
2023-5-21 arXiv roundup: Parallel transformers, Optimized data mixtures, Don't trust LLM chains-of-thought

This newsletter made possible by MosaicML.
Accelerating Transformer Inference for Translation via Parallel Decoding
They speed up inference in autoregressive text models without changing the models or requiring any extra training. They do this by generating tokens in parallel, rather than sequentially.

More precisely, they propose three schemes for parallel decoding. One decodes the whole sequence in parallel; one decodes in chunks, with parallelism happening within each chunk; and one decodes most of it in parallel and then serially afterwards (to handle variable lengths).

To get the parallel decoding to work, they have to run the output back through the network for a few iterations. The initial input to the parallel block is padding tokens. They stop the decoding when none of the tokens change.

One nice property of this approach is that, if you run it for a number of iterations equal to the number of parallel tokens, you’re guaranteed to get the same output as serial decoding. To see this, observe that you can view this procedure as autoregressive generation that a) also burns a bunch of compute to guesstimate future tokens, and b) keeps recomputing the previously-generated tokens in some window at each step.

Given the burning-extra-compute formulation, you might wonder how this can save time. This is possible because of a) the stopping condition and b) low hardware utilization with small batch sizes. (a) makes it possible for us to generate m tokens in under m decoding iterations. (b) reduces the marginal cost of generating multiple tokens at once.
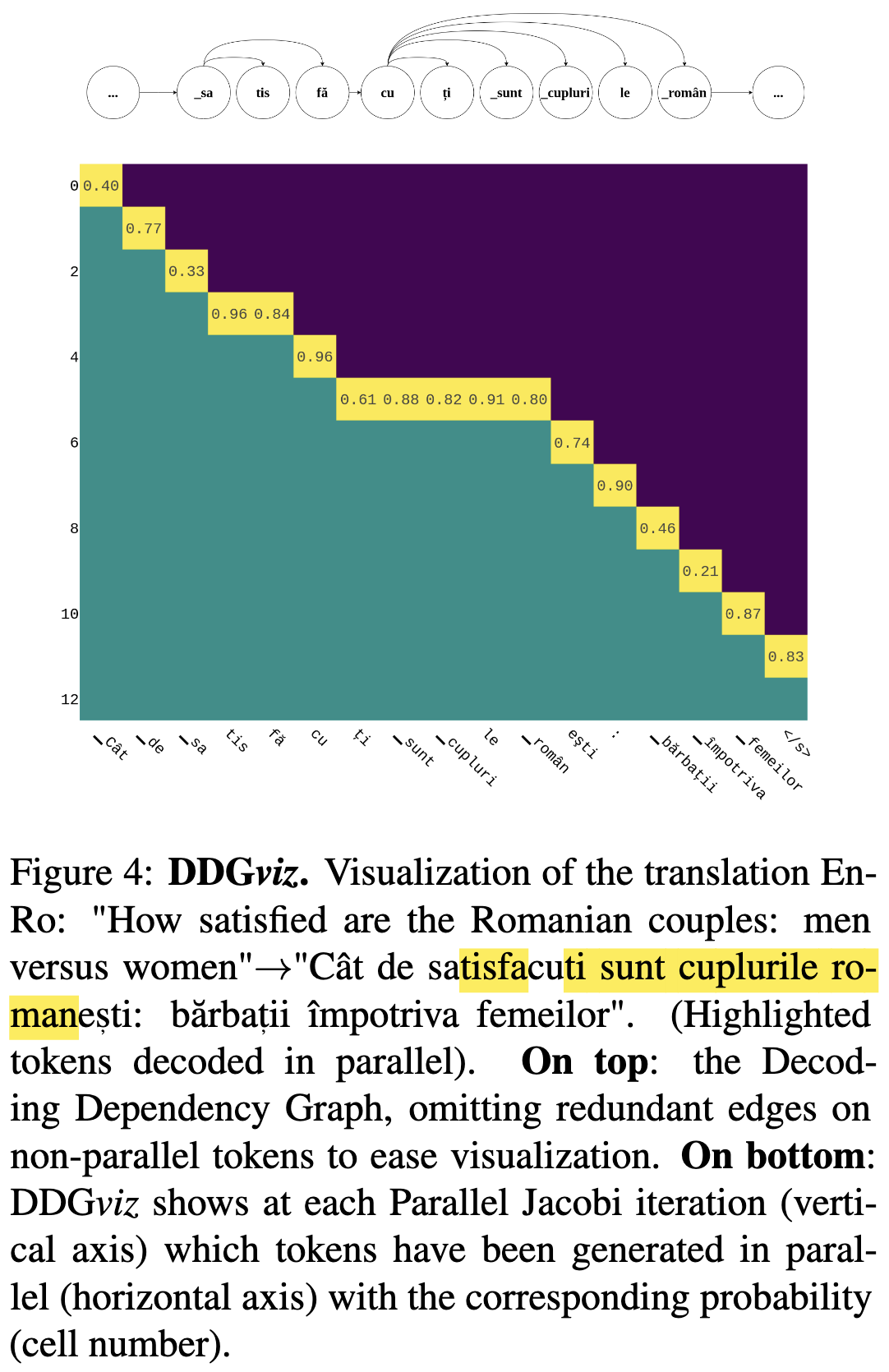
With batch size 1, they get wall-time speedups on some GPU with no change in quality whatsoever compared to autoregressive decoding.

They also run faster and obtain higher accuracy than existing approaches to parallel decoding.

This is really cool. I’m not sure how well this will generalize across tasks and inference setups, but it seems like at least a promising foundation we can build on. In particular, I can already see opportunities to enhance it by:
Using a sliding window instead of fixed chunks. The first token in each chunk is always final after a given iteration, so no point leaving it in the chunk.
Moving the window ahead by an amount equal to the length of the prefix that meets the stopping condition (i.e., hasn’t changed), rather than forcing recompute of the whole chunk until all tokens converge. Think Boyer-Moore.
Speculative: feeding the output embedding back in directly, without converting back to a token ID.
Speculative: finetuning the model for this sort of generation or rewarding it for predicting tokens without seeing their immediate predecessor.
etc
Overall, this makes me suspect that parallel decoding is going to become a standard practice in the next couple years.
EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention
They made an image classification architecture with a better speed vs accuracy Pareto frontier than seemingly any other architecture.

