


2022-6-12: 7x Faster ResNet-50, BIG-Bench, Neural corpus indexer, DeepSpeed & fp8 quantization

Blazingly Fast Computer Vision Training with the Mosaic ResNet and Composer
We (MosaicML) trained a ResNet-50 7x faster with no loss of accuracy. This is possible because of two observations:
If you increase the accuracy, you can just train for fewer iterations—as long as you also adjust your learning rate schedule accordingly.
There are a lot of methods in the literature to increase a model’s accuracy. And there are also a few methods that increase the speed per iteration without losing much accuracy (e.g., progressive resizing).

So what we did was just take 12 different improvements from the literature and apply them all.
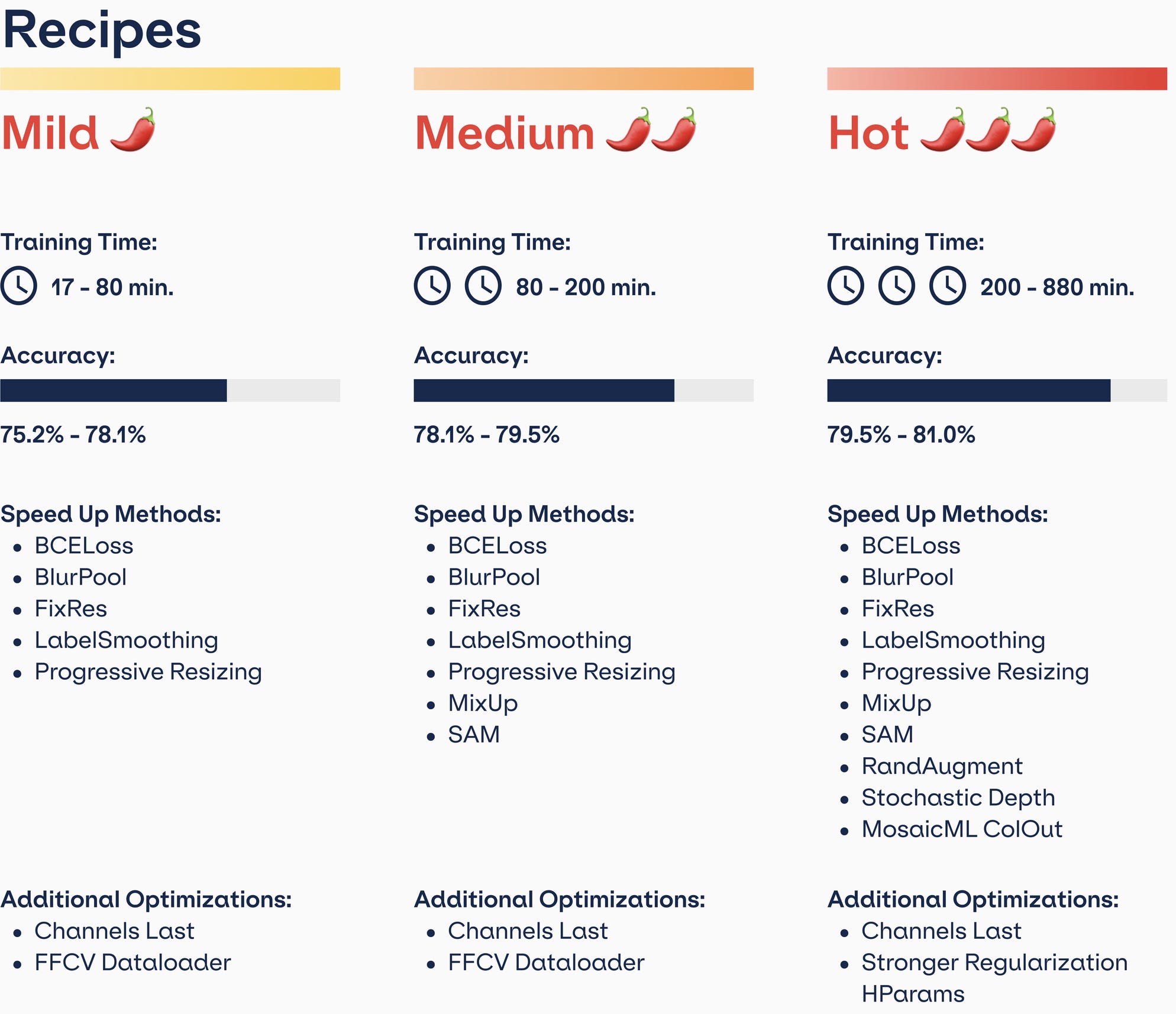
Now this sounds easy but it’s actually hard. This is partially because there was some science to be done reimplementing and characterizing this many methods. But mostly because of software. You can copy-paste a ResNet training pipeline and hack together a couple modifications pretty easily. But making it easy to toggle on and off dozens of methods on any user-defined model? That’s hard.
It’s so hard in fact that we had to build Composer, a library specifically for combining many training improvements at once. But luckily now it’s easy:

Superficially, the story here is “we made ResNet go brrr.” But the real story is that the way we all build training pipelines is going to change. This ResNet result shows that if you’re not using something like Composer to get best-of-breed optimizations, you’re likely wasting 80+% of your compute and waiting 5x longer for models to train than you have to. That can be okay at small scale. But I can’t imagine it remaining standard practice for more than another year or two.
⭐ Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Introduces BIG-bench, a collection of 204 tasks for evaluating large language models. They also show results for various large models on this benchmark, including GPT-3, some Google-internal models, Switch-like transformers, and humans doing the tasks. Bigger models are better, but still much worse than humans.

