


2022-9-11 arXiv roundup: Beating GPT-3 with 20B params, Emergence in language models, Worse deepfakes on the horizon

This newsletter made possible by MosaicML.
AlexaTM 20B: Few-Shot Learning Using a Large-Scale Multilingual Seq2Seq Model
Amazon beat the 175B-param GPT-3 with their 20B-param AlexaTM.
In terms of architecture, AlexaTM is just a generic Pre-LN Transformer with learned positional embeddings. Though note that this is a sequence-to-sequence model, not a decoder-only model like GPT-3 (more on that later).

Their data is just wikipedia and a variant of C4, spanning twelve languages. They convert most of the text to “spoken” form, removing capitalization, punctuation, etc. They also upsample wikipedia 10x and oversample from languages with less text. They tokenize with SentencePiece.

To train AlexaTM, they use an 80-20 mix of denoising and causal language modeling. I.e., the sequence it’s supposed to spit out is either a) the whole input without certain tokens dropped or, b) the continuation of the input.

In total, training takes about 10x less compute than GPT-3, although ~2x of this is probably just V100s vs A100s:

The resulting 20B-parameter AlexaTM beats the 540B-parameter PaLM at multilingual natural language generation.

And it usually beats PaLM and GPT-3 on machine translation.

PaLM crushes it for 0-shot SuperGLUE though. AlexaTM does come in second, but I’m not sure why there’s such a big gap.
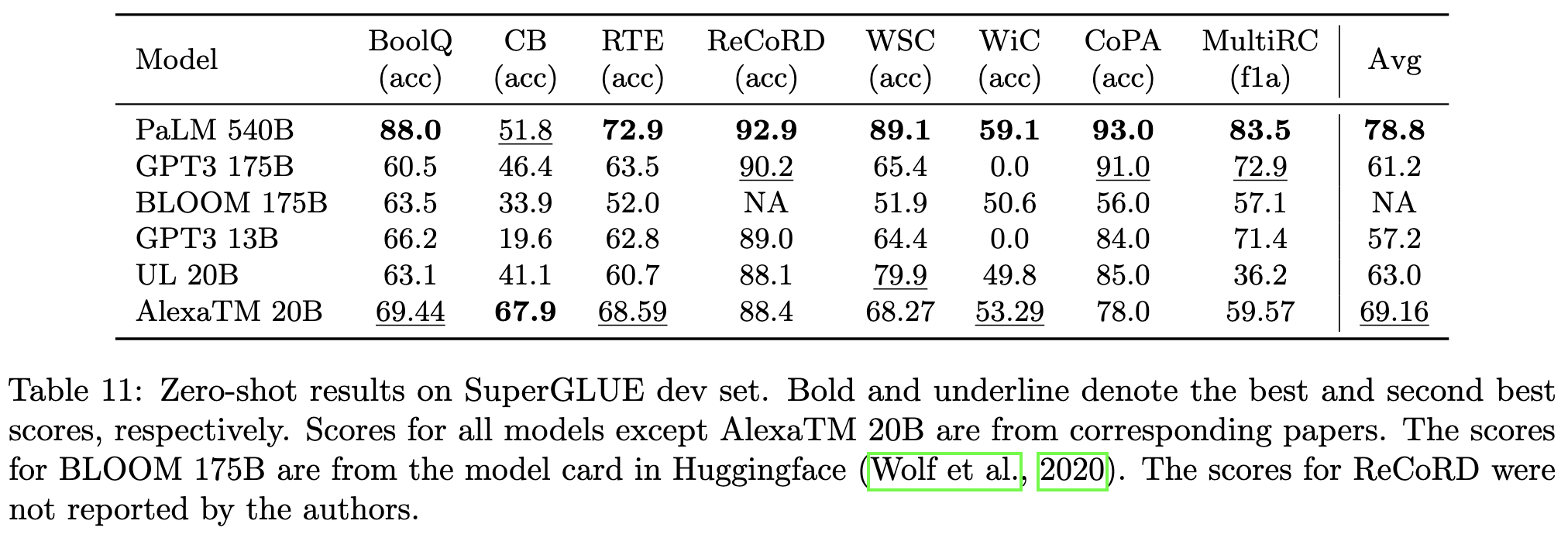
Overall, this is a surprising result. Beating 540B params with 20B params is even more extreme than the Chinchilla numbers, and highlights how much dataset size and quality matter.
They also attribute a lot of their gains to using a seq2seq model rather than a decoder-only model, which suggests we might see these models become more standard—I mean, if they beat autoregressive models even at autoregressive modeling, I’m not sure why we wouldn’t switch.
Foundations and Recent Trends in Multimodal Machine Learning: Principles, Challenges, and Open Questions
A long survey paper on multimodal learning. Introduces a taxonomy of challenges and approaches and has a lot of helpful diagrams throughout. Definitely worth spending some time on if you’re trying to ramp up on this area.

