
2022-6-19 arXiv roundup: RHO-LOSS, Pix2Seq v2, Fisher SAM

This post made possible by MosaicML.
Measuring the Carbon Intensity of AI in Cloud Instances
Different training jobs can have hugely different carbon impacts. Choosing where and at what times you run your training can make over a 2x difference.

If possible, train your model in France or Norway. In the US, train it in the pacific northwest.

Also try to train your model at off-peak times like late at night. Delaying when a job gets scheduled by <24h can yield up to 80% CO2 reduction.
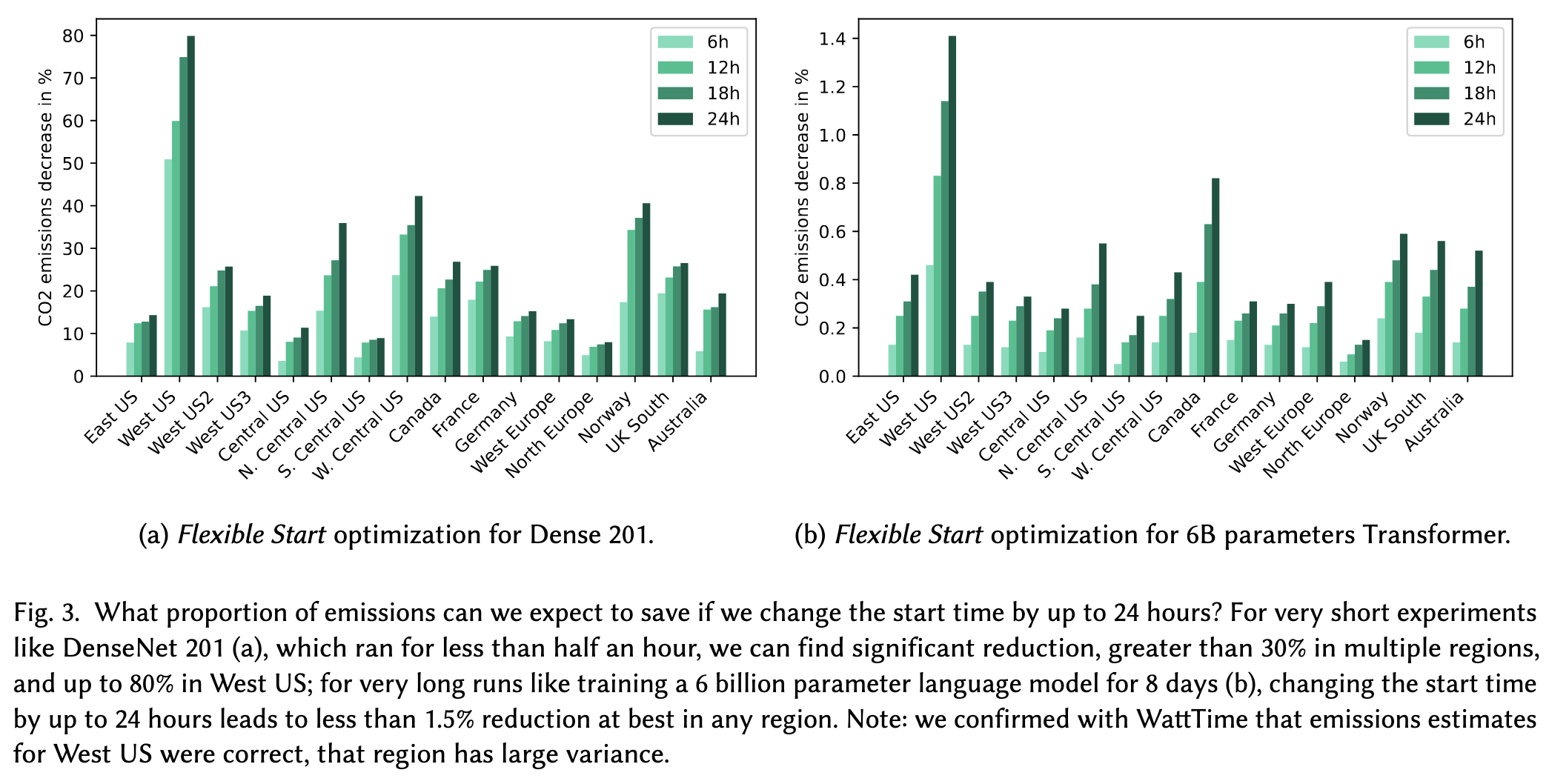
Just plain pausing workloads during peak hours and only running them during off-peak hours can also save CO2.

Alexa Teacher Model: Pretraining and Distilling Multi-Billion-Parameter Encoders for Natural Language Understanding Systems
The Alexa team ran a bunch of large-scale distillation experiments. What’s different from many similar papers is that:

They’re interested in a particular family of text classification tasks, consisting of inferring both intent and slots. E.g., “Alexa, call mom” → (actions.phone_call, contacts[‘mom’]).
They’re dealing with “spoken form” text. So instead of proper capitalization, punctuation, etc, they turn everything into a form similar to what their (separate) ASR module spits out.
Their target model for deployment is only 17M parameters and has to handle multiple languages. This is a 500x teacher→student size reduction, much more extreme than is typical.
They start by pretraining on cleaned public text datasets, then move onto proprietary and more task-specific data. They find that it helps to have huge teachers initially and to use their internal big, labeled corpus.
This is largely a case study that says “We’re 40 people from Amazon and here’s how we got better results on one of the largest and most advanced NLU deployments there is.” Which is a valuable contribution that helps ground the literature in real-world problems.
Prioritized Training on Points that are Learnable, Worth Learning, and Not Yet Learnt
They prioritize training on samples that are most likely to result in decreased validation accuracy according to a simple and Bayesian-motivated heuristic. On some datasets, like Clothing-1M, this lets them achieve their target accuracy in 18x fewer training steps.
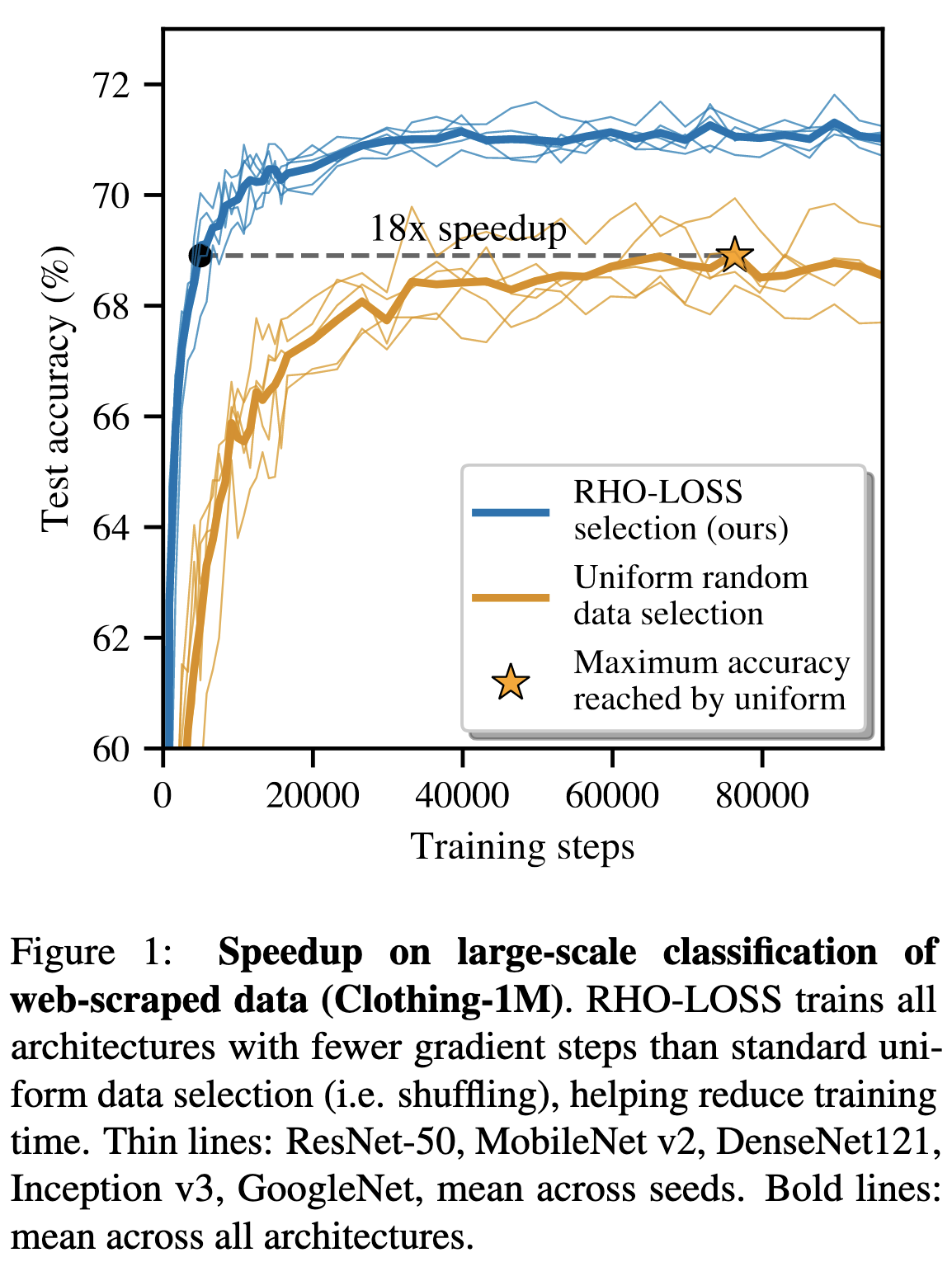
The scoring function they use to select samples is “reducible holdout loss.” This consists of the target model’s training loss for the point minus the loss of a smaller pretrained model. The idea is that samples that a partially-trained model does poorly on but a fully-trained model does well on are less likely to be noisy, irrelevant, or already learned.

Their full algorithm is basically selective backprop with the selection criterion set to the training loss minus the separate model’s loss. The downside here is they sample only 10% of the batch to backward pass, so they need a huge batch size and are doing ~3x more computation total. Though as they point out, this larger forward pass could, in principle, be parallelized across many machines if you could broadcast the latest weights quickly enough.

They perform good ablation experiments to show that they actually do avoid samples that are noisy, irrelevant, and redundant.