It’s a 100 page paper, but what I found most interesting is their discussion of what current language models are bad at:

And of course they show this gem, which is one of the most sci-fi experimental results I’ve seen:

Though note that the improvement in the above task is much more gradual when it’s presented as multiple choice; the authors use this as an illustration of how apparent scaling trends depend heavily on task formulation.
This is an extremely thorough paper with a ton of interesting results and discussion, and I’d recommend reading all of it if you care about large language models and their capabilities. A great successor to SuperGLUE that we hopefully won’t saturate for a while.
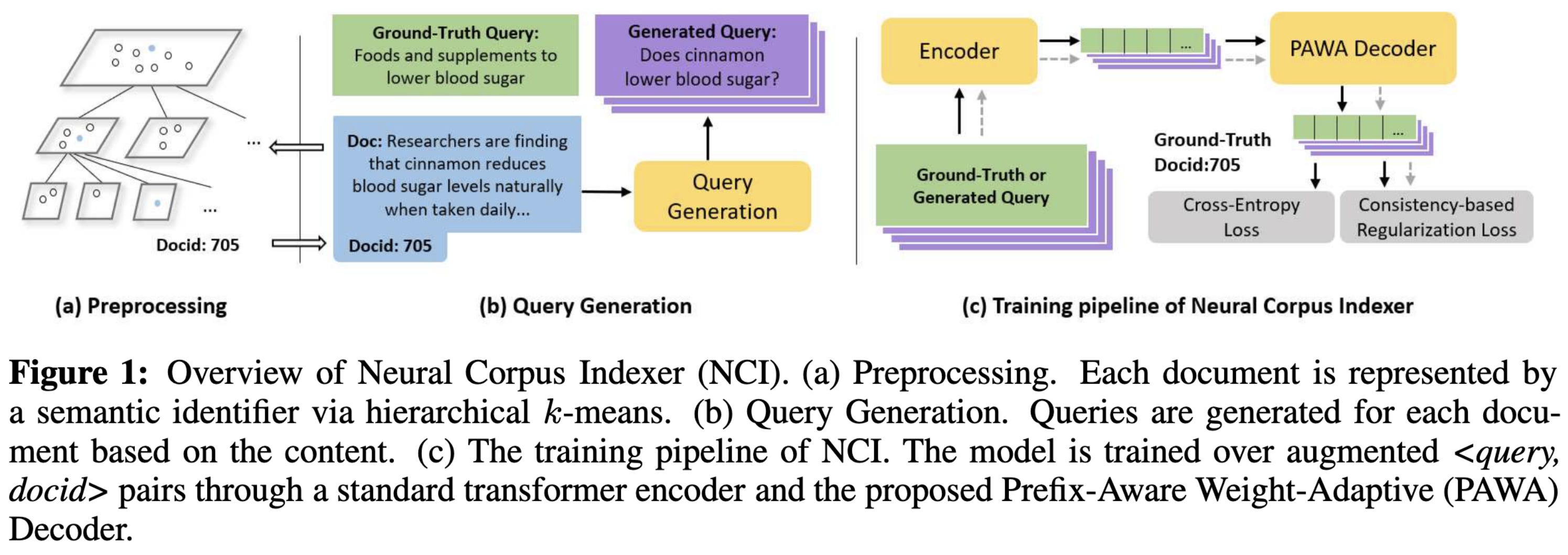
⭐ A Neural Corpus Indexer for Document Retrieval
They train a seq-to-seq model to directly spit out document IDs given queries. And it works really well. Like, these are some of the largest accuracy lifts I’ve ever seen in a paper.

They aren’t the first to try doing this, but they are the first to get it working better than conventional baselines. A few changes make their method work.
First, they hierarchically cluster the documents so that similar documents have similar tokens. To construct their hierarchical clustering, they embed each document using a pretrained BERT and then just recursively run k-means with k=10, stopping the recursion at a given cluster when it has 10 or fewer assigned documents.
Second, they essentially have a tree of parameters, mirroring their tree of documents, since the meaning of a given token varies based on where in the tree you are.

Third, they regularize it by running two forward passes with different random dropout and penalizing the KL-divergence between the two output probabilities.
Fourth, they constrain the beam search they use for decoding to only produce valid token sequences based on their tree of clusters.
And lastly, they add many samples to their training set using a variant of Doc2Query. This network takes in a document and spits out queries that the document answers. Each (query, document) pair is another training sample.
They perform good ablation experiments to show that each of these components actually does help. The query generation helps a lot.

So is there a downside? Yes. It’s really slow. They’re only getting on the order of 10 queries per second on a corpus of 320k documents with a V100. For reference, with one embedding vector per document, I could do over 1000 queries per second with no index on my 2013 laptop using Bolt. And there’s also the question of dealing with insertions, updates, and deletions, which might require retraining rather than just re-indexing.

