


2022-5-8: OPT-175B, Better depth estimation, Mobile TPU NAS

These paper summaries made possible by MosaicML. If you like these papers, you might like our open-source library for faster model training or even joining our team.
Convolutional and Residual Networks Provably Contain Lottery Tickets
For a CNN with skip connections and reasonable initializations + nonlinearities, there exists a wider and slightly deeper sparse CNN that approximates its outputs with high probability. Previous work couldn’t handle skip connections or convolutions. They actually instantiate their construction for some MNIST networks and show they can match the target network’s accuracy without training—instead just (approximately) solving a large number of subset sum problems to directly identify a sparse subnetwork. Doesn’t seem like a technique one would want to use in practice yet, but always nice to see a theoretical result that 1) applies to somewhat realistic networks, and 2) works without relying on quantities approaching infinity.

I also used this paper as an excuse to partially ramp up on theoretical lottery ticket work. To oversimplify, the idea is roughly:
We want to prove that, for a given target network, there exists a wider or deeper version that can be pruned to yield a sparse network with the same outputs (with high probability).
In a sequential network, if the activation function is Lipschitz continuous, and the operator norms of all the layers are bounded, you can bound the error at the output caused by error in any intermediate layer. Worst case, it’s just magnified by the operator norm of the Jacobian for the rest of the network, which is at worst the product of all the subsequent layers’ operator norms times activation function Lipschitz constants.
So we just select a subset of weights in each layer that approximate the behavior of the corresponding layer in the target network (which might require splitting each layer into two, at least in previous work). If the weights follow a nice distribution and the sparse network is wide enough, a satisfactory subset exists with high probability.
There also might be something smart happening with trying to get the errors into the nullspace of the rest of the network’s Jacobian (since I don’t see a bunch of operator norms in the theorems), or maybe it’s just random matrix theory to bound the operator norm probabilistically. Would love to hear from someone who works in this area on Twitter what’s up / how I just butchered that whole explanation.

Optimizing Mixture of Experts using Dynamic Recompilations
Built a system called “RECOMPILE” that lets users recompile the computation graph whenever they want, and is smart about reusing as much of the previously compiled graph as possible—e.g., if you alter the batch size but not the parameters, all the parameter memory will be untouched.

They use RECOMPILE to enable two MoE-specific optimizations:
Expert-specific capacities. Instead of overprovisioning input tensors for each expert by a fixed amount, they do it based on empirical fraction of tokens routed to a given expert. I’m not sure this should help, since you’re limited by the slowest expert, but it might in their experimental setup with more experts than devices (implying that groups of experts are executed serially on each device).
Caching routing assignments from previous epochs. This assumes multi-epoch training (so no text pretraining), and that your data augmentation doesn’t mess with the assignments.
Evaluated on CIFAR-10 with 4x pre-tensor-core GPUs using some unknown model. Their optimizations seem to improve runtime without harming accuracy in this setup.

Also, props for citing (and reading!) the original Mixture of Experts paper from 1991, and some other MoE work from the 90s.
Dynamic Sparse R-CNN
Object detection with an improved version of Sparse R-CNN. Two main differences:
In the original version, the bounding proposals are learned at training time but then fixed for inference. In this work, they’re generated for each image.
In the original, there’s a one-to-one matching between ground truth boxes and proposed boxes during training. In this work, they use an optimal transport approach in which several proposals can be mapped to one ground truth box, with the number allowed increasing throughout training as the proposals get better.
27% training time slowdown vs Sparse R-CNN at constant epochs, so probably an AP vs latency improvement, but would be nice to see this characterized directly. Like nearly all object detection work, there are a bunch of hyperparameters, heuristics, and specific architecture choices baked in. But seems to be an improvement over their matched baseline (Sparse R-CNN).



Efficient Fine-Tuning of BERT Models on the Edge
Trying to reduce memory consumption for fine-tuning, motived by desire to do on-device learning. They propose to fine-tune a subset of the weights in each FFN layer, chosen based on a heuristic derived from an initial full fine-tuning period (which they call “priming”). Namely, they look at how far neurons moved under L1 distance during that time, and choose the top r% of those that moved the most. The clever thing they do is permute the weight matrices such that the chosen weights are all contiguous.

