
2022-10-23 arXiv roundup: CNNs dominating sequence modeling, SetFit, Google finetuning trifecta

This newsletter made possible by MosaicML.
Note: the first three papers all go together and you kind of need to read about them in order.
UL2: Unifying Language Learning Paradigms
They frame prefix language modeling (text completion) as just another form of masking, and propose pretraining using a random combination of different masking strategies.
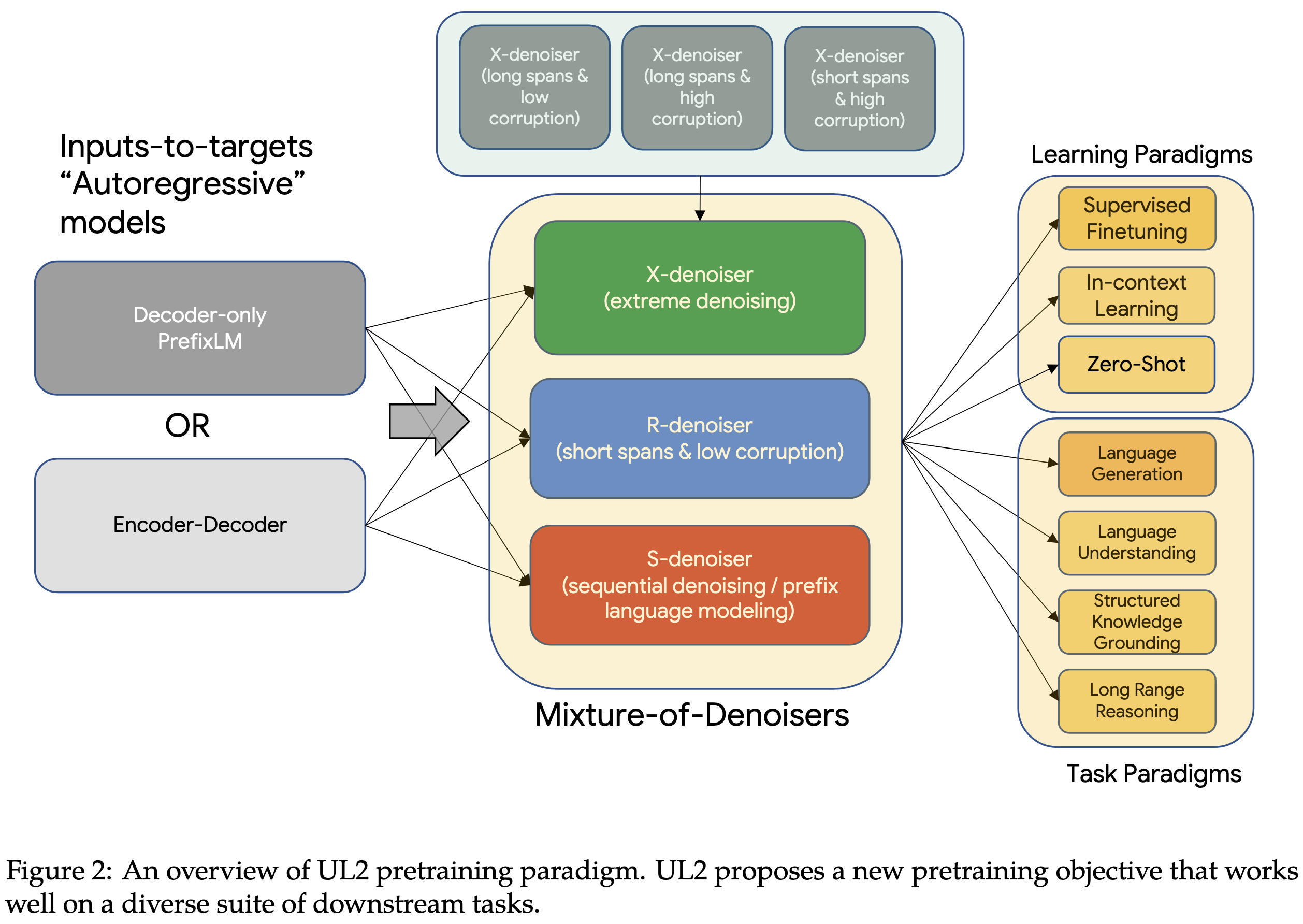
The core masking strategies are R-denoising (masked spans), S-denoising (text completion) and X-denoising (“extreme” span masking, in terms of length or frequency).