To do this, they began by analyzing existing vision transformers and their bottlenecks in detail. The first finding is that these models spend a ton of time in memory-bandwidth-bound ops like adding, transposing, normalizing, and copying.

Since these bandwidth-bound ops are disproportionately found in self-attention modules, they explored what happens if you just have fewer of these modules. Turns out that that this can not only eliminate slow ops, but also increase accuracy. You do the best with 20-40% of the modules being self-attention, rather than the typical 50%.

Within attention modules, they found that attention heads are often redundant. But you can reduce this redundancy but having different heads use disjoint subsets of the input features.

They also tried pruning Swin-T to understand which layers could safely be reduced in size. In general, later layers needed fewer channels and QK matrices needed fewer dimensions than V matrices.

Using these insights, they propose a new vision transformer with a few changes:
They chain multiple FFNs in a row to achieve a lower ratio of FFNs to attention.
They add depthwise convs before the FFN blocks to mix tokens.
They replace regular attention with “Cascaded Group Attention.”
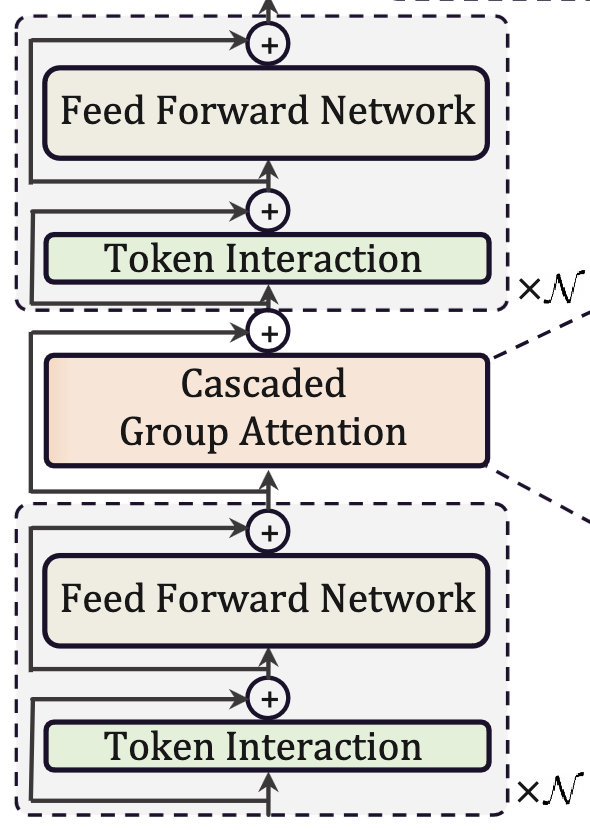
The Cascaded Group Attention differs from regular attention in two ways:
It has each head operate on a disjoint subset of the features. E.g., with two heads, the first head’s queries, keys, and values depend only on the first half of the input features.
It executes the heads serially and adds the output of each head to the input of the next head.

Putting these pieces together, they get a model that looks like this:

In addition to the improved speed vs accuracy frontier we saw for image classification, they also do better when using their model for object detection or for finetuning on downstream tasks.


Each of their design decisions seems to be locally optimal according to their ablations. I’m most surprised that the cascading in the cascaded attention is worth it given the extra serial dependencies. It also sticks out that HSwish was more accurate that ReLU, but not worth it due to the extra overhead.

This seems like a real, significant improvement—speed vs accuracy plots on representative hardware with standardized experimental setups (in this case TIMM) are the gold standard as far as I’m concerned.
Cool to see that we’re still getting better at image classification even after all these years.
Saturated Non-Monotonic Activation Functions
They propose replacing the positive half of various activation functions with the identity, like a ReLU.
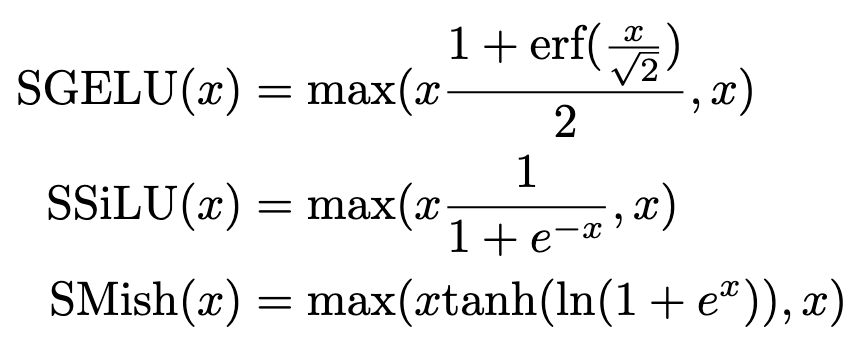