They only compare to an alternative that just finetunes the biases, rather than any gradient checkpointing or prompt tuning methods, so I’m not sure this method is useful. But I do like how they 1) actually timed their approach on a Jetson device, and 2) exploited the ability to permute weight matrices without changing the network’s behavior.
Note that they use “nodes” to refer to neurons, not machines in a distributed training setup.
Retrieval-Enhanced Machine Learning
Lays out a conceptual framework and research agenda for combining retrieval approaches and machine learning models. Identifies challenges like having one retrieval system support multiple production models. Also serves as a pretty good survey of existing work.

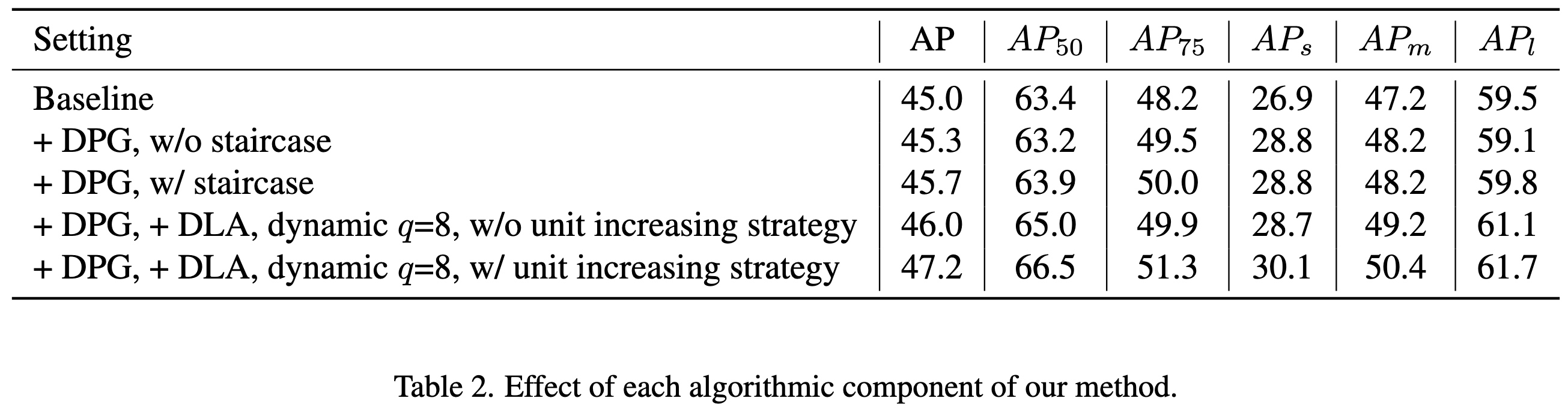
⭐ One Weird Trick to Improve Your Semi-Weakly Supervised Semantic Segmentation Model
Problem setup is that you want to do semantic segmentation but your dataset has only a few images per class with pixel-level labels and many images with image-level class labels. They propose training an image classifier on the data with image-level labels and using its class predictions to filter which classes are even considered for pixel-level labels. Turns out this improves pixel-level accuracy a lot. The intuition they give is that pixel-level labeling with few examples mostly learns to pick up on local features, and so might think that cat pixels are actually horse pixels because they’re both covered in hair. But if the image classifier knows there’s no horse in this image, the model can’t make this mistake. I really like how simple and effective an intervention this is.


