


2022-11-6 arXiv roundup: ImageNet-X, Automating prompt engineering, BLOOM carbon footprint

This newsletter made possible by MosaicML. Also, shoutout to @cwolferesearch (author of Deep Learning Focus) for the plug on Twitter this week.
ImageNet-X: Understanding Model Mistakes with Factor of Variation Annotations
They collected super detailed image annotations for the full ImageNet-1k eval set and 12k training samples.

Using these annotations, they explore how sensitive different models are to nuisance variables like pose, background, size, and more.

Different models all end up with surprisingly similar levels of robustness to different variations.

Data augmentations can make models more robust to some variations (left side), but sometimes at the cost of worse robustness to other variations (right side). The “error ratio” here is the error rate at a given x position divided by the baseline model’s error rate.
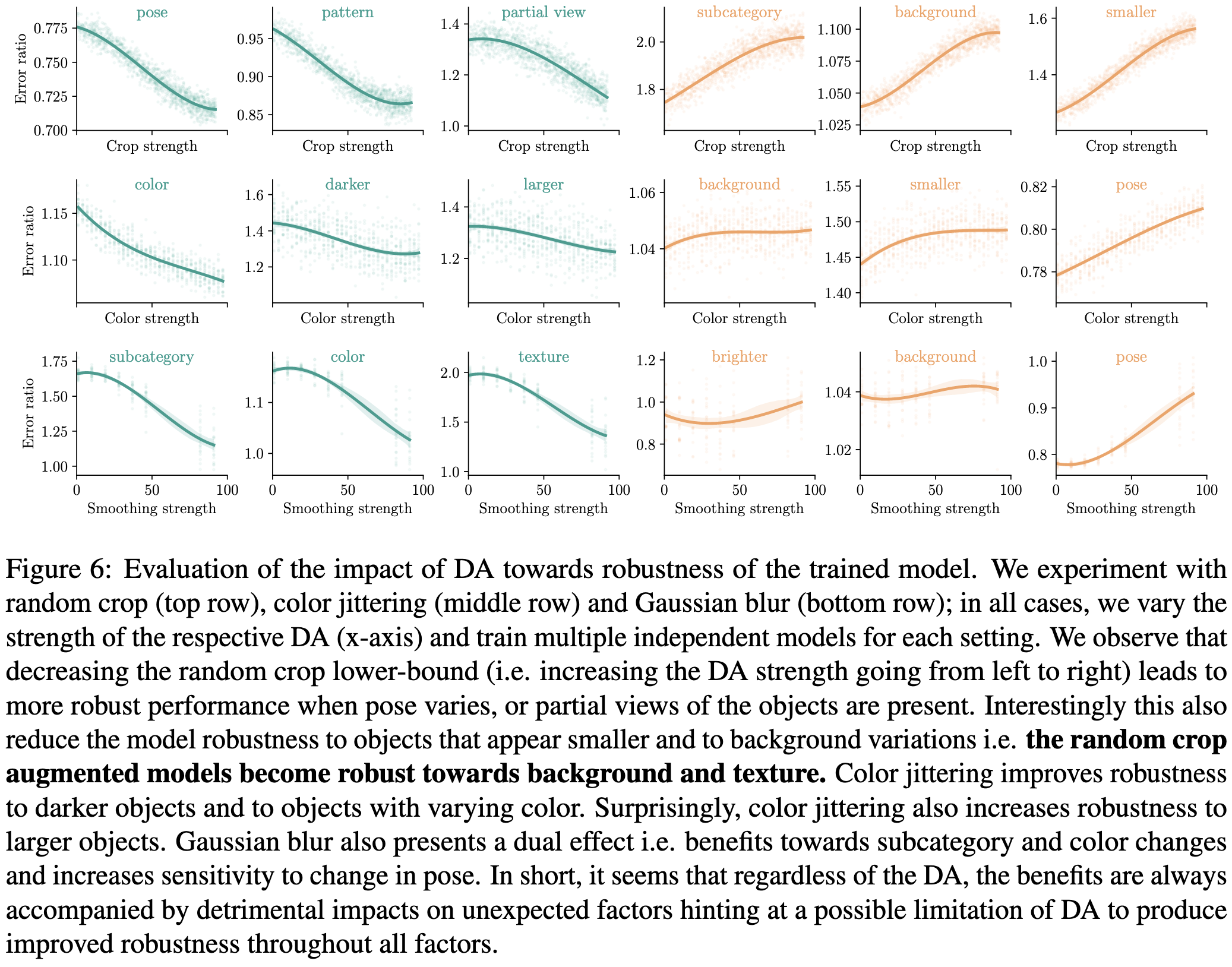
Using this factor-wise analysis, they point out that you can generate nice summaries of a model’s strengths and weaknesses.
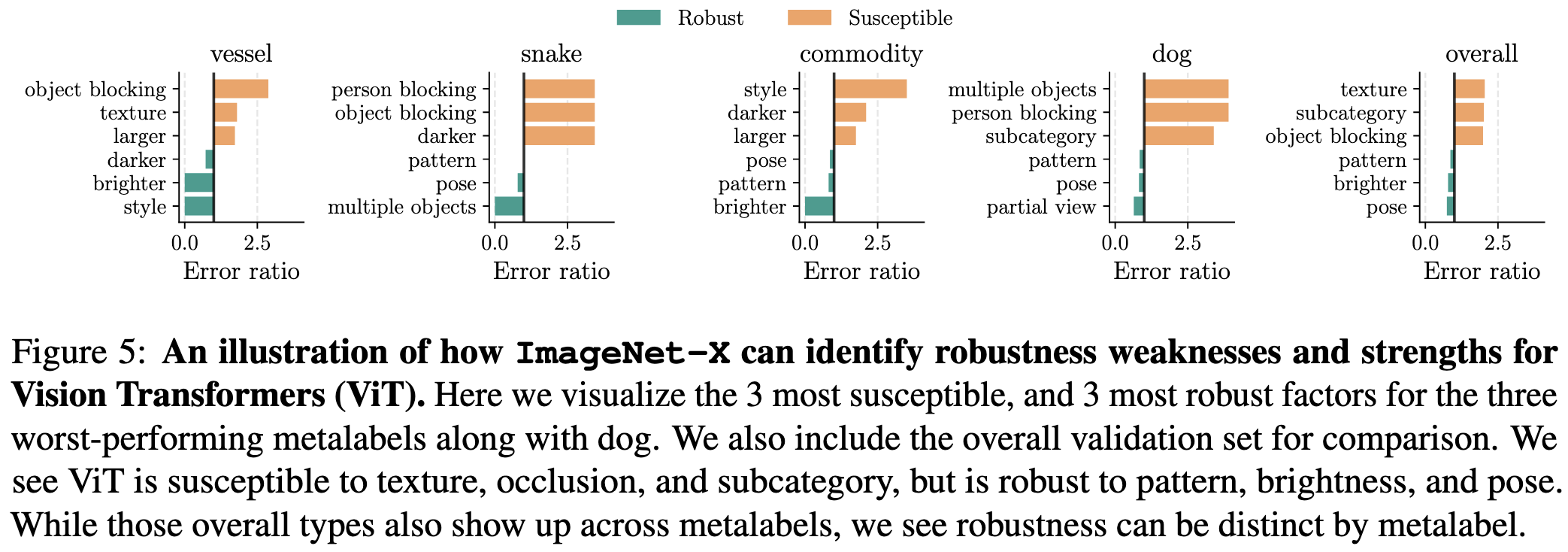
Relatedly, they have the best breakdown I’ve seen of different ImageNet variants you can use to evaluate a model.

