
2022-4-3: Chinchilla, Bootstrapping rationales, HyperMorph

A Stitch in Time Saves Nine: A Train-Time Regularizing Loss for Improved Neural Network Calibration
Adding focal loss + a new auxiliary “Multi-Class Difference of Confidence and Accuracy” (MDCA) loss often works better than other calibration methods. No results saying absolute classification accuracy AFAICT, so not clear at what cost this better calibration comes.

Efficient-VDVAE: Less is more
Some simple training tweaks to get deep hierarchical VAEs to work better. HVAEs seem mildly promising from a local learning perspective. Their changes are using Adamax instead of Adam, a gradient smoothing scheme, smaller batch sizes, and messing with the numbers of layers that use different resolutions. Interestingly, there’s still a lot of inefficiency, in that you can just throw away 97% of the top-down information and not affect the quality of the results. This along with the sheer amount of improvement from simple tweaks is an example of the phenomenon that new tasks + workloads tend to be far less optimized than the ResNet-50s and BERTs often used in research.

MKQ-BERT: Quantized BERT with 4-bits Weights and Activations
Points out that the straight-through-estimator’s gradient wrt the scale does the wrong thing in some cases, increasing the scale when it should instead decrease it. They propose to instead make the quantization scales differentiable by training them to minimize quantization MSE. To get better results, they 4-bit quantize only some of the weights and activations, with the rest 8-bit quantized. They also use distillation to recover accuracy. I can’t tell whether this yields a better quality-speed tradeoff than other approaches from the results, which are just two tables with no numbers from existing methods. They also only go about 20-35% faster that 8-bit quantization.

Deformable Butterfly: A Highly Structured and Sparse Linear Transform
A negative result showing that using sequences of butterfly matrices (deformed to deal with different input and output dimensionalities) doesn’t work very well. Even with careful choice of the sequence of matrices and where they’re added, messing with just the last three bottleneck blocks in a ResNet-50 costs you 1.5% accuracy for ~2x param reduction. And that’s not even taking into account how wrecked you get from a utilization perspective (they don’t show timing results).

⭐ Training Compute-Optimal Large Language Models
They argue that the original Kaplan 2020 scaling laws paper underestimated the effects of training dataset size, largely as a result of using a fixed learning rate schedule instead of rescaling it to match the training duration*. They introduce a new model, Chinchilla, that’s trained with same compute budget as Gopher, but that works way better.
* BTW, this is exactly why `scale_schedule_ratio` is a first-class citizen in Composer. We’ve independently found rescaling the learning rate schedule to match the training duration to be critical.





CNN Filter DB: An Empirical Investigation of Trained Convolutional Filters
They collected a dataset of 1.4B 3x3 filters from common vision models trained on common vision datasets. Filters are more sparse and have lower entropy later in networks, and also when the dataset is smaller.


To Fold or Not to Fold: a Necessary and Sufficient Condition on Batch-Normalization Layers Folding
They observe that BatchNorms aren’t always next to a linear or conv layer in some networks, and so can’t always be combined with said layers using a straightforward algorithm. I’m sure their algorithm is clever, but I see this mostly as a testament to too little thought being given to inference optimization within model design; i.e., a fancy algorithm shouldn’t be needed here. But this work does supply a small, math-equivalent speedup and makes me wonder what other math-equivalent speedups people might not have thought of yet.

STaR: Bootstrapping Reasoning With Reasoning
Exploits the observation that prompting language models to generate “rationales” for their answers improves output quality (see below fig for an example question and rationale). But it’s hard to get a dataset of rationales. So what if we used our pretrained model to generate the rationales? A good language model can often generate a good rationale, but not always. So what they do is 1) ignore all generated rationales that don’t conclude with the right answer, 2) have it generate rationales with a modified prompt that adds CORRECT next to the right answer, and 3) iteratively “finetune on both the initially correct solutions and rationalized correct solutions” repeatedly until the whole process plateaus in accuracy.