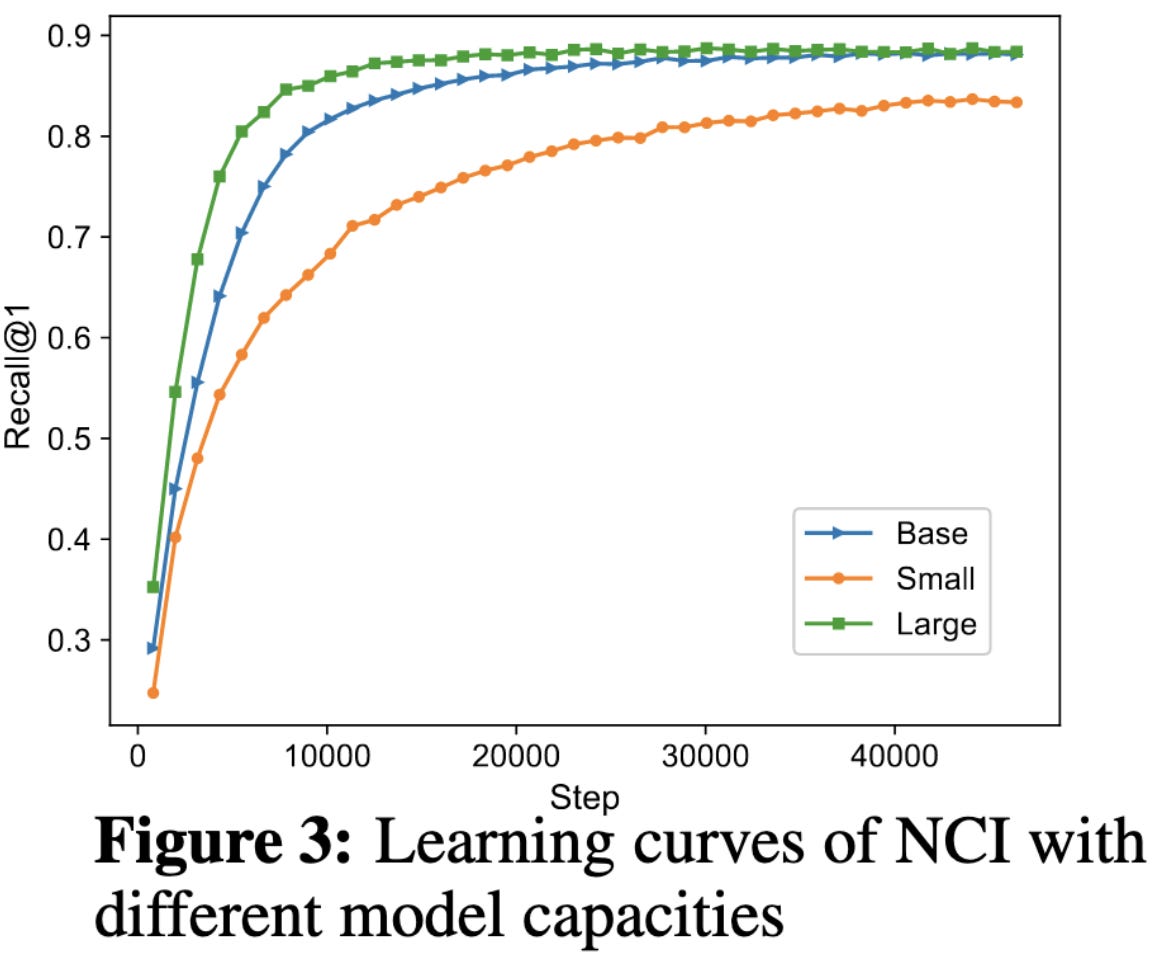
So, ultimately, this isn’t necessarily “better” retrieval so much as a story for how to turn more compute into more recall, focused on the extremely high compute regime. But that’s still really cool, and suggests that scaling up retrieval infra even further might be profitable for recsys-focused companies.
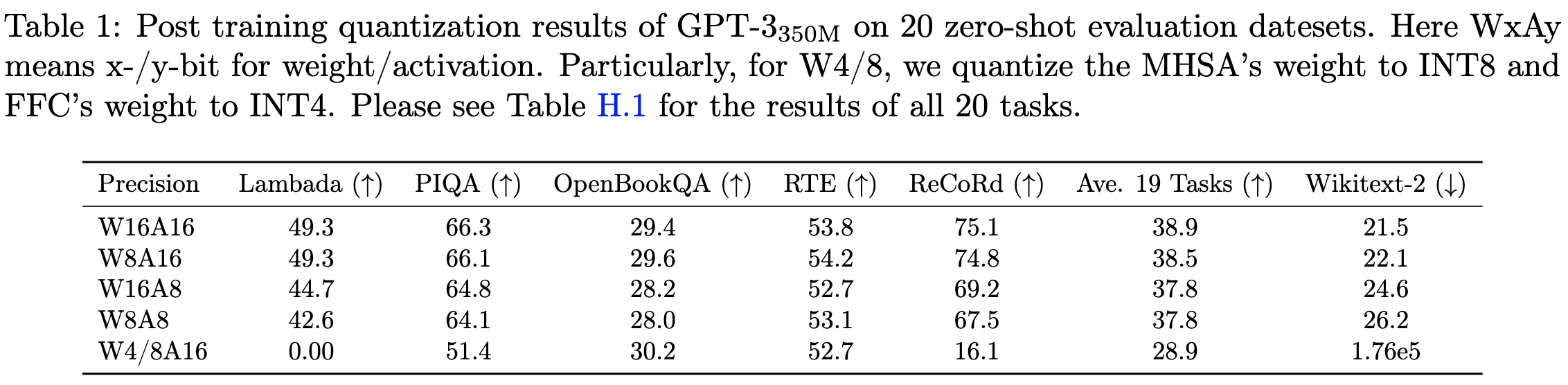
⭐ ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers
Post-training quantization from the DeepSpeed team. Works a little better than other post-training quantization schemes, and they wrote kernels to make inference run faster in practice.

