2022-12-18 arXiv roundup: Robotics Transformer, Dense MoE pretraining

This newsletter made possible by MosaicML. Short installment this week since I have a 103°F fever.
RT-1: Robotics Transformer for Real-World Control at Scale
This is a big paper with a ton of authors about getting robots to work better and generalize across new tasks.

They did a ton of data collection, gathering over 130k episodes. They learn from this data using imitation learning.

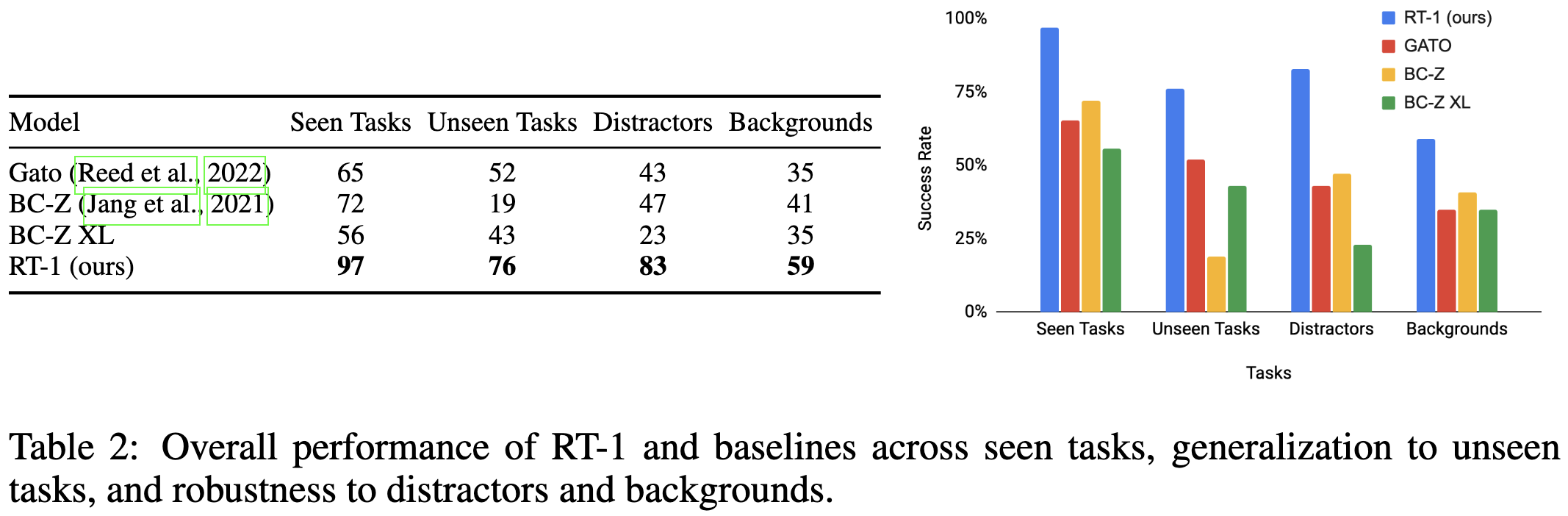
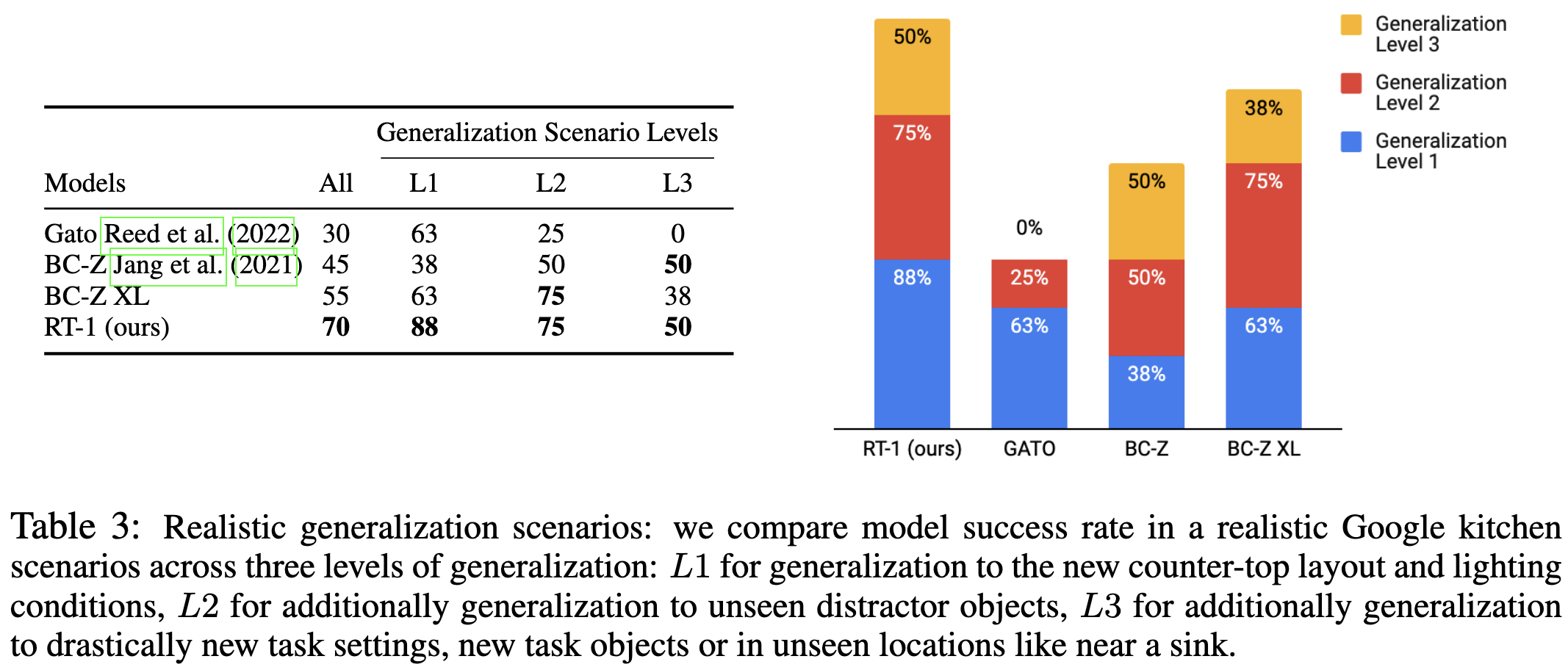
Seems to beat Gato and other baselines.
CLIP Itself is a Strong Fine-tuner: Achieving 85.7% and 88.0% Top-1 Accuracy with ViT-B and ViT-L on ImageNet
You can get CLIP finetuning to work way better if you mess with the hparams and image preprocessing.
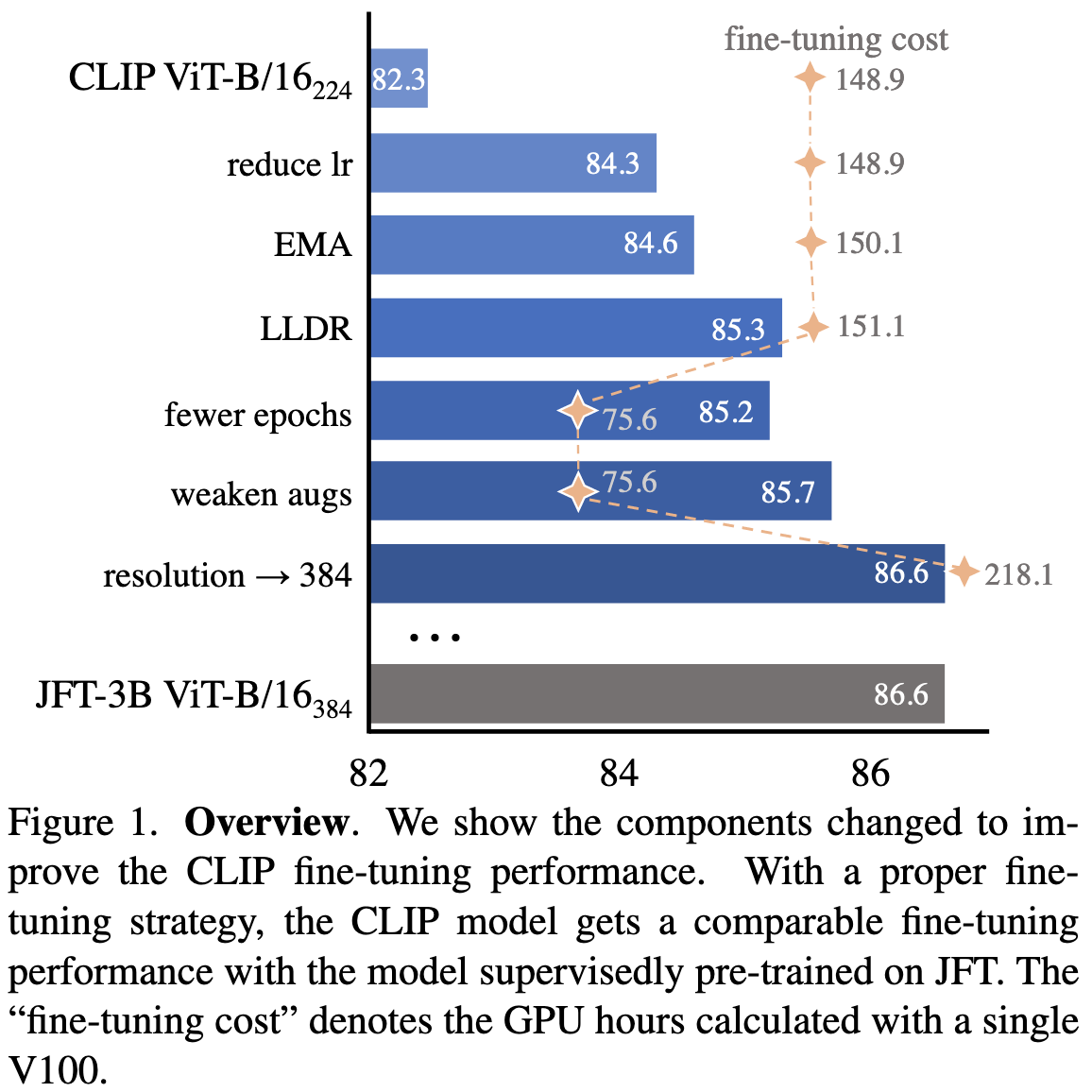
The better hparams they find are the result of a ton of ablation experiments—these are the bulk of the paper.