They also show that the model used to compute irreducible loss can be small, trained using the same data as the target model, and reused many times once trained.
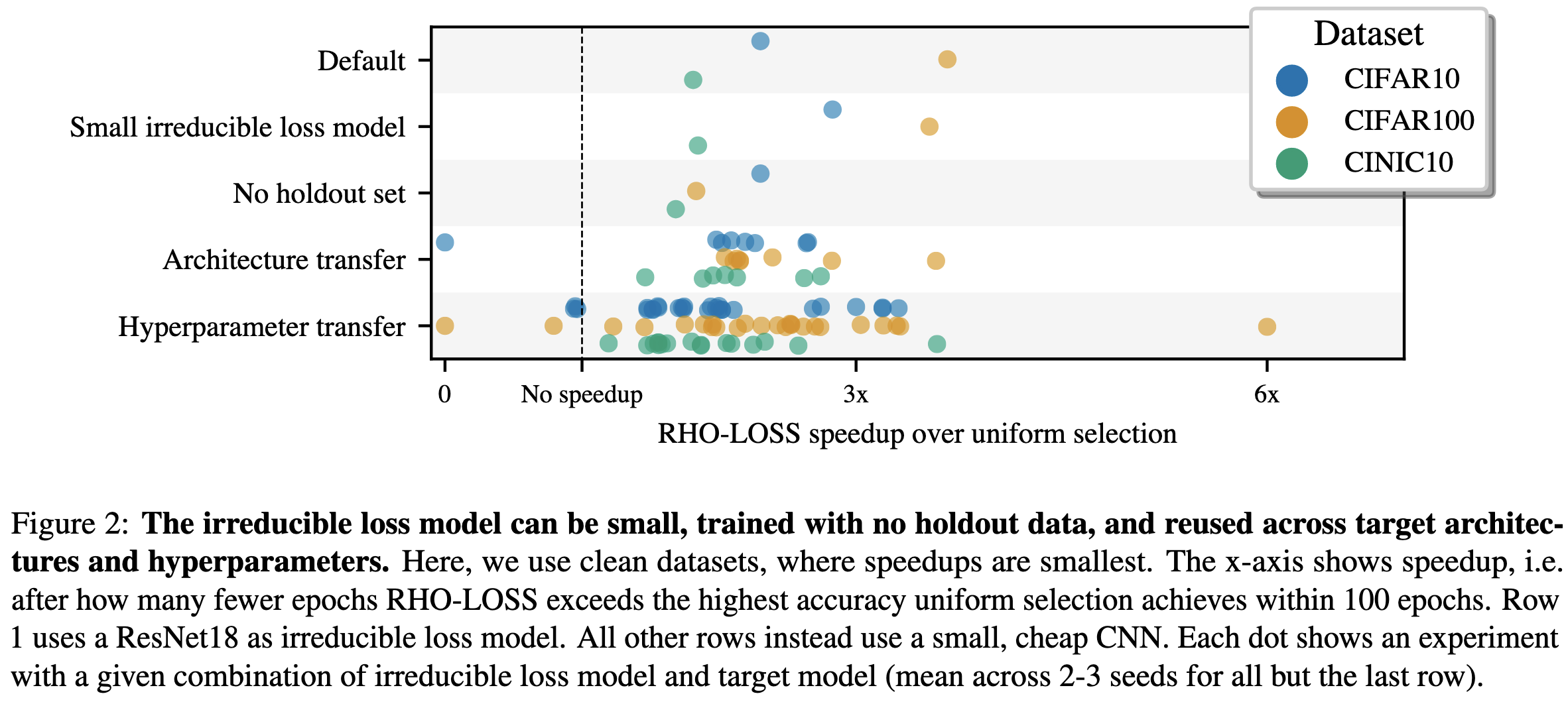
In terms of epochs of training, their RHO-LOSS sampling often does yield large reductions compared to uniform sampling and other baselines.

This paper makes we wonder whether part of distillation’s mechanism of action might be turning unlearnable samples into learnable ones (since there exists *some* network that produced those outputs).
I also just want to commend this paper for being unusually clear, rigorous, and readable. The color coding helped quite a bit and I found myself accidentally reading the entire text because it was so interesting and easy to follow.
Understanding the Generalization Benefit of Normalization Layers: Sharpness Reduction
If you ensure that your weights have a fixed norm, you’re basically doing projected gradient descent on the unit sphere. Under this and some other assumptions, they show that we should expect the effective learning rate to increase until the edge of stability, and for the weights to move according to a sharpness-reducing flow.

