2022-3-27: Pathways, token dropping, decoupled mixup

Overcoming Oscillations in Quantization-Aware Training
Two changes to raw STE quantization: 1) regularization term to try to dampen oscillations in quantized weights; 2) "If the oscillation frequency of any weight exceeds a threshold f, that weight gets frozen until the end of training. We apply the freezing in the integer domain, such that potential change in the scales during optimization does not lead to a different rounding.” The damping seems to help quite a bit (reproducing a 4-bit quantization paper we saw submitted to ICLR a while ago). The freezing helps similarly. Doesn’t seem as effective as some other papers that got iso accuracy on ImageNet, but reproduction of oscillatory behavior hurting performance is a useful datapoint.

Optimal Fine-Grained N:M sparsity for Activations and Neural Gradients
Trying to speed up not just X @ W and Y @ W.T, but also X.T @ Y. I have no idea why they’re trying to prune gradients, let alone with 1:2 sparsity, but it’s a clear negative result, even with their fancy minimum-variance unbiased estimator—model still trains, but like 4% lower accuracy on ImageNet. No timing results, and no results with just f16 2:4 weights or f16 2:4 weights and 2:4 activations. Instead they have some tables with either 4-bit quantization or 1:2 gradients.


Accelerated Sparse Neural Training: A Provable and Efficient Method to Find N:M Transposable Masks
Someone finally did the thing where you make both W and W.T 2:4 sparse like Ampere GPUs require. They have python code simulating it, but aren’t actually calling the sparse CUDA kernels, sadly. They have closed form expressions for how many such masks there are (which they call “mask diversity”) as a function of N and M in N:M sparsity (p4). They can’t hit accuracy as good as unstructured at 2:4 sparsity, but they basically can at 4:8 sparsity. Consistent with previous literature and my own experience, less structure yields more accuracy at fixed sparsity. They have this approximate min-cost-flow algorithm for how to determine which sparse mask to use, which seems unnecessarily complex, even for 4:8 sparsity (which is itself not practical). I would believe this helped if they had magnitude pruning as a baseline, but they don’t. They preserve original accuracy on at least some tasks (table 3), but only with impractical 4:8 sparsity; whereas NVIDIA ASP preserves accuracy at 2:4 sparsity, though only for the forwards pass. Overall, this is a negative result for 2:4 sparsity in the backwards pass at iso accuracy. But it suggests a weak positive result for 2:4 sparsity improving the training time Pareto frontier.


⭐ Decoupled Mixup for Data-efficient Learning
They propose using a different loss along with mixup-style augmentations that seemingly consists of removing the other class’s logit when computing the probability for each class. So you’re basically telling the model (correctly!) that the class probabilities can sum to more than one. Claims extremely consistent improvement across different mixup strategies and vision dataset. I did find the English in the paper a little challenging though. Might not reproduce, but decent chance this yields an easy win. Also a good pointer to the numerous mixup variants that have previously been proposed.


