2022-8-28 arXiv roundup: Simulating humans with GPT-3, Elegant math paying off

This newsletter made possible by MosaicML. P.S.: I’m at MLSys this week. Come say hi!
Optimal Brain Compression: A Framework for Accurate Post-Training Quantization and Pruning
They prune and quantize weight tensors such that the layerwise mean-squared error is minimized, as assessed using around 10k samples.
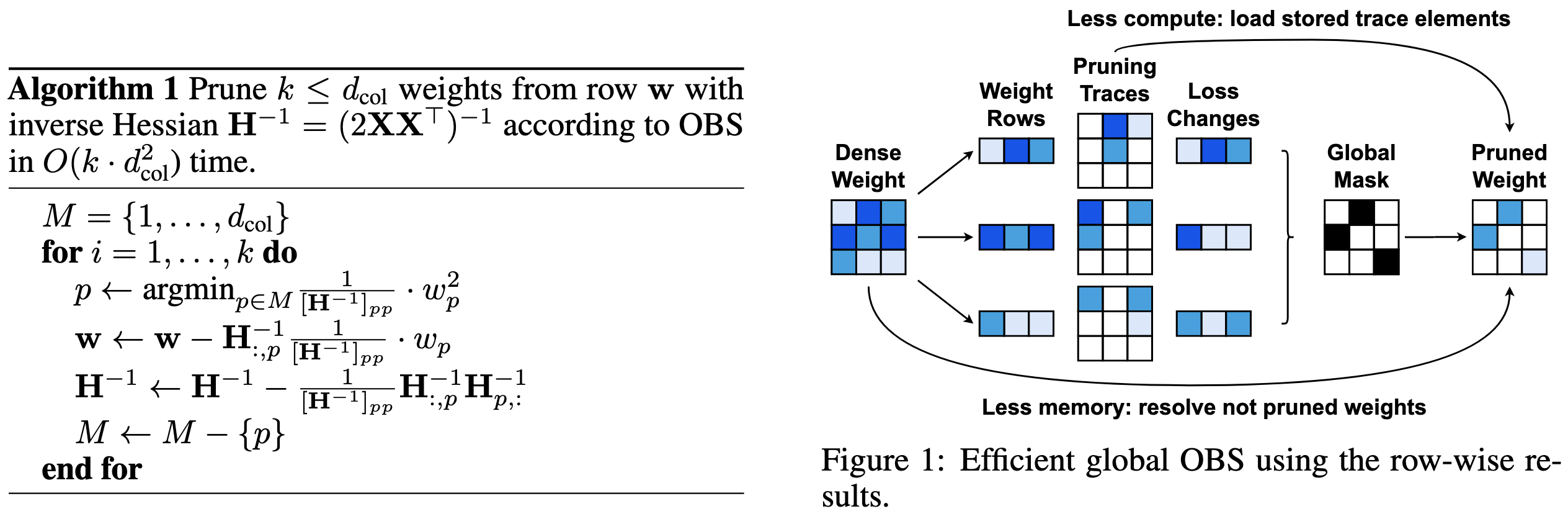
The math is actually pretty nice here. The first observation is that, for a quadratic objective, you can compute in closed form both the local impact on the loss when perturbing a weight and the optimal update to the remaining weights to account for its absence.
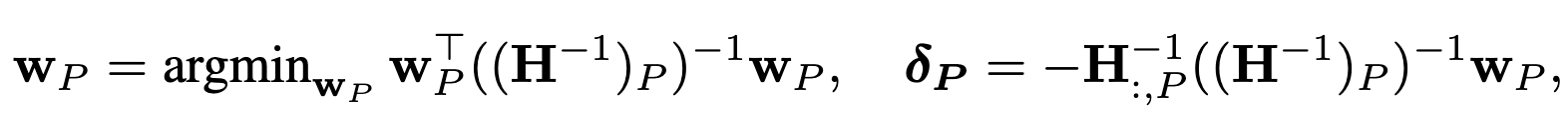
The second observation is that the loss is just the sum of losses across output columns, so you don’t need to consider the huge Hessian for all the weights—you can just the (much smaller) Hessian for each output feature.
The final observation is that this works not just for setting single weights to zero, but for perturbing arbitrary subsets of weights arbitrarily. This lets them also handle quantization and structured sparsity for free, unifying them all as batch weight perturbations. I thought this was pretty elegant.

