2022-11-27 arXiv roundup: Multimodal retrieval, int8 and int4 LLM quantization

This newsletter made possible by MosaicML.
Random-LTD: Random and Layerwise Token Dropping Brings Efficient Training for Large-scale Transformers
They propose randomly dropping some fraction of the tokens for each transformer block except the first and last ones.

They also propose to linearly decrease the fraction of tokens dropped throughout training, which apparently improves both speed and final perplexity.

Their simple method actually seems to reduce training time without hurting accuracy.


Surprisingly, they don’t even need special treatment for tokens like [CLS] as long as the first and last layers are preserved.

Nice to see a straightforward method yielding a wall-time speedup.
SinFusion: Training Diffusion Models on a Single Image or Video
They train a diffusion model to generate variants of an image or video after training on only that image/video.

To get this working for images, they treat various crops of the image as the training data.

For good results, they find that they have to reduce the receptive fields most of their model has access to. They do this by avoiding spatial downsampling and attention, instead just cascading a bunch of ConvNext blocks with skip connections.

After training on enough crops, they can do pretty good image editing:

For video, they decompose the problem into three subproblems, each with their own model.

These models let them extrapolate future (or past) frames of video, upsample videos, and more.

The downside is that “training on a single 144 × 256 image takes about 40 minutes on a single V100 GPU.”
Who Says Elephants Can't Run: Bringing Large Scale MoE Models into Cloud Scale Production
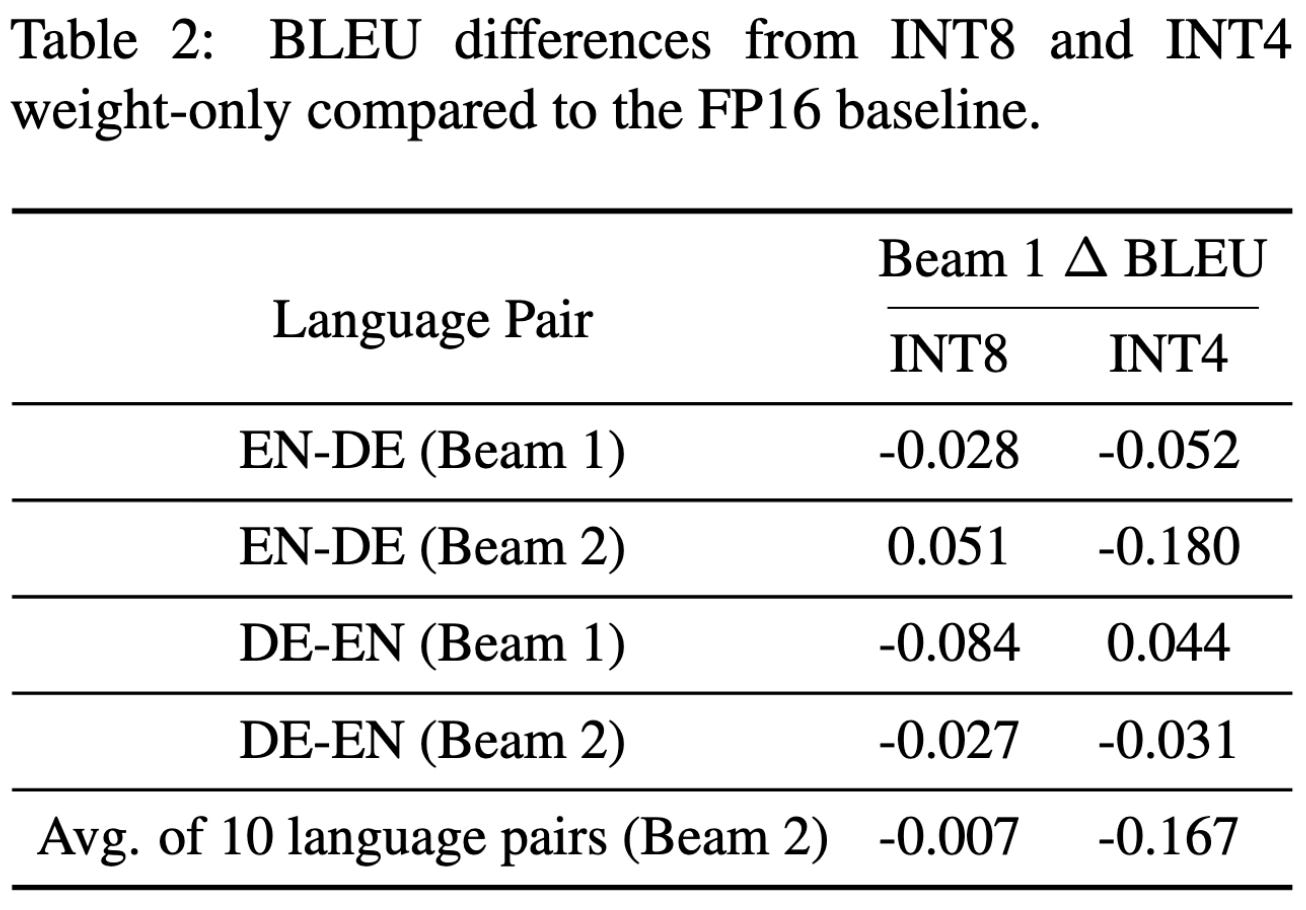
They added quantized, single-GPU mixture-of-experts inference support to FasterTransformer. This entailed building a few clever optimizations.
First, rather than have separate ops for each expert, they horizontally fuse all the experts into one big grouped matrix product. This is like a batched matmul, except that the sizes of the matrices can vary. You need support for variable matrix sizes since a different number of tokens might be routed to each expert.