Is Your Toxicity My Toxicity? Exploring the Impact of Rater Identity on Toxicity Annotation
They find that “rater identity is a statistically significant factor in how raters will annotate toxicity for identity-related annotations.” They recommend having annotators drawn from whatever groups are mentioned in a potentially toxic comment. Serves as a friendly reminder that the world is messy and “higher number = better” doesn’t always work.
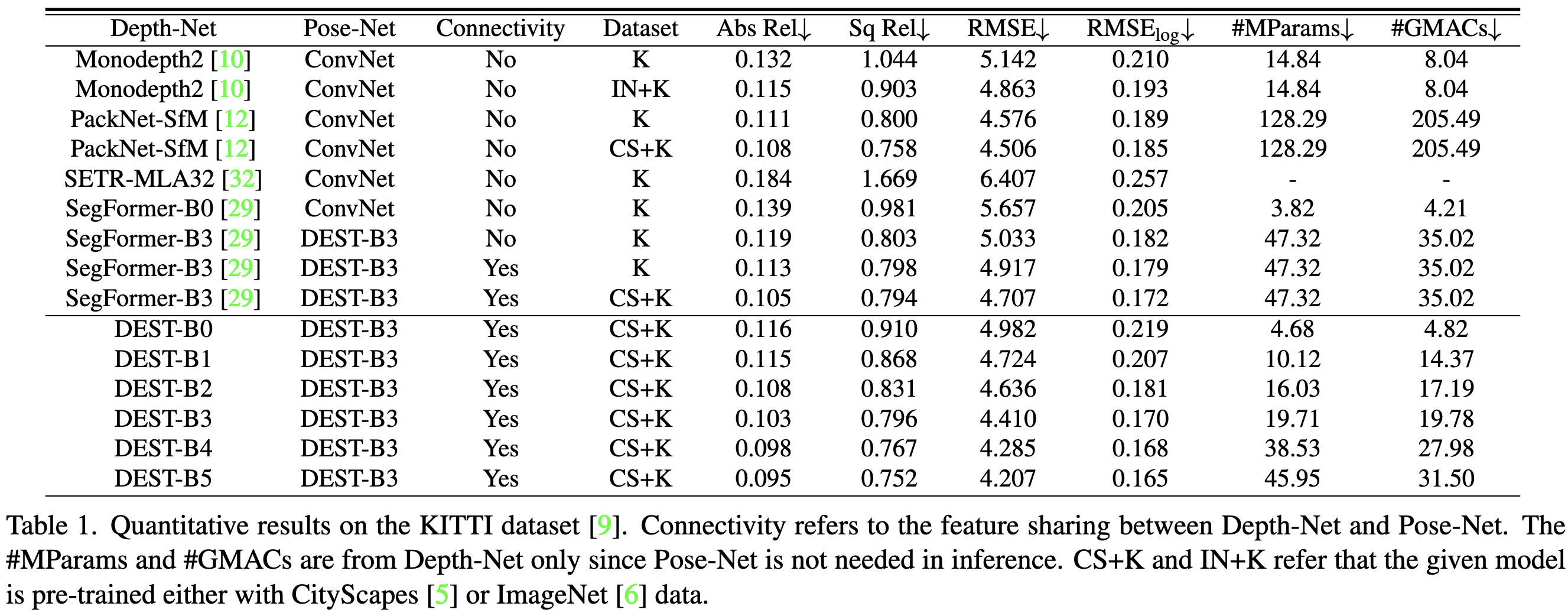
Depth Estimation with Simplified Transformer
New SOTA for depth estimation, using a vision transformer. They’re pretty sparse on details, and assume you already know how to do joint training of depth and pose networks. This mostly feels like a paper where they spent months refining the architecture to get it working super well, and then had so much content that they had to gloss over a lot of the decisions in just a couple sentences. But there are a couple ideas that might be useful in general:
Using a simplified attention mechanism that replaces softmaxing across a row with max-pooling across a row. It also average-pools to get the values matrix. Curious to see how this compares to the mechanism in FLASH, which seems like current SOTA for simplified attention mechanisms.
Replacing layernorms with batchnorms to avoid the inference-time overhead of the former. A one-for-one replacement makes the training diverge, so they had add in more batchnorms and do so in particular places.




Really good results. Much lower latency than existing approaches and also much higher accuracy. Note that it also works well for semantic segmentation on CityScapes, not just for depth estimation.