There are some specific hparams for how they structure the noise.

Also, they also feed the model a “paradigm” token for each input that tells it which type of noise it’s dealing with—one of “[R]”, “[S]” or “[X]”.
With decoder-only models, span corruption (SC) seems to do the best for supervised finetuning, while the proposed UL2 does the best for one-shot eval—though the gaps between best and second-best aren’t significant. For encoder-decoder models, UL2 always beats span corruption.

The above results also show that encoder-decoder models tend to perform better than decoder-only models, though this is likely because they held compute fixed rather than parameter count.
When scaling up to a 20B parameter encoder-decoder model, UL2 allows them to beat the previous state-of-the-art on various tasks.

On top of the gains from their noising scheme, this 20B param model benefits from chain-of-thought prompting and a self-consistency loss.

At test time, which “paradigm” you tell the model to use can affect the results significantly. Telling it to fill in masked spans (like a BERT) works best for XSum, while all three approaches are about the same for SuperGLUE.

Kind of surprising they were able to beat the state-of-the-art on so many tasks, when the ablations didn’t show that much of an advantage. But I guess adding a consistent win to a near-SOTA baseline will do it.
And speaking of surprisingly good results, let’s move on to:
Transcending Scaling Laws with 0.1% Extra Compute
They make PaLM variants significantly more accurate with just a little bit of finetuning.

The finetuning they use is a mix of different masking strategies taken from the above UL2 paper—namely: normal masked span corruption, masked span corruption with tons of masking, and regular old text completion.
The benefits are largest in relative terms for smaller PaLM variants, though look fairly consistent in absolute equivalent FLOPs.
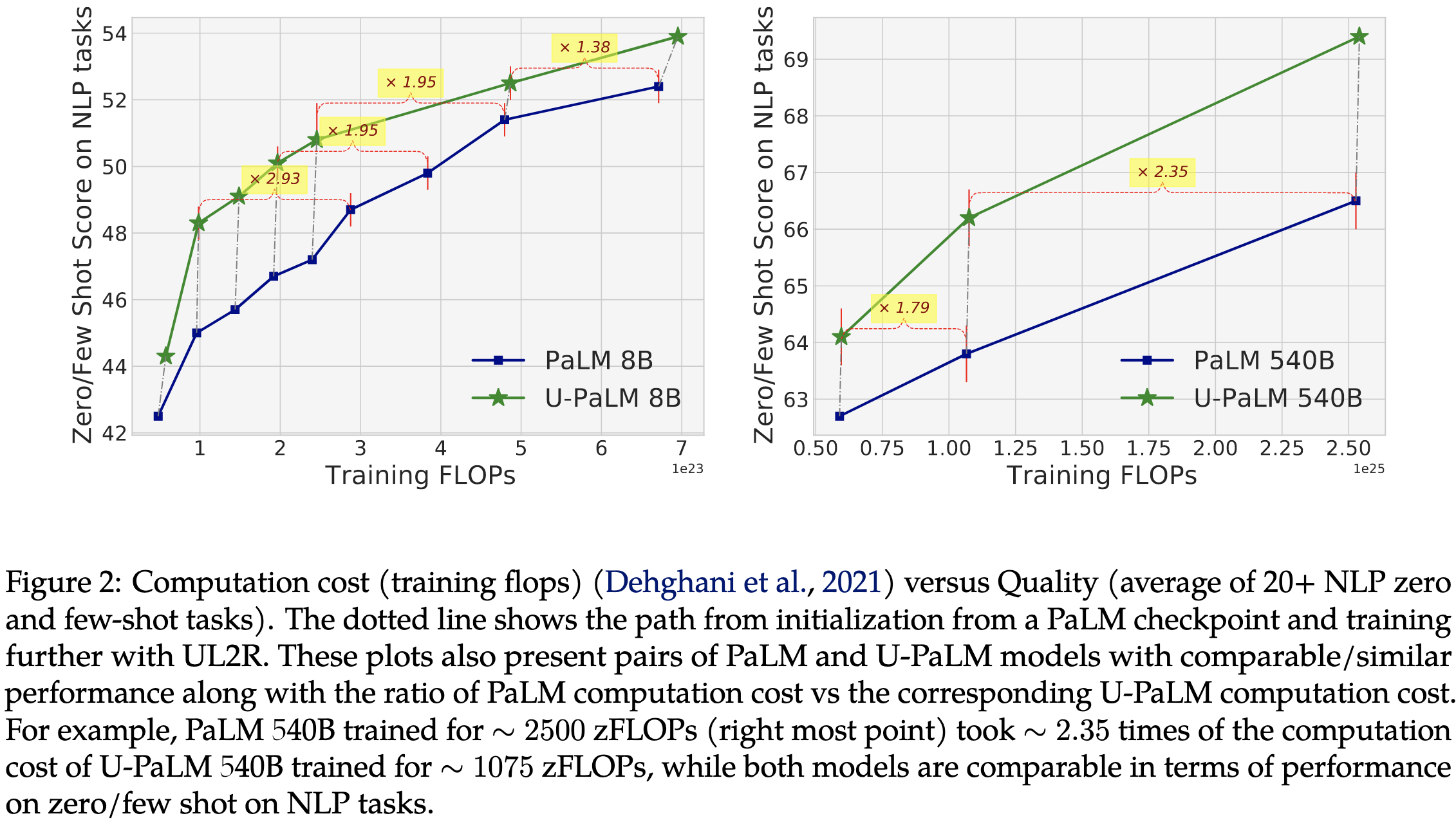
Their mixed denoising finetuning offers a consistent win across a variety of tasks.




