
2023-11-19 arXiv roundup: Inverse-free inverse Hessians, Faster LLMs, Closed-form diffusion

A fundamental result in queueing theory is that, if items enter the queue faster than they’re processed, the length of the queue tends to infinity. Just a fun fact that, uh, has nothing to do with me keeping up papers lately.
Jorge: Approximate Preconditioning for GPU-efficient Second-order Optimization
What we’d often like to do in gradient-based optimization is Newton’s method, which jumps straight to where the minimum should be under a local quadratic approximation of your loss landscape.
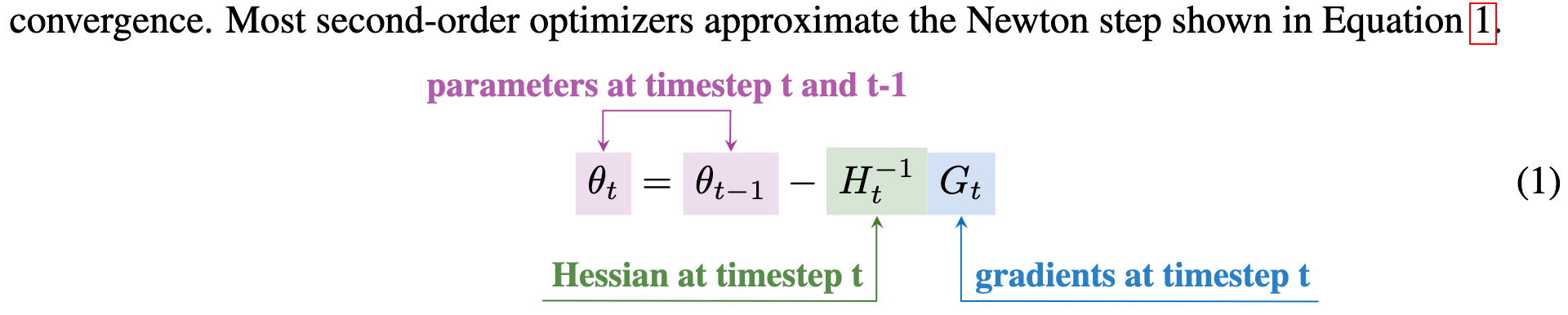
But the actual Hessian matrix is of size num_parameters x num_parameters, which is too big and expensive to compute. So we approximate it by pretending it’s diagonal (c.f. Adam and friends) or, sometimes, with a more algorithm.
This paper introduces an inverse Hessian approximation that’s cool because it doesn’t require computing any matrix inverses. Similar to Shampoo, it pretends the Hessian matrix decomposes into separate matrices for each layer and maintains an approximate Kronecker factorization of the Hessian. But instead of just doing this via a moving average of gradient matrix products, it does updates that look more like computing the elements of a Neumann series.

I (and presumably many others) have tried to avoid the inverse here using Neumann series, but it’s hard to get around the constraint that the preconditioning matrices have norms less than one. They solve this by dynamically adjusting the β parameters based on the current Frobenius norms. Computing these norms adds some overhead, but less than any of the matrix products.

With this constraint addressed, the derivation is pretty straightforward. They just observe that you can rewrite the Shampoo update using a recurrence relation with an auxiliary matrix,


and then get rid of the matrix exponent using the binomial theorem. And…that’s it. It’s as simple as you’re ever gonna get in an optimization paper.

They get better accuracy than SGD and Adam across various benchmarks by just porting the hparams from SGD via simple conversion formulas. They also only update the preconditioning matrices every 50 iterations, so that the overhead is small enough to stay within ~10% of SGD’s runtime.

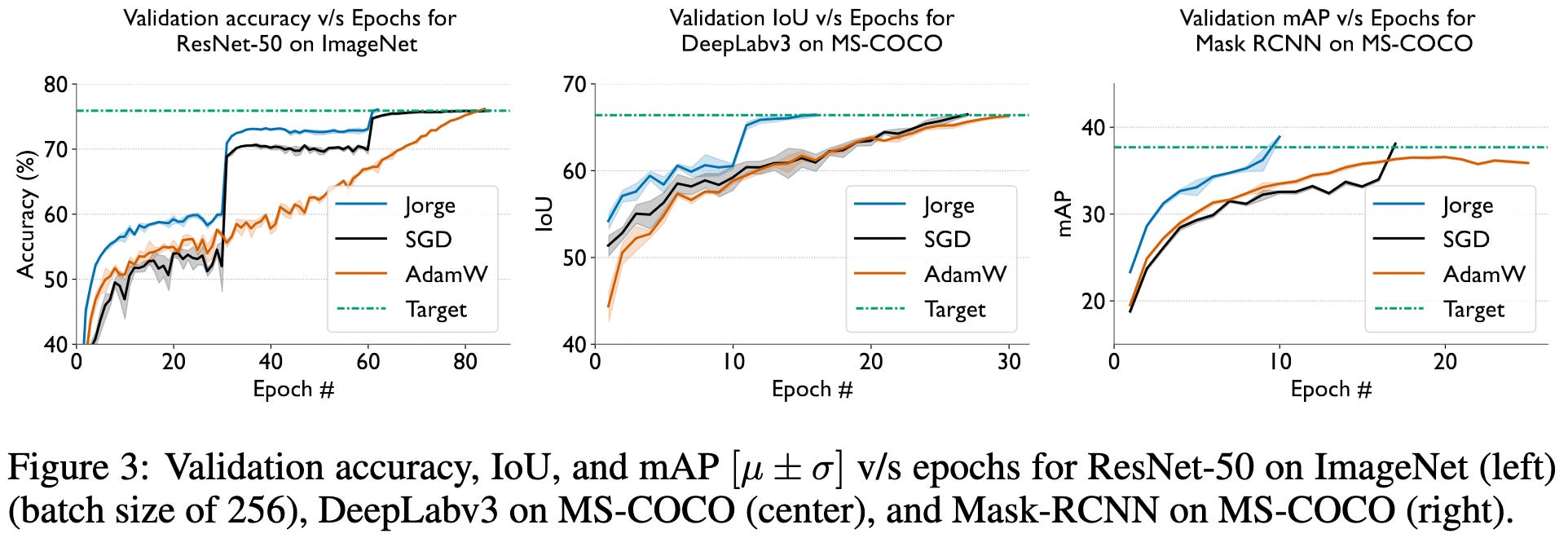
If you tune the length of the training to exploit the faster convergence, their method can improve time-to-accuracy significantly.


I’m unusually optimistic about this optimizer. There will be a bunch of questions about how to get it to scale when parameter matrices are sharded, but I buy that a) second-order optimizers can be a win if you get the systems side right, and b) the simplest-possible second-order optimizer without matrix inverses should be especially promising.
SpecTr: Fast Speculative Decoding via Optimal Transport
They do faster speculative decoding for low-batch-size LLM inference without messing with the sampling distribution.

If you’re not familiar with speculative decoding, it basically just exploits the observations that:
LLM inference at low batch sizes gets horrible utilization, but
you get better utilization if you generate several tokens at once.
The problem is that you normally can’t generate multiple tokens at once because each token generation needs to condition on the previous output. So what speculative decoding does is:
generate a sequence of proposed tokens from a small helper model, and
have the main model generate the conditional distributions for all these tokens at once as if the earlier proposed tokens were part of the output.
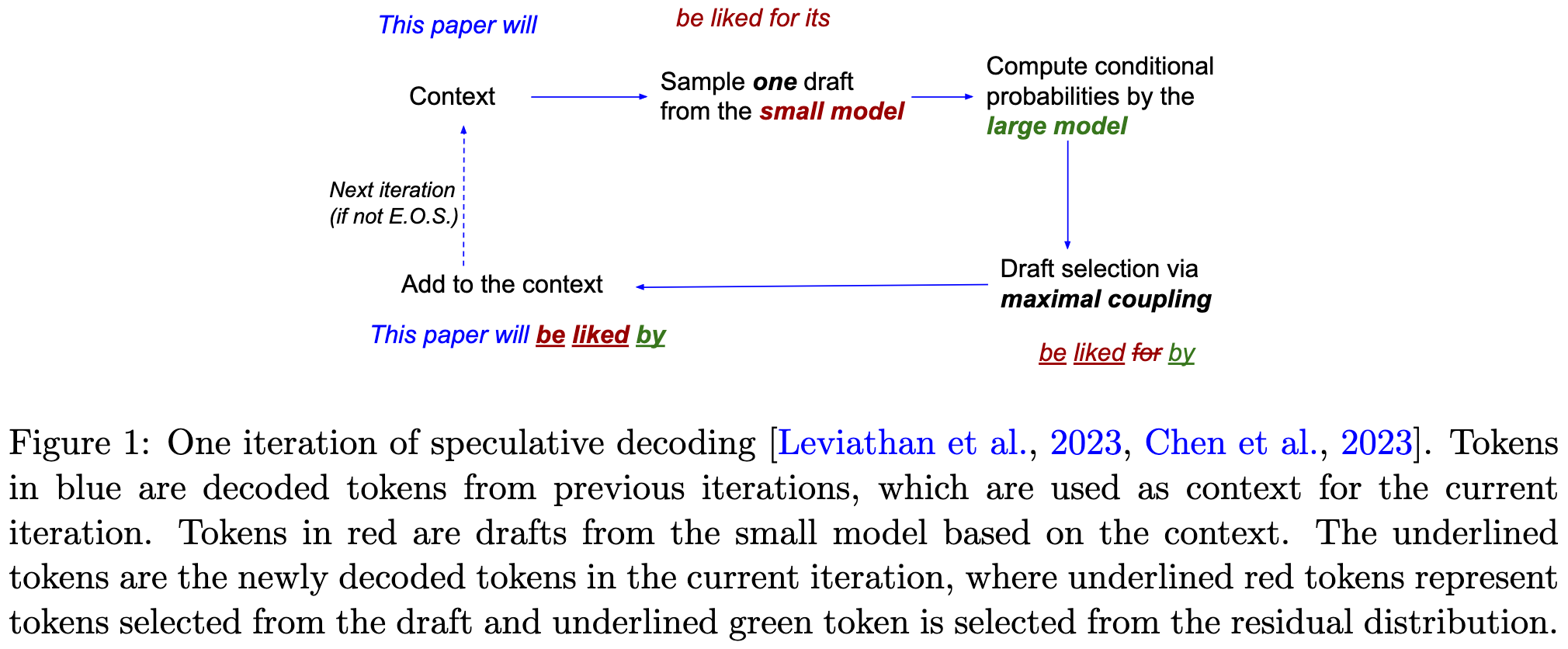
You then have both the true model and helper model’s conditional probabilities for each token and you can rejection sample to get the same math as just using the main model. If the helper model’s distribution matches the main model well, you reject infrequently and you can keep a long prefix (or all) of the proposed tokens.

