


2022-12-11 arXiv roundup

This newsletter made possible by MosaicML.
(We’ve got a little bit of a post-NeurIPS lull this week.)
Task Bias in Vision-Language Models
They investigate what tasks CLIP embeddings tend to be helpful for. E.g., whether it focuses on the snowboard, the text on the snowboard, the person, the action of “snowboarding,” etc. In general, CLIP’s output is biased towards action recognition (“snowboarding”) over text and object recognition.

But it’s not a simple, uniform rule. The implied task can vary across images, often in unpredictable ways—e.g., small patches of text in the image can dominate the representation.

Fortunately, they show that changing the prompt can let you steer the representations to work better for the task you care about.

Changing the prompt is tricky in this case, though. This is because we can’t just write out text. That might change what the text encoder does, but the problem is the image encoder. So what they do is prompt tuning in image space, either by adding a trained border to all images or by adding an extra, trained token to the input (with the latter requiring that you use some sort of vision transformer).
There aren’t a ton of numerical results but it seems to work fairly well. “VP” is the border-based prompting method and “ViTP” is the token-based one.


Kind of surprising that they could nearly double the accuracy on at least one task. Suggests that the task bias in the CLIP model is quite strong. More testament to the power of prompting, even outside of text generation.
DeepSpeed Data Efficiency: Improving Deep Learning Model Quality and Training Efficiency via Efficient Data Sampling and Routing