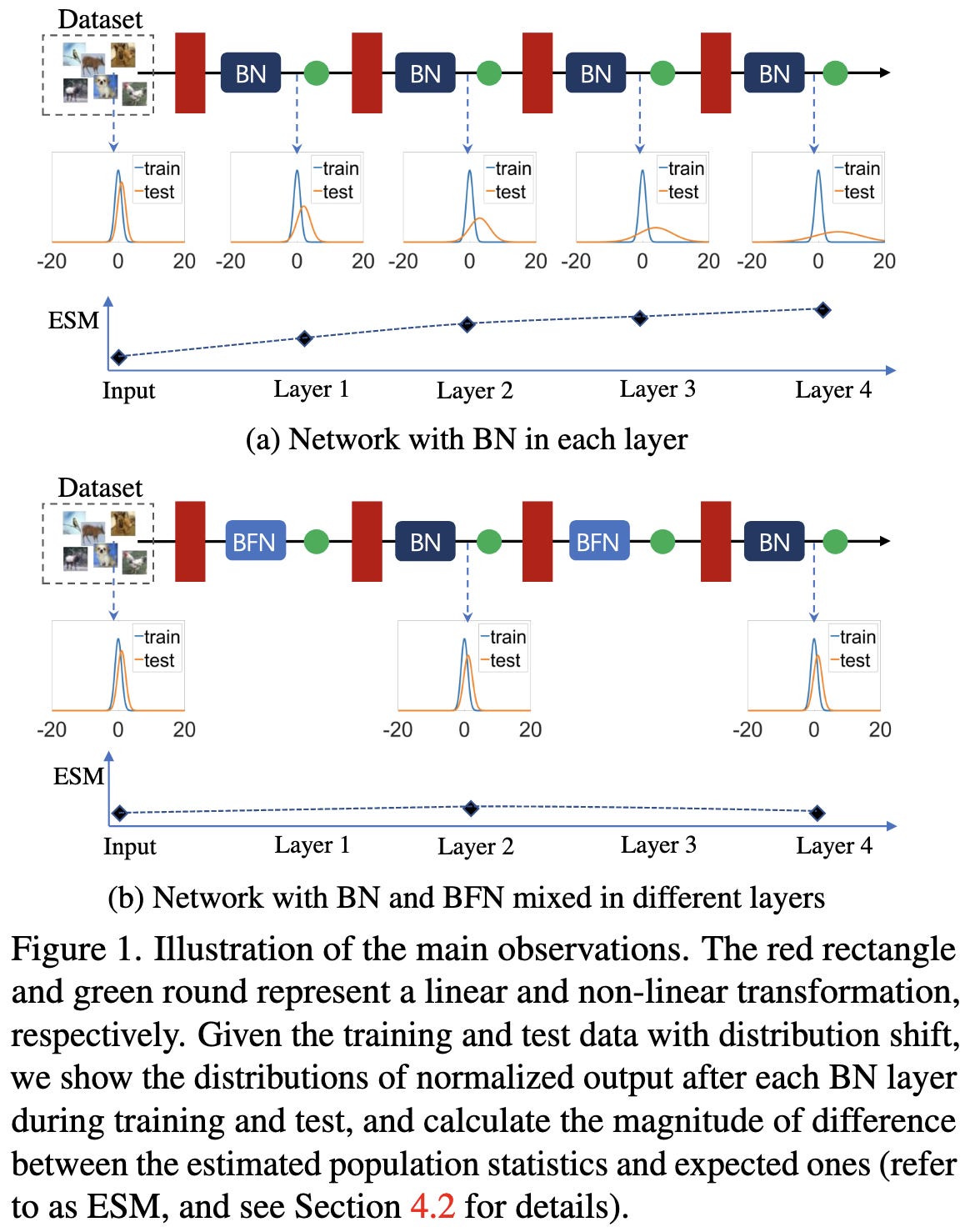
Delving into the Estimation Shift of Batch Normalization in a Network
To avoid accumulating divergence between train and test {mean, variance} as you get deeper in the network, swap out every other batchnorm for a groupnorm. Or, more precisely, replace the second BN with a GN in each bottleneck block in a ResNet. Seems sensitive to exact replacement policy, so not clear how generalizable this approach is.