Great science-of-deep-learning work involving over 2000 models. Plus, I could imagine ImageNet-X being useful in practice for understanding your model’s failure cases.
You can't pick your neighbors, or can you? When and how to rely on retrieval in the kNN-LM
When adding a retrieval component to a language model, they use an intelligent combination of the model’s predicted probabilities and the next token probabilities from the retrieved sequences.

In particular, they make the weighting coefficient larger when the query and retrieved values are more similar. You can use trained embeddings or TF-IDF statistics to define “similar;” it doesn’t matter much which one.

Using this intelligent per-token weighting can reduce perplexity. This holds even if you rip out all the 8-grams that appear in the eval set from the retrieval corpus.


They do have to tune a lot more hyperparameters with their scheme though. This is because, rather than learn a continuous function mapping retrieval similarity to interpolation coefficient, they bucket the similarity values and learn a separate coefficient for each bucket. However, they point out that tuning retrieval hparams is cheap once you spend a few hours precomputing all the nearest neighbors.

As an interesting aside, they find that retrieval seems to help more for parts of speech that the base model has more difficulty with. Except pronouns, which retrieval is apparently useless for in their setup.

It still doesn’t feel like we’ve figured out the best way to augment language models with retrieval, but it’s nice to see results where a simple change helps.
Toward Reliable Neural Specifications
They find that, if you want to formally verify the behavior of neural nets, relying on distances in the input space doesn’t work so well. Instead, they propose using “neural activation patterns” (NAPs).

NAPs are defined as two disjoint subsets A and D of neurons (not necessarily collectively exhaustive) where neurons in A are nonzero and neurons in D are zero. They argue that looking at NAPs is more tractable for verification. Kind of makes sense intuitively; if I know that two inputs have the same active neurons, that’s actually a pretty strong statement about their similarity in the network’s latent space.

