


2022-11-13 arXiv roundup: Will we run out of data? Plus, how Google does large-scale inference

This newsletter made possible by MosaicML.
LMentry: A Language Model Benchmark of Elementary Language Tasks
They introduce a benchmark that can act as a “unit test” for assessing how well language models do on simple tasks with clear right answers.

To better characterize how a model does on a given task, they include several variants of the task.

Larger models, multi-task models, and instruction-finetuned models all do better on this benchmark.

Instruction finetuning in particular lifts performance a lot.

“Robustness” above refers to how well the model does on the four different variants of each task. E.g., here’s the breakdown for InstructGPT and TextDavinci002.

Their robustness analysis finds that even the best-performing model, TextDavinci002, is quirky and inconsistent.

E.g., just swapping the order of words can change predictions a lot.

Or sometimes making the right answer excessively “correct” increases accuracy. E.g., recognizing which word is shorter is more reliable when the word lengths differ more.

Slightly different tasks can have really different accuracies.

I’m pretty excited about this. Model validation and testing are hard but important problems in machine learning, and a benchmark like this could help a lot for text models. This and ImageNet-X make me hopeful that this sort of quasi-unit-testing will become a standard practice.
How Much Does Attention Actually Attend? Questioning the Importance of Attention in Pretrained Transformers
They replace some fraction of the attention matrices with constant matrices and assess how much this hurts the accuracy of a pretrained model. The constant matrices are averages of the attention matrices produced on some training corpus.

They determine which heads to replace by adding a differentiable gating coefficient for each attention head. The k% of attention heads with smallest coefficients get replaced with constant matrices at test time.

So what happens as you replace more and more attention matrices with constant matrices? Up to about 50% replacement, not much. But replacing more than that progressively degrades accuracy in most cases.

There’s a correlation between a model’s accuracy and how much degradation there is from replacing all attention matrices with constants.

The constant matrices you get through averaging are nearly diagonal.

You can maybe do better by initializing the constant matrices using their averaging method and then directly finetuning them.

I think this is the first controlled comparison I’ve seen showing that removing attention while holding FLOPs and data movement (nearly) constant does bad things. Though admittedly it’s with a model that was trained with attention, which doesn’t match the setting of various negative results. It’s also interesting that training the constant attention matrices didn’t help much—this is consistent with the results in the Alibi paper.
MONAI: An open-source framework for deep learning in healthcare
A ton of authors got together and a released a suite of PyTorch libraries for ML in healthcare.

There’s a ton of surface area here, and I get the sense there might be pieces here of interest for more than just healthcare. E.g., the library “MONAI Label” seems to have good image labeling tools.
This is also interesting on an ecosystem level because it’s further evidence that PyTorch is winning. Even if JAX/TF per se have feature parity with PyTorch, third-party libraries like this, DeepSpeed, Megatron, Composer, and basically every non-Alphabet research paper are implemented in PyTorch. There are efforts like Ivy to make everything interoperable, but it’s not clear how much traction they’re getting.
How Does Sharpness-Aware Minimization Minimize Sharpness?
Different SAM variants minimize different notions of curvature, shown below. λ_1 is the largest eigenvalue and λ_min is the smallest positive eigenvalue. The middle option, ascent-direction, is the objective people most often use.

That said, the above are full-batch results. In the stochastic case with batch size 1, SAM using perturbations in the ascent direction ends up looking like full batch average-direction SAM (the bottom row, rather than the middle row).
The full-batch results in the table are kind of counterintuitive; moving in the gradient direction penalizes curvature less (i.e., based on smallest positive eigenvalue) than moving in a random direction (i.e., based on the sum of all eigenvalues). Or at least this holds in the case that all eigenvalues are nonnegative.
I’m a big fan of clear theoretical results like these that offer intuition for empirical best practices.
Profiling and Improving the PyTorch Dataloader for high-latency Storage: A Technical Report
Didn’t compare to DALI, which is what you should actually use for fast data loading. But has a lot of good profiling results. What surprised me here is that they found a ton of overhead from using PyTorch Lightning. I’m skeptical that this is necessary, so maybe we have a case study in the importance of good defaults in libraries?

