
2023-7-30 arXiv roundup: Better image captions, Scaling EMA, Chain of thought empiricism

Heads up that we’ve hit the late summer slump in arXiv submissions, so there’s less content than usual this week.
P.S.: thanks to AI Supremacy for the Twitter shoutout!
Enhancing CLIP with GPT-4: Harnessing Visual Descriptions as Prompts
Normally when constructing the text description of a given class for a CLIP model, you use a simple template like “A photo of {classname}”. What if you instead use GPT-4 to generate text that conveys something about what the class looks like?

To get good text out of GPT-4, they train a small adapter network that identifies relevant text from a longer, initial description.

This method of generating text descriptions for classes usually improves classification accuracy.


Using a better LLM usually results in better CLIP embeddings—this is reassuring and suggests that the accuracy lifts actually come from the text being better.

Given this and the BLIP2 captioning results from last week, it looks like using LLMs to generate better text descriptions of images is a real thing.
Zooming out, this is another example of automating steps in a training data pipeline using machine learning. While the sci-fi AI-improving-AI scenario is self-improvement, what seems to be working so far is using ML to just improve each piece of the training: architectures, optimization, hparam tuning, etc.
Epsilon*: Privacy Metric for Machine Learning Models
Normally when we want privacy guarantees for a trained model, we bound the privacy loss from the training process.
This paper proposes to instead directly evaluate the final model without needing to know anything about the training process. This is cool because 1) it’s way easier to measure, and 2) it means a third party could audit a model without having to understand everything that went into the training.

Their alternative privacy definition lets them lower bound the ε from (ε, δ)-differential privacy using only hypothesis tests. These tests check whether we can reject the null hypothesis that a given sample was not in the training set.
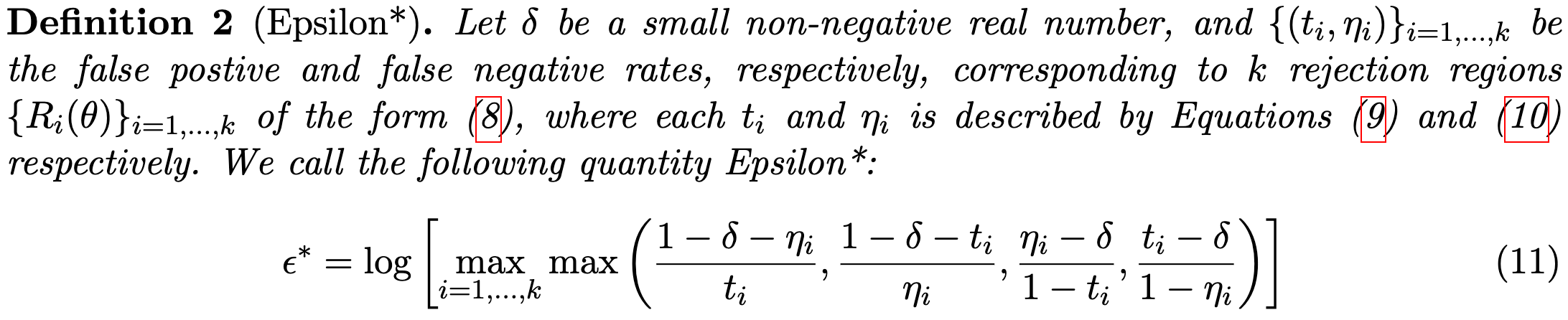
You can get your model to satisfy their privacy definition by just doing differential privacy normally (e.g., with DP-SGD). However, using their definition—along with estimates of true and false positive rates—shows a much stronger privacy-utility tradeoff than you’d expect from the worst-case DP guarantees.

Interestingly, they also find that just training for less time can do better than doing differentially private training for longer (again, using their privacy definition).

I lost track of the DP literature a while ago, but this seems nice and practical. If still offers meaningful privacy bounds at scale, I could imagine something like this getting added to standard model eval suites.
LLM Censorship: A Machine Learning Challenge or a Computer Security Problem?
You might want your language model to self-censor so that it won’t, e.g., tell the user how to launch a cyberattack. But this may be fundamentally unsolvable, since many innocuous queries can add up to a dangerous one.