They add curriculum learning and random layerwise token dropping to DeepSpeed.
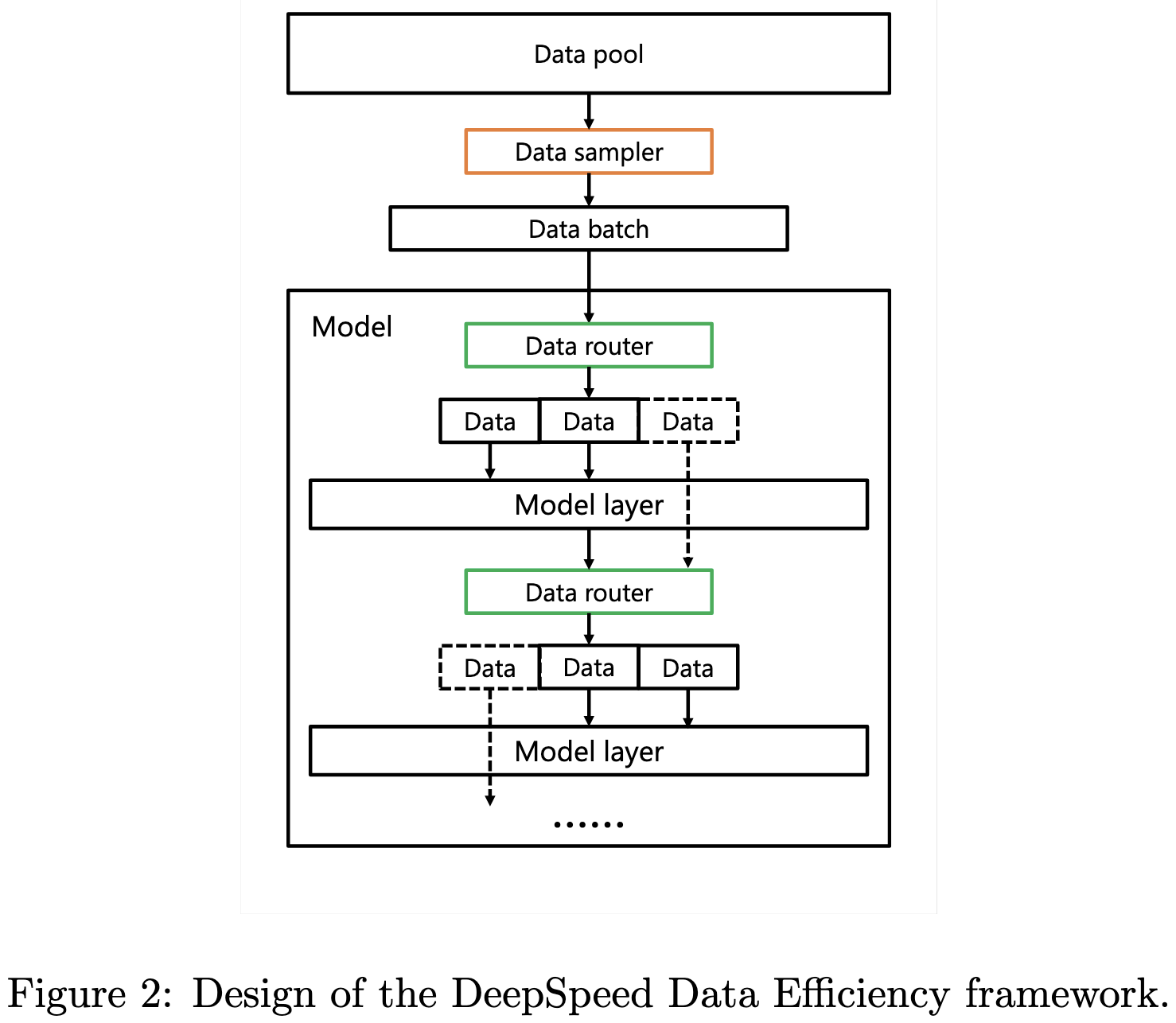
For the curriculum learning, they built a Map-Reduce-based system to let you split up your data ahead of time. They have seven different “difficulty” metrics to choose from, along with various “pacing functions” for how difficulty maps to sampling probability over time. To determine the sharding, you specify information like the intended number of nodes and CPU cores per node.
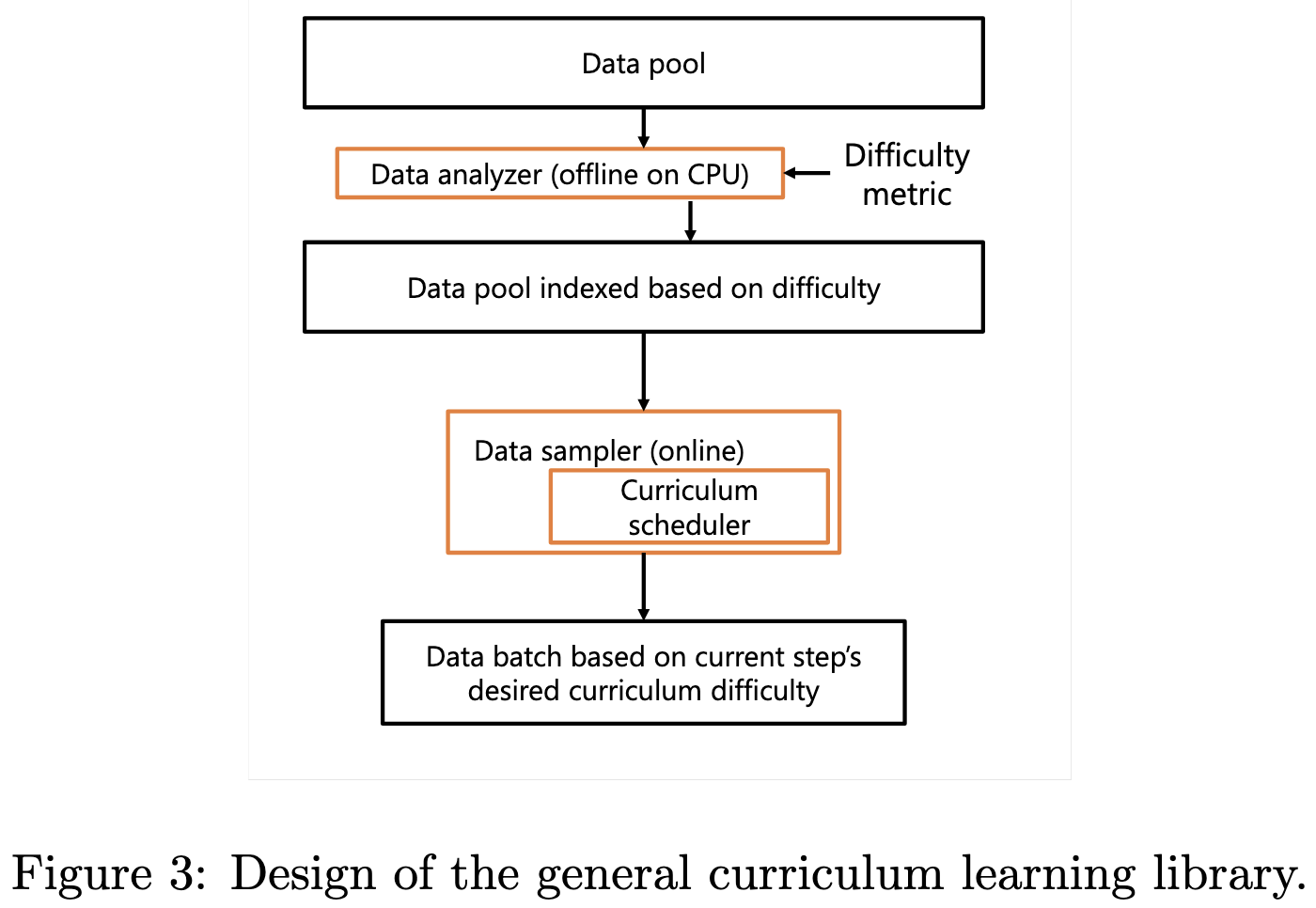
For the random token dropping, they ask the user for similar configuration hyperparameters—namely, the initial fraction to drop and how to pace this over time.
With the right hparams, this combination of techniques seems to help for a 1.3B-parameter GPT model and a BERT-Large:
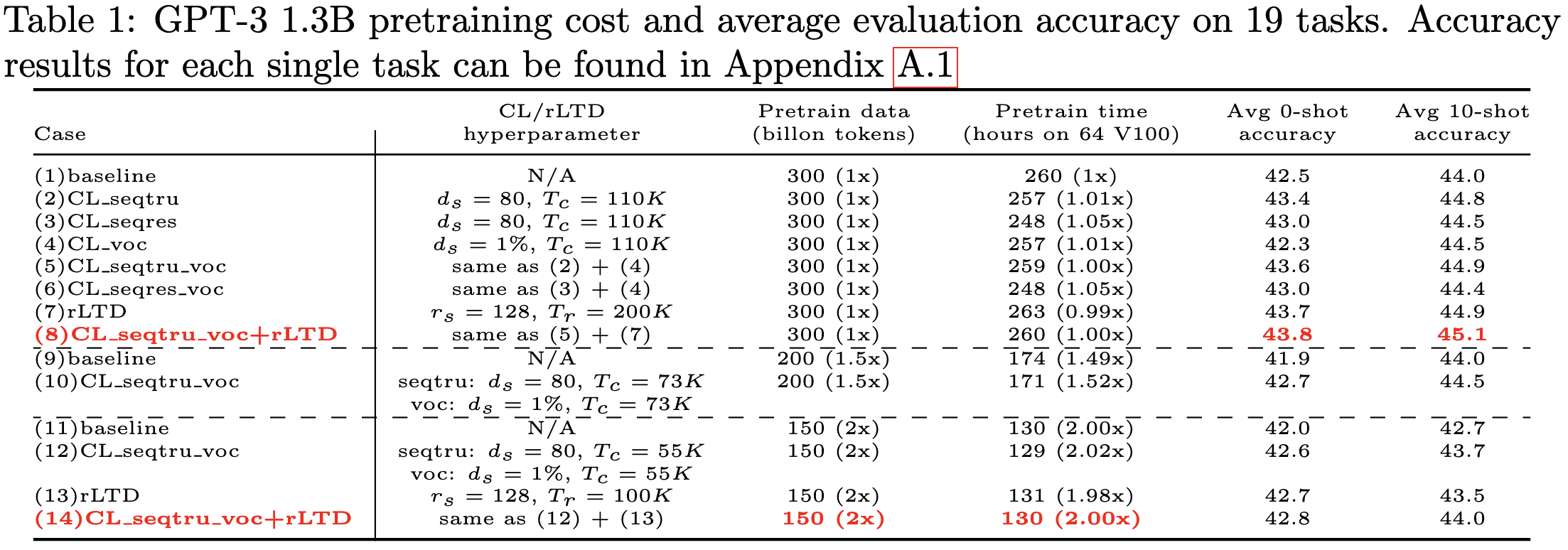

