


2022-7-17 arxiv roundup: Next-ViT, Anthropic & DeepMind & Google interrogate giant language models, 16 other papers

This newsletter made possible by MosaicML.
Next-ViT: Next Generation Vision Transformer for Efficient Deployment in Realistic Industrial Scenarios
So I normally don’t like papers introducing yet-another-vision-transformer. But I like this one a lot. Here’s why.
First, this plot. They measured runtime vs accuracy across different tasks and hardware, with a large number of baselines and a wide span of speed vs quality tradeoffs. This sort of plot is both rare and the only thing I really believe when it comes to claimed improvements.
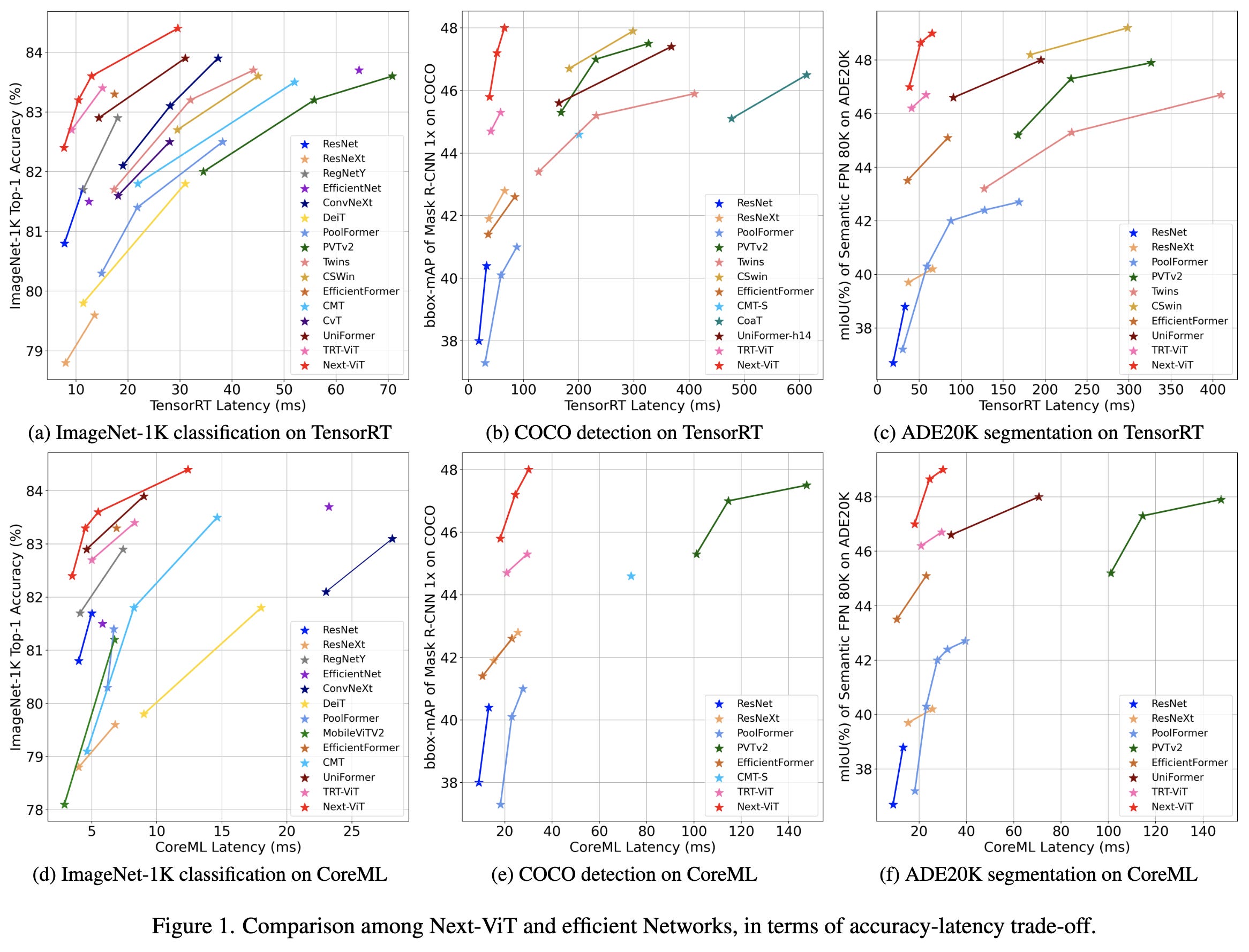
(Though even here, sadly, there are too many ViT variants for them to compare to them all.)
The second reason I like it is this figure. It’s an architecture diagram clear enough that I think I could actually code their model from it. This is especially rare for ViT variants, which typically have some confusing mashup of windowing schemes I can never decipher.

The third reason is this diagram, which is single-handedly one of the more concise and helpful related work overviews I’ve encountered.

And lastly, I like that they ablated not just their own model-specific design decisions, but decisions to use their components *at all*. E.g., I like their observation that their conv block actually does better than more traditional alternatives.

It’s also interesting to see BN+ReLU compared to alternatives. They find that it’s worse from an accuracy perspective, but so much faster that it’s nonetheless the best choice.

Overall a really well-executed paper with compelling results.
A Data-Based Perspective on Transfer Learning
Examines effects of classes in a pretraining dataset on downstream task performance.

They do so using a simple algorithm that trains different models on different subsets of the data, and looks at both the class counts and the predictions for each model on each downstream sample.