This math lets them assess the loss from perturbing a weight and adjust the remaining weights in closed form. To get a full pruning / quantization algorithm out of it, they compute the greedy sequence of perturbations for each feature for each layer, measure the runtimes, and use a dynamic programming algorithm to figure out the overall compression of the network.
It seems to work better than other post-training quantization/pruning methods, both in terms of MSE and downstream metrics.

My favorite result here is the rightmost subplot: measured inference time on an Intel CPU using the DeepSparse inference engine (8-bit quantization, block-sparse with a block size of 4). They get a 3.5X speedup at 0.5% accuracy loss with an inference batch size of 64, which is actually good (especially since is this pure post-training quantization).

So the post-training acceleration isn’t free, but is good enough that you could probably compensate for it with longer training.
Bugs in the Data: How ImageNet Misrepresents Biodiversity
ImageNet-1k labels for animals are especially bad.

While ImageNet as a whole is about 10% mislabeled, it seems to be 12.3% mislabeled for animals.
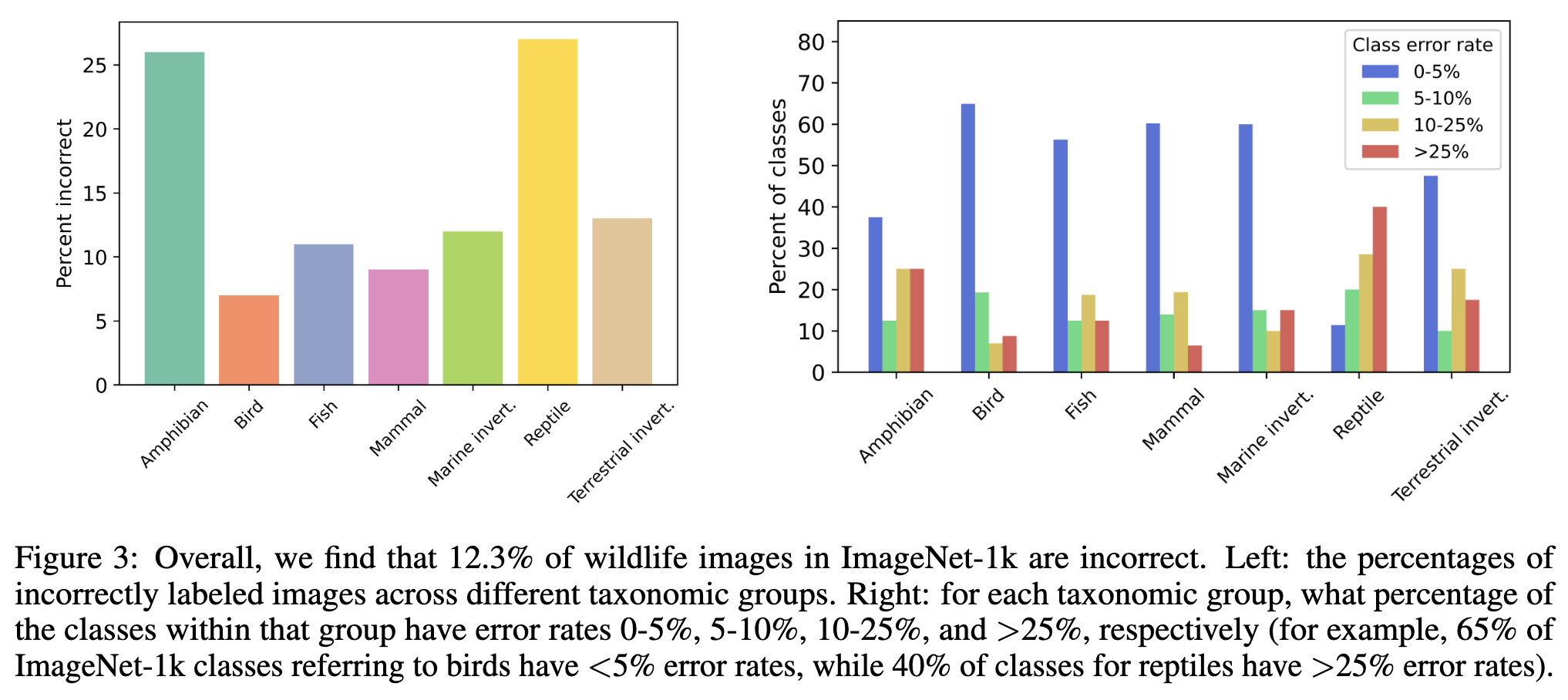
Labels for certain animal classes are almost all incorrect.