SS-SAM : Stochastic Scheduled Sharpness-Aware Minimization for Efficiently Training Deep Neural Networks
Instead of running SAM at every step, and always incurring the overhead of the extra forward pass, just run it according to a scheduling function. But they don’t bold the results in their copious, large tables, or state what worked best in their conclusion, so no idea what the takeaway is here, except that they assert that (consistent with previous work) you can get away with not always doing the SAM step and still achieve the full SAM accuracy.
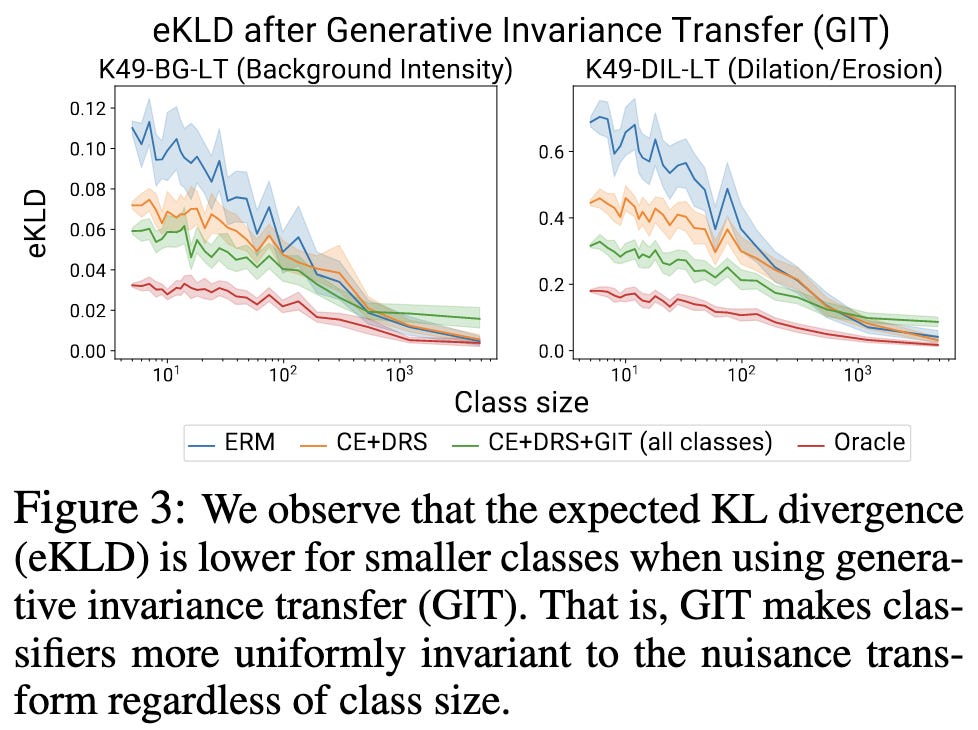
Do Deep Networks Transfer Invariances Across Classes?
Networks seem to learn invariance on a class-by-class basis, and are less invariant to nuisance transforms on rarer classes. They propose Generative Invariance Transfer (GIT) to fix this. Basically performs more aggressive data augmentation on infrequent classes, with the augmentation consisting of an image-to-image translation network. They compare to RandAugment on CIFAR-{10,100}, and do slightly better. Suggests that learned data augmentation can do better than heuristics.




Delta Distillation for Efficient Video Processing
When doing video compression, run a big teacher model on the keyframes, and a student model to predict the differences between frames (an easier task requiring less model capacity).



Practical tradeoffs between memory, compute, and performance in learned optimizers
Big progress on learned optimizers. They now often outperform fixed optimizers once trained on enough tasks (look at the orange, yellow, and green dots). Unsurprisingly, you need a large batch size to amortize the overhead of the learned component though. I’m still not sure this is worth the complexity in practice, but great progress on an interesting research problem.


VQ-Flows: Vector Quantized Local Normalizing Flows
Only results on simple problems, but an interesting and well-written introduction to normalizing flows. Basic idea in this work is to chop up the latent space using vector quantization, and have everything be a diffeomorphism locally within each quantization bucket.
Hybrid training of optical neural networks
Training optical networks is hard because it’s no longer discrete, and your noise model might not match what actually happens. They help mitigate this by running the forward pass on the target optical accelerator and only the backward pass on regular silicon. Wasn’t sure what to make of their evaluation.

⭐ Token Dropping for Efficient BERT Pretraining
Results show 25% BERT pretraining speedup at iso downstream accuracy. They keep the tokens that have the highest MLM losses, moving averaged over times they’ve appeared in past sequences. Certain tokens, like [MASK], [CLS], and [SEP], are never dropped. Padding tokens are always dropped.