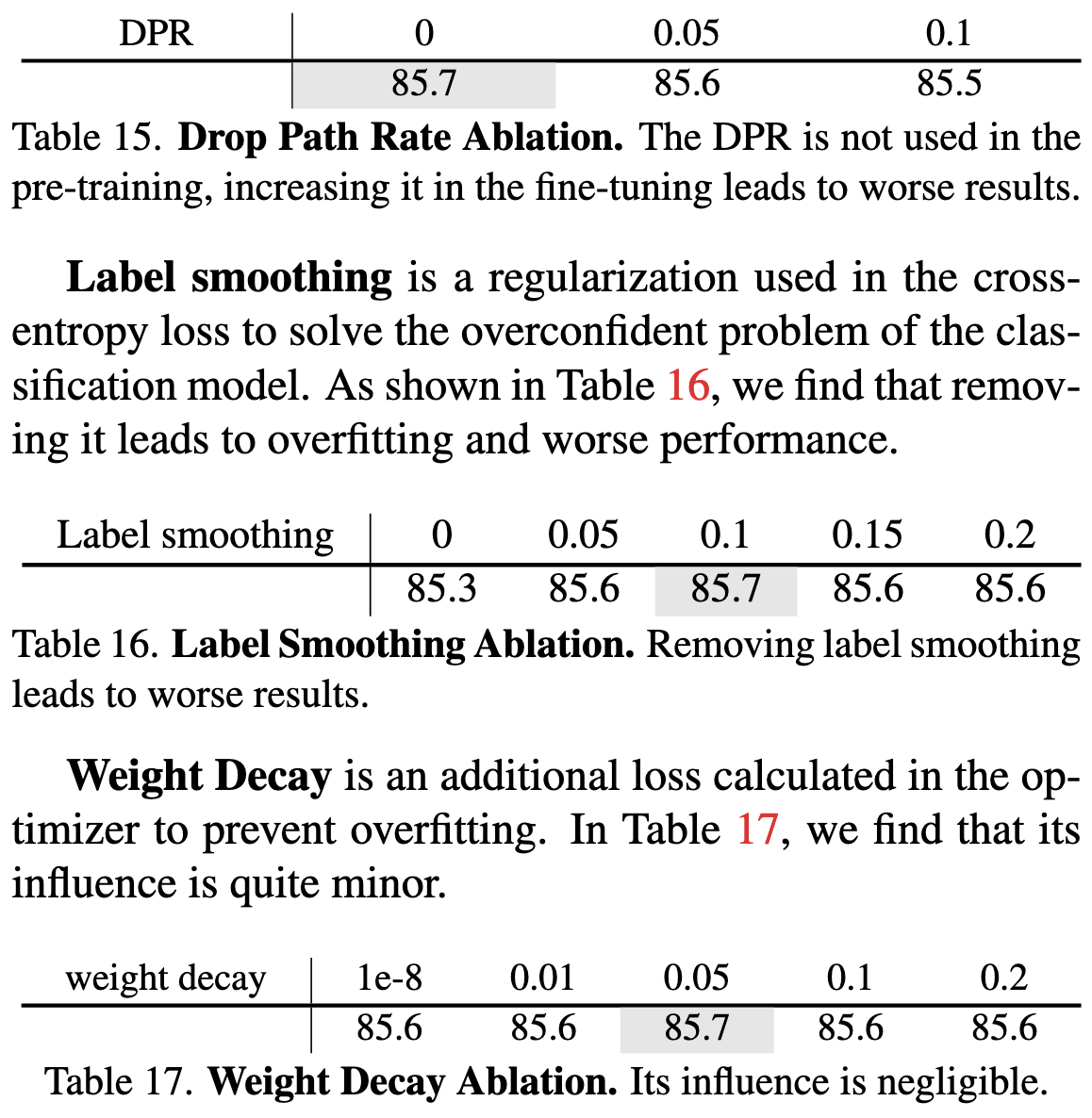
If you ever want to finetune a clip model, sounds like you definitely want to use this paper and their code as a reference.
Measuring Data
They suggest constructing quantifiable measurements of datasets, and point out that this is a unification of various ideas from different subfields.