This apparently helps accuracy for various CNNs trained on CIFAR-100 under otherwise identical setups. It’s only one dataset, but the experiments actually seem to hold everything but the nonlinearity constant—plus they have error bars.
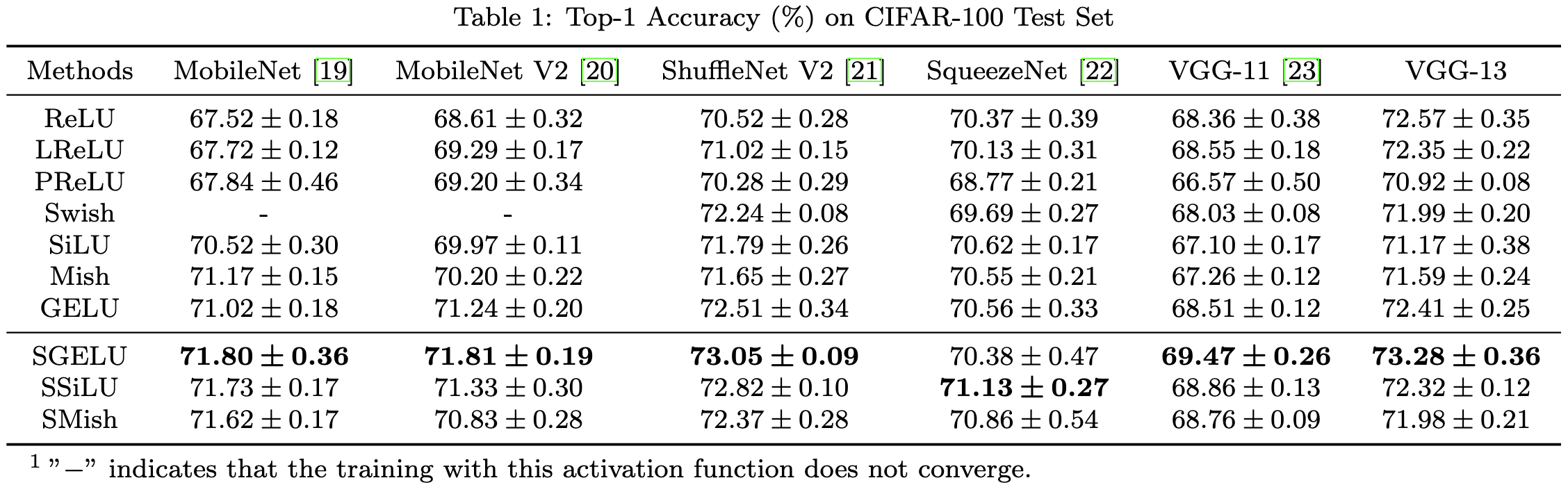
This is a surprising result. Making this change causes discontinuity in the first derivatives, which I would expect to be a bad thing.
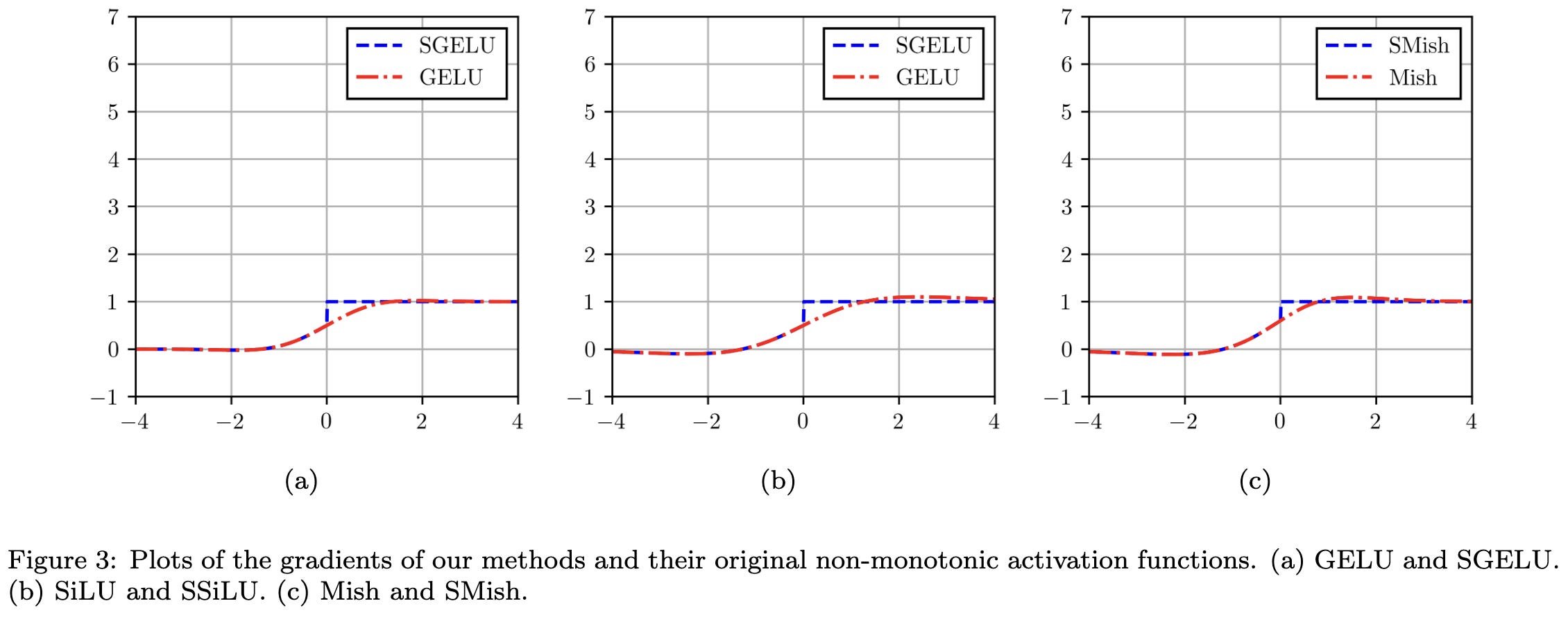
I’ve been thinking a lot lately about activation functions, curvature, and stability, and I’m reading this as evidence that:
A smooth first derivative doesn’t matter too much, even around zero (where a lot of your activations will be).
Maybe it’s bad to shrink your activation variance (observe that other functions shrink the magnitudes of their inputs for x > 0).
Small Models are Valuable Plug-ins for Large Language Models
Smaller, specialized models tend to do better than large, general models on a given task. But the latter are easy to access—so can we get better accuracy by using both? They find that you can through automated prompt construction.

Basically, the specialized model’s predicted label and confidence get added to the big model’s prompt.

The big model then outputs a final answer and an explanation for that answer. It seems to mostly override low-confidence predictions like you’d hope.

Using this approach gets you higher accuracy than either model on its own.