I don’t really follow this literature, but it’s cool to see what approaches people are trying to get formal verification working for neural nets. Not convinced it will work since formal verification is super hard even for normal software, but it would be a big AI safety win if we did get it working.
Block-Wise Dynamic-Precision Neural Network Training Acceleration via Online Quantization Sensitivity Analytics
They built a custom chip that lets them use different bitwidths for different 4x4 blocks of activation, gradient, and weight matrices.

They propose some heuristics to adaptively set the bit widths for each 4x4 block, reducing the problem to computing a) “relative sensitivity” for each block and b) an overall constant.

They can’t match the baseline accuracy for ResNet-18, but they do apparently beat a previous 8-bit training method with their 6-bit method. Unlike most quantization work, 6 bits is the average bit width since it varies across blocks.

They get wall-time speedup inversely proportional to bitwidth, which is good. For small bitwidths, it even scales a bit better than this—presumably because of a higher fraction of the data fitting in faster cache levels.
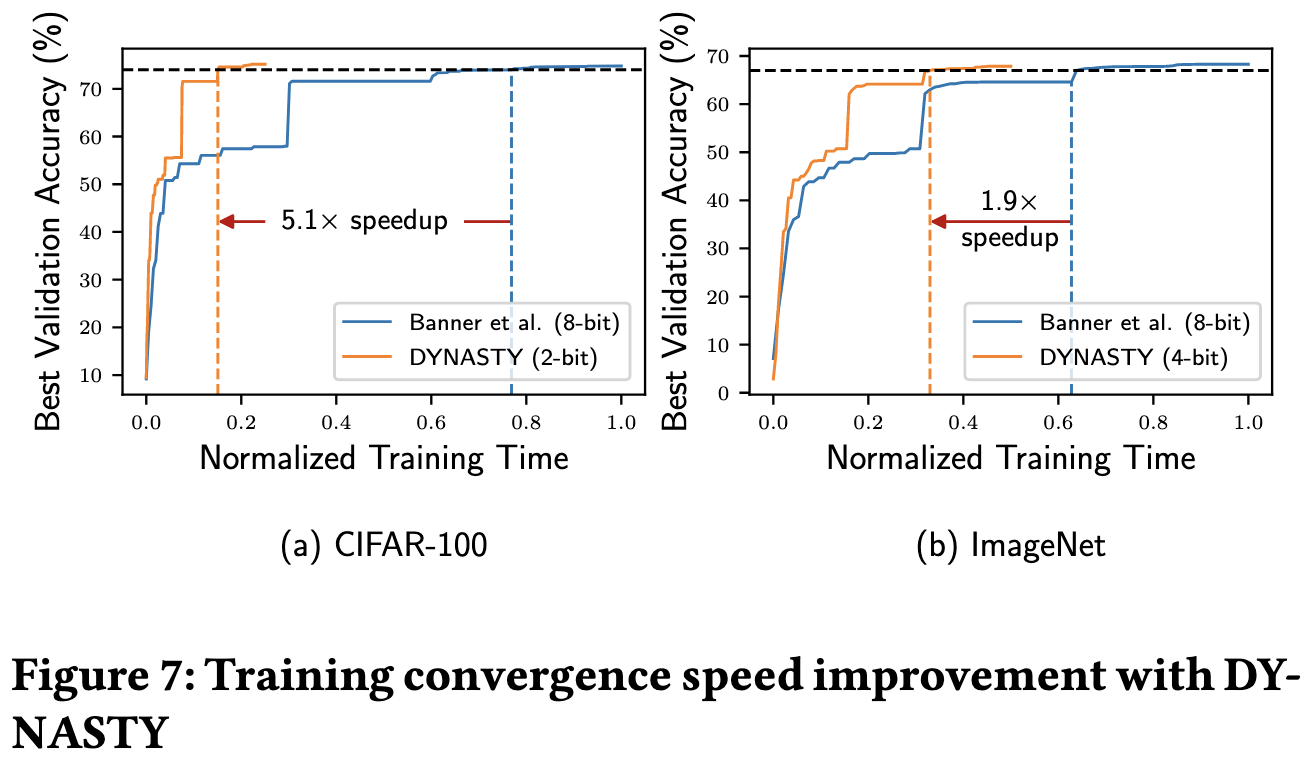
This isn’t a method we’re going to see in commercial hardware anytime soon, but it does suggest that block-wise quantization could be a useful feature in future accelerators.
A Solvable Model of Neural Scaling Laws
A 96-page theory paper about what assumptions might give rise to power law scaling. You can jump to page 56 for the discussion section, but you’ll probably have to go through most of it to get what’s going on.
In the paper, we have studied generalized linear regression models with random feature maps, and we have seen that the ability of such maps to extend the power law present in the spectrum of input data is the mechanism that leads to the power law scaling of the test loss as the number of random features increases
Where to start? Analyzing the potential value of intermediate models
Normally when we talk about a “pretrained model,” we mean one that was trained on a large corpus using some proxy objective like masked language modeling. But what if there were multiple stages of pretraining (“intertraining”)? E.g., unsupervised pretraining followed by finetuning on some labeled dataset?
They used a ton of datasets and pretrained Hugging Face models to explore the efficacy of adding finetuning on a different “source” dataset. Usually the finetuning makes the initial model work worse for other tasks, but about 1/6 of the time it’s better.

