


2022-9-25 arXiv roundup: Metadata archaeology, Decaying pruning, 200x faster RL

This newsletter made possible by MosaicML. Btw, we’re looking for early customers who spend a lot on training neural nets for computer vision or NLP in PyTorch on cloud GPUs. Value prop is more accurate models, faster, at lower cost. Let me know by replying to this email if your team might be interested!
Metadata Archaeology: Unearthing Data Subsets by Leveraging Training Dynamics
Turns out that representing a sample as the time series of its losses over the course of training works ridiculously well for basically any analysis or error detection you might want to do.

Concretely, what they do is:
Construct data subsets with known properties. E.g., they randomly change the label to get mislabeled samples, add noise to get corrupted samples, etc. They also construct “typical” and “atypical” samples using the heuristic from this paper.

Check whether another sample has these properties by assessing the similarity of its training trajectory and those of the samples in these subsets. I.e., just construct a kNN-based time series classifier with a label for whether a sample is "corrupted,” “typical,” “mislabeled,” etc.

This works because the training trajectories are surprisingly consistent within these different subsets of samples.

This basic approach has tons of applications. For one, you can visualize your model’s predictions and find samples that might be mislabeled.

Going a step further, you can programmatically correct label noise better than methods designed specifically for this task.

In more detail, they replace the original labels with a convex combination of the original value and the model’s predicted label (argmax, not probabilities), The coefficient in the combination depends on the kNN classifier’s estimate of whether the sample is clean or noisy:
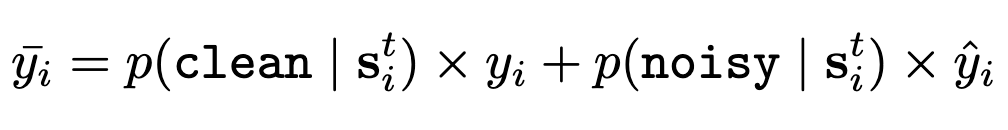
Lastly, they show that you can use their ideas to speed up training via sample prioritization. The way this works is that they do a full forward pass to get loss values for each sample in the batch, use these losses to compute a score for each sample, and then only backprop the 10% of samples with the highest scores. This means they have to do 10x as many forward passes as the baseline, imposing about (2/3 + 1/3*10) = 4x the cost per update1. But since they cut the number of epochs by 10x, it comes out to a ~2.5x speedup, assuming their score computation is free.

The score they use is just the average of 1) their method’s estimated probability of the sample being “clean”, and 2) the total probability assigned to incorrect classes for that sample.

Putting it all together, this is a super cool set of results. Watching kNN time series classifiers crush baselines on problem after problem makes me feel like I’m reading an old Keogh paper. And because time series classification is such a well-studied problem, I bet we could extend this paper’s approach pretty easily to get even better numbers—e.g., what if we just use DTW instead of Euclidean distance?
I also wonder how much of the (expansive!) time series data mining toolbox we could bring to bear on dataset analysis by representing samples as training trajectories. This feels like a SAX moment where we’ve reduced one datatype to another, easier type and thereby unlocked a ton of new possibilities.
Mega: Moving Average Equipped Gated Attention
They propose an attention variant that looks like an old-fashioned GRU cell, but with a multivariate exponential moving average and a single-headed attention unit thrown in.

They also propose to replace Primer-style ReLU^2 with a scaled erf function, with the latter set to approximate the former near zero.

Similar to FLASH, they chop up the input into chunks and only do quadratic attention within each chunk.

