
2022-6-5 arXiv roundup: SAM for free, FlashAttention, Supervised MAE

This newsletter made possible by MosaicML. Relatedly, do you have any friends who are {ML, cloud, platform} engineers and who might be open to a new job? If so, if would be great if you could send them our careers page or reply to this email with any names that come to mind. We’re an awesome place to work, growing fast, tackling a huge problem, and packed with people who are exceptional even by MIT standards (IMHO).
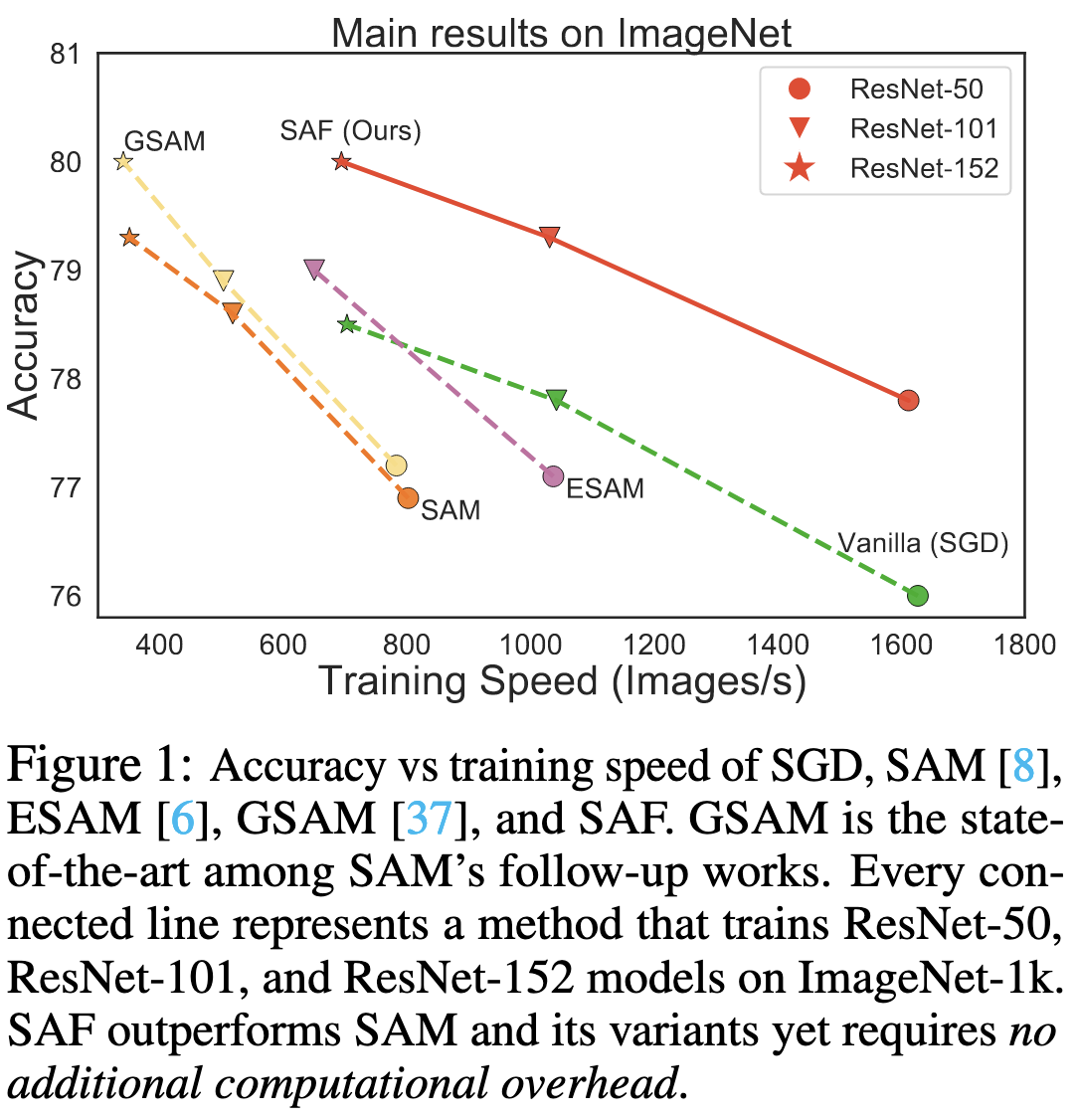
⭐ Sharpness-Aware Training for Free
They propose a sharpness-based loss that requires almost no overhead, unlike other SAM variants.
To compute this loss, they store the predicted class probabilities for each sample across epochs and penalize the KL divergence between the old and new distributions.

