


2022-6-26 arXiv roundup: Way better certified robustness, Progressive SSL, Empirical NTKs

This newsletter made possible by MosaicML.
⭐ (Certified!!) Adversarial Robustness for Free!
Existing work has shown that you can make any classifier provably robust to adversarial perturbations by ensembling its predictions on several copies of its input, each with its own random Gaussian noise. With more copies and more noise, you get more robustness. The downsides are that 1) this takes more time, since you’re running inference on multiple copies of the input, and 2) your accuracy probably goes down a lot because your inputs are noisy.
This paper solves the second problem by prepending a pretrained diffusion model to the classifier. You tell the diffusion model the amount of noise you added (specified as an equivalent timestep in the diffusion process it was trained on), run it on each noisy input, and you’re good to go. If the diffusion model is good, you now have nearly-noiseless inputs for your classifier without throwing away your provable robustness.

This approach works really well given the strength of its guarantees:
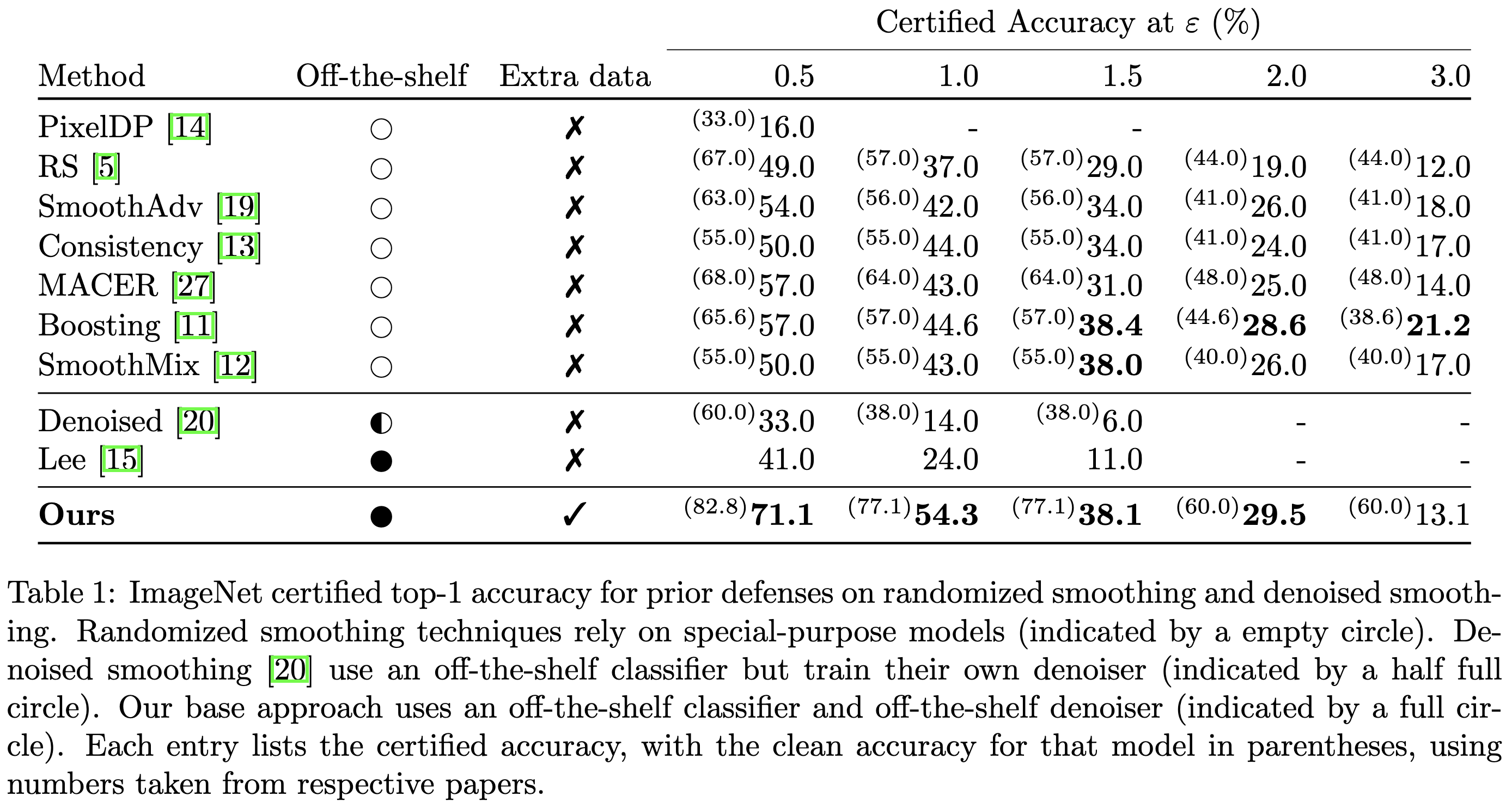
Now, these numbers aren’t great in absolute terms; the baseline BEiT-large has 88.6% accuracy, and if you were to instead spend the diffusion model’s 552M params on expanding this 305M-param classifier, you could probably go even higher. So the 71.1% accuracy is a huge drop. Also, the images are normalized to [0, 1] for each color for each pixel, meaning each image’s maximum L2 norm is sqrt(224*224*3) ≈ 388; so a perturbation of size 0.5 is tiny.