They claim a 2x time saving at iso validation perplexity, in the sense that training with 150B tokens using their techniques does about as well as the baseline when trained on 300B tokens (see the purple vs red curves in the right subplot).

Cool to see wall-time speedups from token dropping and curriculum learning.
Momentum Calibration for Text Generation
We usually train our text generation models based on maximum likelihood, but what we care about is some other metric. They propose a better way of finetuning a seq2seq model with a more complex loss computation. Essentially, they:
Compute a moving average of the model’s weights to get a "momentum generator” model
Sample various sequence from this generator model
Rank the sequences using an an “evaluation” function, such as the BLEU score or a pretrained scoring model.
Train the main model to rank the outputs the same way as the evaluation function using a margin-based pairwise ranking loss.

They also add an auxiliary loss to weight different positions differently based on empirical observations about increasing error rates deeper into the sequence.
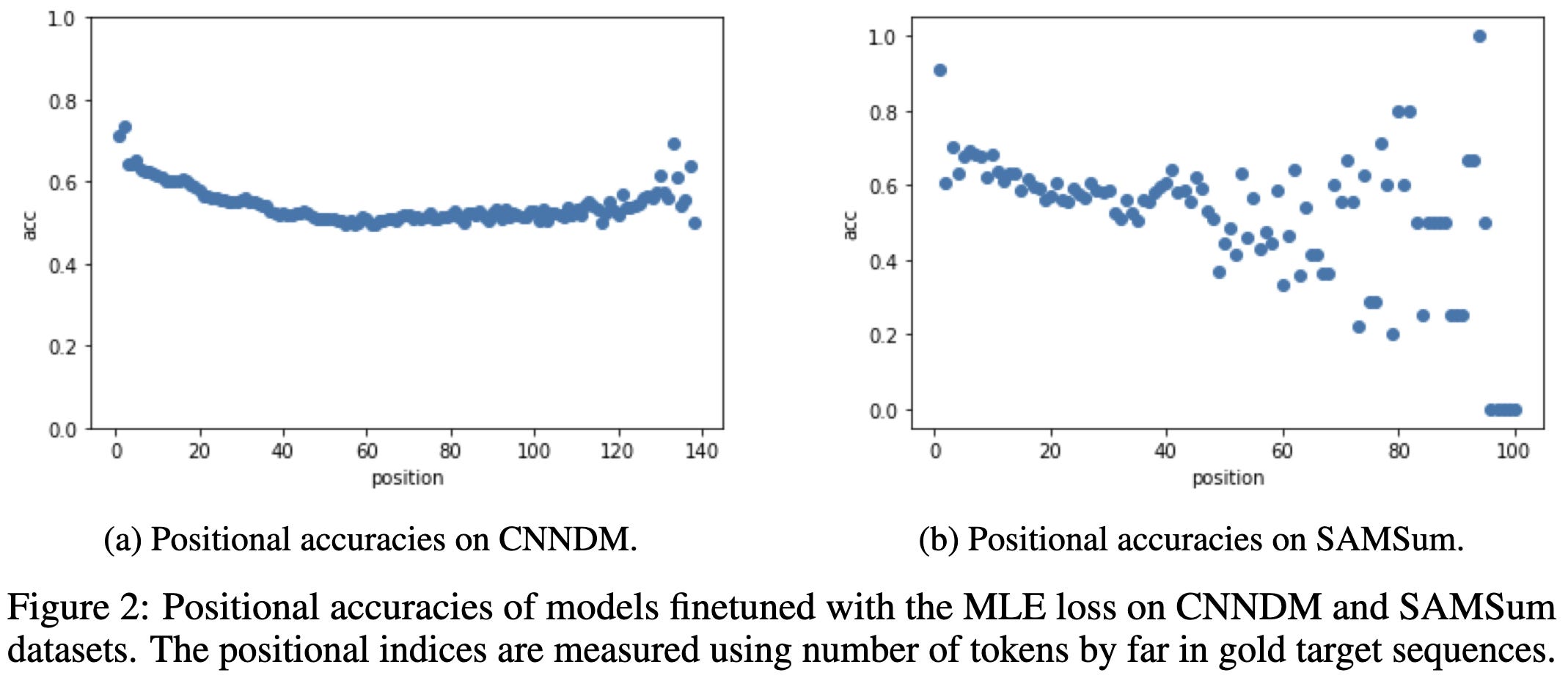
This overall method is more involved than typical finetuning, but seems to lift output quality on various datasets.

