
2022-11-20 arXiv roundup: The many pitfalls of FLOPs, RL in production, A learned optimizer that "just works"

This newsletter made possible by MosaicML. Also thanks to @cwolferesearch and @CorinneMRiley for mentioning it on Twitter!
(Substack doesn’t have a table of contents function, so, I’m trying out just manually pasting links. Let me know if you like this.)
Compute-Efficient Deep Learning: Algorithmic Trends and Opportunities
Breadth-First Pipeline Parallelism
Large Language Models Struggle to Learn Long-Tail Knowledge
Controlling Commercial Cooling Systems Using Reinforcement Learning
Scalar Invariant Networks with Zero Bias
How to Fine-Tune Vision Models with SGD
Holistic Evaluation of Language Models
EfficientTrain: Exploring Generalized Curriculum Learning for Training Visual Backbones
VeLO: Training Versatile Learned Optimizers by Scaling Up
InstructPix2Pix: Learning to Follow Image Editing Instructions
Compute-Efficient Deep Learning: Algorithmic Trends and Opportunities
We wrote a big ol’ survey paper on efficient deep neural net training. There are three main contributions here.
First is just collecting and categorizing a lot of papers on efficient training. We didn’t capture all of them, but there’s a good selection that should give you a feel for what’s out there.
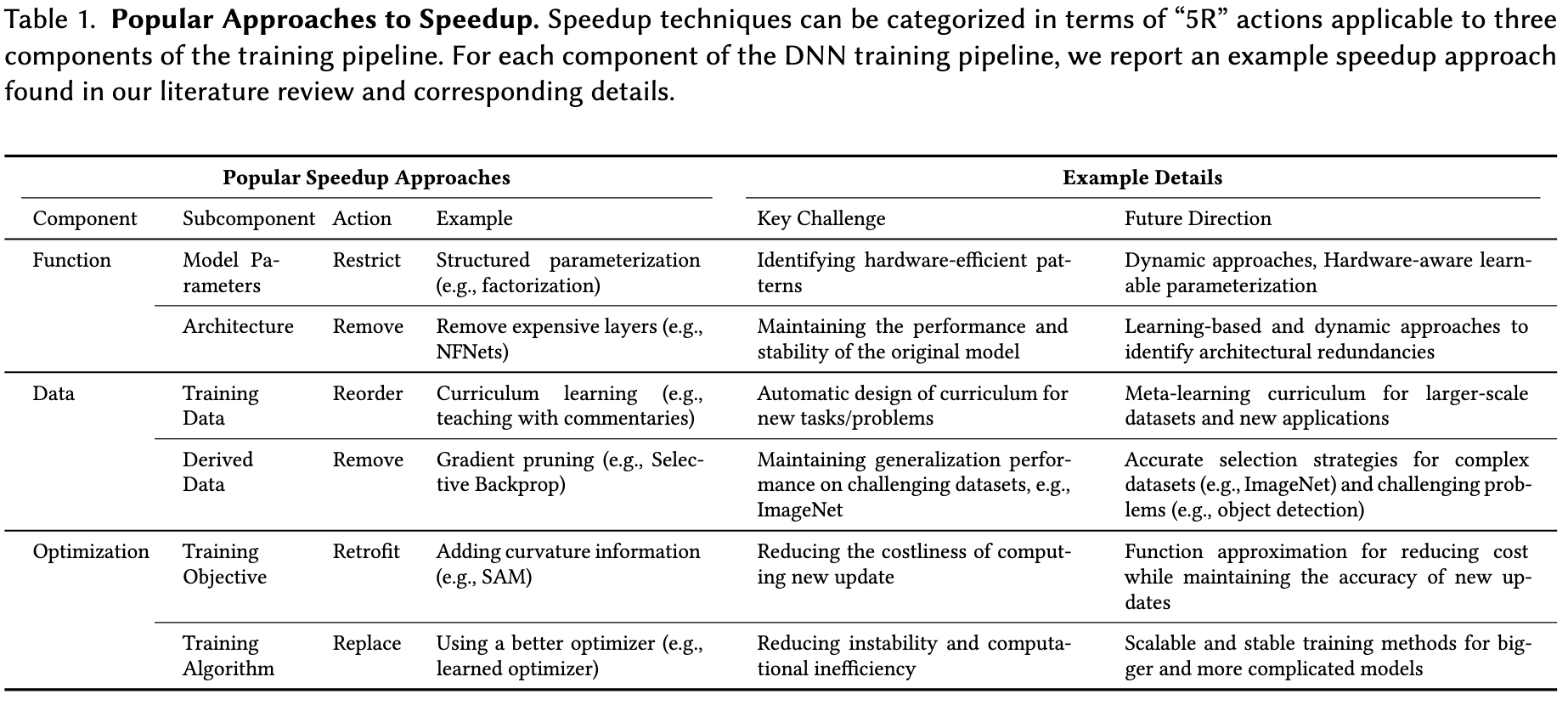
Second, we have a taxonomy of training speedup approaches to help make sense of the vast literature. We break down what “component” of training is affected (“function,” “data,” or “optimization”), as well as how it’s getting modified.
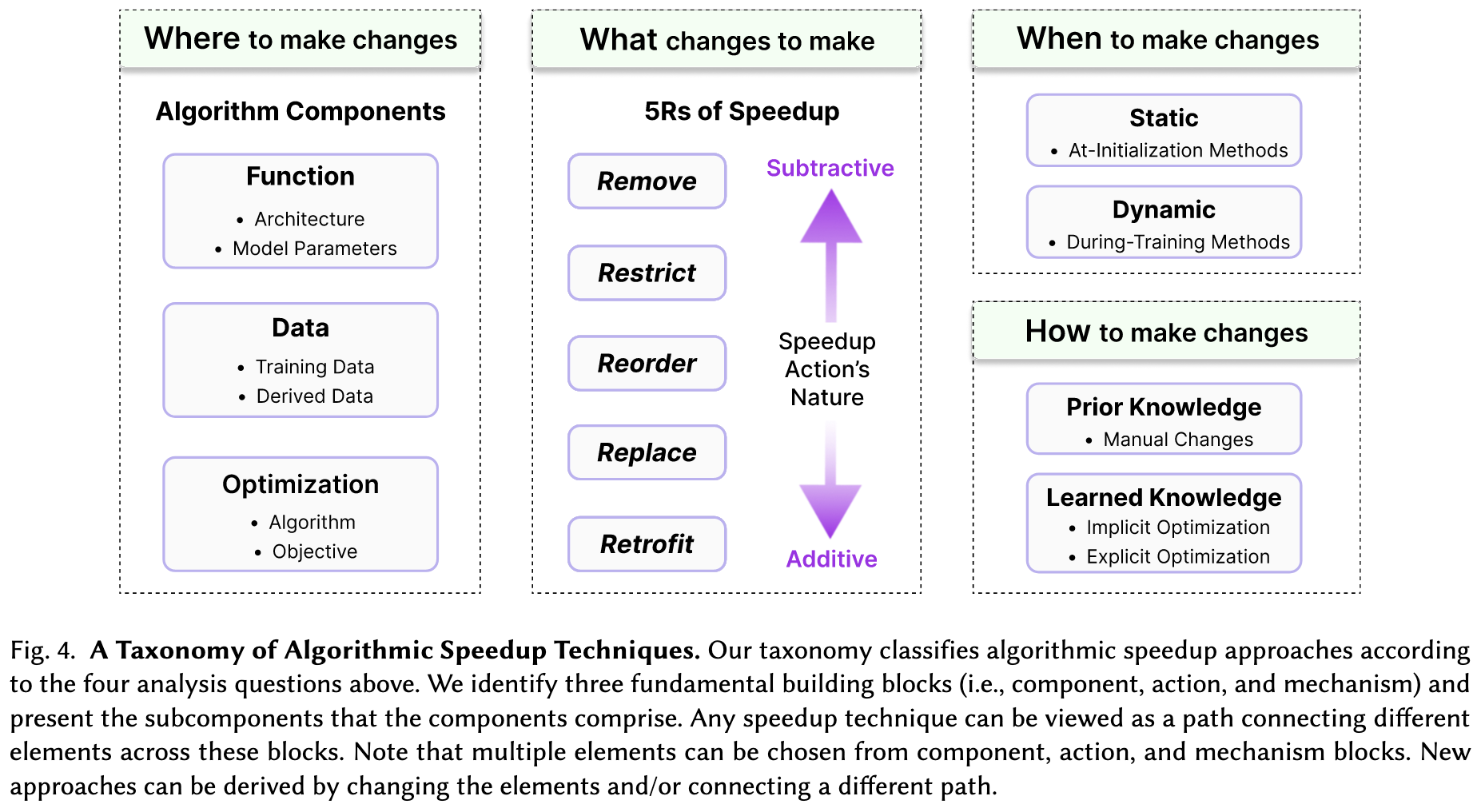
Third, we have a bunch of experiments highlighting evaluation pitfalls. I’m going to focus on this part since it has pictures.
First of all, you need to be really careful with FLOPs. Some FLOPs are 10x more expensive than others. Only when doing large matmuls/convs do FLOPs become a decent proxy for anything.