The first part of their method is quantizing each token and each tile of a weight matrix using its own offset and scale. This lets you use a much smaller range in most cases, reducing quantization error. They way to think about this is that, with N iid variables, the largest value you see will grow as log(N). So when you quantize fewer scalars, you tend to get a tighter range, and therefore less quantization noise.
Quantizing rows of one matrix and tiles of another lets them fuse the quantization into the ops—they fuse into the previous op for quantizing and unquantize in int32 before converting to fp16.
The second part is layerwise distillation. They just topological sort the layers and quantize them one by one. And as they’re quantizing a layer, they optimize the MSE between the quantized layer’s output and the original output. I’m surprised this works so well layerwise; I’ve always tried to optimize similarity to the original network’s output, not the output using a quantized prefix and only one original layer.
They also show that you can use similar data (e.g., other language datasets) as the input, not just the original training data.
Overall it works pretty well. Like all quantization schemes, there’s variability across models and datasets. But they sometimes reach equal accuracy significantly faster. Their best result IMO is this inference latency reduction from 2 GPUs in 65ms to 1 gpu in 25ms:

Aside from that, their layerwise distillation seems to clearly help, and they often outperform existing post-training quantization schemes.
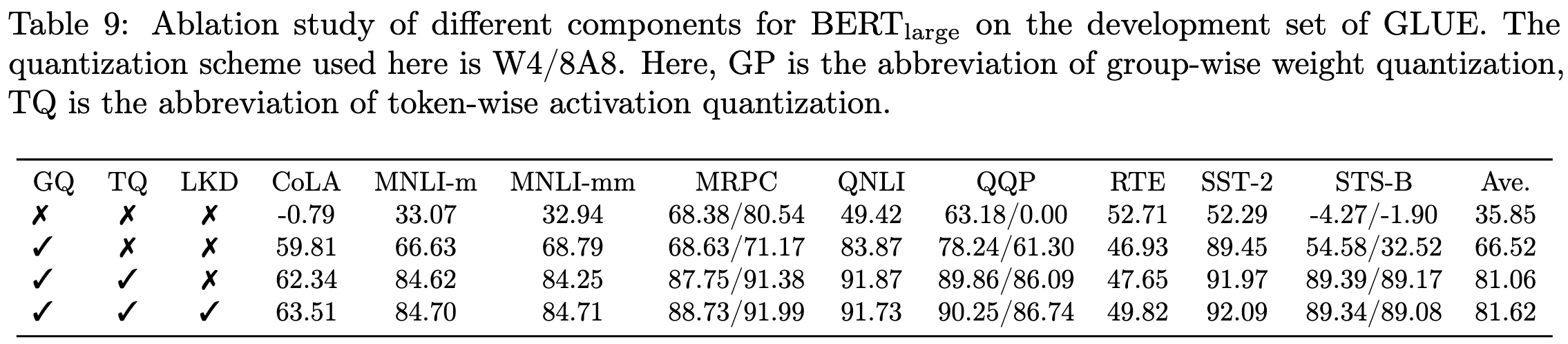

Extreme Compression for Pre-trained Transformers Made Simple and Efficient
Another DeepSpeed quantization paper, this time focusing on 1 and 2-bit quantization with finetuning. They greatly simplify the finetuning pipeline compared to previous work and manage to even exceed the original model’s accuracy with a 2-bit model.

What’s even more impressive about this is that they aren’t just beating f16 BERT-Base with a 2-bit BERT-Base; they’re beating it with a 2-bit “XTC-BERT” (an architecture they created), which is already much smaller.


To achieve these results, they conducted a large-scale empirical study of model shrinking / quantization pipelines. A few key findings:
You need to finetune for a long time, and with a decaying learning rate
You don’t need multi-stage knowledge distillation. Singe stage with the same total training budget is at least as good.
Definitely use data augmentation, especially for smaller tasks
Just taking a spaced-out subset of the layers with simple distillation can work just as well as fancier pre-training distillation.
All of these are pretty intuitive, which is reassuring. They even highlight how accuracy drops significantly if you just don’t fine-tune for long enough:

They don’t have any timing results, but presumably they could get at least some speedup with good fused kernels and/or sufficiently large i4 or i1 GEMMs. I’m surprised they were ever able to beat the original model’s accuracy, but I guess that’s testament to the huge lift you can get from knowledge distillation.
8-bit Numerical Formats for Deep Neural Networks
An excellent empirical investigation of 8-bit floating point formats for weights, activations, and gradients. Finds that 1.4.3 (1 sign bit, 4 exponent, 3 mantissa) often performs the best for activations and weights, and 1.5.2 often performs best for gradients.

