

2023-5-14 arXiv roundup: FrugalGPT, Inverse CLIP scaling, Embedding all the modalities
2023-5-14 arXiv roundup: FrugalGPT, Inverse CLIP scaling, Embedding all the modalities

This newsletter made possible by MosaicML.
An Inverse Scaling Law for CLIP Training
They find that larger CLIP models let you get away with training on fewer tokens per input, in the sense that they experience less accuracy degradation.
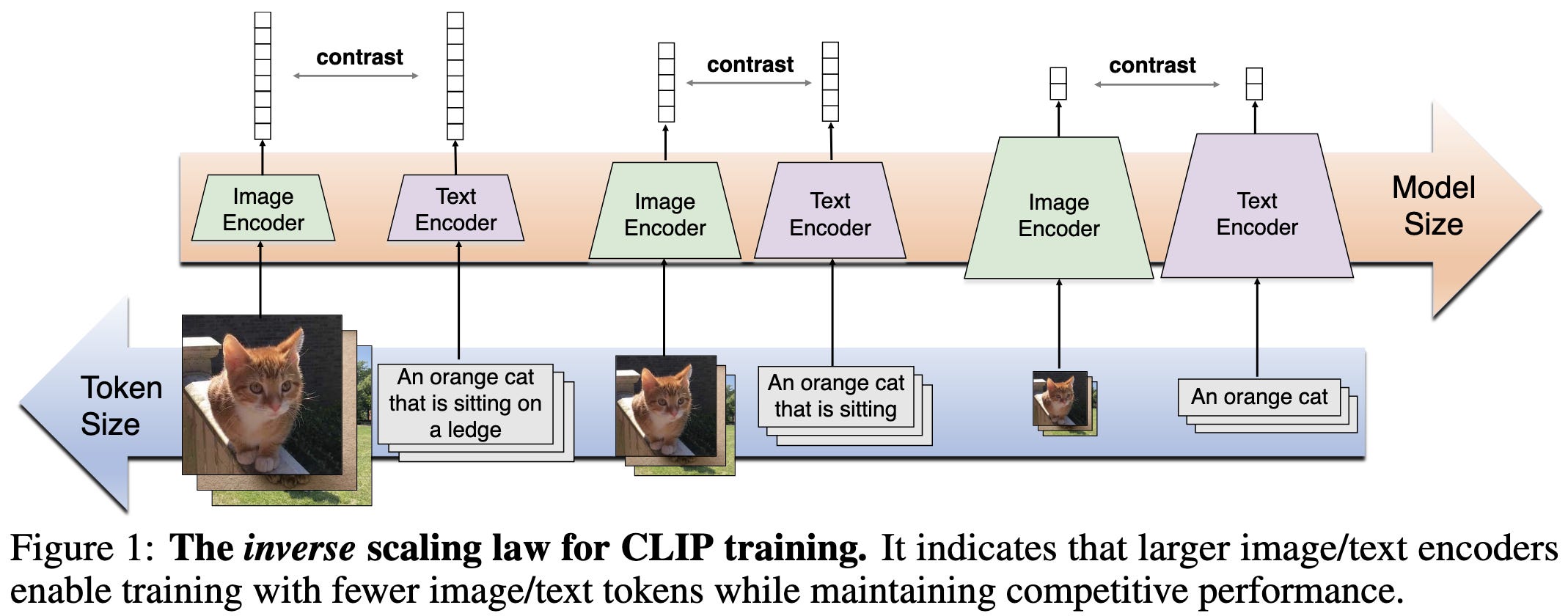
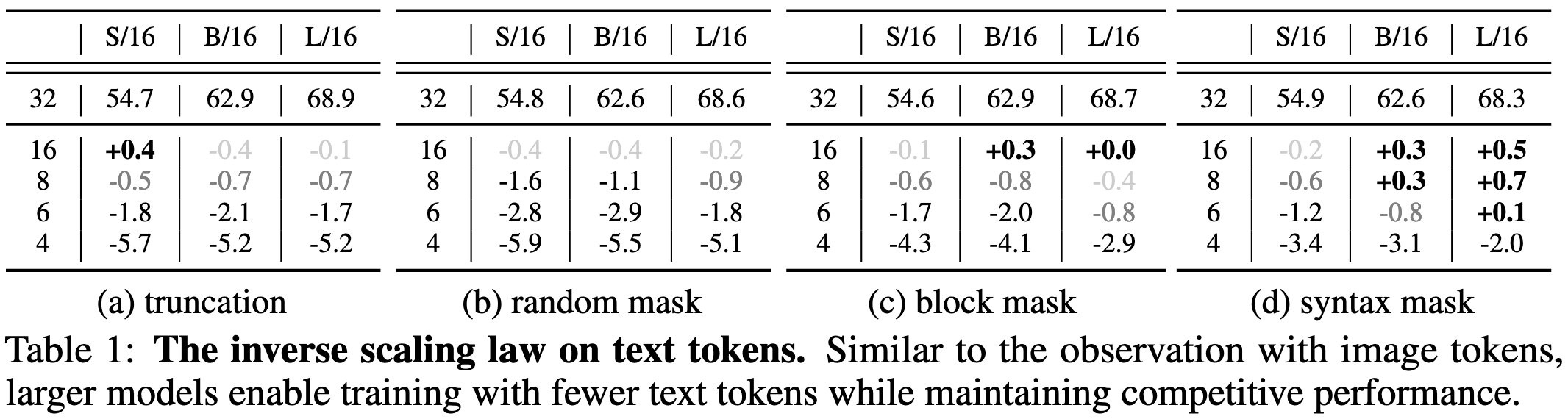
By “using fewer tokens”, we mean algorithmically removing some of the tokens in the input image and text. To remove image tokens, you can mask or resize the image in various ways. They use random masking in most cases.