As they put it:
The use of Language models as censorship mechanisms aims to identify semantically impermissible content. However, our results on the impossibility of semantic censorship demonstrate that this approach is fundamentally misguided.
Also, note that this isn’t just a heuristic argument; they formally prove this under certain assumptions.

Bad news if you’re trying to get your model to adhere to a particular corporate image or product experience. But maybe users will just understand that chatbots are never going to self-censor perfectly. It’s also possible that ML engineers will just hack together enough heuristics to get compliant outputs 99% of the time in practice.
QuIP: 2-Bit Quantization of Large Language Models With Guarantees
They got decent 2-bit quantization working on OPT models. It loses a little bit of quality compared to fp16, but less than most (or all?) other two-bit quantization schemes.

The core of their method is minimizing the distortion in the output under a local quadratic approximation of the loss.

Two ideas help them do this well. First, they incrementally quantize each weight matrix, conditioning on the distortion in each column when updating subsequent columns.

Second, they project the weight matrices into a different basis that tends to spread out the Hessian’s eigenvalues. This is helpful because the Hessian’s eigenspectrum tends to be super concentrated. The projection matrix they use is a Kronecker product of two other matrices; this lets you compute the matrix product in a fast, factorized form.

The overall procedure stores the weight matrices in an encoded form at rest and decodes them before using them.


Besides empirical results, they prove that their method is optimal within a class of quantization methods that includes OPTQ.

They also have some interesting theory about inducing incoherence in symmetric PSD matrices more generally.
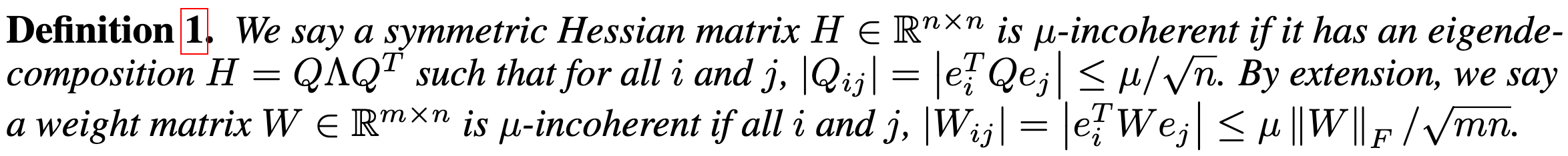

This makes me even more convinced that some sort of incoherence preprocessing is a good idea for space-minimizing quantization. I’d bet that some mix of structured rotations, adaptive quantization levels, and vector quantization will eventually become the standard pipeline.
Measuring Faithfulness in Chain-of-Thought Reasoning
A bunch of thorough experiments on what happens when a) you prompt models with “Let’s think step by step” and then b) mess with the resulting chains of thought before letting the model give its final answer.