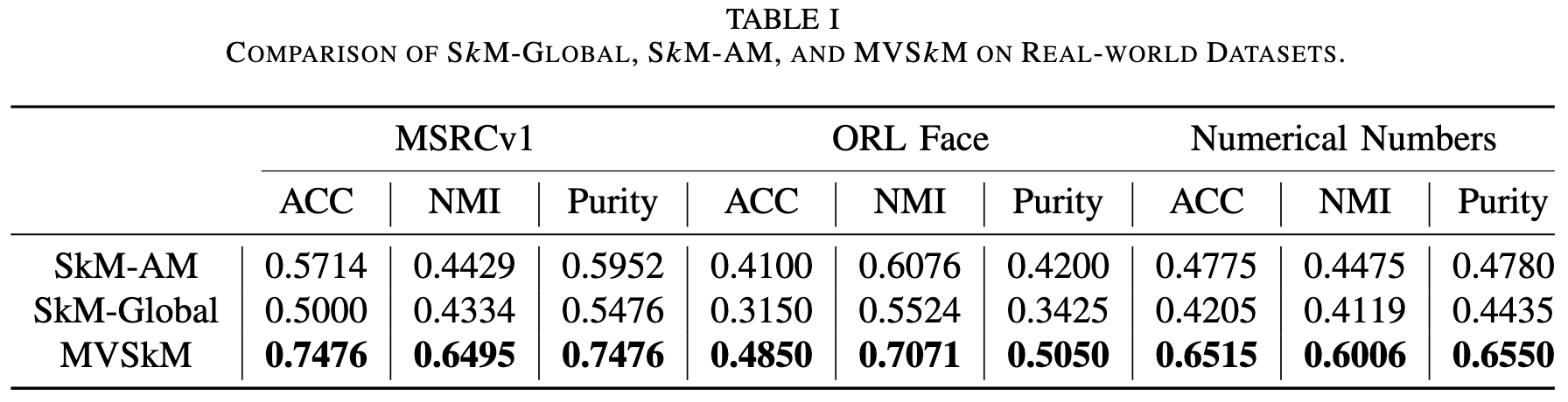
On the Global Solution of Soft k-Means
They introduce an algorithm to find a globally optimal solution to soft k-means.
To understand soft k-means, we first have to think about k-means in matrix notation. Below we’re letting X be a matrix whose columns are samples, F be our centroids, and G be the one-hot matrix of centroid assignments.

For soft k-means, we just let G be any matrix whose assignments are nonnegative and sum to one.

Their algorithm is more complex than regular k-means, but still pretty readable.

Besides being globally optimal in theory, it seems to do well in practice.
Mostly I’m wondering about this algorithm as a foundation for k-means initialization. Global optimality is an awfully nice property; my gut tells me we could take the solution this produces, add in some of coreset math, and get theoretically and practically better k-means centroids.
This would be cool not only because people use k-means directly, but because it’s at the heart of many vector quantization methods used for similarity search.
PS: I like how they have a figure explaining the structure of their main proof. I didn’t read it in detail but this strikes me as a great idea. Might be even better if the blocks had a few words about each Problem.

Rethinking the Structure of Stochastic Gradients: Empirical and Statistical Evidence
A bunch of interesting results regarding the distributions of gradients for CIFAR-10-sized image classification tasks.
There’s a power-law distribution of gradient variance across parameters, but not within a given parameter over time.