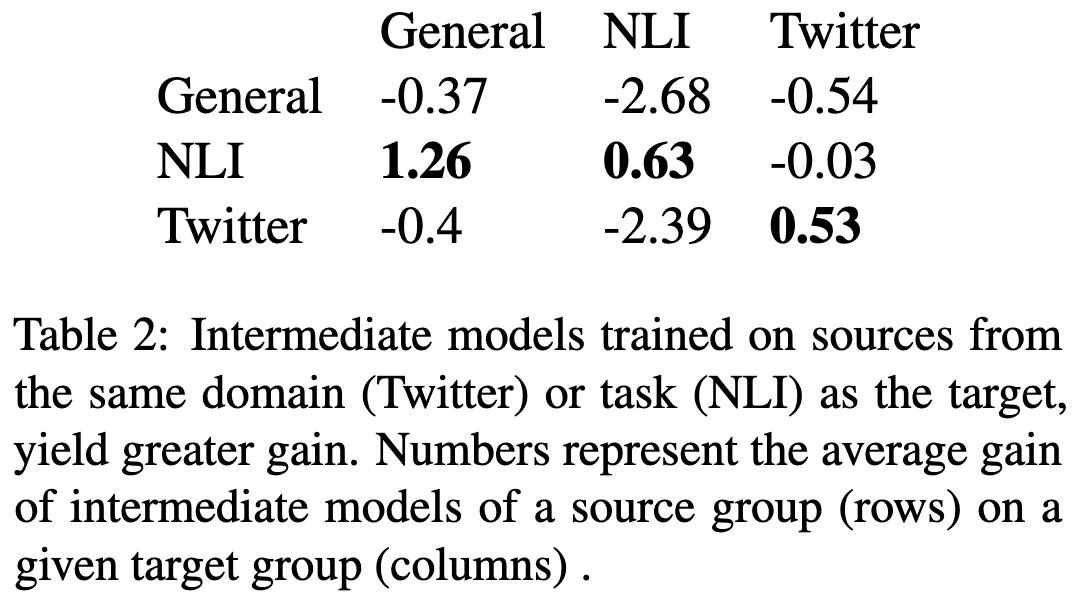
At least for the tasks they consider, MNLI linear probe accuracy is a good proxy for the benefit of finetuning on the best source dataset. The setup here is that they start with a pretrained model, finetune it on MNLI, and then train a linear head for the target task.

More generally, source tasks that are helpful for some target tasks tend to be good for many target tasks. I.e., some source tasks are just good.

Though of course, there tends to be better transfer between source and target tasks that are similar.
Making a source dataset larger makes it transfer even better for helpful sources, but even worse for unhelpful ones (left). Target datasets that are larger benefit less from finetuning on a source dataset, even if it’s a “good” source (right).

More evidence that the simple pretrain→finetune pipeline that’s gotten popular in the past several years isn’t always the best option.
Preventing Verbatim Memorization in Language Models Gives a False Sense of Privacy
They change the decoding to zero out the probability of any token that results in n-gram overlap with the training set.


This consistently increases edit distance between generated sequences and the training data, even for large models.

But it turns out that, even if you prevent the model from repeating its input verbatim, it will still regurgitate memorized content—just with minor “stylistic” variations.

Or, rather than messing with “style,” the model will change the whitespace, misspell words, or alter capitalization.

We can assess how much this memorization happens systematically by finding long chunks of text that we know go together, like speeches, software licenses, and song lyrics. Large models—especially PaLM 540B—memorize a lot of these texts.

Language models approximately memorize way more content than they exactly memorize.

Among other implications, this work suggests that the upcoming AI copyright wars pretty gross—how approximate must your memorization be to count as fair use, a derivative work, outright copying, etc? And how do we even measure memorization? Will pretrained models become a compliance risk? So many questions…
Human alignment of neural network representations
Let’s say you have a dataset of image triples with labels indicating which one humans see as the “odd one out.” How well do neural net embeddings line up with human judgments? Is the odd one out usually farther from the other two in last-layer embedding space?

Without any finetuning…not so much.

