


2022-4-17: Neighborhood attention, 830k TPU-hours, Revenge of the ViT

deep-significance - Easy and Meaningful Statistical Significance Testing in the Age of Neural Networks
Proposes significance testing based on overlap of CDFs of outcomes. Doesn’t address the main problem, which is that no one reports multiple runs in the first place, but it’s an interesting statistic to look at. Might be an informative way to monitor distributions of weights, gradients, etc, changing over time or across runs.

Any-resolution Training for High-resolution Image Synthesis
What if instead of trying to shoehorn our whole dataset into a fixed resolution, we just used the original resolution? To make this work for generation, they train their generator and discriminator on fixed-size patches with scaling. The generator is told the scaling. So essentially, instead of training on the distribution of images of a fixed scale, it’s trained on a continuous mixture of many scales. Works really well.


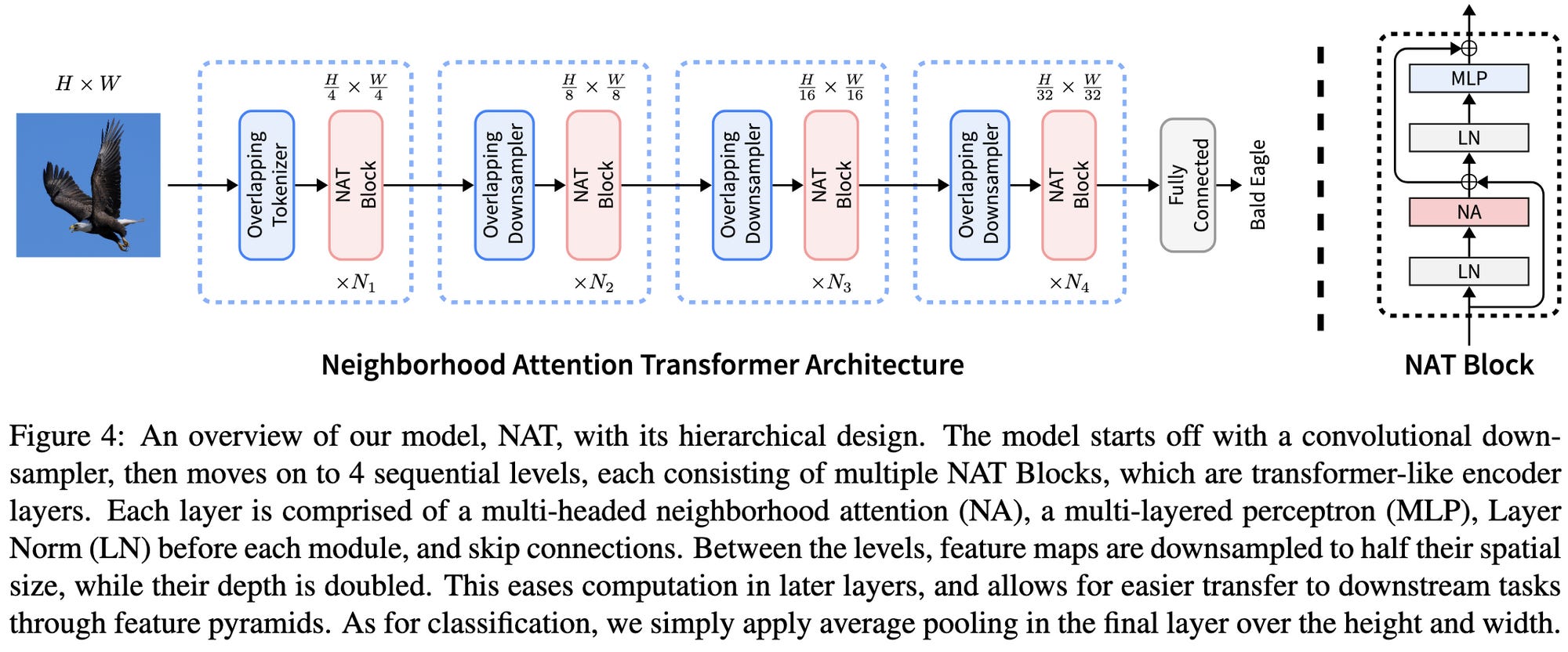
⭐ Neighborhood Attention Transformer
Each pixel attends to a square neighborhood of other pixels around it. Seems like clearly the ideal approach mathematically, but avoided by other papers because it’s hard to execute efficiently. When measured in FLOPs or parameter count, seems to define a new Pareto frontier. And apparently with their CUDA kernels, it runs at about the same speed as Swin transformer (tweet) but with higher accuracy. Trained using TIMM with CutMix, Mixup, RandAugment, Random Erasing, and same training schedule + hparams as swin transformer.



