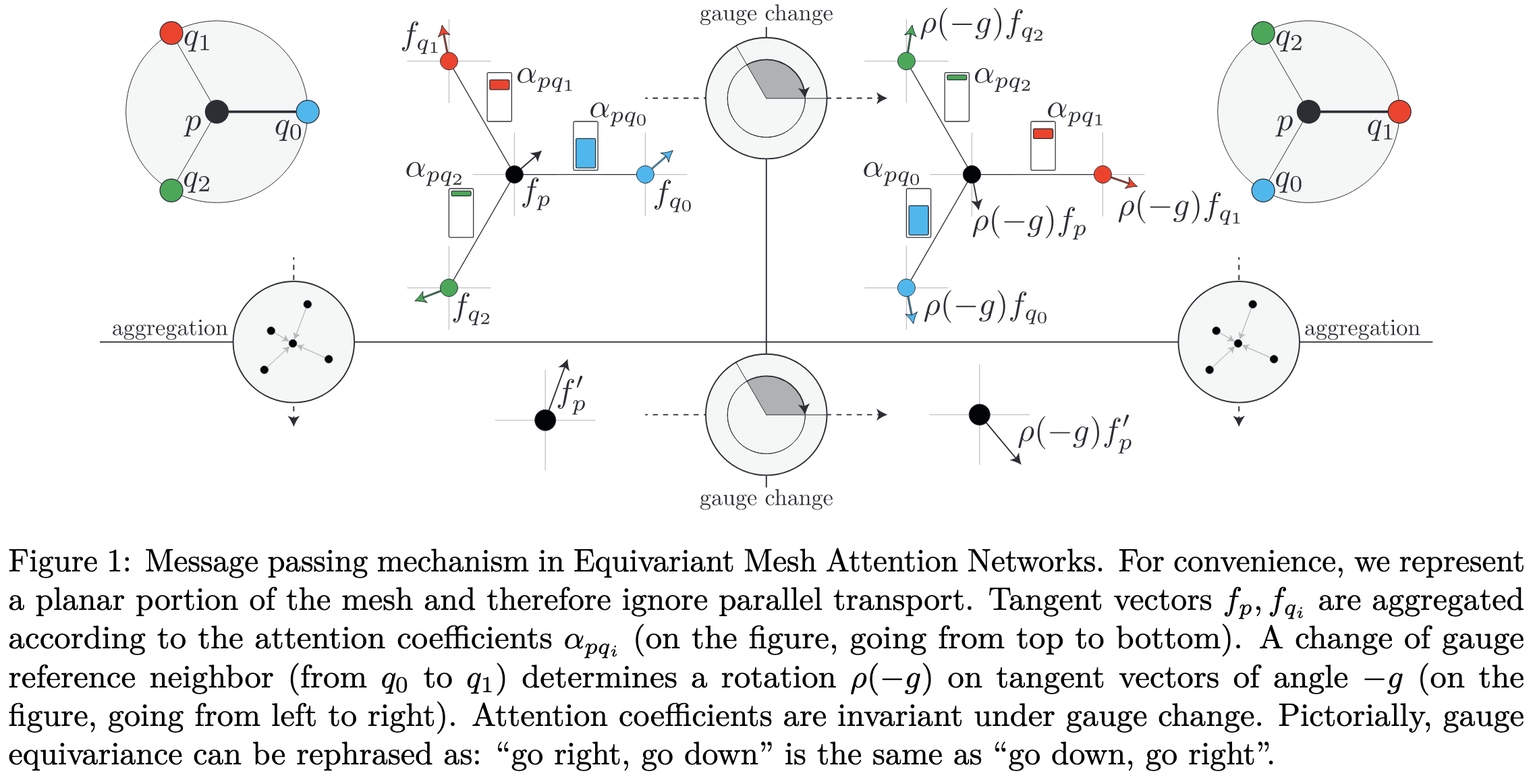
Equivariant Mesh Attention Networks
A new and interesting chapter in Taco Cohen’s never-ending quest to make neural nets equivariant to All of the Things. They consider learning from meshes, which means sets of (nodes, edges, faces) and manage to gain provable equivariance to “translations, rotations, scaling, node permutations, and gauge transformations,” which is really impressive. Will take you a lot of staring at the math to really understand it though.