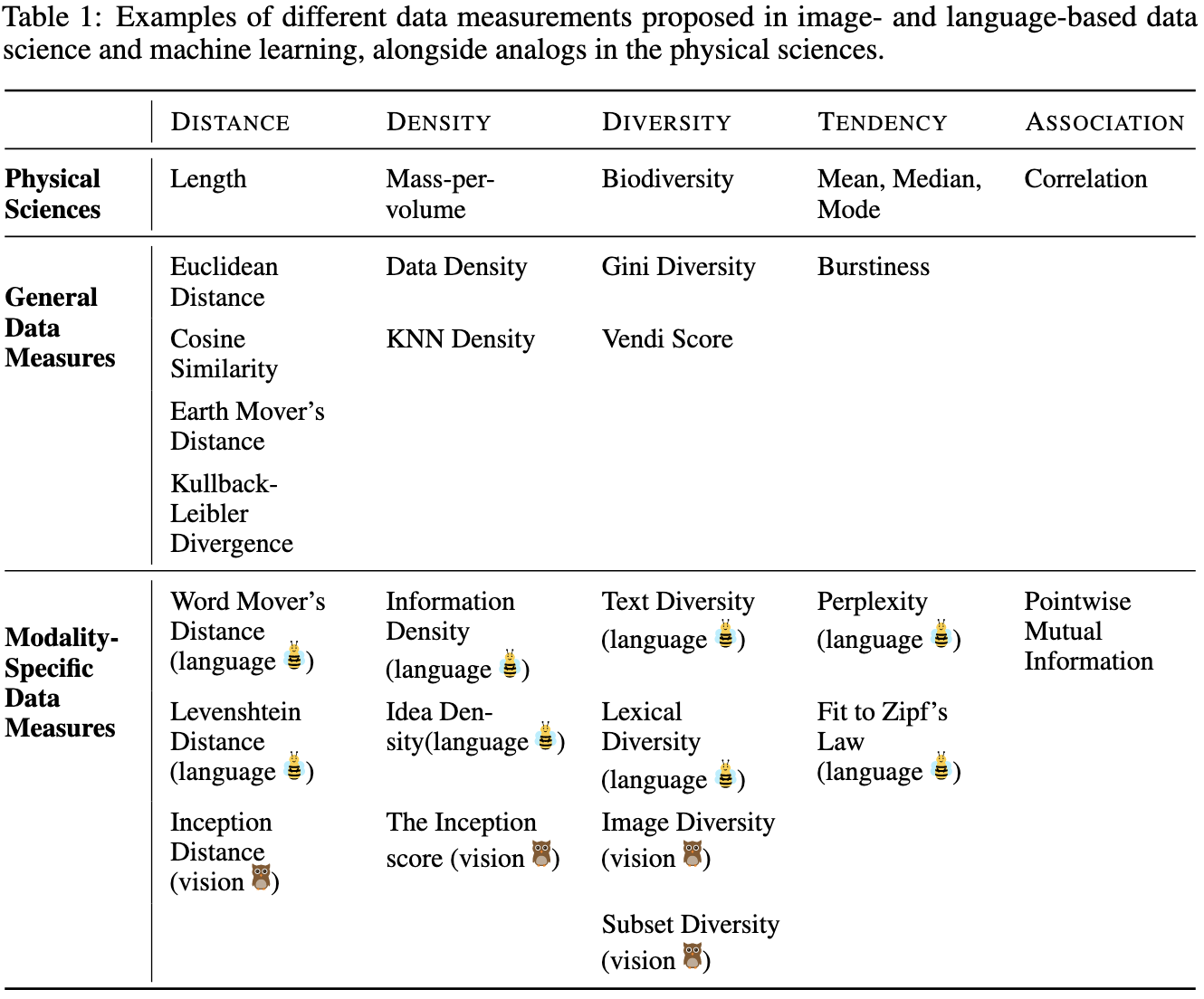
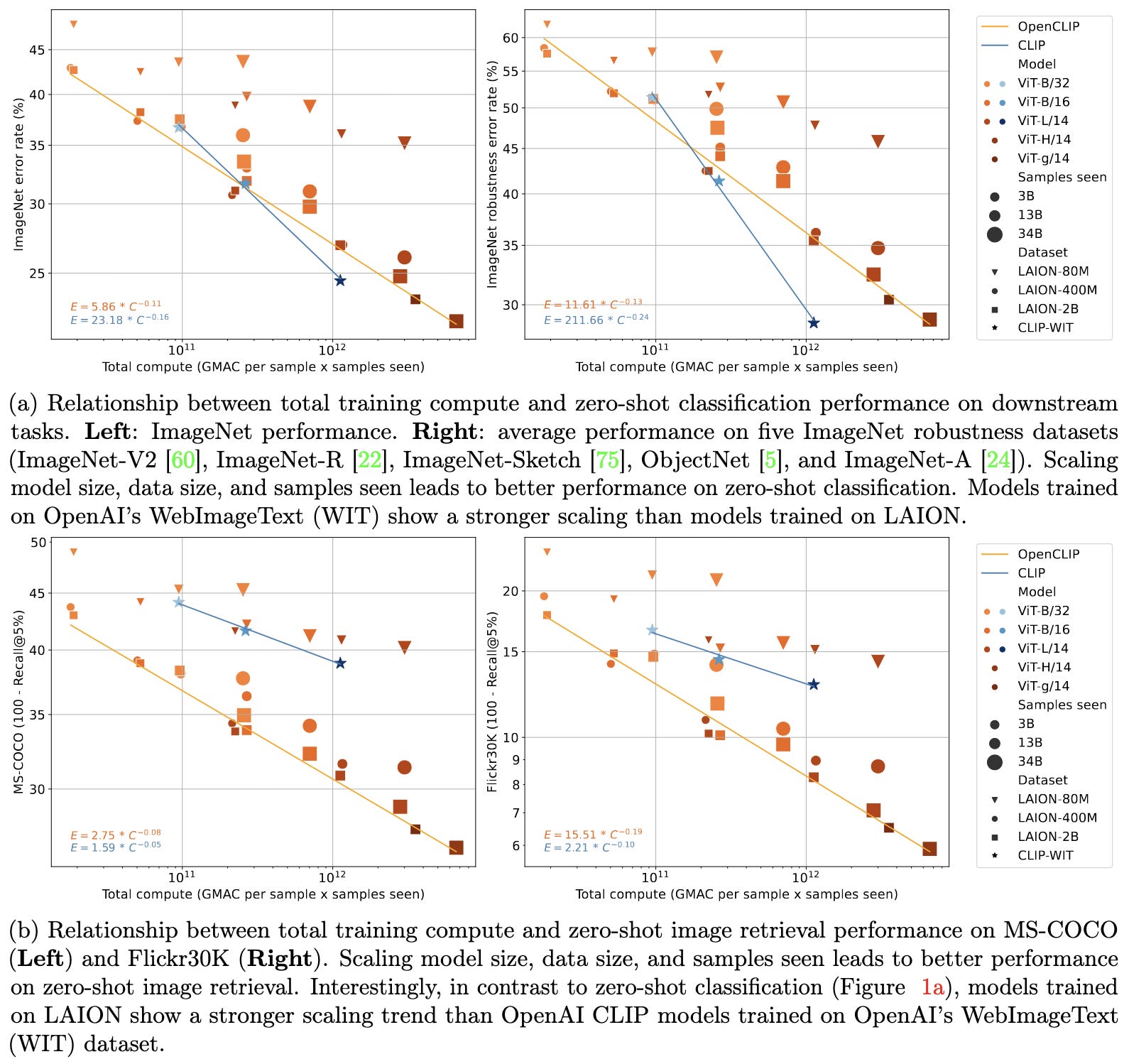
Reproducible scaling laws for contrastive language-image learning
They train a ton of CLIP models and observe power-law scaling. Interestingly, they get different scaling laws than what OpenAI reported despite matching the experimental setup as closely as possible. This suggests that different datasets (OpenAI trained on a proprietary one) can yield different scaling laws. This is somewhat consistent with some previous claims in the realm of dataset pruning.