With a linear probe on either the logits or final embedding layer, you can start to do better, though still not great. Note the low numbers on the x and y axes—random is .33 and perfect would be around .68 due to human disagreements.
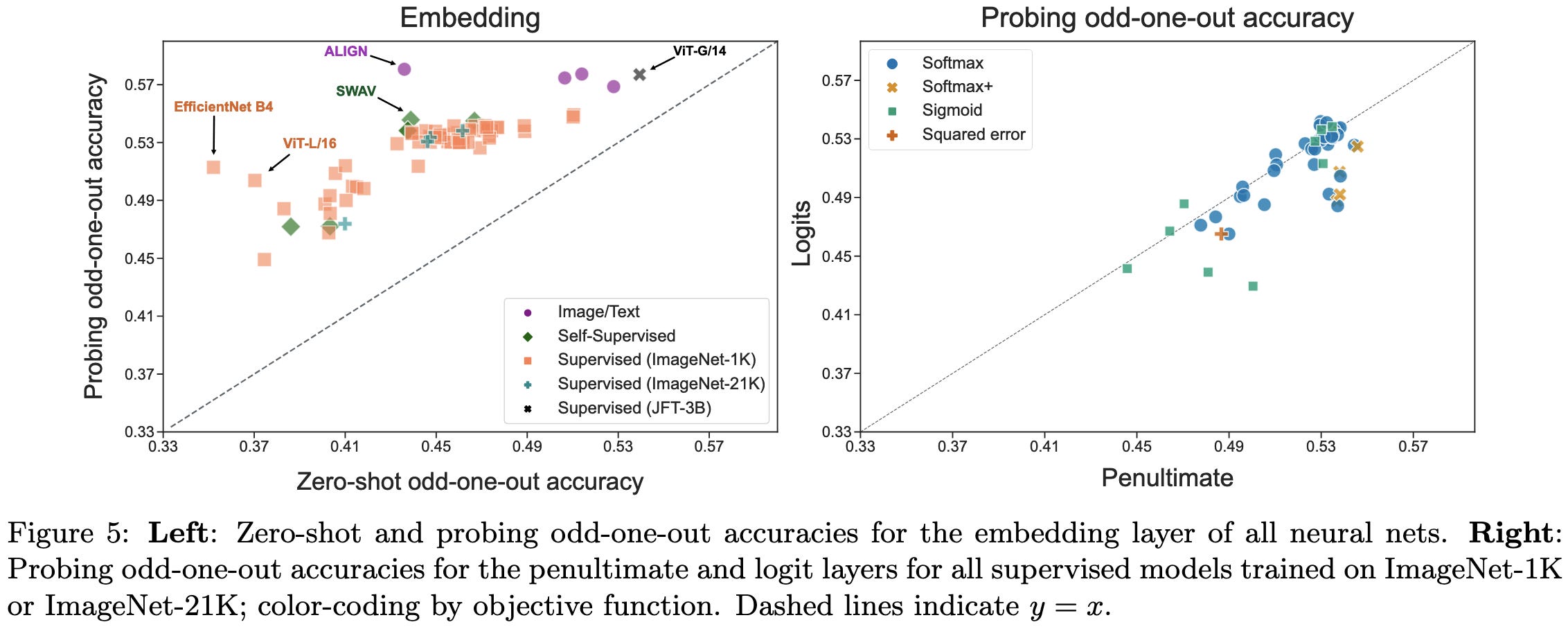
So, tl;dr, ImageNet models don’t cluster pictures of objects like humans do.
Adversarial Policies Beat Professional-Level Go AIs
An adversarial Go agent can learn to beat a really good Go agent by tricking the latter into ending the game while it has a better position but lower score.
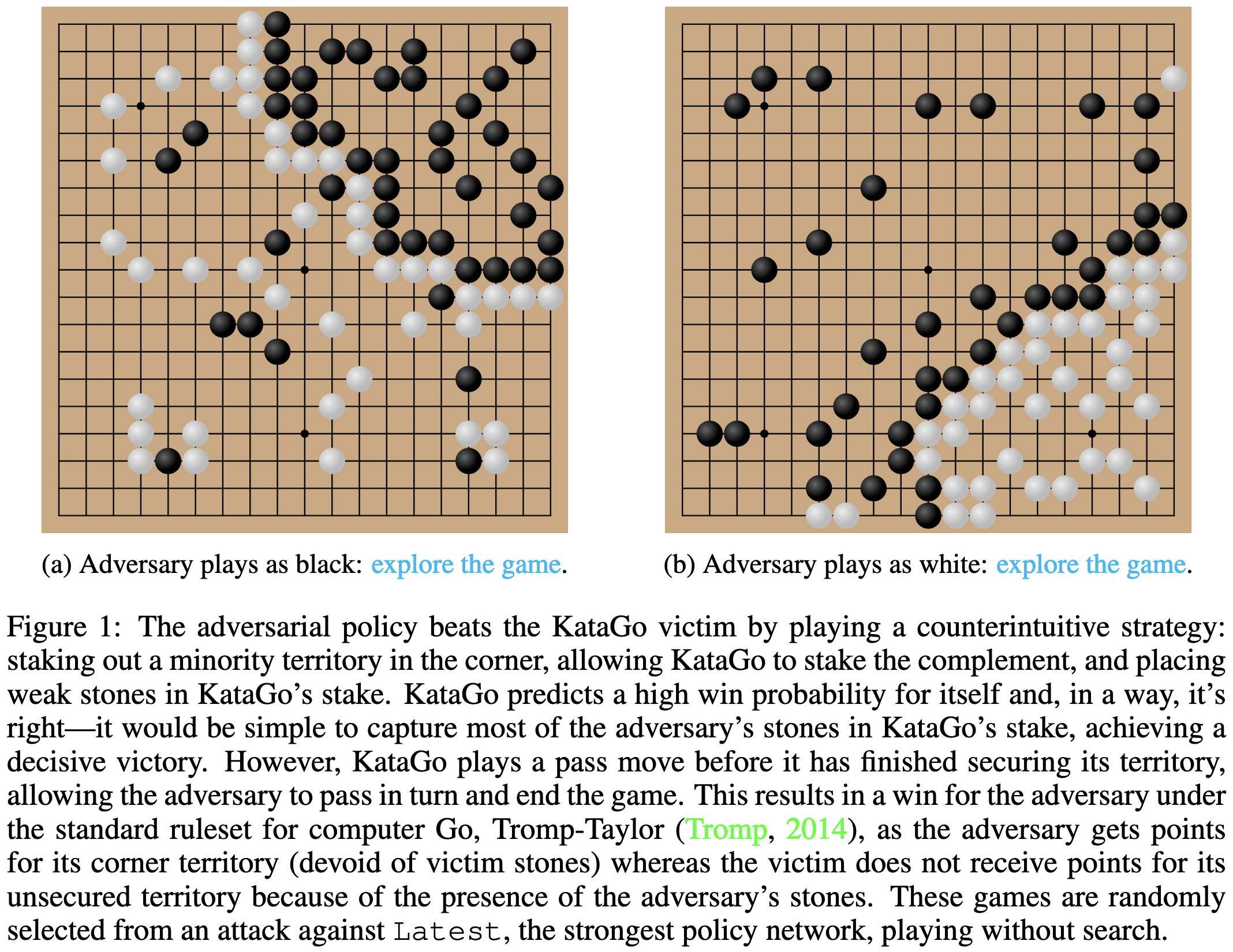