As far as quantization, there are a bunch of ideas here:
They only keep the weights quantized at rest, converting to f16 at the start of their matmul kernels. This saves memory and memory bandwidth but doesn’t speed up the compute.
They only quantize the weights (not activations), and only within the experts. This makes sense since the experts are >90% of the weights and the activations likely take little memory bandwidth during inference.
They use a different scale to quantize each column of each weight matrix and a fixed offset of 0 (symmetric quantization).
To convert between ints and floats quickly, they do some cool bit trickery I haven’t seen before. It’s roughly:
def int_to_f16(x: uint8) -> half: return (0x6400 | x) - (1024 + 128) # 128 to convert uint -> int def f16_to_int(x: half) -> uint8: return 0x6400 | (x + 128 + 1024)The
0x64 = 0 11001 00byte is a sign of 0, an exponent of 10 (25 - the f16 exponent offset of 15), and two 0 bits of mantissa. With the exponent equal to the number of mantissa bits, the mantissa bits act like a regular unsigned int.
Even though it doesn’t let them use int8 or int4 tensor core ops, this quantization still nets them sizable speedups. This is mostly because MoE models are memory bandwidth bound unless your batch size is huge enough to route 1000+ tokens to each expert.

The quantization causes a tiny but nonzero accuracy loss.
They also optimize away a lot of the padding tokens. They do this by “routing” them to a virtual expert with a huge index, grouping them all together at the end so that they can then just slice the tensor to ignore them.
These optimizations together get them good deployment costs, although it’s not clear what the baselines are.

Cool work overall—it’s rare to see a new and general bit hack, and awesome that they got decent accuracy with int4 quantization.
TorchScale: Transformers at Scale
This is mostly just Microsoft announcing that they wrote a new library in the same vein as DeepSpeed, Megatron, FairScale, etc—though seemingly more opinionated about what you train with it.
What I found interesting is their alternate gradient clipping for MoE models.

Basically, they point out that your gradient norm tends to increase with your expert count. Apparently this is bad, so they downweight the contribution of the experts to the norm by a factor equal to the square root of the expert count.