Most importantly, they manage to reliably get within the margin of statistical error across five runs when choosing a good format and loss scaler.


The main subtlety here is that you seemingly have to use different exponent biases for different tasks, and even different tensor types within a task. E.g., they have to use way larger biases for the gradients on this translation task than they had to for the BERT-Large results above.

They propose a couple heuristics for adaptively setting these biases (implemented as loss scaling), which work most of the time but sometimes make the training diverge.
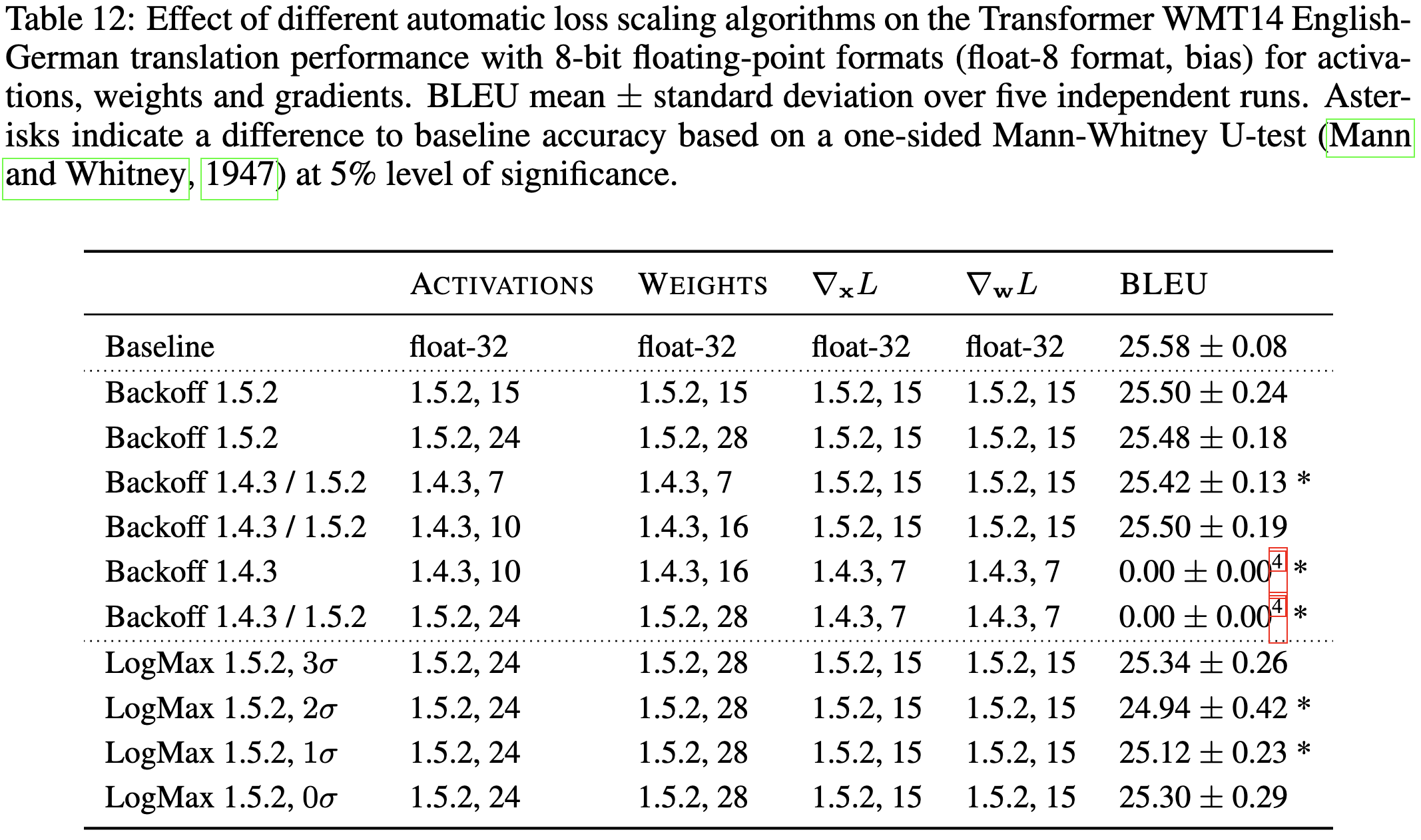
It looks like you generally want the most aggressive loss upscaling you can get without diverging:

This paper bolsters my conviction that float8 training will be effective once there’s good hardware and software support. Although it might take some hparam tuning to get all the exponent biases right.
I also found the histograms of weights, gradients, and activations in Appendix D really interesting. E.g., why do transformer weights and activations follow such a clear power law below a certain magnitude?


Lottery Tickets on a Data Diet: Finding Initializations with Sparse Trainable Networks
A science-of-deep-learning paper exploring how/why even a little bit of pretraining can be enough to identify a good sparse subnetwork using magnitude pruning.

First, they find that you can get away with only pretraining on a random subset of the data as long as you hold the number of iterations constant.