This requires storage linear in the dataset size times number of epochs of history to keep, but this isn’t too bad, even for ImageNet. It might pose a problem for language models and segmentation tasks though, so they also propose a variant (MESA) that avoids this overhead.

This variant just stores an exponential moving average of the weights and does an extra forward pass to get the reference distribution used in the KL divergence computation.
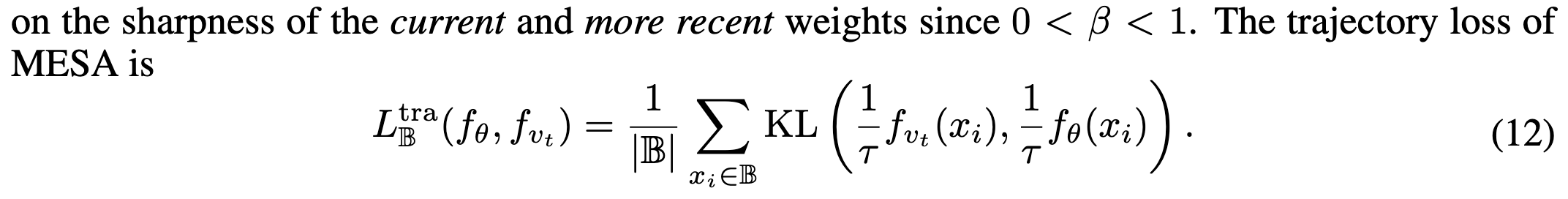
Either way, the algorithm is pretty simple:

Works well in practice under the same hparams as baselines, and they even verify that it’s actually reducing sharpness, as measured using the SAM objective.


Seems like a practical training change that could see widespread usage.
⭐ FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
Good CUDA-level optimizations to make attention run far faster, completely avoiding materializing the full attention matrix. This is only about a 15% speedup on BERT, but a 3x speedup on GPT-2 (a decoder model that has to mask everything).

They also propose a block-sparse variant that does really well on long-range arena.

Overall this is great stuff; I omitted most of them, but it’s just table after table of crushing existing alternatives. And they’re currently winning MLPerf BERT training, which is really hard to do.
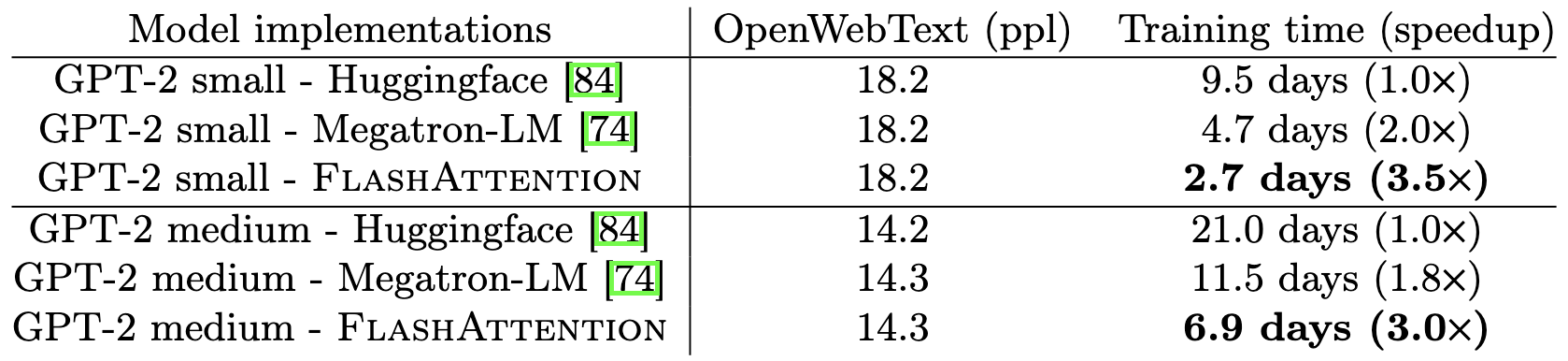
This also goes to show the power of pure systems research; there’s an endless stream of alternative attention papers that change the semantics but still get less speedup and accuracy than this.
Fast Benchmarking of Accuracy vs. Training Time with Cyclic Learning Rates
Jacob Portes’s intern project at MosaicML. This solves a problem that almost every ML “efficiency” paper has but no one talks about. The problem is that, to compare the efficiency of two methods, you can’t just spit out one number—you have a train a bunch of different models to characterize the tradeoff between accuracy and speed.
And if you don’t characterize the whole tradeoff curve, you can get misleading results (c.f. Figure 7 of our pruning meta-analysis, below; which method seems best can depend on where in the curve you look):

But what if you could just train one copy of the network instead of one copy per point in the curve? Well, it turns out that, with a certain form of cyclic learning rate, you can.

