
2022-7-24 arXiv roundup: Int8 training at almost no accuracy loss, DataPerf, Scaling & inductive biases

This newsletter made possible by MosaicML.
Is Integer Arithmetic Enough for Deep Learning Training?
They got integer 8-bit training work with at most 0.5% accuracy loss on ImageNet. This is really impressive.

The way they manage to do it is with intelligent conversion to and from floating point at the start and end of each op.
To convert to ints, they subtract off the largest exponent from each float within a tensor, making all the resulting values subnormal. To convert back to float after performing their integer GEMM, BatchNorm, etc, they just add back in the correct exponent and throw away the low bits as needed.

In both cases, they use stochastic rounding to get unbiased estimates.

According to experiments with identical hyperparameters and similar training code, they lose little or no accuracy compared to floating point training.

They also have theoretical analysis of integer SGD with unbiased rounding.

Because this paper was exciting and I read it in detail, I have a bunch of questions about it. What accumulator bitwidth did they use for their integer GEMMs? What bitwidth did they use to store the weights? Could one get a speedup out of this on existing GPUs (or is their integer emulator hiding too much complexity?).
Overall, these results bode well for low-precision training—we already have int8 support in accelerators, and this result suggests that NVIDIA Hopper’s float8 might end up being easy to train with given the right tooling.
DataPerf: Benchmarks for Data-Centric AI Development
What if instead of holding the data constant and benchmarking different models, we held the model constant and benchmarked different data pipelines?

In particular, what if we broke down data pipelines into discrete, measurable components we could evaluate in controlled conditions?

And evaluated these components on a variety of different tasks?

That’s what DataPerf does. And it looks like it’s going to be an awesome contribution. This is a super important problem and it’s kind of weird that it took us this long as a field to make a large-scale benchmark for it.
Understanding Dataset Difficulty with V-Usable Information
This is one of those rare papers that gave me clearer thinking about the fundamentals of machine learning by giving crisp definitions for concepts I’d only thought about vaguely.
As background, you can define the amount of V-information a dataset has as the output entropy given the true inputs minus the output entropy given a fixed, useless input. If your model has enough capacity, I think the latter term just becomes the Shannon entropy of the label distribution in the case of classification.

They propose to extend V-information to apply to individual samples. Their “pointwise V-information” is the increase in output likelihood given the actual input vs given a fixed, useless input.

A nice property of this definition is that the overall V-information is the expectation of this quantity, similar to the relationship between regular mutual information and pointwise mutual information.

Both the V-information and PVI are easy to compute after training.

PVI turns out to be useful for identifying mislabeled data and understanding which aspects of an input are responsible for predictive performance.

E.g., SNLI results seem to depend mostly on the set of tokens present, rather than their ordering.

They also point out that PVI can be generalized to conditioning on arbitrary subsets B of input variables (or even extra context or confounding variables). In the text case, this amounts to text concatenation.

I like this extra generality for the purpose of having a more complete mental model.
Overall, great to see simple, elegant math with clear practical use cases.
Learning Iterative Reasoning through Energy Minimization
What if we trained our neural nets to recognize good solutions, rather than generate them? This could be promising because there are problems where recognition is provably easier than generation.
But just having a scalar loss “recognizing” the quality of your solution probably isn’t sufficient. Ideally, we’d have a loss that can also provide a gradient, so that the model can use its solution-recognition ability to iteratively output better and better solutions.
And that’s basically what they do.

Now there are several difficulties with training a differentiable loss. One is that you probably can’t find the global minimum of the energy landscape.
So what they do instead is just take a few gradient steps down the current energy landscape and use that in place of the global minimum.

Another difficulty is that, ideally, you’d backprop through this whole inner gradient descent, which is slow and memory intensive. Instead, they just backprop through the last gradient step and observe that this works fine.
To make this procedure work even better, they also maintain a replay buffer of old original states and approximate minima. The full algorithm for training the energy function looks like this:

Having a learned objective function is pretty freaky; this feels like it’s implicitly some sort of self-supervised learning procedure, but I can’t quite pin down how to frame it this way. It’s something along the lines of “find a model such that all your inputs are mapped to your outputs and with uniform gradient in all output directions.”
Anyway, an interesting paper you could spend a long time thinking about.
Formal Algorithms for Transformers
Gives precise and complete pseudocode for common Transformer building blocks. Great for ramping up on this topic and/or checking your understanding.