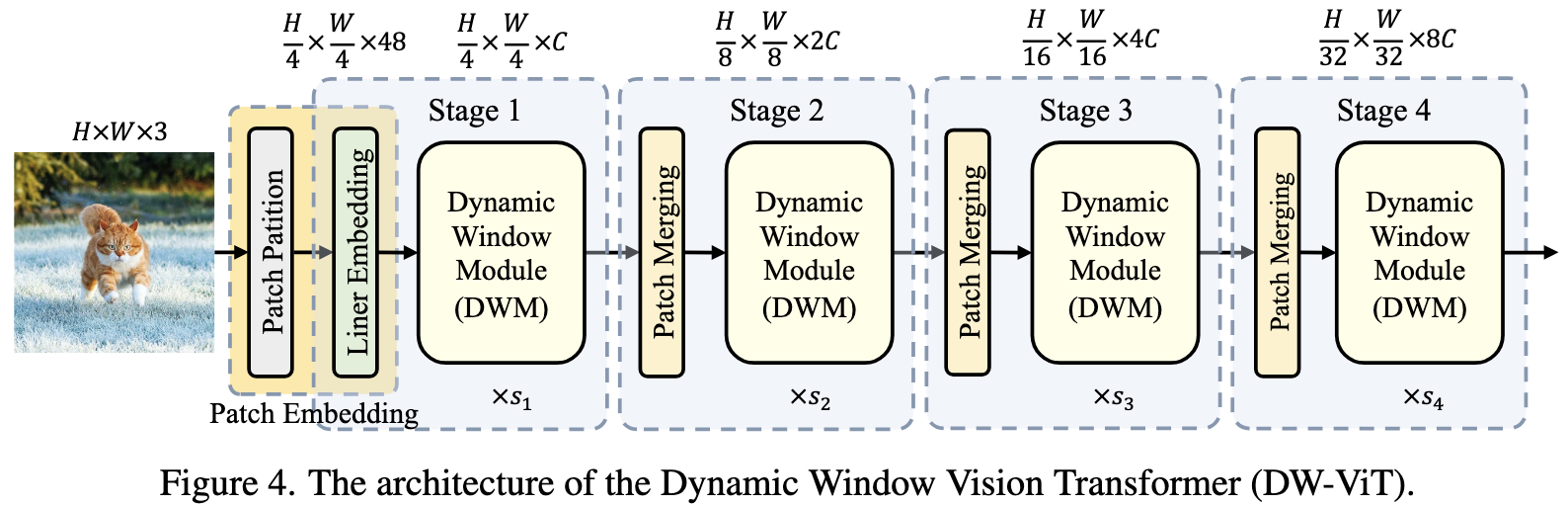
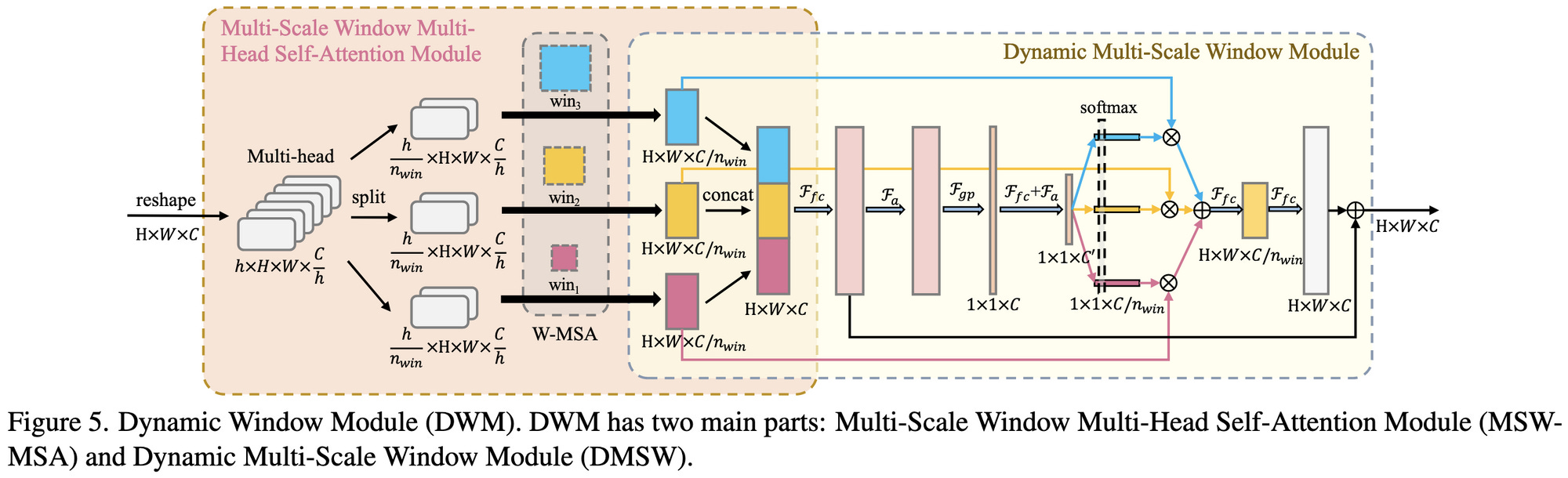
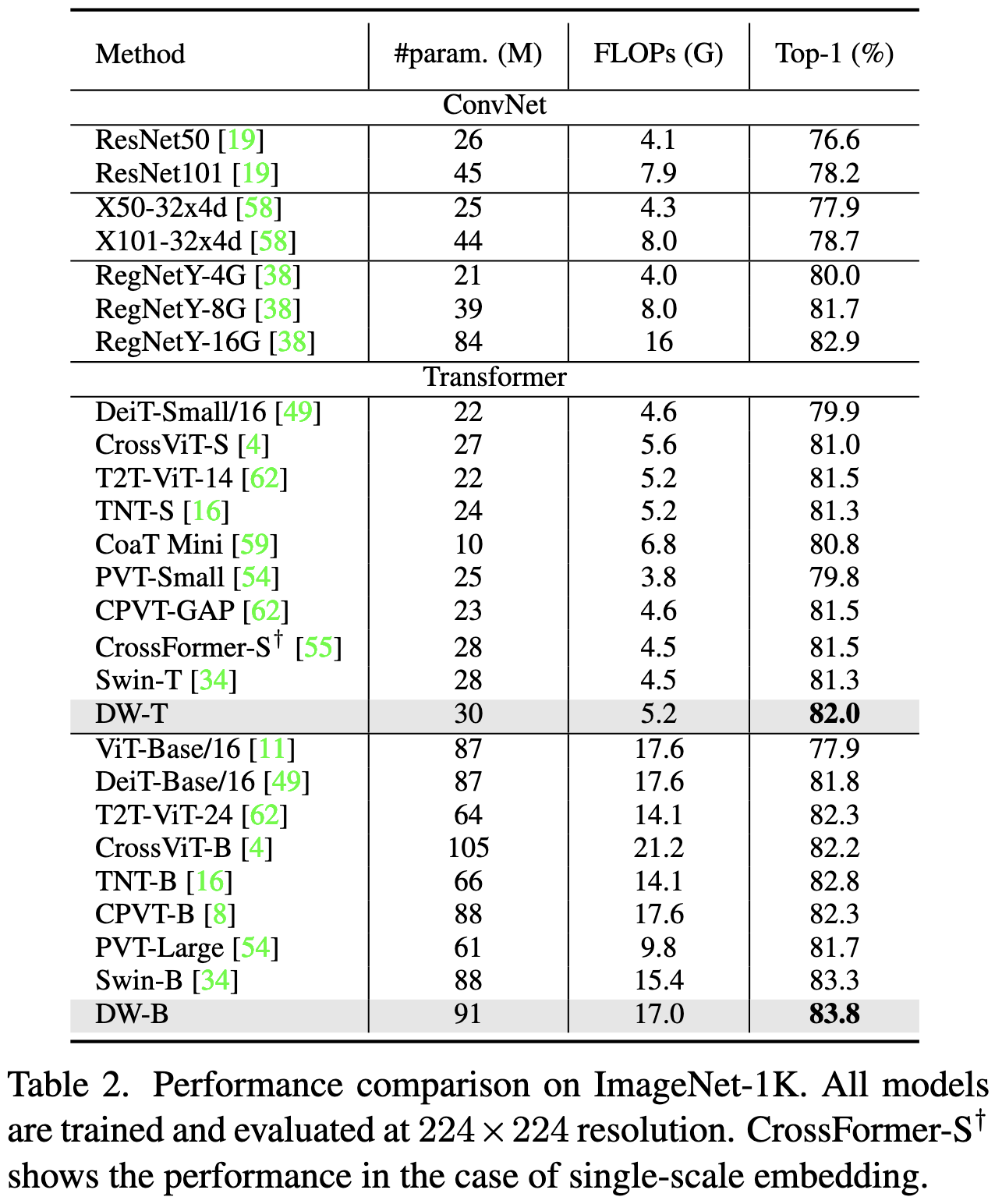
Beyond Fixation: Dynamic Window Visual Transformer Complicated architecture but seems to beat Swin Transformer as measured by FLOPs and params. No wall time numbers.