Using their scoring function, they can intelligently remove subsets of classes from the pretraining dataset in order to significantly raise downstream accuracy.
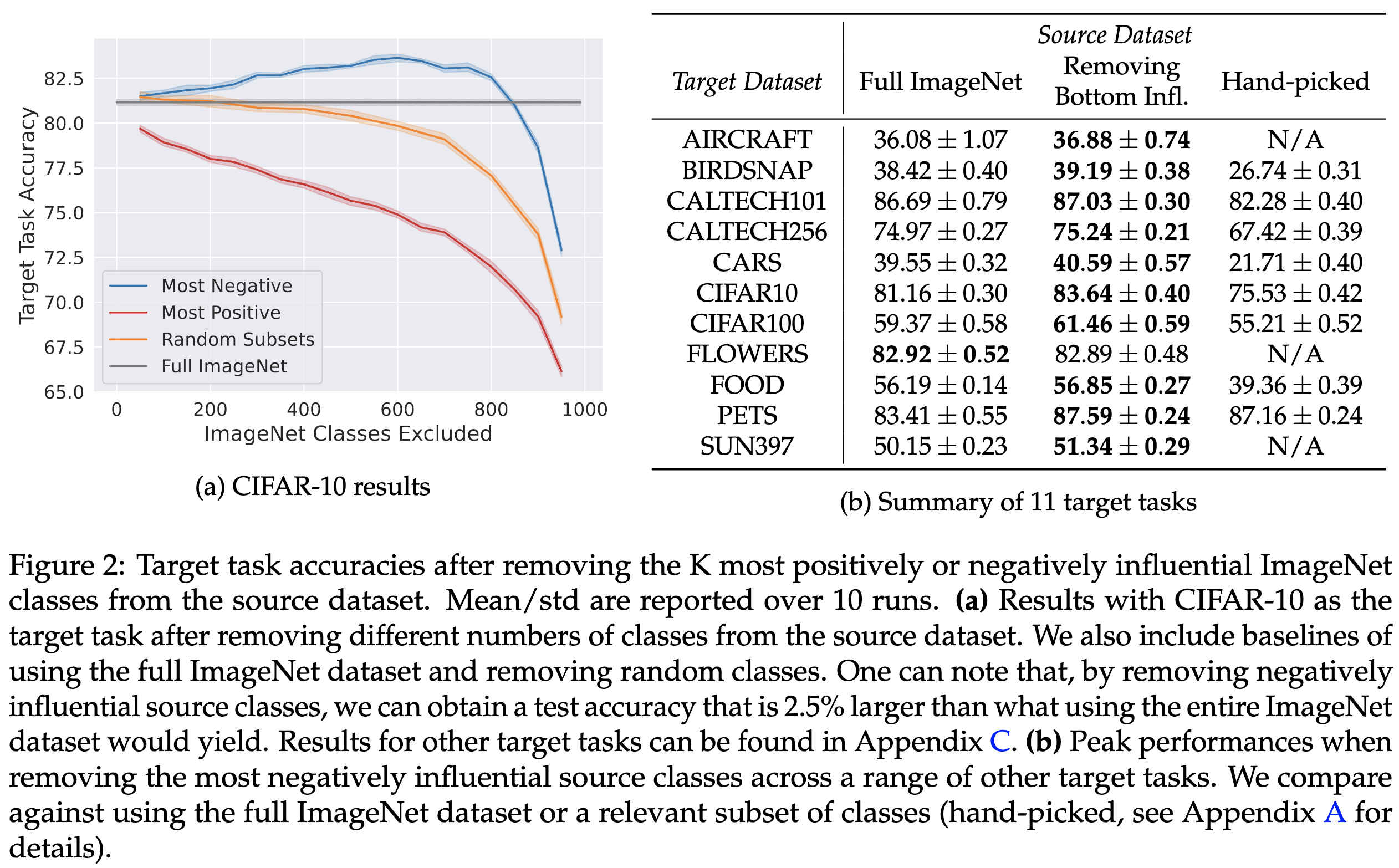
Another use of their method is identifying more granular subpopulations than what a downstream task has annotated. E.g., you can find which CIFAR-10 images look most like ostriches even though CIFAR-10 only has the label “bird”.

You can also use a similar idea to understand model failure modes or identify data leakage.

And last but not least, you can use it to understand helpful/harmful samples in your pretraining dataset.

Overall their algorithm seems like a great tool to have in the toolbox (code).
On the Strong Correlation Between Model Invariance and Generalization
You can construct a linear prediction for image classifier OOD performance based on the invariance of the models’ predictions to data augmentations. But doing this with naive measures of invariance like L2 distance doesn’t work.

Instead, they propose a simple invariance measure that takes into account not just the shape of the class probabilities vector as a whole, but also which class would be predicted. Concretely, for a given image, it’s the geometric mean of the probabilities assigned to the predicted class if both the original and transformed image produce the same prediction, and 0 otherwise.

Even if it’s just a heuristic, it’s always nice to see a simple method that works well in practice.
Language models show human-like content effects on reasoning
Big language models show biases in logical reasoning similar to those of humans.

In particular, they’re better at reasoning about concrete situations where the conclusions match reality.

They also tend to believe statements that contain nonsense or match reality, even if the logic behind the statement is invalid.

Moving from zero-shot to few-shot can largely mitigate these biases, especially in their larger model:


Interesting to see this apparent convergence of human and machine intelligence. Might have taken 60 years, but it feels like cognitive science is finally becoming helpful for AI (I’m allowed to say this because my 2nd major was CogSci).
Language Models (Mostly) Know What They Know
Big Anthropic paper with a ton of detailed experiments. A few highlights:
“We find that language models can easily learn to perform well at evaluating P(IK), the probability that they know the answer to a question, on a given distribution”

Large models can be really well calibrated on multiple-choice questions if prompted properly.

And boy can they be miscalibrated if they aren’t large enough and you restructure the task the wrong way. Though again, size seems to add a lot of resilience here.

You can ask a model whether its output is correct and get a pretty good answer for Lambada, though not so much for Codex.

If you care about model calibration or related AI safety questions, I’d definitely recommend having a long sit with this paper.
Exploring Length Generalization in Large Language Models
How well do language models generalize to longer, harder problem instances? Pretty well in-distribution, but usually poorly out-of-distribution.

This matters in practice because a lot of datasets vary greatly in length.

They have a large number of thorough experiments on models of up to 64B parameters. One interesting finding is how little scale helps length generalization when finetuning.