Analyzing Bagging Methods for Language Models
An ensemble of many pruned copies of a given model is usually worse than the original model on SuperGLUE, but can sometimes be better when the model is overfitting or has high variance.
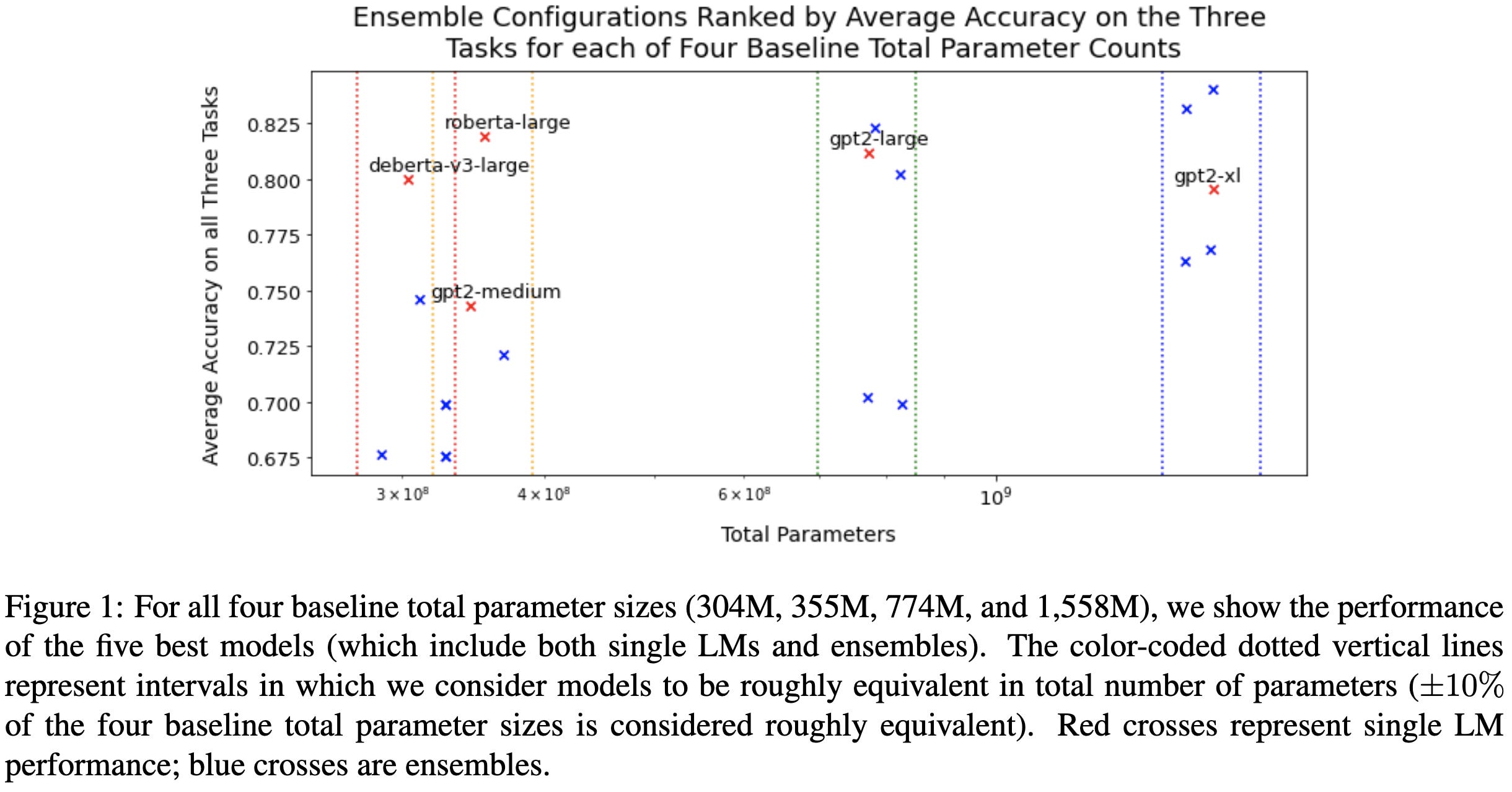
MoEC: Mixture of Expert Clusters
Makes sparse mixture of experts (MoE) work better by 1) clustering experts by adding a clustering loss to the expert routing and, 2) applying structured dropout within clusters of experts.