“On CommonsenseQA [Talmor et al., 2019], we find STaR...performs comparably to a 30× larger model”. Though for learning to do addition, rationalization yields learning in fewer bootstrapping iterations but plateauing at a lower accuracy.
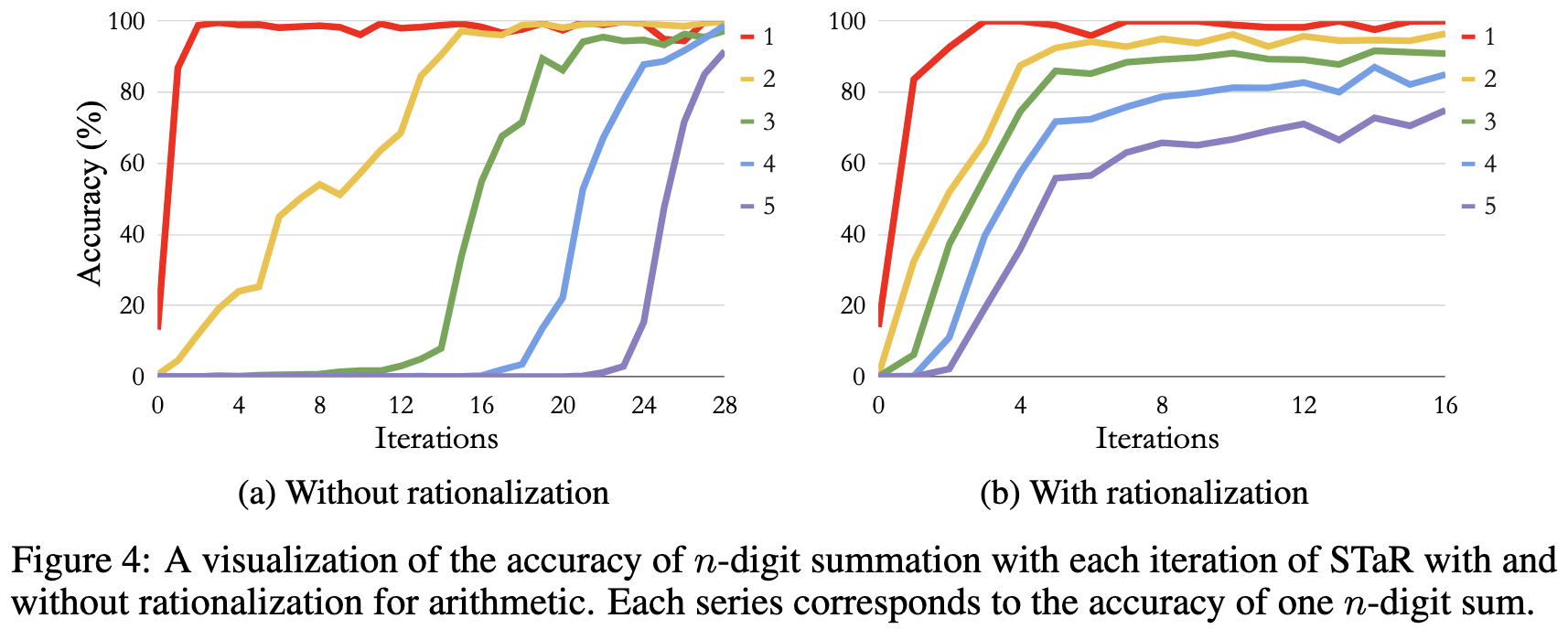
They also observe that “including few-shot prompts during fine-tuning [Wei et al., 2021] appears to have a meaningful performance benefit (60.9% to 68.8% without rationalization, 69.9% to 72.3% with rationalization). For this reason we generally recommend its use for at least some portion of the training”.
A Roadmap for Big Model
This is a 200 page PDF and I’m not gonna pretend I read it. What I found most interesting from the title, abstract, and intro though is that 1) not a single native English speaker proofread it, and 2) they’re trying to make “Big Model” become the term, rather than “Foundation model”. Made me feel like the AI community is kind of splintering into two.
Automated Progressive Learning for Efficient Training of Vision Transformers
Propose to speed up ViT training by gradually adding in layers. To initialize a newly-added layer within the network, they propose to copy over EMA of weights from the next layer (and also replace the next layer with these same weights?). What they actually train is a larger network, but they select a subset of layers to spend almost all of the training time on. Every once in a while they train the full network for 2 epochs and reassess (somehow?) which subnetwork to use. Works extremely well and has real timing results, though some of the accuracy lift is probably just from EMA of weights being independently helpful.