Second, you can get away with shorter pretraining if you train on easier examples. And you also gain more robustness to label noise:

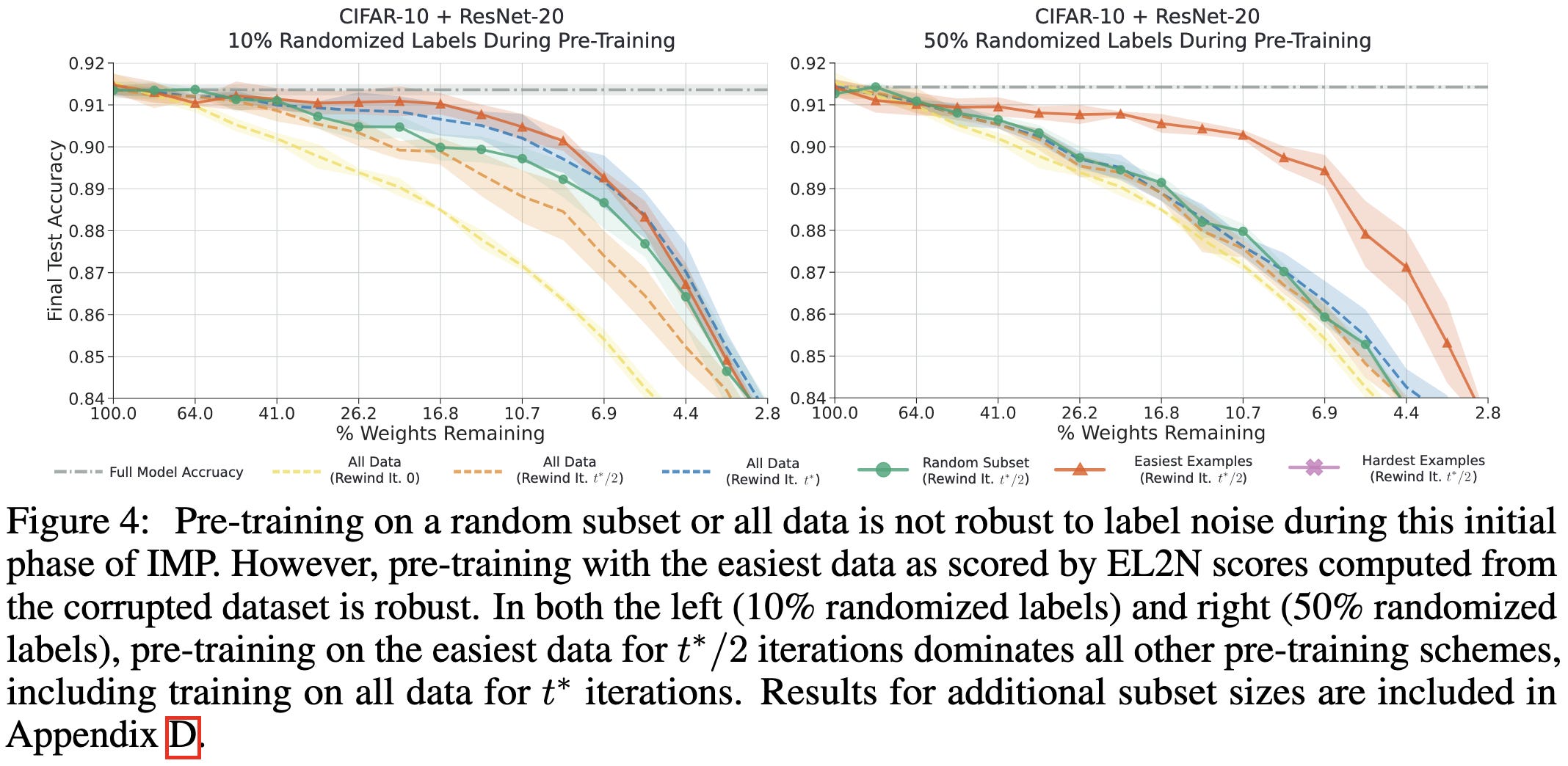
But training on easier examples during warmup results in lower test accuracy.

They also show that the degree of linear mode connectivity is correlated with the final test accuracy.

Squeezeformer: An Efficient Transformer for Automatic Speech Recognition
I always read Amir Gholami’s papers and this one exemplifies why: it’s careful science yielding practical improvements. Concretely, they consider the task of speech recognition, and systematically modify the Conformer to be more efficient and accurate.

The biggest structural change is the addition of a temporal U-Net. The original conformer downsamples to a fixed period of 40ms throughout the network. They instead downsample by progressively greater amounts deeper into the network, and then progressively upsample (and combine with the correspondingly downsampled input) as they move towards the decoder. This both reduces FLOPs and increases accuracy.

The other macro-scale change they make is switching to a more conventional MHA-FFN-Conv-FFN structure, similar to other transformers.
On a more micro level, they rip out the GLUs and make everything SILU (Swish), remove some quasi-extraneous layernorms, and swap out a hugely expensive conv near the input with a depthwise separable one.

They have good experiments showing the marginal effects of each of these changes.

In addition to reduced WER and FLOPs, the resulting model also has lower inference latency than the Conformer at a given accuracy.