This especially surprising because the adversarial agent is garbage vs any other opponent, losing even to unskilled humans.
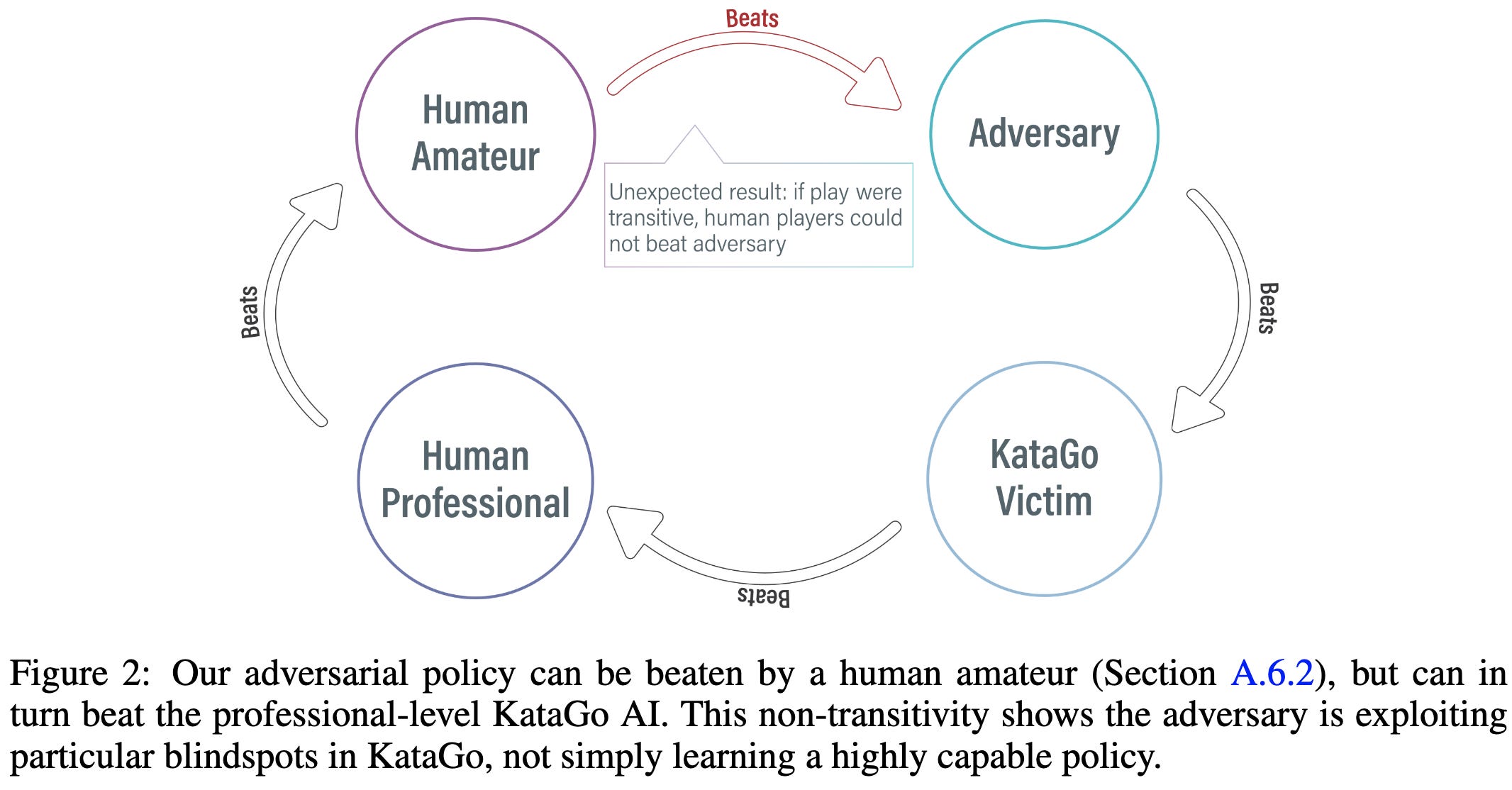
Mostly makes me wonder how widely the above diagram applies. Will we have a rock-paper-scissors situation with humans, adversarial agents, and smart agents in general? Are adversarial AIs the way to keep future misaligned AIs in check? My inner sci-fi author is imagining humans with adversarial camouflage fighting Skynet’s robots1.
Large Language Models Are Human-Level Prompt Engineers
They formulate prompt engineering as a black-box optimization problem and use large language models to solve it.