*But* this is certified robustness, which is absolute worst case. And their numbers are a huge lift over all previous work, with an extremely simple method that anyone can use. Plus, because their method works with pretrained models, you can add robustness post-hoc as needed or as your latency budget allows. So overall, this is a beautiful algorithm and a pretty big deal.
P.S.: This also suggests that we can largely reduce norm-bounded adversarial robustness to a scale and efficiency problem. I see every reason to expect that a 5B-param diffusion model, or even a 500B-param diffusion model, would reduce the accuracy loss further—perhaps to nearly zero. Similarly, faster inference could allow satisfying latency guarantees even with the extra diffusion and multiple noisy inputs.
⭐ Progressive Stage-wise Learning for Unsupervised Feature Representation Enhancement
So this paper is nominally about self-supervised learning, but I’m excited about it because of what it suggests about the future of large-scale training.
What they introduce is a generic scheme for making self-supervised learning work better, consisting of training later parts of the network on harder SSL tasks than earlier parts.

Concretely, they split the network into several overlapping blocks and train each block on its own self-supervised learning task. The tasks are qualitatively the same (e.g., inverting a permutation of image tiles or a set of rotations), but grow more difficult for later blocks. The weights are tied across copies of a given layer in different blocks, but no gradients flow across blocks.
Their “Progressive Stagewise Learning” (PSL) consistently improves the accuracy of various SSL objectives:

But what’s most interesting are the ablations. First, they show that having the gradually more difficult objectives is better than having just the hardest objective for everything (SL). This is pretty intuitive.

But what’s really interesting and promising is that their PSL with no gradients across stages equals or exceeds “"PSL_f”, the version that does backprop across stages. In other words, *they can compute parameter updates without a full backwards pass.*
First of all, this might be the first paper I’ve ever seen that actually beats full backpropagation on something bigger than a toy dataset. Which is already super cool.
But what’s really exciting is that this sort of truncated backwards pass is the ideal case for pipeline parallelism. Roughly speaking, computing the backwards pass only within a block means bubbles and/or memory cost proportional to your block depth, not the full network depth. With constant block depth, you can parallelize an unlimited-depth network with high utilization and low memory cost.
That said, all the parameters are shared across at least two stages here, which will eliminate much of the high compute to communication ratio that current pipeline parallelism enjoys.
But overall, this paper makes me think that improved self-supervised learning could unlock another level of scalability in ML training.
X-Risk Analysis for AI Research
Provides a guide for how to think about existential risk from AI and do empirical AI safety research. This is a hard topic to make rigorous since it touches on full sociotechnical systems and seeks to prevent phenomena that haven’t been observed yet, at least in their most severe forms.
What I found most valuable were pages 2-4, where they go through definitions of many existing concepts from other fields (e.g., manufacturing) that have dealt with concrete safety problems for decades.
They attempt to ground the discussion in specific possible problems people have identified:

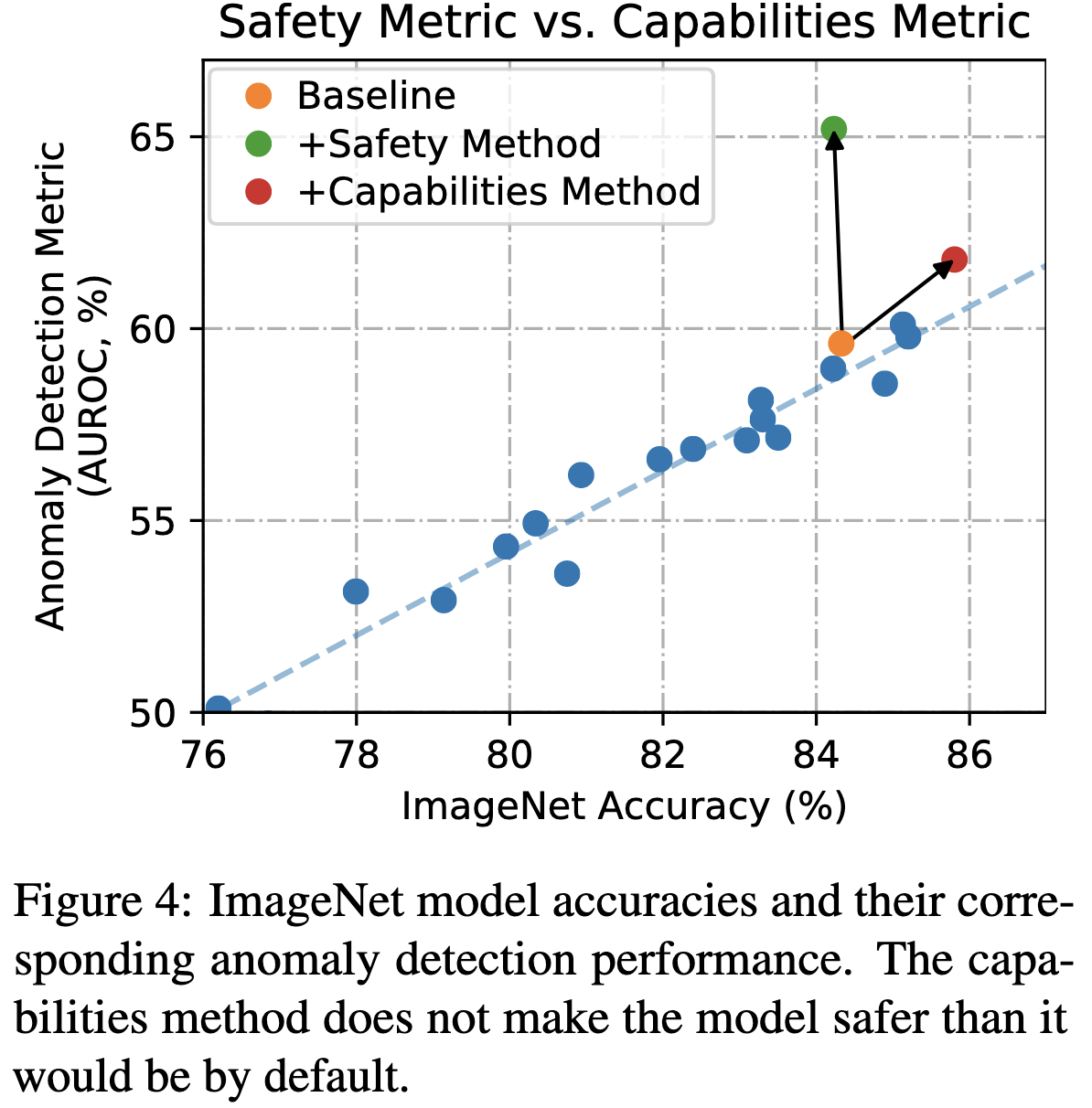
They also propose a methodology for evaluating purported safety contributions empirically. Namely, they suggest identifying a quantifiable “safety” metric and showing that one’s method differentially improves that metric, as opposed to just making a model more capable across the board.
Fast Finite Width Neural Tangent Kernel
Computing the NTK for a given network can be useful as a feature extractor when trying to predict (or dictate) a model’s behavior, but it can be expensive to compute. This work proposes several algorithms for computing empirical NTKs efficiently, along with guidelines for when to use each.
They start off with probably the clearest NTK definition I’ve seen:

They then describe algorithms for computing NTKs for several types of networks, along with their complexities. First, for arbitrary networks:

…then for MLPs:

…and finally for CNNs:

As expected from the differing complexities, they find that using the best algorithm for a given network can yield enormous speedups:


There’s a lot of math, but the high-level takeaway is that you should definitely use their algorithms if you want to compute the NTK for a network, and use their library if you’re okay with JAX.
On Efficient Real-Time Semantic Segmentation: A Survey
Good survey of semantic segmentation approaches. Really like that they measured inference latency themselves on standardized hardware. They also have architecture diagrams and descriptions for many of the methods they discuss.
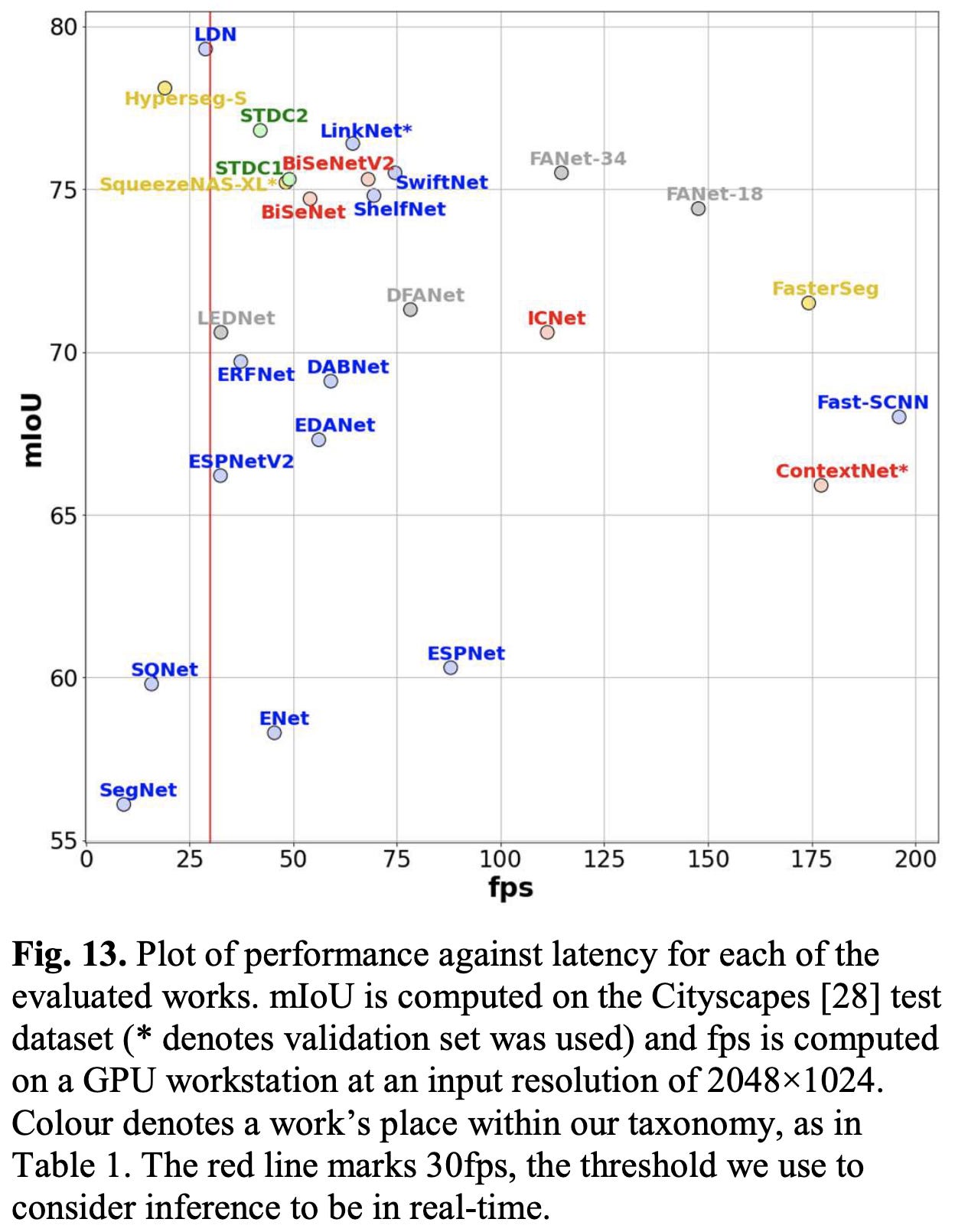
Encouragingly, there does seem to be a positive correlation between year of publication and how up-and-to-the-right the results are (notice that, e.g., the points in the lower left are the oldest methods in the below table). This correlation isn’t present for some problems, like neural network pruning.

Answer Fast: Accelerating BERT on the Tensor Streaming Processor
Groq claims their new chip does BERT-Base inference in 130us with ~1% variation. They claim an A100 takes about 630us, which is at least in the right ballpark since BERT-Large takes ~1.2ms when NVIDIA measures it. This is kind of impressive since their chip is 14nm rather than 7nm and uses 275W rather than 400W.

That said, DL hardware companies have a strong history of benchmarketing, and the biggest question in practice is the software stack. But I could believe that it actually is doing better for batch size 1 inference based on these numbers.
Fighting Fire with Fire: Avoiding DNN Shortcuts through Priming
They address the problem of shortcut learning—e.g., making an image classifier predict based on the foreground object rather than the background.

To do this, they specify a task-specify “key” extraction function k(x) that highlights aspects of the input that aren’t spurious. E.g., for image classification, they use a pretrained saliency detector to crop the image to just the estimated bounding box for the foreground object. They then feed k(x) into another network, and concatenate that network’s output with the activations of the target network.
Seems to work better than other methods on various benchmarks.


However, they’re more than doubling the amount of compute their network gets to use (at least in the image classification case), and just plain taking the output of a network that has the background cropped away. I’d love to see how it performs compared to FLOPs-matched alternatives, or the baseline of just feeding in the intelligently-cropped image with no other changes.

On the Maximum Hessian Eigenvalue and Generalization
They run a ton of experiments using VGG-11 on CIFAR-10 and find that the largest eigenvalue of the Hessian (a common measure of sharpness) doesn’t necessarily correlate with generalization performance. This contradicts the common belief that flatter minima generalize better. Concretely, they find that they can vary the learning rate, batch size, and presence of dropout such that the eigenvalue and the test accuracy vary in different ways.
They also have a few other interesting findings. First, they find that SAM is only helpful for small batch sizes:

And second, they find that BatchNorm only helps when using large learning rates.

There’s only so much that one can say with certainty given small-scale experiments on easy tasks, but it’s always great to see work trying to get to the bottom of what’s really going on in neural net training.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
New version of the Generation, Evaluation, and Metrics (GEM) Benchmark. Has 40 datasets spanning 51 languages, accessible through the HuggingFace datasets API.