You Need Multiple Exiting: Dynamic Early Exiting for Accelerating Unified Vision Language Model
They specialize early exit for multimodal models. When you have an encoder for each modality’s input and you’re trying to align the representations, they argue you can early exit each modality’s encoder once the representations are similar enough. They also early exit in the decoder.

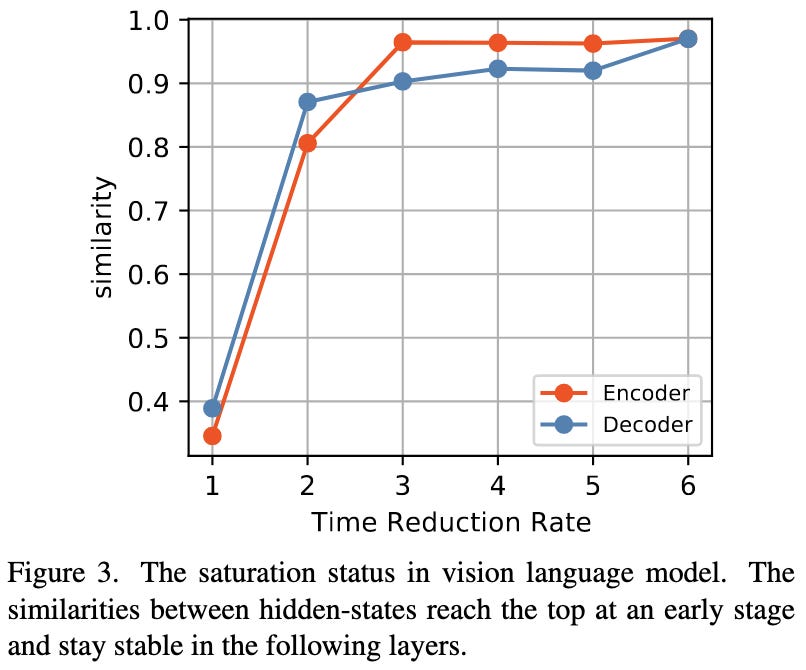
For certain tasks, this approach saves more inference time than existing methods.

Path Independent Equilibrium Models Can Better Exploit Test-Time Computation
Let’s say you have an equilibrium model, meaning a model where you iteratively apply some chunk of it over and over again until the activations converge to a fixed point. One cool use of a such a model is to iterate longer for harder test inputs.
This can let you do stuff like generalize to solving longer mazes than you saw during training.

