
2022-1-23: DeepSpeed-MoE, Guided layer freezing, Low-pass filtering SGD

⭐ Efficient DNN Training with Knowledge-Guided Layer Freezing They claim 19-43% training speedup at iso accuracy via layer freezing. The freezing is guided by using a small proxy model on the CPU that helps estimate each layer's plasticity. They cache the activations for frozen layers to avoid even doing the forward pass through them, and report results on ResNet-50, BERT, and other useful networks.
⭐ DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale Contributes "novel MoE architecture designs and model compression techniques that reduce MoE model size by up to 3.7x, and a highly optimized inference system that provides 7.3x better latency and cost compared to existing MoE inference solutions." There add a lot of optimizations to make this happen:

First, their model (illustrated above) makes two changes to normal MoE architectures: it adds a fixed MLP in parallel with each set of experts, and increases the expert count as you get deeper into the network.
The latter change is based on results showing that MoE modules help more in the second half than the first half of the network:
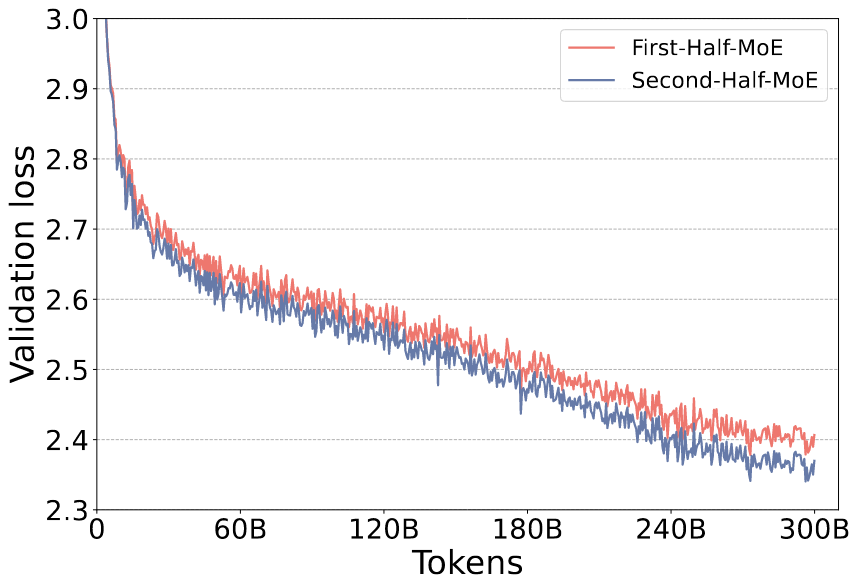
To support these architecture changes, they did some hardcore systems work to allow hybrid expert + data parallelism with variable expert counts. They have each GPU handle one expert, which low-expert-count layers replicating a given expert across multiple GPUs in a data-parallel setup.
Another innovation is switching back to the true labels at the end of distillation. They find that, without this, the distilled model plateaus after a while and doesn’t reach parity with the teacher.

Finally, they have a *lot* of systems optimizations to support inference. This is partially CUDA kernels and partially parallelism schemes (e.g., a “Hierarchical AlltoAll Design”).

Paper: https://arxiv.org/abs/2201.05596
Learning Enhancement of CNNs via Separation Index Maximizing at the First Convolutional Layer Little hard to read, but they basically use PCA on the inputs to set the weights in the first conv layer, and then freeze that layer. They use the eigenvectors and negatives of the eigenvectors as weights so that info gets preserved even with ReLU. Apparently yields 0.28% higher Top-1 accuracy on ResNet-50 + ImageNet. Little skeptical, but might be an easy win.
TerViT: An Efficient Ternary Vision Transformer I don't really believe in ternary quantization, but they report some promising results on ImageNet.
⭐ Low-Pass Filtering SGD for Recovering Flat Optima in the Deep Learning Optimization Landscape Compute gradient at a perturbation in weight space instead of current weights. Similar to SAM, but picks a random direction and increasing step size during training, rather than the gradient direction and a fixed step size (see Algorithm 4.1 and surrounding text).
Building a Performance Model for Deep Learning Recommendation Model Training on GPUs By breaking down device idle time and active time, along with a number of other changes, they manage to do DLRM training throughput within 10% of true values. Harder than predicting throughput for compute-bound workloads, which most similar work focused on.
The Role of Permutation Invariance in Linear Mode Connectivity of Neural Networks "we conjecture that if the permutation invariance of neural networks is taken into account, SGD solutions will likely have no barrier in the linear interpolation between them. Although it is a bold conjecture, we show how extensive empirical attempts fall short of refuting it. We further provide a preliminary theoretical result to support our conjecture."