A Unified Sequence Interface for Vision Tasks
Geoff Hinton and company simplify computer vision pipelines. Specifically, they train a ViT-B to perform four different vision tasks by generating sequences. The sequences encode bounding boxes, class labels, etc, in a simple, human-readable format.
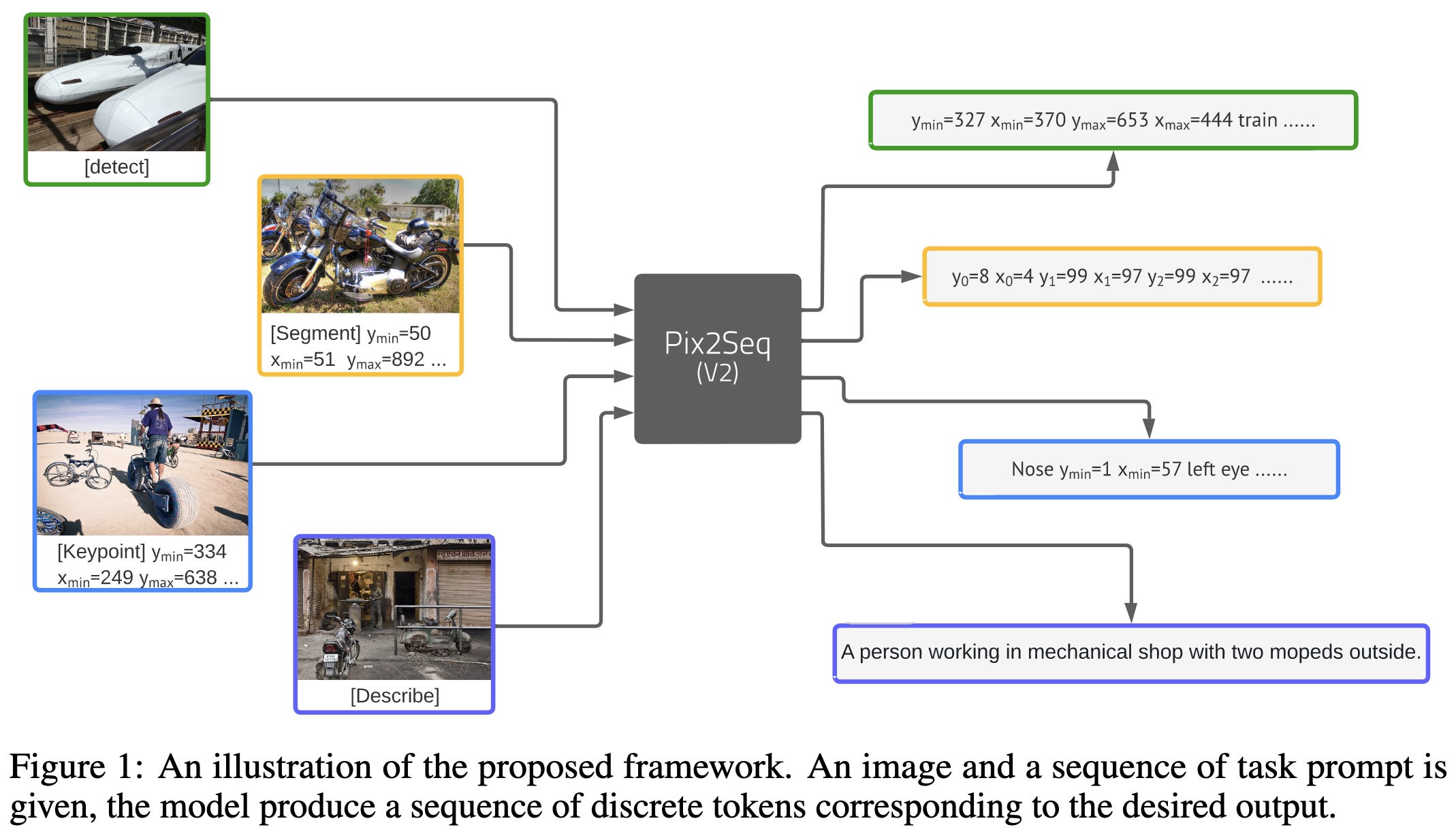

To train it, they feed in images and tell it to autoregressively generate the sequence corresponding to the ground truth labels.
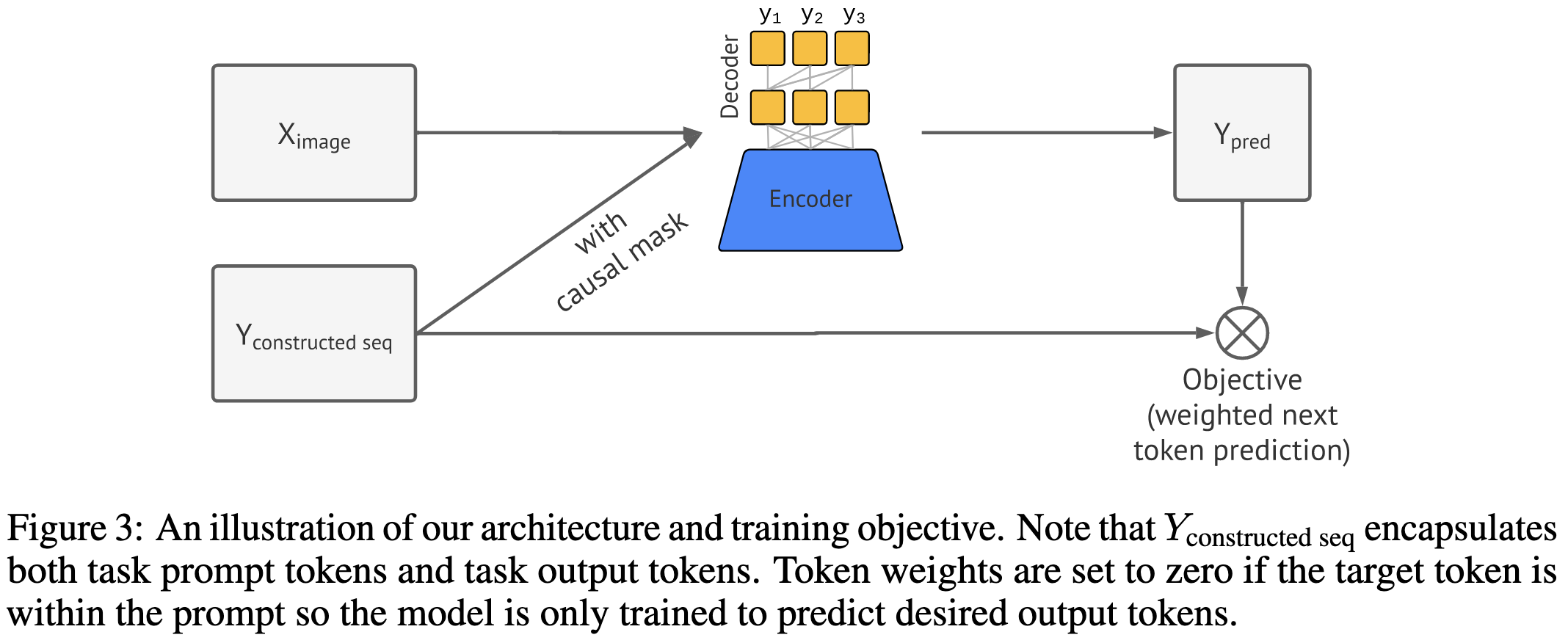
To get predictions, they generate sequences using nucleus sampling and task-specific postprocessing:

Overall it works pretty well. Though note that they pay a hefty inference latency penalty from having to do autoregressive decoding.

The main story here is about sharing a single model and loss function, but it’s also cool that they simplified the individual tasks. E.g., I understand how they did object detection after just a quick read through the paper, which is not something I can say of most object detection papers.
LIFT: Language-Interfaced Fine-Tuning for Non-Language Machine Learning Tasks
They fine-tune language models to perform unrelated supervised learning tasks by feeding in data and targets as sequences in a particular format.

Works reasonably well for tabular and small-scale datasets.

Unsurprisingly, doesn’t seem to be as sample efficient as simple estimators like logistic regression:

ReCo: Retrieve and Co-segment for Zero-shot Transfer
They address the problem of zero-shot semantic segmentation. There’s a lot going on here but a few parts are really clever.

First, they have an interesting pipeline for learning embeddings for a new object category. They use CLIP to filter online images gathered using the class name. They then use a pretrained image encoder to construct an embedding for each pixel of each image. Then, they identify a key pixel within each image that they’re most confident is representative of the class, based on similarity to pixels in all the other images. To avoid picking up on common classes like the sky, roads, or grass, they precompute embeddings for these concepts and filter out pixels that resemble them. The most similar remaining pixels, averaged across the retrieved images, become the embeddings for the class.

At inference time, they construct a saliency map for each class for each pixel in the image, where each value is just a the pixel’s inner product with the class embedding, squashed with a sigmoid. They also multiply in the convolution of a CLIP model’s text embedding for the class name. And run the pixel-wise predictions through a CRF to exploit the spatial structure.

It works pretty well given their restrictive problem setup, usually beating other zero-shot / unsupervised approaches.
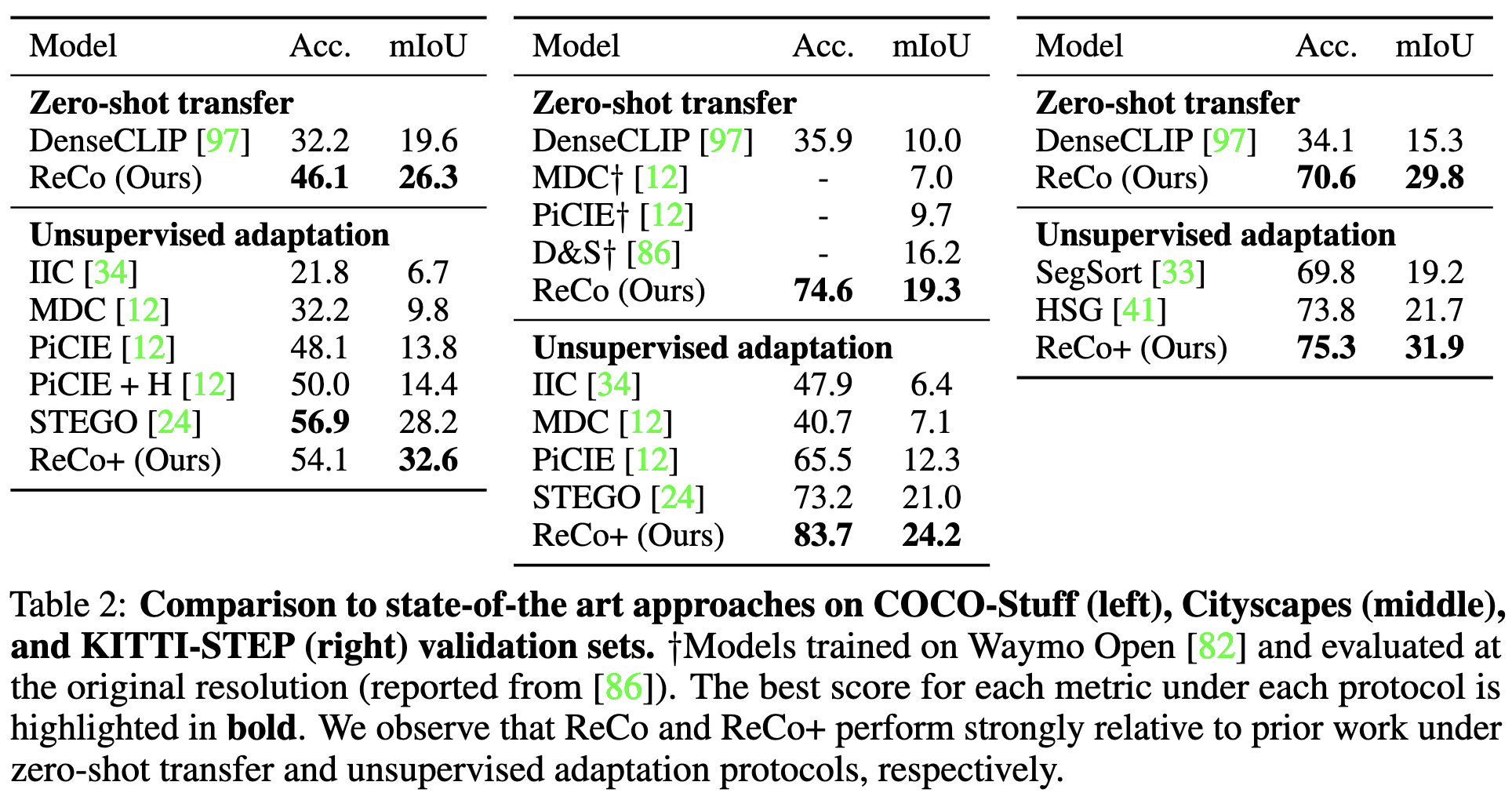
Mostly this paper makes me wonder how much room there is for creative ideas around similarity search over embeddings. Their strategy of finding nearest-neighbor pixels across many images feels a lot like old-school time series motif and shapelet discovery. And even more like my master’s thesis (paper) on unsupervised instance segmentation in time series. There are some big hammers in this literature, and it would be cool if we could find nails for them in modern ML pipelines.
Towards Understanding How Machines Can Learn Causal Overhypotheses
What happens if you present various RL algorithms and large language models with a simple causal structure inference task that children ace after just a few examples? Well…the algorithms don’t work nearly as well. What I found most interesting about this is the concept of a causal overhypothesis, which is basically a hypothesis family for causal structures.