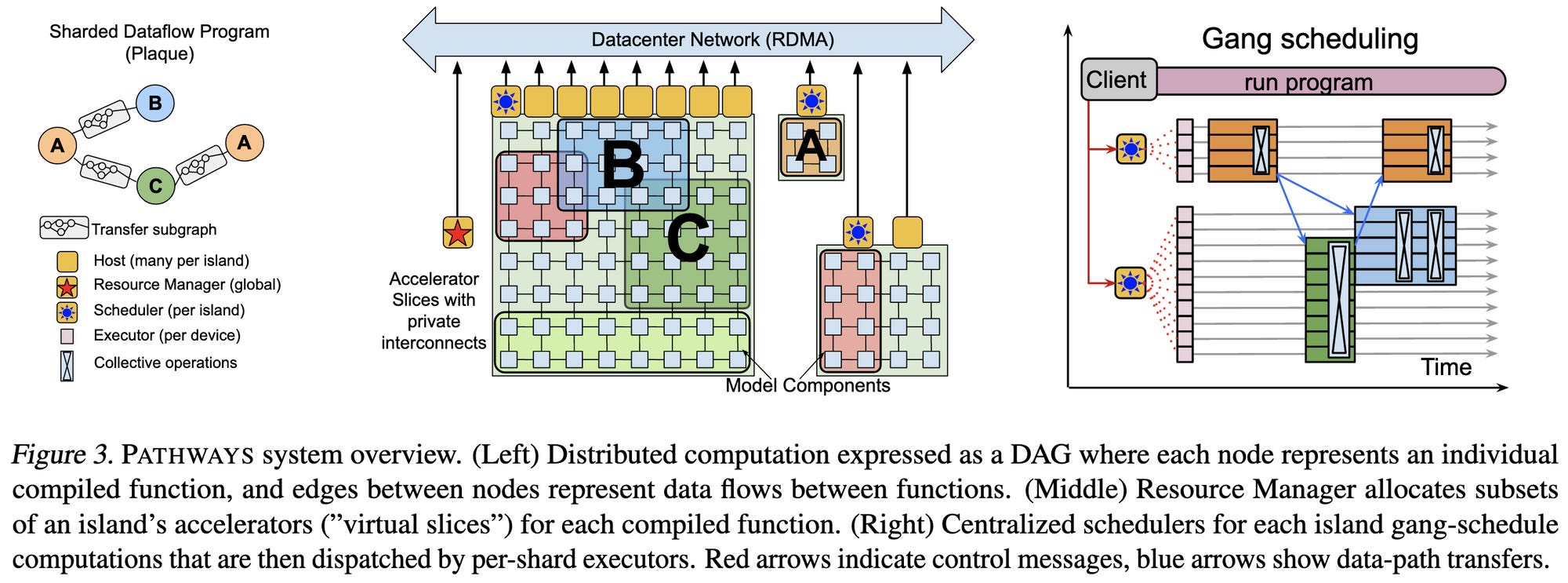
Pathways: Asynchronous Distributed Dataflow for ML
Dense systems paper describing a new Google system for large-scale distributed training. The way I think about this is that it traces and compiles your training program not to run on a device, but to run on a datacenter. Tons of complex considerations around scheduling, flexibility, parallelism schemes, and so on; this must have been a monster to build, and that’s not even factoring in Google’s internal Ray alternative (Plaque) that this is built on.
Overall, this kind of seems like clearly the right way to do things in theory—it’s strictly more flexible than forcing every node and every GPU to run the same program. But in the near term, I would be scared of having something this complicated compiling my code until it was really battle tested and documented well enough that I could reason about it; performance profiling is hard enough just taking into account how individual GPUs or TPUs work, let alone datacenters. And given our ability to design the workload (i.e., architecture and training recipe) to be easy, I’m not sure this much rope is really needed.