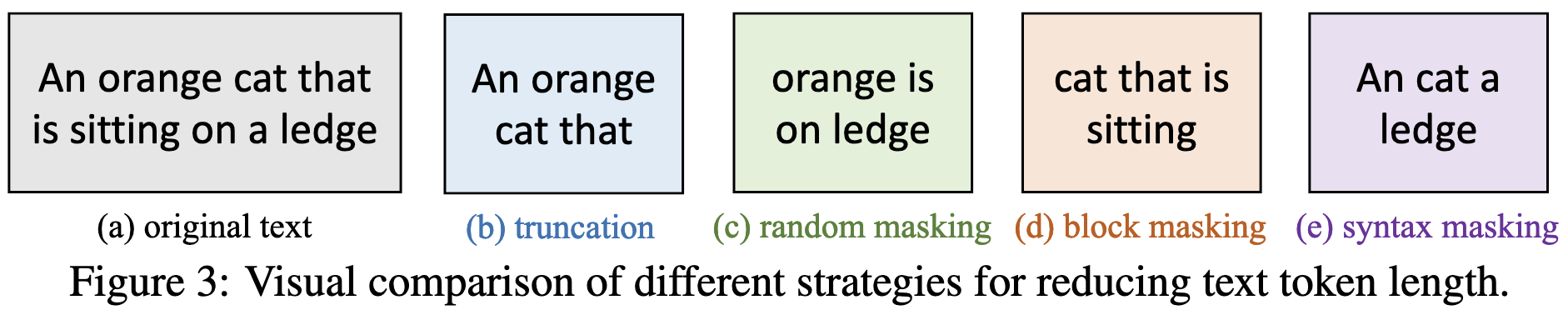
To remove text tokens, you can choose words to rip out using various heuristics.
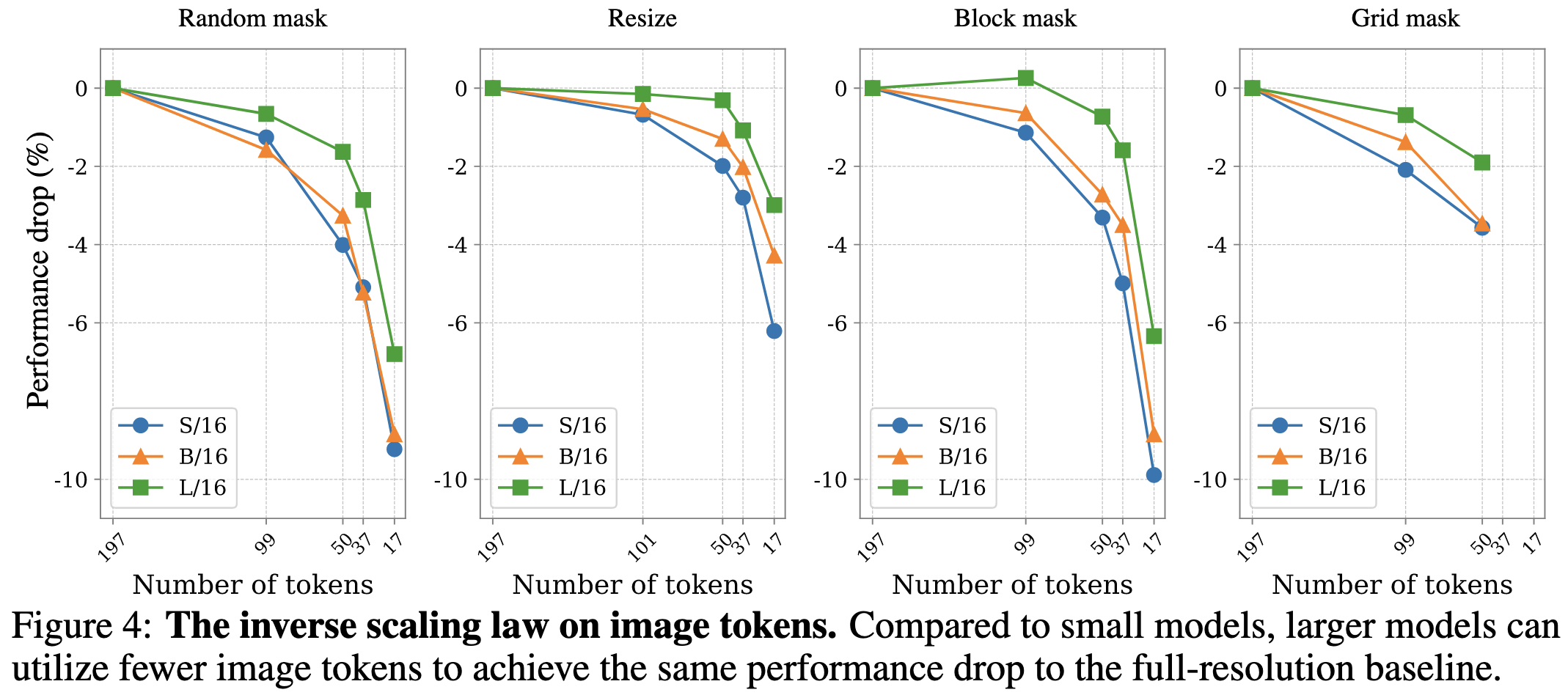
Their first result is that reducing image token count hurts larger models less. This seems to hold across a variety of different strategies for reducing the number of image tokens, as measured by ImageNet-1k zero-shot accuracy.
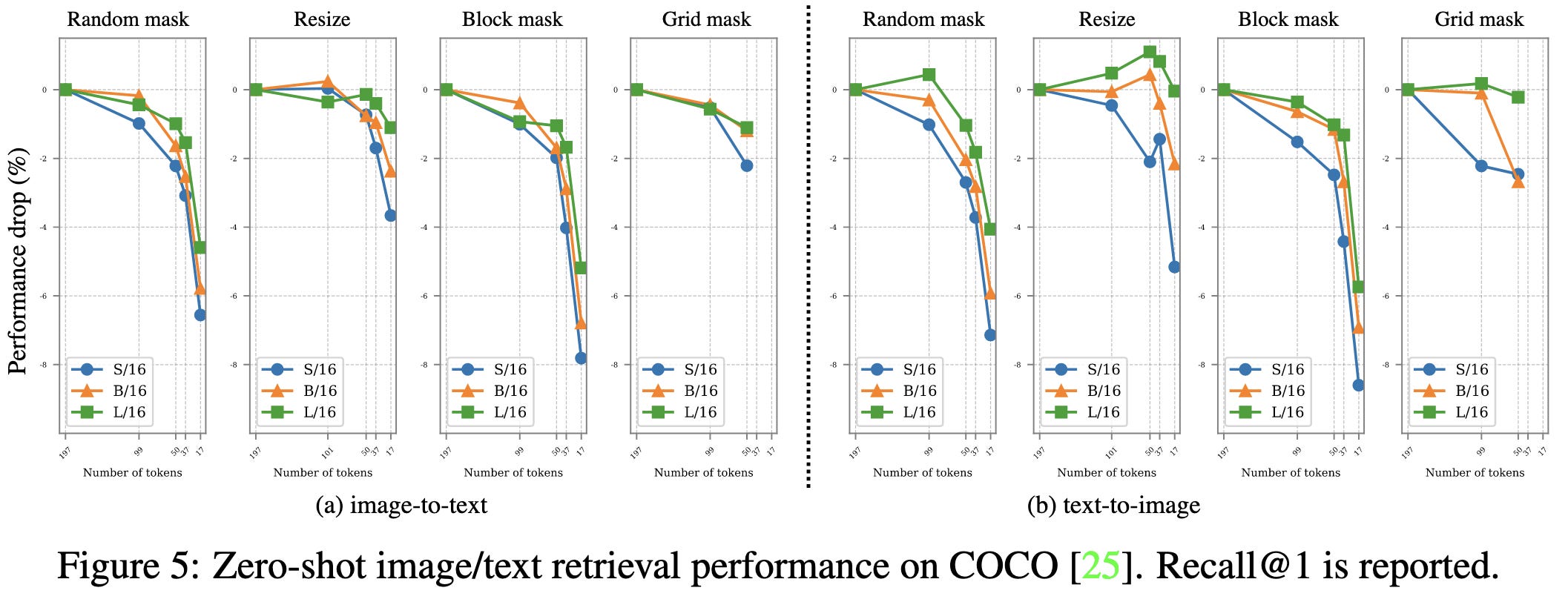
This pattern seems to roughly hold for zero-shot cross-modal retrieval also—not just image classification.
Similarly, large models’ accuracy holds up better when you reduce the number of text tokens. In fact, masking based on syntax (rightmost column) can even improve accuracy for large models.
They use these observations to reduce time-to-accuracy for CLIP models of different sizes.
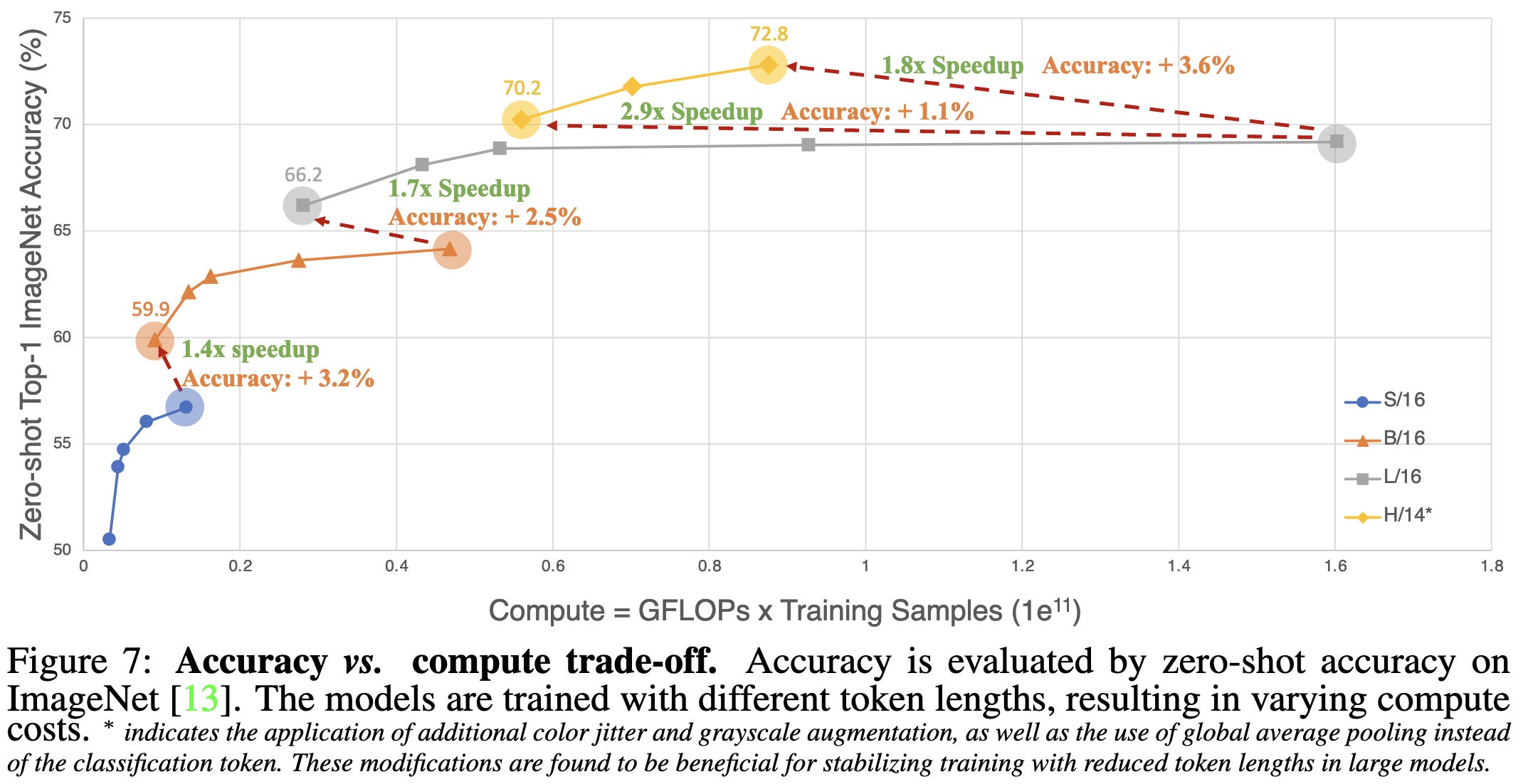
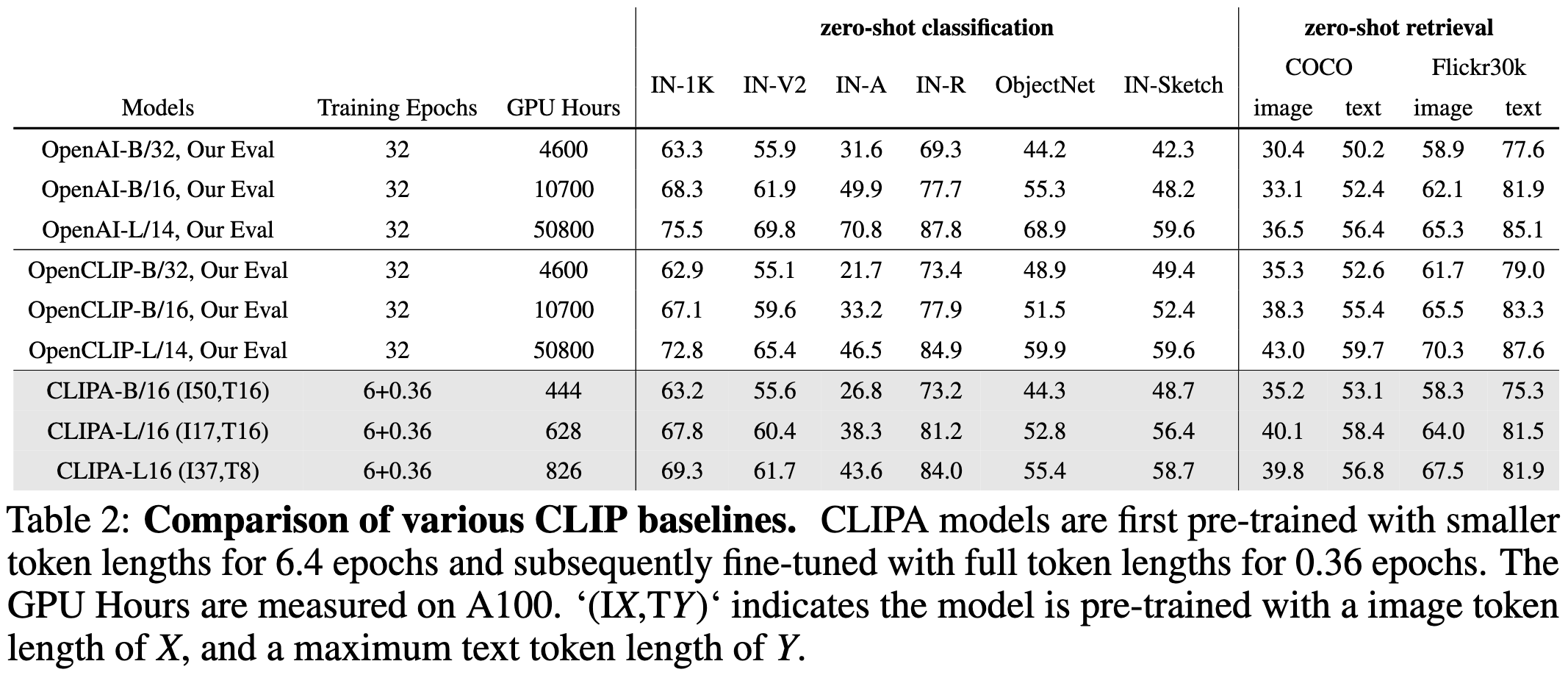
This is a super interesting datapoint that suggests we need a more granular view of what one "example" is when computing scaling curves.
Active Retrieval Augmented Generation
Instead of adding a retrieval step as part of the model or prompt construction, they allow the model to search for relevant information after each sentence it generates.
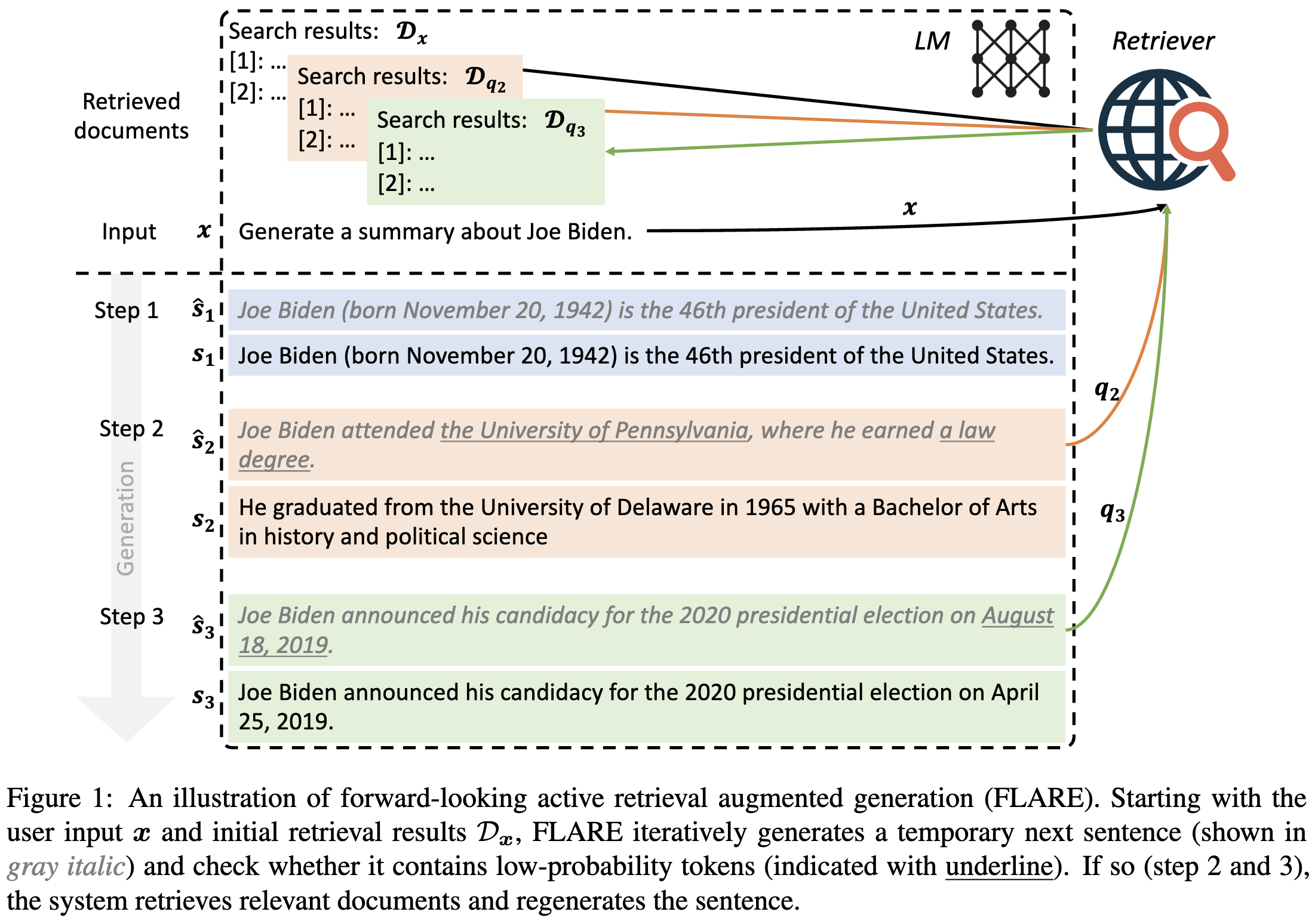