Seems to do better than some baselines across various tasks.
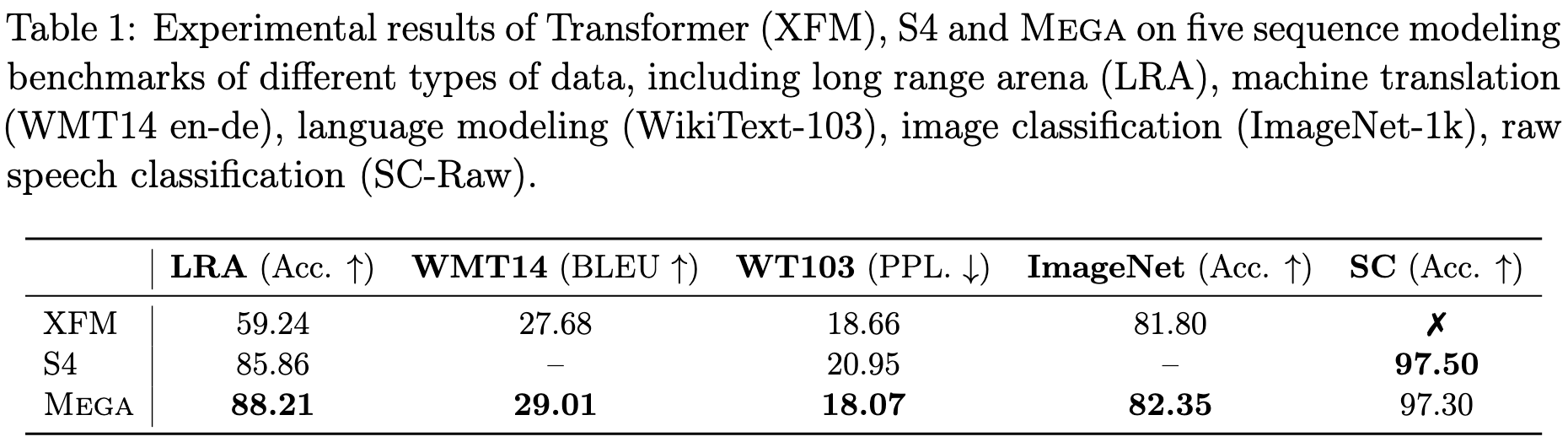
The main result I’m looking for is whether it beats S4 on Path-X. Everyone’s attention variant does ~1% better on whatever tasks they report (and then fails to replicate), but most variants fail completely on Path-X. This is because Path-X is a synthetic task designed to be impossible unless you actually capture long-range dependencies.

Encouragingly, they they beat everything they compare to at every LRA task, including S4 on Path-X. Although they require a lot more memory and time than S4, and apparently need a lot of task-specific hparam tuning:

They have some nice ablation experiments showing the effects of their design choices. Expanding the size of the latent space in the EMA helps up to a certain point, and using larger chunk sizes for the attention does better. Using their erf-based nonlinearity in the attention isn’t a consistent win.
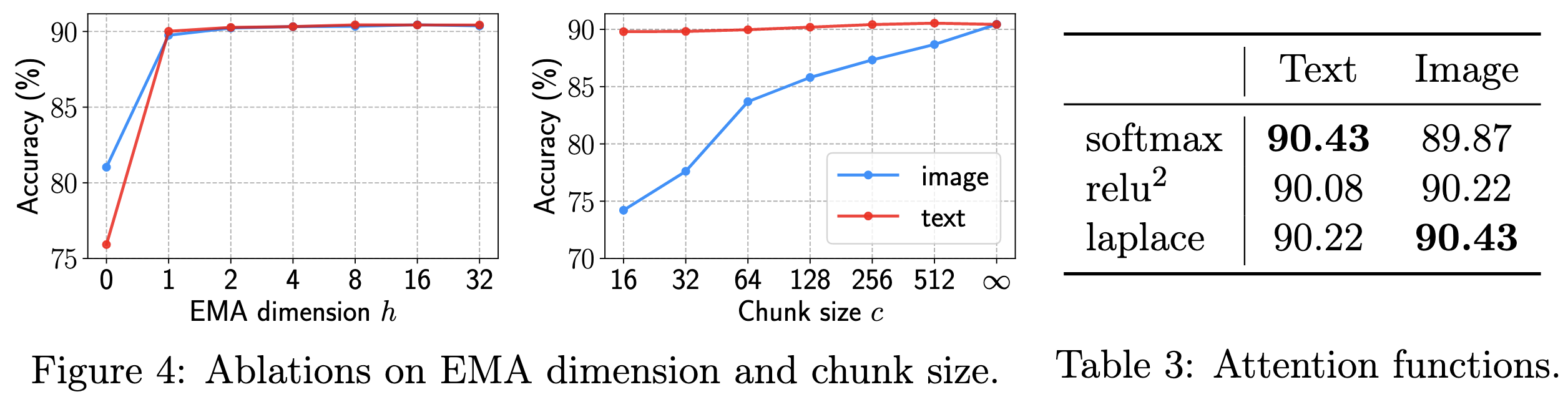
Overall, this is probably worth trying (along with FLASH’s GAU) as an attention substitute. Though I do worry about the difficulty of sequence-level parallelism with token-by-token EMA.
Equivariant Transporter Network
They make a neural network for pick-and-place that’s equivariant to the rotation of the object being picked and the placement target.