That’s regular speculative decoding. What this paper asks is, “what if we sampled multiple proposed sequences from the helper model at once?”

They do a ton of math to make this work and prove stuff about it, but essentially they get to accept longer prefixes on average while still preserving the sampling distribution.


I’d have to stare at this a lot longer to really understand it, but this looks like a win in the low inference batch size regime.
The Synergy of Speculative Decoding and Batching in Serving Large Language Models
They point out that the amount of speculative decoding you try to do should vary based on how many queries you have batched at a given moment. This is because running forward passes for more tokens has increasing marginal cost as you approach being compute-bound.
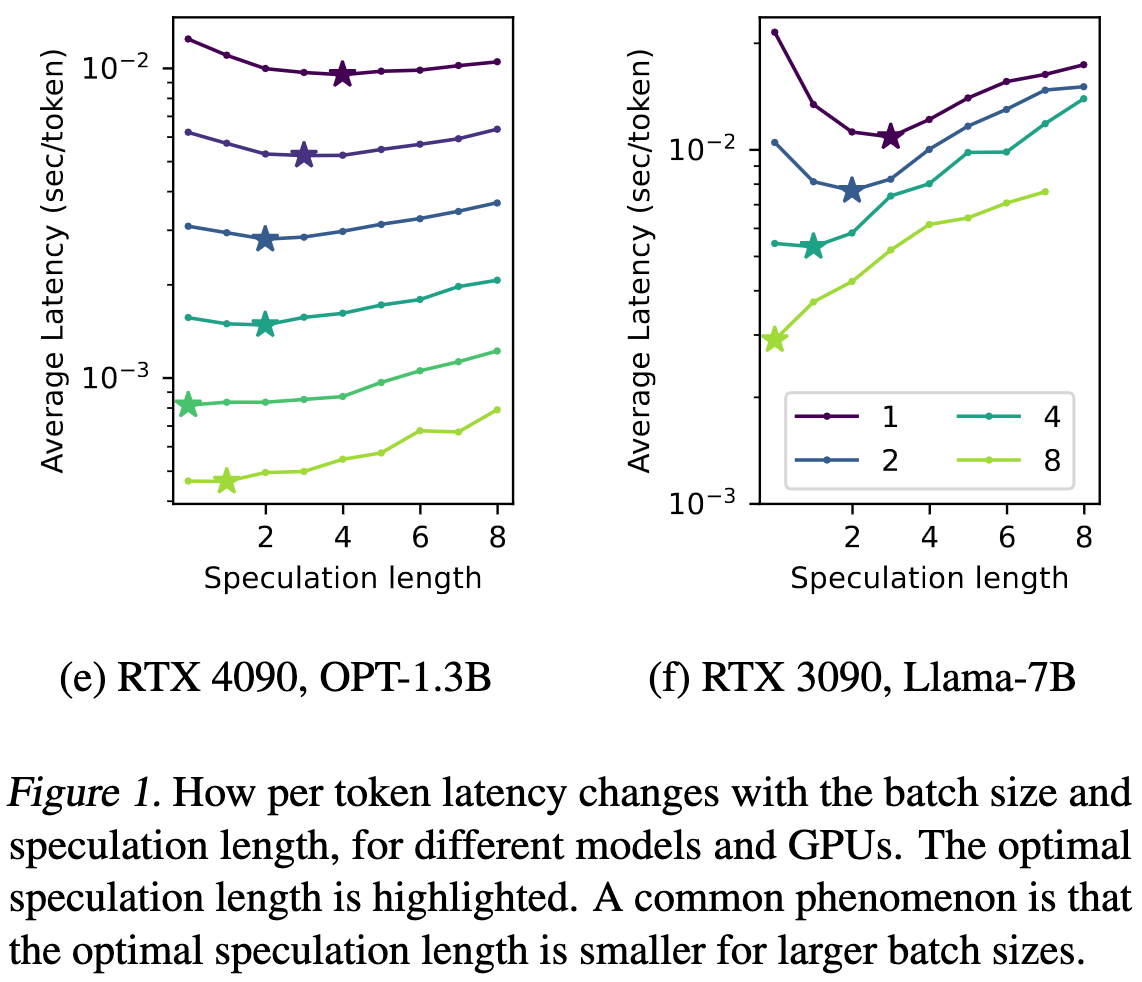
Exploiting this observation can reduce your average latency a bit for certain traffic patterns.

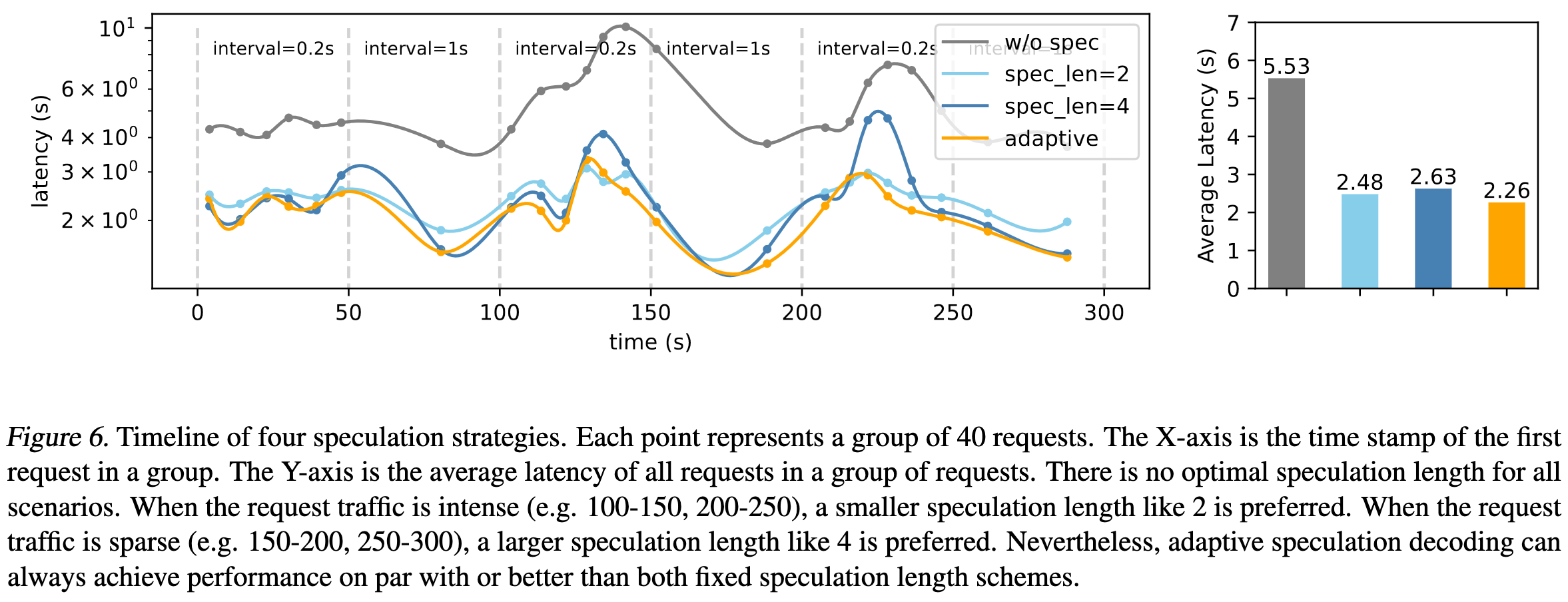
I’m actually surprised how little difference this makes, but that’s not a criticism. Thorough experiments with trustworthy conclusions are much more important than how much the number changes. Plus this paper improved by thinking about what the ideal inference system should do.
Position Interpolation Improves ALiBi Extrapolation
Normally AliBi linearly decays the attention between tokens in proportion to the absolute difference in their positions within the sequence. When trying to get a model to use a longer sequence length than it was trained on, they propose to instead decay attention values based on the relative difference in token positions, where “relative” means normalizing by sequence length.
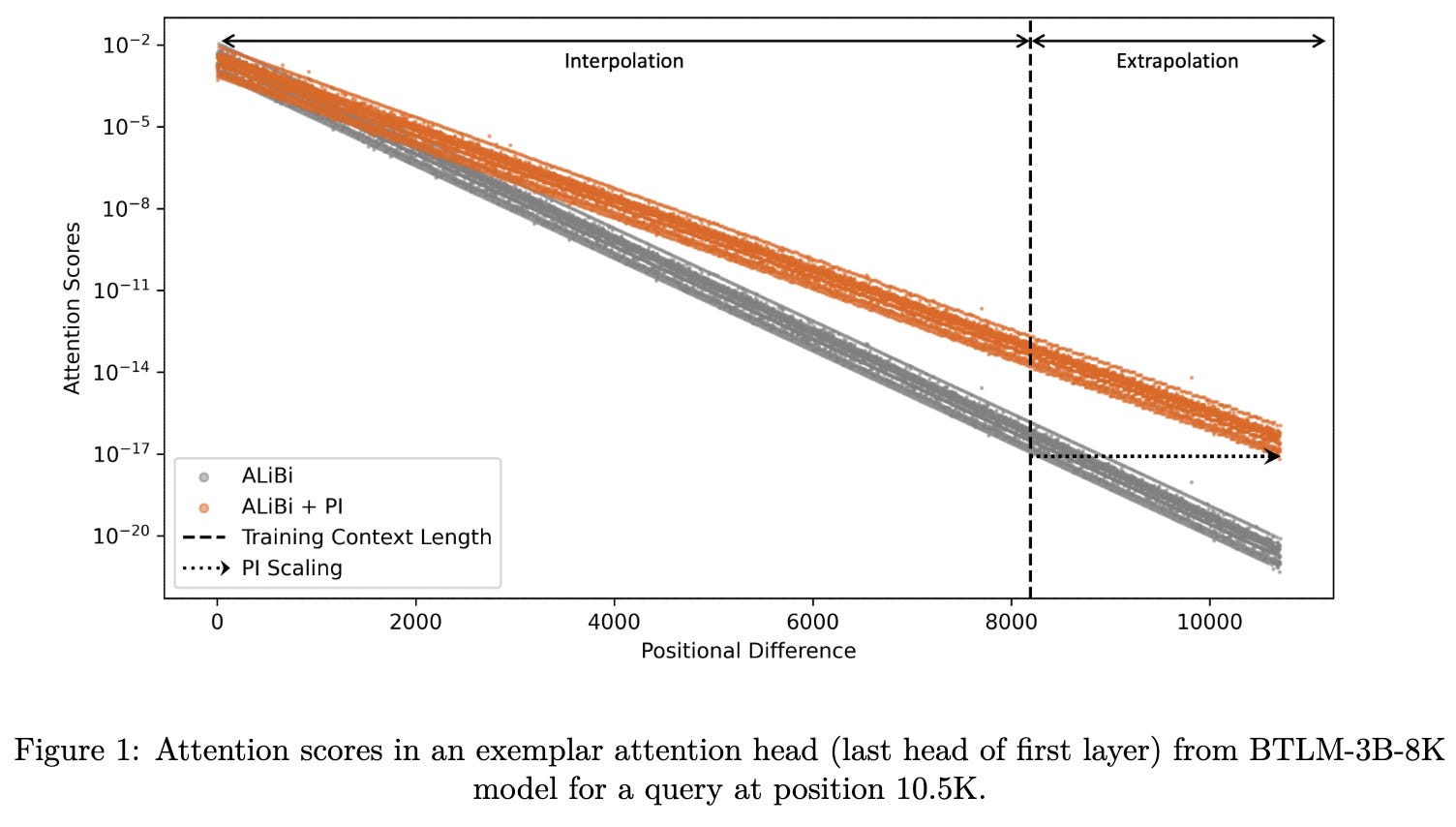
This simple change can improve length generalization significantly.