Limitations of the NTK for Understanding Generalization in Deep Learning
Neural tangent kernels scale worse with dataset size than the actual neural network. This holds for the infinite-width limit and the finite-width emiprical NTK.
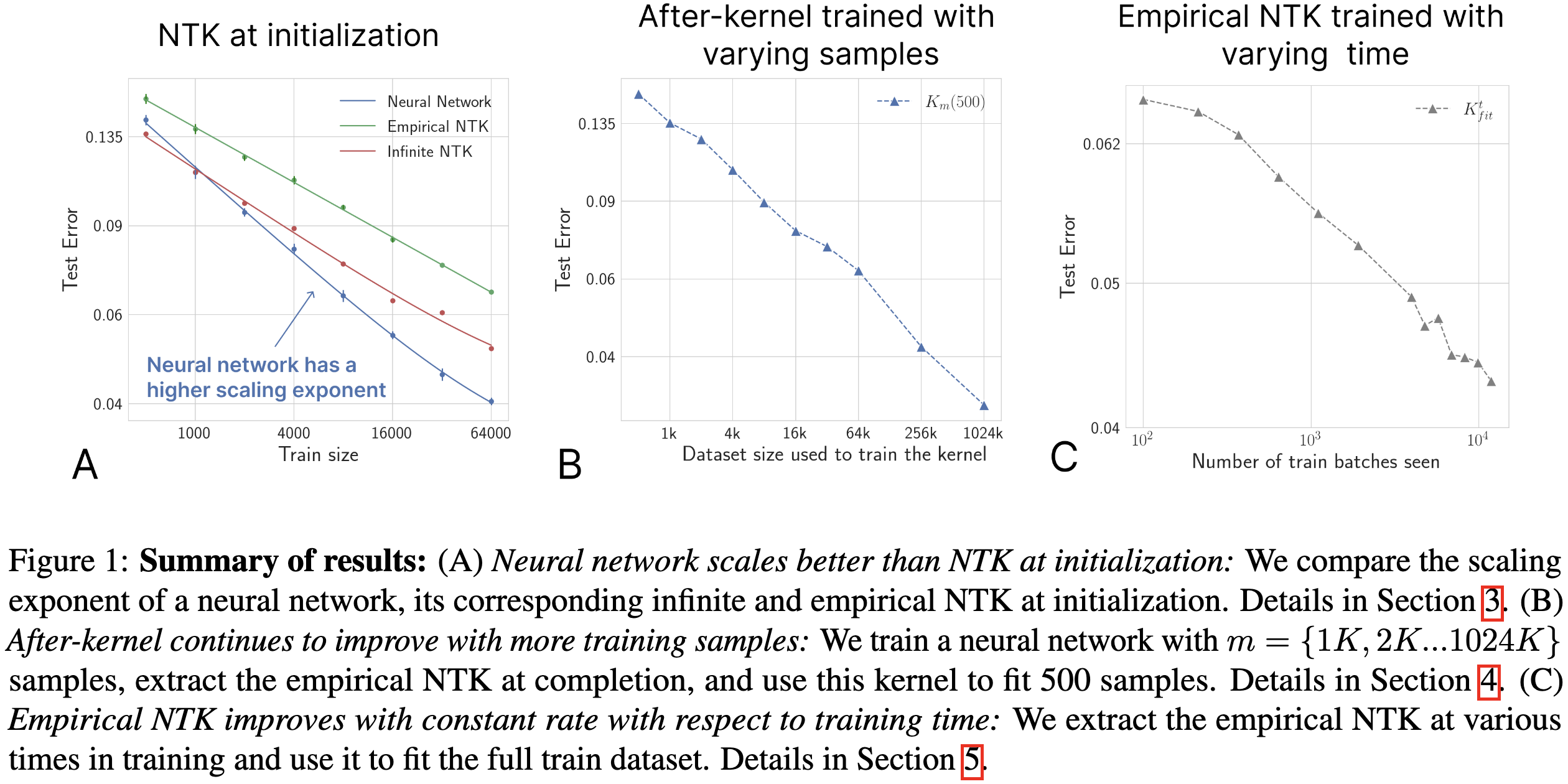
This result seems to be robust to various choices of hyperparameters:

They also find evidence that we can’t think of training as two distinct regimes for the purposes of NTK scaling laws. I.e., while you might hope that the network stabilizes after a few epochs and the NTK starts working better, this doesn’t happen in practice. The NTK keeps scaling at a consistent rate throughout training.