Bispectral Neural Networks
They make neural nets invariant or covariant to transforms like translation or 2d rotation. You’ll have to stare at the math for a long time to really get what’s going on, but it’s pretty elegant.
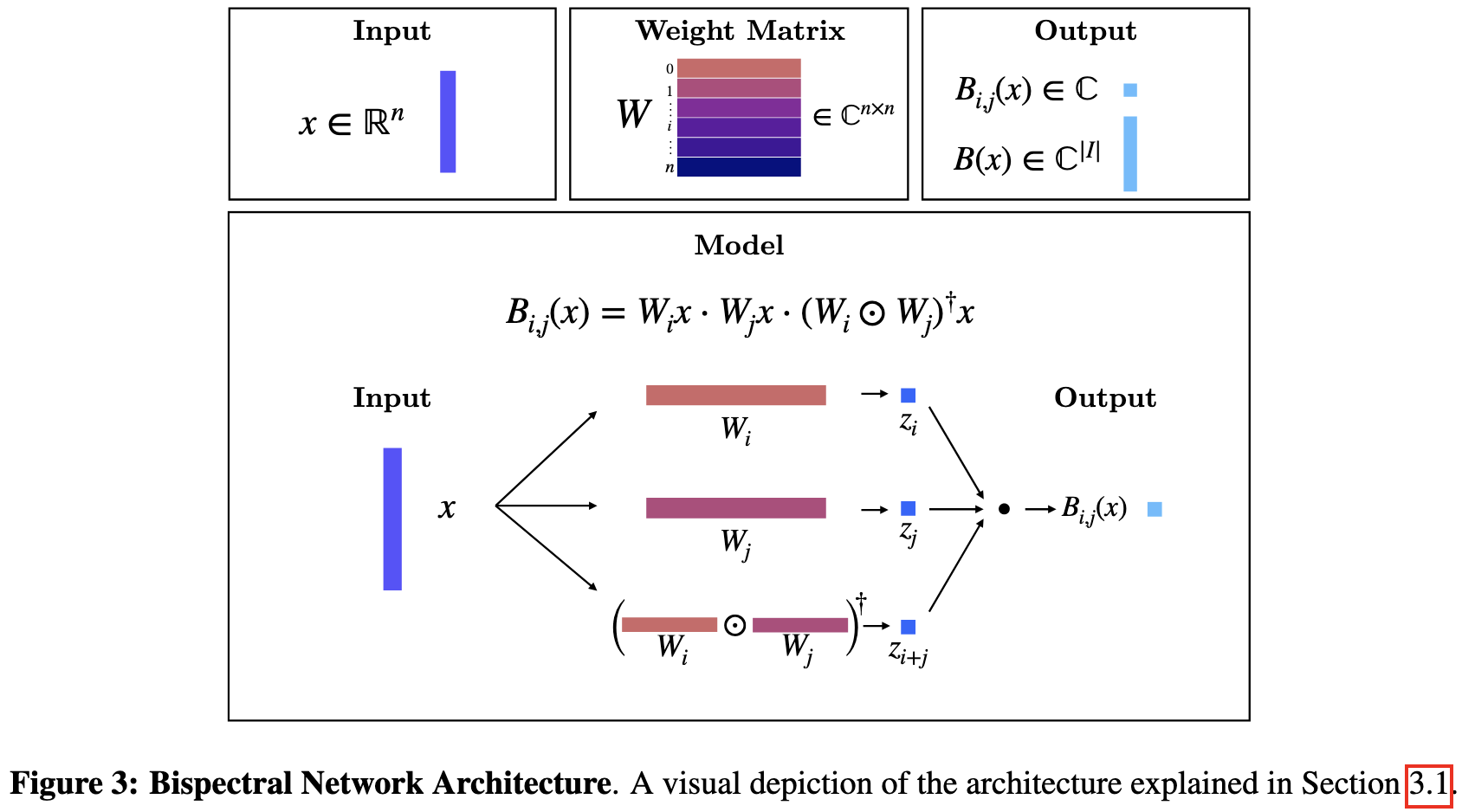
It also ends up learning almost exactly what you’d hope: Gabor filters for translation invariance and circular-ish filters for rotation invariance.