It turns out a great indication of how well this will work is the “path independence” of the model—i.e., how reliably it converges to the same activations for a given input.
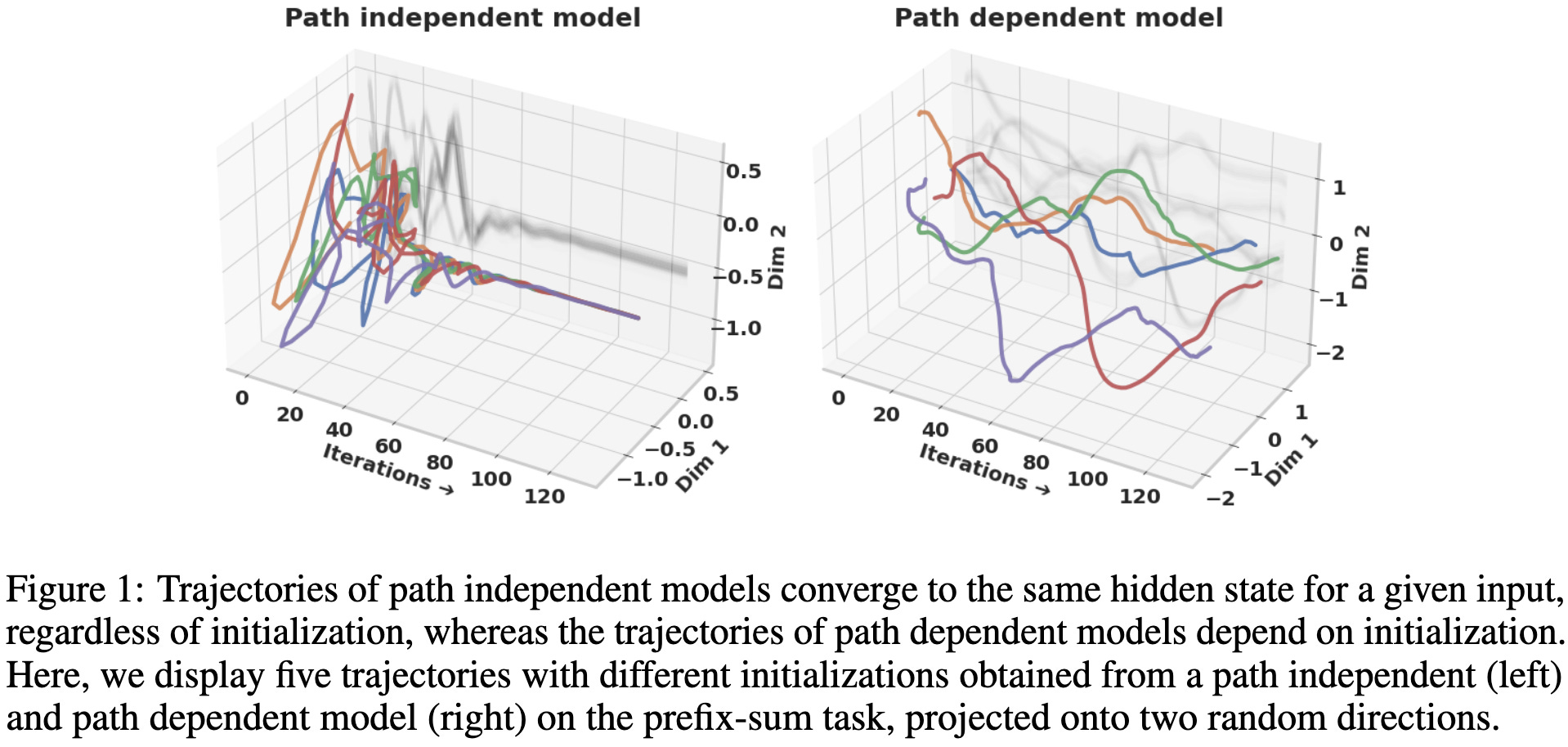
The path independence is a good log-linear predictor of accuracy in the tasks they consider.

I’m still not sure equilibrium models are ready for production, but they’re sure appealing from a computational perspective. This is because they let you a) adapt the amount of computation to each sample, and b) use the implicit function theorem to decouple your FLOP count from your activation memory.
Plus, my inner cognitive scientist finds the prospect of letting models “think” longer about harder inputs super appealing.
Overall, interesting findings and experiments that taught me something new about an interesting class of models.
SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models
They do post-training quantization of huge language models with only a tiny amount of accuracy loss. Moreover, they actually get wall-time speedups.

The observation they exploit is that you can simultaneously scale down the activations and scale up the weights such that the function is preserved. Since activation tensors have huge outliers but weights are pretty well-behaved, this can get you two good tensors instead of one great one and one terrible one (which is an improvement).

Concretely, they compute activation statistics using a few sequences and then use these to scale down the activations and scale up the weights such that the worst-case outliers are minimized.

There are a few different ways to structure your quantization. For the lowest quantization error, you want the most granular quantization (per-token or per-channel). But for the highest speed, you want the coarsest quantization (per-tensor).

They explore quantization using different granularities, denoted SmoothQuant-01 to -03, in increasing order of coarseness + speed.

All of these variants cause minimal accuracy loss, with the most granular tending to preserve more accuracy than the least granular.


In terms of runtime, their fastest variant is consistently faster than either the f16 baseline or LLM.int8().

Interestingly, even the slower variants of their method still run faster than both of these alternatives, despite not fusing into GEMM kernels well.