Stop Overcomplicating Selective Classification: Use Max-Logit
To determine which points to make a prediction on, just look at the largest logit. No extra heads, auxiliary logits, etc. Works even better if you add a loss term to penalize the entropy of the class probabilities to encourage more confident predictions.
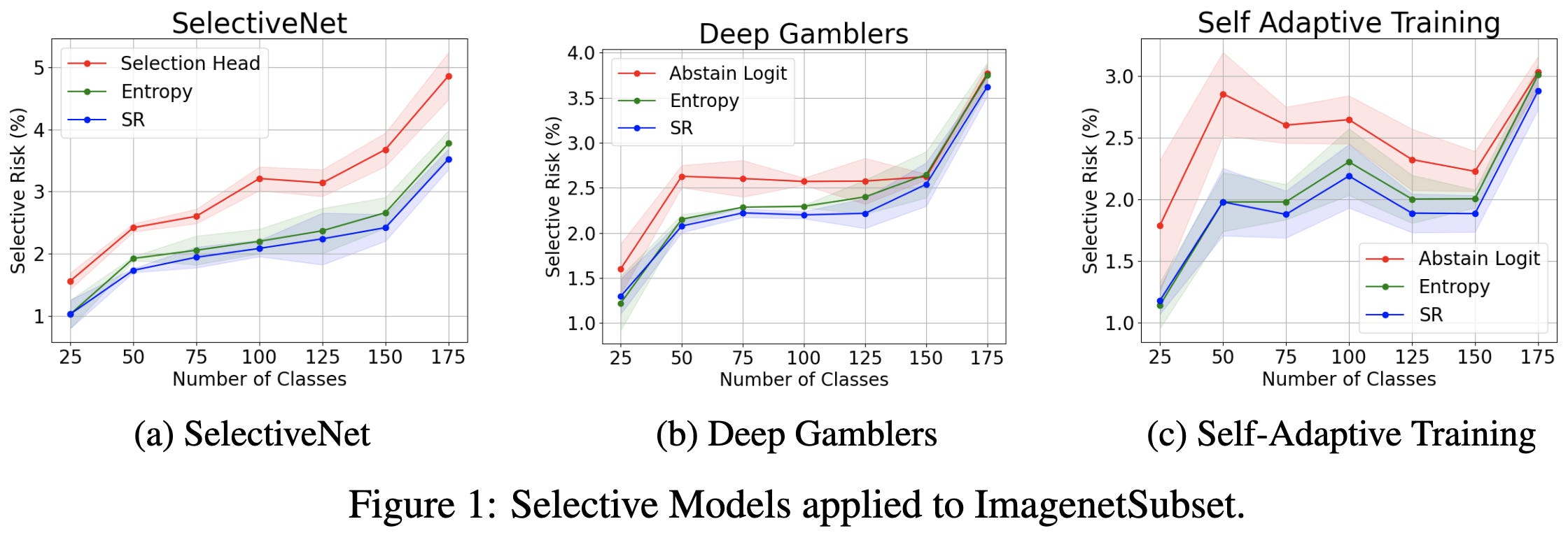
The efficacy of the entropy penalty is surprising since uniform label smoothing 1) penalizes the negative of the entropy and 2) consistently improves vanilla classification results for images. So apparently there’s a vanilla vs selective classification discrepancy here.
Diffusion models as plug-and-play priors
They combine a pretrained diffusion model with a pretrained classifier to generate inputs that 1) are probable, according to the diffusion model, and 2) maximize the classifier’s estimate of some user-chosen output.
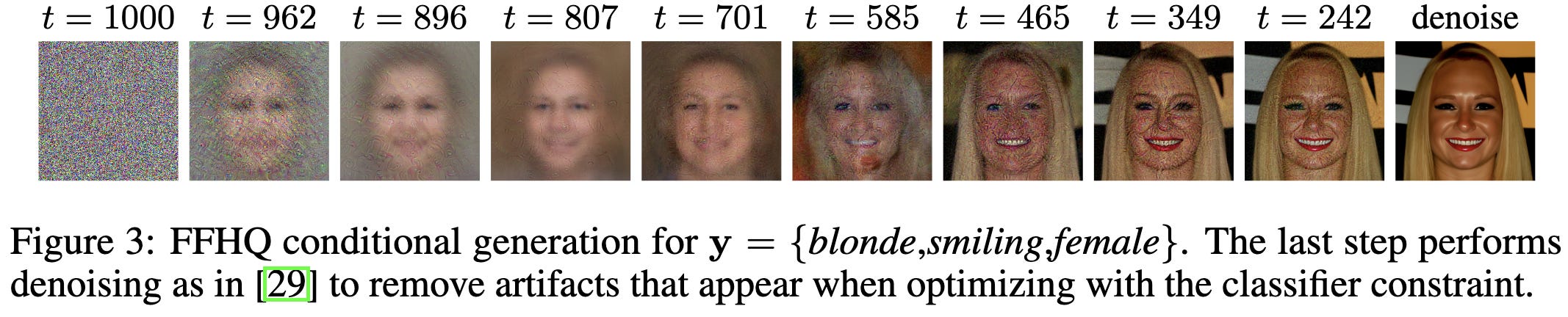
Seems to work well, and is pretty intuitive. The diffusion aspect of their updates tries to make the output look realistic, while the classifier aspect tries to make it maximize the classifier’s confidence for the target class(es). If you only had the former, you’d get some random, unconstrained image. If you only had the latter, you’d get some DeepDream-ish quasi-adversarial garbage.