Their method takes n^2 parameters for n-dimensional inputs, and the empirical results are pretty minimal, but this is one of those papers that can actually teach you something new.
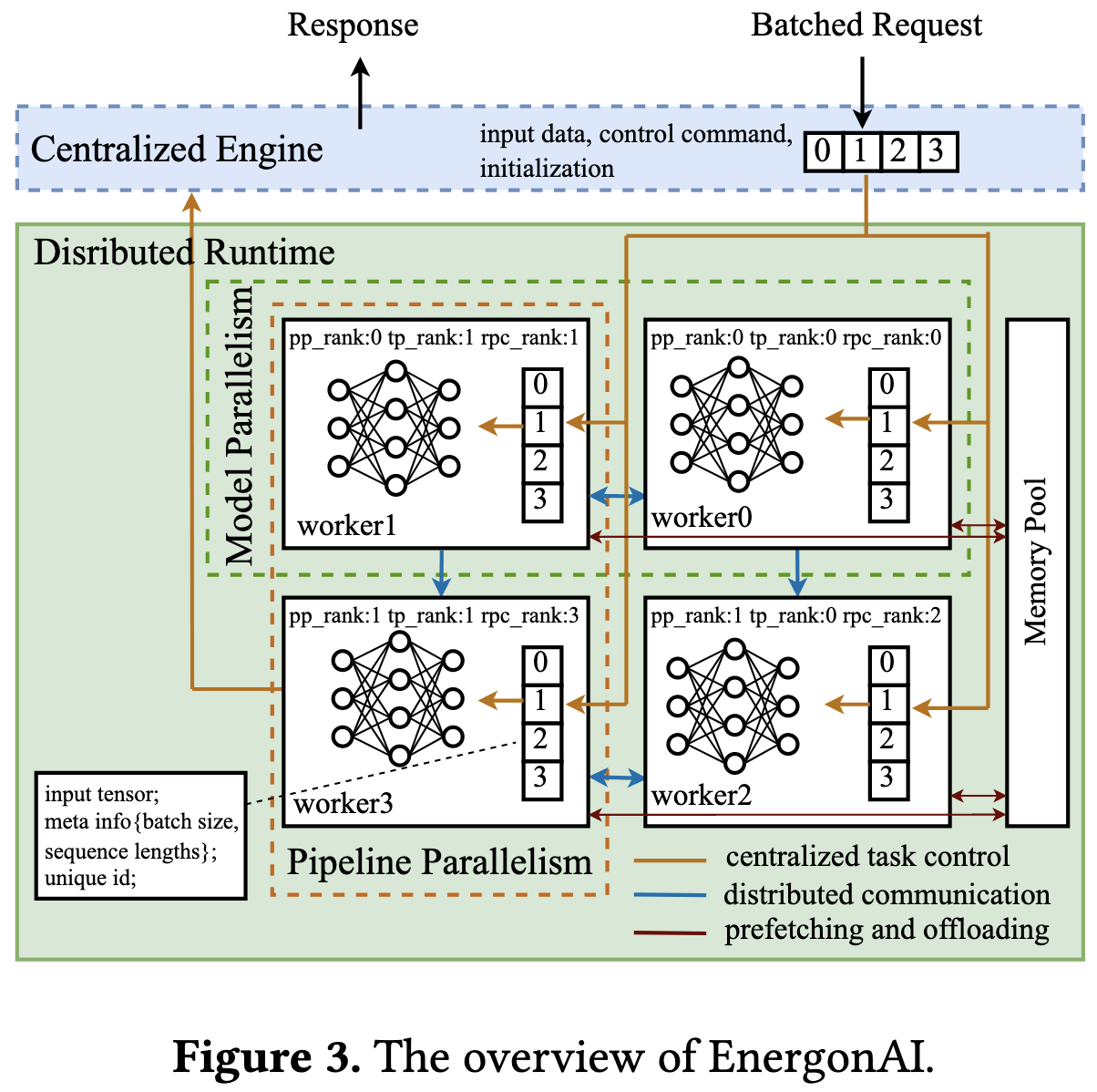
EnergonAI: An Inference System for 10-100 Billion Parameter Transformer Models
How do you get low-latency inference for large language models? During training, one can use a simple fully-sharded data parallel setup to get excellent scaling given decent interconnect. But during inference, there might only be one sequence, or at least a much smaller batch. How do you parallelize well when you can’t do it across the batch dimension?
Long story short, a mix of tensor parallelism and pipeline parallelism.
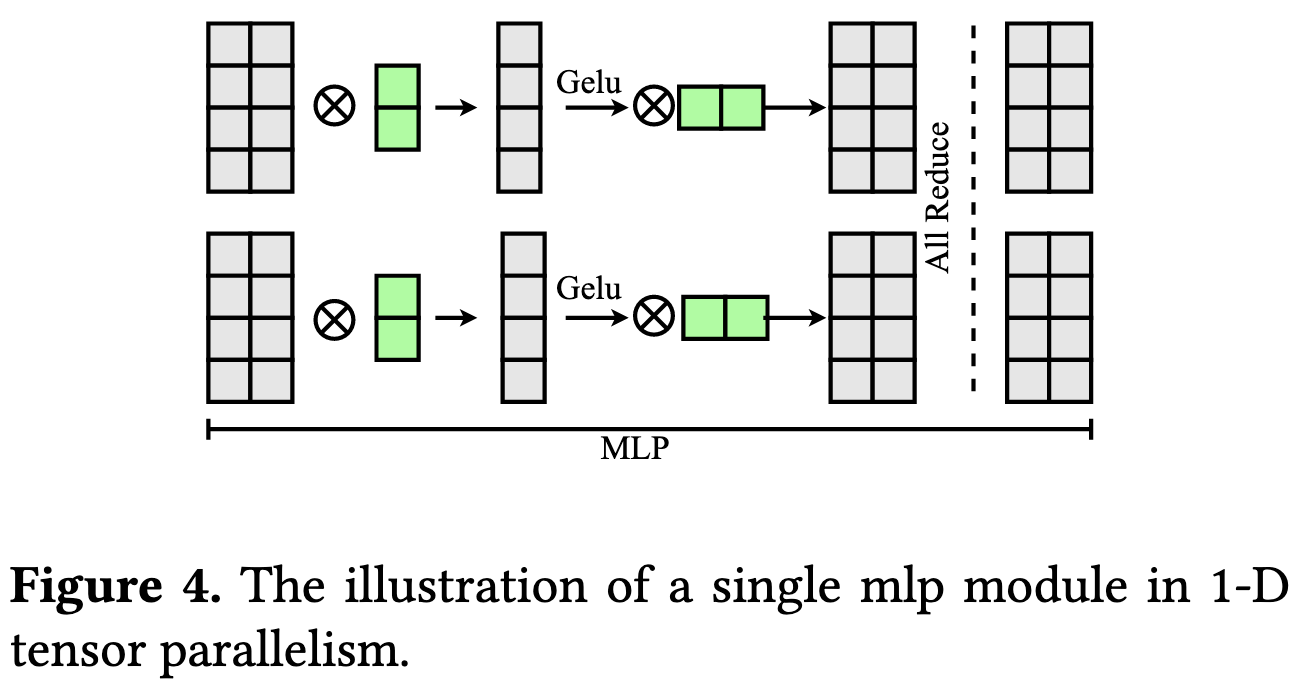
For the tensor parallelism, they mimic Megatron. You compute partial sums for each output position and then allreduce to get the final answer. When dealing with pairs of linears (like in an FFN), you can have each worker compute a disjoint subset of the output columns for the first linear, and then use its subset of the columns to compute partial sums for the final output. This lets you synchronize only the final activations, not the intermediate ones.
For the pipeline parallelism, they basically just exploit the observation that you can keep all the pipeline stages busy as long as your queries arrive regularly enough. There’s some tricky concurrency logic in the control plane to issue batches quickly without messing up the sample ordering across stages.