Also, the gradient covariance matrices have power-law distributed eigenvalues. This kind of explains why there would be power law gradient variance across dimensions.
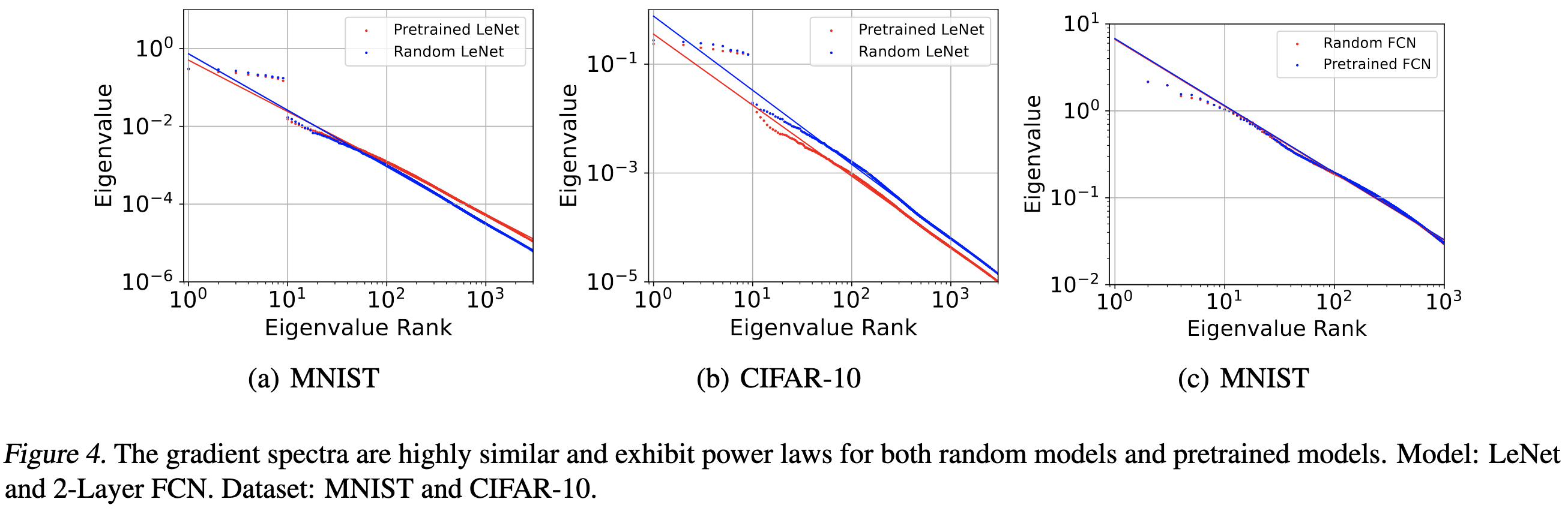
Somewhat surprisingly, the top eigenvalues of the covariance matrix can be 10x different than the top eigenvalues of the Hessian; this violates the common assumption that one can approximate the Fisher Information using the Hessian.
These results seem to hold as long as the network is wide enough and independent of depth.
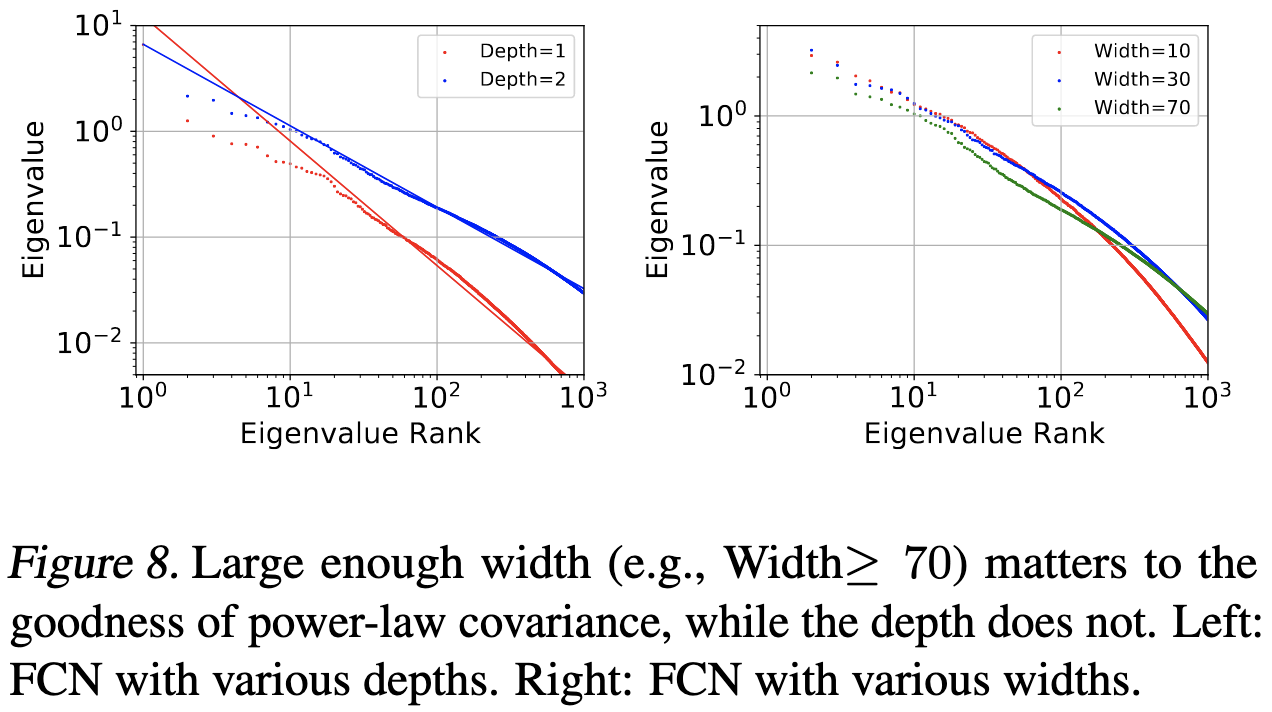
I’m always a little hesitant to trust results on small image classification tasks, but it’s great to see such thorough analysis of an important aspect of deep learning training.
Nonparametric Masked Language Modeling
They let BERT-style models output a whole phrase for each mask rather than just a single token. They do this by encoding a big corpus of text and having the model choose which phrase from the corpus to put in the masked spot.

