2022-3-6: N:M sparse attention, Rethinking demonstrations, Shift instead of attention

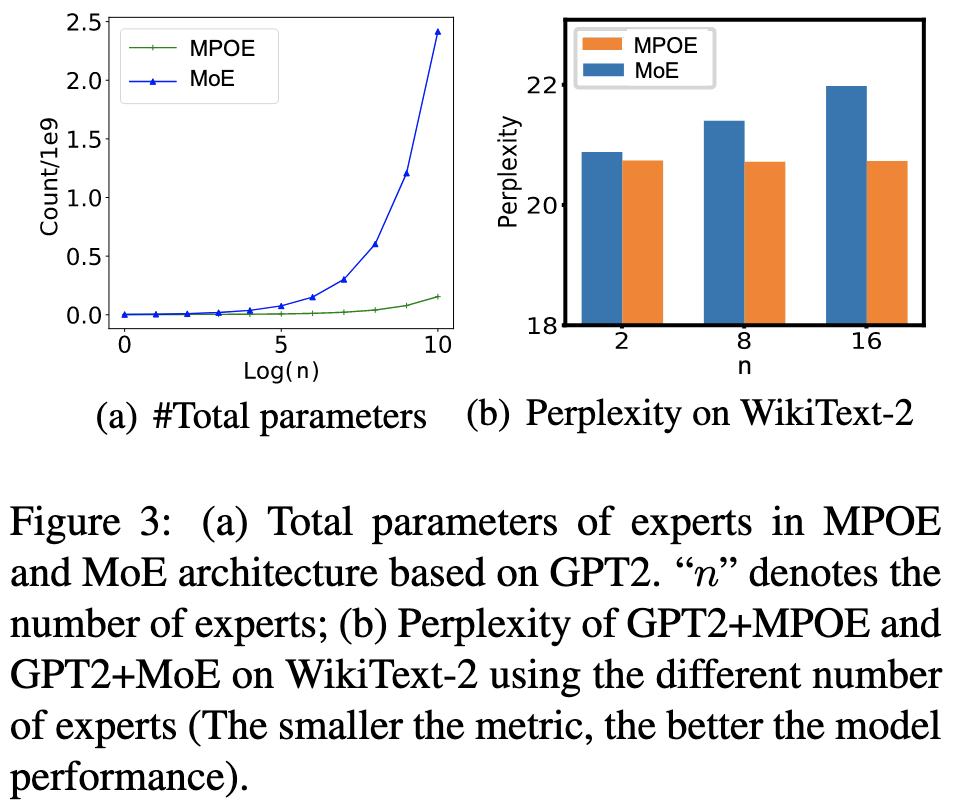
Parameter-Efficient Mixture-of-Experts Architecture for Pre-trained Language Models
Factorize the experts and reuse the biggest matrix in the factorization across all the experts. Maybe outperforms switch transformer-style MoE when grafted onto GPT-2? At the operating point, about 1.25x more params overall, whereas switch-like baseline was 4.67x. Seems to do better than regular MoE on WikiText-2 perplexity:
HyperPrompt: Prompt-based Task-Conditioning of Transformers
Goal is to do better than vanilla finetuning for LLMs. They 1) still do finetuning on the whole model, but also 2) add extra task-specific Keys and Values to all the self-attention layers. Since the number of queries is still equal to the number of tokens, you can just do this and the model works fine. They generate the keys and values for each module using a hypernetwork that takes in where the module is and what the task is. It’s only this hypernetwork that has its prompts tuned, not the original network (AFAICT). Minimal inference-time param cost, but no latency vs accuracy numbers. Seems to work as measured by param count:

Do Transformers use variable binding?
You might hope that transformers can learn abstract rules, and then apply them to particular inputs, logic program style. But doesn’t look like they do, as measured in some careful experiments where they would do great iff they developed this ability. Specifically, if you keep the structure of the task the same (e.g., sequence reversal) but swap the vocabulary at test time, transformers completely fail.
⭐ Dynamic N:M Fine-grained Structured Sparse Attention Mechanism
They add ampere sparsity into the self-attention kernels at runtime (can’t do it statically since attention mat not known ahead of time) and get 1.25-1.9x speedups at iso accuracy. Seems to compose pretty well with fast attention variants, although requires some thought in each case (and maybe unreported trial and error?). Works because they wrote CUDA kernels that fuse the pruning into the GEMM kernel that produces the attention matrix. They don’t quite have pareto frontiers, but it seems basically just as accurate and faster. We might be able to just use their library to get faster attention. Also strengthens my conviction that we should be exploiting ampere sparsity.