CLUES: A Benchmark for Learning Classifiers using Natural Language Explanations
Collection of 180 datasets for learning from natural language explanations. They also propose a new model for this task, which works significantly better than RoBERTa, at least when pretrained on most of their datasets. Also a good ablation experiment suggesting that models struggle with quantifiers, complex sentence structure, and negation in explanations. I can imagine a world where users users adapt pretrained models to their problem just by writing out a few examples with simple explanations for the right answer. Very different interface for adding prior knowledge than the normal practice of feature and loss engineering.





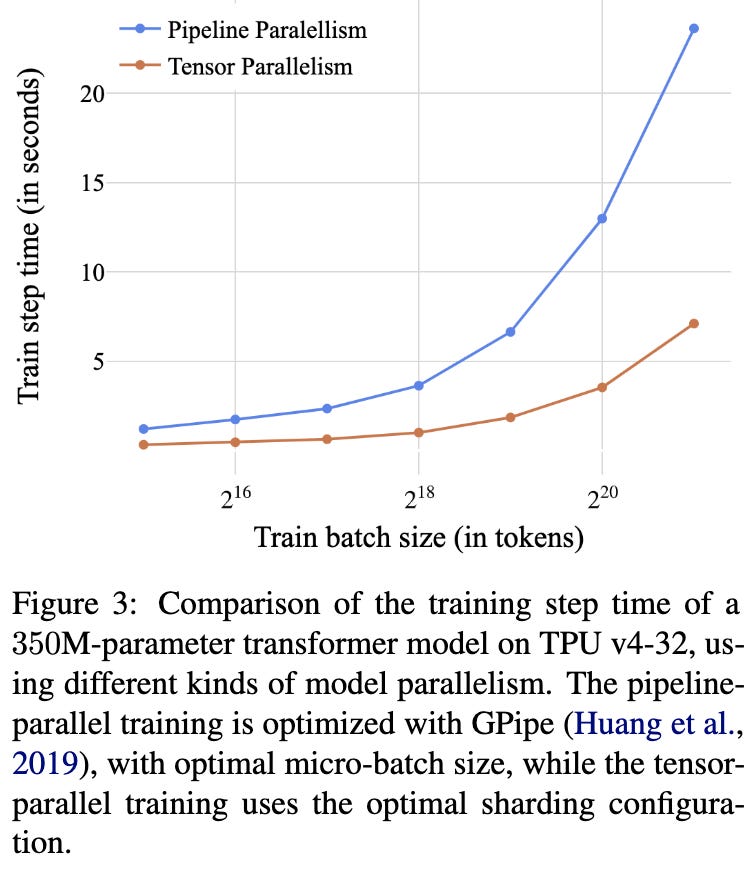
Scalable Training of Language Models using JAX pjit and TPUv4
Cohere.ai talking about their training infrastructure. Mostly they have some interesting benchmarking here, but there are also some non-obvious design choices to help them iterate on their model development. E.g., they define models using config files, partially to enable static analysis and estimation of latency or memory requirements. Main tool they lean on is JAX pjit (partitioned just-in-time) to shard model across all the TPUs in their pod.