More precisely, they generate outputs one sentence at a time by repeating two steps:
The model generates an initial sentence based on the prompt and everything retrieved so far.
If there are any tokens in the sentence with probabilities below a threshold, they generate a query based on that sentence and add its result to the context.
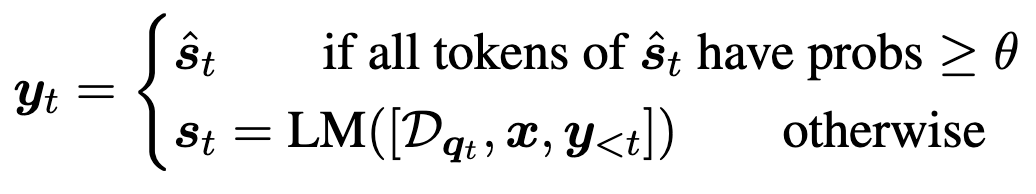
They consider two options for how to generate the queries:
Just masking out the low-probability tokens based on a threshold hyperparameter; e.g., if unsure about “Stanford” in the generation “Joe Biden attended Stanford,” we’d search for “Joe Biden attended”.
Asking a pretrained LLM for a relevant question to which the current tokens are an answer; e.g., “What university did Joe Biden attend?”
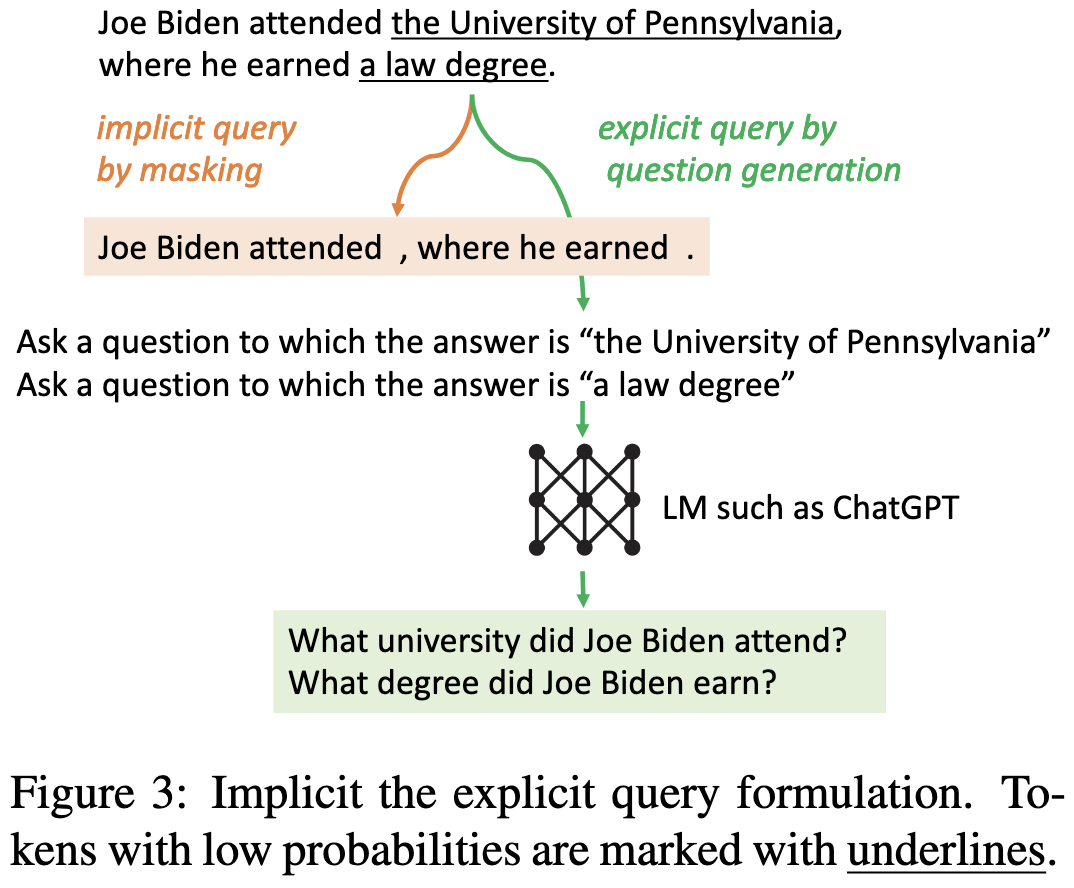
Both options work about equally well.
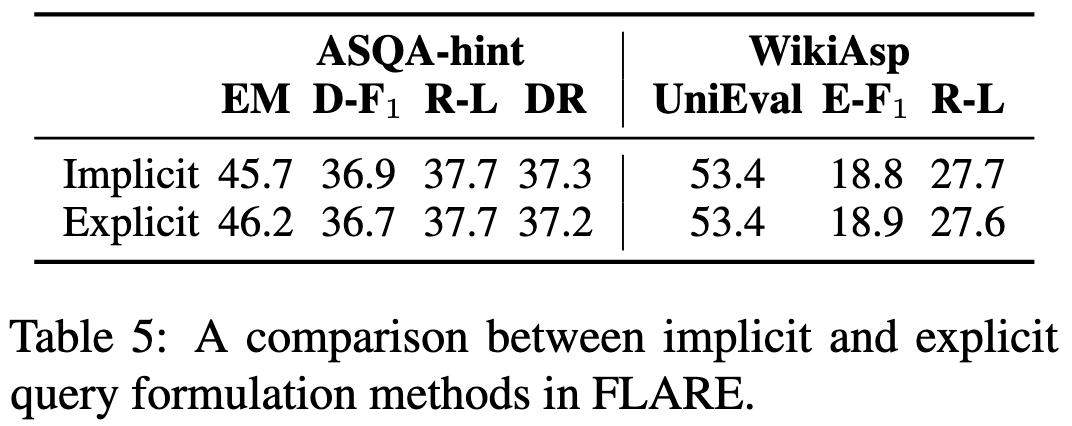
Retrieving information as-needed using their approach lifts accuracy significantly vs not having retrieval. It also does better than a) just retrieving relevant context at the start of generation, or b) retrieving based on the previous context instead of the tentative completion.
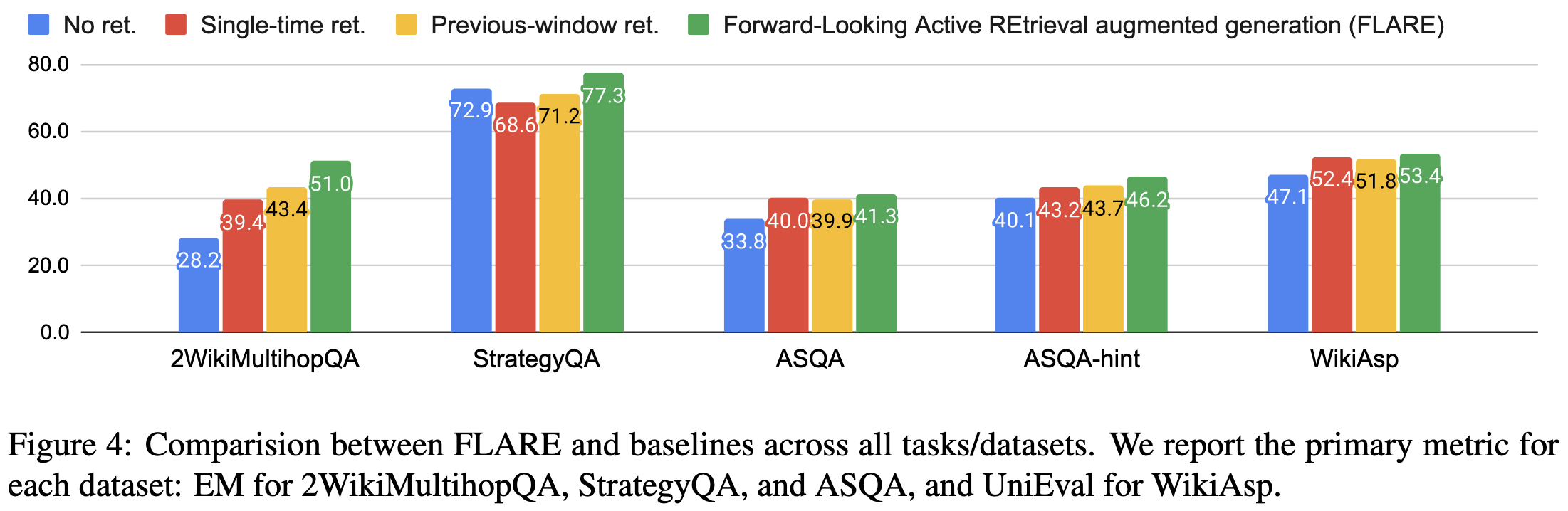