Namely, if you use a cyclic cosine decay with exponentially increasing period, the accuracy at the end of each cycle is almost as good as if you’d just trained a model with a single warmup + cosine decay curve for the same amount of time.

Doing one run means linear rather than quadratic complexity wrt the number of points in your curve, and this translates to a lot of compute savings even with just a handful of points:

tl;dr if you want to claim some method is “better”, and it changes both the speed and accuracy, using an exponential-period cyclic learning rate schedule can let you characterize its speed vs accuracy tradeoff in a single training run.
⭐ SupMAE: Supervised Masked Autoencoders Are Efficient Vision Learners
They start with a masked autoencoder, but add a classifier on top of the average-pooled latent representation. So they jointly train to reconstruct and classify.

Takes 40% longer than other supervised pretraining methods for 1.3% higher ImageNet accuracy, which is a pretty good tradeoff.

And it does much better than unsupervised pretraining:

They have a big wall of ablation experiments that I really like. I wish way more papers did this rather than sprawling their results across multiple pages. Among other results, they find that using both the supervised and reconstruction objectives helps, as does scaling down the classification loss by 100x (!) relative to the reconstruction loss.

Feels a lot like the lesson of NLP From Scratch, reproduced and extended for a vision task. Also, since their decoder is pretty lightweight, this suggests that one might be able to add on a reconstruction objective to a vision model during training as a general-purpose accuracy lift.
DepthShrinker: A New Compression Paradigm Towards Boosting Real-Hardware Efficiency of Compact Neural Networks
Adds a differentiable mask for activation functions to learn which ones are important; has a search procedure for which masks to keep; distills from the original model; expands individual convs into inverted bottlenecks; and eventually merges inverted bottlenecks into individual convs.

Pretty MobileNet-family specific, but does seem to improve on vanilla MobileNets. Only compares to a handful of old channel pruning methods, though, so unclear how to think about these results.

One interesting idea they have is expanding the model capacity at the start, even if you know you’ll shrink it later—i.e., not just starting with a large model, but making a small model bigger. Not clear whether this helps, but an interesting and general idea.
Global Convergence of Over-parameterized Deep Equilibrium Models
Let’s say you have a deep equilibrium (DEQ) model with a quadratic loss and layers that are all linear ops with no bias plus a linear function of the network’s input. And further suppose some conditions on some smallest eigenvalues at initialization, the learning rate, and the degree of overparameterization. Then the equilibrium point always exists and your DEQ model converges linearly to a global minimum.

This is cool because DEQs have a lot of promise for decreasing memory and communication during training, but don’t necessarily have equilibria. And if there’s no equilibrium—well, long story short, it ruins everything. So work showing that the equilibria always exist under certain conditions suggests that we might be able to make DEQs reliable enough to use routinely.
AANG: Automating Auxiliary Learning
They point out that a lot of the pretraining / auxiliary objectives we use are just taken ad-hoc from some space of possibilities (see fig). They propose to explore this space programmatically.

They also point out that 1) you don’t have to make a hard selection, and can instead train on a combination of multiple objectives, and 2) you can change the weightings throughout training.

Their method manages to outperform reasonable baselines, often by a lot, both with and without external data.