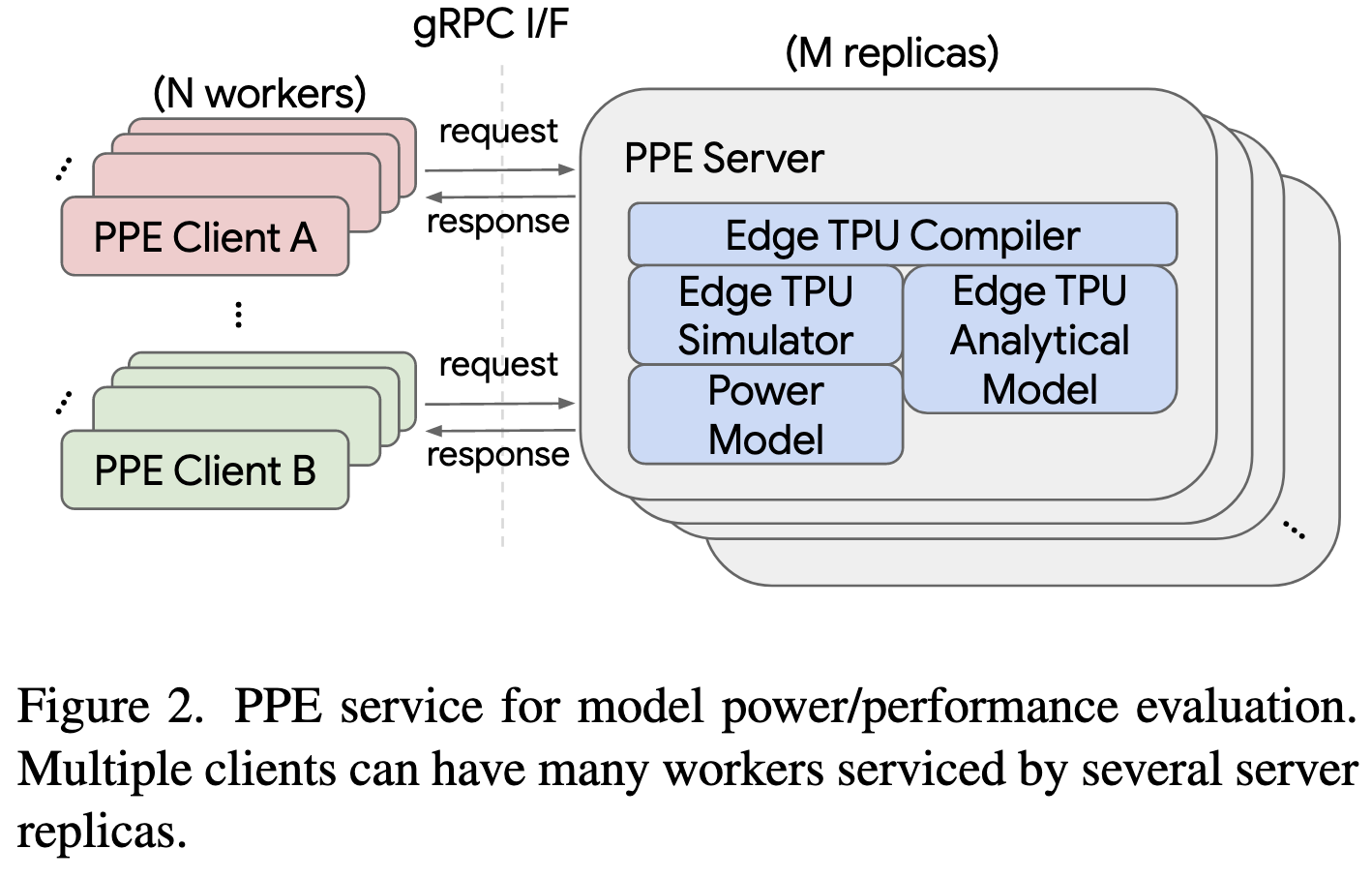
Searching for Efficient Neural Architectures for On-Device ML on Edge TPUs
Google NAS paper for Edge TPUs. A few interesting aspects:

They have a cloud Edge TPU simulator service. You send it a model and it runs the inference compiler on it and then hands you some mix of a cycle-accurate simulation result + results from an analytic model of the power and latency. I’m surprised the service doesn’t just runs models on actual Edge TPUs, but looks plenty accurate regardless.


They do a lot of exploration of inverted bottleneck blocks with grouped convolutions. I’m so glad someone put depthwise vs grouped profiling results in a paper. They show that grouped convs “can provide 4× the trainable parameters and number of operations while having 0.5× the latency cost of depthwise” convs. This is possible because depthwise convs are extremely memory-bandwidth-bound. Whenever I see a depthwise conv, I always ask “why is this not a grouped conv?” and this is why I ask that.

Their NAS search doesn’t seem super interesting. RL coming up with bottleneck designs (and other hparams) and querying the above PPE server.
But boy do the resulting models work well. Excellent quality-latency tradeoffs for ImageNet, ADE-20k, COCO detection, and SQuAD with a BERT-like model. Not positive this is SOTA for any given task since the literature is so crowded and so few people time their models, but it’s certainly a strong contender.