Exciting to see post-training 8-bit quantization working (seemingly) reliably for huge language models, especially when the underlying idea is so simple and elegant.
Indexing AI Risks with Incidents, Issues, and Variants
The authors have been maintaining an online, human-readable database of real-world “incidents” involving AI—think self-driving car crashes, recommender systems showing bad stuff to kids, content moderation algorithms censoring creators they shouldn’t have, etc. It’s mostly a bunch of links to news articles with some structured data attached.
I’m a big fan of grounding the AI safety discussion in concrete problems and data, and it’s great that some people are putting in the work to maintain this resource.
Improving Multimodal Interactive Agents with Reinforcement Learning from Human Feedback
DeepMind trained an agent with a reward signal inferred from human labels of helpful and unhelpful behavior. They start off with behavior cloning, telling it to just do what a human would, and then finetune it based on labels collected offline.

The labels are binary feedback about what the agent is doing at a given time step. The human raters see video from the agent’s point of view in its virtual environment, along with its latest instruction.

Given these labels, they construct a simple reward model that outputs positive values at points with positive labels and vice-versa, with sensible interpolation across time steps.

Adding a period of finetuning with this reward signal consistently improves results vs just behavior cloning, often doing about as well as humans.
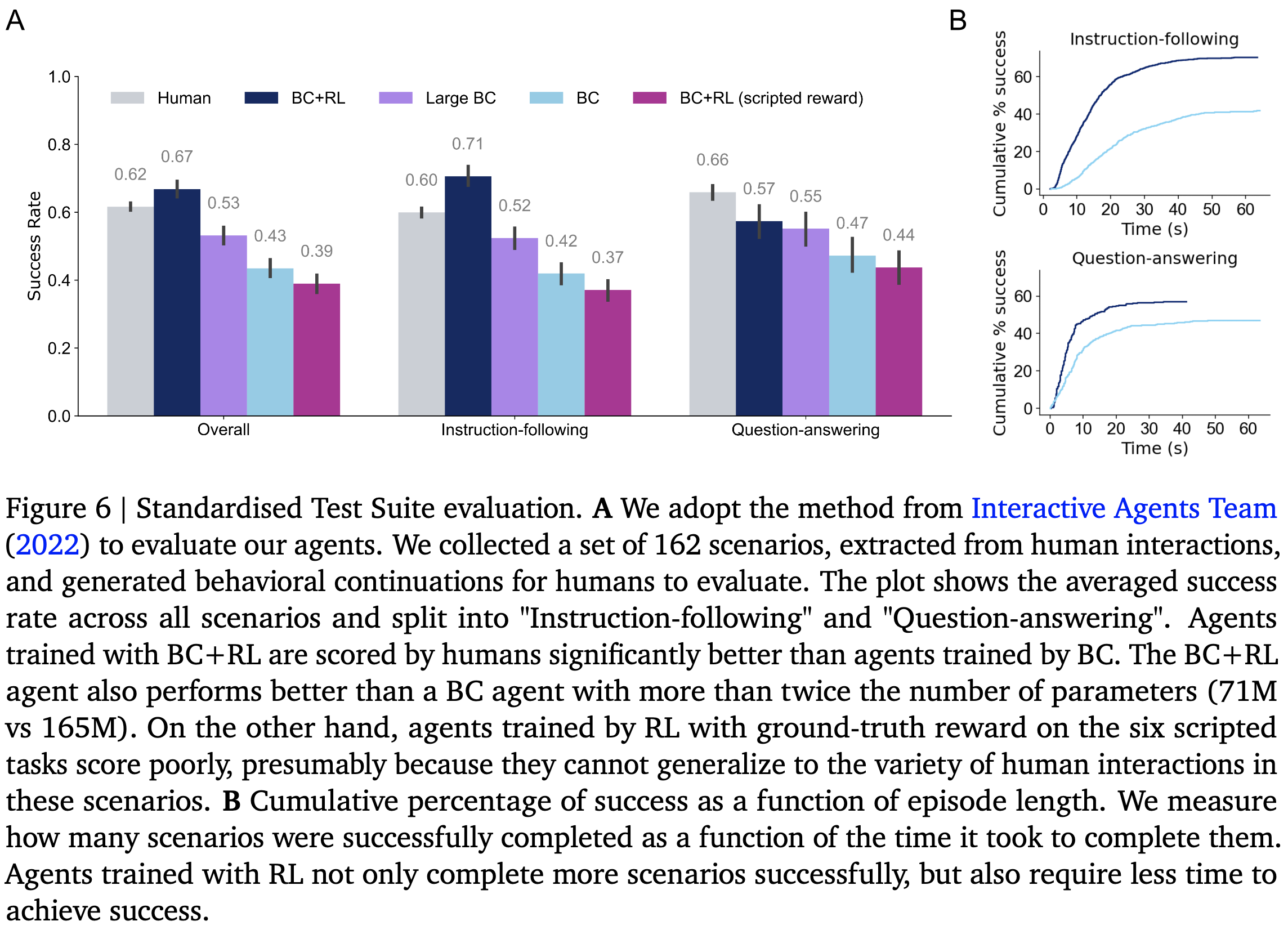