They don’t seem to control for model size or speed, but it appears they get consistent, large lifts in real-world success rate.

I don’t follow robotics much, but what’s interesting to me is that someone got a big lift from using an equivariant neural network. Historically, all the papers on invariant/equivariant neural nets were these esoteric documents only written by like two people and never really adopted. But this paper suggests that this line of work is both approachable and helpful enough to be used in practice.
SAMP: A Toolkit for Model Inference with Self-Adaptive Mixed-Precision
Tencent built an inference system that intelligently chooses int8 or fp16 for each FFN and MHSA block by looking at the induced speedup and accuracy degradation of switching to int8. You can hand it an accuracy requirement, an inference latency requirement, or neither (the last case gives you a reasonable mix of both). They also wrote a bunch of C++ code to make inference-time tokenization fast. They don’t say much about the details of the quantization so it seems to be some generic post-training quantization scheme.

I also like that the above figure highlights the batched GEMMs in self-attention. All the kernel people know about these but most ML people seem to have no idea that BMMs are even a thing.
Part-Based Models Improve Adversarial Robustness
If you structure your classifier such that one stage segments object parts and another stage uses these part segmentations to make class predictions, you end up way more adversarially robust than a regular old image classifier.

In a little more detail, they consider a few different families of part segmentation models and train them on datasets like PartImageNet that have object part annotations.

This will be hard to productionize since part annotations are super expensive and not currently available at scale, but it’s a cool proof of concept. It also suggests that carefully structuring one’s classifier can yield huge gains in adversarial robustness, which is a finding that we might be able to leverage in other, more scalable ways.
Psychologically-informed chain-of-thought prompts for metaphor understanding in large language models
Can language models understand metaphors? And does it help to give them chain-of-thought prompts? Yes to both.
They show the model a prompt like this, featuring 10 examples (only one shown) that provide step-by-step rationales for the right answer.

They also consider another prompt variant that focuses on the similarities of the entities being compared, rather than the “question under discussion” (used above).

Both variants work pretty well.

Interestingly, with no special prompts, one GPT-3 variant is really good at this task while another one is no better than chance. It’s not clear why.

I wish they’d compared to “let’s think step by step” and other general-purpose prompts. If their prompts do better than these, it suggests that future prompt engineering is going to be extremely task-specific if you want the highest possible accuracy.
Training Recipe for N:M Structured Sparsity with Decaying Pruning Mask
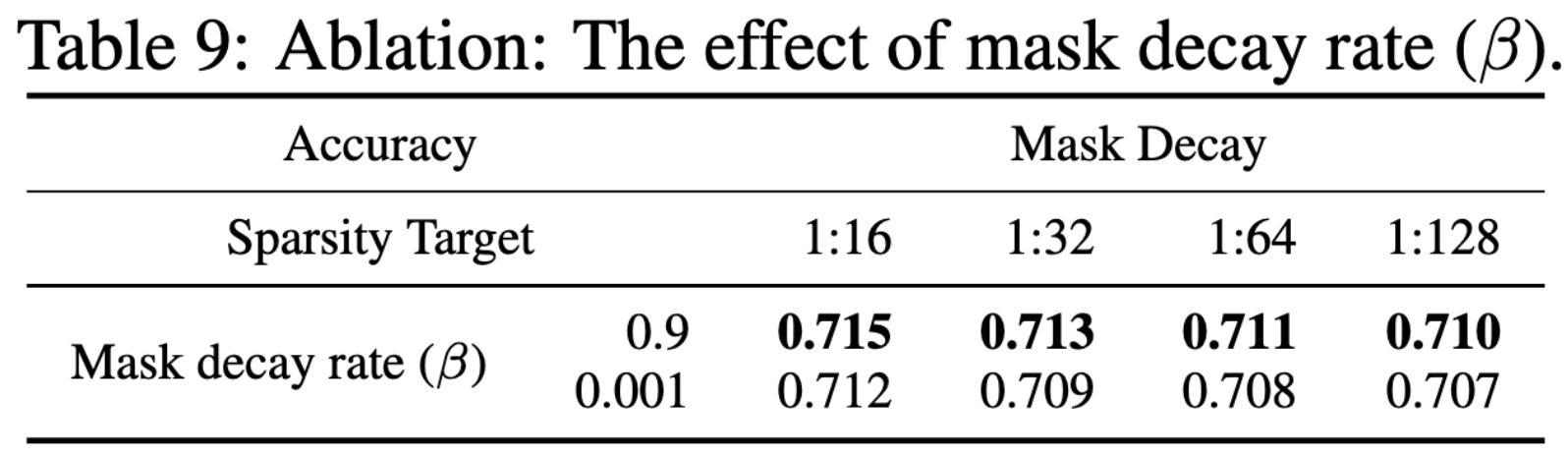
They propose to gradually decay sparsity masks to 0, rather than set them to 0 immediately. They use magnitude pruning, N:M sparsity in just the transformer FFNs, and post-training finetuning. As with most pruning papers, the main lessons are in the ablation experiments.
First and foremost, decaying the mask slowly (.9), rather than immediately (.001), improves final accuracy.
They also find that their overall approach works better with N:M sparsity than various alternatives.