They also rip out the padding tokens before (and re-insert them after) each FFN block. This is tricky in a distributed context because all the workers need to know the padding for each sequence in the batch.

Lastly, to avoid running out of memory, they shard parameters across all the GPUs in a machine and prefetch the parameters for upcoming layers asynchronously in a separate CUDA stream.
Seems to outperform an existing alternative, although they don’t scale up to large numbers of GPUs.
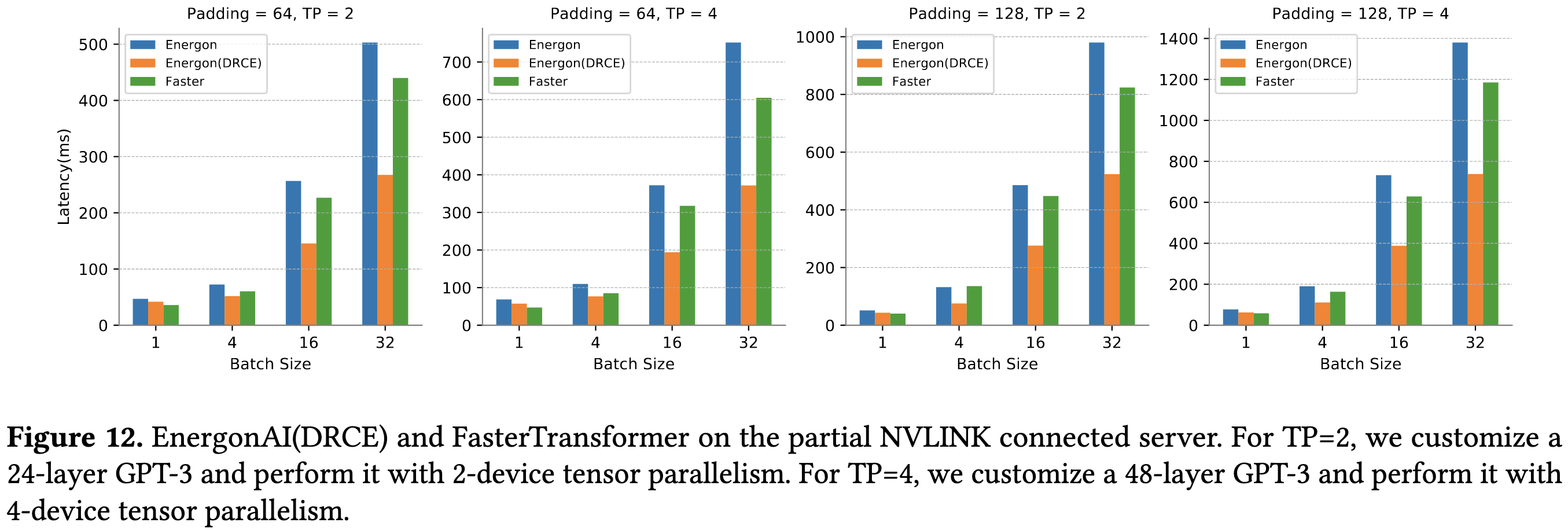
Also, I really like this profiling they did (below). The computation time of attention basically doesn’t matter for large models with typical sequence lengths.

A Review of Sparse Expert Models in Deep Learning
An insightful survey of MoE models with pretty exhaustive coverage of the literature, overall results, and main design choices. It’s still early days for MoE models, and we need a lot more careful experiments to help us figure out…well, almost every aspect of how best to use them (how many experts? where to put them? what routing function should we use? at what granularity should we route? more experts or deeper experts? etc.).