You can also iterate this whole process to get better results, updating your agent and labeling more data each time.

If you want to understand the environment and tasks more fully, here’s a video of the agent running around doing various tasks:
I find this paper interesting on two levels.
First, it might be a story for how we get RL to work better and more reliably, which maybe (?) could lead to more widespread adoption.
Second, it’s interesting from an AI safety perspective. On the one hand, it’s pretty hard to argue against ideas like instrumental convergence1. On the other hand, papers like this suggest that maybe we're overcomplicating things and you can just tell your agent to do what you want.

Retrieval-Augmented Multimodal Language Modeling
They use embeddings from a pretrained CLIP model to find similar multimodal documents and use these to inform their model’s output. The retrieved documents are filtered for excessive similarity to the query to avoid duplicates, and their image tokenizer represents images as 1024 tokens.

To use the retrieved images + text, they just add them to the input, essentially doing in-context learning. Although unlike with in-context learning, they also compute (downweighted) loss terms for each of these retrieved tokens. They argue that this offers more training signal per input sequence and avoids wasting computation. They also randomly drop out tokens from the query sequence during training to encourage diversity in the retrieved documents.

Their method lets them generate higher-quality images than alternatives with way less training compute.

Their model + retrieval mechanism together allow them to do a variety generative tasks.

For example, their model lets them generate compositional images much better than baselines—e.g., images containing two or more distinct entities.

They can also infill images with missing sections really well.

Using this infilling capability, you can do image editing—just crop out the part you want changed. To control the changes, you can directly supply the “retrieved” images.

Yet another example of retrieval working really well. I especially like the ability to let users specify related images to steer the generation—this feels like something that will become a standard feature in generative AI tools.
NEVIS'22: A Stream of 100 Tasks Sampled from 30 Years of Computer Vision Research
They assembled a collection of 100 diverse image classification datasets, sampled from computer vision workshop and conference proceedings over the past 30 years.

Since image classification is an easy task to work with, hopefully this will help us assess how well proposed methods generalize. E.g., I could see reporting average NEVIS score becoming a standard practice analogous to average GLUE/SuperGLUE results.
One Venue, Two Conferences: The Separation of Chinese and American Citation Networks
Authors from the US, Europe, and China tend to cite within their region more often.