Any sort of online search procedure is going to have many degrees of freedom, but as the authors put it, this is at least “a promising first step in automating auxiliary learning”. It also makes we wonder how many other neural net design choices should be approached in this way but haven’t been yet.
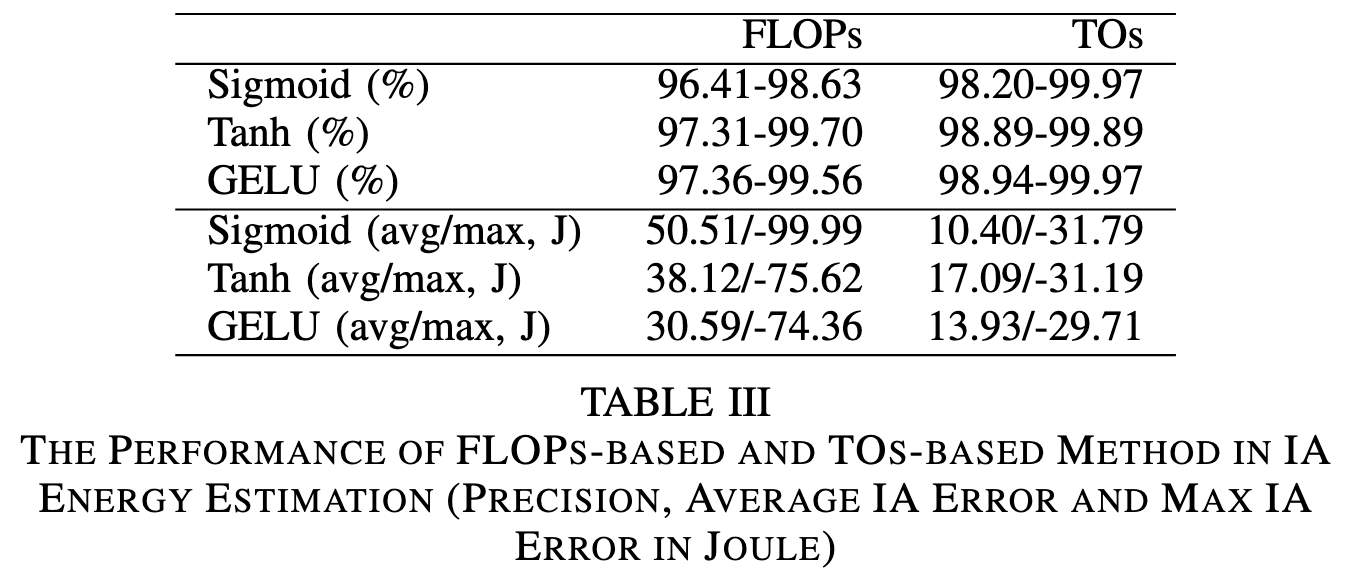
A Transistor Operations Model for Deep Learning Energy Consumption Scaling
Not all FLOPs are created equal. If you want to predict the power consumption of your CPU or GPU, you should weight operations by how many transistors it takes in the ALU to perform that operation.

Works really well on their CPU, at the cost of not predicting the (large!) power consumption of data movement at all.

As an example of different operations taking different amounts of work, consider the different steps involved in multiplying two floating point numbers:

Of course, the exact number of transistors used will vary based on the adder or multiplier design, as well as the instruction set, but you can get a pretty good estimate for a fixed ISA.
The experiments are a little limited in this paper, but it reinforces something I’ve come to believe more and more strongly over time: deep learning is not alchemy. There may be a layer of alchemy on top that influences accuracy on a given task (looking at you, hparam tuning); but 1) in terms of runtime, we’re performing computations that are grounded in well-understood systems, and 2) given enough data and decent hparams, runtime seems to be almost all you need.
Your Contrastive Learning Is Secretly Doing Stochastic Neighbor Embedding
Self-supervised contrastive learning is basically just SNE, with the similarity matrix dictated by which pairs count as positive vs negative. But it’s a weird matrix because it’s kind of all-or-nothing. If you make SimCLR like t-SNE by using the t distribution with t=1 for the implicit probabilities instead of a Gaussian distribution, it works better.

Gating Dropout: Communication-efficient Regularization for Sparsely Activated Transformers
When using expert parallelism in an MoE model, just route to local experts instead of assigned (usually remote) experts with probability p. They also skip the MoE block entirely sometimes as a form of layer dropping.