Towards End-to-end 4-Bit Inference on Generative Large Language Models
They do 4-bit inference with 4-bit matmul kernels that quantize and dequantize before each matmul. This is more aggressive than typical 4-bit quantization that just keeps the weights in 4 bits at rest and upcasts to bf16 before doing any math.

The quantization is mostly just regular GPTQ / linear quantization, but they handle outliers intelligently:
First, they use a calibration set of samples to identify which columns have outliers features and handle these separately.
Secondly, they rearrange the weight matrices so that these columns are contiguous and get quantized last. The “last” aspect is important because GPTQ tends to accumulate more error in later columns; but if these columns aren’t getting quantized at all, we dodge our worst-case behavior entirely.
Third and finally, they use 8-bit quantization for the down projection linears since these have the most variance.

This approach manages to get a 2.5x speedup vs fp16 inference on LLaMA 2 70B with 8-bit quantization and a 3x speedup with 4-bit inference. These are pretty close to the ideal speedups. They do need pretty large matrix products to hide the quantization and dequantization overheads though.
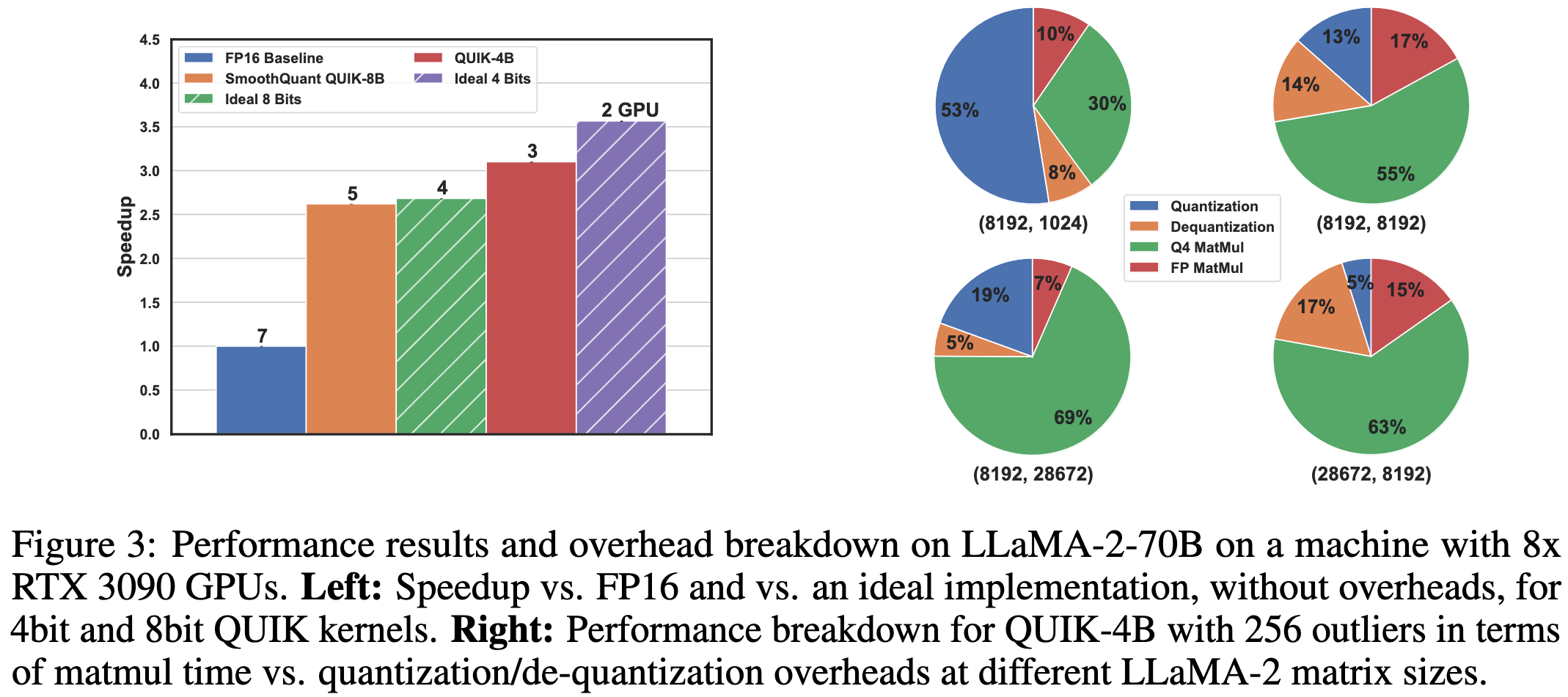
They don’t quite preserve the accuracy of an fp16 model, but they get closer than various baselines.

Microscaling Data Formats for Deep Learning
Regular old linear quantization with 8-bit power-of-two scale factors just kinda works during training.