There are also some qualitative differences in capabilities, stemming from the model knowing how to handle different denoising modes. E.g., instead of asking it for the completion of a text, you can ask it for what goes in the middle.

Because of these differences, you can sometimes do even better by telling the model to use a specific denoising mode.

Based on the breadth and consistency of their results, the accuracy lifts seem to be real. But I’m not clear on where they’re coming from. Why should training with different masking strategies help so much? And does one actually have to pretrain with a different objective first? Or should we just always be using a mixture of masking approaches?
On a different note, I don’t see any evidence that they’ve “transcended” scaling laws. They improved the time-to-accuracy Pareto frontier, just like dozens of other techniques. But they don’t show, e.g., a scaling pattern better than a power law.
Overall, great results and an extremely thorough evaluation though.
But not as good as the results in the last paper of our trifecta:
Scaling Instruction-Finetuned Language Models
They jointly finetune models on a huge number of tasks, many of which feature explicit instructions and/or chain-of-thought prompts.

And wow, they really evaluated the crap out of this. 1836 tasks spanning 473 datasets is a lot.

If you’re not familiar, here’s what they mean by having a chain-of-thought (CoT) prompt or an instruction. It’s basically what it sounds like. The hard part here is data acquisition—these are handcrafted input-output pairs, not just random excerpts from web pages.

Before getting to accuracy results, they first point out that their proposed finetuning takes almost no compute compared to the pretraining.

As far as accuracy, jointly finetuning on more tasks helps, though there are diminishing returns.

Whether larger or smaller models benefit more depends on how you measure it; smaller models gain more accuracy on both an absolute and relative basis, but larger models have a higher relative reduction in error rate.

The benefits of their finetuning method are consistent across many benchmarks.

Adding in chain-of-thought finetuning doesn’t hurt accuracy on non-chain-of-thought tasks. But the reverse doesn’t hold—finetuning on non-CoT data can hurt accuracy on CoT tasks. Luckily, you can’t go wrong jointly finetuning on CoT and non-CoT data.

Even a little bit of chain-of-thought finetuning lets PaLM do better when prompted with “let’s think step-by-step” at the end.

The benefits of instruction finetuning hold across a variety of models, including the U-PaLM we just saw in the previous paper. Finetuning with U-PaLM’s mixture of denoising objectives followed by instruction finetuning yields some crazy high numbers (bottom row). The benefits of the instruction finetuning seem much larger than those of the denoising finetuning.

As a final evaluation, they have humans rate the outputs of their finetuned PaLM and the original PaLM. As you might expect, their PaLM is better.