In fact, FLOP counts may not even be monotonically related to speed. E.g., low-rank factorizing all the convs in a ResNet-50 makes it slower.

Second, just training for less time is a ridiculously strong baseline. Provided that you go through the full learning rate schedule (and don’t just look at your accuracy partway through training), almost nothing beats it.

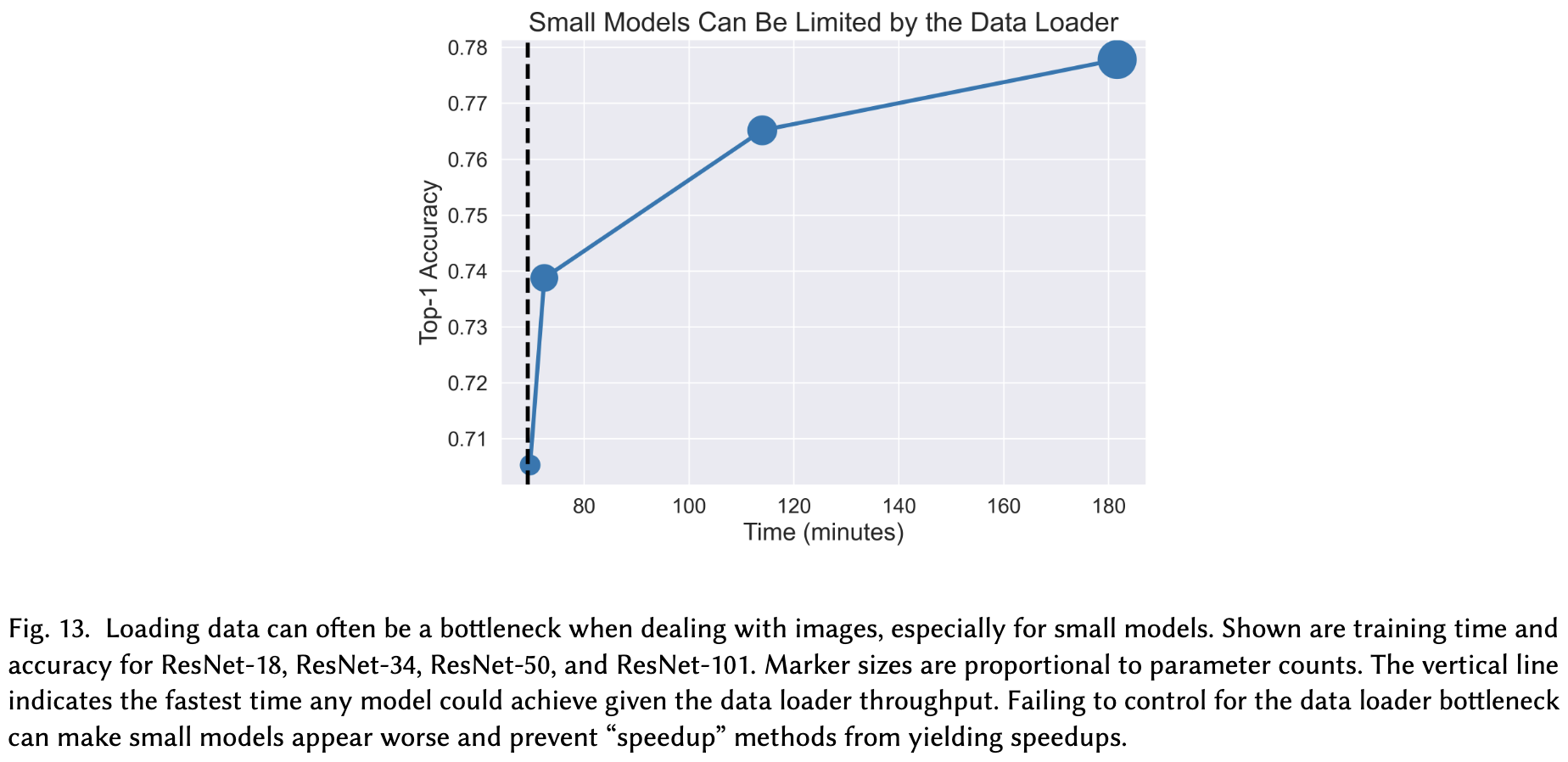
Third, you need to watch out for dataloader bottlenecks. If you’re training an image classifier and you’re not sure if your training speed is limited by the dataloader, it is. This not only wastes compute, but also artificially penalizes fast models—e.g., your method might not seem slower, but that’s just because your dataloader is hiding the slowdown.
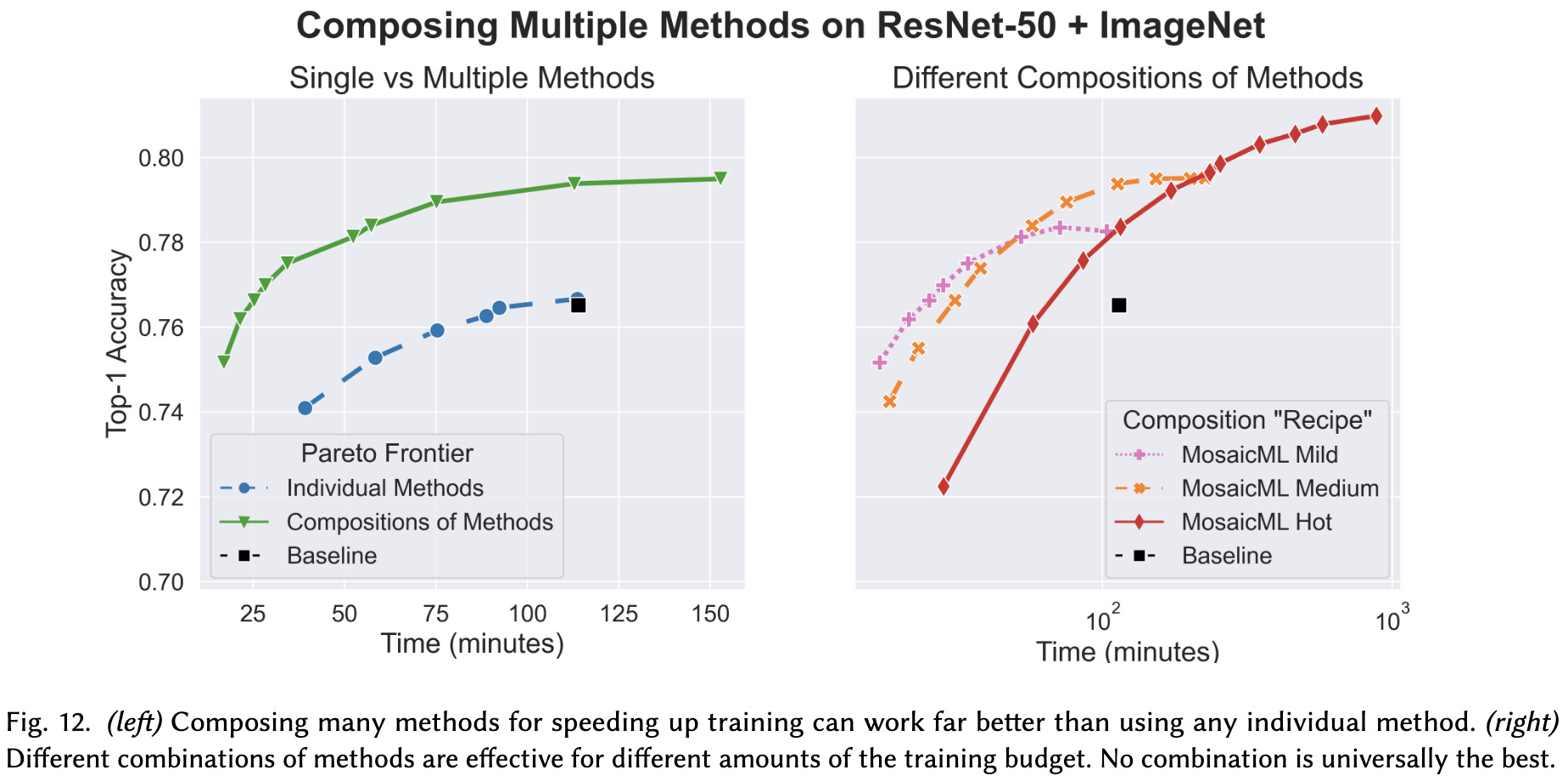
Lastly, you need to characterize not whether something works, but when it works. Combining different enhancements often helps (left), but different combinations are effective for different training durations / when paired with different other methods (right).
The above recipes are taken from the Mosaic ResNet. As suggested below, stochastic depth, sharpness-aware minimization (SAM), and various data augmentations only become helpful once you’re training for long enough.
Oh, and one more thing. Many people’s mental model of “work” in deep learning is just FLOPs. But FLOPs only tax one small part of your system. There are many computational resources that can be the bottleneck, such as memory bandwidth, interconnect, storage, and more. If you work on deep learning “efficiency,” you should probably be familiar with everything in this table:

Also, this isn’t in the paper, but I’m convinced 80% of claimed “improvements” are people trading higher memory bandwidth usage for lower FLOP + parameter count, then only measuring the latter. Like, yes, you can add depthwise convs and sparse receptive fields everywhere to reduce the FLOP and parameter counts at iso accuracy. But if you want your proposal to be useful, you probably need to improve time to accuracy, inference latency, or maybe peak memory consumption.
Anyway, I hope this is helpful for people. Keeping up with the literature is hard, and evaluation is one of those things that’s super important but rarely taught or standardized.
Breadth-First Pipeline Parallelism
They propose a pipeline parallelism scheme that trades increased communication for smaller pipeline bubbles.
First, they propose executing multiple stages of the pipeline on each device. This requires passing around more activations and gradients, but lets you use all the hardware earlier in forward and for longer in backward.

Second, they propose having each GPU/node run the earliest stages it owns first for every microbatch (“breadth-first”) rather than the earliest microbatches available for every stage (“depth-first”).

This scheme yields better utilization than alternatives when the ratio of batch size to GPU count is small. With their sequence length of 1024, these plots consider up to 8192 tokens per GPU, which is in the right ballpark for what you’d fit in GPU memory in practice.

They also have a lot of back-of-the-envelope analysis of the tradeoffs associated with different parallelism schemes—a good read to sit down and really digest if you’re trying to ramp up on this area.
Mechanistic Mode Connectivity
Model weights corresponding to qualitatively different solutions don’t seem to have a low-loss basin linearly connecting them in the loss landscape.


At least as assessed using some synthetic data.
Large Language Models Struggle to Learn Long-Tail Knowledge
For question answering tasks, models do way better when the answers to the questions show up many times in the pretraining corpus.

This suggests there’s a lot of value in looking at document rarity when making sense of top-line accuracy numbers. E.g., if you find your model answering some questions incorrectly, you should check how often the answers came up in the pretraining data.

Just to be sure this relationship is causal, they perform an experiment where they rip out all the relevant documents for some questions. As you’d hope, this is more harmful for questions that had more documents.

How big a model would we need in order to close the gap with human performance? A really big one—over 10^20 parameters. This is like taking every neuron in a 10B parameter model and replacing it with an entire 10B parameter model.

However, if you feed the model a “golden” paragraph from Wikipedia that’s known to contain the answer, the accuracy goes way up. It also becomes higher for questions with few documents, just like how humans perform when allowed to see reference material.

Adding the three most relevant Wikipedia paragraphs to the input (with relevance assessed using BM25) helps accuracy quite a bit. Though it’s still nowhere close to the accuracy you get from adding a ground-truth paragraph—note the ~2x drop in y-axis values compared to the previous plot.

This might be due in part to BM25 sometimes missing the most relevant results. This is especially likely to happen when retrieving few documents.