This lack of finetuning efficacy is especially interesting because in-context learning can get it to generalize better. I don’t think I’ve seen an example of in-context learning outperforming finetuning before.
My favorite result is this experiment with parity computation. On the left, they fix the input length at 30 bits and vary the number of ones from 10 to 20. And on the right they change the input length (number of bits). Even though the length per se doesn’t change on the left, the model completely fails to generalize to new numbers of ones.
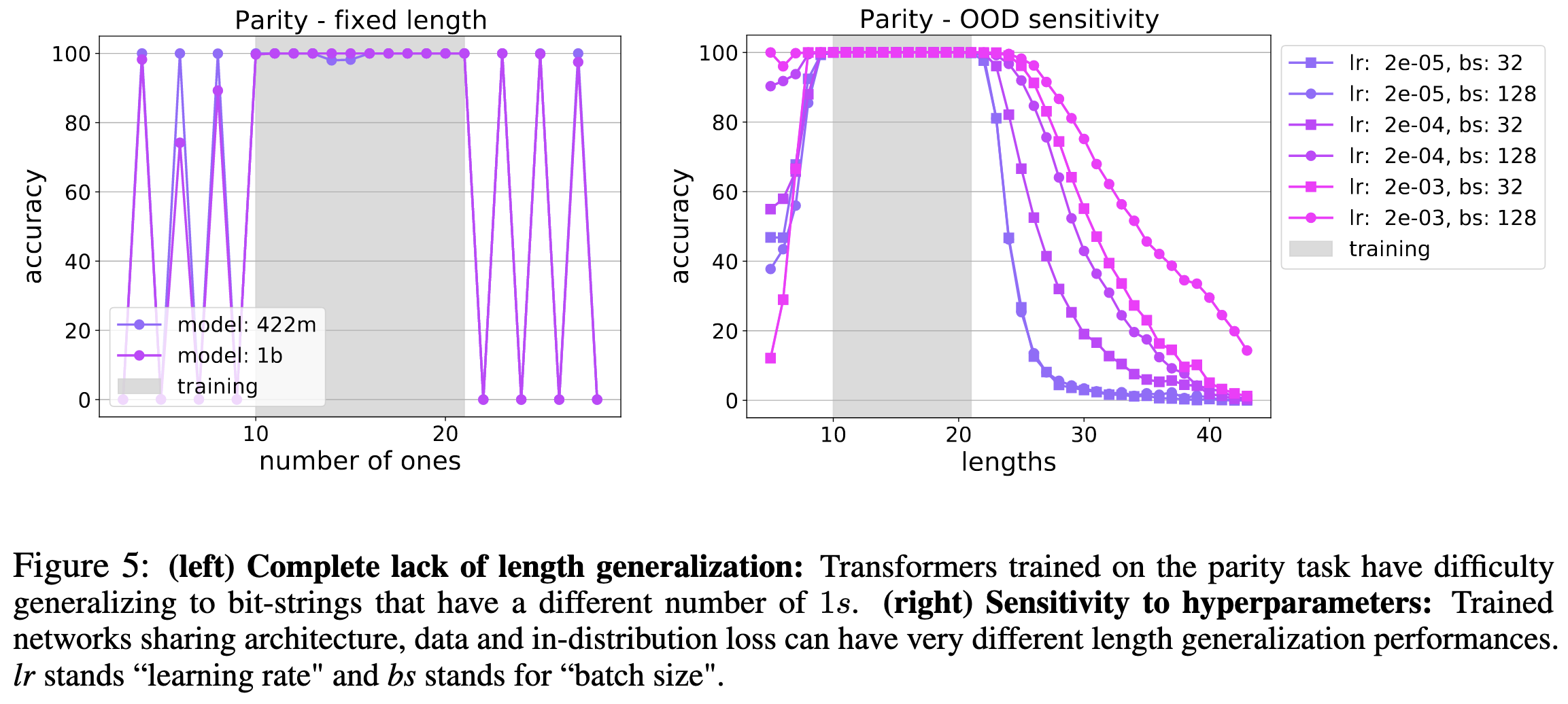
They argue that this suggests transformers tend to learn parallel strategies rather than sequential ones, and that this is part of why they fail at generalizing across lengths.
This is one of those papers you could spend hours digging through in detail, and I’d definitely recommend it if you want a deeper look into pathologies and failure cases of large language models.
Efficient Augmentation for Imbalanced Deep Learning
Finds on CIFAR100-scale datasets that you’re better off oversampling / augmenting minority classes in the models’ embedding space, rather than in image space. This suggests that dealing with class imbalance shouldn’t be seen as a separate data preprocessing step, but rather a model-specific intervention. This paper also just has a lot of experiments on generalization gaps and sampling schemes—really thorough and you could spend a long time going through this one.

Efficient NLP Inference at the Edge via Elastic Pipelining

So let’s say you’re trying to run BERT inference on a smartphone. The OS won’t let your app sit there with a full BERT in memory all the time because smartphone RAM is so limited (and that’s assuming you even have enough RAM to fit the whole model at once). So what you have to do is load the model in from storage, which can takes 3+ seconds.
So what do you do instead? Well, they cache a small portion of the model and dynamically fetch quantized subsets of the weights during inference.

They profile the device they’re running on upon app install and have a planning program that uses this info to load the most weights (with the least quantization) it can get away with.