Along with InstructGPT and other previous work, these results indicate that finetuning language models to follow instructions yields a huge lift for downstream accuracy. So much so that this feels like it will become standard practice in the near future. It’s also cool that this approach composes so well with UL2’s mixture of masking strategies.
LAION-5B: An open large-scale dataset for training next generation image-text models
The LAION 5B dataset of image-caption pairs has been an ongoing project for a while, and it looks like they’re officially “releasing” it now. Super valuable contribution to the community. To get the data, they scrape image-caption pairs from the internet and use a pretrained CLIP model to filter out pairs where the caption doesn’t seem to go with the image. So it’s noisier than something like OpenImages, but ~1000x larger.

Active Image Indexing
Let’s say you’re uploading images online and you want to be able to find near-duplicates that someone else uploads (derivative works, copyright violations, etc). This is the task of “image copy detection.”
Their approach is to imperceptibly alter the initial images such that they end up farther from the boundaries of adjacent cells in the similarity search index.

To do this, they optimize over the input with losses that limit distortion in both the original and embedding spaces. The optimization uses perceptual information (Just Noticeable Differences) to inform the learned perturbation.

Adding this input optimization helps quite a bit.

I’m not super invested in this problem, but I see similarity search papers by Jégou and Douze together as mandatory reading.
DALLE-2 is Seeing Double: Flaws in Word-to-Concept Mapping in Text2Image Models
Describes systematic quirks of DALLE-2’s text-to-image mappings.

Essentially, rather than picking one meaning for a word, it often incorporates multiple meanings into the image. I think of this as returning a posterior mean rather than mode in a multi-modal distribution.

As another example, here are multiple meanings of “bass” and “fan” in a single image.

You can also get one word modifying multiple other words.

You can even get association effects, where a word’s texture or typical background can affect other parts of the scene.


Putting it all together, this feels like some of the old DeepDream results, where the activation-maximizing input was often one object over and over again in various poses blended together in a trippy way.
My mental model is now that text-to-image networks are basically doing: “put the following words in the image as much as possible, subject to the constraint that it looks like it could come from your training set.”
Efficient Few-Shot Learning Without Prompts
They propose SetFit, a finetuning method for sentence transformers that’s much more sample efficient.

They finetune in two stages. First, they train the network to make embeddings for sentences from the same class more similar to each other embeddings from different classes less similar. They do this using a triplet loss, where sentences in each triplet have two samples from one class and one sample from another.

What’s so powerful about the triplet loss is that, with N samples, you get roughly N^3 possible sets of samples. At least according to the intuition they offer, this is similar to having a much larger training set.
After finetuning with the triplet loss, they add + train a linear classification head.
They evaluate this approach using several pretrained models.