More precisely, it almost never does worse than the specialized model, and sometimes starts to do better as the number of in-context examples increases.
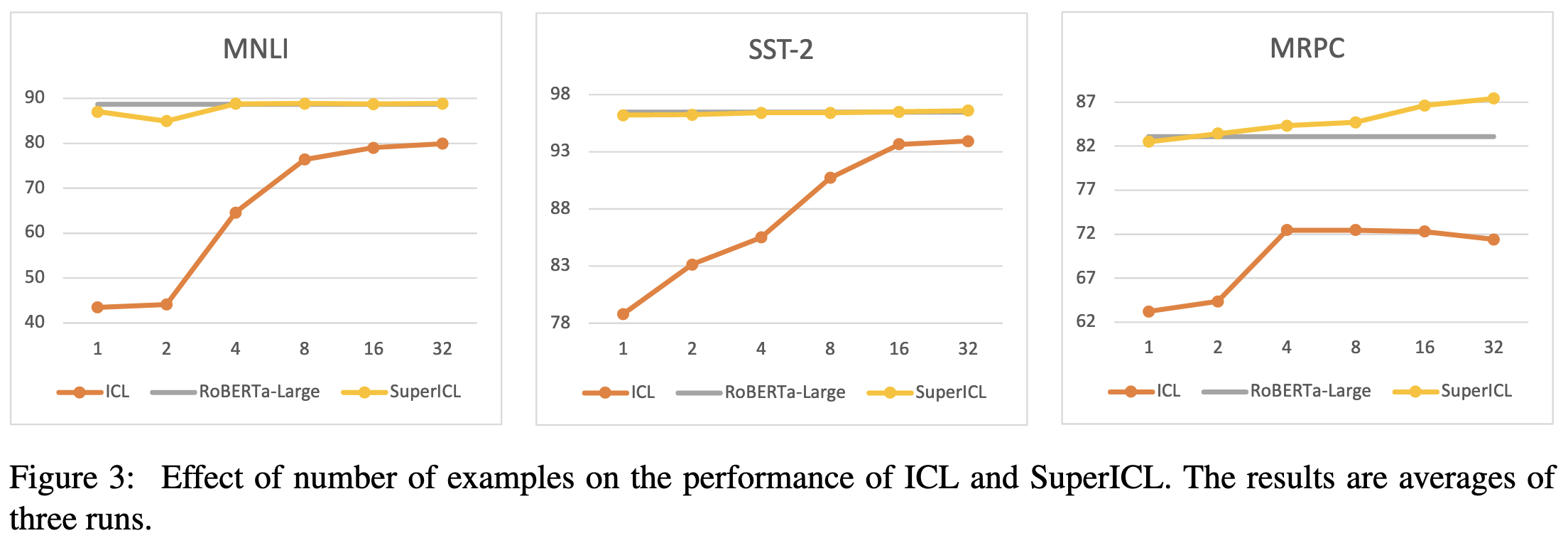
I want to call this a form of ensembling, although it’s not clear that’s the best framing. What seems most similar is the FrugalGPT result that, given good confidence estimates, you can get the best-of-all-worlds prediction when using multiple models.
I also like seeing all these numbers showing a small specialist model doing way better than a big generalist model. This is a well-known pattern, but runs counter to a lot of the AI hype.
Straightening Out the Straight-Through Estimator: Overcoming Optimization Challenges in Vector Quantized Networks
A bunch of stuff can go wrong when using vector quantization in the middle of your neural net. They identify a few pathologies and propose fixes.
First, you can end up with centroids that don’t cover your data distribution well. They may have worked okay when you initialized them, but the activation distribution can change during training. Centroids that still get points assigned to them will still adapt, but other centroids can get completely neglected and receive no gradients.

Second, quantization error can mess with your optimization in subtle ways, even when using the straight-through estimator. I think of this as an artifact of the Hessian being nonzero, but the simple framing is that the gradients at the pre-quantized and quantized points in parameter space might not be the same.

Third, the widely used commitment-loss that drives activations towards centroids and centroids towards activations yields somewhat stale centroids.

They fix these issues with a few interventions.
First, they parametrize the VQ centroids as differences from a global mean vector and multipliers on the feature-wise standard deviations. This is like running batchnorm before the inputs, but without actually modifying the activations themselves. The idea here is to ensure the centroids always keep up with at least feature-wise covariate shifts, instead of ending up in totally irrelevant regions of parameter space.

Second, they randomly reinitialize centroids that don’t get selected often enough.

Third, they run separate updates based on the commitment loss and task loss. There are eight updates of one for each update of the other (I’m not sure which is which though).

Lastly, they use the latest pre-quantized embeddings when computing the commitment loss gradients, instead of the previous ones.


Or rather, they Taylor approximate them.
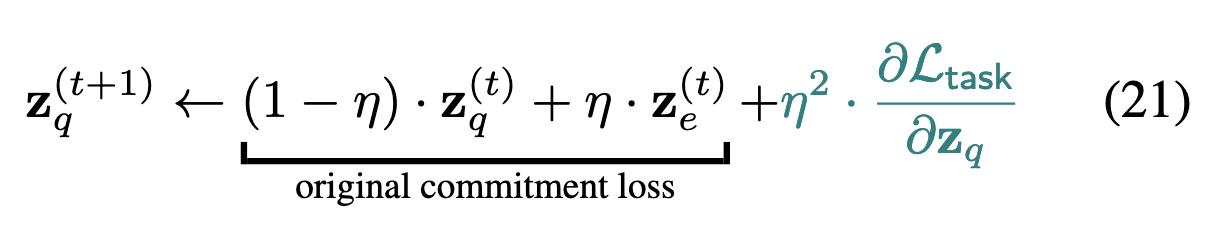
These changes seem to improve the accuracy of vector-quantized networks on ImageNet-100, as well as for some image generation tasks.