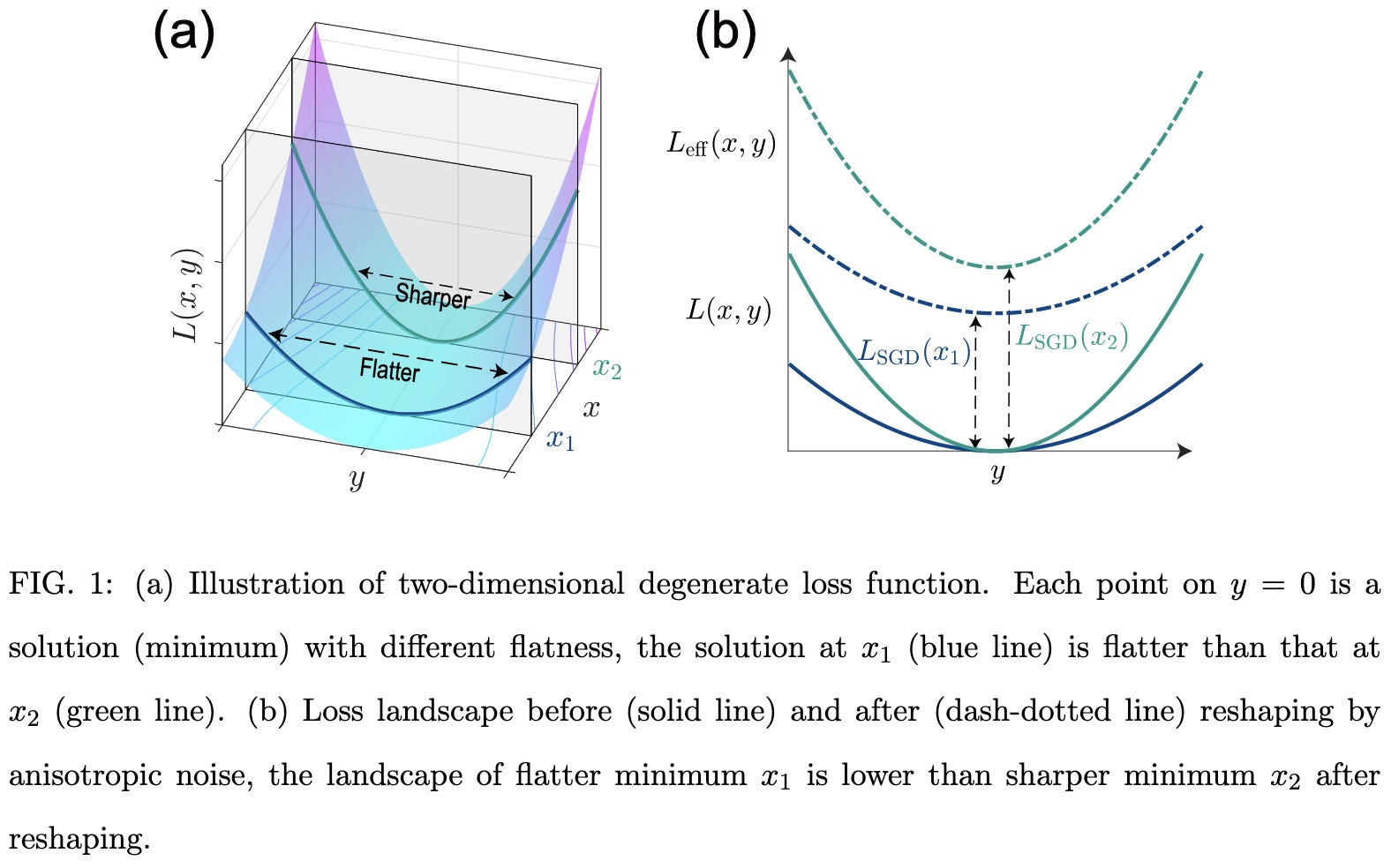
Stochastic gradient descent introduces an effective landscape-dependent regularization favoring flat solutions
Highlights that the covariance matrix of gradients in SGD tends to be similar to the Hessian. And therefore, under some assumptions, SGD ends up effectively adding a term to the loss that penalizes curvature.
Predict better with less training data using a QNN
They built a small CNN-like network using quantum computing. Doesn’t seem like something you’re going to use anytime soon, but I was surprised to learn that quantum ML has reached the point where you can just use an off-the-shelf library and try this kind of stuff. Also has a good overview of quantum computing and related quantum ML work.

