
2022-3-20: Memorizing transformers, {knn, non-trainable} softmax, reducing flipping errors

Do We Really Need a Learnable Classifier at the End of Deep Neural Network?
I really like this because they did a thing I thought about a long time ago, but couldn’t figure out the math for; namely, constructing a matrix whose maximum cosine similarity between columns is minimized. Instead of having a trainable softmax classifier at the end, they just use such a matrix. Works worse for class balanced problems but often better for small, imbalanced ones. They also replace cross-entropy with a different loss based on cosine similarity. I wonder if we could get it to train faster by solving the procrustes problem to get an initial U matrix that lines up better with the initial average embedding for each class. I’ve been wanting to have a fixed final layer to make classifying each pixel cheaper in segmentation, and this seems like the most promising initialization to make that happen. For more on the math, see this 2017 paper or this 2003 paper.

⭐ Memorizing Transformers
Adding approximate knn lookups to one layer in a transformer gives it the perplexity of a model 5x larger or more. The knn store sizes they consider are 50k-262k, and the contents are all the most recently seen keys and values at that attention layer (including those seen at test time within the current document). They find the k most similar keys for each query vector and use softmax weights to convex combo the associated values. So it’s basically a sparse attention mechanism over the KV store, added to the results of the regular attention. And by added, I mean it’s a convex combination with param equal to softmax of a learned bias. They don’t say how they do the knn lookup (just that it’s “a simple approximation of kNN for TPUs, which has a recall of about 90%”). But no wall time results anywhere...

Oh, and you can pretrain it with small or no knn, and then fine-tune it for just a little while with a large knn memory and it’ll work just as well as using the knn module from the start:

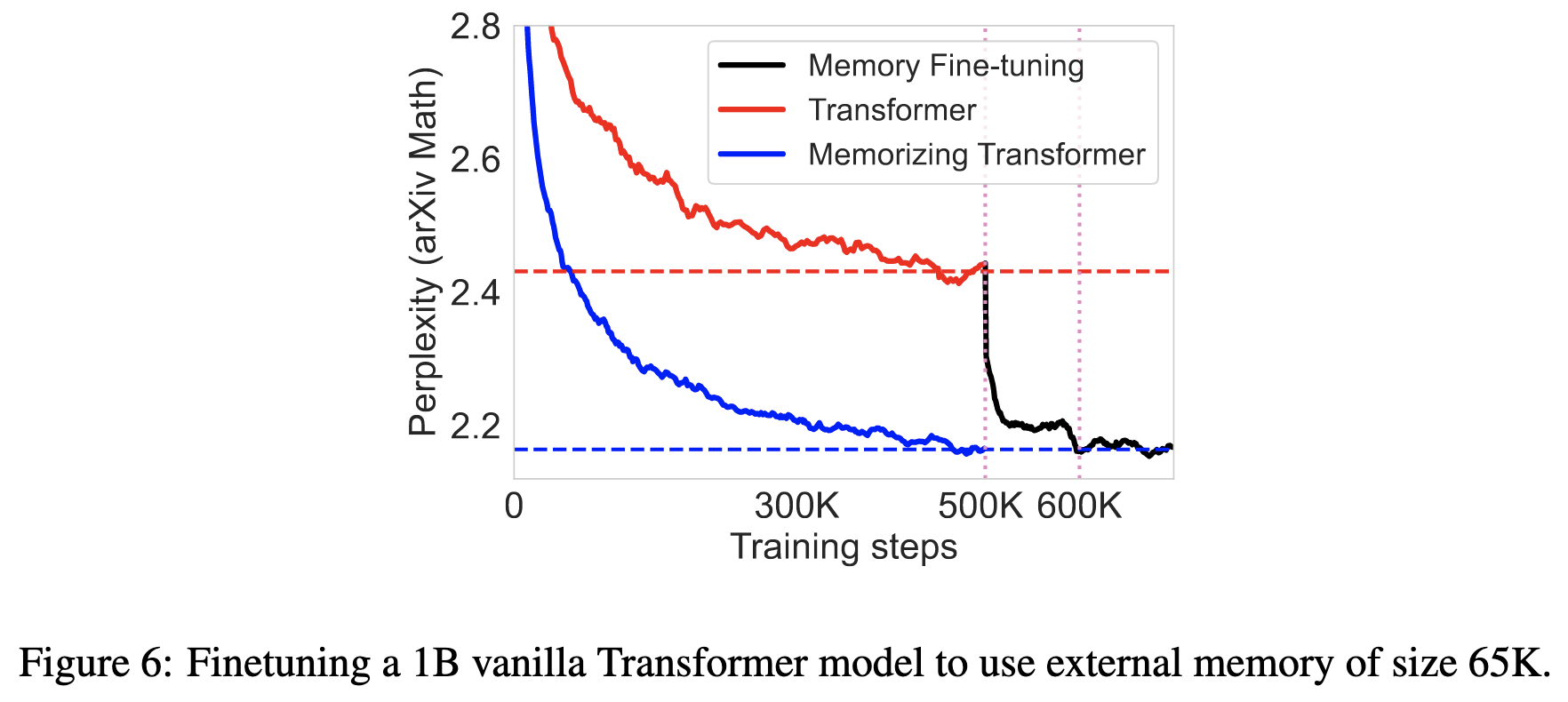
Some relevant experiment details: “We used a 12-layer decoder-only transformer (with and without Transformer-XL cache) with an embedding size of 1024, 8 attention heads of dimension 128, and an FFN hidden layer of size 4096. For all of our experiments, we used k = 32. Unless specified otherwise, we use the 9th layer as the kNN augmented attention layer. We used a sentence-piece (Kudo & Richardson, 2018) tokenizer with a vocabulary size of 32K.”
How Many Data Samples is an Additional Instruction Worth?
You can improve language model accuracy on downstream tasks significantly by rephrasing the instructions in the prompt a few different times and taking the output from each case. Seems like test-time augmentation (e.g., 10-crop eval) for NLP, basically. "Our results indicate that an additional instruction can be equivalent to ~200 data samples on average across tasks.”
⭐ Reducing Flipping Errors in Deep Neural Networks
Trying to do intra-run self-distillation / label denoising, which is basically better label smoothing informed by the model’s predictions. Idea is to form targets as EMA of model’s previous predictions on that sample, but only updated if the model got the answer right (see right side of p3 and left of p4). So it never treats incorrect predictions as supervision. They only test on vision datasets with size up to Tiny ImageNet, but get like 1% accuracy lifts or more pretty consistently, even relative to label smoothing. Might be an easy win.

Object discovery and representation networks
So you know how DetCon and other SSL methods pick certain groups of pixels that should be “similar” across two different augmented images, and train the model to make them all have the same representation? This paper replaces superpixel or other heuristics with k-means on the model’s own embeddings of each pixel in order to create the “similar” groups. Except it’s embeddings from an EMA of the model so it works better. Seems to generate nicer object boundaries, based on the masks they show (below). Apparently beats DetCon, ReLICv2, DINO, BYOL and supervised pretraining when fine-tuning on PASCAL, Cityscapes, and COCO.


Deep Learning without Shortcuts: Shaping the Kernel with Tailored Rectifiers
They did math to make ResNets without batchnorm only a little bit worse, and ResNets without skip connections bad but not terrible. The original arxiv version was interesting, but this ICLR version is too compact to make sense IMO. Plus if I’m going to spend a ton of time wading through initialization / signal propagation math, I’m gonna spend it on the muP paper, which has insights that translate into huge empirical utility.
Block-Recurrent Transformers
Similar to FLASH in that they operate on fixed-size blocks of tokens at once, but instead of just cumsum-ing previous state, they have a transformer with fixed, learned queries that takes in a block of previous state and combines it with current input, along with a couple gating functions. Bunch of details to get it to train well. No wall time results, let alone time vs quality tradeoff curves, so seems like a less validated version of the FLASH paper.