Their clustering loss tells the router to minimize the variance of the routing probabilities within each cluster m, as well as to have a large gap in maximum routing probability between the assigned cluster and other clusters.

To avoid overfitting as expert count increases, they propose to drop out experts only within clusters, as opposed to globally across all experts. The idea is that 1) even with the dropout, tokens should always have a relevant expert this way, and 2) experts within a cluster will see a greater variety of tokens than without dropout.

Their approach seems to successfully prevent overfitting.
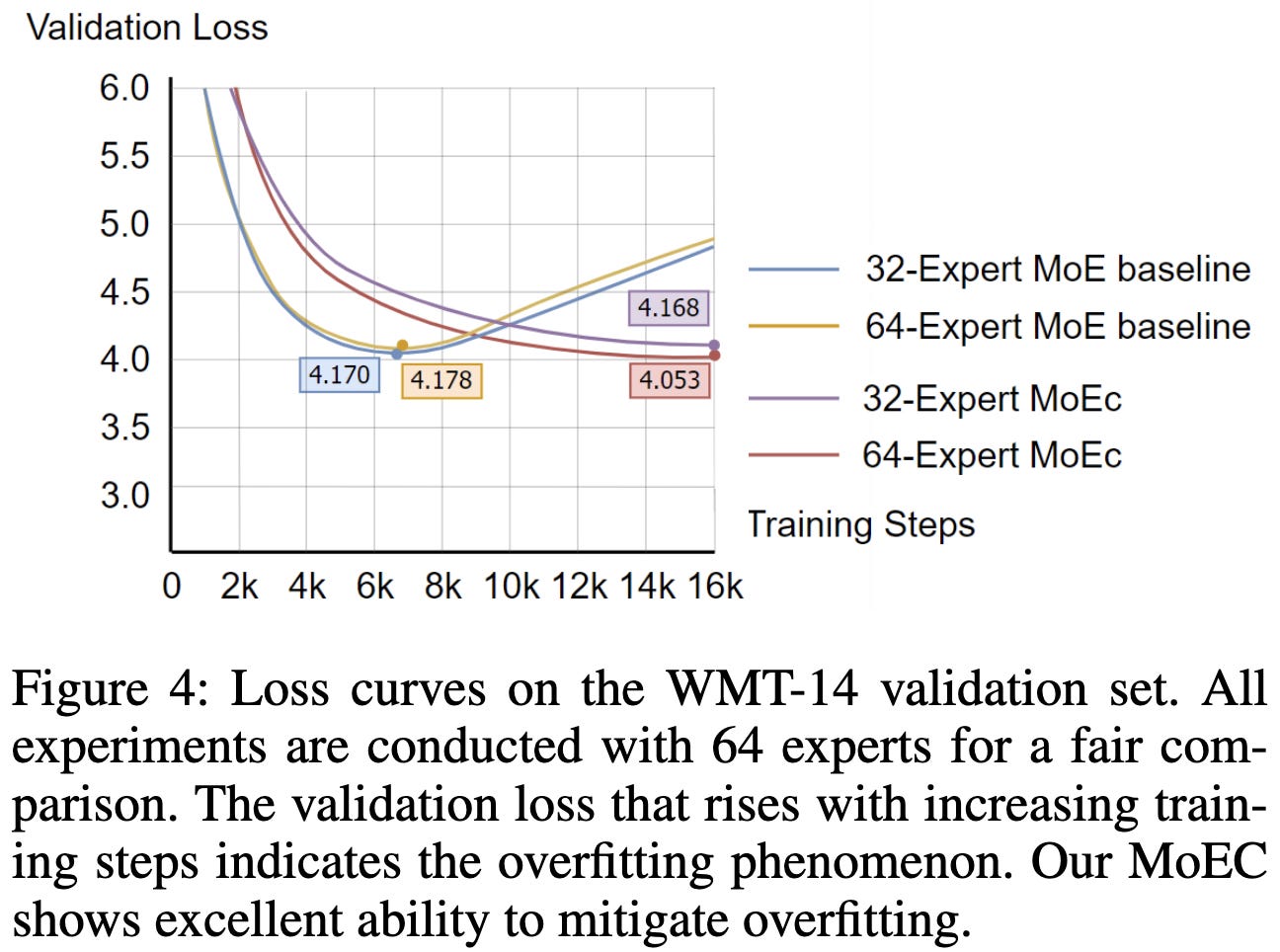
And there’s evidence that their clustered dropout works better than regular expert dropout.
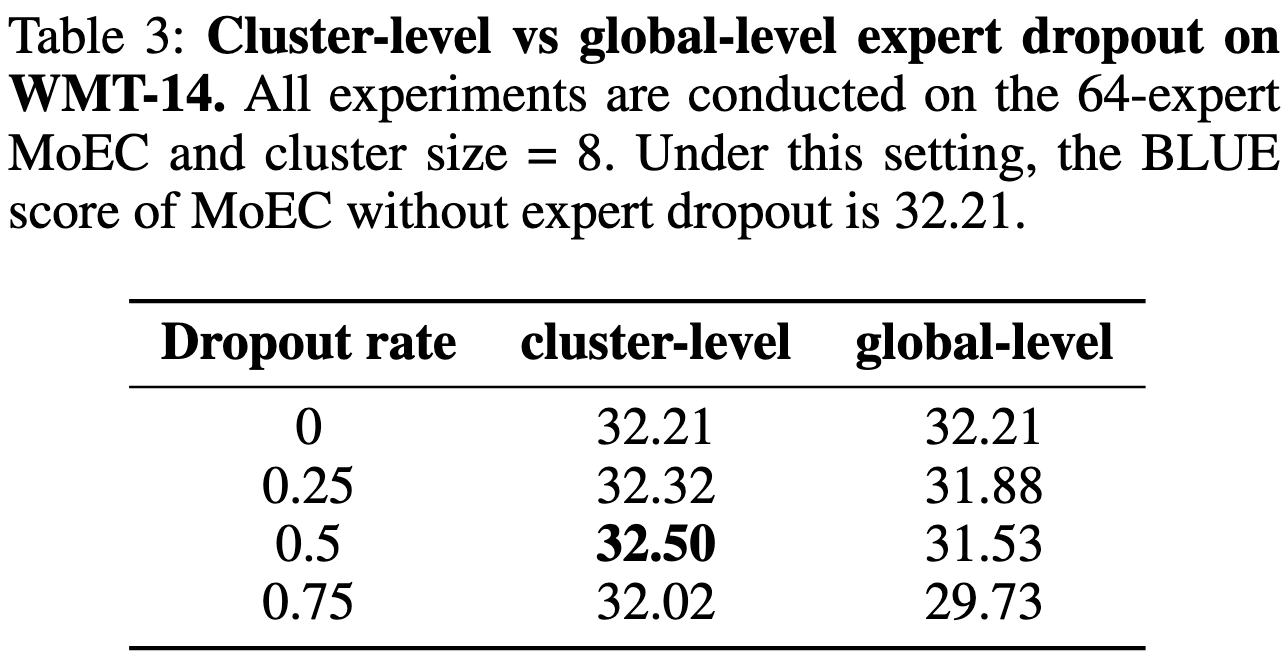
Their method seems to be especially helpful for large numbers of experts, which is consistent with the reduced overfitting story.
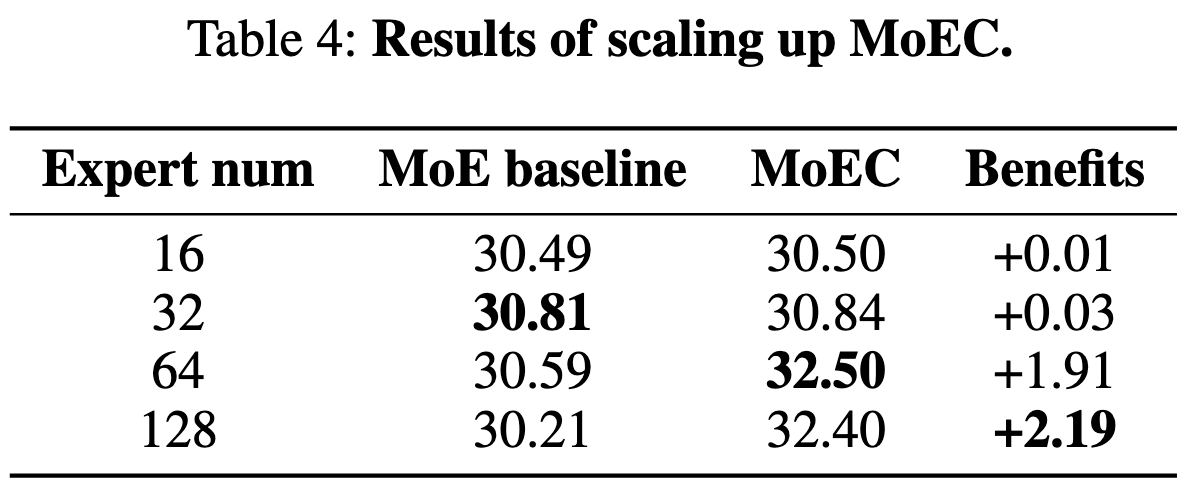