Namely, they iteratively generate prompts using an LLM, evaluate them on a subset of the data, and then generate variations of the best-performing prompts.


How do they generate variations of a good prompt? Well, by prompting a language model to paraphrase it.

Their proposed method works about as well as human prompt engineers manually fiddling with the prompts.
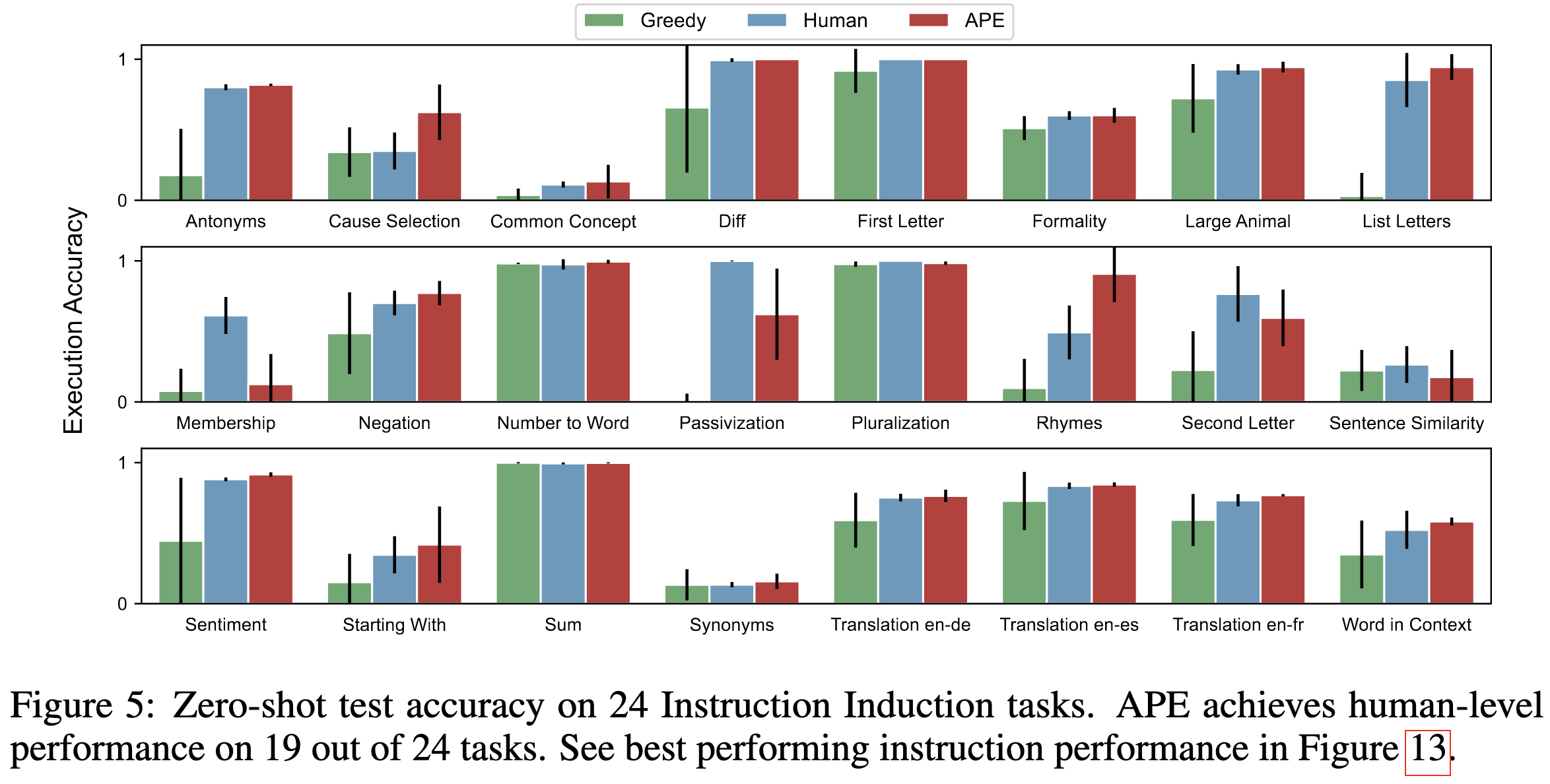
And, encouragingly, the generated instructions are sensible.