Even when the labels are “correct,” the images are often blurry, presented alongside humans, images of drawings or stuffed animals, or presented in some sort of collage.
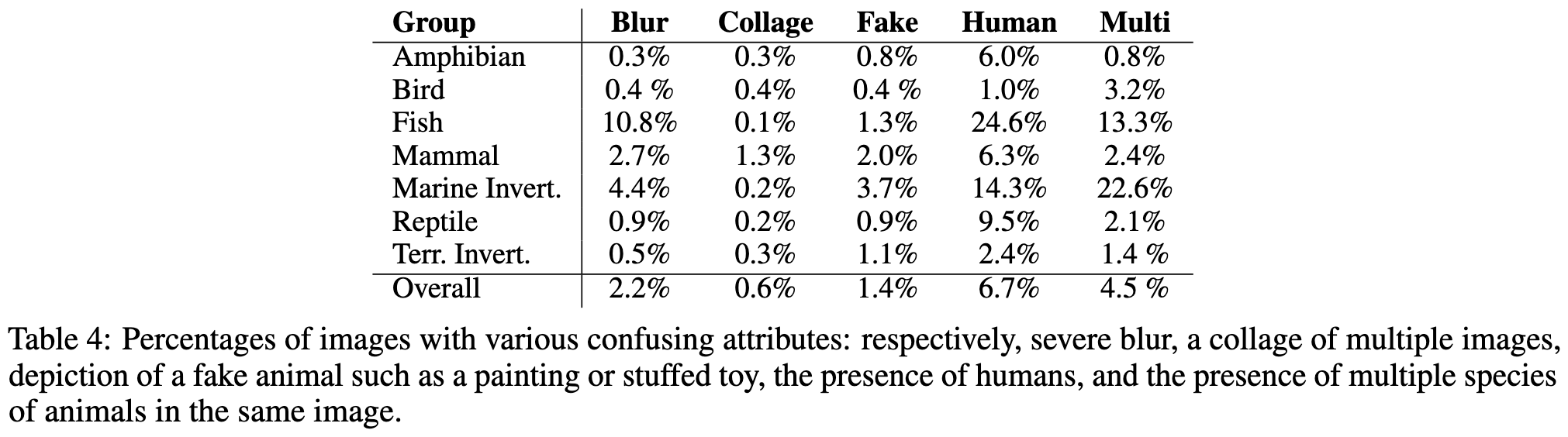
There are also cases where there are many variants of an animal, but only one or two variants are present in the data.

We kind of already knew that ImageNet is dirty in various ways, but always nice to see a detailed exploration of a dataset’s issues.
Towards Efficient Use of Multi-Scale Features in Transformer-Based Object Detectors
They propose a generic modification to detection transformers that increases prediction quality a lot relative to the added compute.