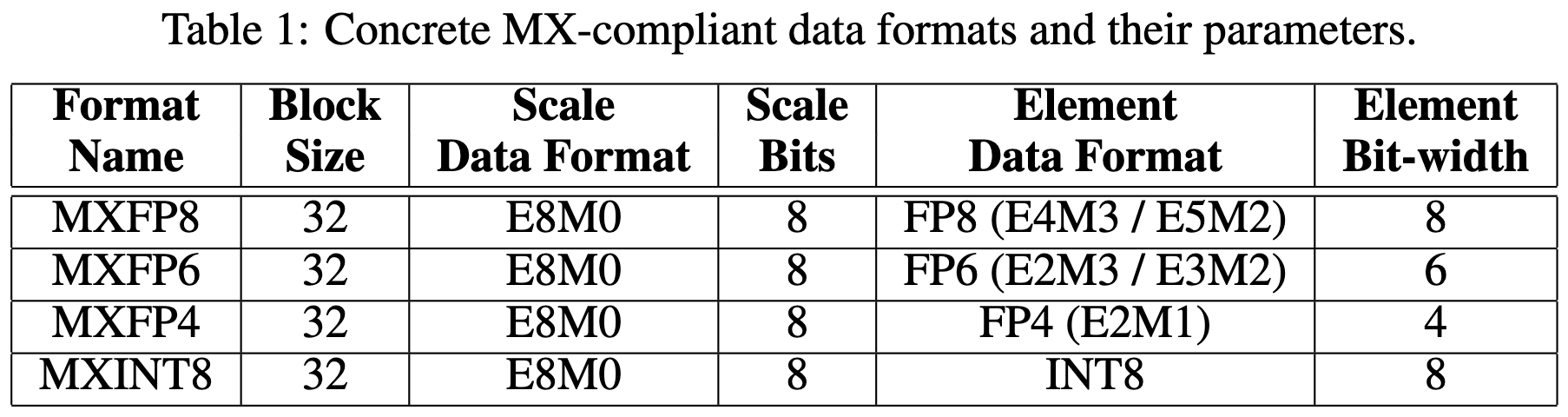
By “just kinda works,” I mean you can quantize all the matmul inputs with ~0 accuracy loss.
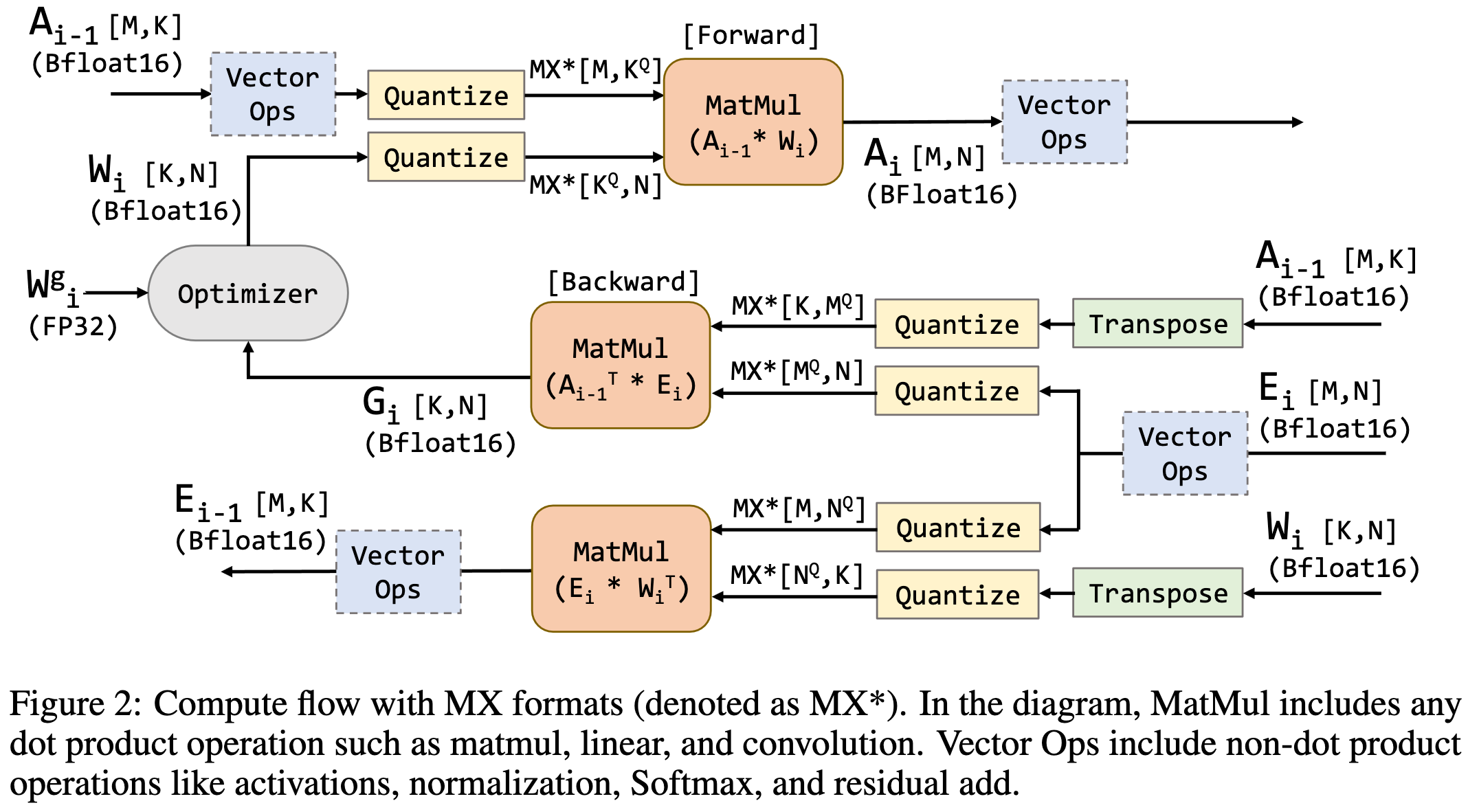


Basically, if we had hardware support for block-specific scale factors, we could just do everything with 8-bit (or even narrower) formats. This isn’t news for inference and is weaker than the unit scaling claims for training, but it is new to see that simple quantization just works out of the box with no special math or initialization.
FP8-LM: Training FP8 Large Language Models
They do a bunch of careful numerical changes to get more of the training process to work in fp8. First, they track tensor-specific scale factors for the gradients to keep them from overflowing or underflowing. When they detect an overflow, they scale down by a factor of two, and otherwise gradually increase the scale slightly at each iteration.
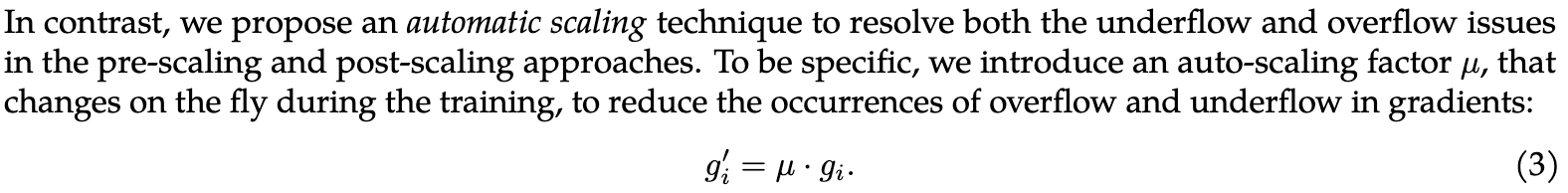
Before allreducing gradients, they allgather the scale factors and have every device use the smallest scale factor. They then undo this scaling before feeding the gradients into the optimizer. This lets them allreduce (and allgather) in fp8, saving 2x communication vs bf16.

They also save some space in the optimizer. Instead of having 4 bytes for each of the {master weight, gradient, momentum, variance} tensors in Adam, they use fp8 gradients, fp8 momentums, 16-bit variance estimates, and 16-bit master weights. Importantly, the 16-bit values have associated scale factors, rather than just using the default fp16 range. You can do math to find the effective step sizes at which 16-bit master weights will break (i.e., a learning rate that yields steps around 2^-(num_mantissa_bits + 1) as large as the weights will go badly; even 24-bit master weights are often sketchy for finetuning), but this is a nice savings if your steps are large enough.
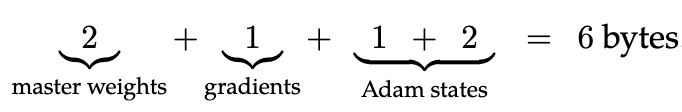
They also propose to shard entire tensors across devices instead of slices of tensors. This scares me from a complexity and interconnect utilization perspective, but does give a clean story for how to handle all the scale factors.

Even with all these space savings, they still get relatively little model quality loss compared to using bf16 for everything.


They also make training go ~30% faster, which likely yields a time-to-accuracy improvement:

It looks like mostly-fp8 training is going to become a standard practice within the next year or so, at least for the big industry labs.
Emergent Mixture-of-Experts: Can Dense Pre-trained Transformers Benefit from Emergent Modular Structures?
They use the observation that a set of sparsely-gated MoE FFNs can be seen as a big activation-sparse matmul, similar to MegaBlocks. But instead of using this to define an MoE module at the start, they train a regular network and then approximate it using an MoE router. To do this, they cluster the columns of the first linear, use the centroids of each cluster as routing weights, and then only apply the rows from the second matrix associated with the chosen cluster’s features. You can also look at this as doing an approximate matrix product using vector quantization.