Their 110M-parameter model does about as well as the 3B parameter T-Few model. These two methods tend to do the best, though it’s hard to eyeball what’s statistically significant.
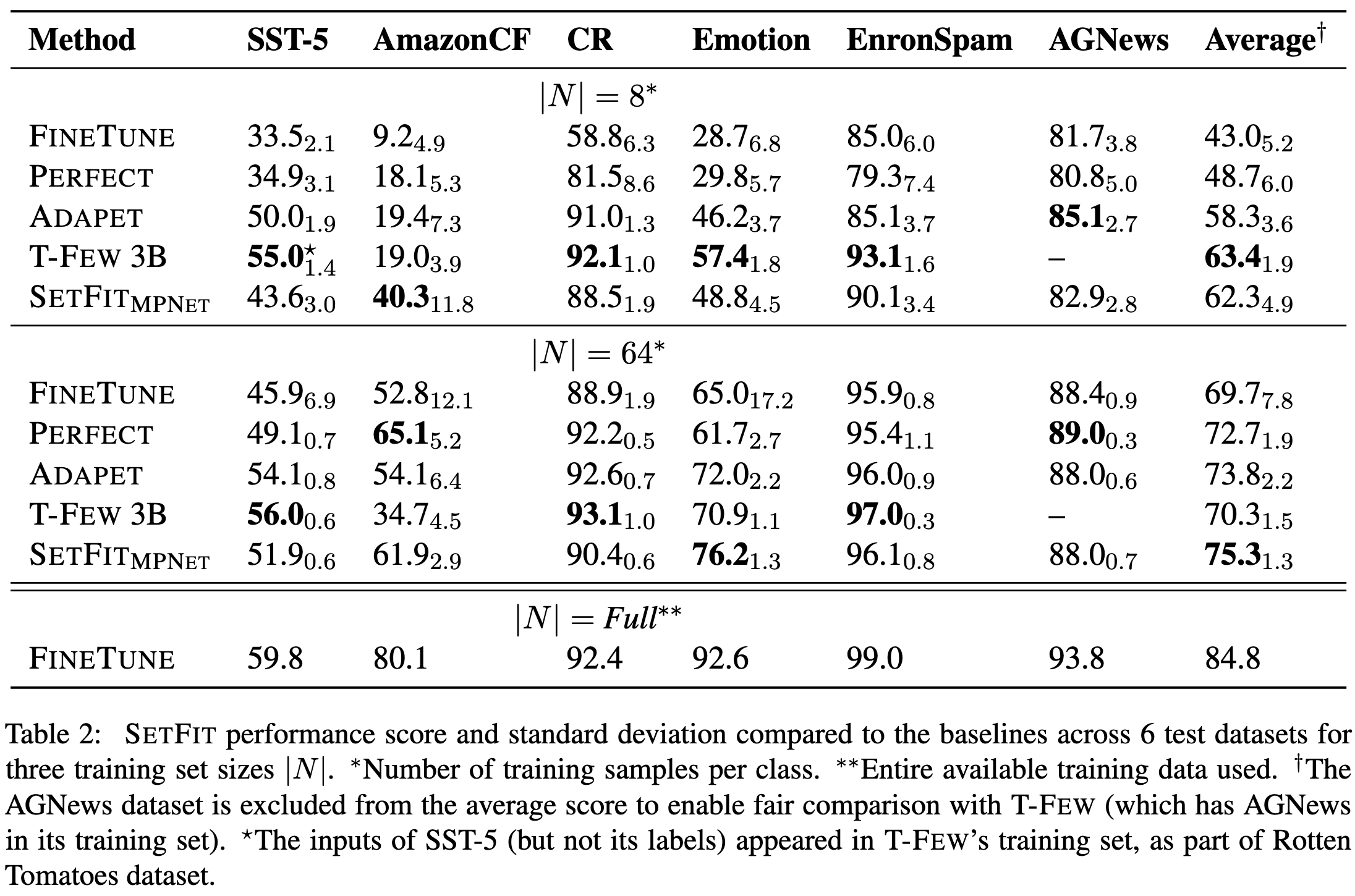
Their reduced model size compared to T-Few yields large training and inference FLOP savings.

Overall, this approach is simple and seems to yield great sample efficiency. Probably worth trying next time you have scant text data.
Surgical Fine-Tuning Improves Adaptation to Distribution Shifts
To handle different distribution shifts, you should finetune different subsets of your network.

At least on image classification datasets, there’s an intuitive relationship between the type of distribution shift and where in the network you should finetune. For shifts in low-level image statistics (e.g., added noise), you should finetune the early layers. Whereas for shifts in the output space, you should finetune the later layers.

You can automatically select which layers to finetune to some extent. Picking the layers with the highest ratio of gradient norm to parameter norm (Auto-RGN) is the most effective heuristic they found—aside from just brute forcing the choice via cross-validation.

Between this, the above SetFit paper, T-Few, and Locked Image Tuning, I’m convinced that naively finetuning the whole model isn’t always the best approach.
Global Convergence of SGD On Two Layer Neural Nets
For neural nets with:
smooth, bounded activation functions like sigmoid and tanh,
Frobenius-norm-regularization on the weights,
reasonable initializations, and
L2 distance as the loss function,
two-layer networks provably converge to the global minimum. These are almost realistic assumptions, so this is a pretty cool result. If we can push this line of work further, we might actually get guarantees about real neural nets.
What Makes Convolutional Models Great on Long Sequence Modeling?
Heck yes, someone is answering the question I keep raising about why state space models like S4 do so well when they’re just structured convolutions:

They argue that two principles underly these models’ success:
Having a global convolution kernel with a parametrization sublinear in the sequence length.
Having the kernel more heavily weight nearby elements of the sequence.
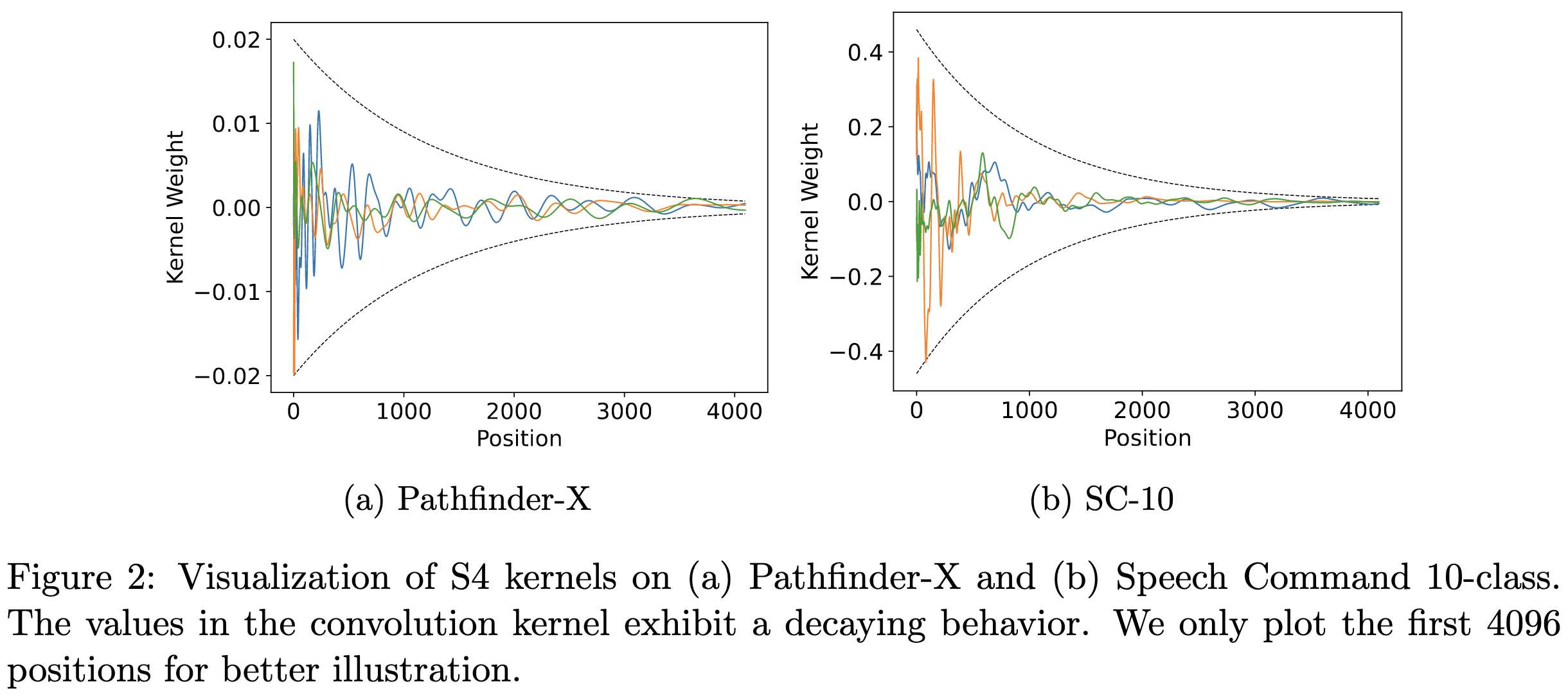
They only sort of show that this is the case as far as ablations, but they provide strong evidence in the form of a simple method embodying these two properties. Their proposed SGConv constructs convolution kernels as concatenations of successively longer but lower-magnitude sinusoids. What’s nice about this functional form is that you can convolve with it super fast in the frequency domain.

Their method consistently beats S4 and other baselines on the long range arena. It’s also faster and needs less memory at every sequence length.



It doesn’t do quite as well as ConvNext for image classification, but does beat the Swin transformer and EfficientNet. Also, props for plotting speed vs accuracy so we can tell what’s really winning.

What’s remarkable about this paper is that we now have a simple convolutional network that crushes every transformer on a variety of sequence modeling tasks. And since state space models (which are fancy CNNs) occupy all the other top spots on the long range arena, our hardest sequence modeling tasks are now dominated by CNNs.
Maybe we never needed attention at all.