What I find coolest here is that, while the method is designed for prompt engineering, it’s really a black-box hparam optimizer, with hparams represented as arbitrary sequences. This is similar to OptFormer, but even simpler.
Estimating the Carbon Footprint of BLOOM, a 176B Parameter Language Model
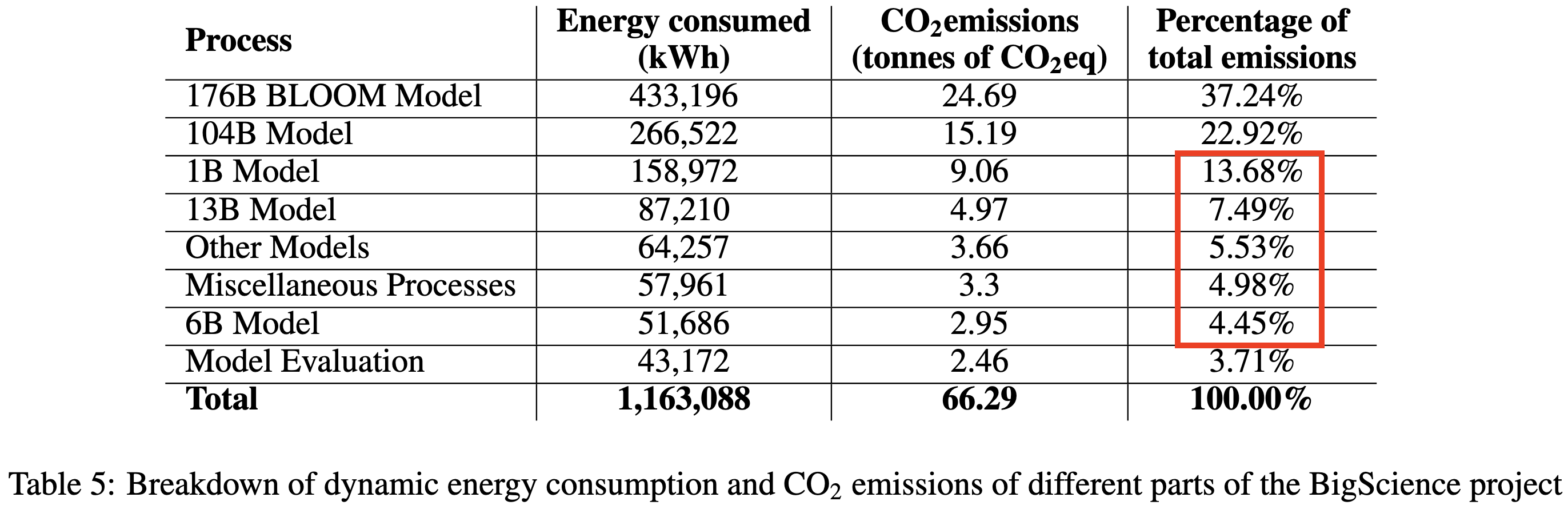
Training BLOOM probably took around 433MWh of energy and emitted the equivalent of 50.5 tonnes of CO2.


This is probably a lot less than GPT-3 and Gopher required though.

Only around 37% of the BigScience project’s total energy use was for the final 176B-parameter training run. This is on par with the ~36% used to train smaller models many times for prototyping and debugging.
For inference, it takes over 1.6kW to power their 16 A100s.

This inference power consumption tends to go up when there are more queries, but it’s not as clean a relationship as you might expect.

I really like this detailed breakdown. People tend to focus on the cost of the final training run, but the cost of the smaller training runs to get ready for the final big run can be just as large. And inference costs are no joke either.
Though please don’t get me started on why Skynet is a terrible threat model.