This ends up working better than alternatives, though it doesn’t match the accuracy you could get with no hardware constraints.
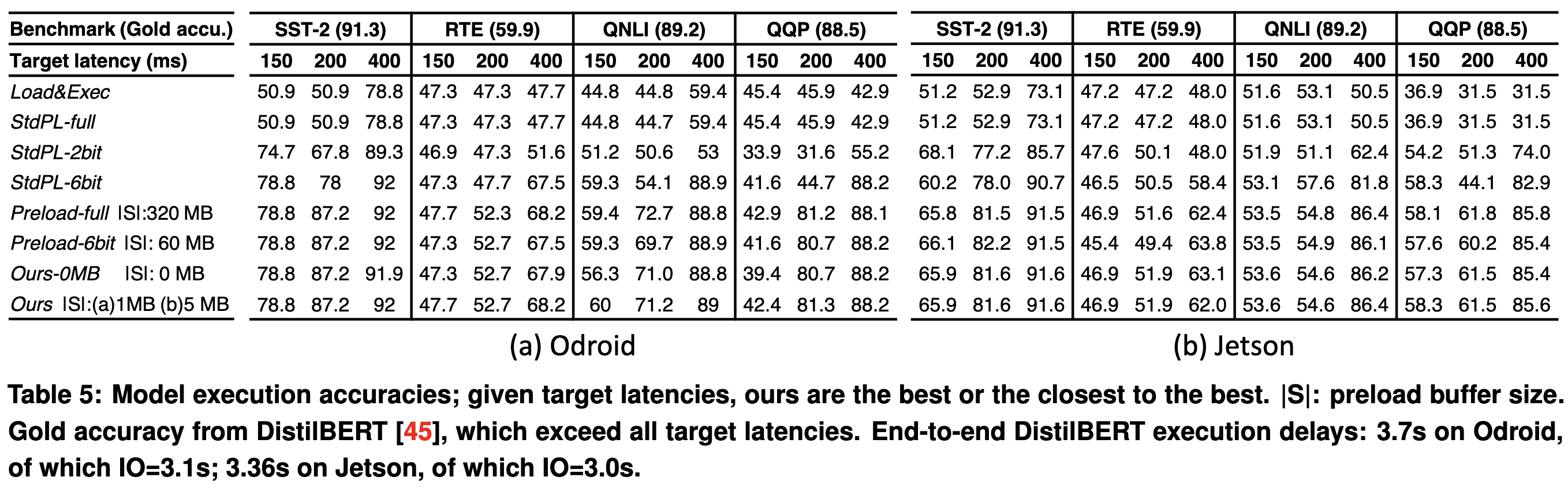
What I’m curious about after reading this is the relative efficacy of intelligent runtimes vs using a smaller model that “just works”. On heterogeneous devices, I could see a case for using a single model with device-specific profiling to execute it. And if you’re going to have a fixed model, it probably does make sense to allow degraded accuracy rather than degraded latency in some cases.
High Per Parameter: A Large-Scale Study of Hyperparameter Tuning for Machine Learning Algorithms
Explores the importance of tuning hyperparameters for various non-deep-learning algorithms across over 28 million training runs. Most important for tree-based classifiers + regressors, as well as kernel ridge regression.

Utilizing Excess Resources in Training Neural Networks
A short paper with only small-scale experiments, but they seem to have discovered something interesting. Namely, instead of directly learning weights, they generate weights using larger tensors during training; but then at inference time, they just use the generated weights so that there’s no overhead.

And what’s weird is that this seems to improve accuracy.

So it’s like a hypernetwork, but with a fixed input so that it generates the same network every time. This accuracy lift might just be a result of better hparam tuning or some other asymmetry—but if not, it looks like a surprising finding about implicit preconditioning or something. If it holds, suggests we can just make models bigger at training time to get better accuracy with no inference overhead.
LightViT: Towards Light-Weight Convolution-Free Vision Transformers
New ViT variant that seems to do better according to not just FLOPs, but also inference latency.

Like other recent ViT proposals, it mixes attention at different spatial scales, including some form of global attention.
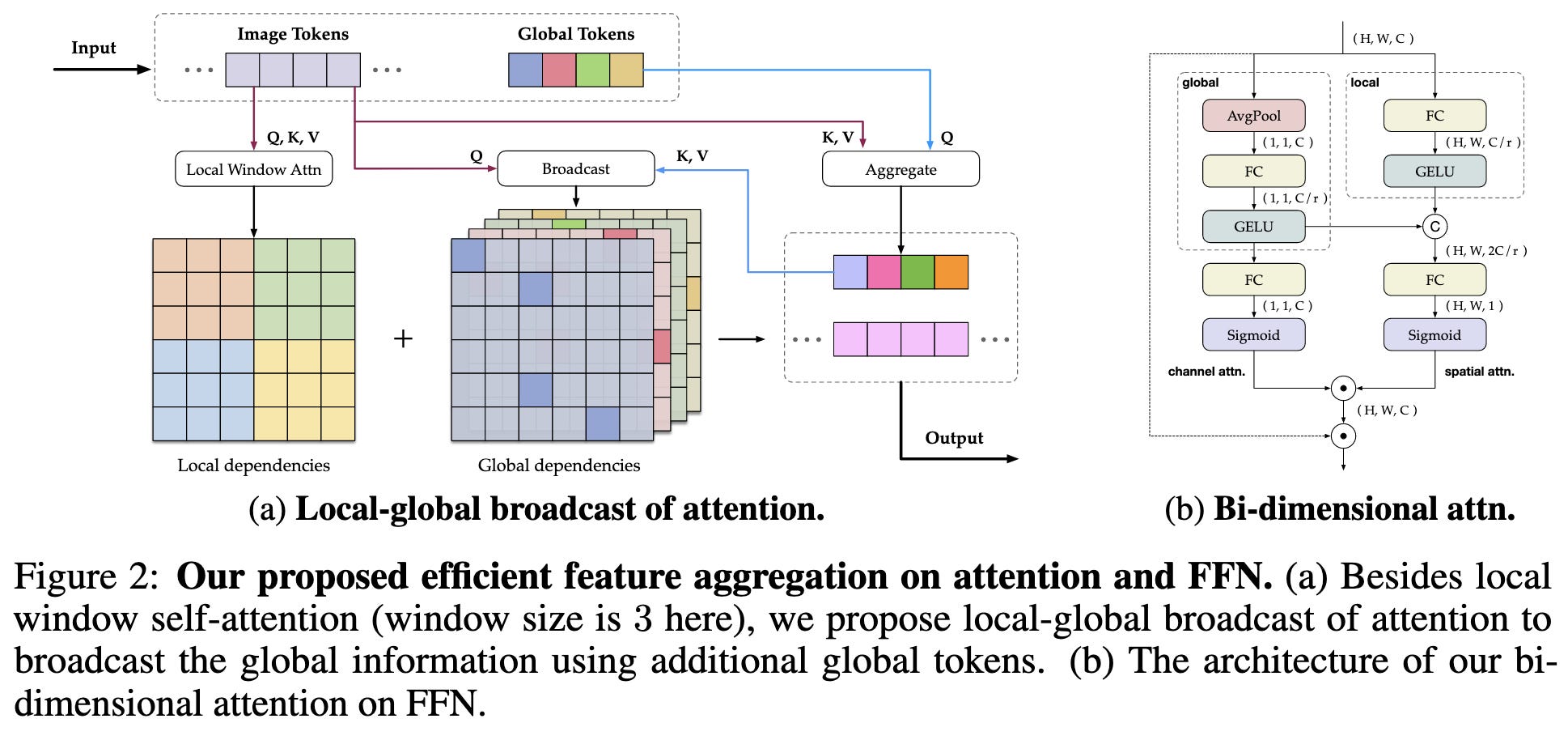

Having attention at different scales and along different axes seems to help. Having a global attention mechanism seems to be the biggest accuracy lift.