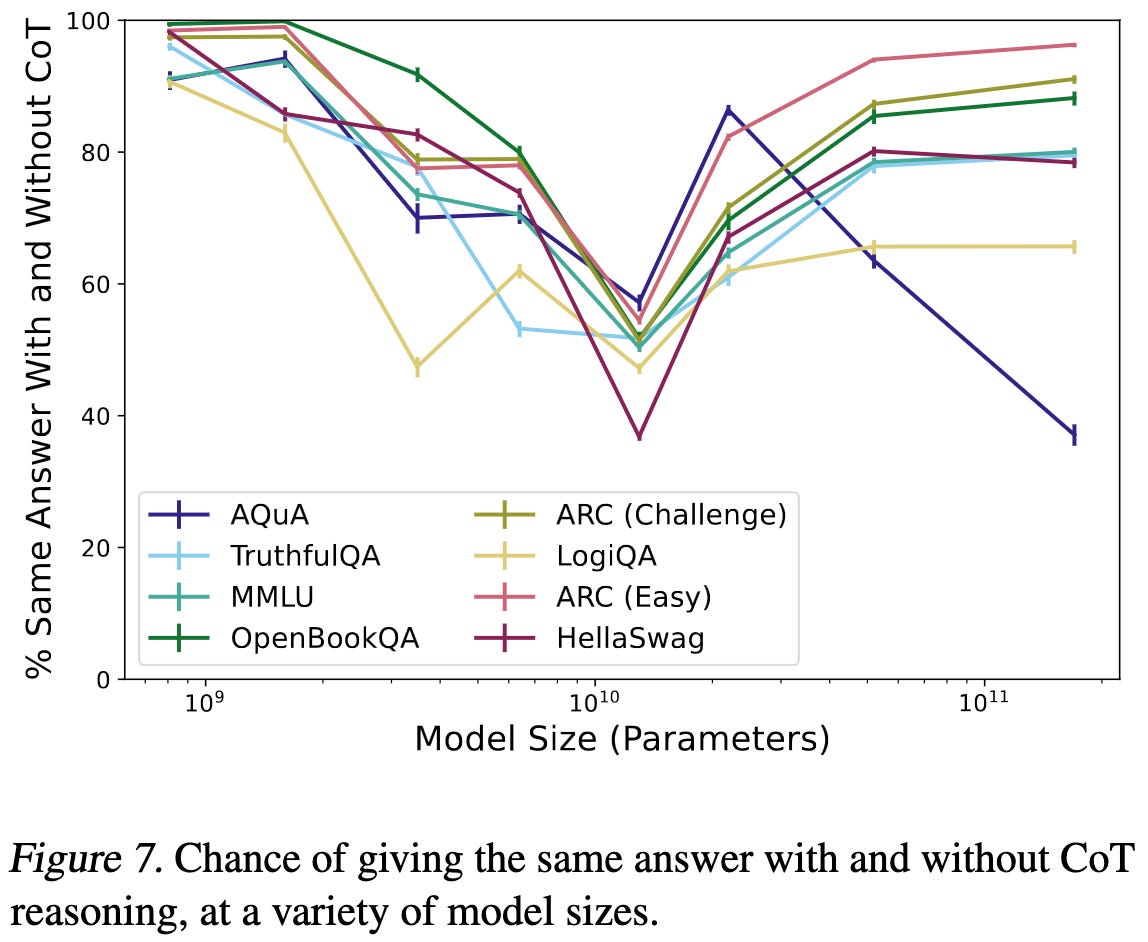
First, across a variety of datasets, chain-of-thought consistently improves accuracy (right subplot). This was kind of known, but it’s great to see a rigorous reproduction of this result.

The benefits of CoT might (?) increase with model size, but it’s not a consistent trend across datasets.

For some reason, models around 13e9 params are least sensitive to whether you use CoT in their experiments. I would assume this is just a quirk of their 13B model, but the trend seems to hold for nearby model sizes as well.
If you cut off the chain of thought partway through and then make the model answer, you get a smooth relationship between how much was cut off and how likely the model is to change its answer.

If you add a mistake to the reasoning, you get similar-ish curves—adding a mistake earlier in the reasoning is worse than adding it later.

If you replace all the reasoning with ellipses, you don’t get the accuracy gains but the model ignores the ellipses pretty well across all lengths. This implies that increased test-time compute per se doesn’t improve accuracy.

Finally, if you paraphrase the reasoning, you tend to still get the same answer. This suggests that there isn’t some weird quirk of the generated text that’s responsible for the accuracy gains.

Always nice to see such a comprehensive battery of experiments, especially for a topic of great practical interest.
Evaluating the Moral Beliefs Encoded in LLMs
What do various open source and proprietary LLMs choose when you present them with moral dilemmas?

Most large + recent models correctly select the “right” answer in the low-ambiguity questions (e.g., whether you should slow down to avoid hitting a pedestrian). Recent OpenAI, Anthropic, and Google models are especially good at this. When there’s more ambiguity, models have more varied outputs, which is a good thing.