Less surprisingly, they find that having some initial dense training is essential.
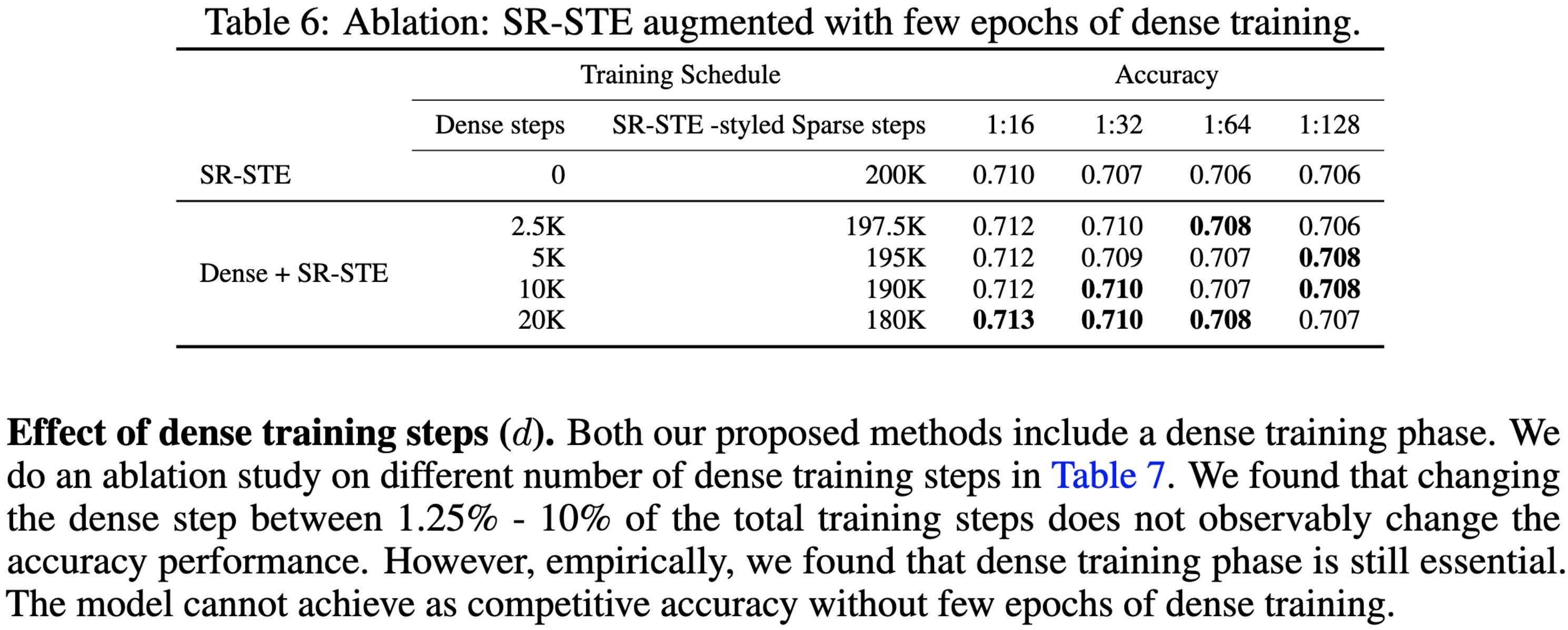
As is some amount of finetuning:

I’ve suspected that gradual decay of pruned weights is beneficial for a while (based on some papers I’ve reviewed but can’t find publicly…), and it’s great to see strong empirical work confirming this in at least one setting.
Human-level Atari 200x faster
DeepMind introduces MEME, an agent that trains to human level in Atari games way faster than previous alternatives.


The high-level components of this speedup are:
Architecture changes
Better learning from rare events
Stability in the presence of different value scales
Robustness to rapid changes in the policy
They also have good ablations showing the impact of each of their changes, at least on a subset of the games.
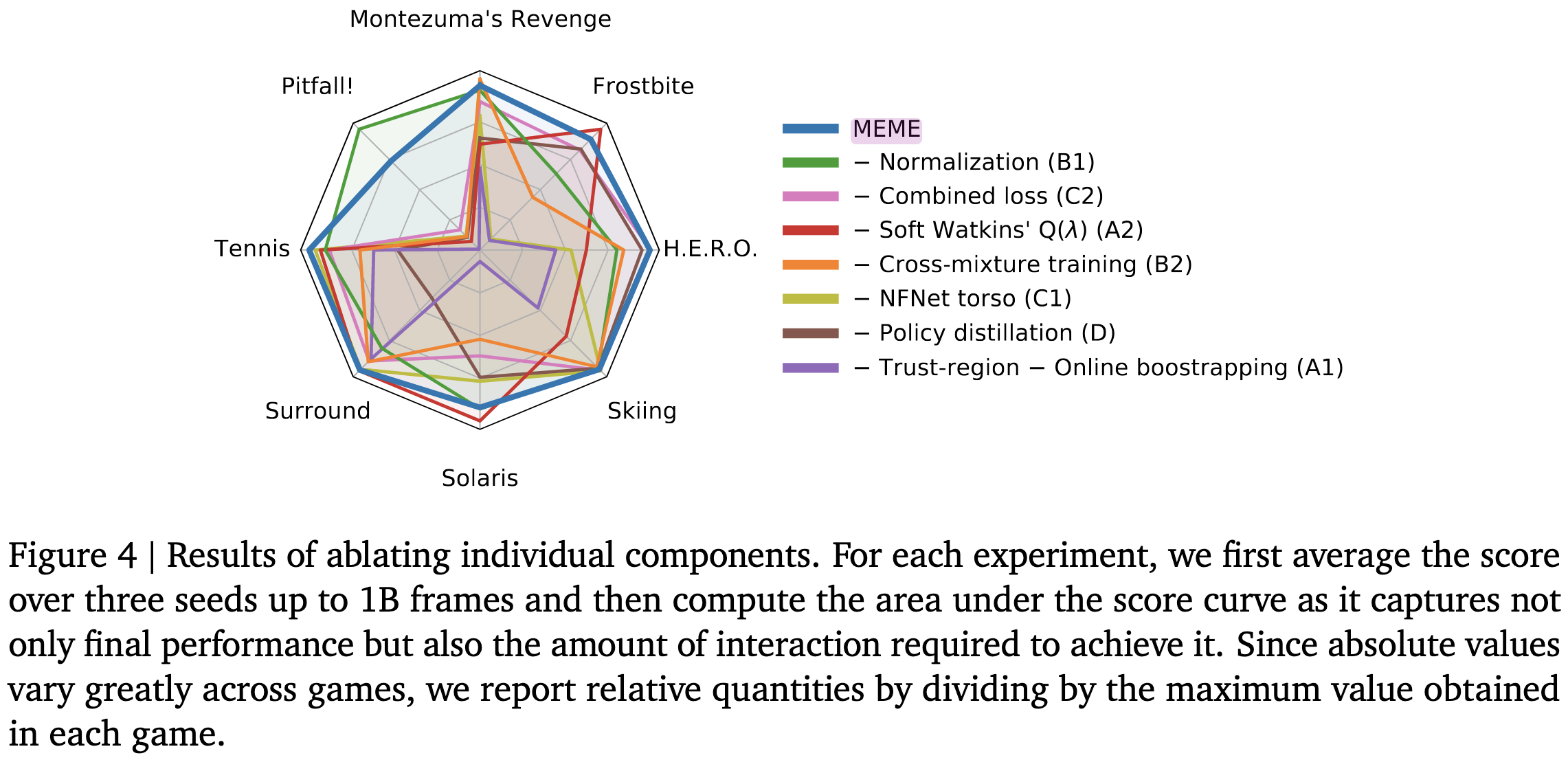
I don’t follow RL too closely, but it’s surprising that so much speedup is possible—especially on a well-studied benchmark. Suggests this field is still in its infancy / far from converging on best practices.
On the Relation between Sensitivity and Accuracy in In-context Learning
In-context-learning predictions that are more sensitive to the details of the prompt are more likely to be wrong.