Also, if you’re loading your data from an object store like S3, I’m just gonna shamelessly plug our StreamingDataset. Starts training as soon as the download starts, zero download redundancy, local caching, good shuffling, random access, fast resumption—usually in software there are a bunch of viable options, but this is just straight up the best way to load a remote dataset right now.
On Optimizing the Communication of Model Parallelism
So let’s say you’ve organized all your GPUs into 2d “meshes,” and you want to do some combination of sharding and replicating each tensor within a given mesh. This is easy—just slice the tensor and send each slice where it needs to go.
But what happens if you have different meshes for different parts of the model? E.g., you want to shard the tensors by row in one part of the model and by column in another?

This is a gross all-to-all communication problem, and they propose an efficient method for solving it. The exact method is kind of tricky, but basically there’s a randomized greedy search over communication / re-sharding schemes.

They also propose “eager 1F1B,” a pipeline parallelism variant that allows more overlap of communication and computation.

You’ll probably have to read their earlier paper to fully get what’s going on. They kind of assume that the system in that paper has handed you the meshes and the sharding strategy, and you just need to optimize the communication given that sharding strategy. Ideally you’d jointly consider both, but I suppose that’s future work.
Efficiently Scaling Transformer Inference
Google talks about how they got PaLM inference to be low-latency and low-cost.
First off, I’m a big fan of these plots—always a plus when you show the full tradeoff curve rather than just report some point estimate in a table.

From a method perspective, this paper is mostly about parallelism and sharding. You can’t fit all the weights on a given device, so you have to shard them somehow.
For FFNs, they describe a few different sharding schemes. You can split along the rows or cols of each matrix (1D), along both rows and cols (2D), or just gather all the weights onto every device before each op. In the former two cases, we move the activations to the weights. In the latter, we move the weights to the activations.

You want different amounts of gathering the weights vs the activations depending on their relative sizes. Interestingly, there’s a 1.5 order of magnitude regime wherein you want to partially gather both to varying degrees.

For sharding attention, they focus on optimizing PaLM’s multi-query attention. This uses the same key and value matrices for all heads, making the K and V matrices smaller by a factor equal to the head count.