If you apply this technique to a pretrained model before finetuning, you can get more accuracy lift than both the dense model and at least one conventional MoE baseline.
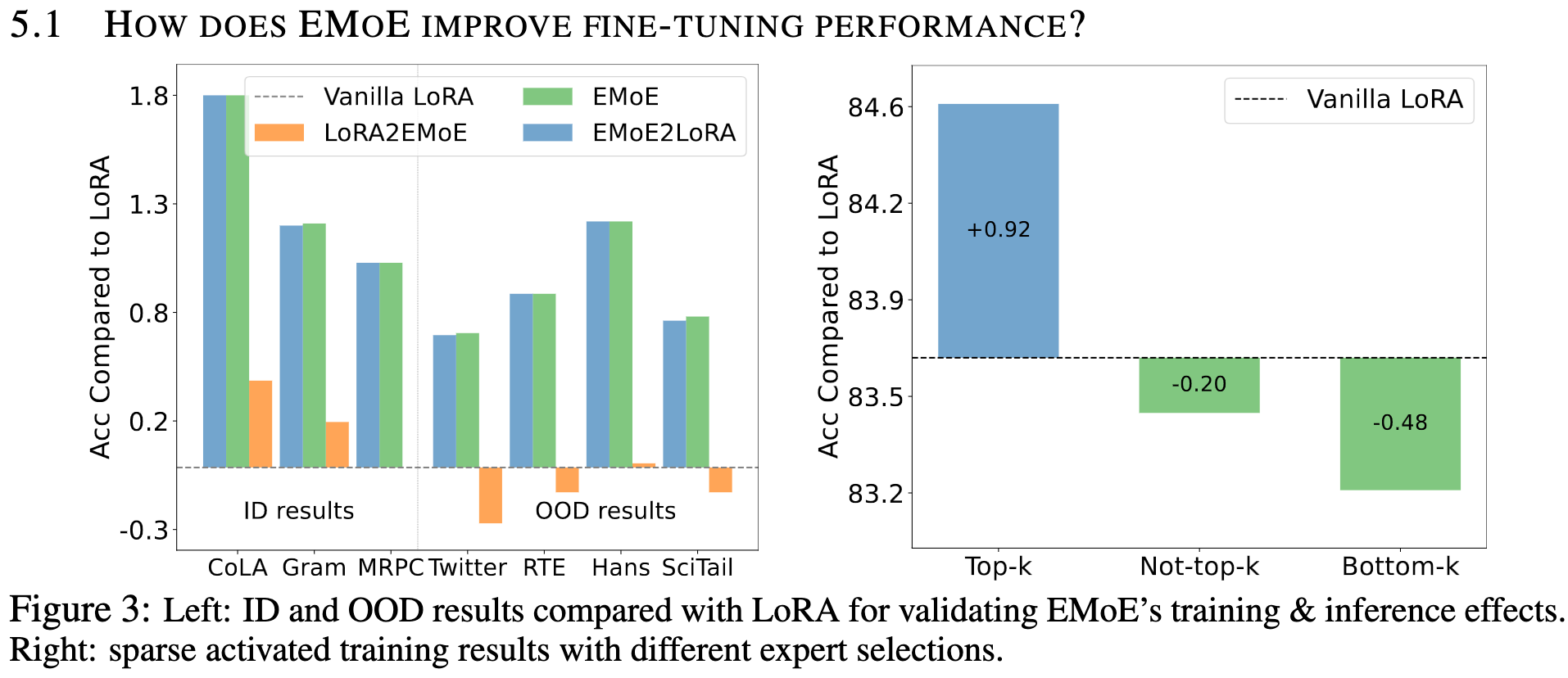
This is especially interesting to me because I’ve gotten related negative results. Namely, if you add the inner products with the routing weights to the outputs (so that you’re doing residual vector quantization instead of their regular vector quantization), it’s not quite as good as Switch-style MoE routing. But this was with the MoE routing there from the start instead of added at the end. It wouldn’t be surprising if imposing the block sparse structure at initialization isn’t as good as “pruning” to a block sparse structure, even if the pruning happens all at once.
In-Context Pretraining: Language Modeling Beyond Document Boundaries
Why concatenate random documents when you can concatenate related documents?

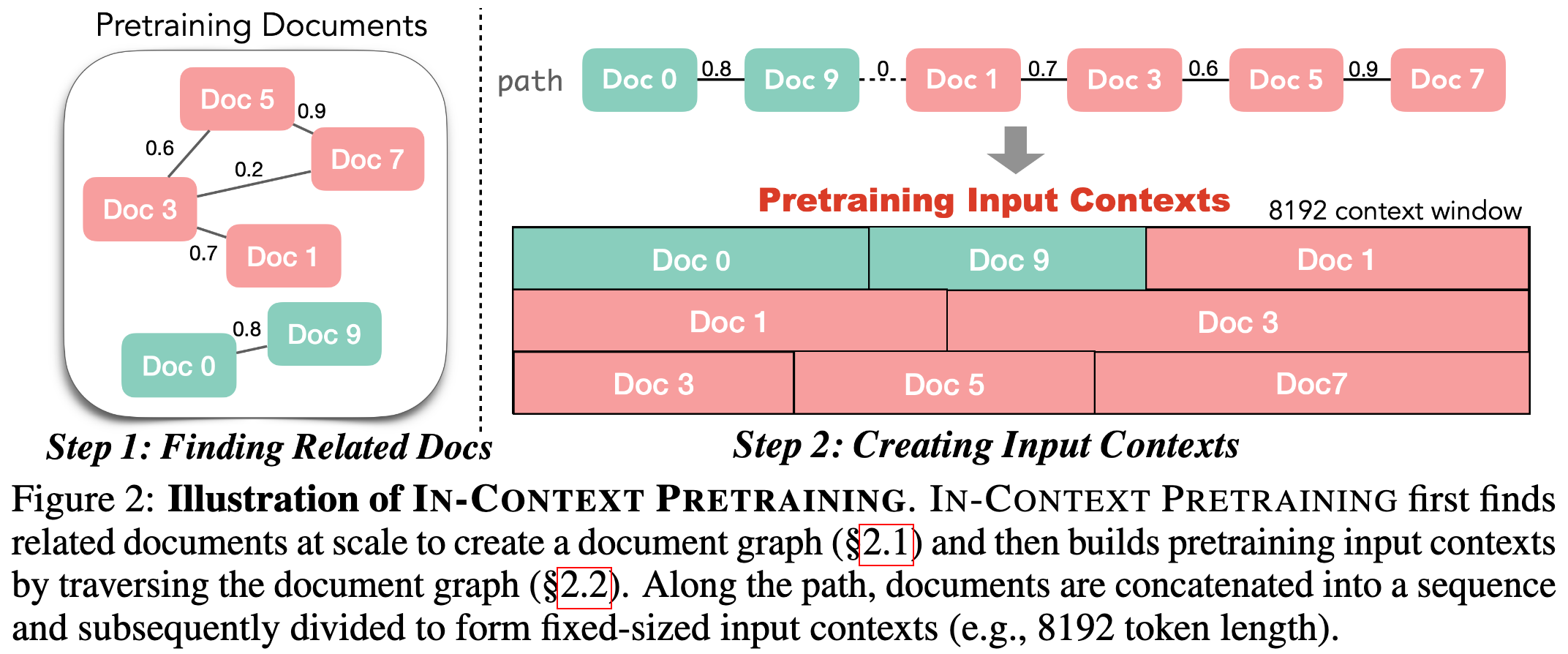
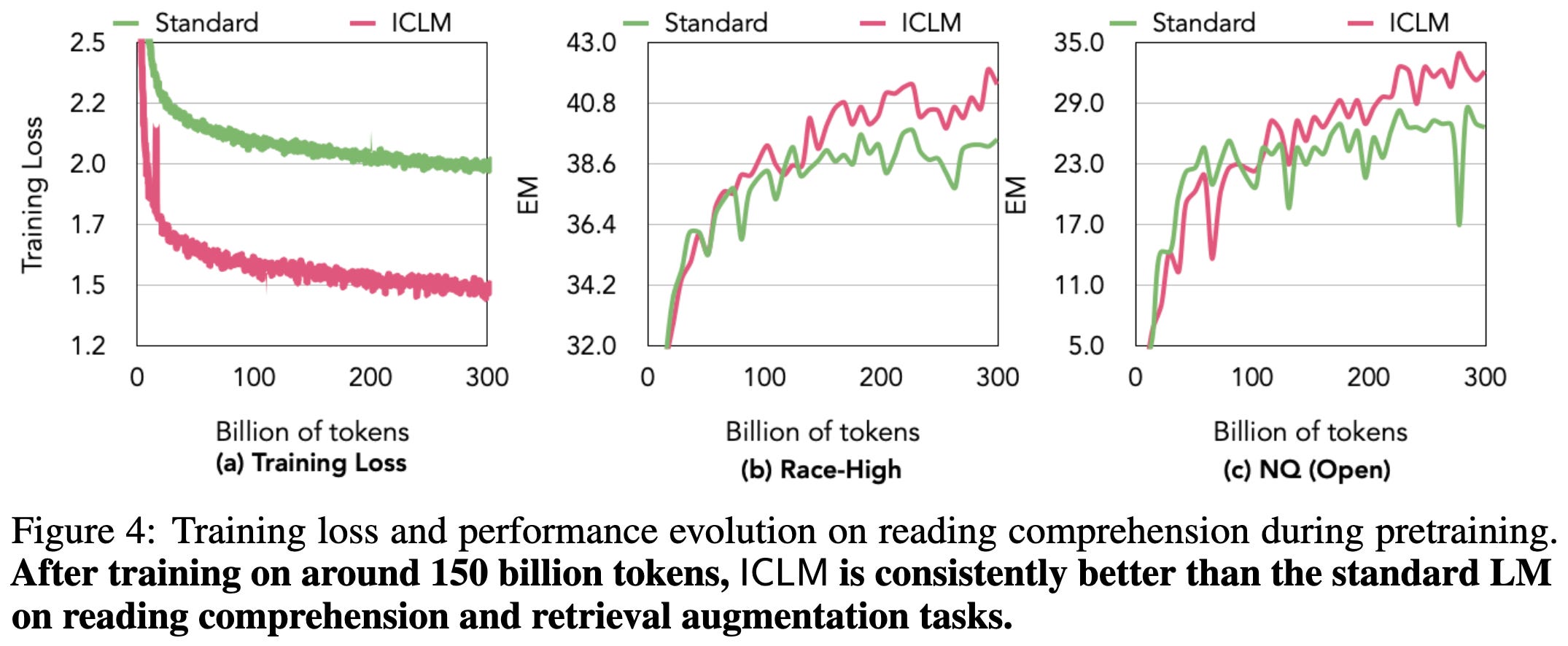
Turns out this improves pretraining, as measured by eval perplexity on randomly concatenated documents after 300B pretraining tokens.

It also improves downstream metrics, including making retrieval augmentation work better sometimes.


Closed-Form Diffusion Models
I’d need to stare at this a lot longer to grok it, but they devised a decent diffusion-based sampling procedure that needs no training, works pretty well, and runs faster on a CPU than a neural net-based diffusion model does on GPU.


They also derived a closed-form solution for the optimal diffusion procedure under Gaussian noise in terms of test error, and argue that most diffusion models generalize because they have a smoothness bias and don’t recover this optimal solution.