They also show that you can generalize this approach to other tasks like segmentation and even the traveling salesman problem.
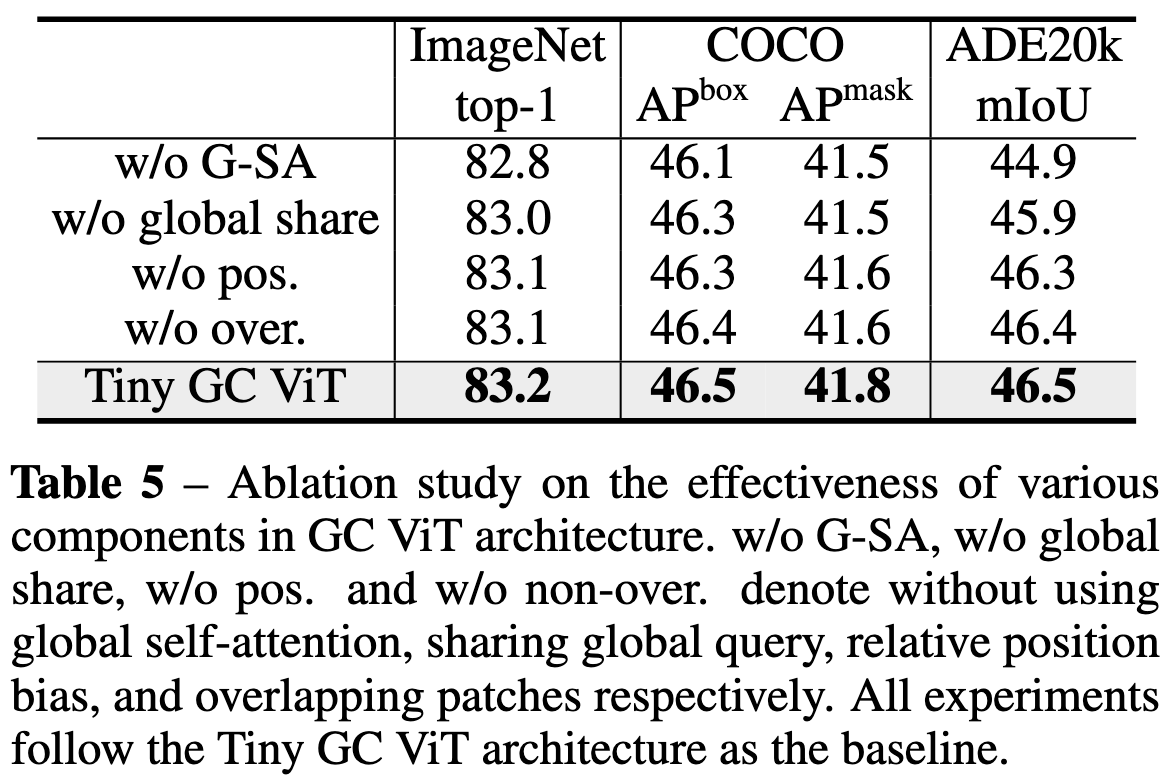
Global Context Vision Transformers
Proposes a vision transformer that alternates between local and global attention. The local attention is kind of like in a Swin transformer, using disjoint windows and all-pairs attention within each window. The global attention uses a fixed set of query vectors, one set per stage, and a more complex scheme that uses these same queries for every window.
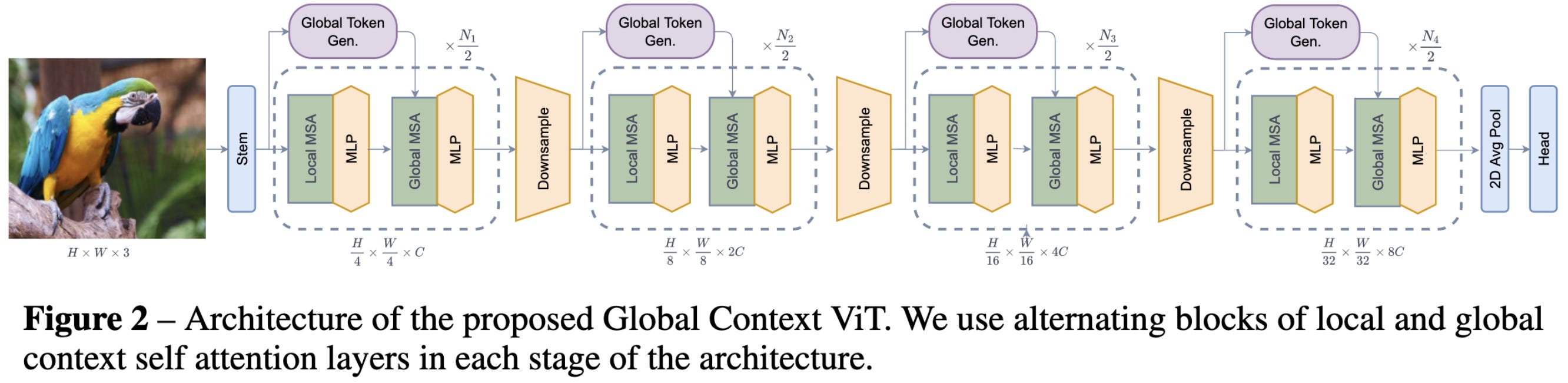
They have a particular form of downsampling involving depthwise convs, GELU activations, and Squeeze-and-excitation modules.