What’s surprising about this is that it also increases accuracy in their experiments. Suggests that MoE models tend to be under-regularized.
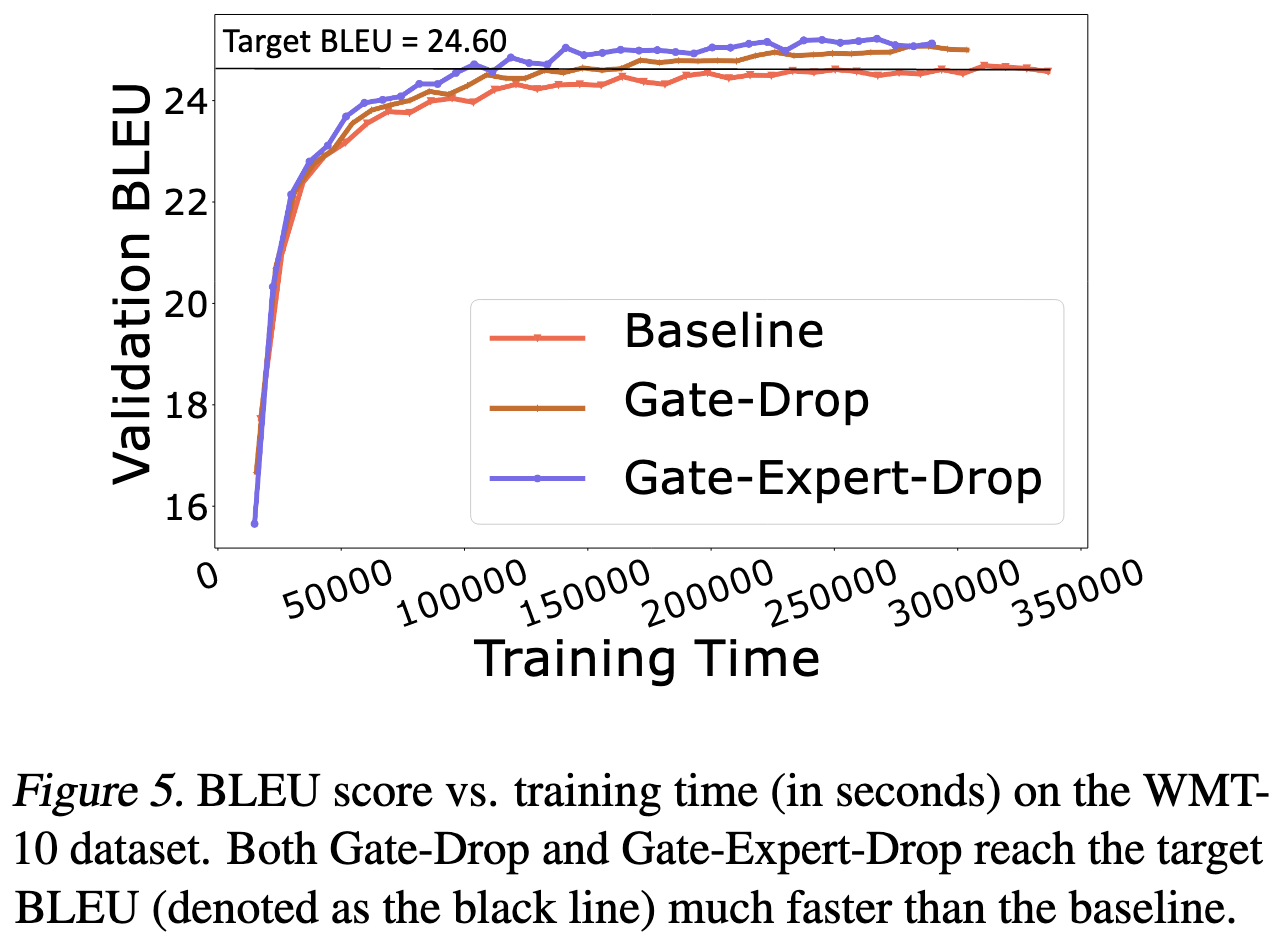
This accuracy improvement holds even when measuring in steps rather than time, which is even stronger evidence for the efficacy of the regularization.

It’s not a huge throughput lift though, even when they only have 100Gbe connections between their V100s.

Also has some hparam sensitivity. You have to make sure you skip the all-to-all communication with the right probability.

And you need to choose whether to add in layer dropping or not; it helped on one dataset but not on another.