They shard the attention over heads for processing the prompt and over the batch dimension for the decoding. One tricky aspect of the latter is that, to be compatible with the sharding in the FFNs, they have to add all-to-all operations at the start and end.
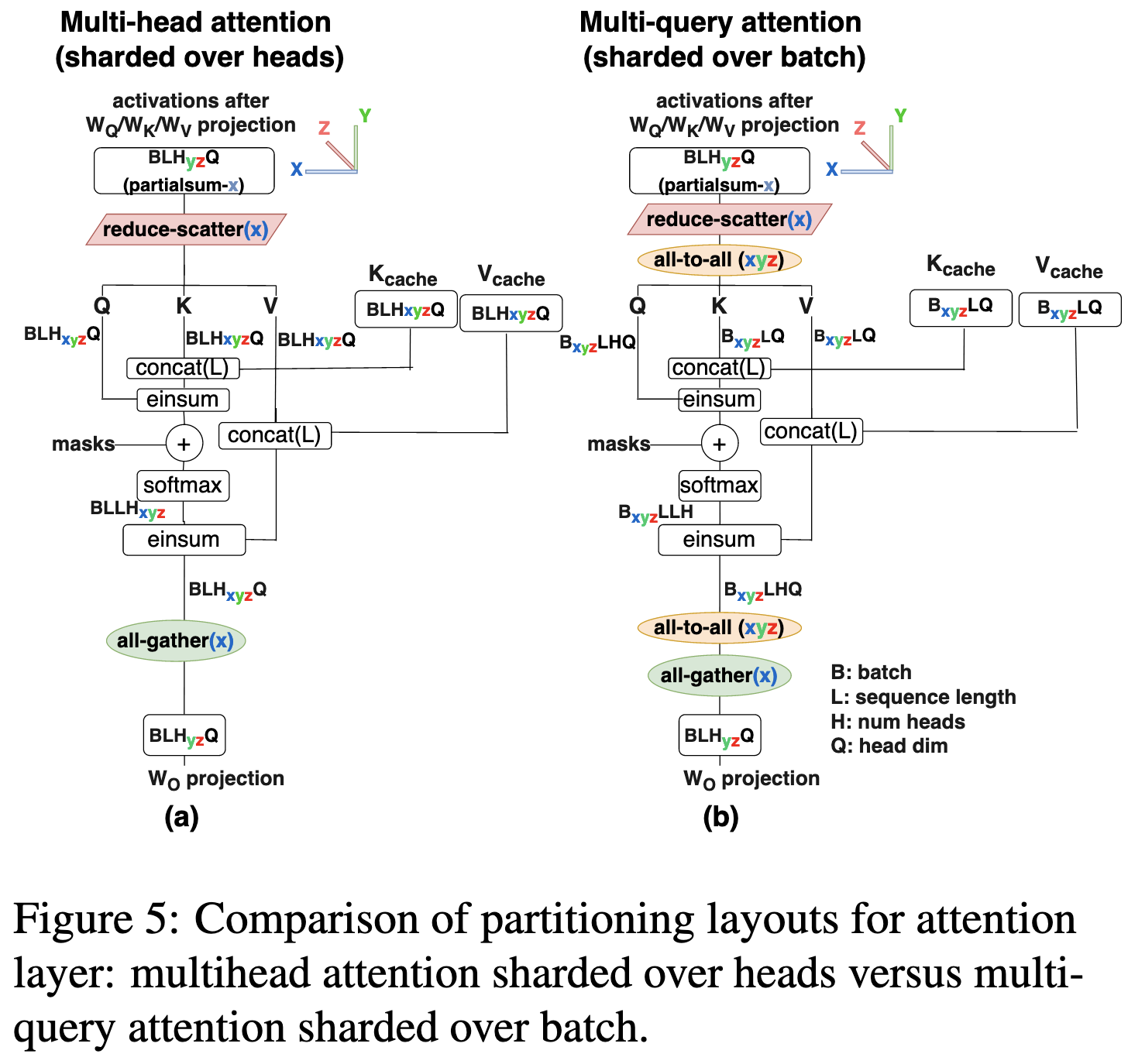
Their optimized multi-query attention lets them use much longer context lengths before running out of memory.

They also have some optimized einsum operations that overlap communication and computation, based on an API sourced from the future1.

Another low-level optimization is sharding the matrices to maximize the efficiency of the computations being done while chunks are still in flight.
Finally, they quantize the weights to int8 using AQT.
These optimizations together let them get a better latency vs utilization tradeoff than FasterTranformer.

They also have some interesting profiling results. What parallelism is best for the FFNs depends on whether you care more about latency (huge node count) or throughput (high utilization). Also, handling the prompt (“prefill”) and iterative decoding are super different workloads—the former has 2x higher utilization or more.