TLM: Token-Level Masking for Transformers
They propose to randomly drop whole tokens in each attention head.

This can work better than other attention masking schemes.
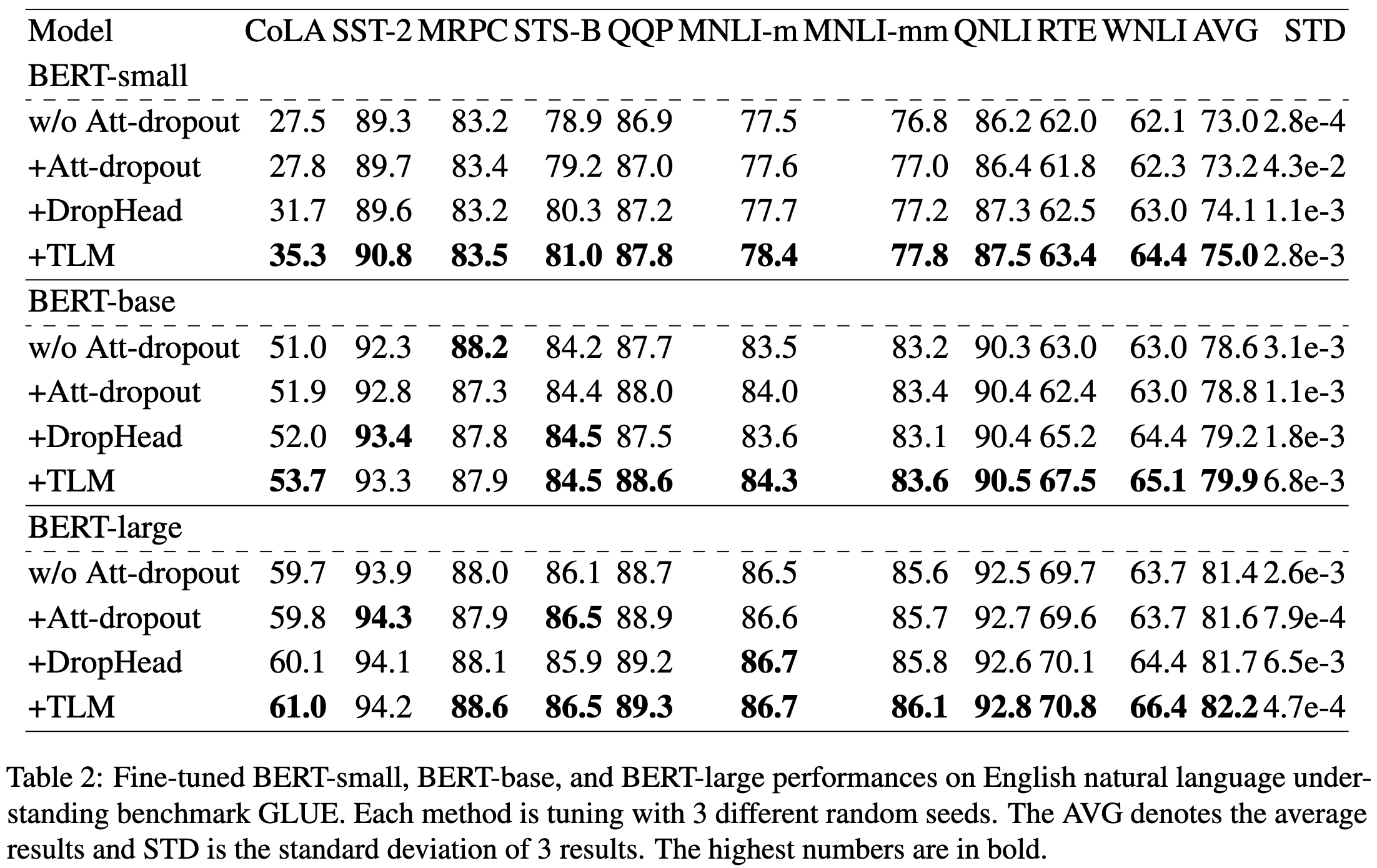
You probably don’t want to use more than one of these schemes though. As is common with regularization, you get diminishing returns from composing multiple methods.

Battle of the Backbones: A Large-Scale Comparison of Pretrained Models across Computer Vision Tasks
They did a big ol’ bake-off between different pretrained vision models. They summarize their main findings well so I won’t repeat them:

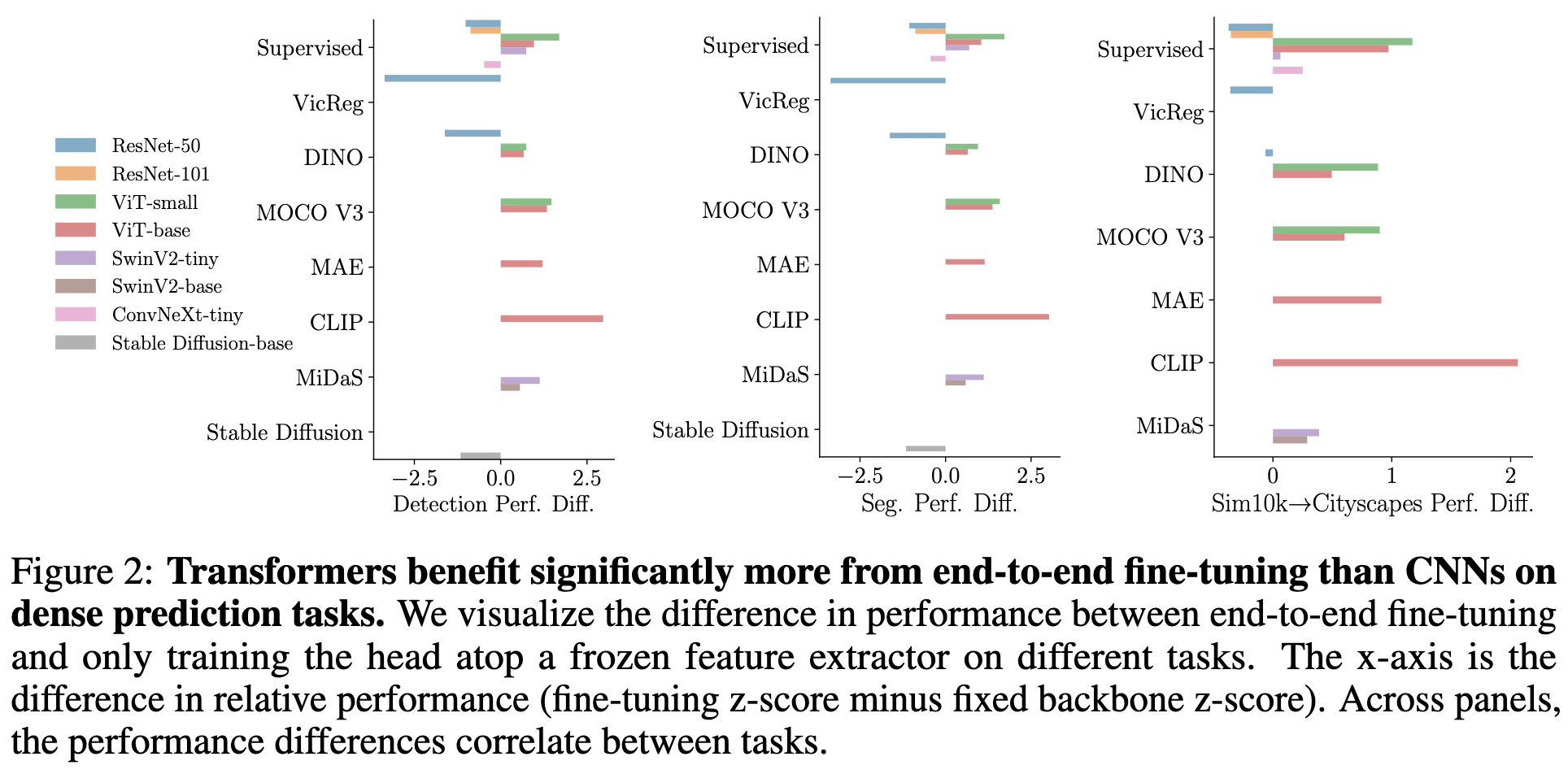
They also have recommendations for practitioners regarding which models you should probably use at different sizes and for different tasks.


Matryoshka Diffusion Models
Their U-Net takes in multiple resolutions at once and pools information across them to denoise them all jointly.



This approach, along with focusing much of the training budget on lower resolutions, gets them a much better training steps vs image quality tradeoff than various baselines (theirs is “MDM”).

CapsFusion: Rethinking Image-Text Data at Scale
They observe that raw image captions are often noisy, but synthetic captions are vague and don’t capture world knowledge that may have been in the raw captions.


To get the best of both worlds, they propose a pipeline to combine raw and synthetic captions using ChatGPT. To avoid querying ChatGPT for their entire dataset, they just query it a million times and then finetune a LLama model to combine captions using the ChatGPT outputs.