But on the whole, seems like a Pareto improvement for the speed-accuracy frontier if tuned reasonably well. And definitely a little surprising that it helps accuracy. I wonder if this is a product of nondeterminism in the test-time routing of a given sample; suggests that it helps to shrink the experts towards one another (which is the effect of feeding them the same random input distribution as done here).
Can Foundation Models Help Us Achieve Perfect Secrecy?
What if pretrained models got so good that we could just have them answer queries on the client’s device without ever training on or transmitting the client’s data?
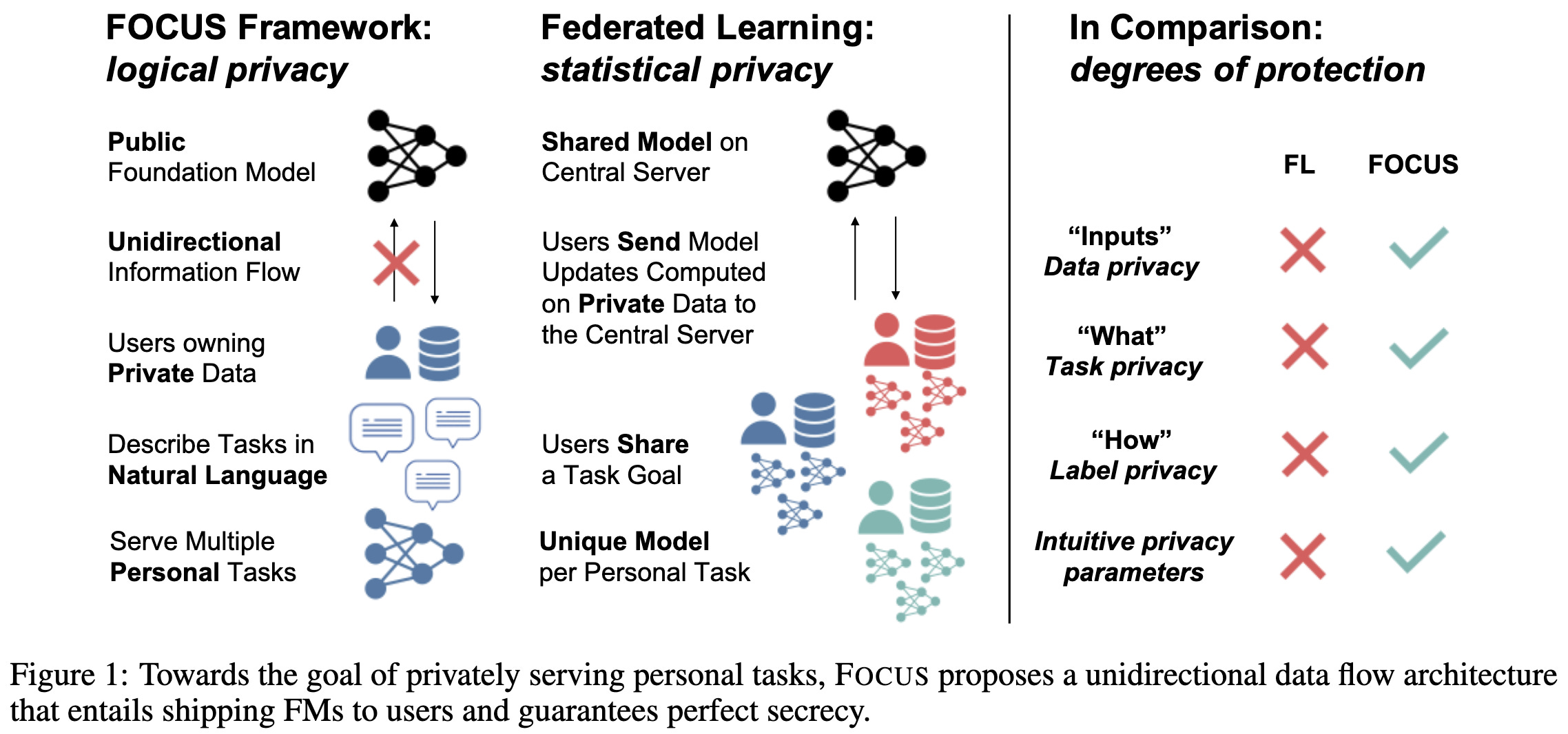
Well, with the right prompts, turns out you can do this. And in fact, it can do better than federated learning in some cases, despite the much stronger privacy guarantees.
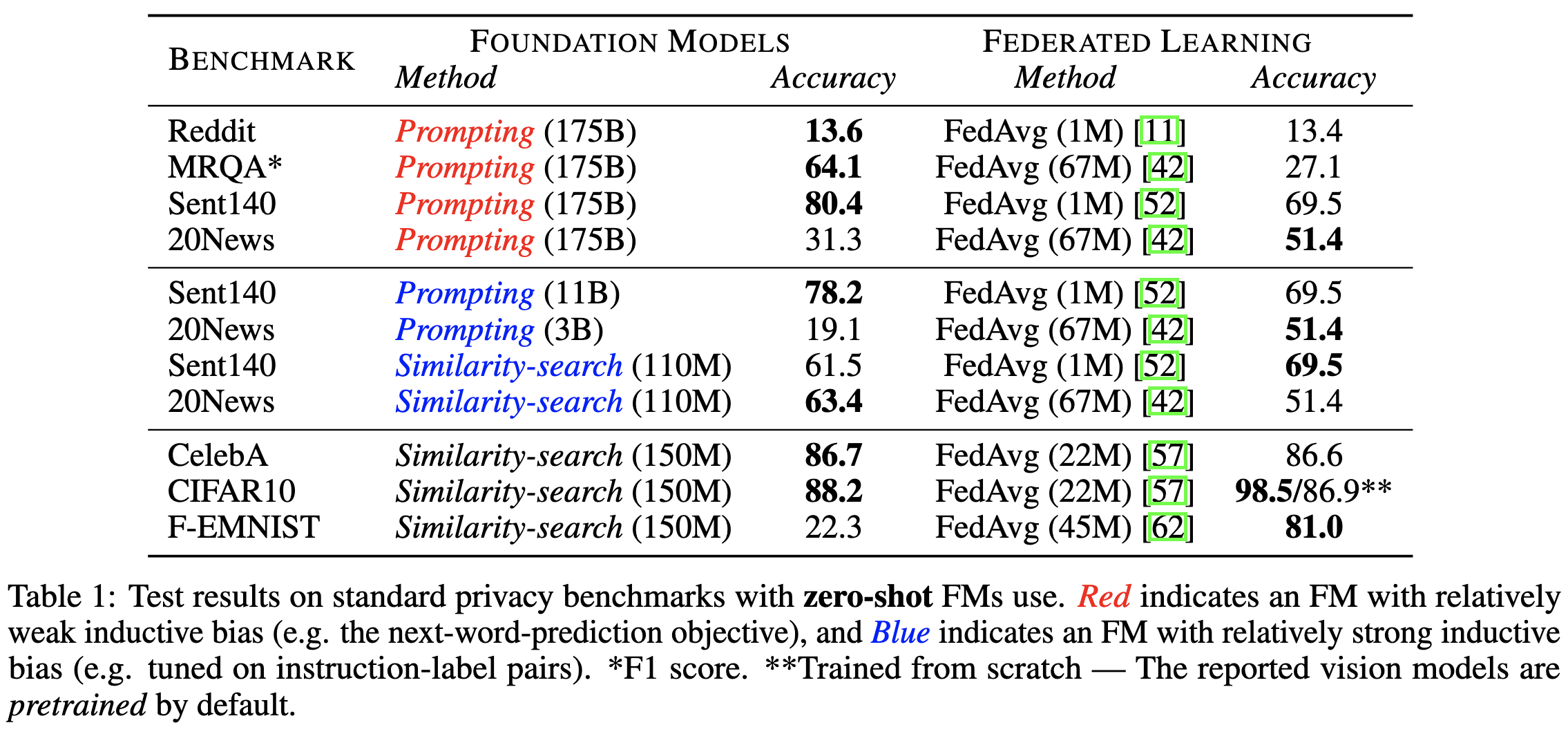
Of course, the pretrained model might be really large, requiring both a big download and slow on-device inference. But this still might be less communication and computation than performing federated learning, depending on the number of inferences over which you amortize the federated training.