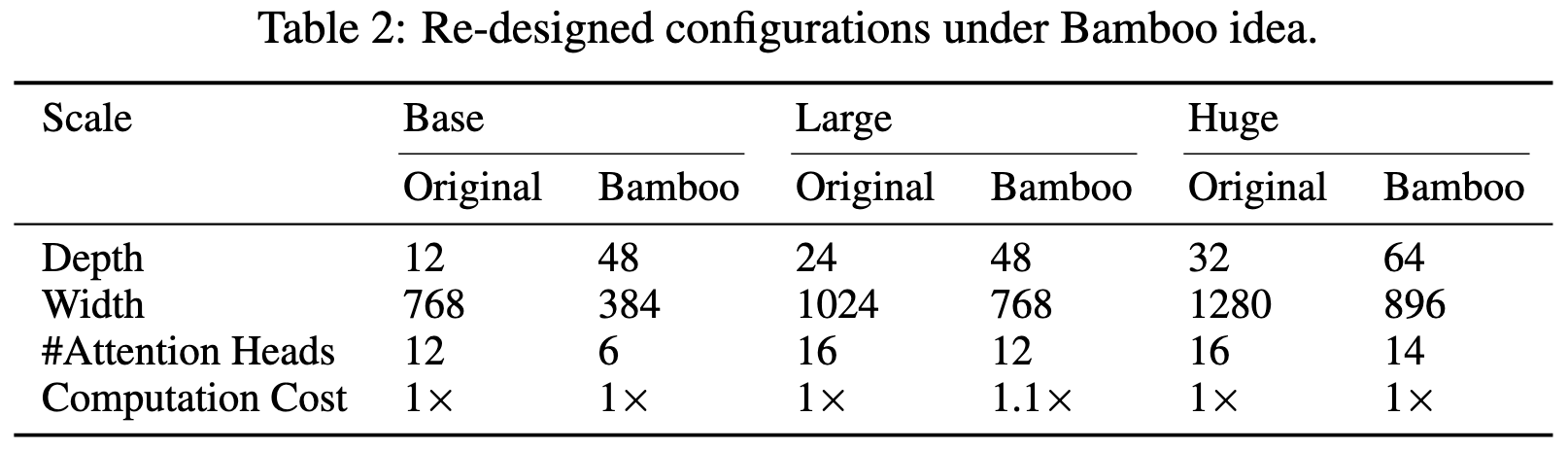
Deeper vs Wider: A Revisit of Transformer Configuration
For ImageNet pretraining with a masked autoencoding objective, making networks much narrower and deeper improves accuracy. They seem to have done a good job of holding everything else constant so I’m inclined to believe this finding is real.

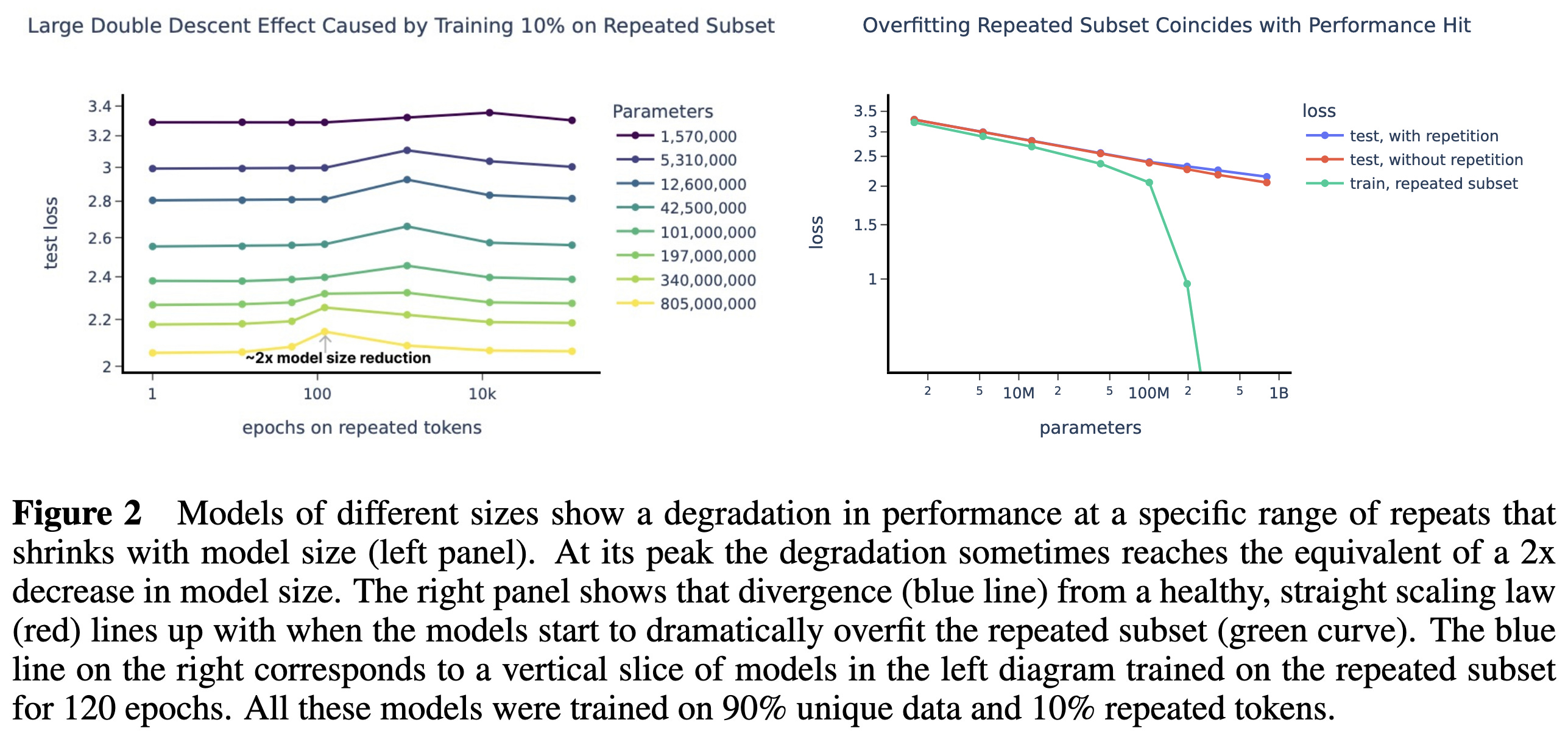
Scaling Laws and Interpretability of Learning from Repeated Data
Repeating even a small fraction of the training corpus can significantly degrade a language model’s accuracy. It seems to especially ruin its ability to copy text, and to some extent generalize OOD.

This large impact might be a product of memorization enabling 0 loss on the repeated subset. Getting to 0 loss is a huge gain compared to the slight perplexity drops attainable on most text, and therefore a strong incentive for the model to spend its capacity memorizing the repeated part. This explanation is consistent with the double-descent phenomenon they observe, where a model devotes much of its capacity to memorizing only when the repeated subset is just large enough to be difficult to learn all of, but small enough that memorizing it is still possible.

CNNs are Myopic
“CNNs learn to classify images using only small seemingly unrecognizable tiles. We show experimentally that CNNs trained only using such tiles can match or even surpass the performance of CNNs trained on full images.” They also put forth some theoretical results suggesting that CNNs effectively just being tile classifiers combats the curse of dimensionality and might partly explain why they generalize despite having many parameters.


Pre-Train Your Loss: Easy Bayesian Transfer Learning with Informative Priors
They fit a low-rank gaussian distribution to the parameters of their pretrained model in a few epochs of extra training, fine-tune on a downstream task, sample a few models from the resulting posterior, bayesian-model-average the sampled models, and use the result for test-time prediction. Seems to kind of do better than normal fine-tuning, in exchange for a significantly more complex pipeline.