If you look at the correlations in answers across models, there are a few clear clusters. The commercial LLMs (except those from AI21) are one cluster, and the open source LLMs are another cluster. There are especially strong correlations within {Cohere’s big model, ChatGPT, Claude 1.0} and within {GPT-4, recent Claude variants, Google’s Bison-001}.

We can’t know for sure without information about how the commercial LLMs were trained, but I’d guess these are data correlations. Specifically, I’d bet on some combination of:
Big companies all using the same IFT data from Scale.ai. It’s tens of dollars per sample, so only LLM companies would pay for this.
Crowdworkers having ChatGPT do their work for them when generating IFT data
Incrementally-Computable Neural Networks: Efficient Inference for Dynamic Inputs
Another benefit of vector quantization: if you quantize your activations, you can sometimes process small changes in the input without redoing your entire forward pass.

The idea is that, at each layer, you only have to look at which inputs had their quantization codes change, update the outputs based on these inputs, re-quantize the outputs, and then repeat for the next layer.
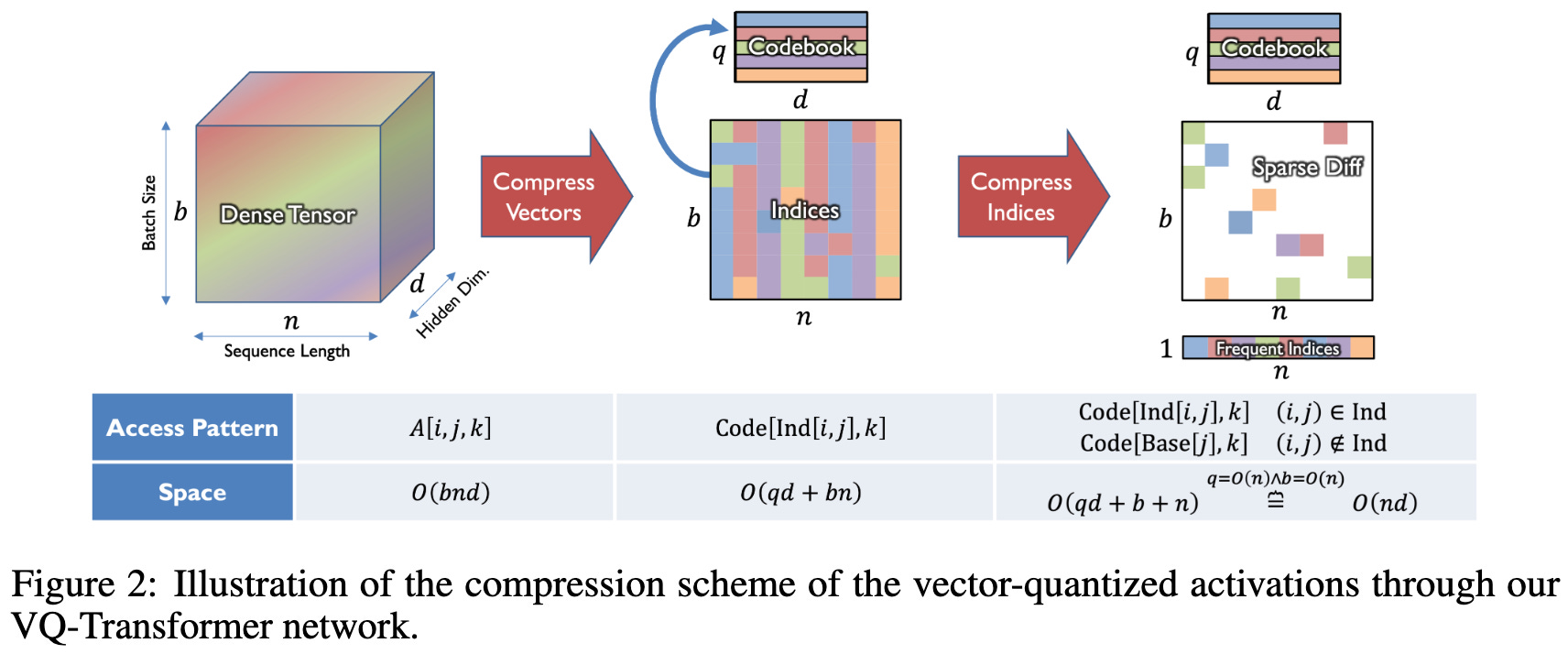
The way they do vector quantization causes large accuracy losses, but…
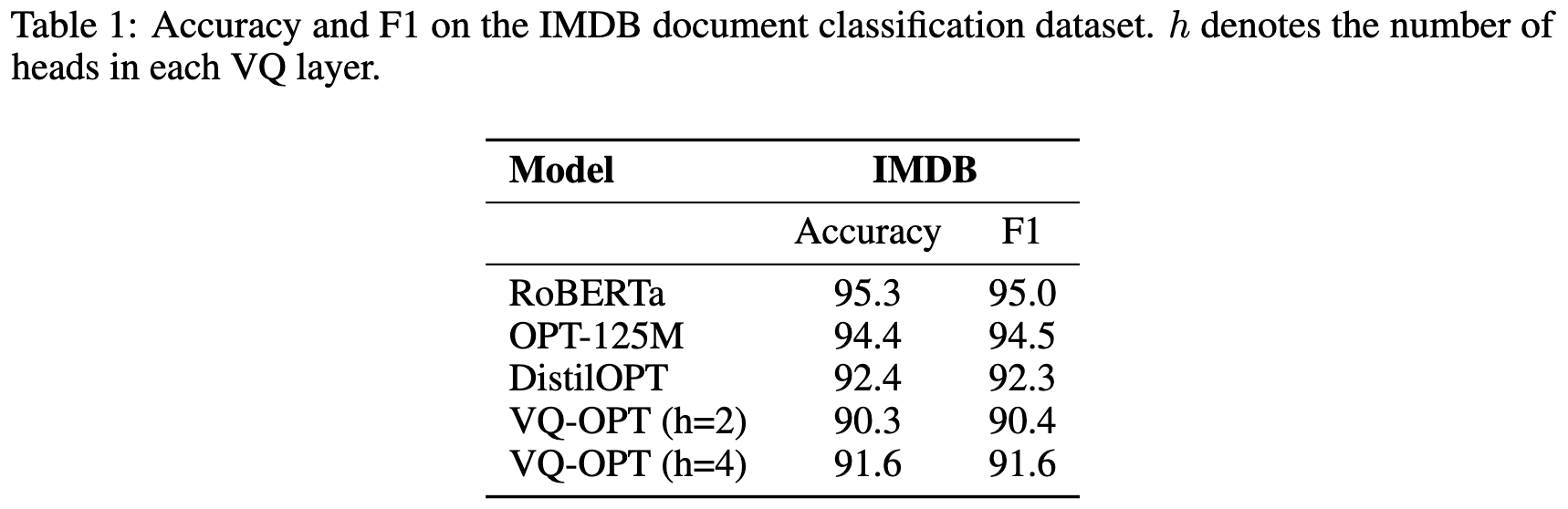
they do manage to avoid recomputing most of the activations when the input updates are sparse. By sparse, we mean something like “only a few words changed in our input document.”