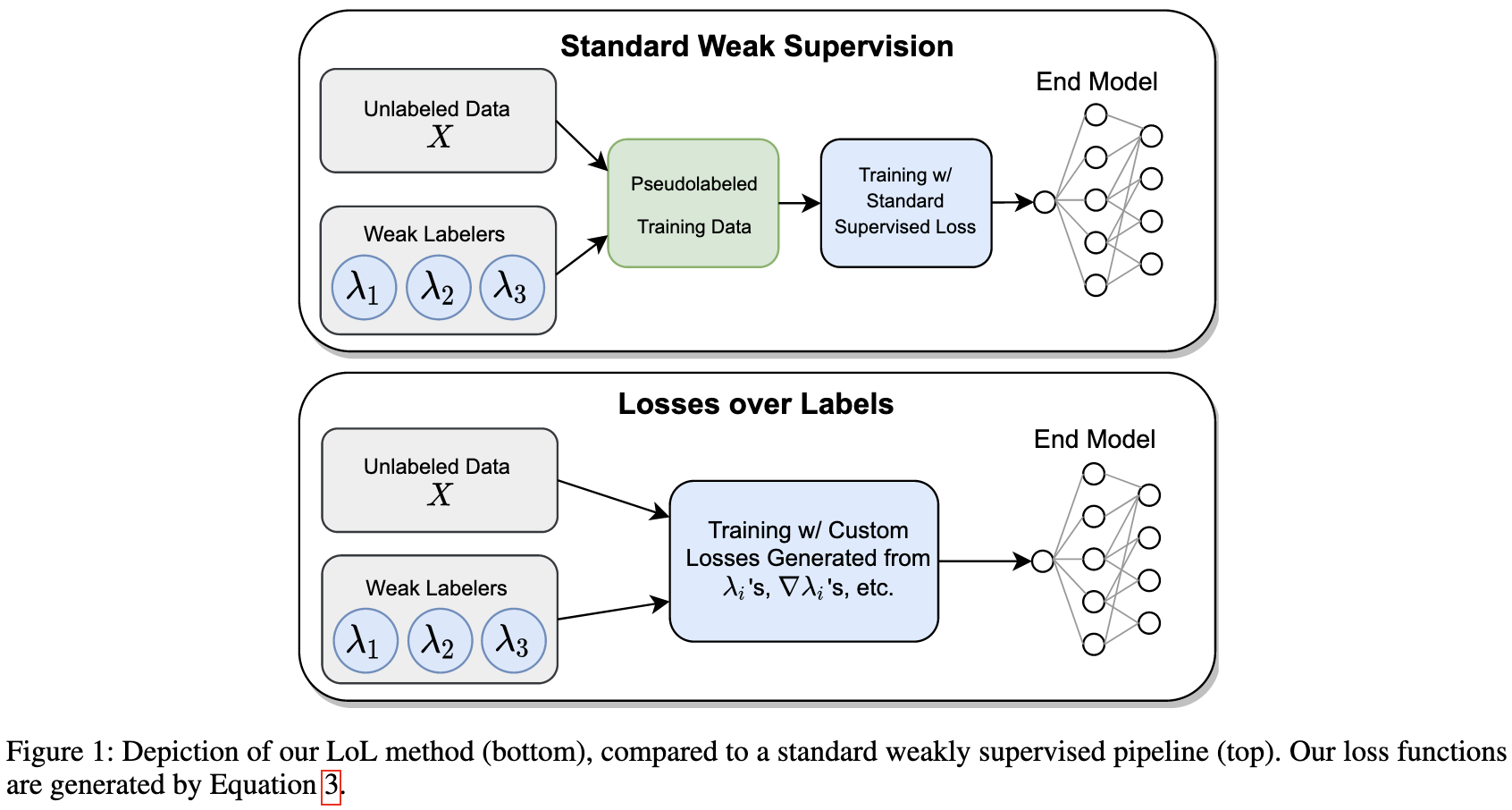
Losses over Labels: Weakly Supervised Learning via Direct Loss Construction
So let’s say you’re constructing pseudo-labels for your data using some combination of heuristics. They find that it’s better to just treat the heuristics as loss functions and optimize them directly, instead of constructing the pseudo-labels and using a normal loss like cross-entropy.

