


2022-2-20: Fantastic generalization measures, How vision transformers work, 0/1 Adam

Fantastic Generalization Measures and Where to Find Them. Section 4 summarizes results, which seem to all be on CIFAR10 or SVHN. Confirms that overparameterization helps generalization, that norm-based and classical VC-style measures correlate negatively with generalization, and that flatness (and proxies like final gradient variance) also correlate with generalization. Also, faster initial loss reduction correlated with worse generalization, supporting the explore/exploit model of optimization we’ve seen with cyclic learning rates.
On the Origins of the Block Structure Phenomenon in Neural Network Representations Why do neural nets end up with these block structured activation correlations?

Basically a bunch of datapoints with similar image statistics (like background color) have huge activation magnitudes. If you regularize the first principle component of the activations, or do other stuff like shake-shake regularization, you can make the block structure go away without hurting accuracy.
Deep Ensembles Work, But Are They Necessary? Yes, ensembles can get you an accuracy lift, but they’re not any more robust, good for quantifying uncertainty, or anything like that.
A Survey on Model Compression for Natural Language Processing Pretty generic survey covering factorization, quantization, pruning, distillation. I never cease to be amazed by the number of meanings people assign to “Lottery Ticket Hypothesis.” I found the survey of knowledge distillation informative, since personally I haven’t looked at that literature much.
An Introduction to Neural Data Compression Really good tutorial covering a lot of stuff. I got some dense learning out of this despite already having a good compression background, which I consider high praise. Even if this isn’t a problem you immediately care about, still a good firehose to get ML experience points from.
COMPUTE TRENDS ACROSS THREE ERAS OF MACHINE LEARNING Just look at the scatterplot below + summary table. I’m not sure why they split off the red points though; seems kinda weird.

HOW DO VISION TRANSFORMERS WORK? They argue that 1) multiheaded self-attention (MSA) flattens + smooths the loss landscape, 2) acts as a learnable low-pass filter along the spatial dimensions (like blurpool), and 3) is largely held back by negative hessian eigenvalues (indicating non-convexity). But these negative eigenvalues go away if you use enough data or use GAP at the end instead of a <CLS> token. They argue that putting MSA at the end of each conv block in a resnet is especially effective. Regarding point (1), they show some results examining the frequency content of MSA and conv layer outputs, as well as how much accuracy goes down when you add in noise of a given frequency; and both suggest that MSA acts as a lowpass filter.
Learning the Pareto Front with Hypernetworks They want to train a model once and spit out a model at an arbitrary point on the inference speed vs accuracy pareto frontier. They formulate Pareto-Front Learning (PFL), which is maybe a term we should all use when considering multiple objectives at once.
“Training is applied to preferences sampled from the m−dimensional simplex where m represents the number of objectives.” Input is a minibatch and a preference weighting. Not sure how they quantified loss for runtime. Also, only has results on small tasks like fashion-mnist.
Characterizing and overcoming the greedy nature of learning in multi-modal deep neural networks Some heuristic interventions to try to get the model to learn from all the modalities and not just lean on the most informative modality. Reportedly helps generalization.
Investigating Power laws in Deep Representation Learning If you compute (X.T @ X) for flattened feature representations X (which they incorrectly call the covariance), and look at the distribution of eigenvals, it sometimes looks like a power law. And they argue through a bunch of plots that if this power law has exponent alpha=1, that’s good for generalization. Didn’t read closely but came away pretty skeptical.
Learning Fast Samplers for Diffusion Models by Differentiating Through Sample Quality Better results in less time by learning the sampler. Apparently lower gains on Tiny ImageNet than CIFAR10 though, which is a bad sign regarding scalability. Lot of diffusion math background needed to understand what’s really going on here.
Predicting Out-of-Distribution Error with the Projection Norm Trying to predict performance on a test set given test set inputs but not labels. Proposed metric takes in 1) a pretrained model to be fine-tuned for the test task, and 2) the test inputs. They then give the test set random labels, finetune the whole model, and compare the distance in parameter space between fine-tuned and original. Larger distance → worse generalization. You have to fit the linear regression for each specific problem, though not for each specific network.
Efficient Natural Gradient Descent Methods for Large-Scale Optimization Problems Nice unification of different variants of regular + natural gradient descent. Need to stare at the math + code more to figure out the exact algorithm, but seems like a nice hammer to keep in mind if you think about optimization. Start at sec3 on page 13 for method.
Scaling Laws Under the Microscope: Predicting Transformer Performance from Small Scale Experiments Asking "can scaling laws provide a principled method for developing models at very small scale and extrapolating to larger ones?” Answer is yes, for some downstream tasks, if you tune hparams. Hparam tuning is done for each downstream task, not for the pretraining. Scaling laws seem to have better fit for downstream tasks that more closely resemble the pretraining task.
Deduplicating Training Data Mitigates Privacy Risks in Language Models “We first show that the rate at which language models regenerate training sequences is superlinearly related to a sequence's count in the training set. For instance, a sequence that is present 10 times in the training data is on average generated ~1000 times more often than a sequence that is present only once”
⭐ Maximizing Communication Efficiency for Large-scale Training via 0/1 Adam Good related work re: existing 1-bit adam. Its initial full-precision stage is so heavy that avg bits transmitted over full BERT-Large training is 5.69 bits. This paper reduces it down to 1.03 at iso accuracy wrt full precision by basically eliminating this part. And 0.61 if you relax it to only allreduce like 2/3 of the time. Seems like a thing you could just use if their code is easy enough to integrate. They pick the steps on which to do full-precision allreduce based on some heuristics regarding the current gradient variance.