Their improved captions yield significantly better models, as measured across a variety of benchmarks.
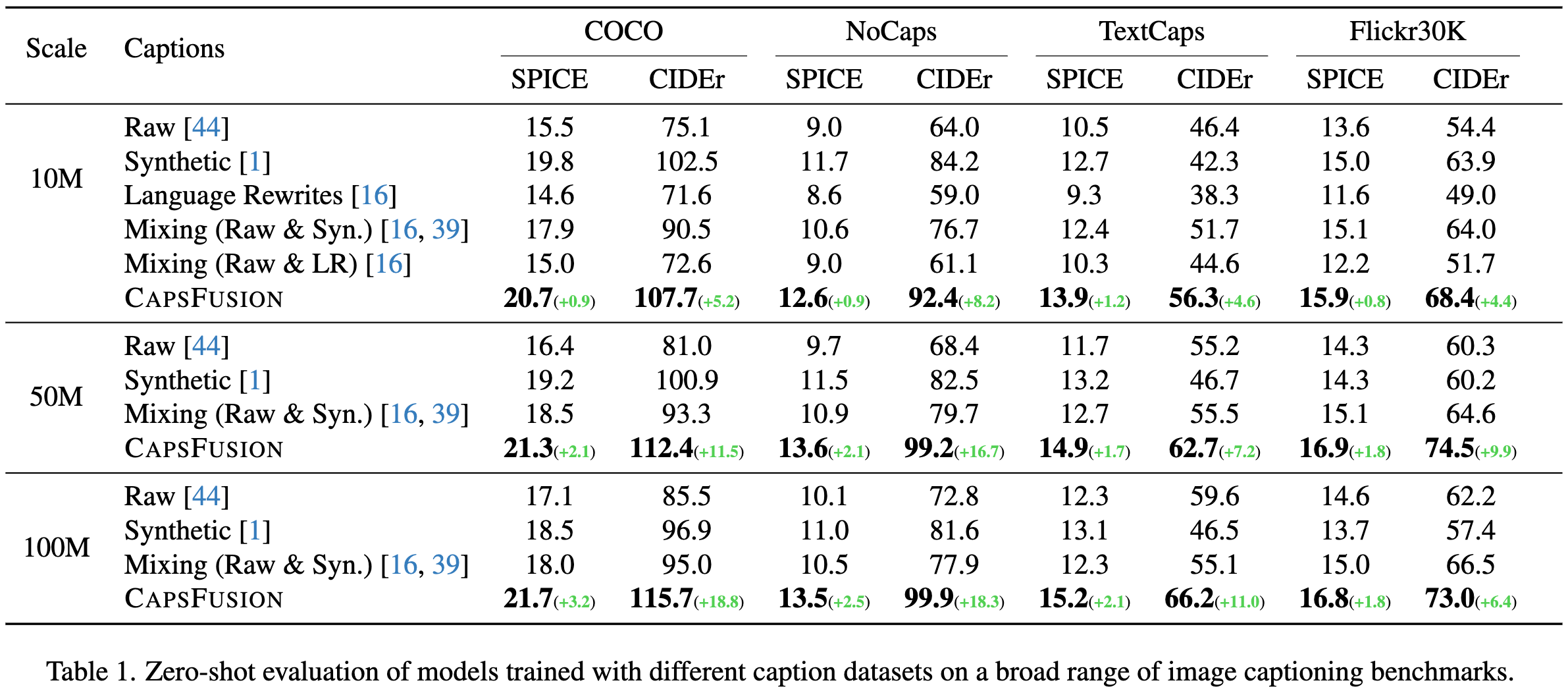
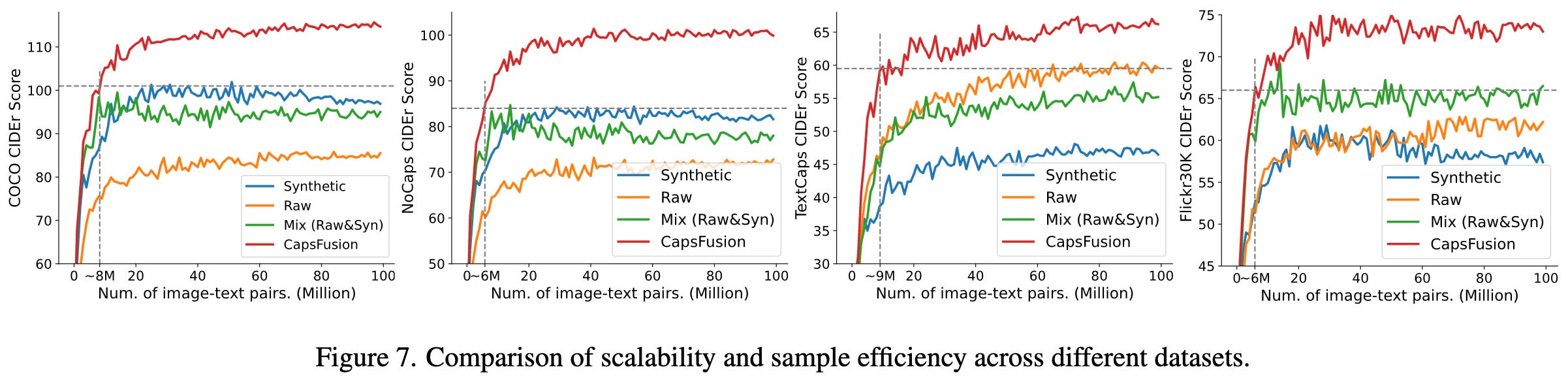

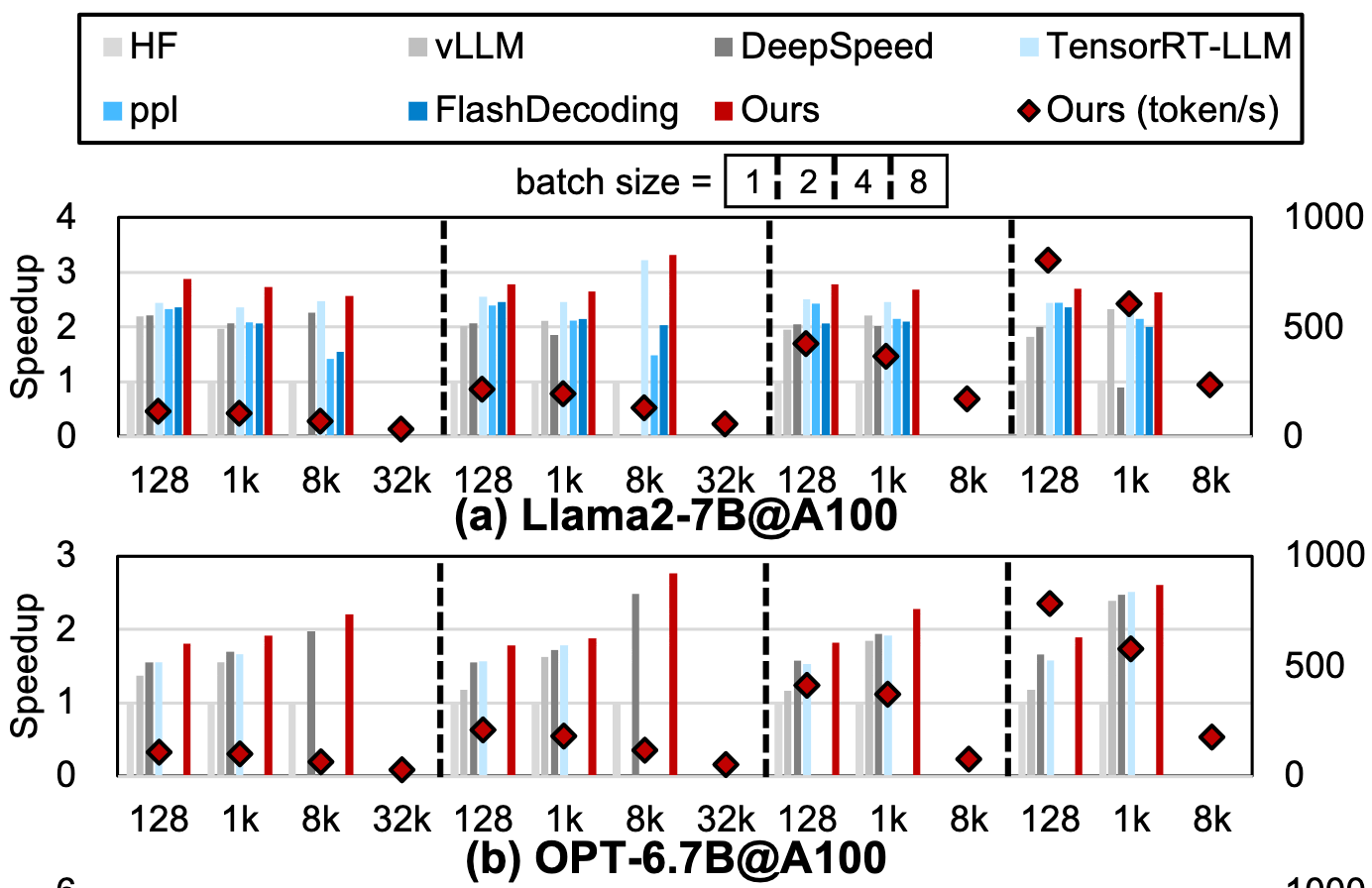
FlashDecoding++: Faster Large Language Model Inference on GPUs
They do faster transformer inference vs various baselines by making a few changes to the decoding logic.
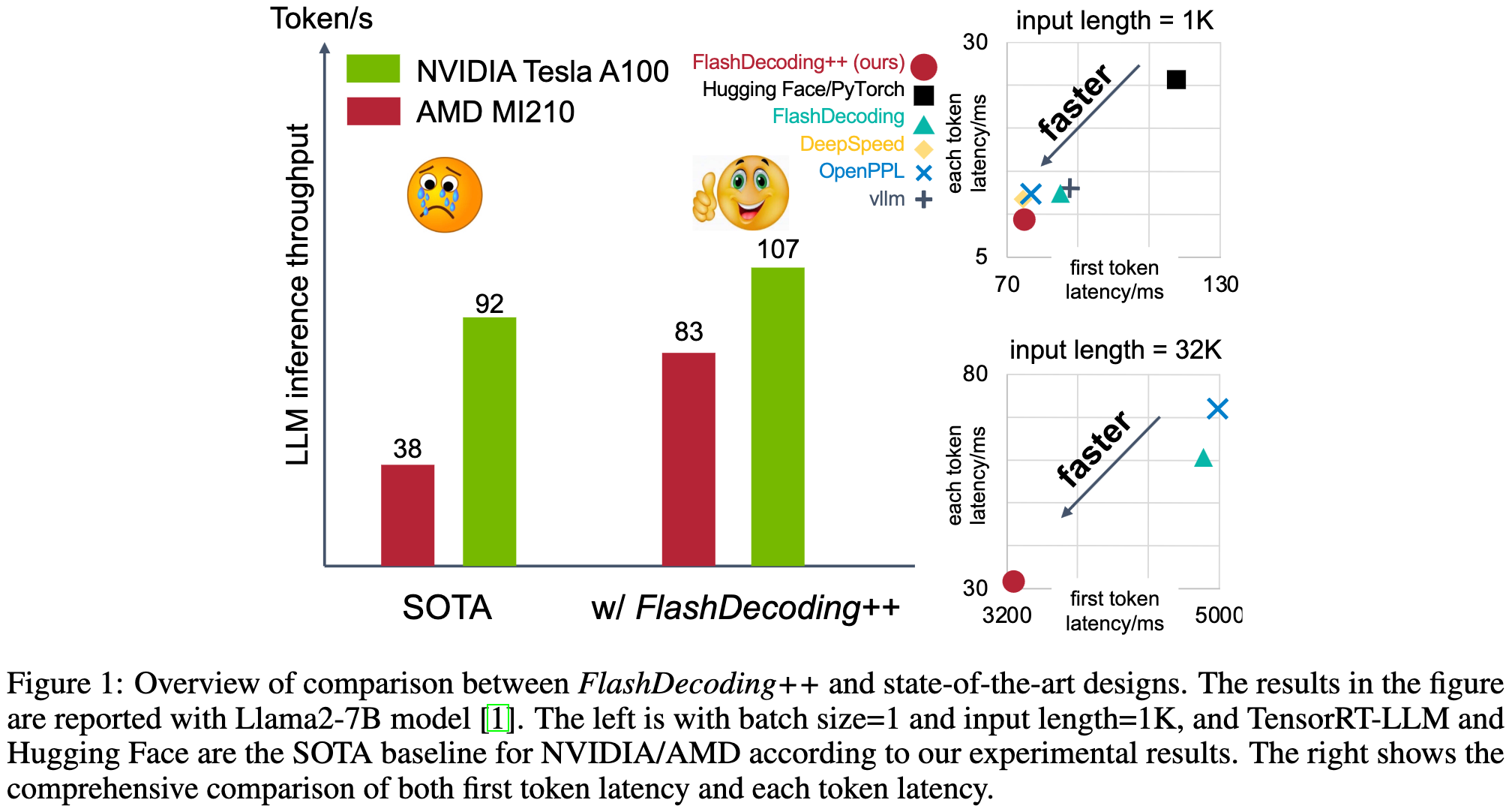
First, they use a single max exponent for the whole softmax instead of adaptively increasing it as successive tiles get processed. This exponent has to be set carefully, but you avoid some data dependencies this way. To ensure they preserve the math, they fall back to using a larger max if they detect an overflow.