I like that this paper improves our understanding of a problem, shows how good a result we could hope for, and highlights strategies that do and don’t seem like they could get us there. Makes me more optimistic about retrieval being helpful, plus more convinced that the quality of the retriever matters a lot.
Controlling Commercial Cooling Systems Using Reinforcement Learning
Google, DeepMind, and Trane teamed up to optimize data center cooling with RL. This is interesting because it’s someone doing something useful in production with RL.

They have an action space of 12 continuous values and some discrete ones. This input space consists of 50 sensor measurements, logged every 5 minutes. There are also a ton of constraints along the lines of “this temperature needs to stay below this value.”
They formulate the problem as a Markov Decision Process and use existing RL methods to solve it. Roughly, they have an ensemble of neural nets to estimate the world’s transition model and the action value function. They avoid actions that the model estimates would violate the constraints.
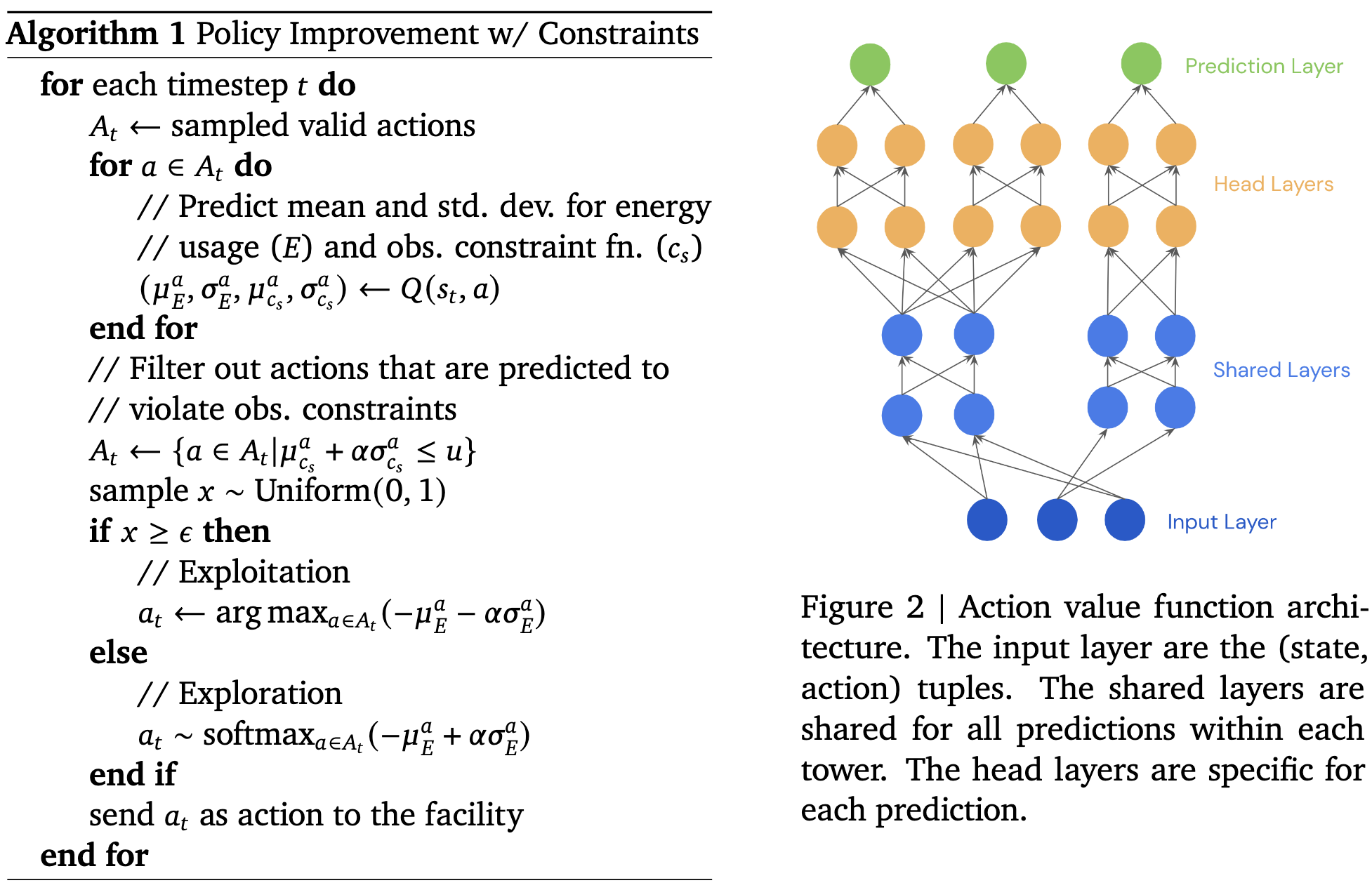
After a ton of feature engineering, debugging, and baking in domain-specific knowledge, they got it working pretty well. It reduces energy consumption by about 9-13%.