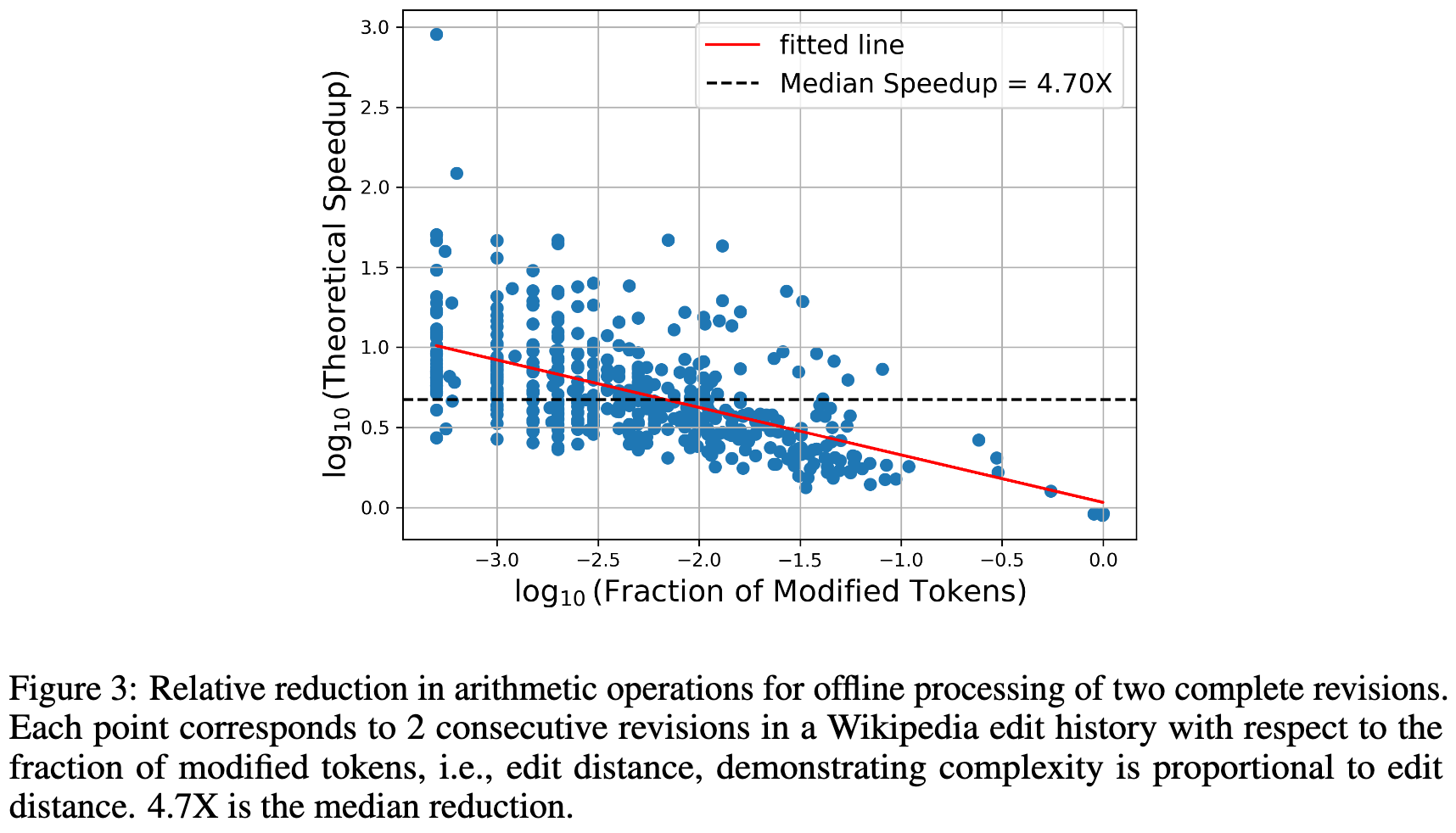
I’d vaguely thought about checking whether VQ encodings change in order to buy adversarial robustness and/or differential privacy guarantees, but hadn’t really thought about it for incremental computation. It’ll be hard to squeeze wall-time speedups out of this due to the unstructured, dynamic sparsity, but my inner neuroscientist likes the idea of only spending energy on what changed in the input.
How to Scale Your EMA
When using an exponential moving average of your weights, scale the EMA coefficient exponentially with batch size.
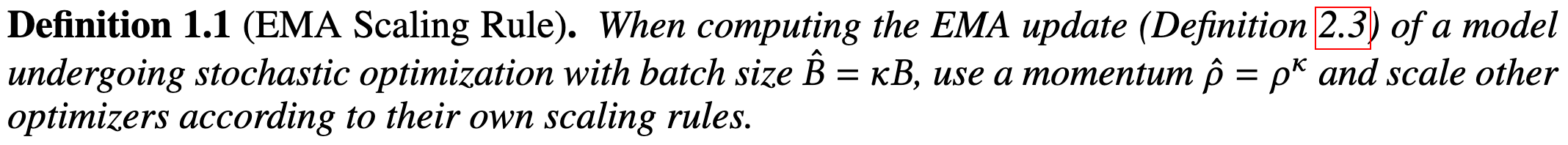
This is the right thing to do mathematically to preserve the EMA semantics across batch sizes (see the black and blue curves overlapping).