Data Smells in Public Datasets
Cataloging common data quality issues, focused on tabular datasets up to 1G in size.
Optimizer Amalgamation
They introduce the problem of “optimizer amalgamation”, which is basically distillation for optimizers. I’m not convinced this is actually working, especially since they don’t compare to various learned optimizer papers. But kind of an interesting problem. Their basic approach is to backprop wrt learned optimizer params across a few training steps, which should only necessitate keeping a few copies of the model.
Delta Tuning: A Comprehensive Study of Parameter Efficient Methods for Pre-trained Language Models
Whole bunch of experiments finetuning/adapting language models in various ways. Has huge tables of results for various tasks in a standard setup, which is awesome. Finetuning the whole model is basically always the best, and prompt tuning is terrible. If you combine multiple approaches (e.g., prompt tuning and adding learned prefixes throughout the network, or adding a couple layers at the end and adapter modules throughout the network), results get really unpredictable and who knows what will work best when. Good related work going over many approaches to make pretrained models work well on downstream tasks.
Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs
Using depthwise separable convs with large filters seems to be a good idea. Although they don’t have any timing results, and I don’t think Swin Transformers or ResNeXt-101 are the SotA baselines. Five observations/guidelines to get this working well:
Even with large depthwise convs, they still aren’t the main bottleneck in the network. At least with their custom CUDA kernels that make them suck way less (torch impls are apparently terrible).
Super important to have identity connections. Large kernels wreck performance without them. Apparently some related work also proved that transformers tend to lose rank doubly exponentially in depth without skip connections or FFNs.
Helps to pull the RepVGG trick of having a 3x3 dwconv in parallel with the larger dwconv. Can fuse these at test time.
Larger receptive fields seems to help more for downstream tasks than ImageNet pretraining. Seems to have to do with enabling the model to look at shape.
Large kernels can help even when they’re larger than the input size. Zero-padding ends up making output from a fixed filter depend on position.
Anti-Oversmoothing in Deep Vision Transformers via the Fourier Domain Analysis: From Theory to Practice
Elegant proof that attention acts as a low-pass filter. Basically, with softmax nonlinearity, attention mat is square and positive, so perron-frobenius theorem guarantees that dominant eigenvector is all positive. And any all positive filter is a low-pass filter, at least in some sense. They propose two modifications to transformer blocks in ViT variants that give about 1% more accuracy, but are almost certainly not worth the time overhead. They separate out either the attention matrix (variant 1) or the feature maps (variant 2) into spatial low and high-freq components, and they apply a gain > 1 to the high frequency component so that it doesn’t vanish. A faster module capturing the same idea might be promising. I’m confident it’s not worth the time because we tried OctaveConv, which does a similar high and low-frequency separation but without the bandwidth-bound gain step in the middle.
AUTOMATA: Gradient Based Data Subset Selection for Compute-Efficient Hyper-parameter Tuning
"Our experiments show that using gradient-based data subsets for hyper-parameter tuning achieves significantly faster turnaround times and speedups of 3×-30× while achieving comparable performance to the hyper-parameters found using the entire dataset.” I’m not super sold on their exact coreset construction method, but I am cautiously optimistic about intelligent subset selection for hparam selection. Method is basically to select a (weighted) subset of points via OMP that approximates the true (full-batch) grad wrt the params, evaluated a few epochs into training. For efficiency (and because cudnn won’t even give you the grad wrt one sample in the batch), they select entire minibatches, not individual samples. Would be super cool if we could combine this with muP to tune hparams on both smaller datasets and smaller models.

⭐ Rethinking Nearest Neighbors for Visual Classification
Combine a knn classifier for the final embedding with the regular linear classifier for downstream tasks. Two components: 1) during training, upweight loss from samples that have high cross entropy according to knn classifier; there are hparams here for both num neighbors returned and RBF bandwidth. 2) during test time, linearly interpolate predictions of knn and linear function, using yet another hparam. It consistently yields a solid accuracy bump, but I have a little skepticism given the number of hparams added. Plus the extra potential extra inference cost. Might be something where you can just tack on a knn module to the final output and get better accuracy for very little extra compute time.

Global Filter Networks for Image Classification
They just elemwise multiply (not even a matvec) in the frequency domain and then convert back. It’s basically a depthwise conv computed in the frequency domain, so probably extremely bandwidth-bound. Results didn’t suggest a good time vs accuracy tradeoff.