Interestingly, you get the best accuracy when a little less than half the sentences trigger any retrieval. A rare case where doing more work doesn’t get you more accuracy.
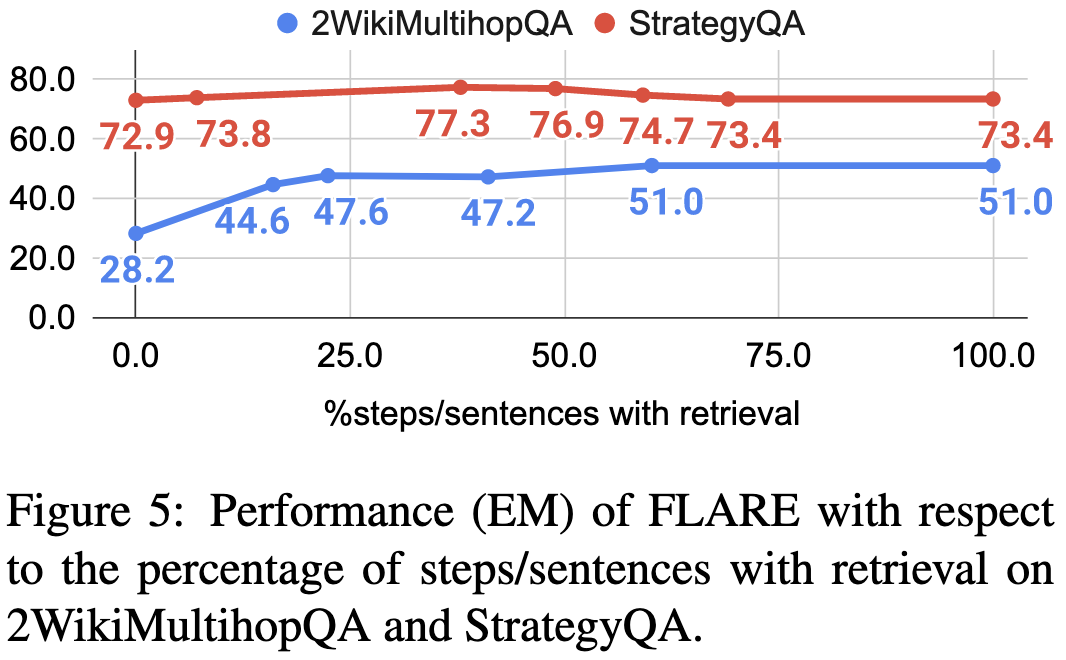
This method adds a bunch of inference latency, but might be worth it given the large accuracy gains. Plus it just seems like a good idea intuitively—searching on an as-needed basis is exactly how humans use search engines, after all.
I also appreciate their controlled comparison between searching based on past context vs searching for the (masked) sentence you’re trying to generate. The observation that the latter works better might be of general interest.
Software-based Automatic Differentiation is Flawed
Suppose you have the code:
a = x*x - 4
b = x - 2
c = a / bIn math, c simplifies to x + 2. We can pass in x=2 and everything’s fine. But in an autograd library, x=2 makes b=0, and we then divide by zero. More generally, failure to make mathematical simplifications can cause bad numerical behavior.
ASDL: A Unified Interface for Gradient Preconditioning in PyTorch
They a made a library for preconditioning / second-order optimization in PyTorch.
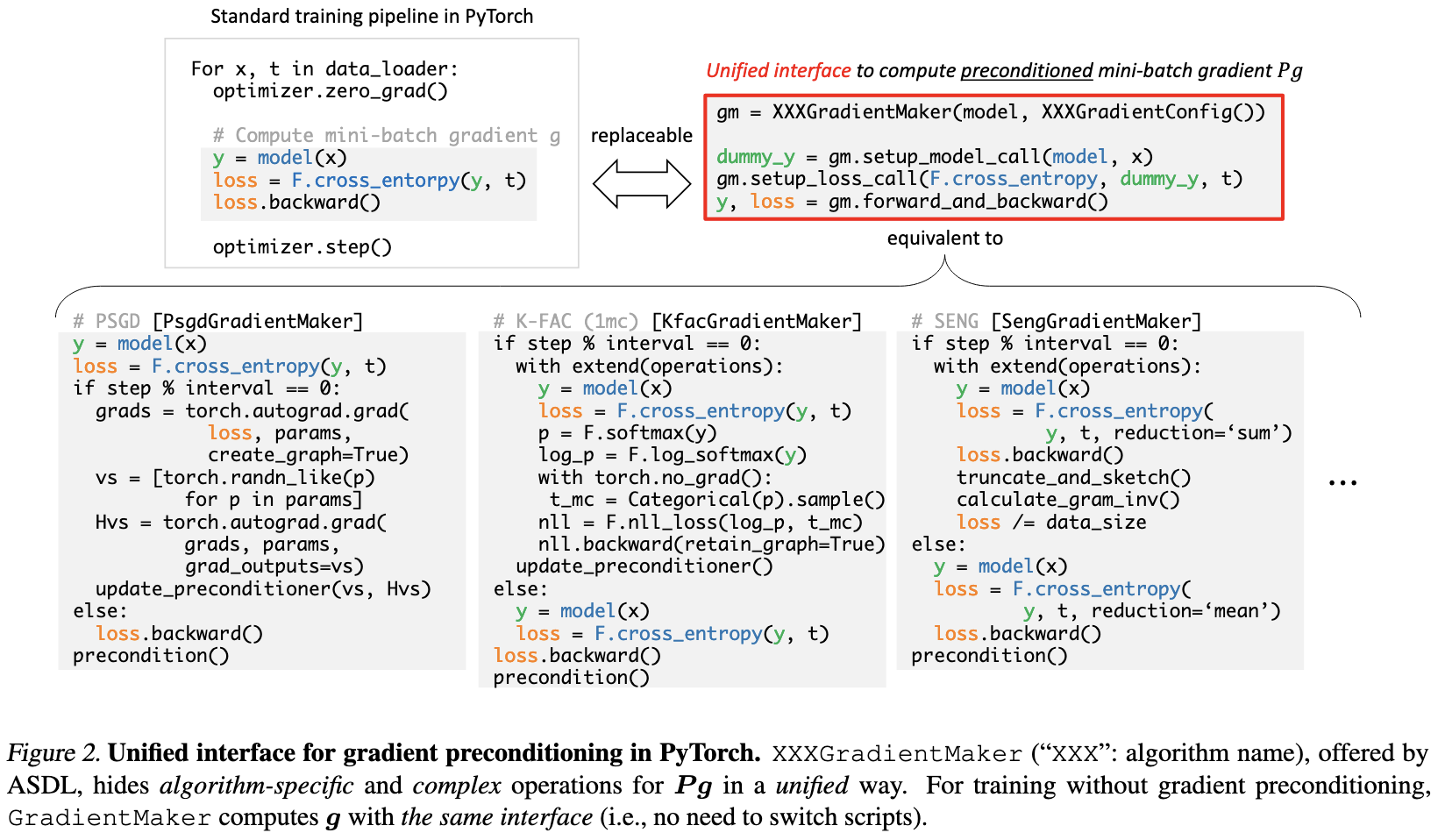
Mostly I like that they have clear thinking about the similarities and differences between approaches, and summarize them nicely.