It also usually satisfies the many physics-based constraints on its actions. The baseline here is the “Sequence Of Operations” controller previously in use, which depends on physics and various heuristics.
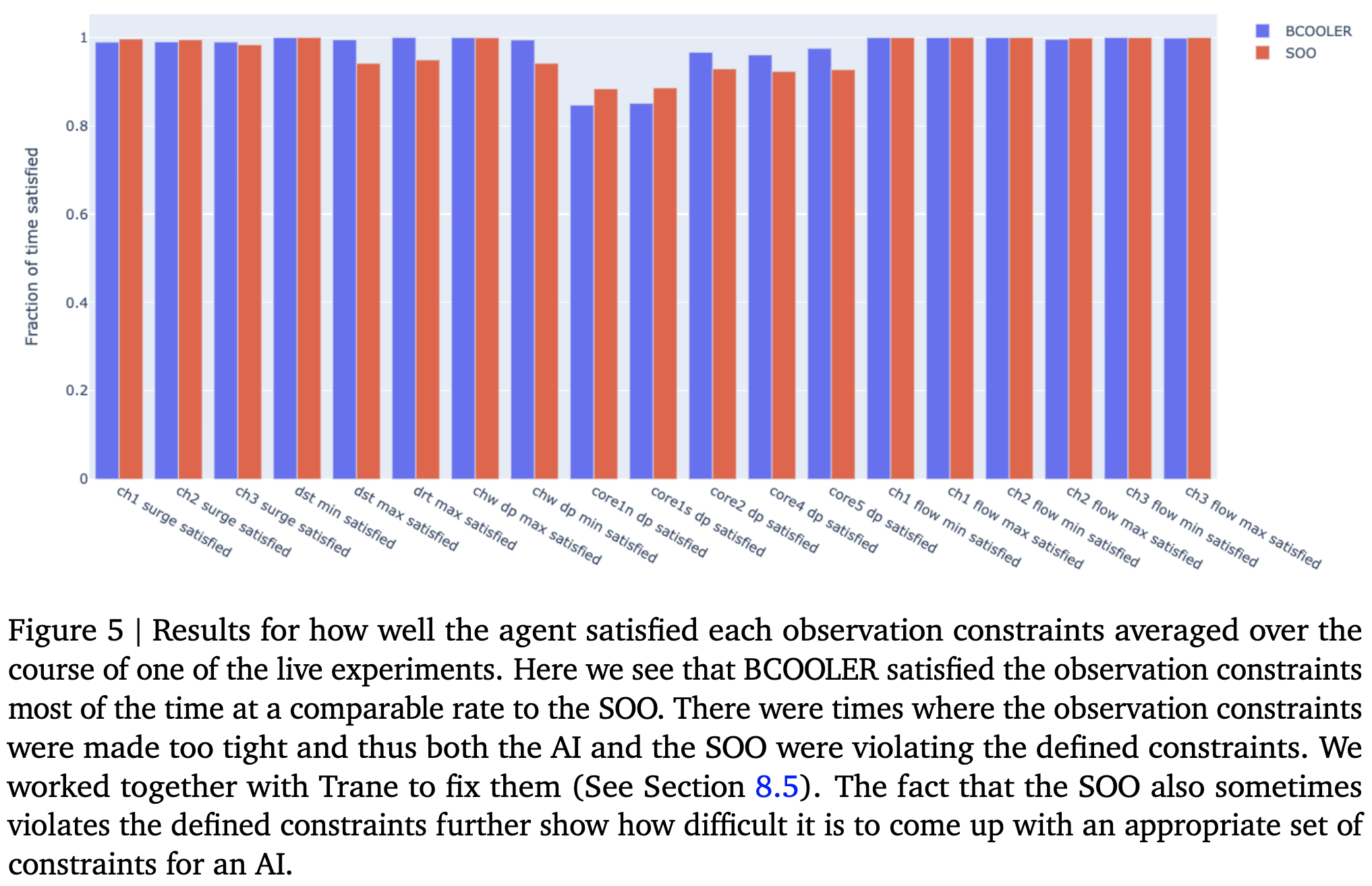
To make sure the system doesn’t do anything crazy, they have a way to switch between the old rule-based system and the RL recommendations. The switch happens automatically when the RL agent violates various constraints (e.g., some temperature exceeding a threshold) or when it just gets confused and fails to make a recommendation. It can also happen manually if the human operators don’t like the agent’s output.
This paper is mostly interesting to me on a meta level. First, this is one of only a handful of examples I’ve seen of RL in production, despite the field being decades old. Is RL just “not there yet” (like text generation until recently) or does it only have a few use cases (like distributed ledgers)?
Second, this paper runs counter to the ontology of many online discussions of AI risk. In no way did they just define an objective and throw “optimization power” at it. Rather, the paper is ~20% about RL and 80% about their specific problem. Since this problem is about as simple and close-to-the-physics as one could hope for, it suggests that future RL deployments will also require high per-problem effort.
Scalar Invariant Networks with Zero Bias
Points out that, if you have a ReLU network with no biases, the class prediction is independent of input scaling (in the scalar multiplication sense, not the changed resolution sense).