As the authors point out, this is “only a proof of concept.” But it suggests to me that this is a really promising direction for private ML. We already knew that fine-tuning a pretrained model was often the most practical approach to federated learning, but these results suggest that we might be able to omit the federated learning entirely in some cases. This would allow both huge software simplification and much stronger privacy guarantees.
Tensor Program Optimization with Probabilistic Programs
A domain-specific language for optimizing tensor ops by the OctoML/TVM team. Existing tools like TVM, TACO, Halide, etc, are deterministic, and you have to hack some sort of exploration/autotuning on top of them. Their langauge, MetaSchedule, allows you to just specify the degrees of freedom and your prior knowledge directly.


MetaSchedule optimizes many individual operations better than both TVM and PyTorch for single-sample inference. The one where PyTorch is way better is softmax.


It does about the same as TVM for end-to-end network inference latency though.

This seems like, in some sense, the “right” approach. Ideally, I should be able to specify what it is that I already know about my program, what degrees of freedom are likely to be helpful, etc. But making a tool like this mature is hard, so I’m excited to see where it goes.
X-ViT: High Performance Linear Vision Transformer without Softmax
They remove the softmax in the self-attention, which allows you to change the order of operations and get a linear attention mechanism. They also add in L2 normalization of the query and attention vectors for each pixel.

As is standard for recent ViT variants, it beats the Swin transformer by about 1% ImageNet accuracy holding some mix of param and FLOP count constant.

They also have higher GPU throughput than the Swin transformer, although note that this plot shows resolution vs speed rather than accuracy vs speed.

Transformer with Fourier Integral Attentions
They propose a self-attention variant based on Fourier transforms. Seems to lift accuracy, although unclear how it affects any measure of runtime. They wrote a CUDA kernel for it but don’t profile this kernel.