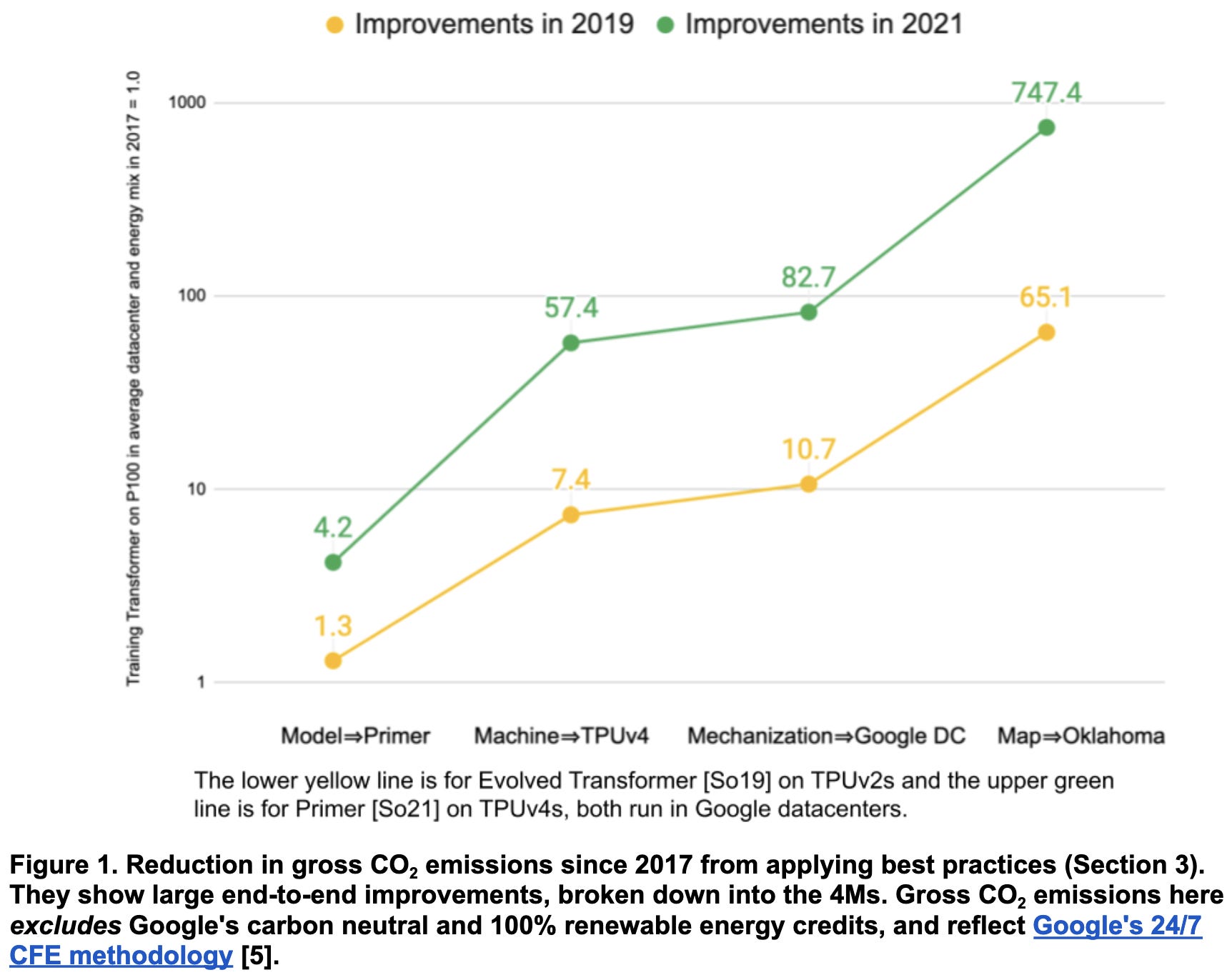
The Carbon Footprint of Machine Learning Training Will Plateau, Then Shrink
One third scientific paper, one third google press release, one third google internal memo. This is a google doc exported to PDF talking about how external estimates of google’s carbon footprint for models like the Evolved Transformer have been off up to 100,000x. Talks about how
People can just plain misunderstand the training pipeline described in a paper (and advise that authors estimate the carbon impact themselves to avoid this),
People don’t account for clean energy sources, and
People don’t account for algorithmic/model improvements.
They don’t present any evidence that the carbon footprint of machine learning will shrink, but they do point out that, internally, it’s plateaued at <15% of Google’s energy footprint over the past three years.
Does Robustness on ImageNet Transfer to Downstream Tasks?
Mostly no, but Swin Transformer seems to retain more robustness than CNNs.