Cool result that I feel like we all should have realized years ago. Maybe an argument for ReLU over SiLU, GELU, etc? Or maybe we can get away with just having the early stages scaling-invariant and then adding a Layernorm—pretty sure this would get the whole model scaling-invariant even if there were non-ReLU activations after the Layernorm.
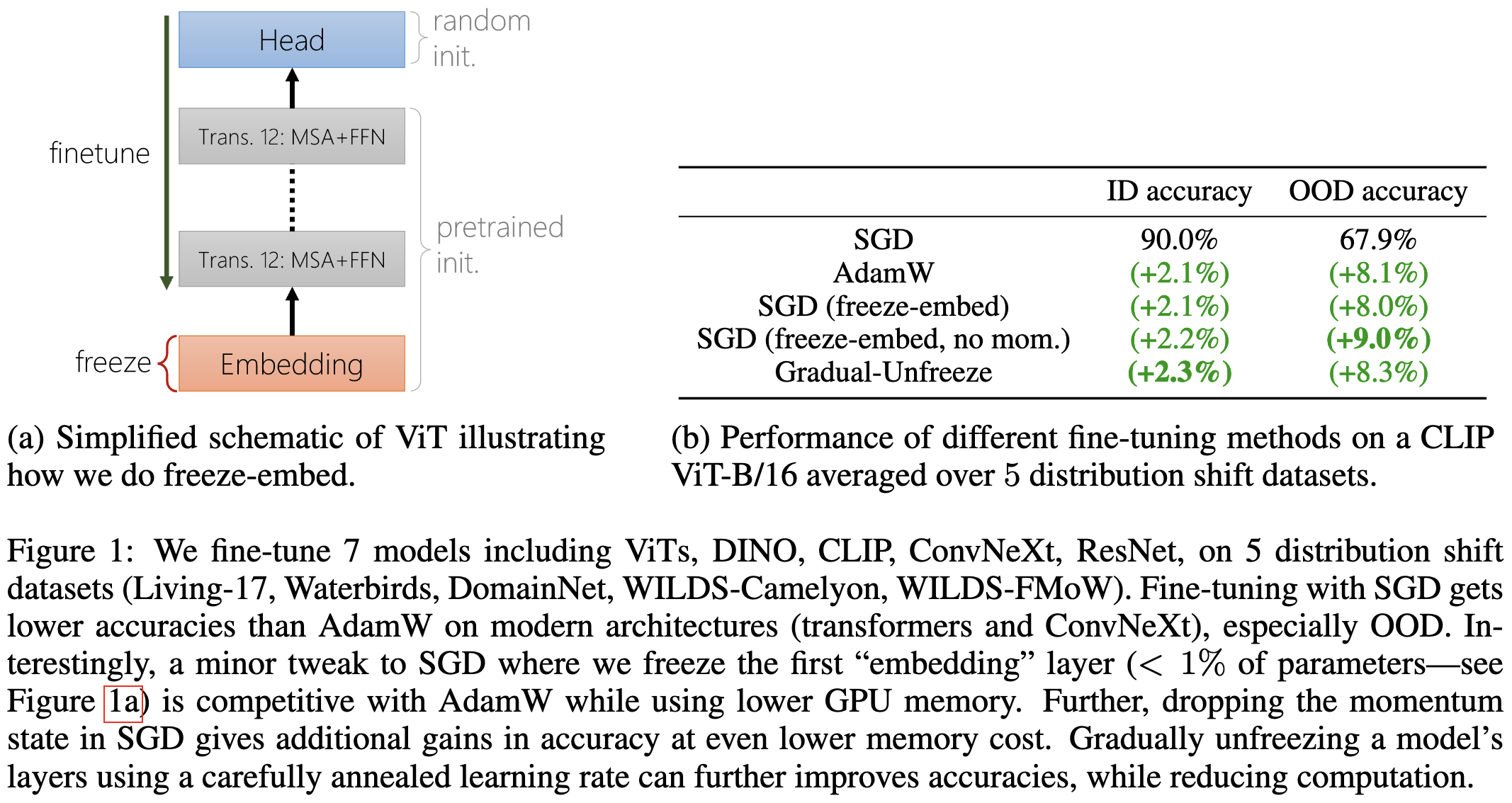
How to Fine-Tune Vision Models with SGD
They find that it helps to freeze the first layer’s weights when finetuning vision models with SGDM. Also, sometimes removing the momentum from SGD helps a little bit, especially out-of-distribution.
Holistic Evaluation of Language Models
A 163-page paper + website authored by dozens of Stanford people. They measure “accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency” across 42 different “scenarios.”

Basically, they break the coupling between what dataset you use and what metrics you report, computing every metric for everything as much as possible.

This yields a more comprehensive evaluation of various models and datasets than in any previous study.

They describe 25 takeaways from their results on pages 9-13. A few highlights:
Instruction-tuning is really effective.
The best models are proprietary: InstructGPT davinci v2 175B, TNLG v2 (530B), Anthropic-LM v4-s3 (52B).
There’s a strong correlation between accuracy and robustness but not between accuracy and calibration.
More accurate models are more likely to regurgitate text, though it’s not too common outside of passages from popular books.
Models can be super sensitive to how you construct the prompts, especially for multiple-choice questions.
While the best model does vary by task, OpenAI’s InstructGPT davinci v2 175B is the king overall.
EfficientTrain: Exploring Generalized Curriculum Learning for Training Visual Backbones
They do curriculum learning for image classification not by choosing a subset of samples, but by messing with the contents of each sample over time.

Concretely, they just do progressive resizing and also gradually increase the data augmentation severity.

This improves the training time vs accuracy tradeoff.

It looks like the linearly-ramping data augmentation helps a little bit compared to keeping it at maximum from the start. There might also be a small gain from doing expensive frequency-domain smoothing rather than bicubic smoothing.