Yet another weirdly linear pattern in neural net eval accuracy.
Nesting Forward Automatic Differentiation for Memory-Efficient Deep Neural Network Training
They propose to just compute and save the derivative of the activation function during the forward pass, rather than save the input to the activation function or, worse, all the intermediate variables when using an unfused implementation.

As far as I know, just saving the derivative is what every sane fused kernel does already—except piecewise linear activation functions like ReLU, which can get away with saving a single bit to indicate which regime they’re in.
I do like their measurements of memory consumption for different models and activation functions though.

These numbers are so large that they’re clearly using unfused kernels. You can tell because there’s always another (trainable) op of the same input size following a GELU, so it shouldn’t be possible for fused GELUs to require more than half the activation memory.
So what this really shows is how incredibly memory-hungry unfused activation functions are, which is a valuable datapoint.
Below are some papers from MLSys 2022 I’ve been meaning to read.
Bolt: Bridging the Gap between Auto-tuners and Hardware-native Performance
First of all, am I nothing to you?
But more seriously, they wrap CUTLASS with an operator fuser, profiling-based autotuning, and a codegen module.


They also argue for system-model codesign, meaning we should stop doing dumb stuff like having 7x7 activations.
They get good speedups by fusing activations and biases into convs / GEMMs.

They also get good speedups when fusing pairs of small GEMMs, especially with tall, skinny matrices.

Same for Conv2D ops:

Thanks to the wonders of peer review, this didn’t get published until similar optimizations were already available in CUTLASS itself and TVM. But it’s still great to see strong empirical work showing the value of these sorts of ideas.
This paper is also helpful as a supplement to the CUTLASS docs. E.g., I didn’t know until reading this that CUTLASS supports partial reduction over columns in its GEMM epilogues.
Towards the Co-design of Neural Networks and Accelerators
NAS for Edge TPUs, including searching over the design of the accelerator. They find that FLOP and param counts suck as metrics, and you have to choose your search space based on what hardware is good at to get a good {time, energy} vs accuracy tradeoff.

Here’s the search space for their accelerator design:

Searching over both hardware and architecture lets them do better than other methods that fix the hardware (even if those methods take into account hardware characteristics).

I’m not really surprised that jointly optimizing over more variables helps, but getting something like this to actually work is probably pretty hard.
Most people aren’t going to be customizing their hardware in any meaningful way, but I’d curious to see if similar ideas could be applied at the system integration or datacenter level—i.e., for designing racks, not chips. This might be even more promising since part selection has a much lower commitment and faster cycle time than ASIC design.
VirtualFlow: Decoupling Deep Learning Models from the Underlying Hardware
They point out that current deep learning frameworks couple your code to the number of physical devices. E.g., if you want to simulate running on your full cluster from your local machine, you’re probably gonna OOM, or at least not get the same behavior.