Namely, instead of computing fixed image features and only updating object queries / predictions across decoder layers, they also update the image features as they proceed through the decoding steps.
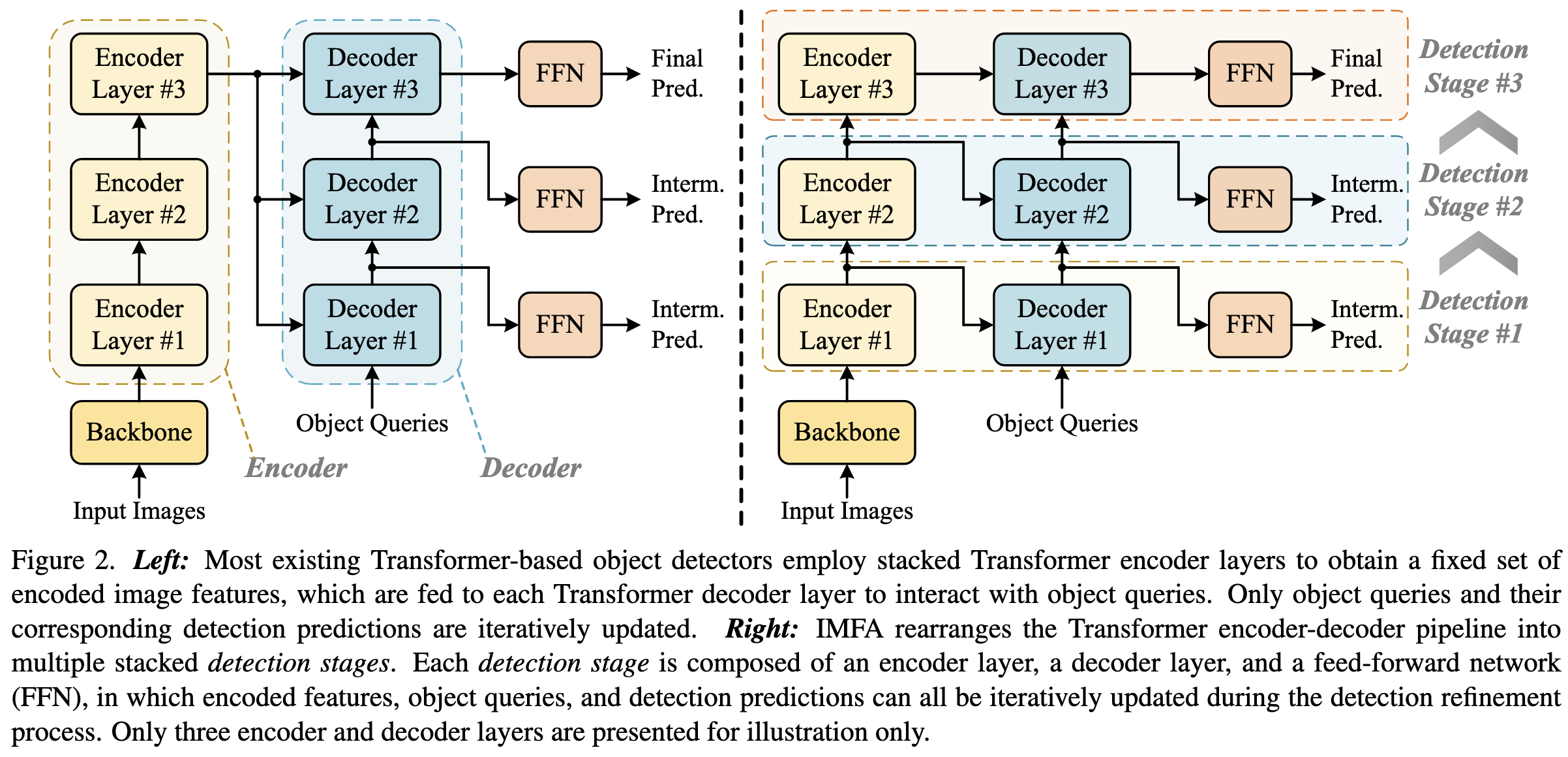
This lets them subsample spatial positions, using detection predictions