Parameter Convex Neural Networks
You make a neural network a convex function of its parameters if you’re willing to restrict / preprocess your weights, activation functions, and inputs. Basically, if your activation and loss functions are convex and your {weights, inputs} are nonnegative, the neural network is a convex function. You can make this happen by, e.g., using the weights or inputs as exponents for some positive constant.

It’s not clear this works better than typical approaches, but it’s an interesting idea that hasn’t been explored much in the literature.

Note that the overall problem doesn’t become a convex optimization problem because of the softmax at the end of the network and the lack of an activation function (other than exp(x)) whose derivatives have certain properties.
⭐ Fisher SAM: Information Geometry and Sharpness Aware Minimisation
SAM but with KL divergence instead of Euclidean distance. This ends up just meaning that the SAM perturbation gets weighted by the inverse of the elementwise gradients. Look at equations 10 and 12 to get the exact form of their perturbation.


Seems to consistently help accuracy a little bit in the long training and/or small data regime. The ImageNet results are for continued training of a pretrained DeiT-B, which is a large vision transformer.


The Slingshot Mechanism: An Empirical Study of Adaptive Optimizers and the Grokking Phenomenon
They find that late-stage training sometimes alternates between periods of stability and instability, with large loss spikes punctuating the phase transitions. Happens for Adam, AdamW. and RMSProp but not SGD[M] or Adagrad. This doesn’t seem to be explained by existing theories of deep learning or optimization.

Since it only happens for adaptive optimizers, and only a subset thereof, I would bet on this being an artifact of some subtlety in these optimizers’ updates. E.g., neurons going dead for a while and receiving huge updates when they finally have a nonzero gradient. But it’ll be interesting to see what people eventually figure out is behind it.
Learning to Limit Data Collection via Scaling Laws: A Computational Interpretation for the Legal Principle of Data Minimization
You can use scaling laws to predict how much data you have to collect from your users. This can help minimize privacy loss. You can also do better adapting scaling to individual users or groups thereof.