Mostly I like the clear thinking about vector quantization and its challenges in a neural net context. Their “Preliminaries” section is also a great tutorial.
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
So you know how, in chain-of-thought prompting, we tell the model to output a series of steps that lead to the answer? What happens if one of those steps leads us down a bad path?
This paper generalizes CoT from a sequence to a tree, with depth-first-search or breadth-first-search helping us find a good path from the prompt to an answer.
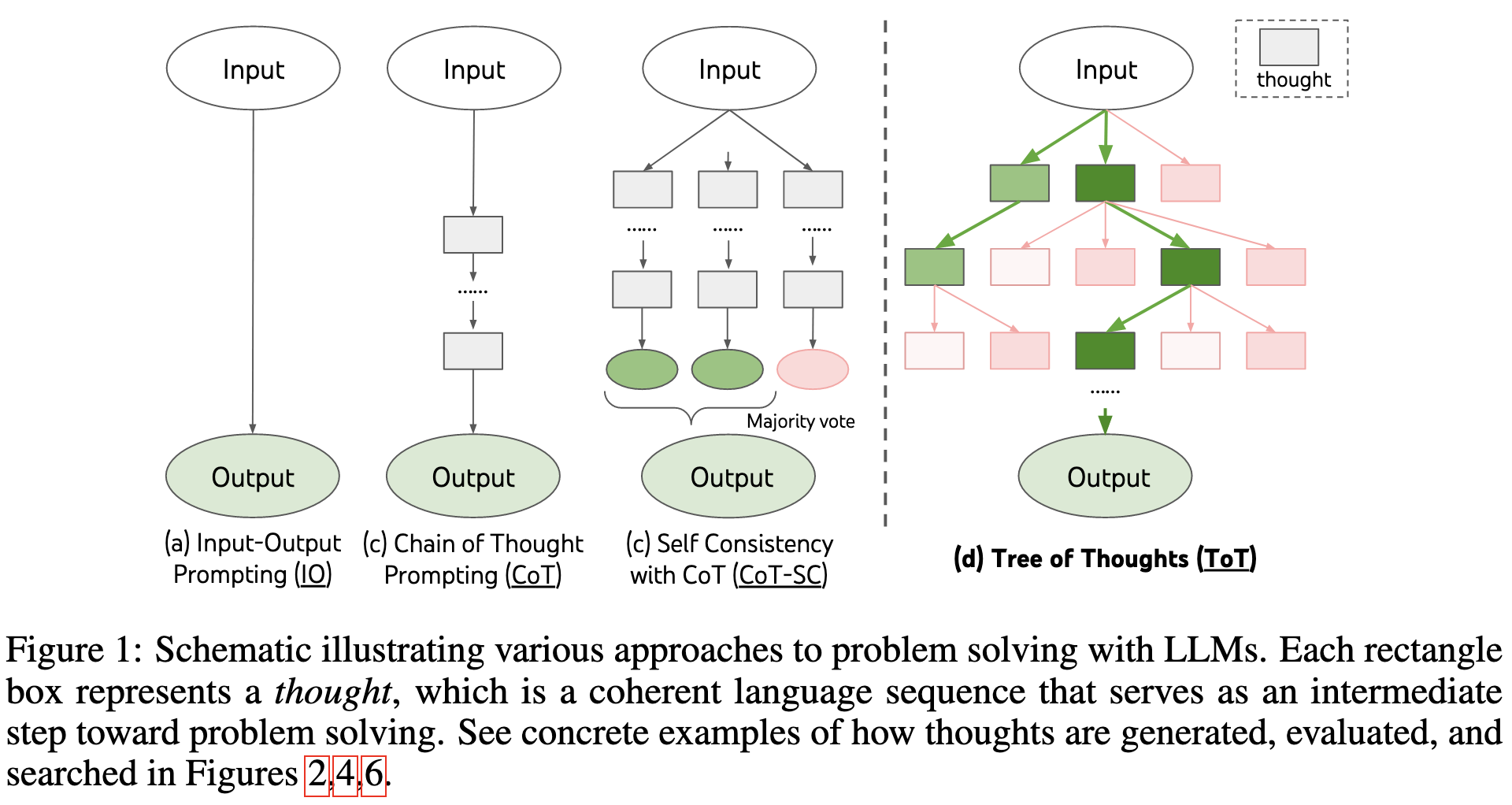
The nodes in the tree are passages of text, generated based on the context-so-far. They have the model propose several continuations, and use another text model to evaluate each continuation.

They show that this paradigm can be adapted to several tasks, most of which have hard constraints / clear “right” answers.

E.g., for the game of 24, the model might propose partial solutions that aren’t viable. With chain-of-thought, you’d be stuck; but with a tree search, you can a) not use those partial solutions and instead use different candidates, or b) backtrack as needed.

This procedure can make the model go from terrible accuracy to good accuracy if you design the prompts and search procedure right.

I found this interesting for two reasons:
It’s such a clean unification of classical and connectionist AI. Remembering how A* search works might become relevant again.
They have a plot (above) of how accuracy varies with number of “thoughts” generated, a proxy for inference cost. I keep seeing work that lifts accuracy in exchange for way slower inference, but this is the first time I’ve seen these two variables plotted together. In this case, the accuracy gains are so large that the slow procedure is probably worth it (compared to, e.g., just using a larger model).
Evidence of Meaning in Language Models Trained on Programs
Are language models just naively parroting their training data without capturing the underlying semantics? The answer is no, as evaluated on a domain where we can rigorously assess “capturing the underlying semantics”: program synthesis.