Cool that Google is opening the curtain on how they’re doing large-scale inference. Plus it’s always nice to see such thorough profiling.
Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning
Yes. At least based on extrapolating the Chinchilla scaling laws, growth in internet users, number of books written per year, etc.
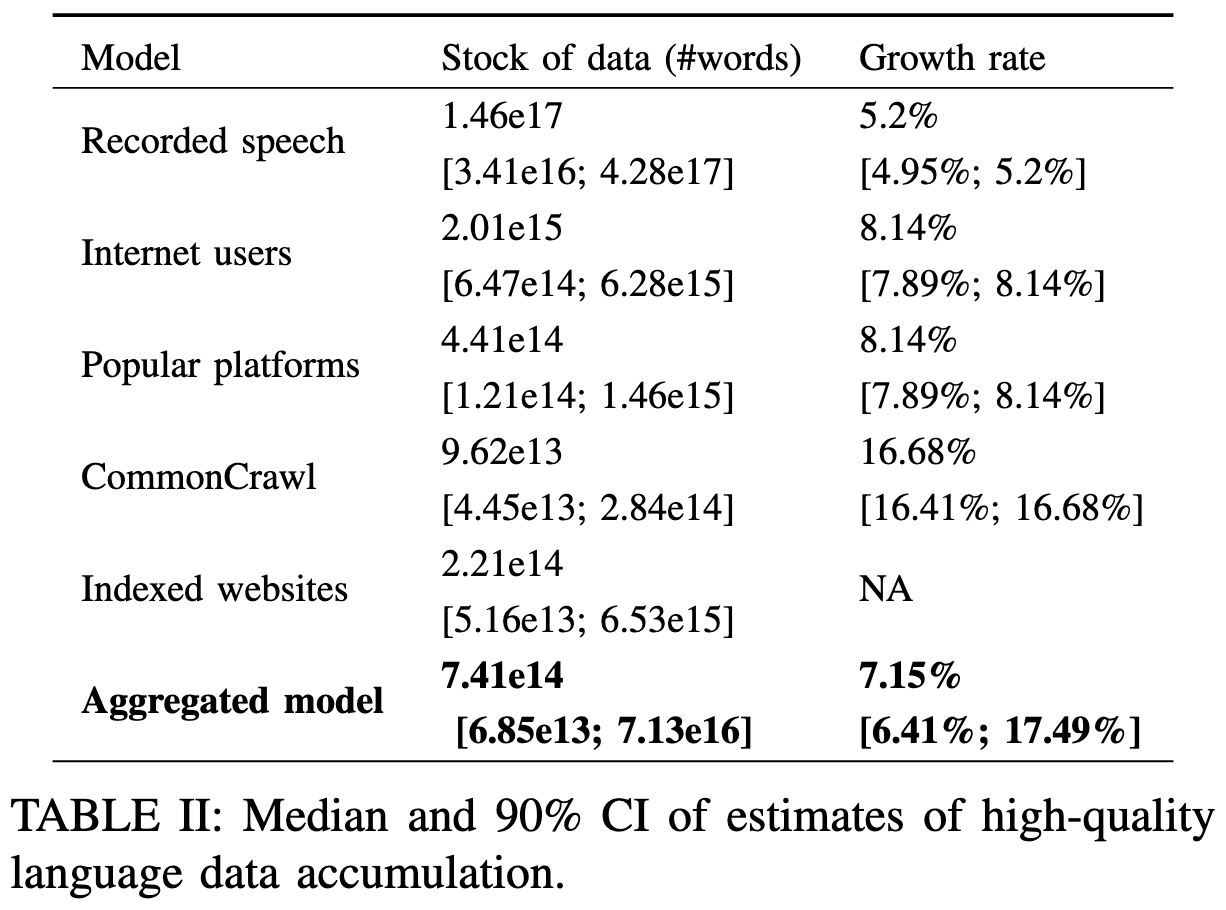
Although we’ll run out later for lower-quality data, like recorded speech, than for high quality data, like books.


We’re also likely to run out of images at some point.

One interesting wrinkle here is the likely plateau in internet users. This has looked like an exponential trend for ~30 years, but at some point we’re going to run out of humans.

Of course, as the authors note, all sorts of changes could break these predictions. Some standouts include:
More data reuse (no need for single-epoch training on text)
Better sample efficiency
Synthetic data
New data sources
This last one is the most concerning—people write and photograph very little, but speak and look around constantly. With the right surveillance2, you could increase your data stock almost arbitrarily. E.g., at 1MB/s HD video feeds from "only" 1 million cameras, that's about 1TB of data per second.
We won't run out of data—just data privacy.
To appear in ASPLOS 2023
Imagine if companies and/or governments convinced people to install always-on listening devices in their homes. Or install cameras that surveil their families, their neighbors, and anyone passing by. Or wear glasses that can video everything you do. Or if cities had security cameras on every block. Or if you could just buy tiny microphones for $1 and leave them anywhere. Or if every car were covered in cameras. Or if our computers could silently monitor our screen, microphone, keystrokes, and webcam. Or if we we kept devices with hackable microphones in our pockets all day.
But whatever happens, don’t worry—we’ll have plenty of privacy in the metaverse, kindly provided to us by a digital advertising company.
Hi David, 👋 great summary as always! Why do you prefer DALi over FFCV https://docs.ffcv.io . Have you used it before? What are your arguments or the benefits you see in using DALi instead of FFCV? In their docs they report much better performance.