⭐ OPT: Open Pre-trained Transformer Language Models
The paper for Meta’s open-source 175B-param GPT-3 alternative that works just as well.
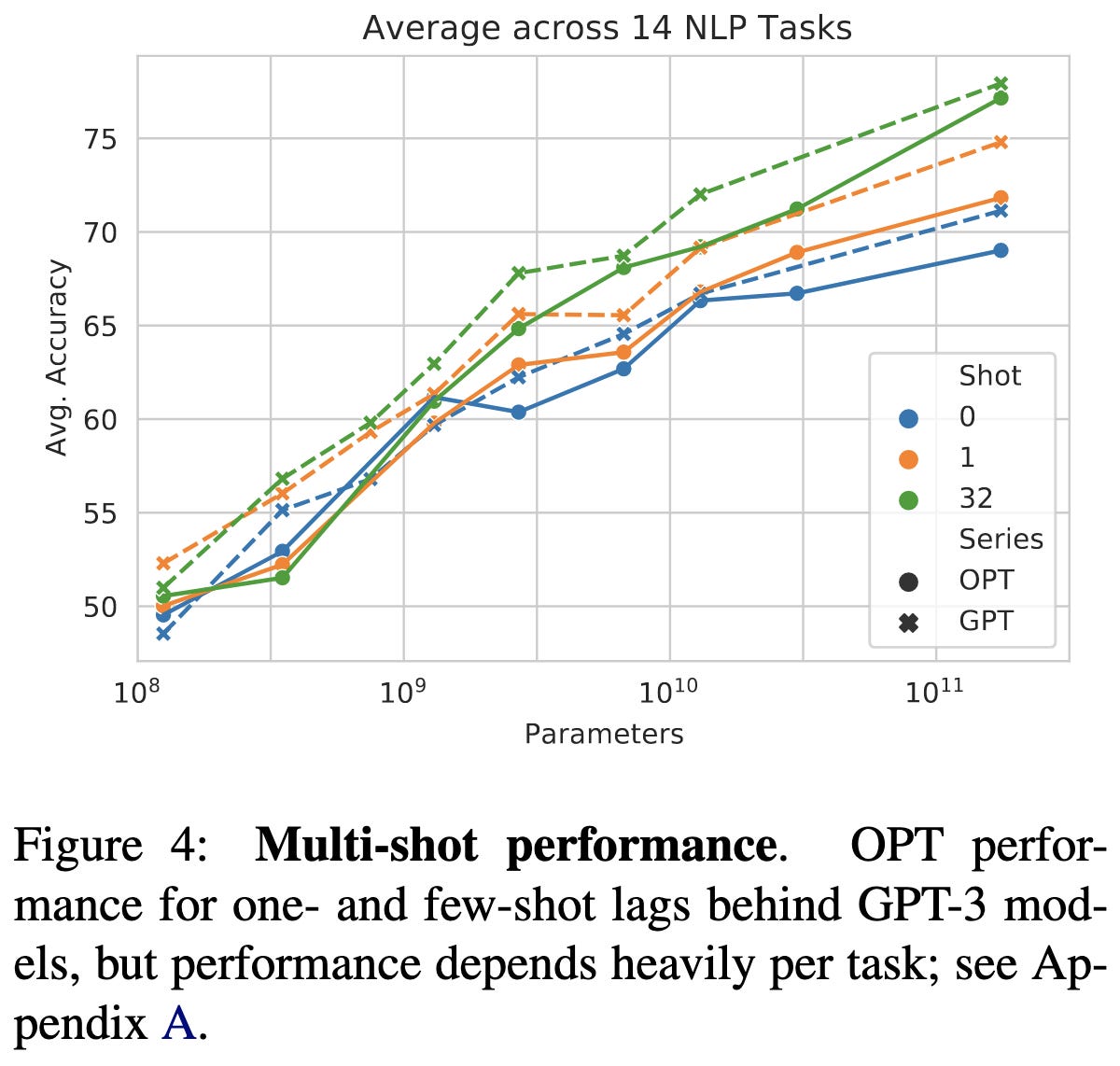
My main takeaway from this is how incredibly difficult and manual a process training becomes at this scale. For example:
They did 35 manual training restarts + cluster diagnostic checks due to hardware failures.
There was a ton of data cleaning and corpus-specific preprocessing. The most interesting part to me was taking only the top comment thread for reddit posts so that the page would look more like a coherent document.
They repeatedly had to revert to an older checkpoint and reduce the learning rate, resulting in this monstrosity:


They tried switching from AdamW to SGD partway through, and then decided to switch back.
They upgraded their version of Megatron during training, and saw improved throughput.
The learning rates, batch sizes, and model hparams had somewhat consistent trends until 30B, and then largely reversed at 175B.