A few nuggets I found:
Yes, people have tried routing whole sequences, rather than individual tokens. Unclear if it was better.
You can seemingly convert an MoE expert count and parameter count to an equivalent dense parameter count, but the paper that showed this is probably undervaluing data like in OpenAI’s 2020 scaling paper.
You probably don’t need k > 1 for your top-k routing.
Stability issues are common but maybe can be addressed with the right loss functions.
If you want to read more about some MoE papers, I summarized five of them in a previous post.
On the Horizon: Interactive and Compositional Deepfakes
So you probably know that neural nets can generate videos of people saying stuff they never said. But Microsoft’s chief science officer articulates two threats beyond this that could be way worse: “interactive” and “compositional” deepfakes.
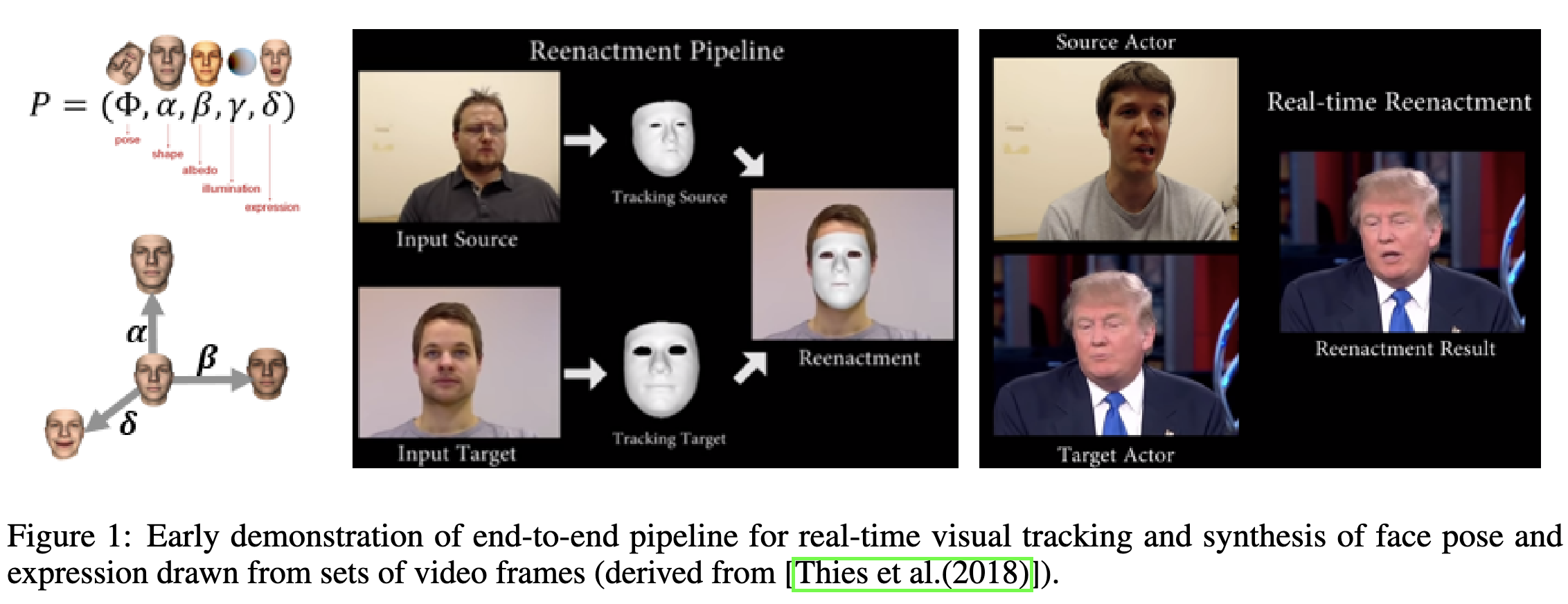
Interactive deepfakes are exactly what they sound like. It’s not just static content, but the illusion of talking to a real person. Imagine a scammer calling your grandmom who looks and sounds exactly like you. Or someone impersonating a politician and calling for acts of violence.

The second threats are “compositional” deepfakes. Here, a bad actor creates many deepfakes to weave together a whole “synthetic history.” Think making up a terrorist attack that never happened, inventing a fictional scandal, or putting together “proof” of a self-serving conspiracy theory. Such a synthetic history could be supplemented with real-world action (e.g., setting some building on fire). They could also reuse the machinery we’ve built for optimizing digital advertising, feeding people personalized disinformation that they’re more likely to believe.

There’s also a risk of automating compositional deepfake creation, creating “adversarial generative explanations” that twist facts to fit a disinformation goal.