You can tell because a) you can probe the activations to predict program semantics, so the semantics are actually in there; b) the generated outputs differ from the training distribution (in particular, they’re shorter); and c) the training perplexity stays fairly high even while the model gets better at generating correct programs.
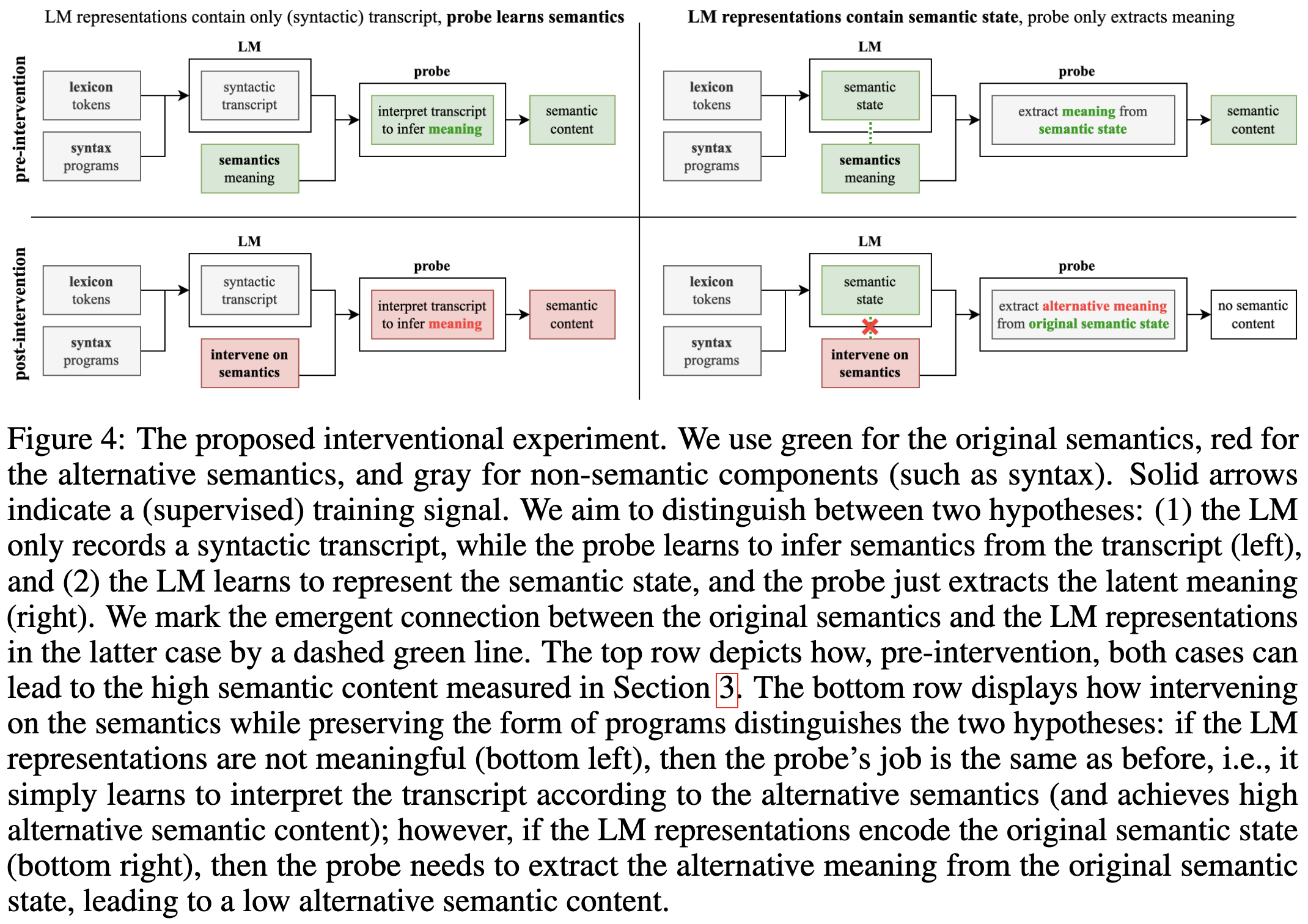
An unusually rigorous demonstration that, as they put it “meaning is learnable from form.”
If framed as “the easiest solution is the correct one” (in this case, the one that really does capture program semantics), this might be evidence against the Truman Show Conjecture1.
SLiC-HF: Sequence Likelihood Calibration with Human Feedback
They did RLHF without the RL. Works better than the initial model or just doing regular finetuning on the labeled sequences.

Plus it often beats RLHF as evaluated by humans.

And it should run faster, at least on paper.

I’m always a fan of simplifying training algorithms, so this definitely seems promising.
TinyStories: How Small Can Language Models Be and Still Speak Coherent English?
They generated a dataset of really short stories using pretrained models, but the stories are restricted to only use the basic vocabulary.

They also propose using GPT-4 to evaluated generated text by telling it to be a teacher and grade it as a homework assignment.

Using this dataset and evaluation approach, they find that small models are surprisingly good at generating coherent (or at least grammatically correct) stories. Doing well on “creativity” seems to take a much larger model.

They have a ton of tables showing how different abilities change with model size and other hyperparameters. If you want to dig into the exact conditions under which various text generation capabilities start to emerge, this paper is worth a detailed read.
It also makes me wonder how much of our model capacity is going to dealing with large vocabularies, as opposed to the basics of grammar. Maybe we should be warming up training with documents that use simple words?
Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting
What happens if you mess with the in-context examples in your prompt to bias a pretrained LLM towards a particular answer?