This also suggests that the future of deep learning is less DIY and more “as-a-service.” A lot of people get away with writing their own little training loop in PyTorch today, but I can’t imagine 99% of organizations ever managing the distributed system it takes to train a model of this scale. And even with the checkpoints open-sourced, getting inference to run on a model that doesn’t fit in one GPU’s memory is still beyond the capabilities of most organizations.
Finally, this makes me worry that we’re headed for even worse reproducibility issues than we already have. If normal training runs start needing this much manual intervention and are so long that we experiment within a run, controlled comparisons will be challenging.
Significantly Faster Vision Transformer Training
Doesn’t seem to have an associated paper yet, but Meta wrote a long blog post about speeding up ViT with (mostly) systems optimizations. The top bar in the graph shows 2.18x, but it’s really more like 1.6x at iso accuracy. The 2.18 uses half-precision accumulation and messes up the accuracy (“less than 10 percent”, which is a lot). The 1.86x uses an image size of 256 instead of 224, so the higher FLOP throughput reported is only 7/8 as good as it looks.
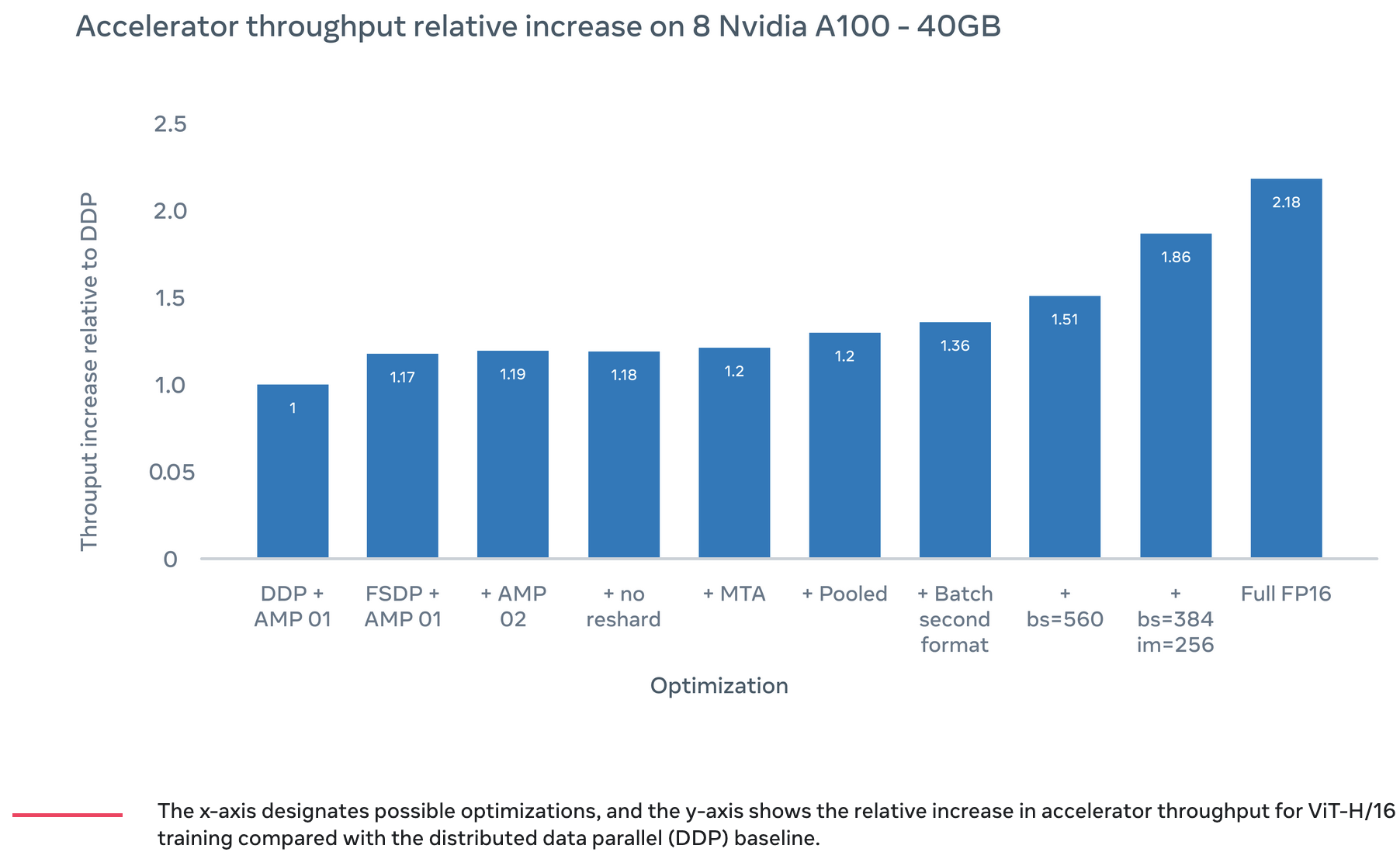
What I found surprising about this is that they get a 17% lift from FSDP (“fully shared data parallel”), which splits the model, gradients, and optimizer state across all nodes. Suggests that they’re not doing a normal ViT, but instead something much larger that was previously hitting some communication bottlenecks in a more naive sharding scheme.
My favorite nugget in here is their link to this PyTorch issue that talks about the overheads associated with optimizer steps. At 10us per sequential kernel launch, 100 parameter tensors and 5 kernels per optimizer step yields 10us * 100 * 5 = 5ms of latency, which is a ton. I have no idea what “MTA” stands for, or where they got the reduced-overhead optimizer implementations (since the PyTorch issue is unresolved), but this is what the MTA bar in the figure is referring to.
They also got a big lift from using sequence-batch-feature layout (1.2x→1.36x) and a carefully chosen batch size (560), but those are well-known optimizations.
Standing on the Shoulders of Giant Frozen Language Models
They developed techniques to get good performance on various NLP tasks without finetuning their pretrained model at all. I’m not certain their results are actually better than finetuning if you hold model and inference latency constant, but the approach is creative and at least works pretty well. Their motivation is to make pretrained models more like reusable software components, similar to the goals of T5 or LiT. I hope this happens, but it’s not quite clear to me yet that we can do this without a quality-speed cost.
The three approaches to using a frozen LM they consider are:
Input-dependent prompt tuning for multitask learning with many tasks.