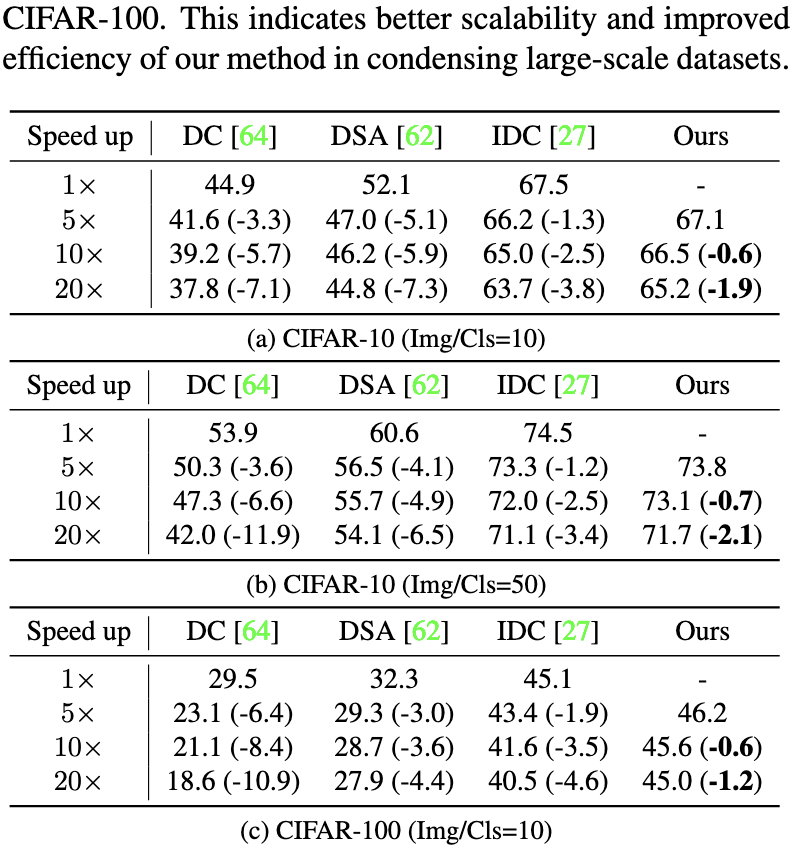
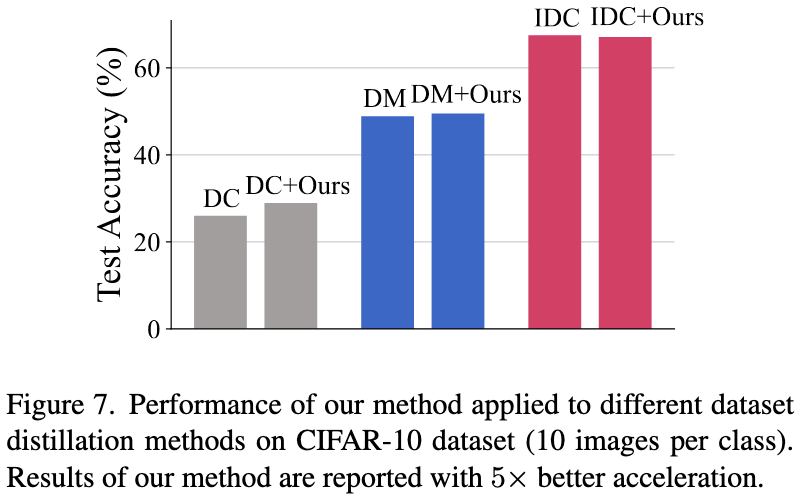
Accelerating Dataset Distillation via Model Augmentation
Dataset distillation is the task of constructing a smaller dataset that lets a model achieve similar accuracy as with the full dataset. Unlike data pruning, the samples in the distilled dataset can be the results of some optimization process, rather than unmodified samples from the original data.