They also have some experimental comparison of different methods in a unified codebase, which is always super valuable.
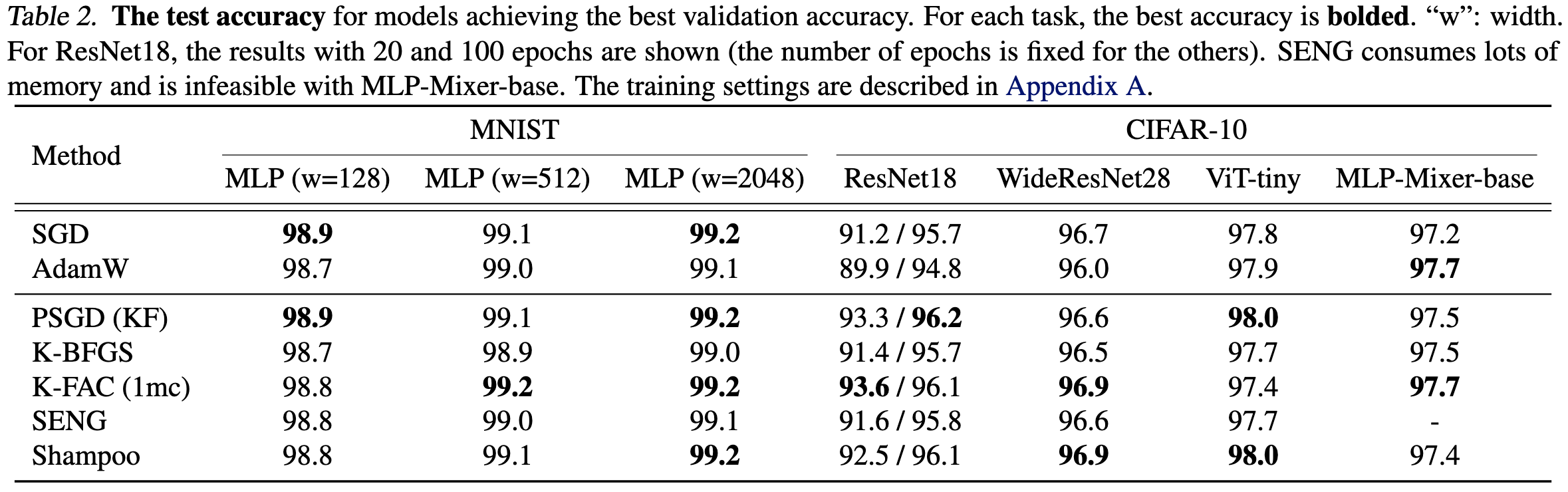
Not clear yet the circumstances under which one should use each method, but seems like a great starting point to make this question answerable.
Professional Certification Benchmark Dataset: The First 500 Jobs For Large Language Models
They introduce the “Professional Certification Benchmark Exam Dataset”, consisting of 5197 questions encompassing 1100 practice exams for various professional certifications. These aren’t tests like the SAT or GMAT; more like the test to become a “Salesforce Certified Community Cloud Consultant” or a “Lean Six Sigma Green Belt”.
OpenAI’s various models do fairly well on these tests, with even GPT-3 (not ChatGPT) getting >70% right on 39% of the tests.
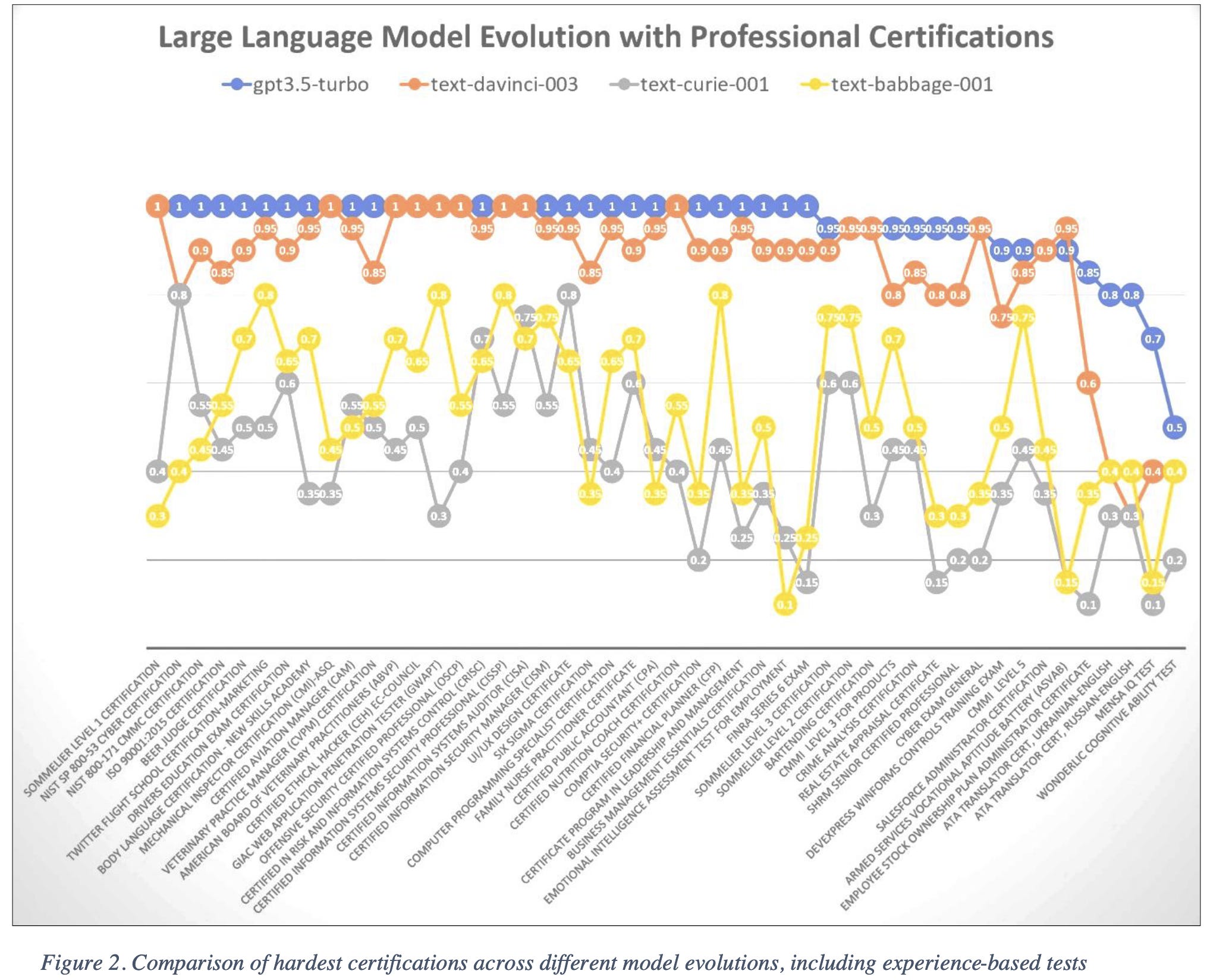
One caveat here is that the results are based on answering practice test questions, not any hands-on display of competence. E.g., ChatGPT nominally scores 100% on the Offensive Security Certified Professional exam, but the real exam requires performing a live pen test.
The emergence of clusters in self-attention dynamics
If you keep applying the same self-attention block to your inputs, your attention matrix collapses to a rank of 1 and ends up with boolean entries—although they only prove the boolean part with scalar token projections.
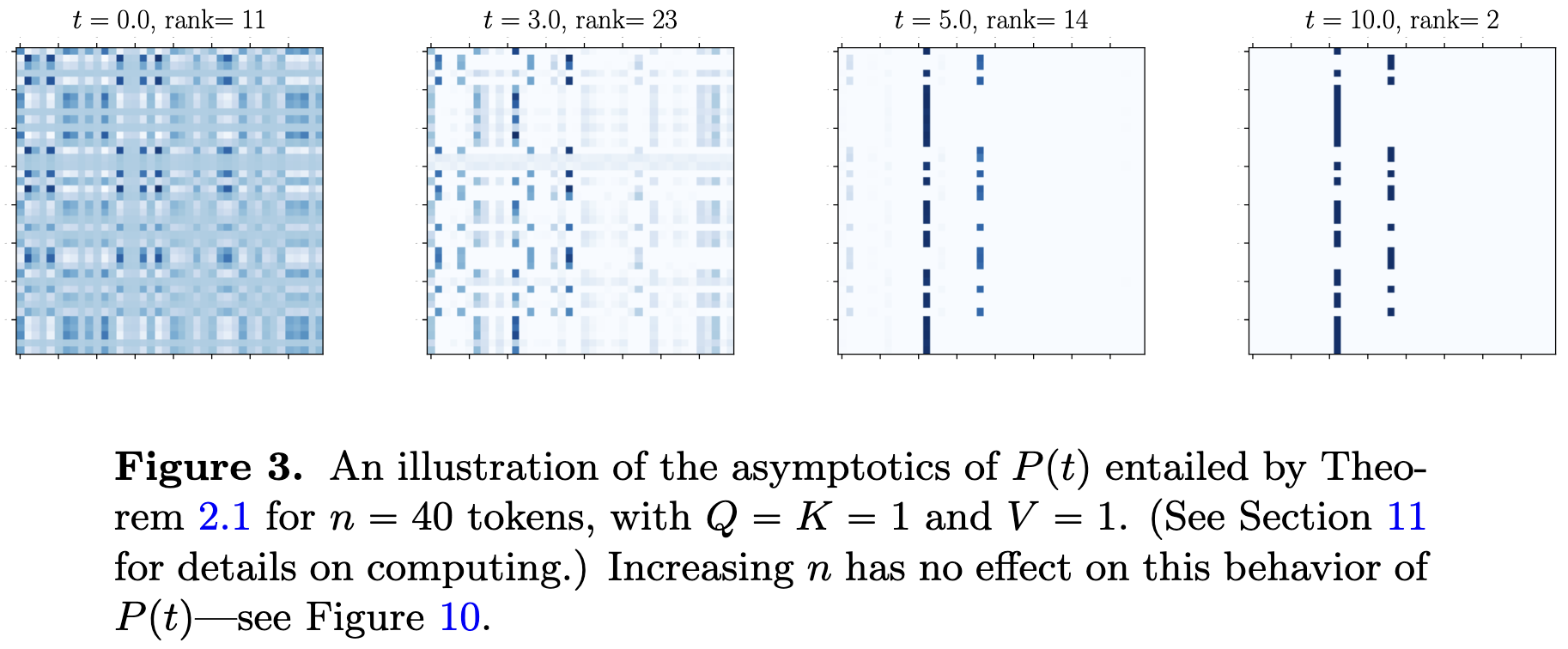
They also prove some other low-rank-ness / clustering results that hold under various assumptions.