Resolving label uncertainty with implicit posterior models
Trying to get models to work better with crappy or insufficient labels. E.g., can you do classification when you only know for sure a few classes that each image isn’t. They learn a sample-specific prior over labels, and have a couple modified cross-entropy-like losses (there are two because of KL(p||q) vs KL(q||p)). Need to stare at the math and/or code for longer, but seems like there’s a clever idea here that might help get self-distillation or self-label smoothing working really well.
BagPipe: Accelerating Deep Recommendation Model Training
They do a bunch of analysis of DLRM access patterns and basically build a giant distributed cache with synchronous training semantics. Good profiling* and probably good systems work. Interesting cache design because 1) some keys are super hot and, 2) you can read ahead as far as you want within an epoch, so you know the access patterns in advance.
*E.g., found only 8.5% of time spent in fwd-bwd, 1% of embeddings are responsible for 92% of accesses.
FastFold: Reducing AlphaFold Training Time from 11 Days to 67 Hours
A bunch of people at a Chinese university (not DeepMind itself) sped up alphafold by a lot using systems optimizations. Got 90% strong scaling up to 512 GPUs with a customized model parallelism approach along with good communication interleaving. This is mostly interesting to me because, basically, AlphaFold is weird. It has these highly custom blocks baking in structural priors, and it also runs its own output back thru 4 times (1-4 times at random during training). I don’t understand the details, but this points to the existence of a long tail of well-tuned, domain-specific architectures we don’t hear about in mainstream ML literature. Contraindicates “one model to rule them all” conjecture.
Standard Deviation-Based Quantization for Deep Neural Networks
Bag of heuristics to get to 76.4% ResNet-50 on ImageNet accuracy at test time, and with constraint that weights are all either 0 or a small power of 2. They talk about how setting their learned clip threshold as a number of standard deviations helps, how gradually reducing the bitwidth while keeping the thresholds constant helps (so that the dynamic range just gets halved), and how shrinking the gradients wrt their clip threshold (effectively increasing the weight decay on it) helps. I get the sense it’s mostly just that they have this trainable threshold with a ton of weight decay.
I’m skeptical of all these papers’ claims of “improvement” because the literature seems too saturated to maintain a total order, but the absolute numbers here are enough to bolster my belief that iso accuracy 4-bit logarithmic quantization by the end of training is possible (since we’ve seen this in a couple other papers). Which in turn suggests that 8-bit partway thru training and/or in part of the network is reasonably promising.
Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
“Randomly replacing labels in the [fine-tuning] barely hurts performance, consistently over 12 different models including GPT-3. Instead, we find that other aspects of the demonstrations are the key drivers of end task performance, including the fact that they provide a few examples of (1) the label space, (2) the distribution of the input text, and (3) the overall format of the sequence.” I’m not sure what to take away from this concretely, but it seems like important data about what’s really going on in fine tuning.

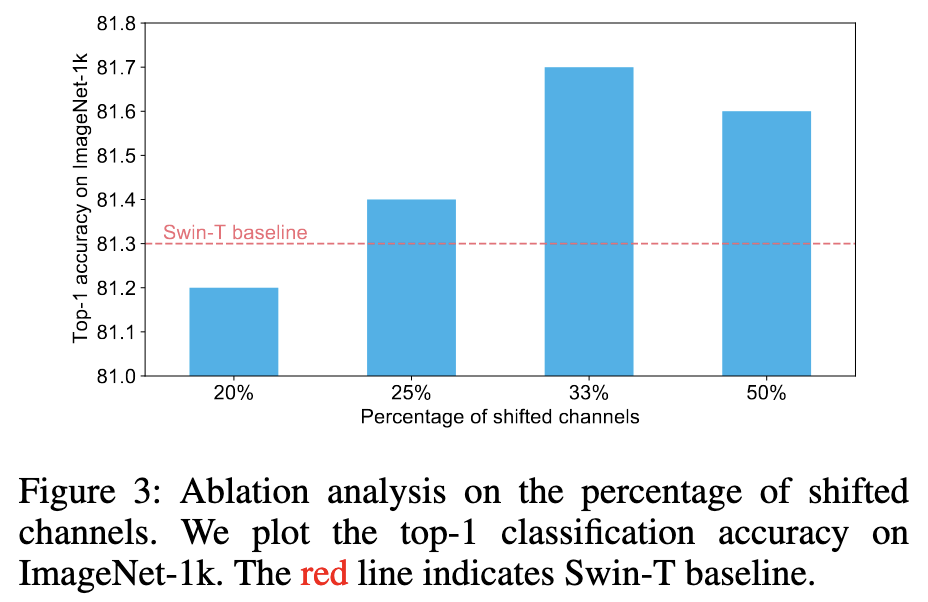
When Shift Operation Meets Vision Transformer: An Extremely Simple Alternative to Attention Mechanism
They replace the attention mechanism in a Swin transformer with a simple spatial shift of some of the channels. Works just as well, essentially, as measured in accuracy, flops, params, and time. Although their times are inference on a GTX1080-Ti, which doesn’t have tensor cores, and therefore probably makes their bandwidth-bound ops look better. They argue that this suggests that attention isn’t that important to ViT accuracies, and instead it’s more from AdamW, GELU, and training for 300 epochs (see nice ablations table below).