This paper introduces a much faster method for constructing distilled datasets that seems to preserve accuracy at least as well as baselines for a given dataset size.
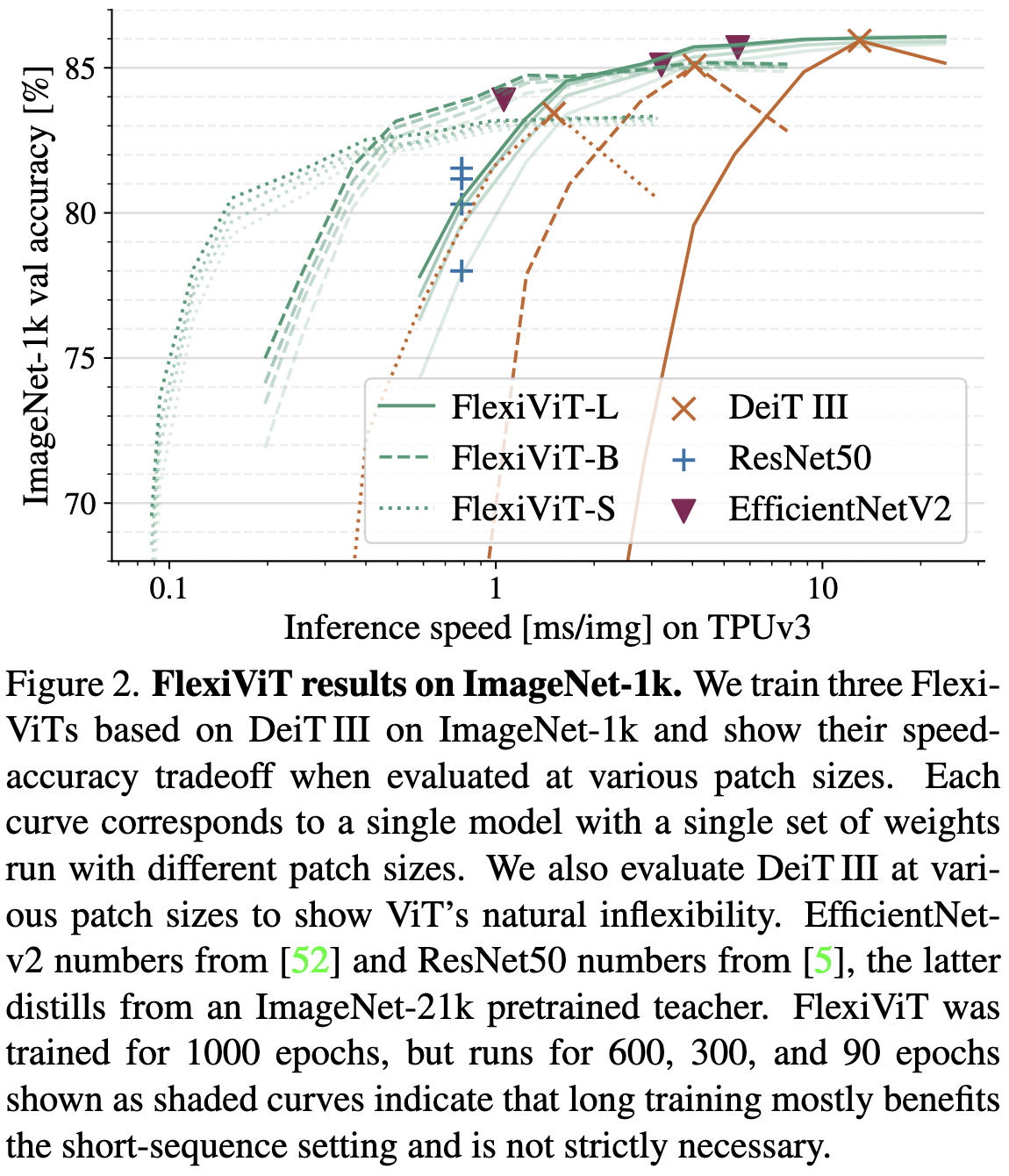
FlexiViT: One Model for All Patch Sizes
Vision transformers split images into many (often disjoint) patches. Using more patches can yield better accuracy, but also increases the compute burden. Instead of training different models for different patch counts, they just train one model that sees random patch counts and learns to deal with it.