I’m kind of amazed we get away with using self-attention in models. Chaining operators that super-exponentially lose rank seems like it should, at the very least, limit model capacity and make optimization way harder. The latter definitely happens, but I haven’t seen much investigation of the former.
Fast Distributed Inference Serving for Large Language Models
When running inference in an autoregressive text model, you have upfront preprocessing of the prompt, followed by serial token generation. Naively, you can ignore this structure and just run inference like in any other model, answering queries as they come in and maybe batching them.
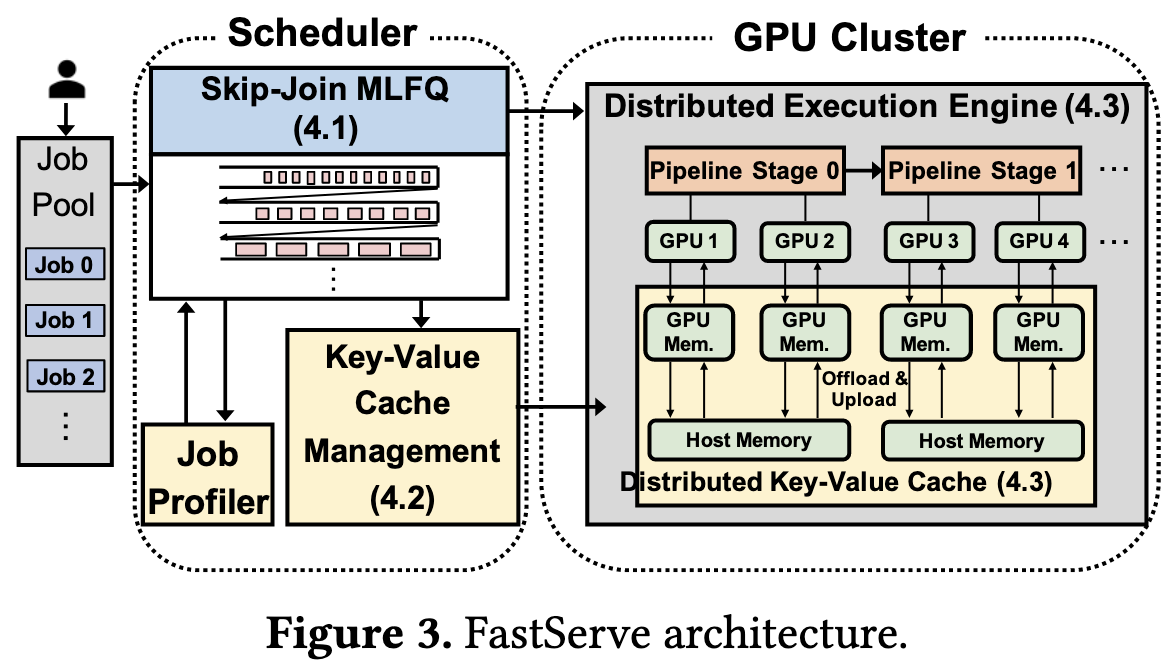
But there’s room to do a lot better. By intelligently managing the RAM required for caching past keys and values and beginning to process new inputs before old inputs are done, you can get much higher utilization.
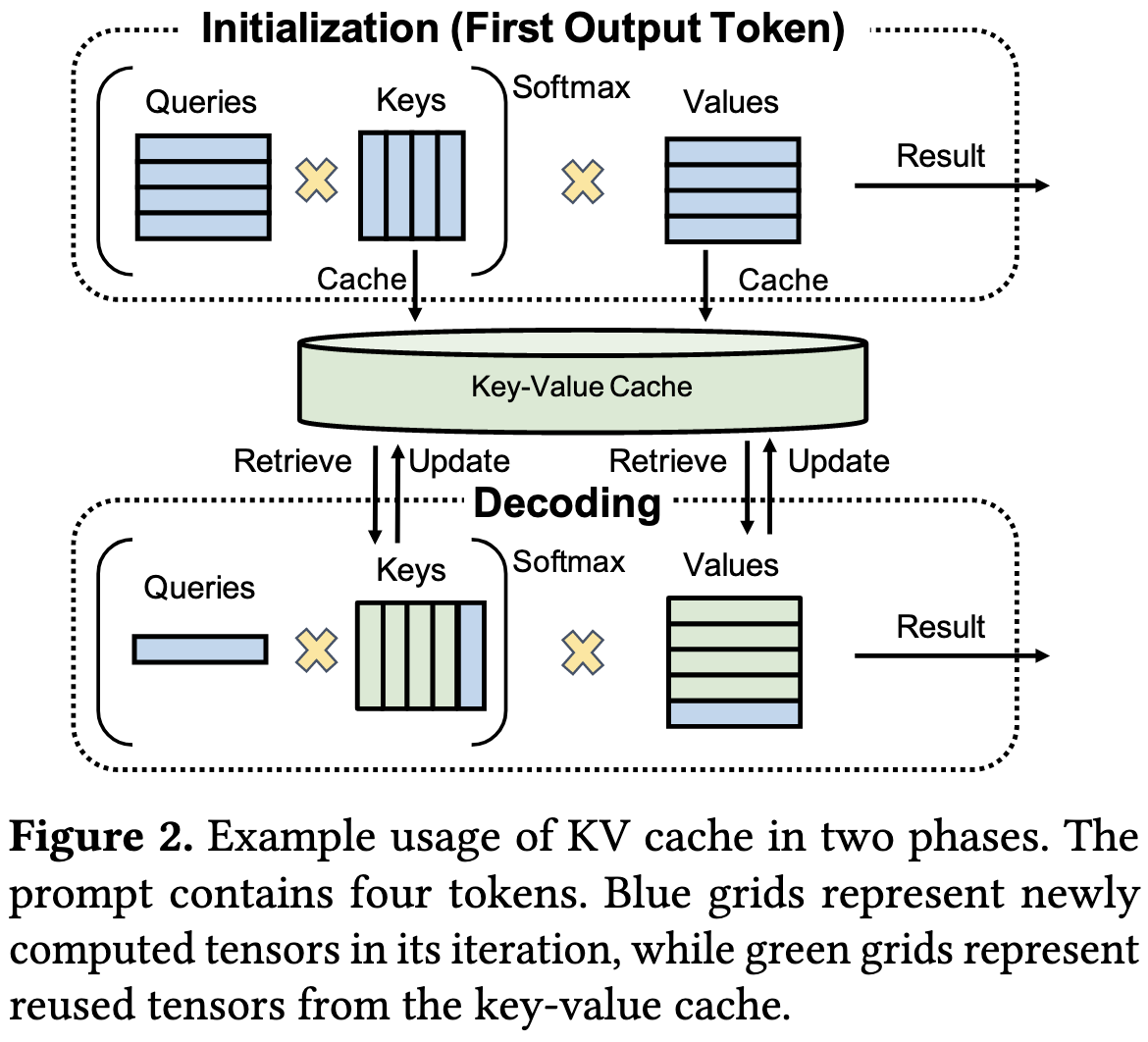
It’s complicated to do this well, but definitely possible—thanks to the ability to use prompt encoding and token generation times in your scheduling.