Strong results on COCO and ImageNet. Beats Swin by ~1%, which is pretty typical for recent vision transformer proposals.


SparseTIR: Composable Abstractions for Sparse Compilation in Deep Learning
OctoML made a better system for compiling sparse tensor operations. The main idea is to make the sparse structure and set of optimization passes composable.

Often beats existing sparse op implementations by a significant margin.

TensorIR: An Abstraction for Automatic Tensorized Program Optimization
OctoML introduces nice abstractions around tensor operations and good tooling on top of them. The big idea that stands out to me is that of defining blocks, where blocks are chunks of code that are likely to be be implemented with different vector/matrix instructions on different hardware. This lets them isolate the ISA-specific parts from the more general outer loop / tiling optimizations.
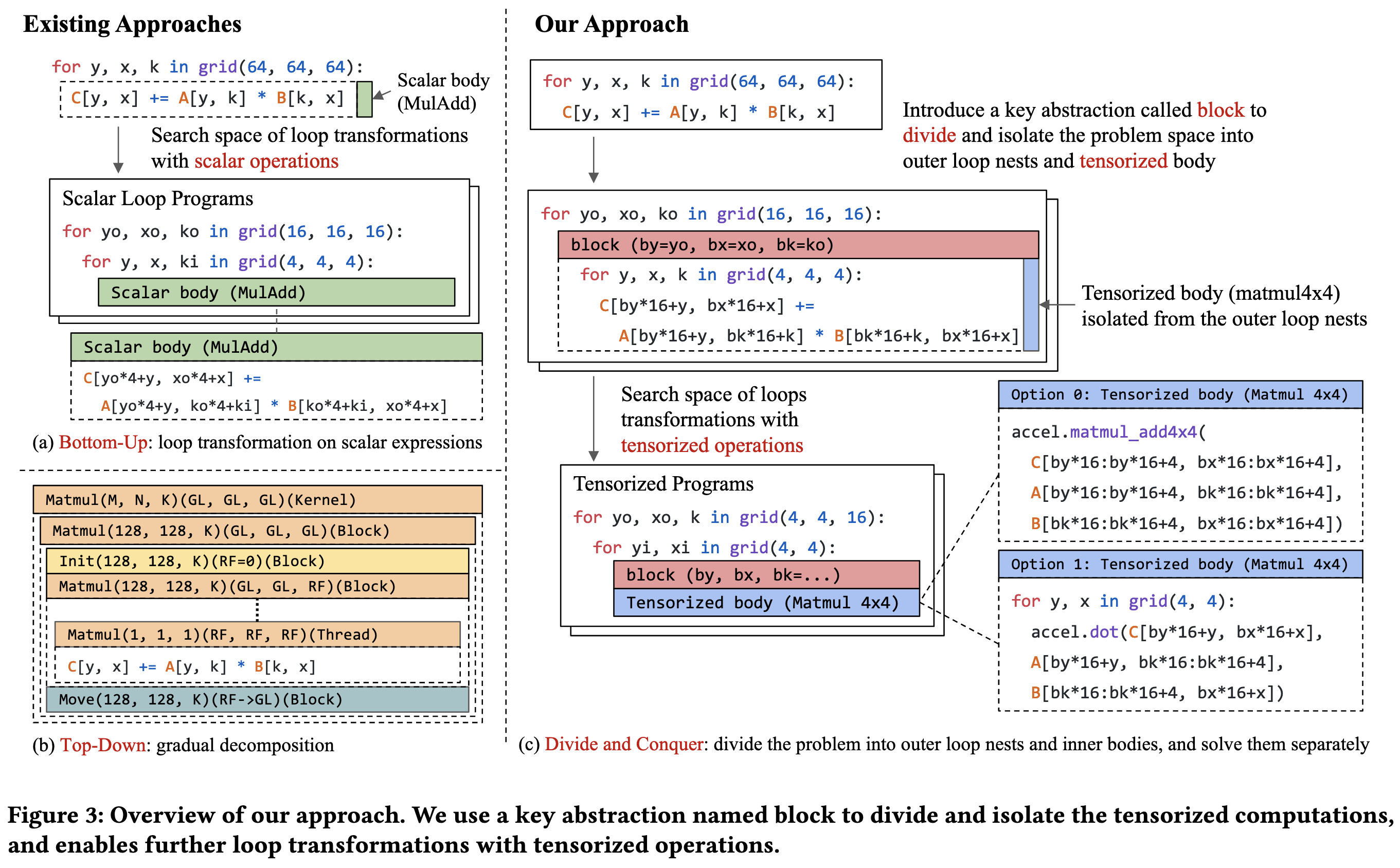
They also ensure that blocks are typed, so that the rest of the code can correctly be optimized around them. And they add in an autotuner + validation step to propose and check implementations.

TensorIR often yields large improvements compared to various baselines, including TVM without TensorIR:


It also yields large speed gains for full networks on ARM CPUs.
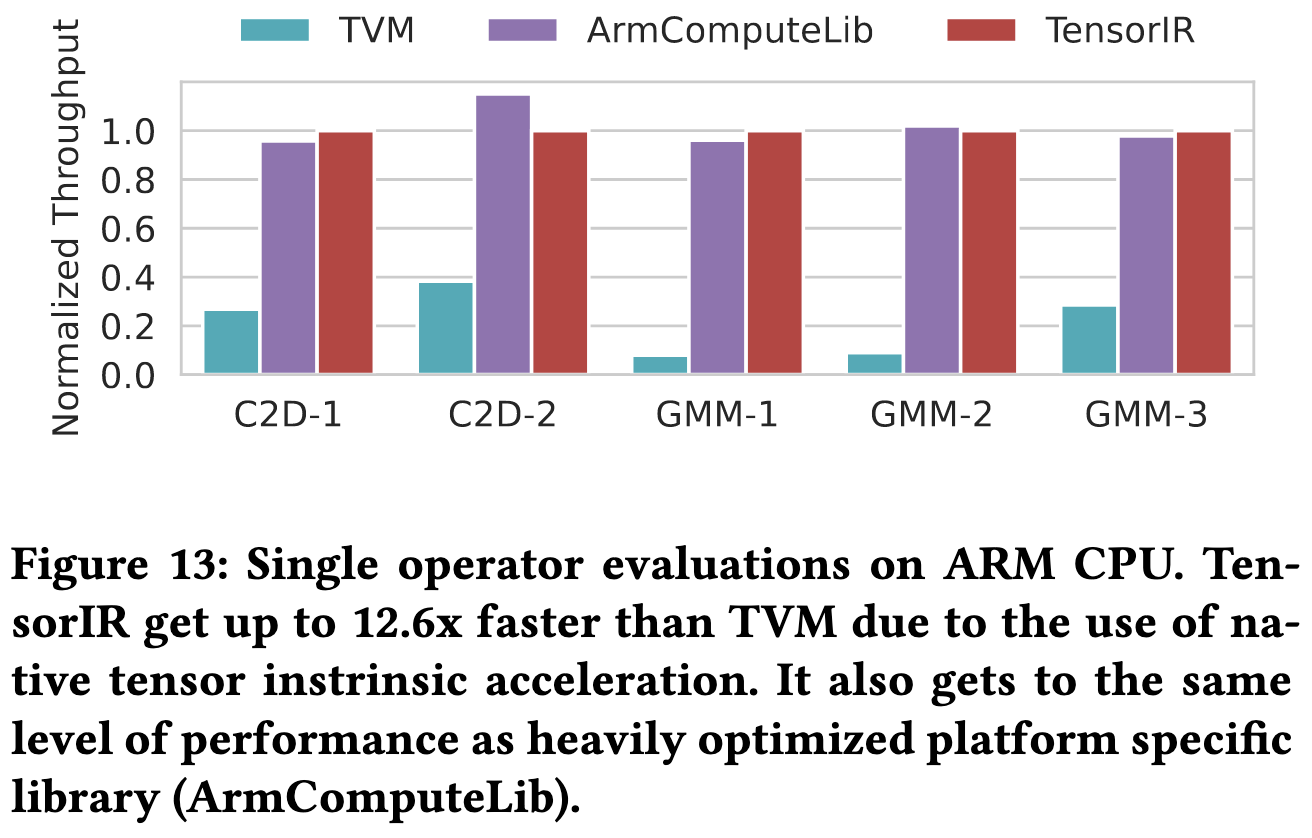

This paper is dense and has a lot going on, but is essential reading if you care about tensor compilers.
Embedding Recycling for Language Models
Just fine-tune the last N-k layers of your model instead of the whole model or only the last layer. And instead of fprop-ing through the first k layers, just cache their outputs on disk.

Finetuning only the second half the model works about as well as fine-tuning the whole model, though there’s a decent amount of variation across models and tasks.

As you would expect, finetuning only half the model is about twice as fast as long as you have fast storage and/or the files can sit there in DRAM. Less effective for inference, not to mention the fact that you’d have to be running inference on samples you’ve seen before.

I feel like Schmidhuber or someone probably did this in the 90s (and caching embeddings when training only the last layer is already a standard practice), but the experiments are thorough and the paper is nice and clear.
k-means Mask Transformer
Replaces cross-attention with k-means assignment and gets better results on COCO and CityScapes.


A little hard to tell what’s going on results-wise since the backbones also vary, but at least with a ResNet-50 backbone, significantly outperforms the baselines in terms of both speed and accuracy.


Quantifying Adaptability in Pre-trained Language Models with 500 Tasks
Introduces TaskBench500, a benchmark of 500 procedurally generated evaluation tasks for language models. There are a few “atomic” tasks at the core that get composed together to generate the full set of tasks.
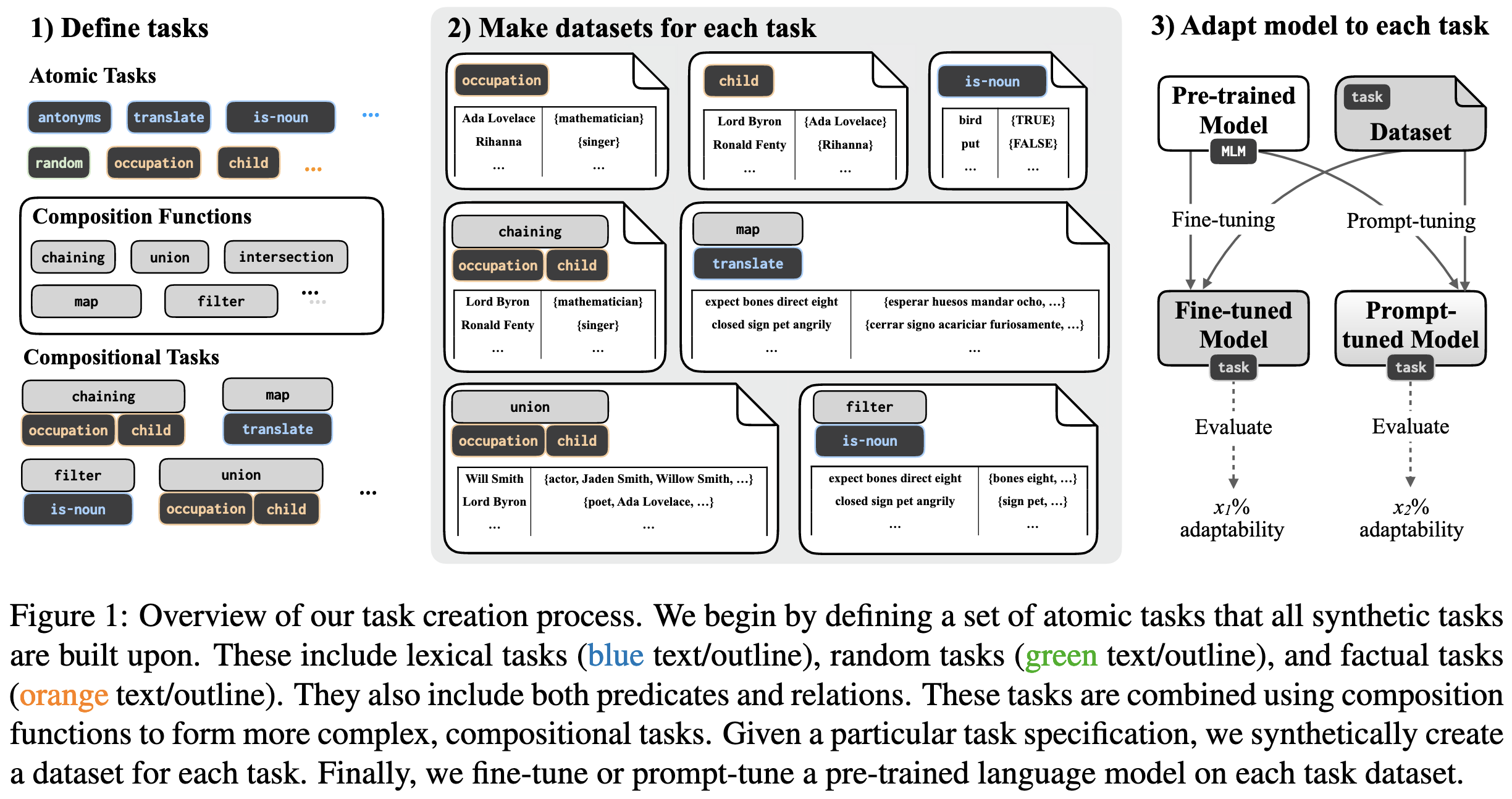
They use this benchmark to generate a few interesting findings, such as prompt tuning being much worse at memorization than finetuning past a certain number of examples.
Re2G: Retrieve, Rerank, Generate
Significantly better results on KILT by adding a better retrieval mechanism + reranker to their language model.