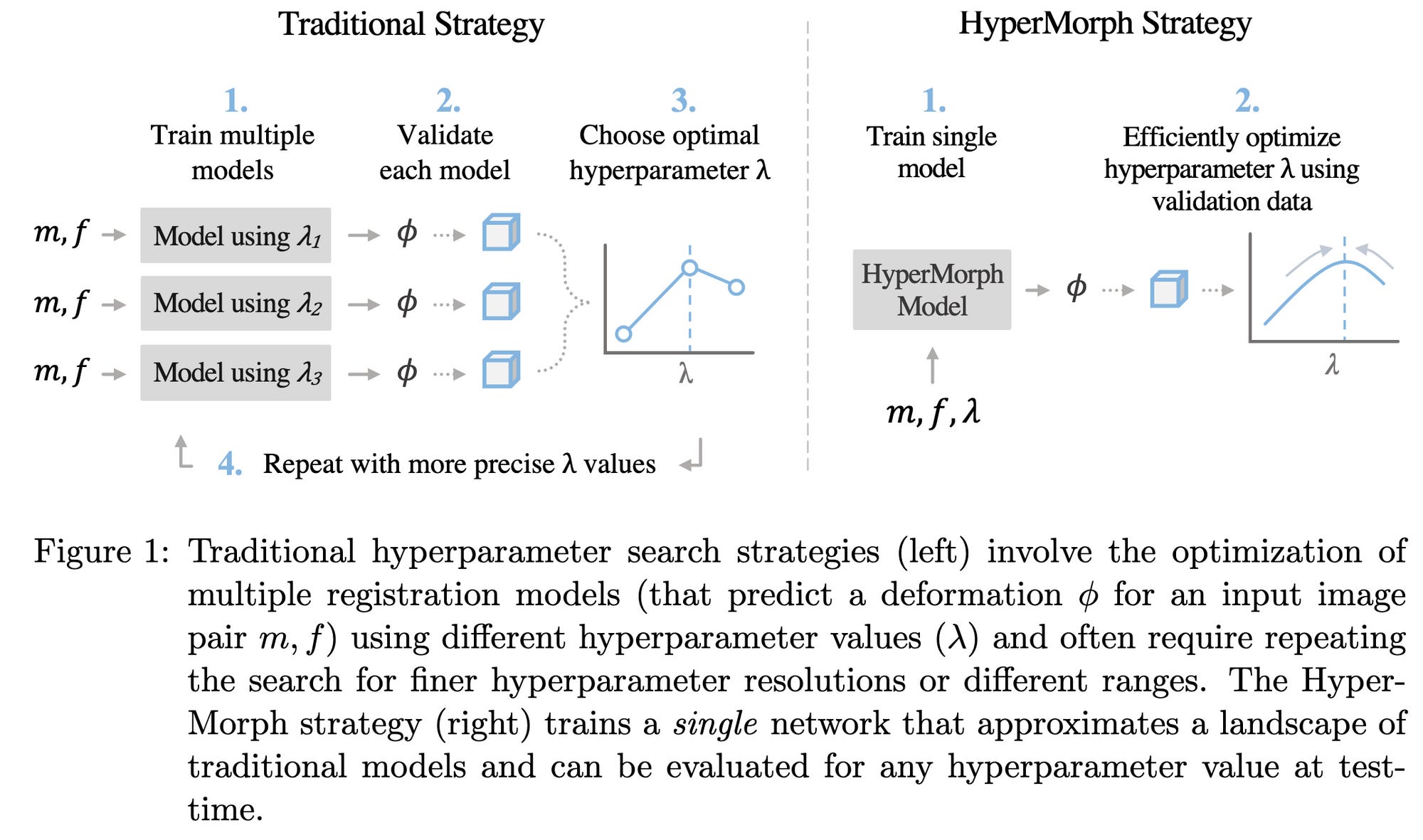
Learning the Effect of Registration Hyperparameters with HyperMorph
Some of my old labmates train a hypernetwork to spit out the network parameters given the hyperparameters, with no additional training. Only evaluated for medical image registration, but works at least as well as normal hparam search. One subtlety is that their formulation only includes hparams within the loss function (e.g., strength of L2 penalty), though it might be possible to generalize to other hparams. The hypernet they use is a 5-layer MLP, almost all of whose params are in the final linear layer of shape 128x{num_target_network_params}. Non-obvious benefit is that you can evaluate different hparams at test time without fine-tuning the model. Which could be super convenient for applying an off-the-shelf model to a new dataset. More evidence that hypernets are really powerful, though perhaps at the cost of greatly increased parameter count.