Their optimizations allow them to achieve much lower job completion times (latencies) than other serving systems for GPT-3 175B.

A detailed systems paper that seems to offer immediate practical improvements.
ImageBind: One Embedding Space To Bind Them All
Why stop at embedding text and images in the same space when you can also embed audio, depth maps, thermal data, and Inertial Motion Unit (IMU) data from accelerometers, gyroscopes, and magnetometers?

Mapping all these modalities to the same space lets them do cool stuff like audio-to-image generation and search.

They also get decent zero-shot classification with cross-modality labels for free.
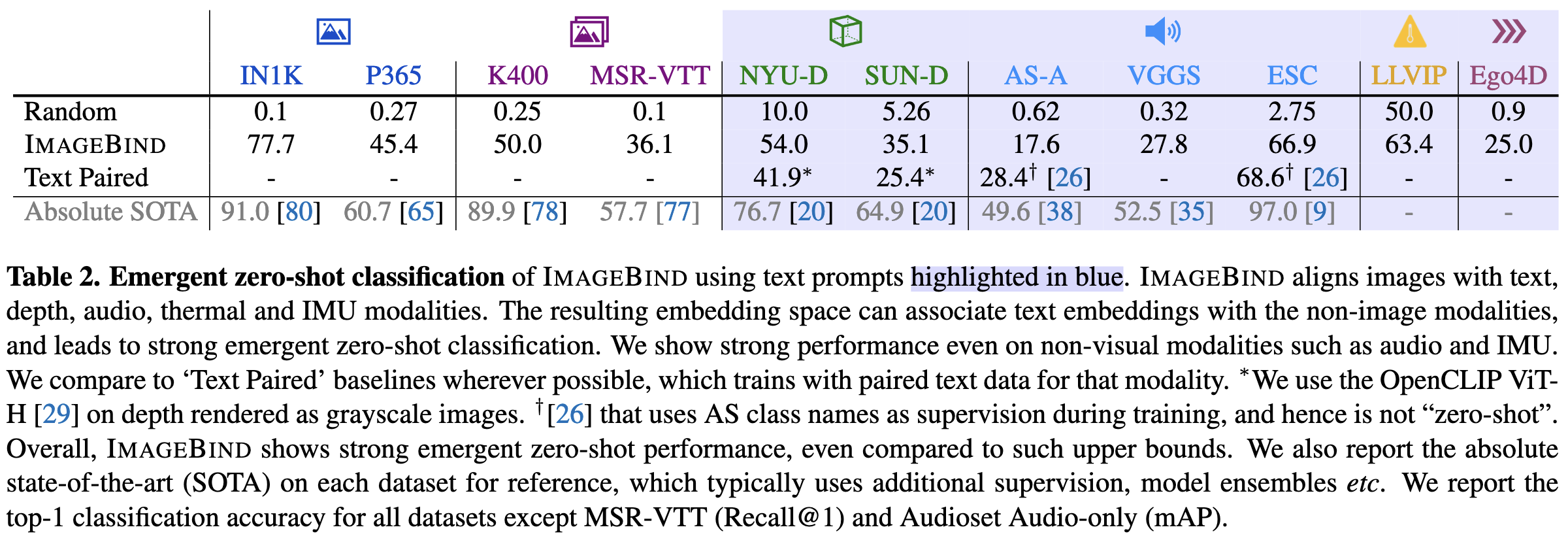
It’s not clear what baselines to compare to when your input space is unique. But they do find that using audio + video together with their method can work better than relevant audio + video baselines.