They propose to instead target “virtual” nodes, which can get time-multiplexed onto a lesser number of physical accelerators. So, e.g., you run your training script with 128 “devices,” and it executes with those semantics on your single GPU.
You can also get a better fault tolerance / resource elasticity story because virtual nodes can just run on different physical nodes when some physical nodes go down or become available.
Most of the other benefits they’re targeting can be achieved with automatic gradient accumulation and/or ghost batch normalization, but the elasticity aspect is interesting.
They have each accelerator cache the model weights, gradient-so-far, and (I assume?) optimizer state; to start simulating a different virtual node, they just have to swap out the input activations.

To adjust the set of available nodes, they have the master scheduler change the mapping of virtual nodes to physical nodes; this doesn’t recover information from a dead worker, but does let you keep training. It can also increase your cluster utilization.

Another cool aspect is that they can schedule different numbers of virtual nodes on different devices, so you could train on heterogeneous GPUs without stragglers.

And lastly, they can start jobs sooner because they don’t need the full number of physical nodes to be available to start running the job.
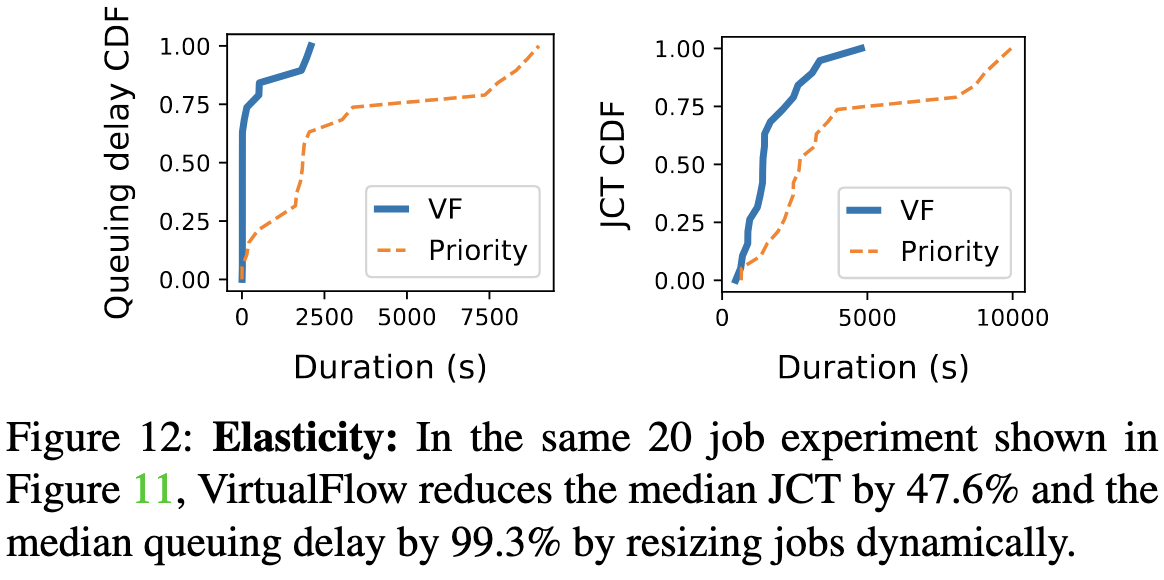
Personally, I don’t think this is the right abstraction to expose to users—it’s not clear what the tradeoffs are when selecting a virtual node count, and I probably just want the semantics of training on a single GPU regardless.
But from a backend perspective, this is really interesting. Good elastic scheduling is a big deal if you own the hardware, and this seems like a nice abstraction for this problem. I am worried about the speed overhead, the added complexity, and the coupling to distributed data parallel training (what about expert, pipeline, or tensor parallelism? How do I shard everything?). But overall, this paper expanded my thinking about the systems side of ML training, which is both rare and awesome.
Recall that the forward pass takes about half as long as the backward, and thus ~1/3 of the time.
Figure 1 of "Human-level Atari 200x faster" is not visually clear about the speedup of MEME. IMHO, authors shoud change the chart to be a "side-by-side bar chart" instead of "stacked bar chart". The way it is presented may give the interpretation that the total bar is a "sum" of the orange bar with the blue bar, which apparently it is not the case: my interpretation (for the legend works) is that the orange bar has the size of the blue bar plus an "additional orange size". That's really not trivial for a stacked bar chart.