I’m not sure I buy the intuition for why this works, but it does seem like a substantive improvement on the tasks they consider.
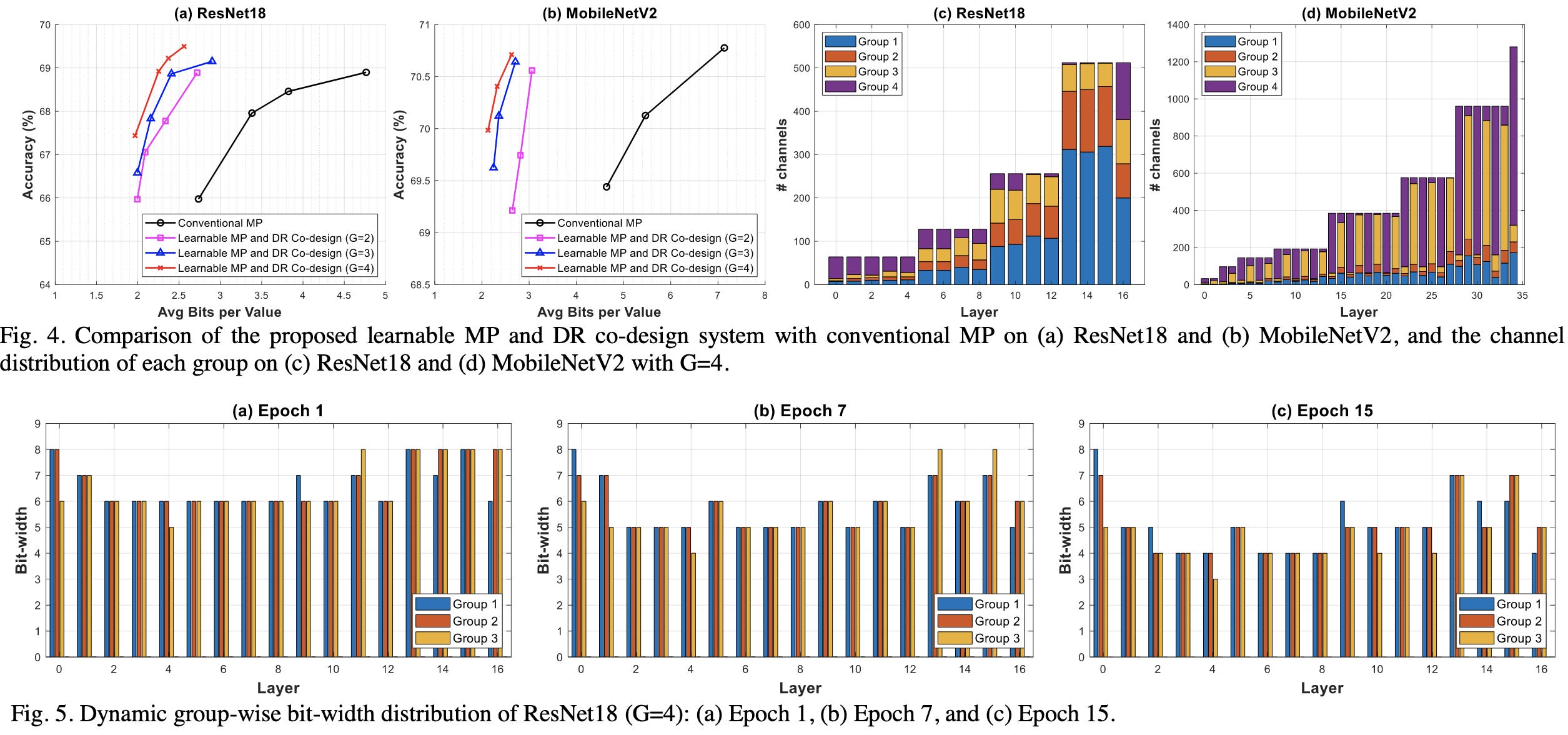
Learnable Mixed-precision and Dimension Reduction Co-design for Low-storage Activation
Compresses activations to save memory using a mix of quantization and PCA. They first run PCA, then group channels by variance, and assign more bits to groups with more variance. The bitwidth reduction is gradual and based on an online search procedure.