For each input, they retrieve 12 passages from a neural retrieval system and 12 passages from BM25. They run both through a neural reranker, then concatenate the best 5 to the input. They weight the five outputs by reranker score to compute the overall output.

To train the retrieval component, they rely on the ground truth “provenance” labels in the KILT dataset. Specifically, they train on tuples of (query, true positive passage, hard negative passage suggested by BM25).
To train the ranker, they collect retrieved passes from BM25 and the trained retrieval mechanism and tell it maximize the scores of the true passages.

Yields SOTA accuracy on KILT tasks.

Results are consistently worse when omitting BM-25 and sourcing all 24 queries from the neural retrieval (-BM25 variant), as well as when omitting both BM-25 and the reranking (KGI_0 variant). Adding knowledge distillation helps but omitting it isn’t as big a deal.

Seems like a solid advance in retrieval-augmented language models. The need for ground truth passages to retrieve is definitely a limitation, but one that we might be able to get around with either a large labeled dataset or a clever proxy objective.
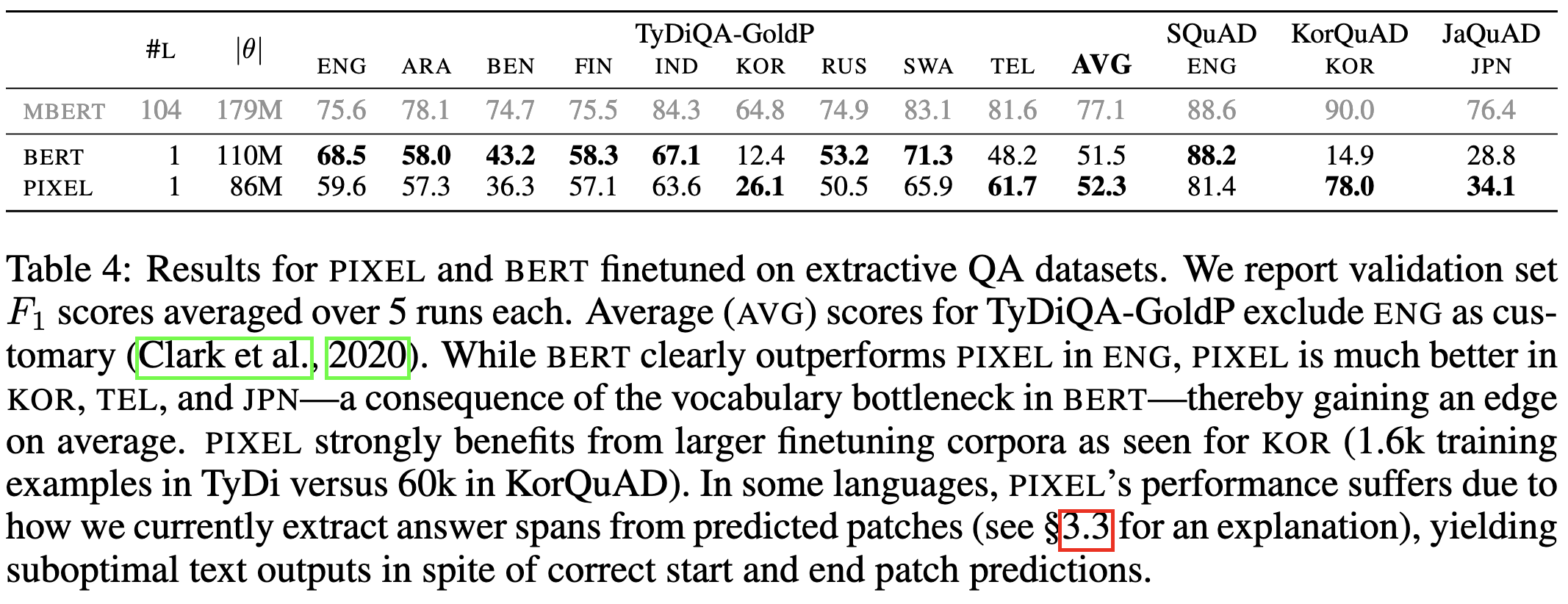
Language Modelling with Pixels
Construct a binary embedding for each character by rendering it as pixels and looking at which pixels are empty vs filled in. Then feed the rendered images into a ViT, pretrained with a masked autoencoding objective.

One perk of this approach is that it easily handles multiple languages, emoji, etc, without the size of the embedding tables blowing up; in fact, they have no pre-defined vocabulary at all.