Large-Scale Retrieval for Reinforcement Learning
Retrieving similar board states from a million-scale database helps an agent play Go.
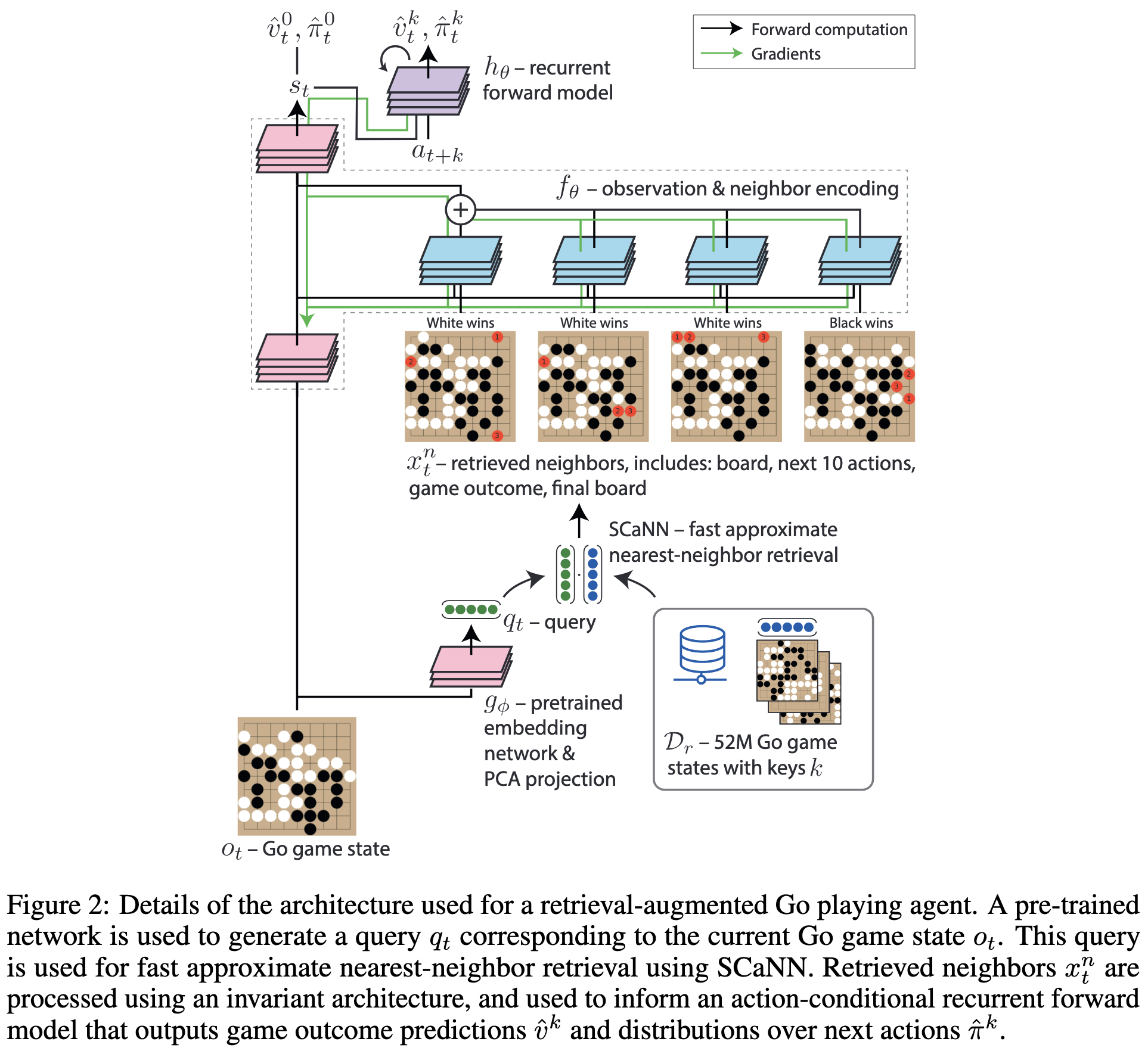
They have to precompute the knn graph for training efficiency, but that’s not too bad in this case since the database isn’t that big and they aren’t as sensitive to inference latency (note that test time will feature new queries that aren’t cached yet).

Seems to help a lot. And more neighbors help more up to a point, which is a good sanity check.

More validation that retrieval-augmented models work extremely well, at least when you don’t have to worry about the cost of the retrieval.
Efficient Decoder-free Object Detection with Transformers
They propose a transformer-based object detector that has no decoder and fuses information from different scales into a single H/32 x W/32 feature map. They have a fixed, sparse set of anchor points at which they make predictions, with a single head that outputs both class predictions and bounding box coordinates. They also propose a variety of architectural components and a particular overall architecture.

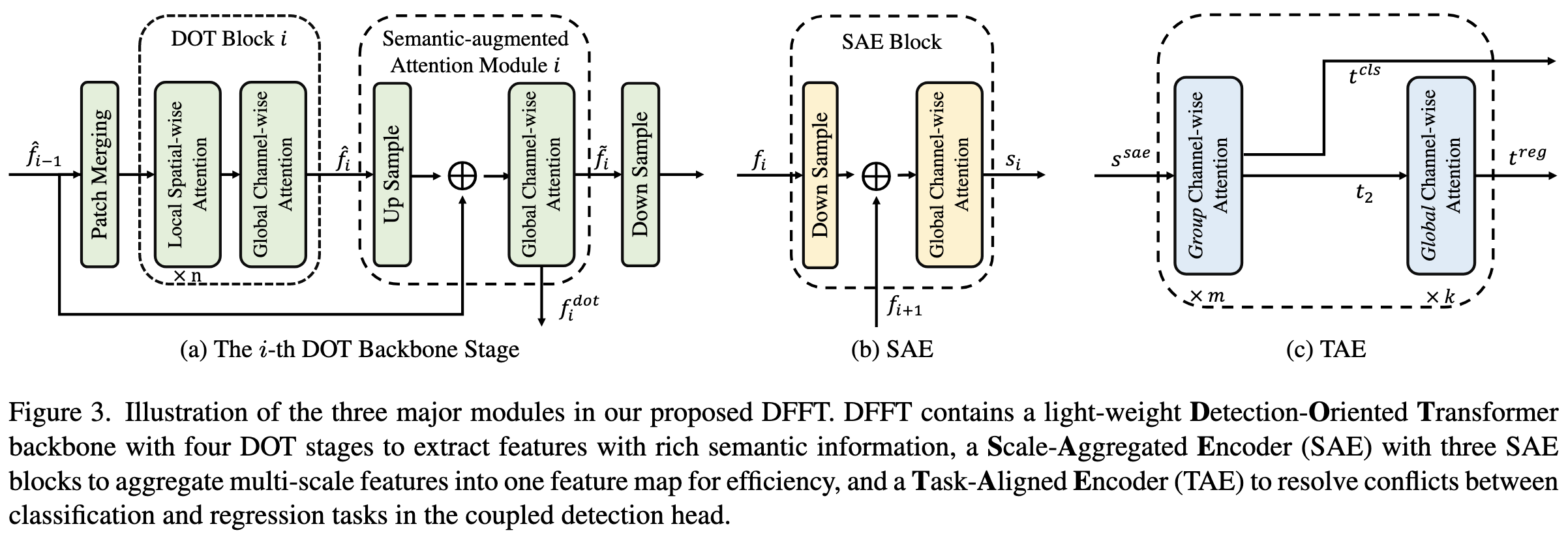
They have fairly good ablations for their different components, although there are enough degrees of freedom here that it’s hard to know how they arrived at this exact architecture.