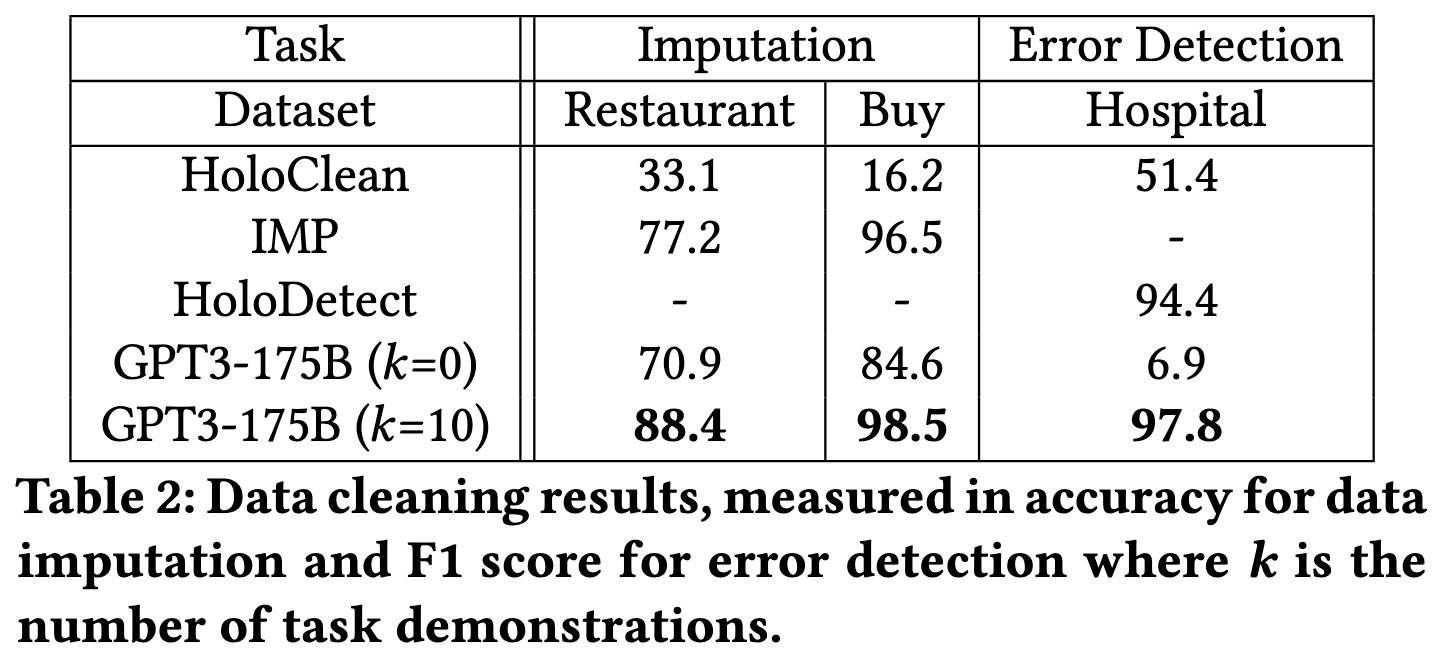
Can Foundation Models Wrangle Your Data?
Asking giant language models to detect errors in your rows, resolve whether entities are the same, or impute missing values turns out to work pretty well.