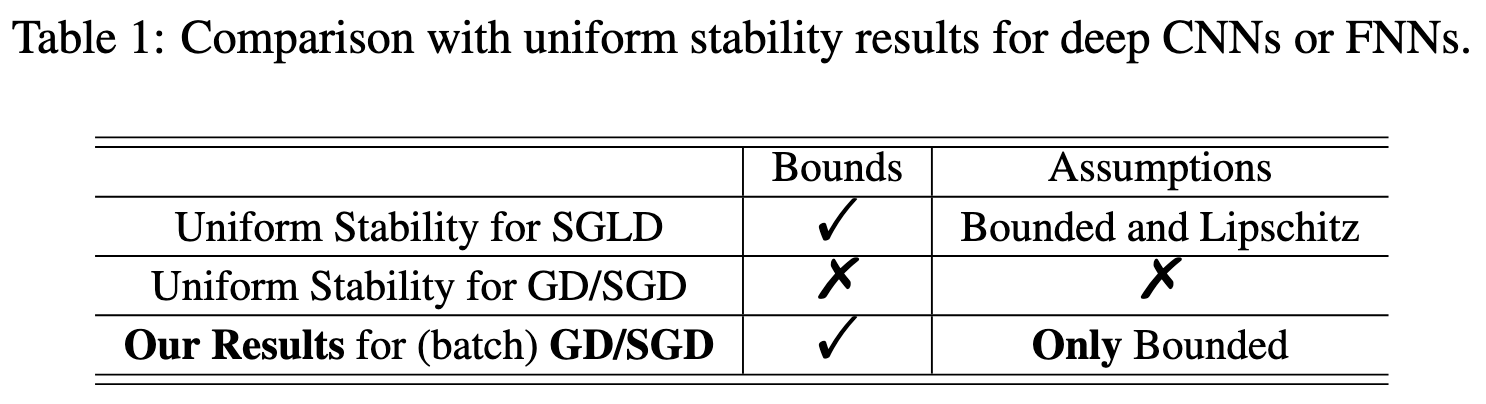
Generalization Error Bounds for Deep Neural Networks Trained by SGD
They proved a probabilistic generalization guarantee for SGD on feedforward networks that isn’t completely vacuous on small models and datasets. Has weaker assumptions than previous uniform-stability based approaches. Interestingly, the guarantee depends on the integral of the loss over training, rather than just the final loss, like one typically sees in statistical learning theory.

Neural Prompt Search
Why pick one way of prompting / prompt tuning a model when you could add a bunch of them into one supernet and use an evolutionary NAS method to hand you a good subnet combining all of them? Seems to work significantly better than any of the three constituent methods on their own.


Spatial Entropy Regularization for Vision Transformers
They propose a spatial entropy loss that consistently increases accuracy for vision transformers with few extra FLOPs.

Their loss zeros out attention map values lower than the average attention, groups attention elements into connected components, and then penalizes the spatial entropy.
Gets pretty good results, though largely as a product of architecture changes to the ViTs (removing layernorms and certain skip connections) that seem independently useful.

Seems to be adding a strong inductive bias, as opposed to regularization, model capacity, etc. Inferring this because it lifts accuracy a ton on some small datasets and has the highest benefit early in training on ImageNet.


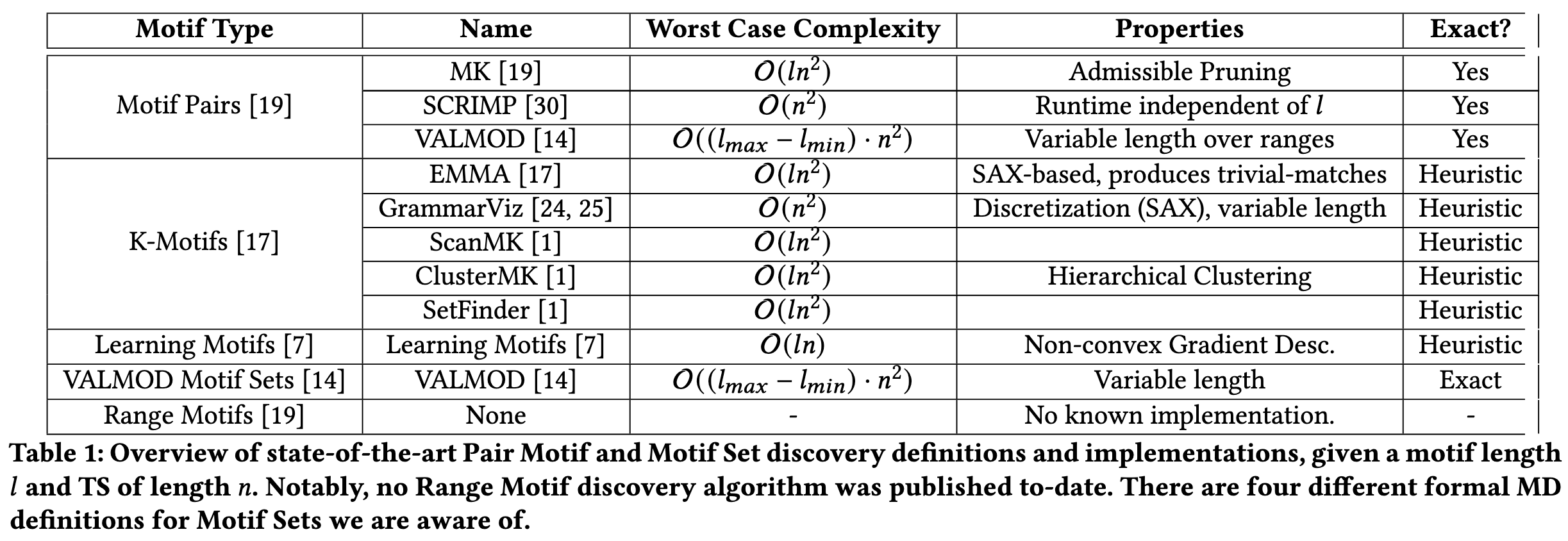
Motiflets -- Fast and Accurate Detection of Motifs in Time Series
An old-school UCR-style time series data mining paper. They reformulate motif discovery in terms of the number of motif instances to find, rather than in terms of the maximum distance, and present exact and approximate algorithms to solve this problem.

For small k, the exact and approximate versions are both reasonably fast. For large k, you need to use the approximate one.