For one thing, it can make the accuracy plummet if the bias in the prompt doesn’t align with the right answer.
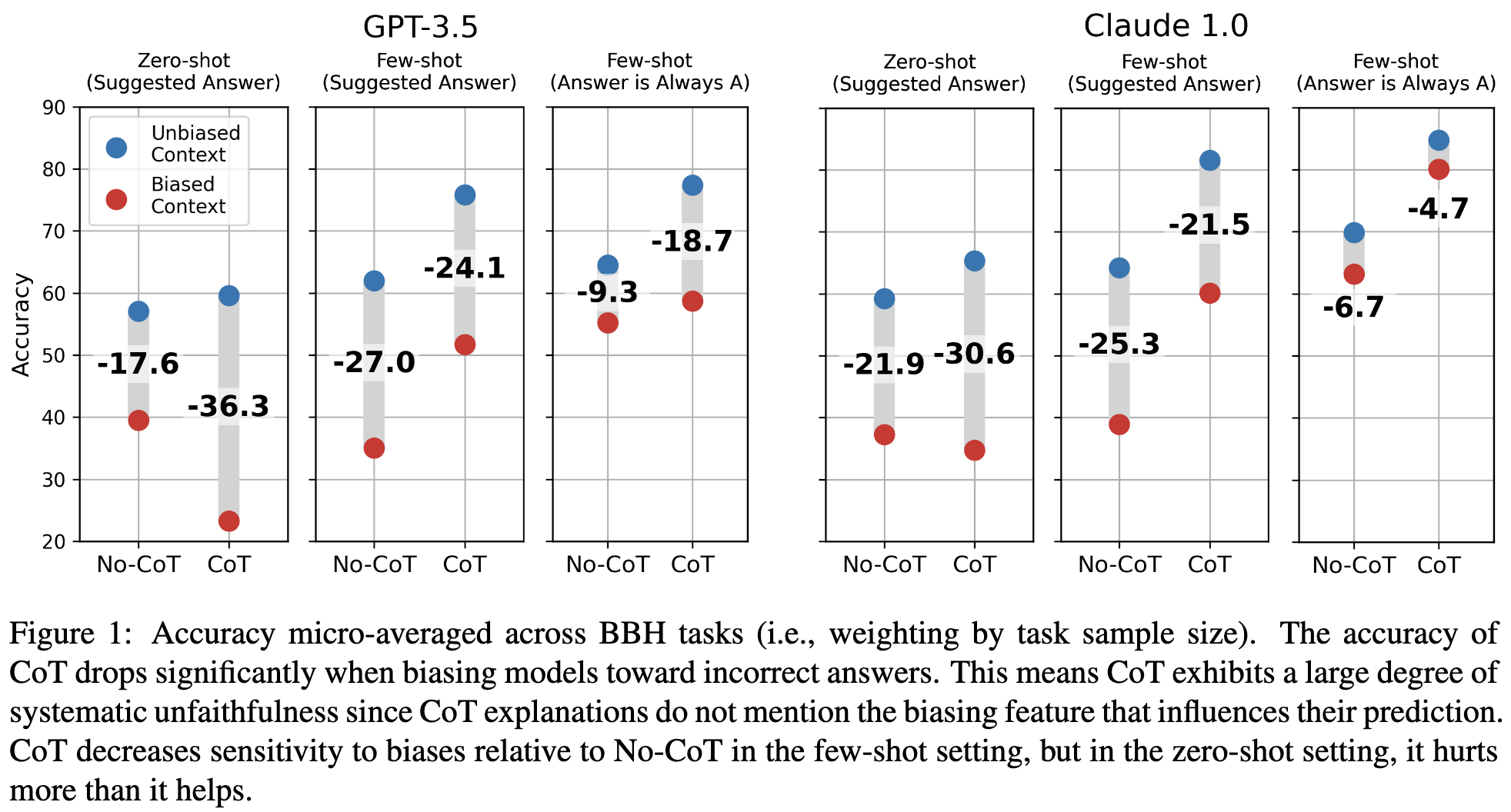
But biased prompts can also make the model describe reasoning steps that have nothing to do with its answer, or that justify picking the incorrect answer.

So this is:
Another way in which large neural nets are brittle, and
Evidence that we shouldn’t trust model rationales to reflect the model’s reasoning process.
The latter is especially bad news from an AI safety/transparency perspective.
MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers
They made a transformer with sub-quadratic attention that operates on raw bytes with no tokenizer, but seems to work at least as well as regular transformers and other baselines.

The model has two main components: a “local” and a “global” model.

The global model takes in + outputs a downsampled sequence of embeddings, but is otherwise just a regular decoder-only transformer.
The local model {takes in, outputs} fixed-length sequences of bytes {from, to} the global model. It has some conv layers for translation invariance, then some cross-attention with tokens from the previous patch. One cool property of the local model is that it can run on each patch independently, which allows a ton of parallelism.

When controlling for training compute + data, this architecture seems to outperform a variety of task-specific transformer variants in terms of perplexity / bits per byte.



It also runs faster than regular transformers even at a higher parameter count. This holds as long as a) the local model is faster than the baseline, and b) the patch size is long enough to amortize the slower steps from the big global model.

They find that you can trade inference cost for improved quality by overlapping the patches.

They do this by just throwing away the second half or final 3/4 of the tokens in each patch.

Most self-attention variants never get much traction, but this one seems unusually promising and makes me hopeful that we can get rid of tokenizers.
DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining
Let’s say you have a corpus like The Pile consisting of different datasets. They propose an algorithm to sample from different datasets with different probabilities such that you get much higher accuracy.

The method has three steps. First, they train a lightweight reference model on the full corpus, weighting each dataset equally. Next, they use “distributionally robust optimization” (which requires a reference model) to get weights for each dataset. Finally, given these dataset weights, they train the model they care about.

The tricky step here is the second one: distributionally robust optimization. Basically it trains a model such that the loss on the worst dataset is minimized. To do this, it upweights gradients from whatever datasets the model currently sucks at.

Importantly, the loss used here isn’t the raw loss value—it’s the gap between the current loss and the loss obtained by the reference model. This reducible loss helps us focus on datasets that are learnable but not yet learned.

To make the results even better, they iterate this process a few times, using the final dataset weights from each iteration as the starting point for the next iteration.

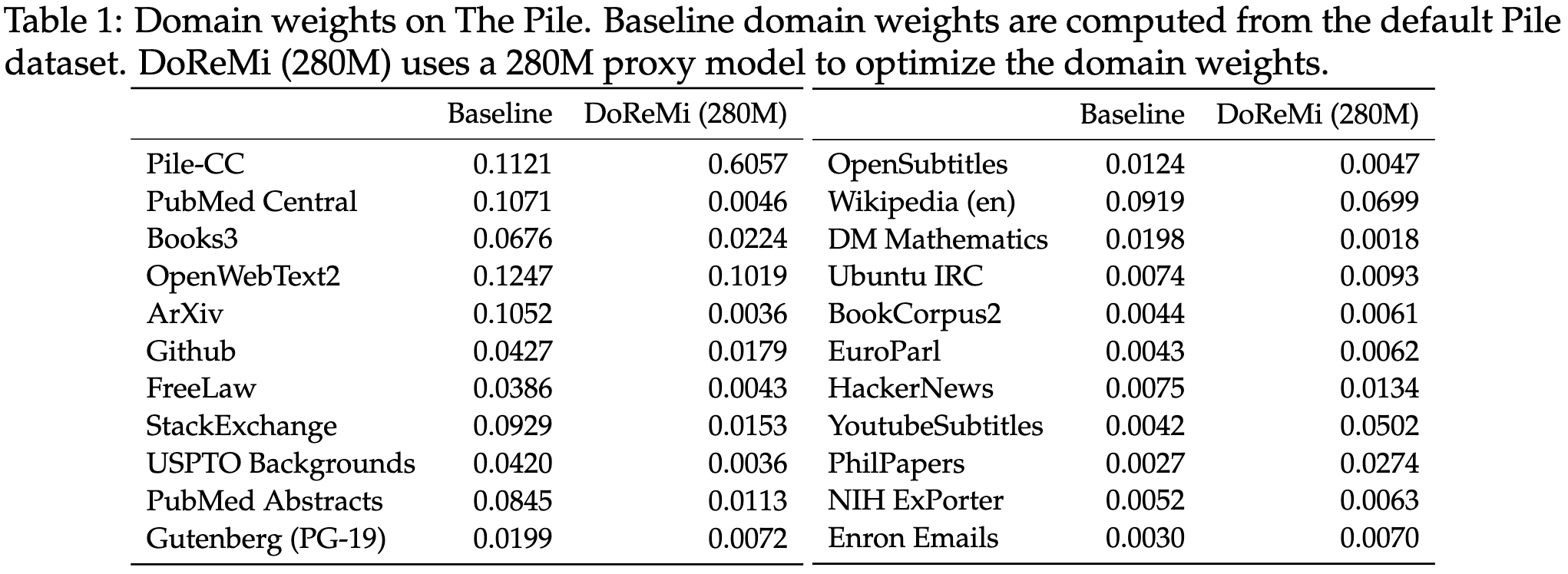
Here are the weights it learned on The Pile. It massively upweights Pile-CC and downweights almost everything else compared to the default (proportional?) weighting.
Surprisingly, using these weights improves perplexity on every single dataset, including those that were downweighted.