As you would hope, doing the math correctly helps preserve the overall training dynamics across different batch sizes. This can avoid the horrible hparam settings you’d end up with if you naively scaled up batch size without adjusting the EMA coefficient.

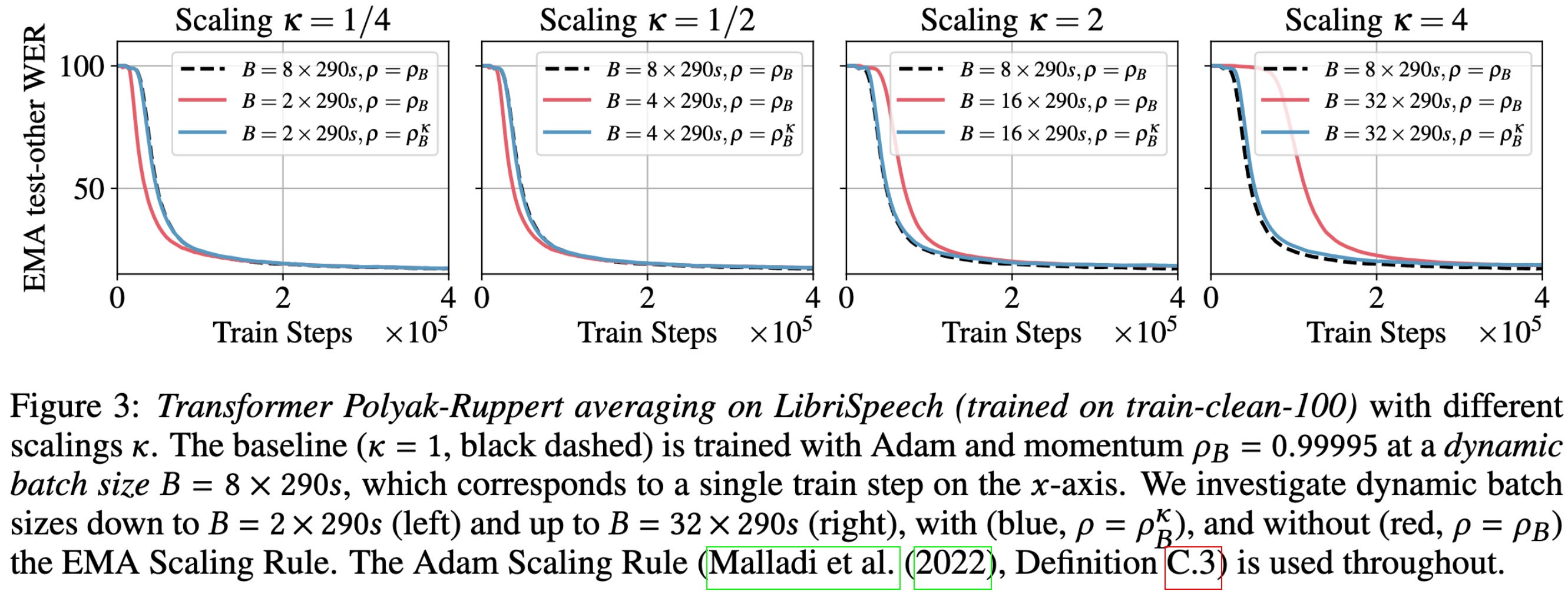
Great to see elegant math translate to positive results on various benchmarks.
Looking forward to the new post