The MIT Supercloud Workload Classification Challenge
A big dataset of cluster logs, including CPU and GPU usage, memory usage, and file system logs. They also release a workload classification challenge. Goal is to “develop AI-based approaches that can identify workloads and provide feedback to researchers and datacenter operators for improving operational efficiency.”
CowClip: Reducing CTR Prediction Model Training Time from 12 hours to 10 minutes on 1 GPU
Proposes a gradient clipping method and learning rate + L2 penalty scaling method to allow huge batch training for CTR prediction without accuracy loss. An interesting aspect is that their gradient clipping has a per-feature threshold, so that is ends up clipping relative gradient sizes rather than absolute sizes. Might be useful for embeddings in language models also?
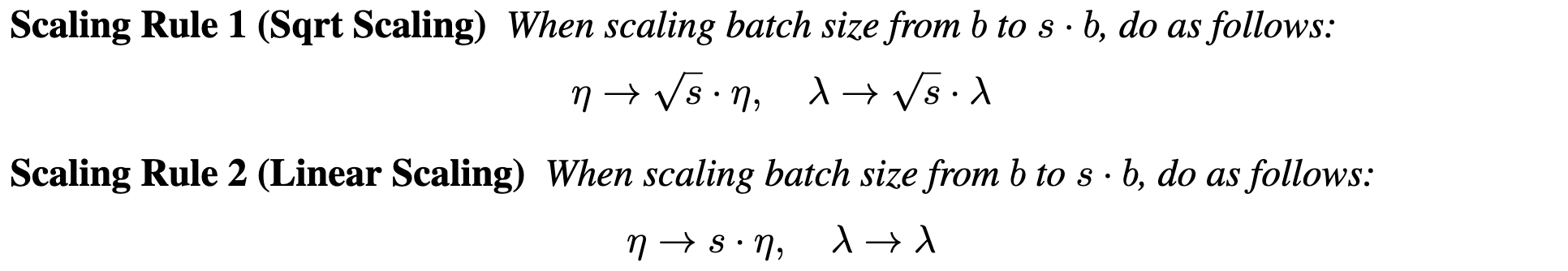



⭐ What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?
Google spent 830,000 TPU-v4 hours trying different combinations of language model types and pretraining pipelines so you don’t have to. Found that “a causal decoder-only pretrained with full language modeling performs best if evaluated immediately after pretraining, whereas when adding a multitask finetuning step, an encoder-decoder pretrained with masked language modeling performs best.” To get a strong mix of both generation and post-fine-tuning performance, start with a causal decoder-only model trained to predict the next word, and then pretrain it some more on MLM objective with a non-causal decoder. I don’t feel like I gained a ton of insight from reading this, but maximizing LLM performance on some task were my job, I would pore over every detail in this paper.


⭐ DeiT III: Revenge of the ViT
They introduce a training recipe for ViT that makes it work about as well as ConvNext when controlling for training throughput. Of particular interest is their data augmentation scheme, which seems to outperform TrivialAugment, RandAugment, and AutoAugment according to their ablations: “For each image, we select only one of this data-augmentation with a uniform probability over 3 different ones. In addition to these 3 augmentation choices, we include the common color-jitter and horizontal flip.” Just simple random crop (no resizing) for ImageNet-21k. Also uses LayerScale.