Seems to work pretty well, although seemingly doesn’t preserve full accuracy on ResNet-18 and doesn’t have comparisons to other activation compression methods like ActNN.
YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
This is a pretty dense paper featuring such components as the “coarse-to-fine lead head guided label assigner” and “planned re-parameterized convolution.” tl;dr they tweaked the heck out of their architecture and got the numbers to go up quite a bit.

One generalizable idea I found is that of increasing channel count while also switching to grouped convolutions (along with added channel shuffling). Plenty of papers have claimed that this works better in terms of FLOP and parameter count, but it’s interesting to see it apparently yield wall-time improvement also.

Scaling Laws vs Model Architectures: How does Inductive Bias Influence Scaling?
Google and DeepMind trained a *ton* of large language models of diverse architectures to investigate how different architectures scale.
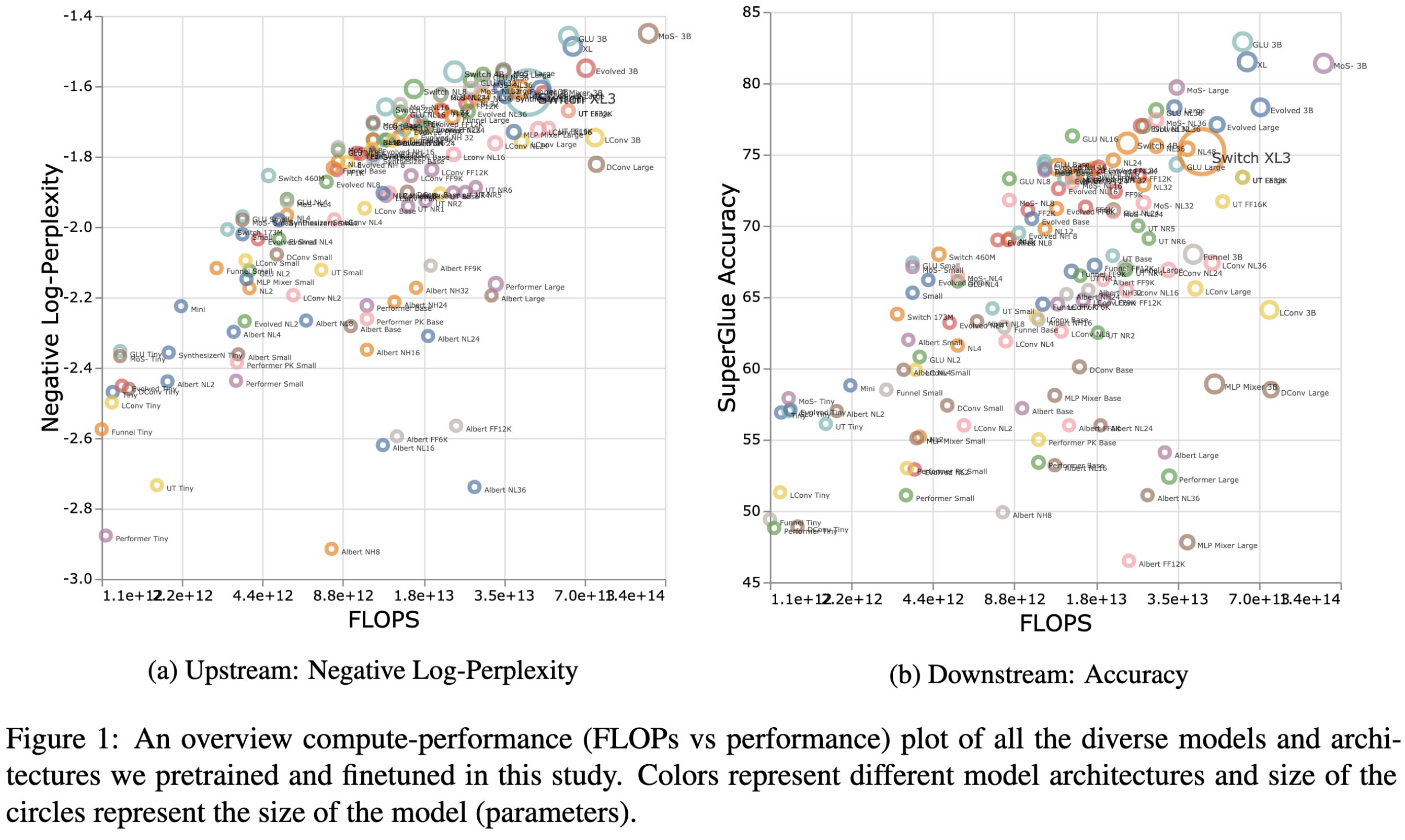
Consistent with previous work, it’s rare to beat vanilla transformers.

And even rarer to beat vanilla transformers on downstream tasks. GLU/GELU, Mixture-of-softmax, and sort of MoE are the only methods that every really beat transformers.

How you scale up a model can matter, with different scaling methods yielding different apparently “better” models. Though the relative ordering is somewhat stable upstream vs downstream for depth scaling.

I was hoping they’d find that better architectures would yield more favorable scaling laws, with clear power-laws and high explained variance. But it looks like reality isn’t so clean.
Overall, this is thorough, well-executed empirical work answering important questions, and I wish more papers were like this.
Deep equilibrium networks are sensitive to initialization statistics
DEQ models are cool because they promise to allow decoupling training compute from activation memory storage. But they’re unstable and hard to train in practice. This paper suggests that using an orthogonal initialization can help with the instability (both in theory and practice), although there might be a slight test accuracy cost according to their transformer experiments.

Plex: Towards Reliability using Pretrained Large Model Extensions
A 40-page monster of a paper, excluding appendices. But it addresses an important problem, introduces tasks and datasets to facilitate future work, and gets great results.
The problem they’re going after is model “reliability”, roughly formulated as a mix of robustness to different distributions and uncertainty estimation.


To improve reliability, they introduce Pretrained Large model EXtentions (PLEX). These consist of a few interventions on top of a vanilla model.
First, they use BatchEnsemble on a few layers near the output to get an ensemble of predictions. And second, they use a Gaussian process as the last layer, but modified to better handle input-dependent label noise.
These interventions are added to a pretrained model trained on a ton of data in two different pretraining stages.

Their approach works extremely well, beating SotA solutions for various problems without even training directly on the tasks in question.

Makes me hope that evaluating reliability across a standard battery of tasks will become a common practice.