To get their method working as well as possible, they explored a variety of design choices, ranging from data augmentation strength to inter-modality alignment strategies.
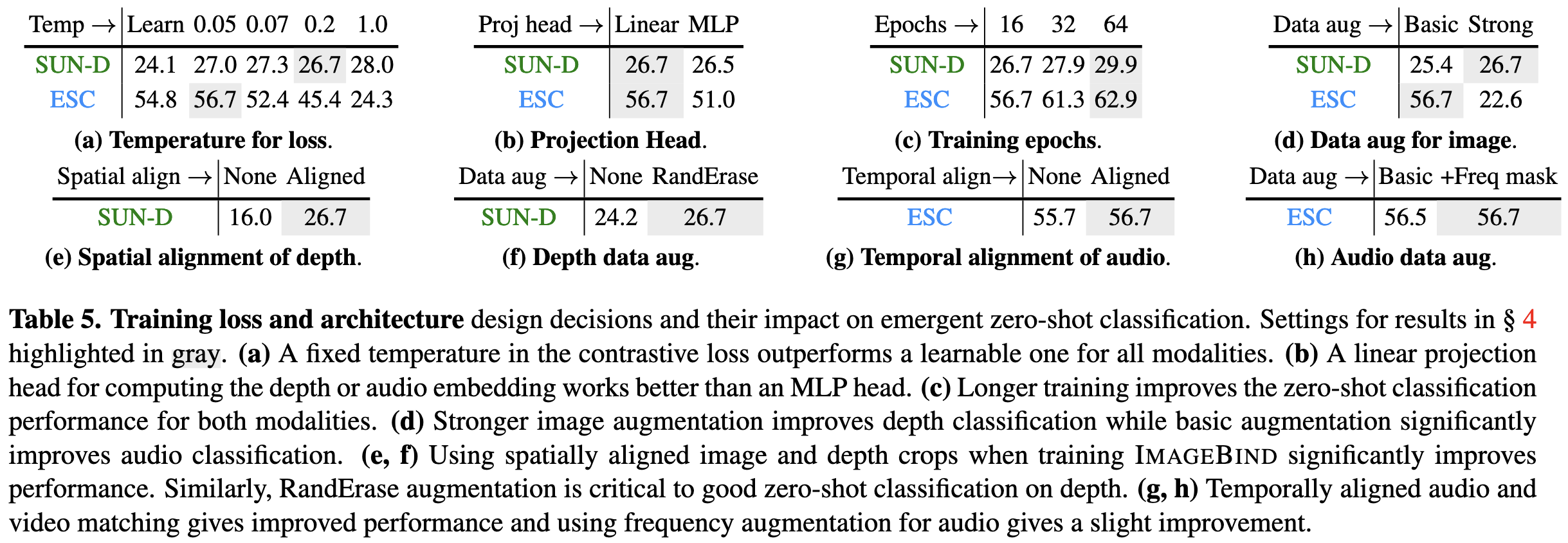
I’m never sure how to think about multimodality papers. They’re always like “we embedded some stuff in the same space using some encoders”, and I’m usually not sure what the takeaway is. But in this case, we seem to have an illustration that embedding even more modalities in the same space can kinda just work if you do it right.
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
They improve the cost vs accuracy Pareto frontier when using pretrained models via a few different techniques.

First, when the prompt contains multiple in-context examples, they choose a subset of those examples to reduce the prompt length.

Second, when there are multiple queries that can share the same prompt, they fuse them into one query.

Third, they cache previous answers and use the cached answer if they encounter the same query again.

Fourth, they finetune a smaller model based on a bigger model’s outputs and query the smaller model instead. An extra benefit of this approach is that the finetuned model can often use a shorter prompt, since it’s more specialized.

And lastly, they cascade LLMs, querying a cheap model at first and proceeding to progressively more expensive ones until some model has high confidence in the answer.

By combining these techniques, they can often reach the same accuracy as a single powerful LLM at greatly reduced cost.


One reason that cascading the models works is that different models make different errors. There are cases where the small GPT-J is right while the huge GPT-4 is wrong. If models are good at estimating their odds of being correct, you can do better than any of them individually by waiting until one has a confident prediction.
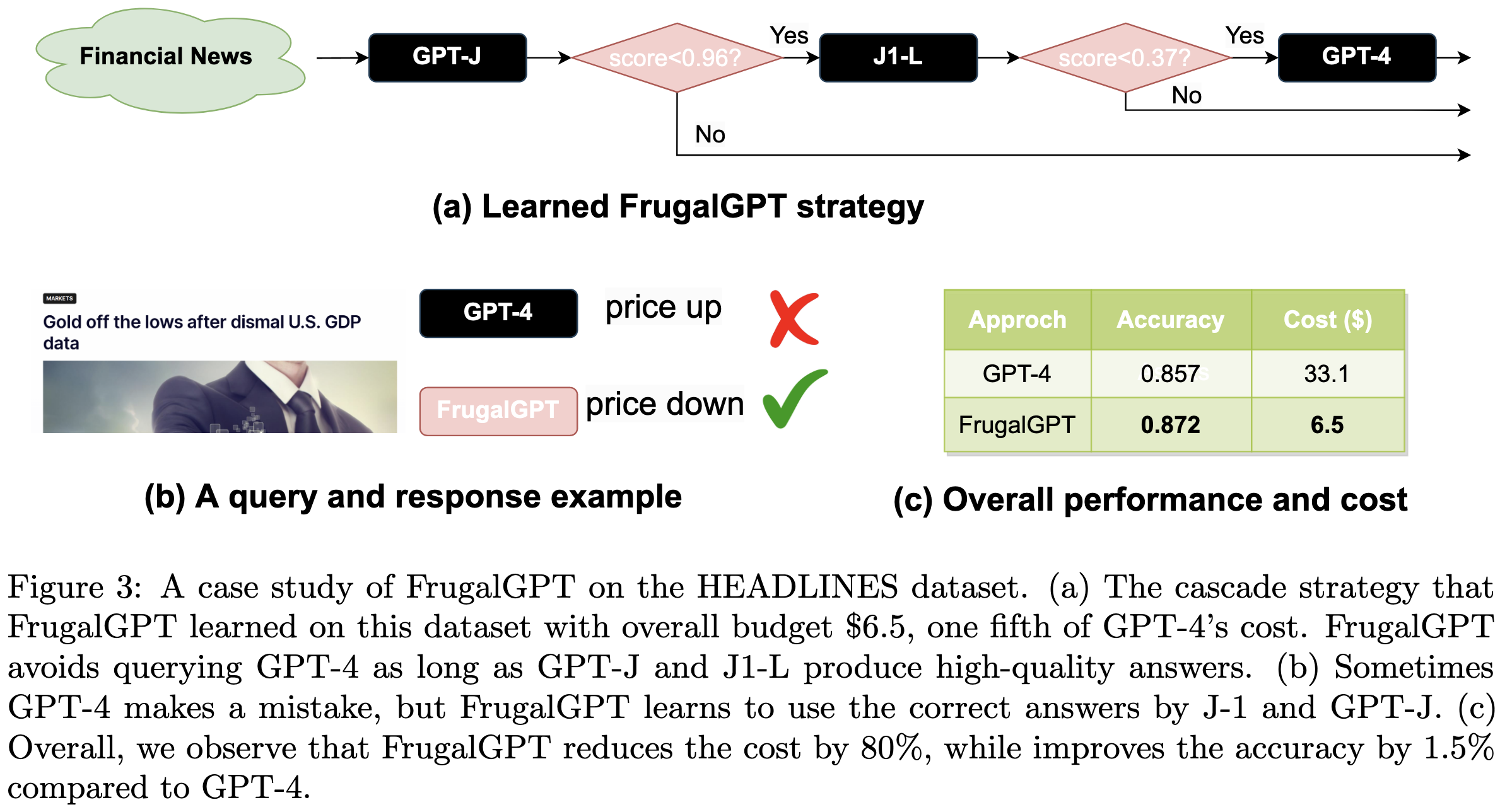
This paper changed my thinking a lot on two fronts:
This is the strongest evidence I’ve seen of early exit being super promising. If you can get a big lift from cascading separate APIs, you can surely get a lift from stopping partway through a single model. The former can be cast as a janky version of the latter where we pay network + framework overhead repeatedly and throw away all our compute-so-far at the end of each stage of the model.
Calibrated output probabilities are not just a nice-to-have, but a necessity for making early exit work well.
Also gives me flashbacks to my favorite paper, another example of cascading better-but-slower estimators to get awesome results.