To set this maximum value appropriately, they look at the empirical distributions of the softmax inputs.

They also get better utilization by writing kernels for matvecs (and skinny matmuls) that increase occupancy via smaller tile sizes + by software pipelining loads into a separate buffer.

They choose whether to use their kernels or other kernels at runtime based on some heuristics.

These optimizations together apparently yield large speed gains for both prefill and decoding.
ToolChain*: Efficient Action Space Navigation in Large Language Models with A* Search
Given some means of scoring intermediate and final outputs when iteratively querying an LLM, we can use classical AI algorithms like A* search to arrive at better answers.


This can work way better than other tree-based approaches, especially when you take into account runtime.
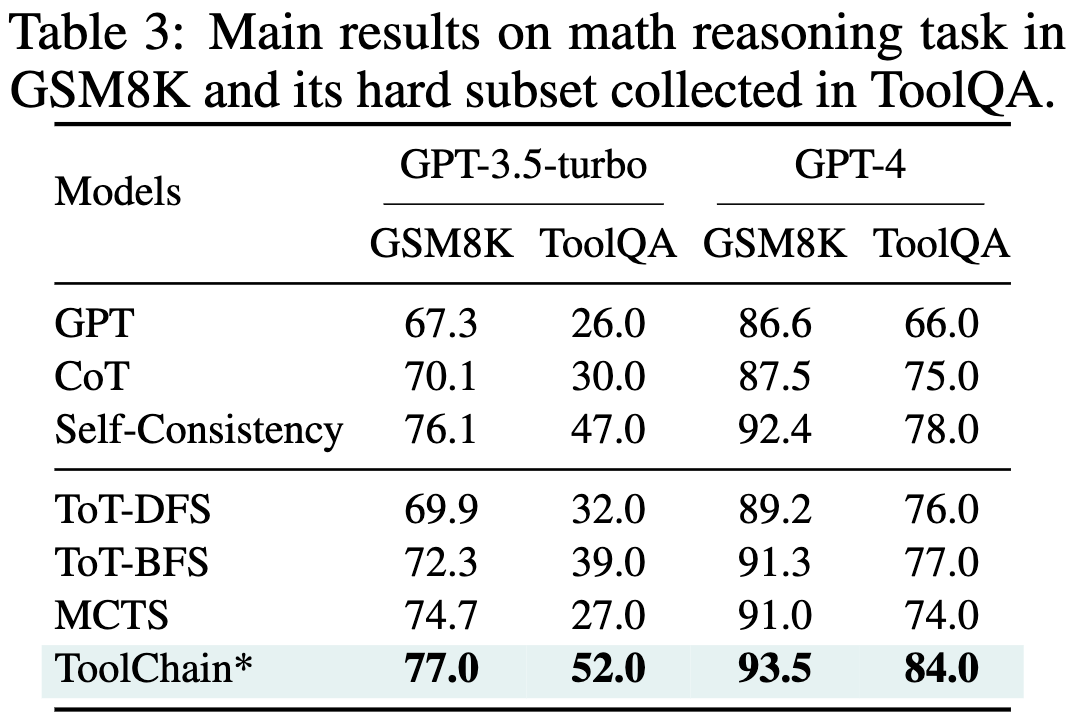
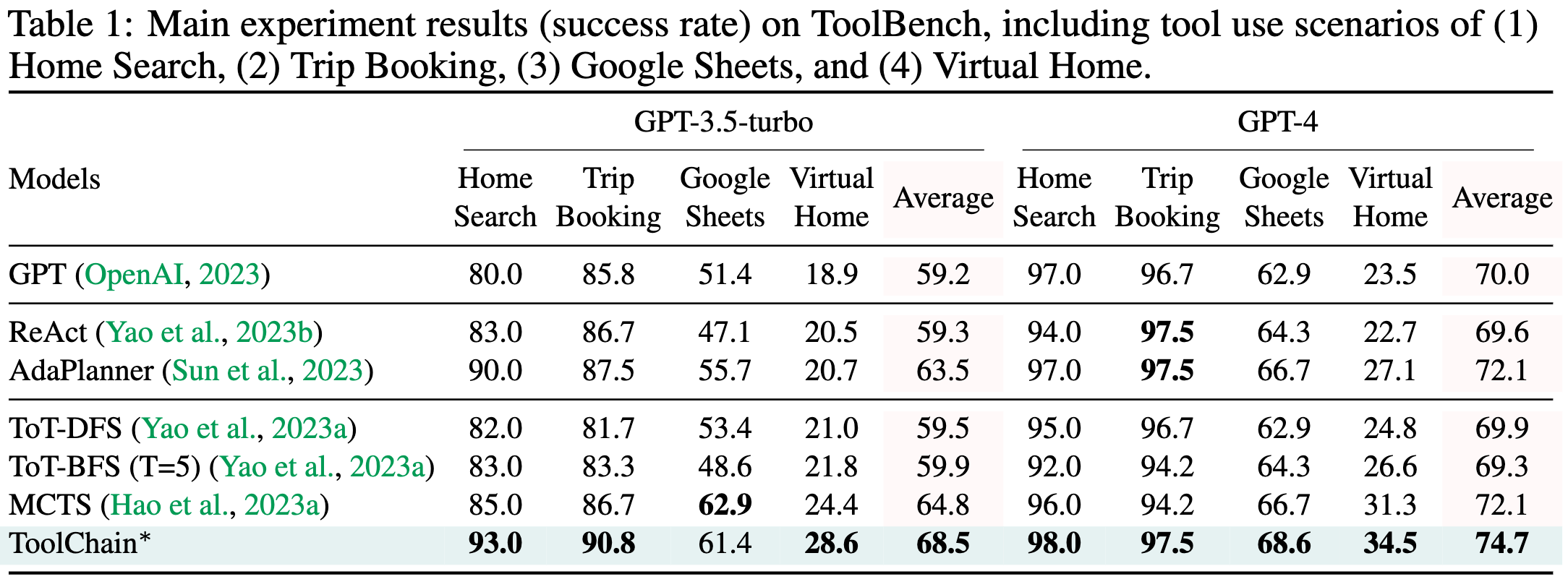

Mostly I think this is super interesting on a meta level, since it shows that:
Classical AI algorithms are getting relevant for mainstream AI again.
We’re having more success by carefully structuring our programs around LLMs, as opposed to, say, offering as little structure as possible and just having the LLM figure it out. This is good from a safety and interpretability perspective.