Transformer Language Models without Positional Encodings Still Learn Positional Information
Just like the title says. Although doesn’t generalize to encoders trained with masked language modeling objective. They conjecture that causal attention is needed to implicitly learn positions.

Remember to correct the bias when using deep learning for regression!
When minimizing MSE, deep neural nets often produce outputs that have nonzero bias. Explicitly correcting the bias can reduce error.
LinkBERT: Pretraining Language Models with Document Links
Pretrain language model on pairs of documents with MLM objective, but 1) choose pairs such that, often, the second document is linked to by the first, and 2) have the model predict whether the second doc is a continuation of the first doc, linked to by the first doc, or a random doc. Helps quite a bit for question answering.

Domino: Discovering Systematic Errors with Cross-Modal Embeddings
Addresses the Slice Discovery Problem, which entails identifying related low-performing subsets of samples. E.g., images of the sky incorrectly classified as birds. Because a slice is hard to define, they propose a particular evaluation framework and a large corpus of slice discovery settings. Their pipeline for identifying slices and converting them to text representations is pretty detailed, and uses models that vary by input domain (e.g., natural images vs chest x-rays), but seems to work better than previous approaches.



Generation and Simulation of Synthetic Datasets with Copulas
Roughly three components: 1) learn the CDF of each variable; 2) learn the correlation matrix of different variables; 3) sample from a copula, which is basically a bunch of (marginally) uniform distributions. You transform your copula sample with the matrix square root of the correlation matrix, and then run it through the inverse CDF to get your samples. AFAICT, better than just pretending your dataset is gaussian because you use the true CDF for each variable. Could be useful as a form of metadata about user data, without having to store the user data.
BDDM: Bilateral Denoising Diffusion Models for Fast and High-Quality Speech Synthesis
Drastically cuts down on the number of sampling steps in a diffusion model for speech generation, getting as low as three steps, and apparently becoming indistinguishable from human speech in as few as seven steps. Fairly heavy math to really get what’s going on, but they end up with a tighter lower bound than the classic ELBO in their modified training approach. Curious to know how this compares to the recent diffusion paper that just repeatedly distills and cuts number of sampling steps by a factor of two each time.

SepViT: Separable Vision Transformer
A vision transformer with an unusual attention structure I had a hard time making sense of from the paper. They alternate between doing attention within windows (or contiguous groups of 4+ windows “in the late stages of the network”), and attention across windows. The latter involves constructing a “window token” (which is a learnable vector, but also somehow summarizes the contents of the window?), computing the attention matrix using these, and then using these attention weights to construct linear combinations of all the windows.