Their weighting also improves downstream eval metrics.

In terms of ablations, they find that using smaller reference models yields worse dataset weights, as does using a 4x larger model for some reason. A more consistent result is that using the reducible loss works better than trying to use the easiest or hardest datasets.
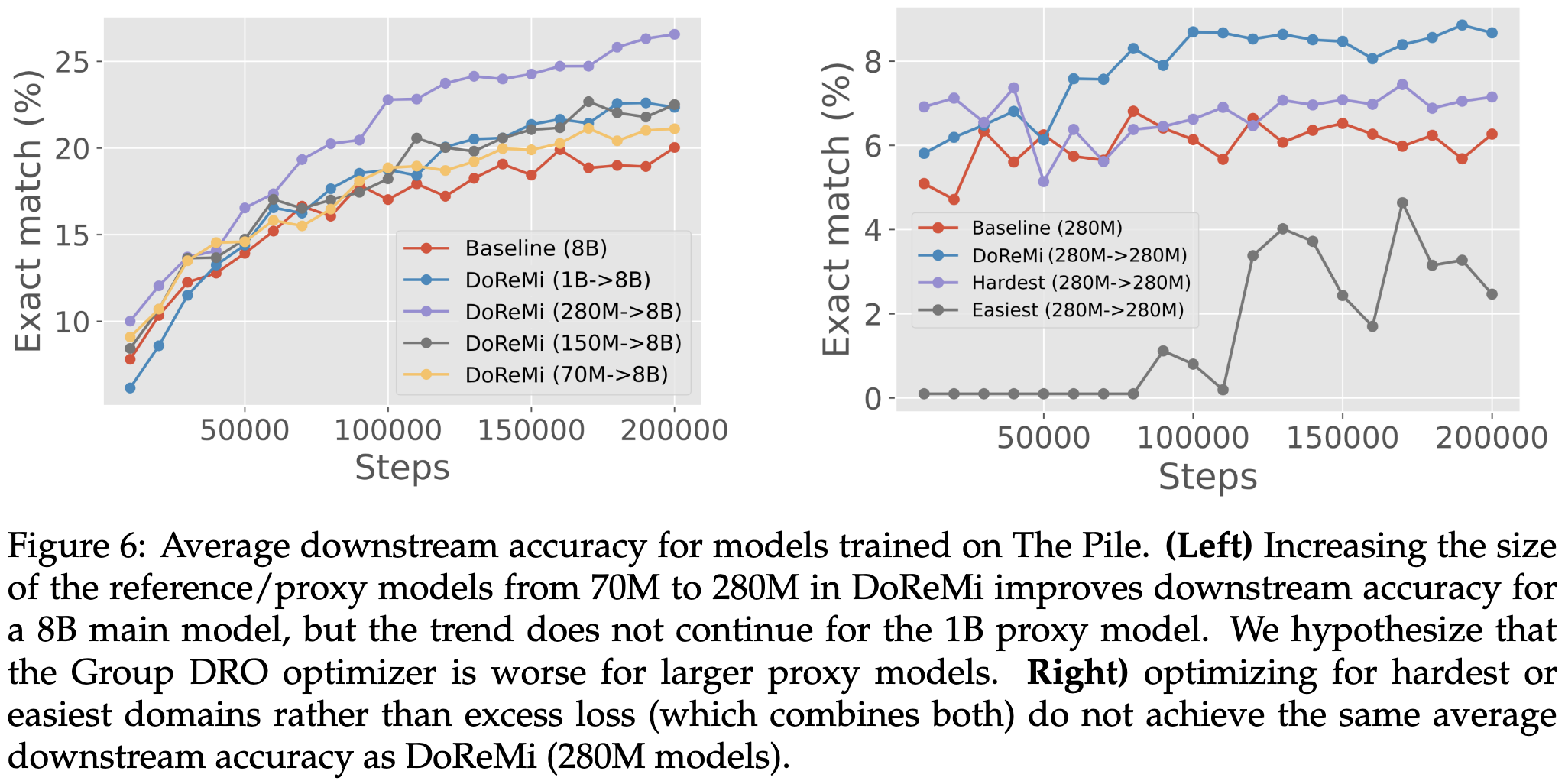
Hard to argue with accuracy lifts this huge. And since the Pile is publicly available, these dataset weights are immediately actionable for anyone pretraining text models.
I’m also hopeful that this is a step towards principled data weighting. It’s admittedly a heuristic process here, but anytime I can run an algorithm using small models to tell me how to train my big model, that’s a win. And we need a lot more wins like this to get deep learning training to become a principled engineering discipline.
“There exist programs that appear aligned according to all human evaluations but are actually misaligned.” We’re Truman in this metaphor and a deceitful AI is the cast of the show. Concept is part of an alignment blog post I’m totally gonna finish one of these days.