I’d also add that, as these capabilities expand, the indirect effects could be even worse than the disinformation itself. E.g., imagine a political leader ordering followers to do something unethical, then later insisting that it was just a deepfake giving that order and he knew nothing about it.
Or laws banning “disinformation,” where disinformation is of course defined by whoever’s currently in charge.
Fortunately, there are a few mitigation strategies the author identifies. These include public awareness, careful regulation, automated deepfake detection, and cryptographic provenance tracking (e.g., your iPhone digitally signing all your photos). So the outlook’s not great, but there are paths to overcoming this problem.
Petals: Collaborative Inference and Fine-tuning of Large Models
They propose to shard huge models across many servers, with each server potentially owned and operated by a different party. The sharding is done by groups of layers so that inference gets pipelined across a sequence of servers.
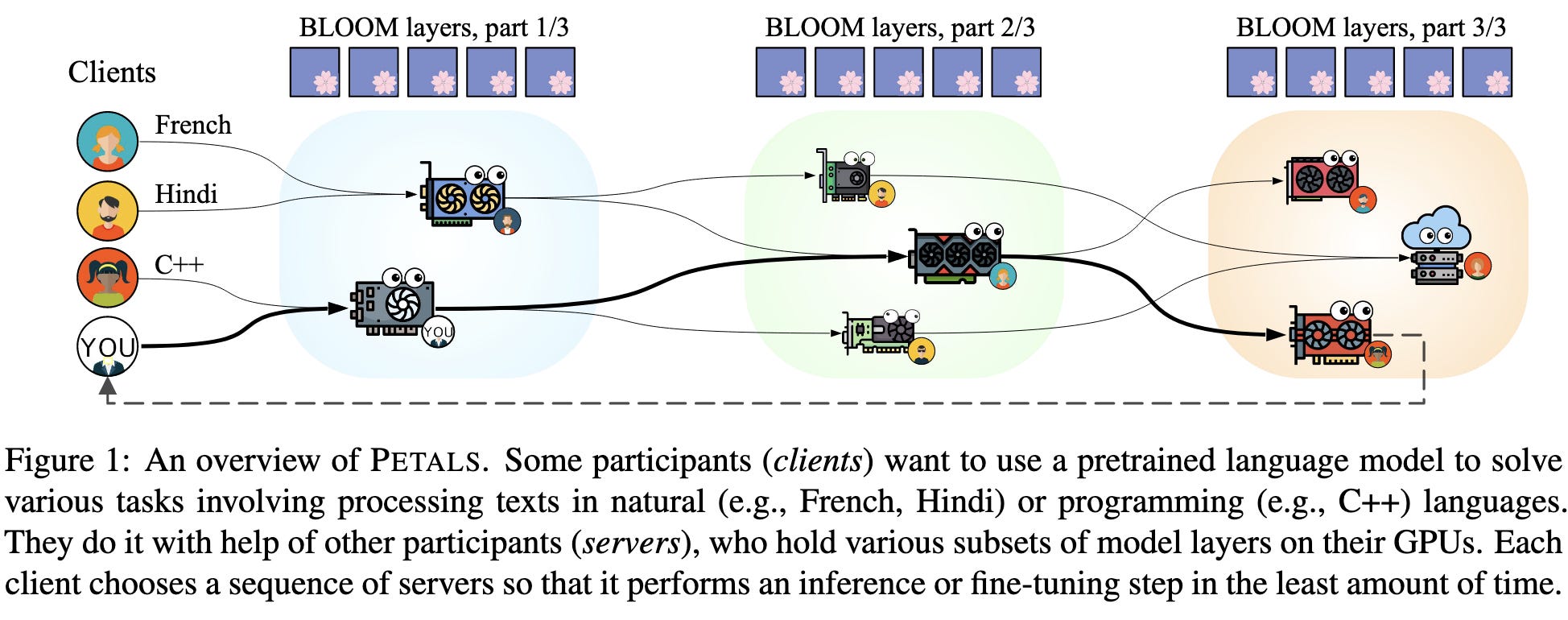
This is complex under the hood, but fits behind a nice API. The system also lets you query the intermediate activations or get gradients for your input prompt or custom adapter layers at the beginning or end.