Beats swin transformers by about 1%, which is pretty standard for new vision transformer achitectures. But they do time (although not plot) throughput vs accuracy and seem to do unusually well on that front.

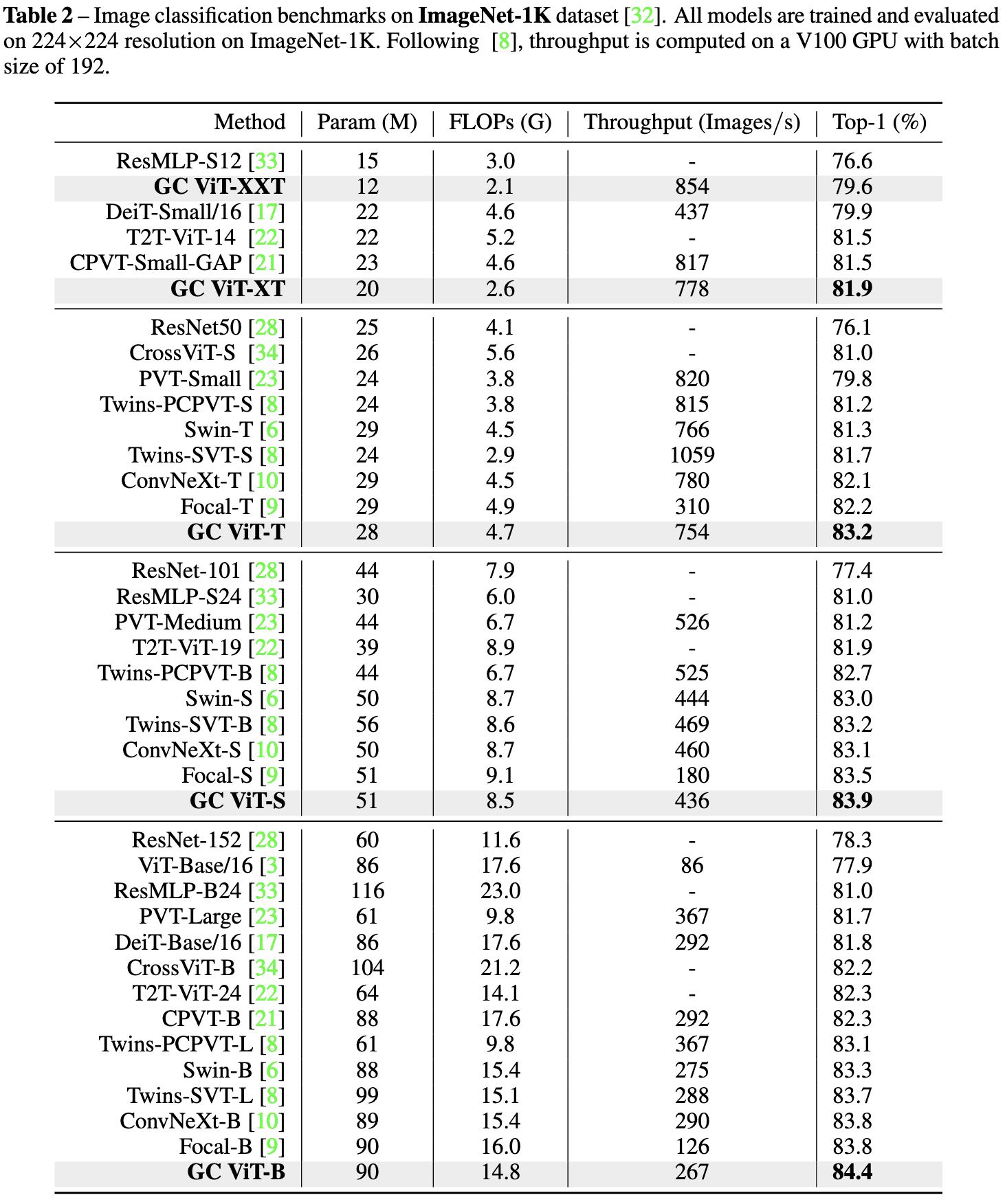
They also show improved mIOU on ADE20K and COCO detection.

Finally, they have ablation experiments showing that sharing the global queries within a stage and using global attention rather than local attention consistently help.
Contextual Squeeze-and-Excitation for Efficient Few-Shot Image Classification
They use a variant of squeeze-and-excitation blocks that pools over the batch dimension to produce shared channel weights for a whole batch. At test time, they replace the entire mechanism with fixed channel weights. Their goal is improved meta-learning, and they seem to do better than various alternatives on VTAB+MD.