The effect size is small, but these might be practical enhancements to progressive resizing (which is already a key component of the fastest image classifier training).
VeLO: Training Versatile Learned Optimizers by Scaling Up
They used meta-learning to meta-train a really good optimizer.

The optimizer itself is a parameter-specific MLP that takes in the history of weights and gradients to output a new weight. But what produces this MLP is an LSTM. The LSTM is instantiated for each tensor (I think with weights tied across all the tensors) and takes in various features like the loss and moving averages of the squared gradients.

Their optimizer, VeLO, works super well out-of-the-box. It’s both more reliable and more accurate than Adam.
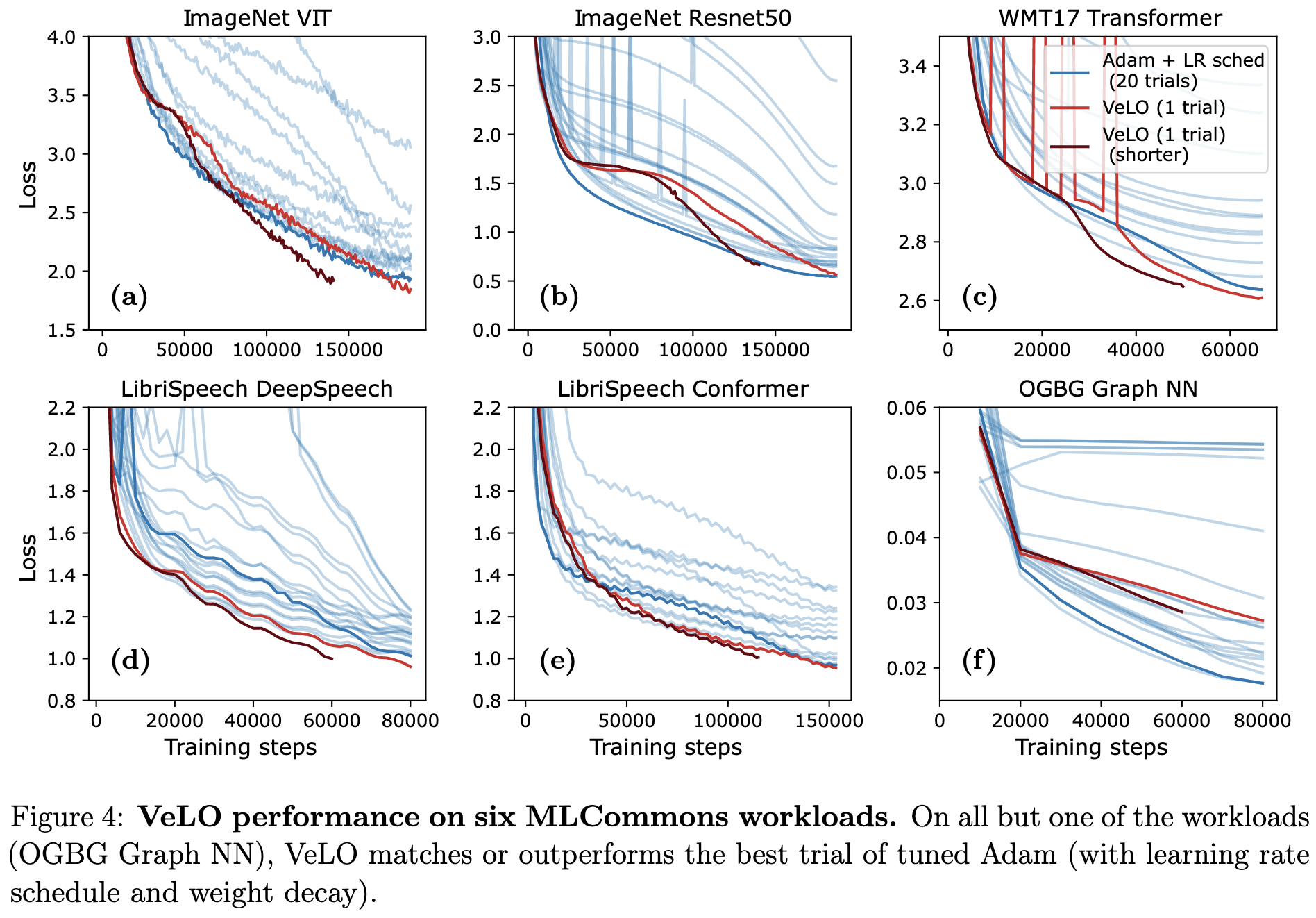
It also generalizes well even to weird tasks that don’t resemble the meta-training corpus, like NERF and MLP-Mixer training.

Seems worth a try (code) if you a) are okay with JAX, b) can afford a way larger optimizer state, and c) have a large enough batch size to amortize the increased optimizer step time. Might be a big win depending on your problem.
InstructPix2Pix: Learning to Follow Image Editing Instructions
They train a model such that you can just tell it how to make the image different and it does it.

To do this, they’re essentially training the model to mimic their two-step training data creation procedure in one step.
In step one, they have GPT-3 modify the original caption to reflect some requested change. In step two, they use StableDiffusion to generate an image for the modified caption.
This gets them a tuple of (original caption, original image, new caption, new image), which they use to train their model.

Seems to work really well, though there are definitely times it fails.