Overall, it yields significant improvements in training GFLOPs vs AP on COCO when compared to DETR and various CNN-based object detectors.
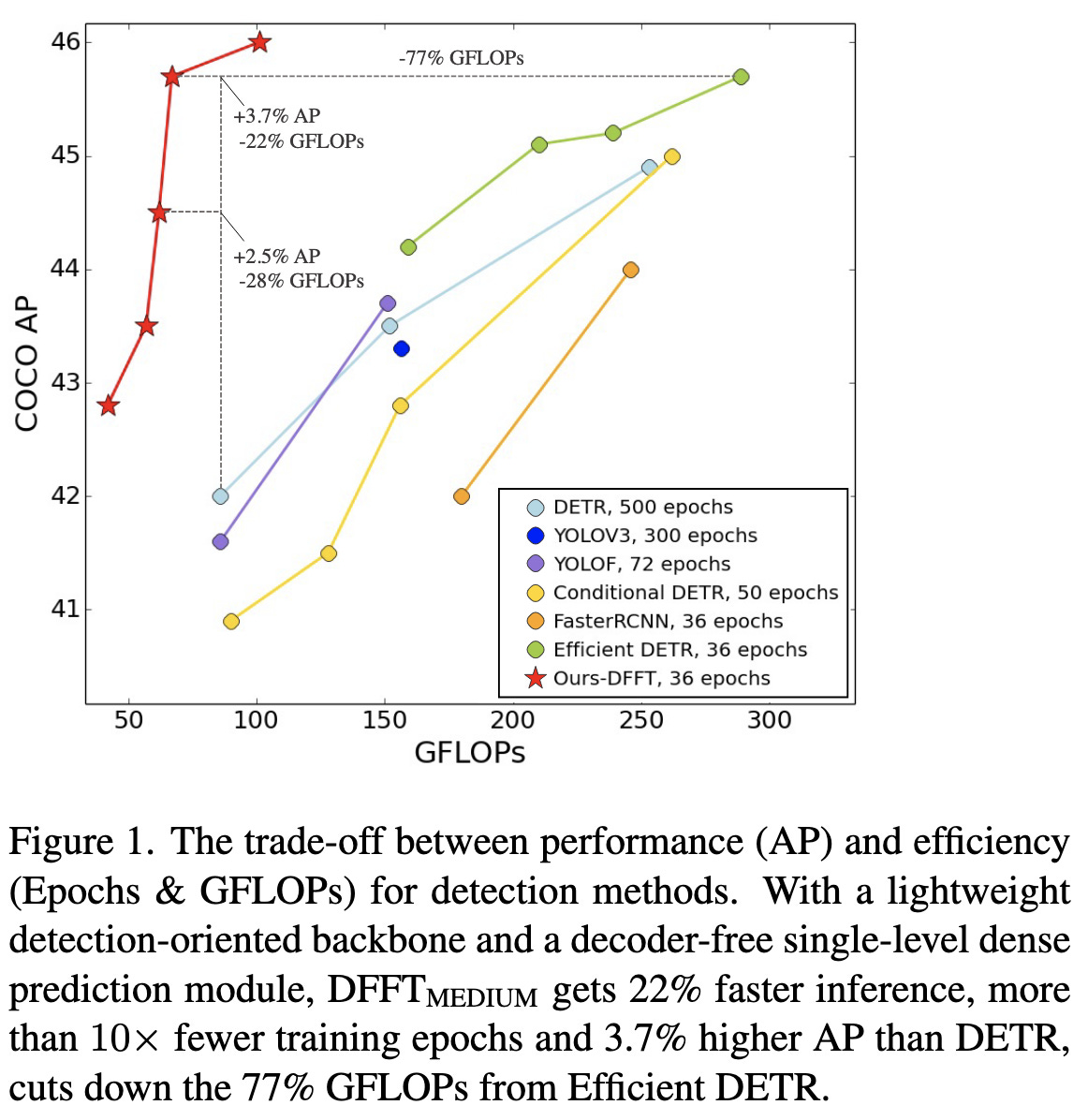
What I’d most like to try from this paper is the detection part on a more generic vision transformer; fixed anchor points and a single head sound nice and simple, and I’d be curious how this aspect works without the rest of their architectural choices.
Memory-Based Model Editing at Scale
If an input matches a textual “edit” in your database, feed the input and the edit to a different model instead of your regular model.

Works significantly better than previous approaches, especially as the number of edits to incorporate grows.