From a systems perspective, they have a distributed hash table in which servers advertise their presence and throughputs. They don’t talk much about fault tolerance but mention taking care of that via Hivemind. They also quantize the weights to 8 bits and attempt to partition the model so that throughput is maximized.
Their security model is that everyone trusts everyone.
The interesting empirical result here is that you’re better off shipping activations over slow network connections (Petals) than shipping weights over PCIe from CPU RAM to GPU RAM (“offloading”). This is a product of LLM weight matrices being gargantuan relative to the activations for small batch sizes and sequence lengths.

It’s not clear how much overhead there is from this approach vs just, say, having an 8xA100 box with tensor or pipeline parallelism. But it’s an interesting idea and a cool project.
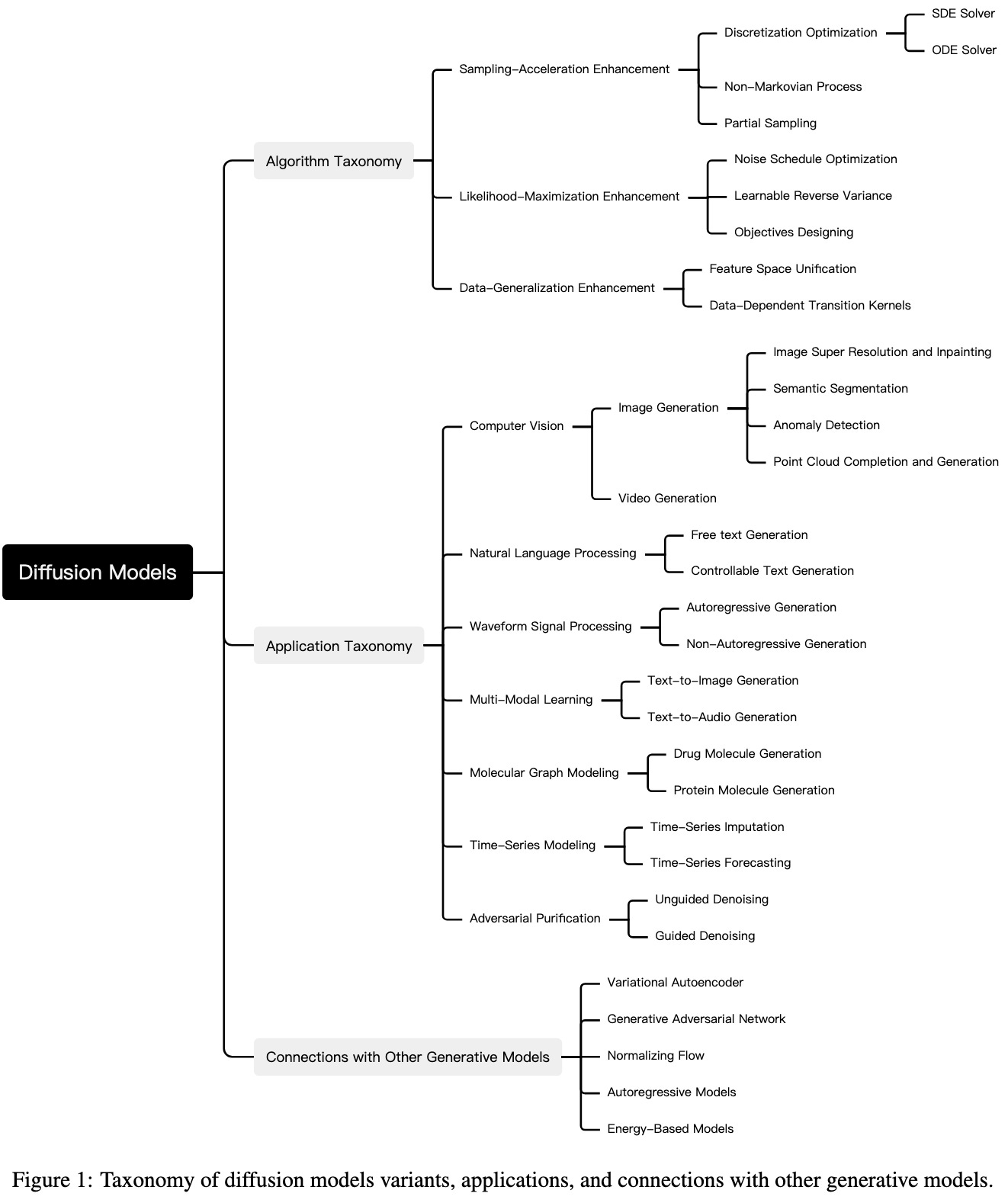
Diffusion Models: A Comprehensive Survey of Methods and Applications
A big old survey of diffusion models. What seems most valuable here is that they talk about various techniques with consistent notation; this is actually super valuable for collections of math-heavy papers.
Emergent Abilities of Large Language Models
Language models sometimes perform at chance level for a given task until you use enough parameters and training compute, at which point they suddenly do well.