SQuant: On-the-Fly Data-Free Quantization via Diagonal Hessian Approximation Going to take a bunch of staring at their math + source code to really understand what’s going on, but basically they try an initial quantization solution and then adaptively pick elements to flip the rounding for (i.e., rounding up vs down) such that some error constraints are satisfied. Could be really useful because it takes <1s to quantize a whole ResNet-50, needs no data so it’s easy to run post-training, and seemingly causes no accuracy loss (e.g., 77.7% top1 for 8-bit ResNet-50 on ImageNet).

Above three terms are: sum of squared rounding errors, sum of (total rounding error in a row(?)), squared total rounding error. So rather than just making all the rounding errors individually small, also make them tend to sum to 0 when reduced across various subsets of axes.
Quantifying Memorization Across Neural Language Models “We describe three log-linear relationships that quantify the degree to which LMs emit memorized training data. Memorization significantly grows as we increase (1) the capacity of a model, (2) the number of times an example has been duplicated, and (3) the number of tokens of context used to prompt the model.” Although different results across model families.
General-purpose, long-context autoregressive modeling with Perceiver AR. I couldn’t really find any new ideas here relative to the other perceiver papers. They just have a fixed number of queries at the input layer instead of one per input token, so it ends up basically being a linear attention mechanism. But they don’t benchmark on long-range arena or control for compute or model size in any way AFAICT, so couldn’t really find anything to conclude from this.
General Cyclical Training of Neural Networks Proposes cyclic weight decay, softmax temp, and other cyclic everything basically, mostly on CIFAR but sometimes on ImageNet. By the same dude who wrote the superconvergence paper. Tiny effect size; basically seems to be an instance of the principle that you can add an arbitrary hparam, tune it on the test set, and get apparently better results.
Where Is My Training Bottleneck? Hidden Trade-Offs in Deep Learning Preprocessing Pipelines Propose to intelligently choose to cache preproc steps vs recompute them at each time step based on profiling. Their code sadly isn’t available on the author’s github, but it appears they meant for it to be. They also profiled a bunch of workloads:
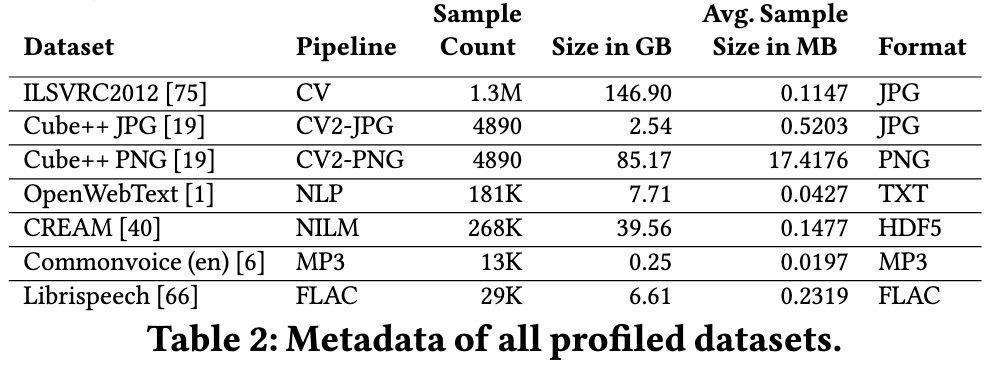
“Application-level caching improved the throughput compared to system-level caching by a factor of 1.3-4.6×, and should be preferred as the deserialization of cached files can slow down the pipeline”. Plus they confirm 10x gains in certain cases, which is unsurprising given that one can be arbitrarily dataloader-bottlenecked.
If you care about system-level data loading optimization, I would definitely recommend going through and staring at their figures.
Transformer Memory as a Differentiable Search Index Addresses info retrieval task of mapping text queries to document ids. Instead of having any retrieval step, they train a model to directly spit out docids as strings, treating it as a seq2seq problem. They have it spit out topk indices using the beam search tree in the decoder. They do hierarchical clustering to try to get the similar documents to have similar identifiers; the clusters are just k-means on embeddings from a small BERT model. They jointly train the model to spit out the docids associated with a given string (indexing) and the topk documents for a given string (retrieval); more data + noiseless supervision for former, but latter is the task they care about. Initialize their model as a pretrained T5. Seems to beat BM25, but it’s also way more expensive AFAICT. Super interesting though; not a lot of papers that are doing something this qualitatively new.