To avoid a zillion-way softmax over an entire corpus, they make a couple simplifications. First, they do a similarity search over phrase embeddings and only retrieve the top k. Second, they encode each phrase as just its first and last token. This means they actually perform two similarity searches, one for the prefix and suffix, after which they (I assume?) union the results.

To generate the prefix and suffix queries, they use pairs of mask tokens ([MASK_START] and [MASK_END]) instead of just one [MASK] token. The model’s embeddings of these tokens are used for the similarity search + classification. The latter is what provides the error signal, since there’s some true phrase that got masked out.

This approach seems to increase the final model’s accuracy at a given parameter count.

Improved Deep Neural Network Generalization Using m-Sharpness-Aware Minimization
They do SAM but with different perturbations for different subsets of the batch. This can be more efficient than having a single perturbation if you compute each perturbation within a single device, since it lets you avoid allreducing across devices to find the global perturbation direction. This “mSAM” is already known, but they study it in more detail.

They find that, besides being efficient, mSAM also yields higher accuracy than regular SAM—at least if you set the number of independent perturbations well.


You do have to set the number of batch subsets / different perturbations to use, but it does seem clear that just one (as done in SAM) isn’t ideal on their tasks.

There’s also some evidence that using more perturbations reduces the sharpness better, as measured by the largest eigenvalue of the Hessian at convergence.

This convinces me that mSAM is probably an easy, practical win for training neural nets better.
General-Purpose In-Context Learning by Meta-Learning Transformers
They do meta-learning with transformers. What’s interesting is that, rather than trying to generate a good initialization that tends to do well on any downstream tasks when finetuned, they’re targeting in-context learning. That is, they just feed in examples from the new task as part of the prompt without updating the model at all.

Their proposed algorithm is fairly simple. It’s just meta-training across a bunch of tasks with some generic data augmentation; this augmentation consists of subsampling, Gaussian random projections for the inputs, and random permutation for the output classes.

This method yields pretty good generalization to unseen tasks as long as you meta-train on enough tasks and have a large enough model.

If you have too few tasks, the model just memorizes each training set. As the task count increases, it starts generalizing within each task, but not across tasks. Finally, with enough tasks, it starts generalizing across tasks.

One cool aspect of this is that the accuracy gets better as the number of in-context examples increases. This means that the forward pass of the transformer is (by definition) implementing a learning algorithm.

Sometimes it takes a lot of meta-training for the generalization to kick in, with the loss stuck on a plateau for many iterations.

You can help avoid plateaus and generalize better by training on just the right number of tasks at once.

You can also bust the loss plateau by using a fixed permutation for the labels in your data augmentation a small fraction of the time. They suggest that this is a form of curriculum learning, making the meta-training somewhat easier.

Great to see such thorough science-of-deep-learning work.
This is also one of the more AGI-ish papers I’ve read in a while; like, if a single, domain-agnostic model that can complete new tasks with no training isn’t general intelligence, I’m not sure what is.
"General-Purpose In-Context Learning by Meta-Learning Transformers" is a very cool paper. In-context learning by meta-learning is not really new, having been shown for recurrent networks back in 2001 (Hochreiter et al. 2001). This paper is to some extent just replacing a recurrent network by a transformer in the setup of (Hochreiter et al. 2001) and (Wang et al. 2016; Duan et al. 2016). But since transformers scale so nicely compared to RNNs, guess it's possible to get a lot more interesting behaviour more easily. On the other hand, I would expect transformers have a limit in terms of context length that RNNs don't (at least in principle).