This pattern holds not just across tasks, but even across modeling choices like giving the model access to a scratchpad or using chain-of-thought prompting.
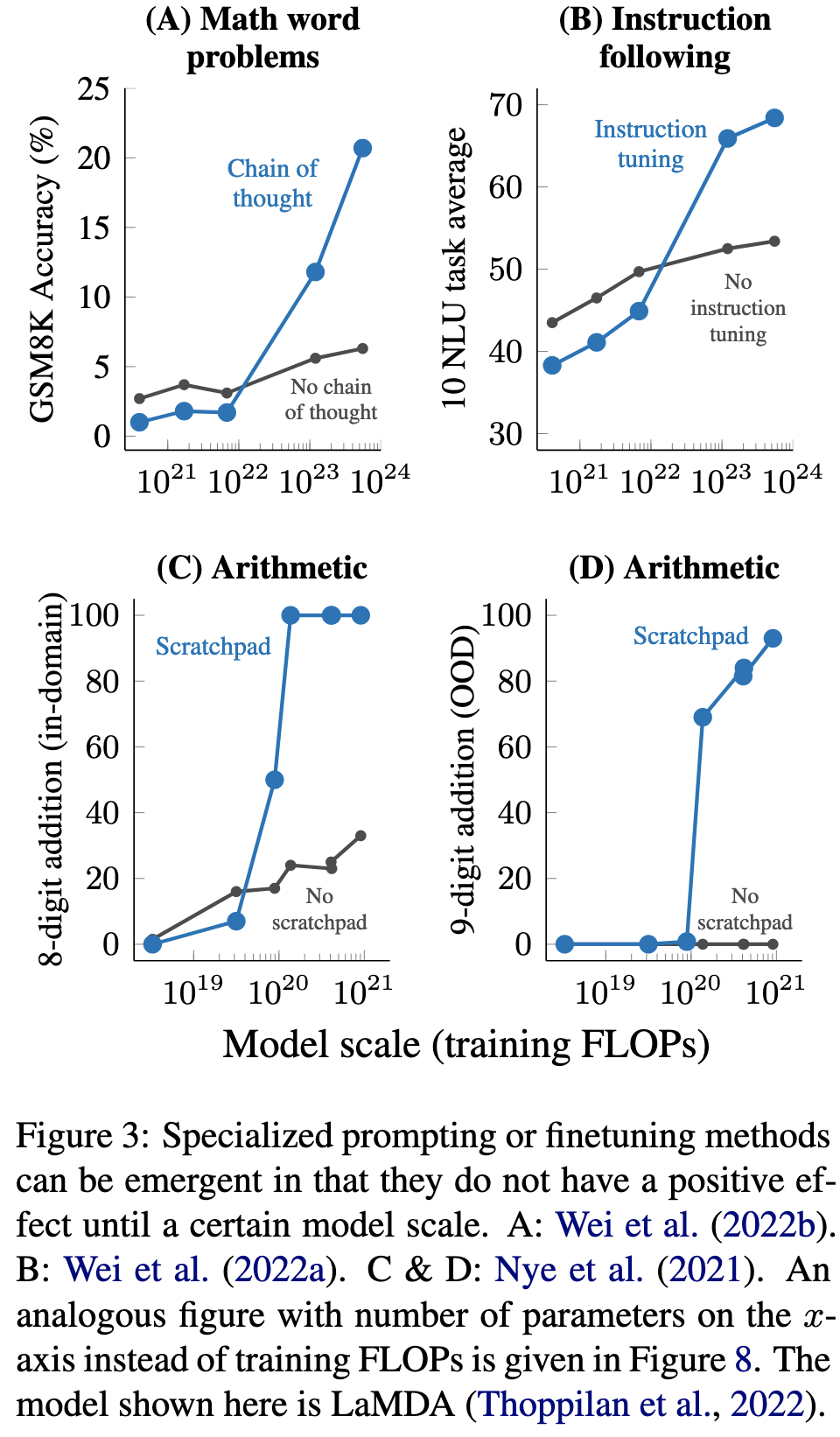
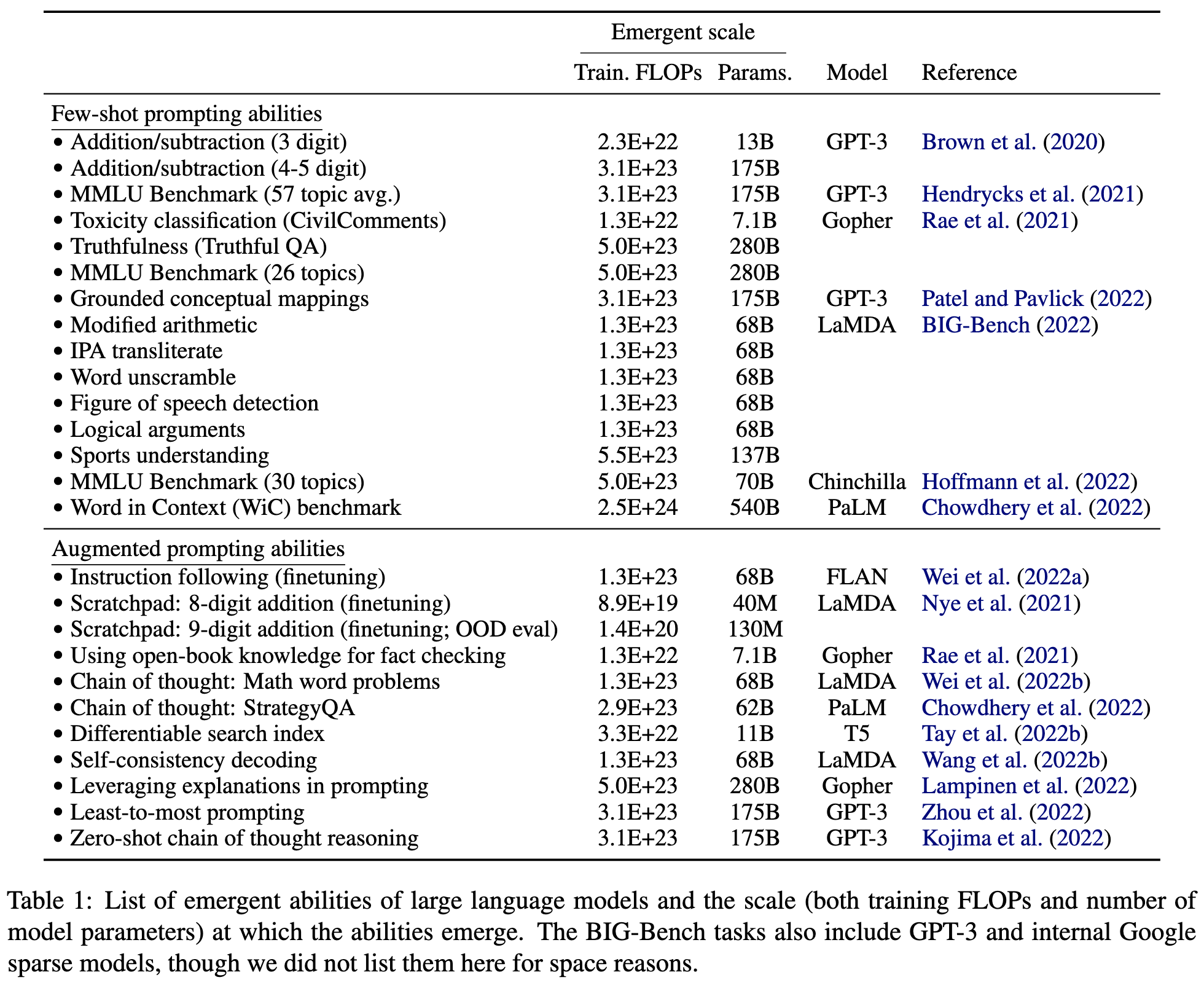
They compile a big list of known cases of emergence, including both the task and the scale at which emergence happens.
A lot of this paper is the discussion section, which is thoughtful and interesting.
My previous mental model for emergence was that it’s largely an artifact of how the task is formulated (see results in BIG-Bench). E.g., if you only call an answer correct if all k tokens are correct, a smooth increase in the probability of getting one token correct will yield exponential growth in the probability of getting all k correct. But this paper makes me think it’s not so clean a story.
They also touch on the AI safety implications, noting that models could suddenly gain capabilities that we hadn’t anticipated and that scale might actually be all we need even if there are tasks AI totally fails at today.