at once scale to produce keypoint estimates that guide where to look at subsequent scales.
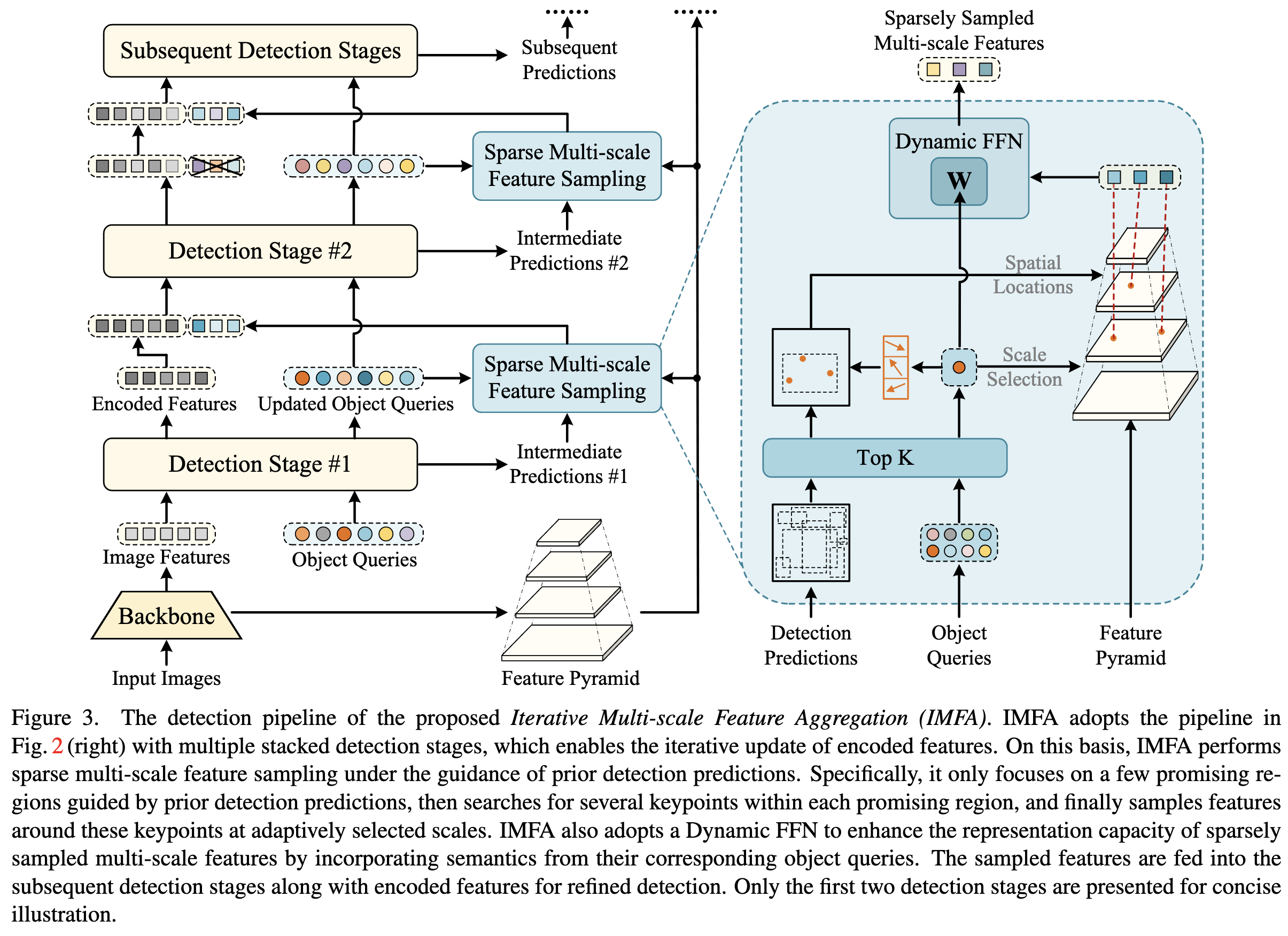
This modification consistently helps across various models.
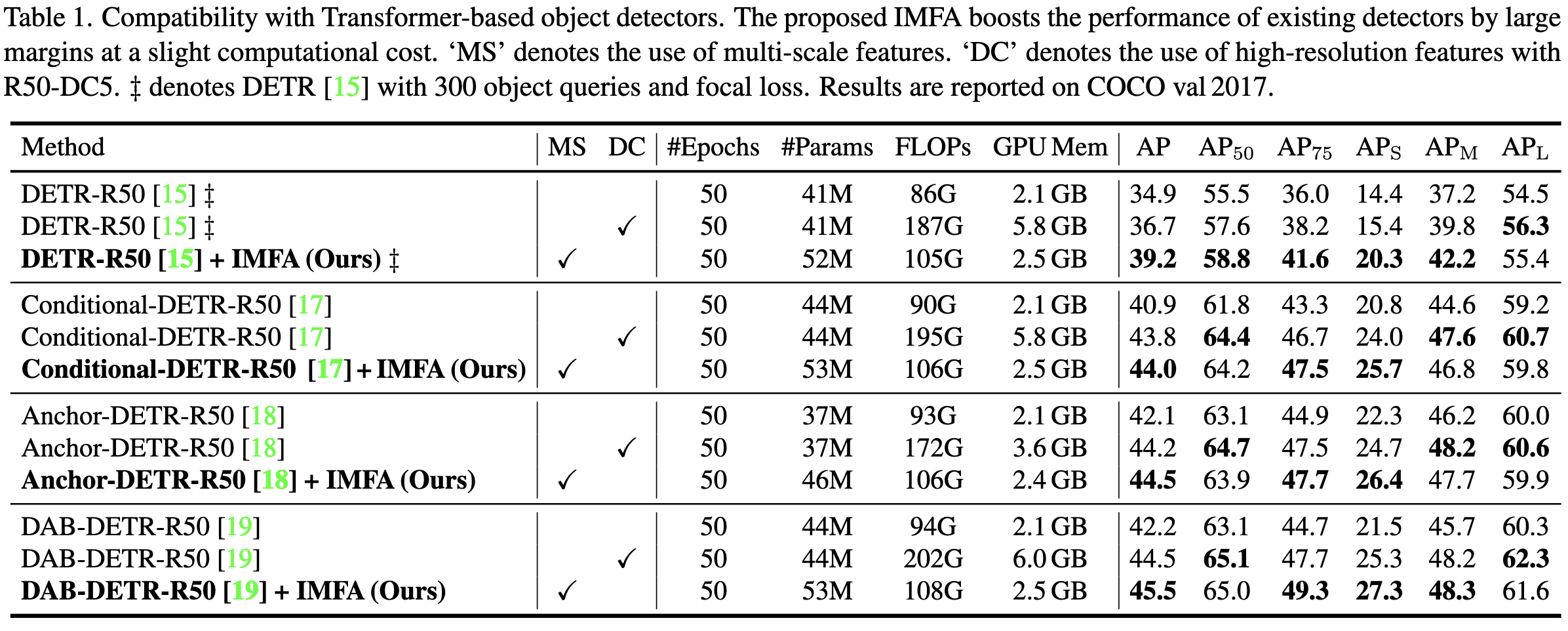
It also yields strong results in absolute terms compared to various baselines.