It’s not totally clear why. They conjecture that some of this is a matter of which problems are popular in each region—e.g., Chinese authors are massively overrepresented in the person reidentification literature and underrepresented at “fairness, accountability, and transparency” conferences.
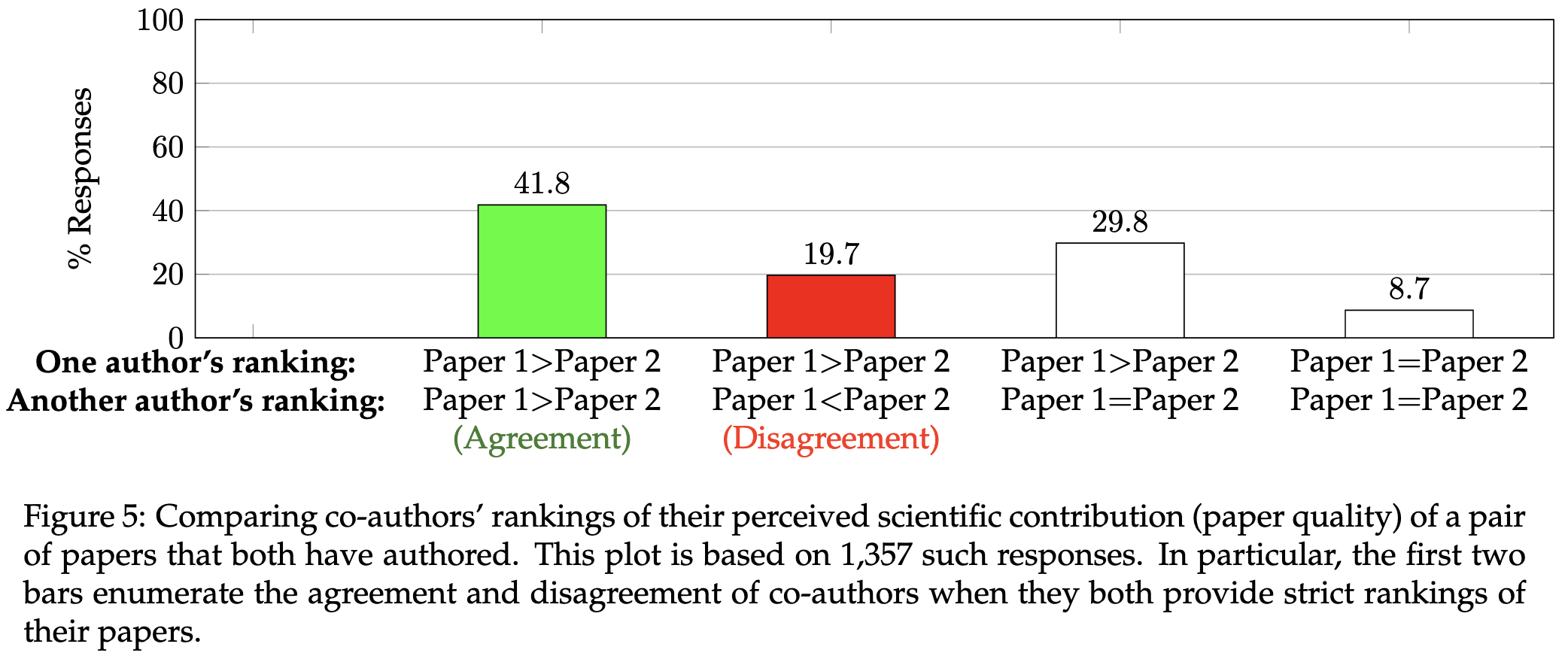
How do Authors' Perceptions of their Papers Compare with Co-authors' Perceptions and Peer-review Decisions?
They did a big survey of authors submitting papers to NeurIPS to assess how well author perceptions match reviewer perceptions.
First, authors massively overestimate the chances of their papers getting accepted.

Your estimated probabilities tend to improve as you get more involved in the peer review process for a given venue, but they never get great.

However, authors are pretty decent at estimating the relative probabilities of their different papers getting in.

Perhaps most discouragingly, even coauthors often disagree on the quality of their own papers. This suggests that randomness in peer review is not just a product of reviewers failing to “correctly” evaluate a paper, but also a product of there existing no universal standard of correctness. If even coauthors aren’t consistent, how can reviewers be?