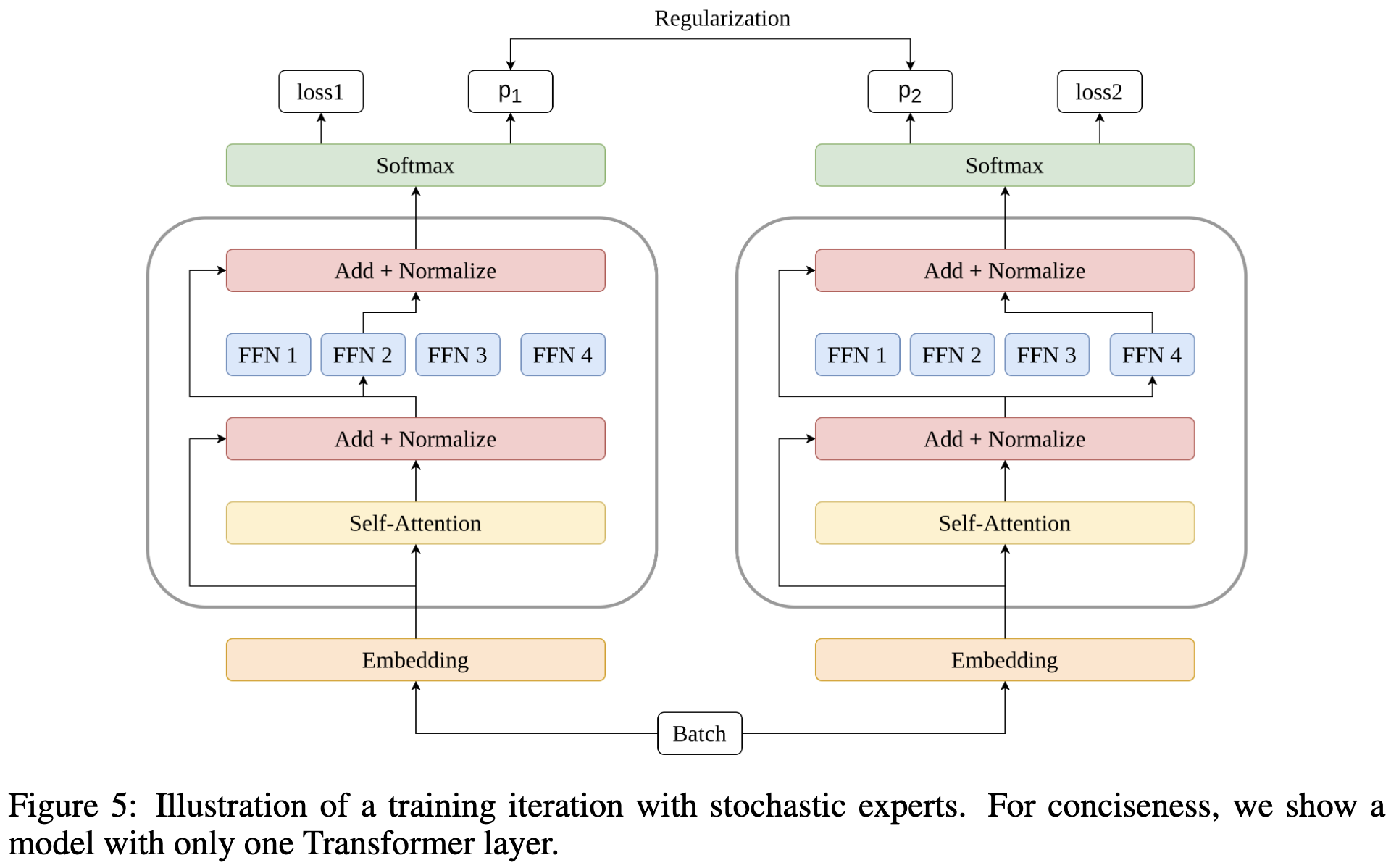
Taming Sparsely Activated Transformer with Stochastic Experts
This is a paper where I’m tempted to say that it’s obviously a bad idea, except that it actually seems to work (which is interesting!). Basically they just have random routing at train and test time for their MoE modules, along with a consistency loss that sort of looks like self-distillation across a stochastic ensemble if you squint. I can see how this would be an effective form of regularization, but it’s surprising that regularization can yield the accuracy gains they report, especially with the MoE capacity going to waste (by being driven towards computing a constant function across all experts).
Transformer with Memory Replay
An ELECTRA variation in which the generator is trained separately from the discriminator. The generator’s output is stored in a buffer from which the discriminator samples. Each sample in the buffer has a trained weight, and the lowest-weight samples get replaced at each time step. Apparently yields a small accuracy lift vs ELECTRA at iso time and steps. The reason it’s possible to train the generator and discriminator separately is that the former is just being trained on masked language modeling and the latter is being trained on corruption detection—so the gradients don’t actually need to flow between them.


Tracing Knowledge in Language Models Back to the Training Data
They created a dataset with ground truth for attributing model predictions to specific samples. Turns out gradient-based and embedding-based attribution methods fail to outperform BM25, which just retrieves similar samples without even looking at the language model in question.