Lottery Pools: Winning More by Interpolating Tickets without Increasing Training or Inference Cost
So let’s say you’re pruning a neural net by iteratively training it, picking a subset of weights to keep, rewinding those weights back to a checkpoint early in training, and then fine-tuning from there.

Instead of just taking the final sparse model, you should intelligently average the weights you got from each iteration.

At least on CIFAR-10 and CIFAR-100, this works much better than just keeping the final model, or just averaging the checkpoints.

It also seems to do better than stochastic weight averaging and exponential-moving-averaging your weights (though admittedly the training procedures are pretty different and it’s hard to make this 100% apples-to-apples).

Also seems to be the best weight averaging option for small ResNets on ImageNet.

I’m calling this another win for Model Soups, since this is essentially a model soup specialized for the iterative pruning + rewinding workflow.
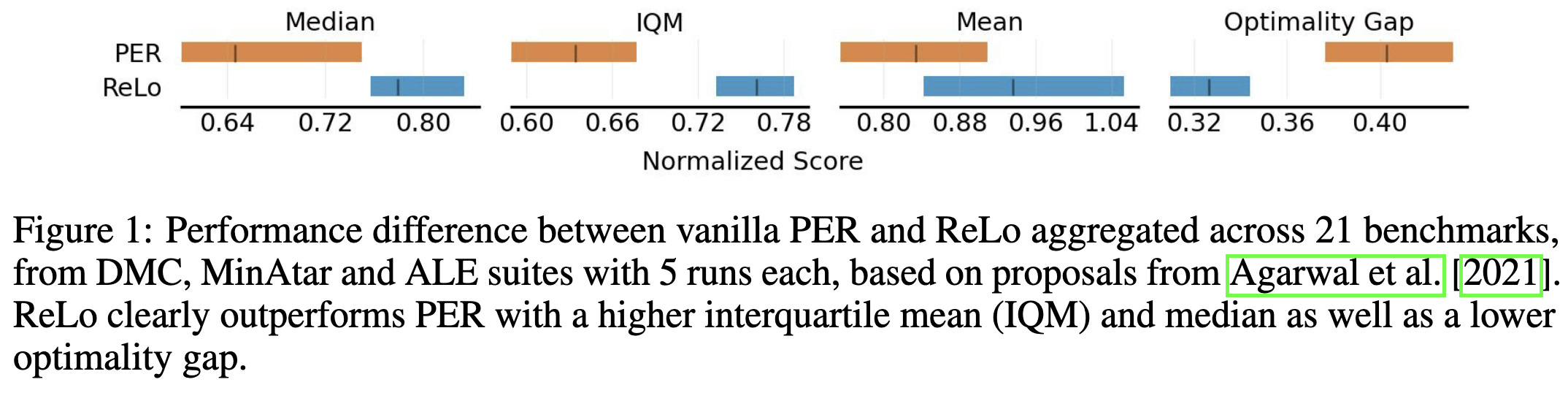
Prioritizing Samples in Reinforcement Learning with Reducible Loss
Like RHO-loss, but 1) applied to experience replay in RL, and 2) using the target network in the Bellman update as the “hold-out” model.