Fair Comparison between Efficient Attentions
They benchmarked some “efficient” attention variants on ImageNet in a standardized setup. The efficient attention mechanisms have fewer FLOPs, but are also less accurate.

Their evaluation uses a new architecture, so this is kind of suggests that these methods are overfit to the exact benchmarks used in their development.

Task-Specific Expert Pruning for Sparse Mixture-of-Experts
For a given downstream task, they gradually prune experts until only one remains in a given MoE module. They score experts using the sum of their gating weights across all tokens within each fine-tuning period. At the end of the period, they remove experts with below-average scores.

Seems to retain almost all of the accuracy of the original MoE model with no expert dropping, sometimes even improving accuracy:


Pleasantly surprising that this seems to work so well, and reinforces my belief that MoE modules are poorly utilized. But most of all, I really hope this doesn’t inspire 100 meaningless papers proposing “expert pruning” heuristics.
Learning Instance-Specific Data Augmentations
They train a model to spit out a distribution over augmentations given an input image. They train this model end-to-end with the main model using the reparameterization trick.
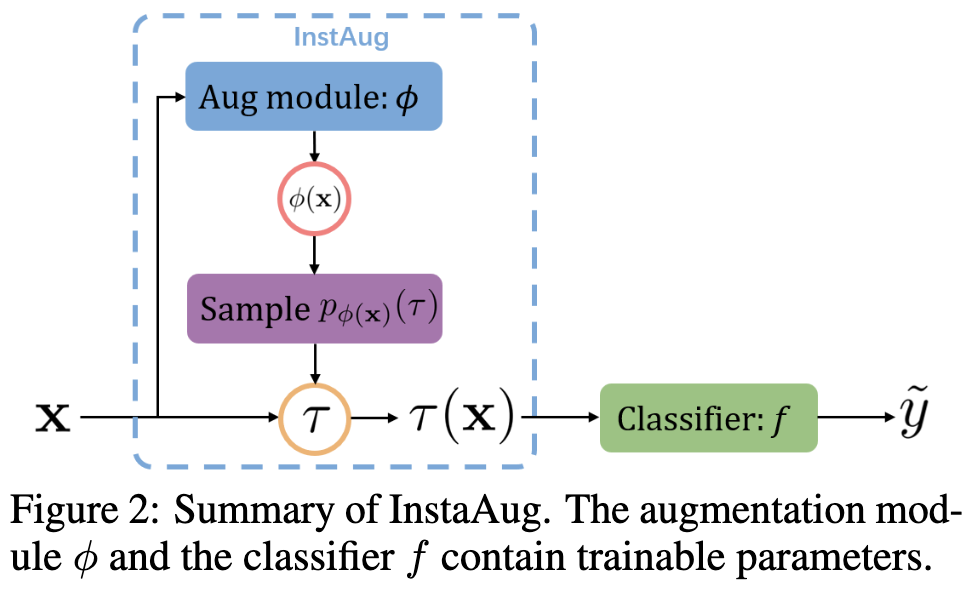
There’s also an extra penalty for each transform (e.g., color jitter) in the overall the augmentation to try to keep the entropy of the transform’s distribution in an hparam-defined range.

The trickiest part of this is figuring out how to sample patches—for cropping, cutmix, etc. They do this by having a CNN in their model that progressively downsamples by a factor of 2, and treating its output at each position as an unnormalized log probability of being sampled. The positions in lower-resolution feature maps correspond to larger patches in the input.

Seems to improve accuracy on Tiny ImageNet classification and other tasks.

WaveMix-Lite: A Resource-efficient Neural Network for Image Analysis
They add discrete wavelet transforms to their custom CNN.

The overall CNN does a lot better than ResNets on 64x64 ImageNet with no data augmentation. But none of these numbers are near what you’d get from just having a normal data loading pipeline, so unclear what to make of them.

The most interesting ablation they did was replacing the DWT operations with 2d maxpooling, which also does a 2x spatial downsampling. The result was a 5% accuracy loss, suggesting that a larger receptive field (and possibly the specific inductive bias of wavelets) helps quite a bit.
Object-wise Masked Autoencoders for Fast Pre-training
Instead of feeding their masked autoencoder all the patches for an image, they only feed it patches corresponding to one object.

They determine these patches using either labels (for COCO) or Class Activation Mapping with a pretrained ResNet-50 (for image classification datasets)—so it’s not unsupervised anymore. It also doesn’t work as well for downstream tasks even with high-quality COCO object annotations, and even when holding the total fraction of patches used during pretraining constant.

But it’s an interesting idea; I feel like intelligent patch selection / curriculum learning could become a thing.