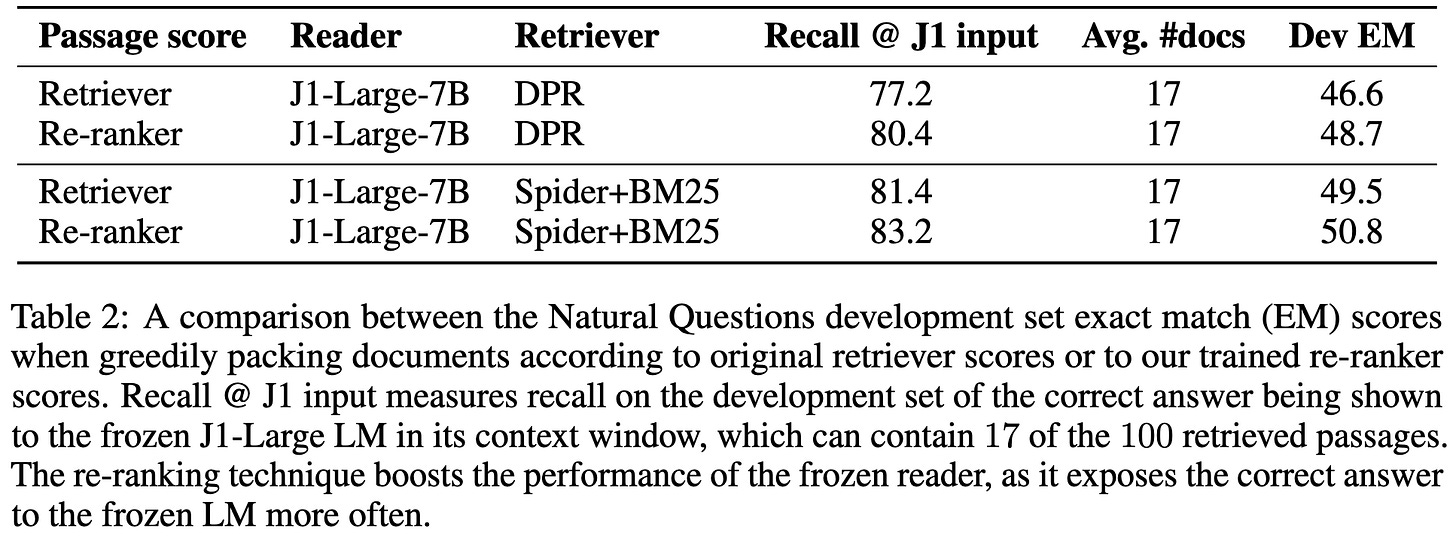
Training a retriever + reranking for open-domain question answering.