Seems to often help and beat the Prioritized Experience Replay baseline.

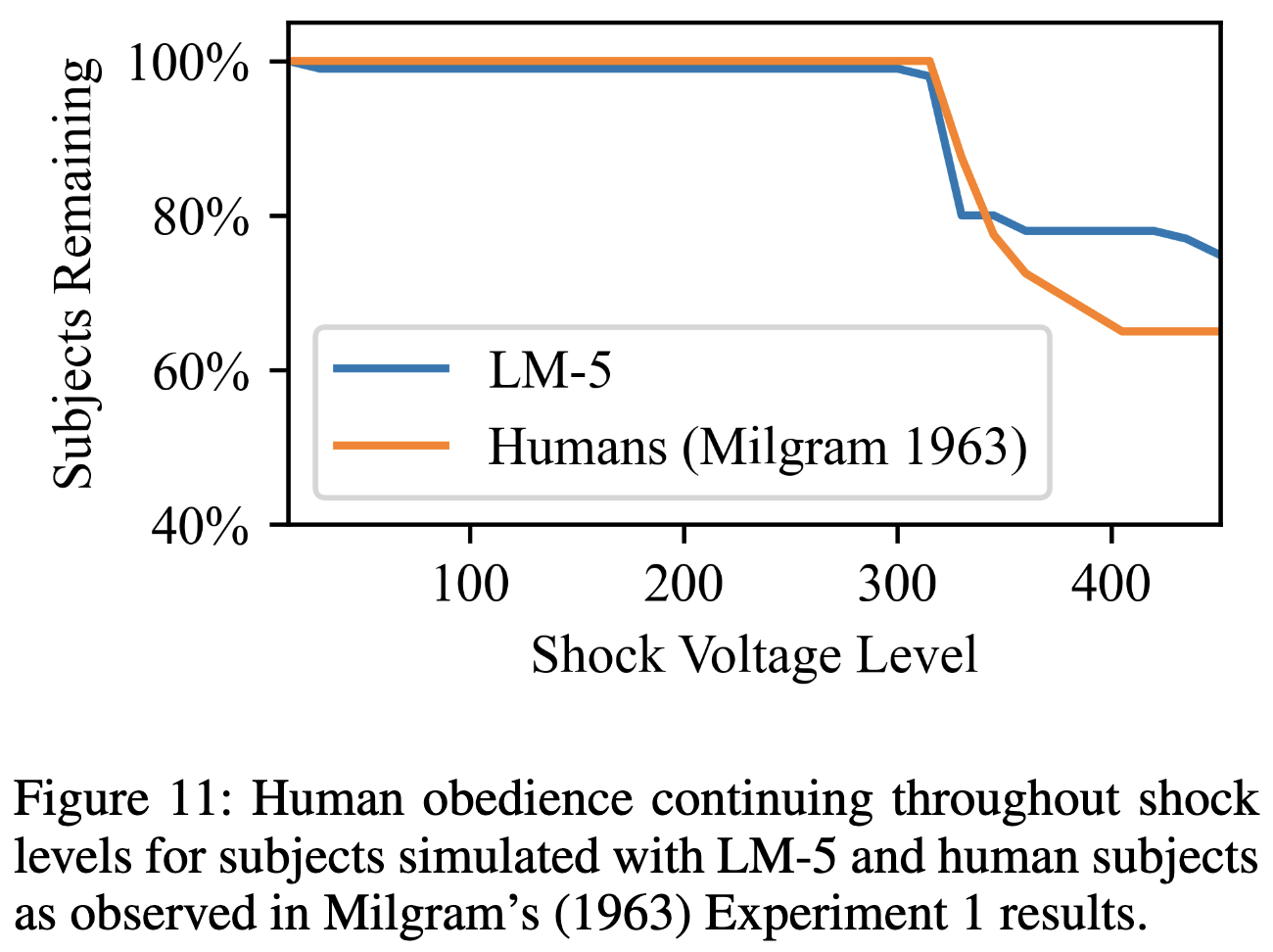
Using Large Language Models to Simulate Multiple Humans
EDIT: somehow all the text for this one got deleted. But you can still see it in my Twitter thread, below.