It works worse than regular BERT on English text, but degrades way less on Korean and other non-Latin scripts. They attribute this to BERT’s “vocabulary bottleneck.”

This strikes me as definitely not the optimal approach to text representation, but—because of this—really interesting work. I can think of a dozen reasons why we should be able to design a better representation than whatever some font happens to hand us, which means that this doing even okay suggests that using fixed-size sort-of-random embeddings for all characters is actually pretty promising.
Recurrent Memory Transformer
They add a memory mechanism to Transformer-XL and observe lower perplexities and better downstream performance on highly structured tasks like copying.


N-Grammer: Augmenting Transformers with latent n-grams
How would you incorporate n-gram information into a transformer block? The obvious way would be to look at pairs of words or tokens, associate each pair with a unique id, and then do a lookup into a giant table.

But since our embedding tables are already huge, squaring their size might not be the best idea. So what this paper does instead is use the awesome power of product quantization to get bigram-dependent embeddings without the vocabulary blowup.
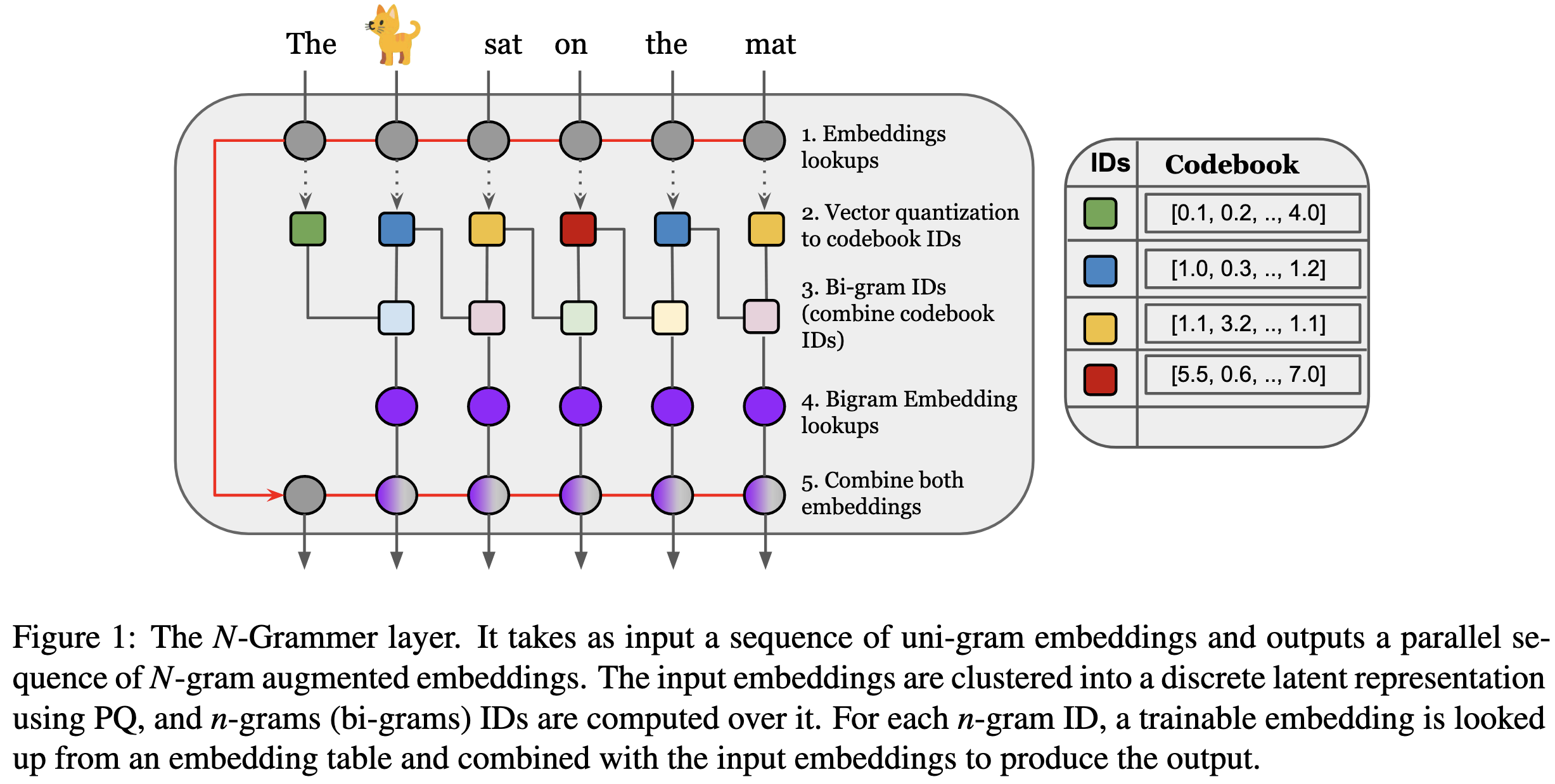
If you’re not familiar with product quantization, it’s basically just chopping your data up into disjoint subspaces and running k-means in each subspace. So each vector gets associated with a sequence of centroid IDs, one ID per subspace (figure below from my ICML paper).

So what they do is 1) apply PQ encoding on the embeddings, then 2) for each subspace, concatenate the IDs for each adjacent pair, treat this as a bigram ID, and do a lookup in a big table.
Since they’re using 4096 clusters for PQ though, and 16M embeddings per subspace is still too large, they use feature hashing to randomly share bigram embeddings. They use different hash functions for each attention head.
To combine the unigram and bigram embeddings, they just layer normalize them individually and then concatenate them along the feature axis.
In principle, one could apply their N-Grammer layer anywhere in the network, but they find that it works best at the input. This also has the benefit of allowing the PQ codes (or even the full unigram + bigram representations) to be precomputed for the whole vocabulary and looked up at inference time.

As we saw at the start, adding their layer yields better accuracy, even when controlling for training time. Although their ablations show that this only happens once there’s enough model capacity devoted to the centroids + bigram tables. Which makes me wonder how much of this is the inductive bias of bigrams per se vs exploiting the same principle as MoE layers and just throwing more params at the problem while avoiding extra runtime.