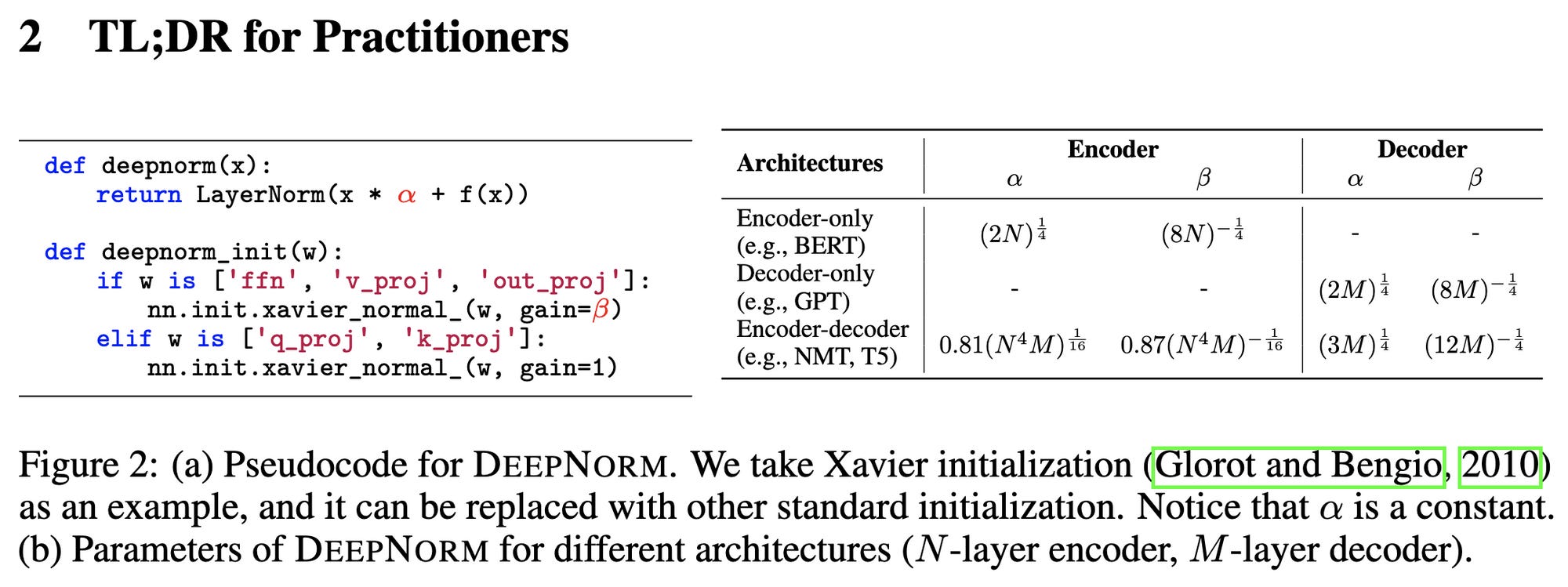
DeepNet: Scaling Transformers to 1,000 Layers
TLDR image sums it up pretty well. If you dig into the appendix, you’ll find that their derivations don’t really point to these exact numbers, but instead fairly abstract formulas that these particular numbers satisfy. Which is kind of good, but also makes it hard to build intuition for what’s going on here.