Feeding an LM’s output back in as input, with a learned “connector” in the middle—evaluated for closed-book open-domain question answering. Feeding a model’s output back in as input isn’t new (c.f. AlphaFold, deep equilibrium models, Universal Transformers), but using a frozen model with a trained intermediate step is new AFAIK.
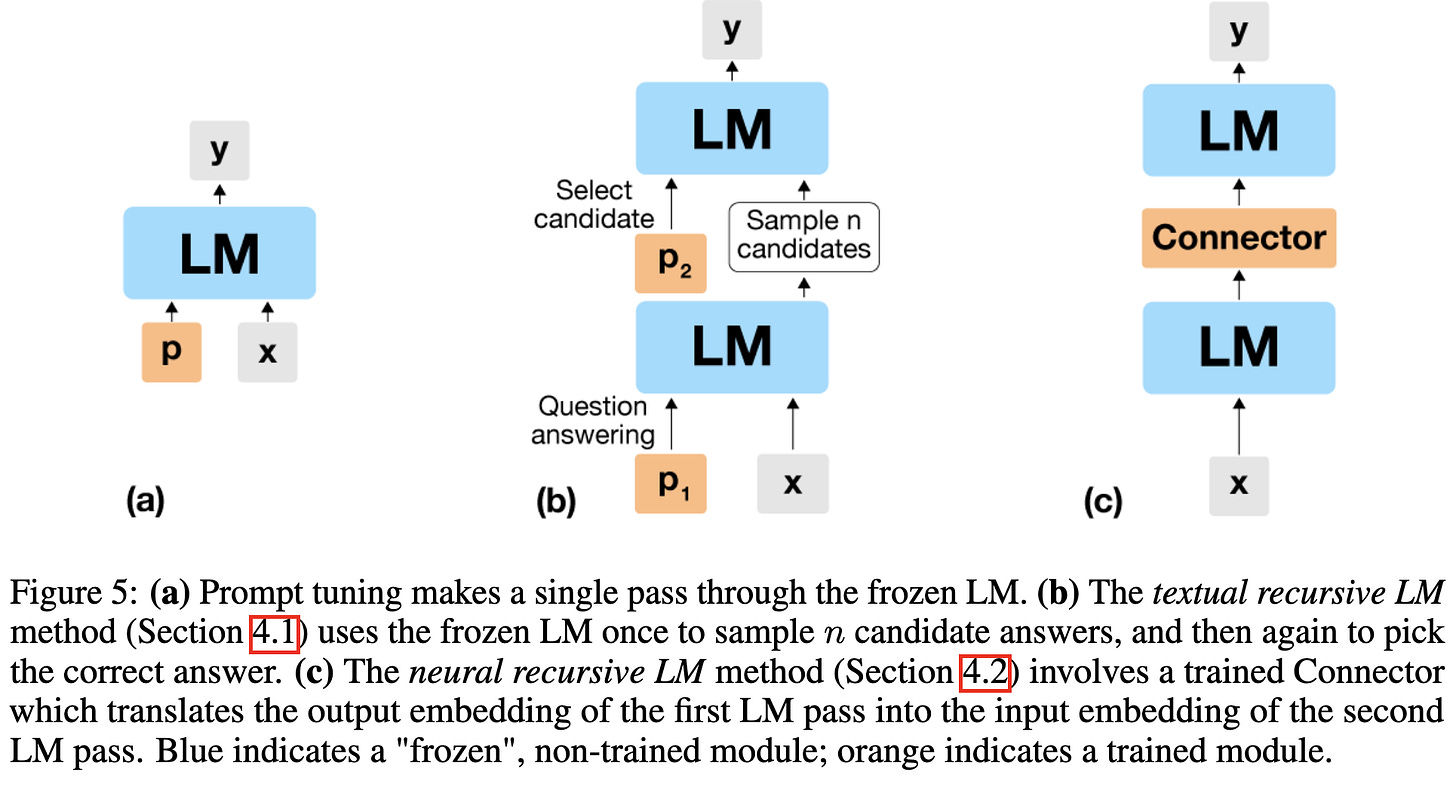








This paper also makes me wonder how much prompt tuning and other fine-tuning-like approaches are confounded by the size of the modules being fine-tuned. E.g., do the proposed approaches to using a frozen LM have especially good inductive biases, or are they just training more parameters? Either way, I appreciate how the outside-the-box this approach is.
That’s all for this week. As a final note, my list of readers went from a dozen coworkers to 1300 (!) strangers this week, so I feel a lot of pressure and really hope you all like this. Feel free to let me know what I could do better.