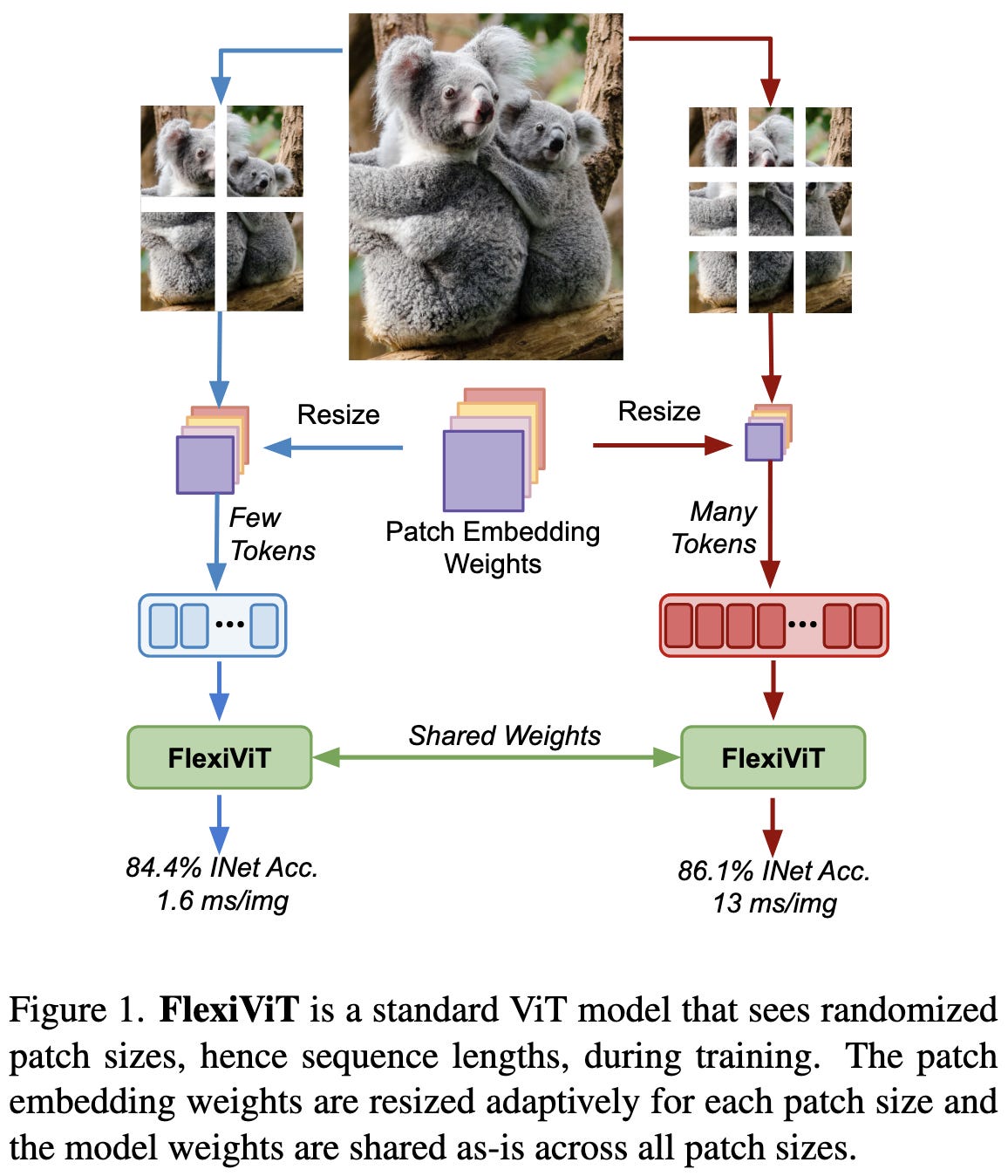
This is cool because it lets you adjust where you are on the inference latency vs accuracy tradeoff curve without having to swap out the model. So if you, say, wanted to meet an inference latency target across tons of different smart phones, you could get away with deploying fewer unique models.
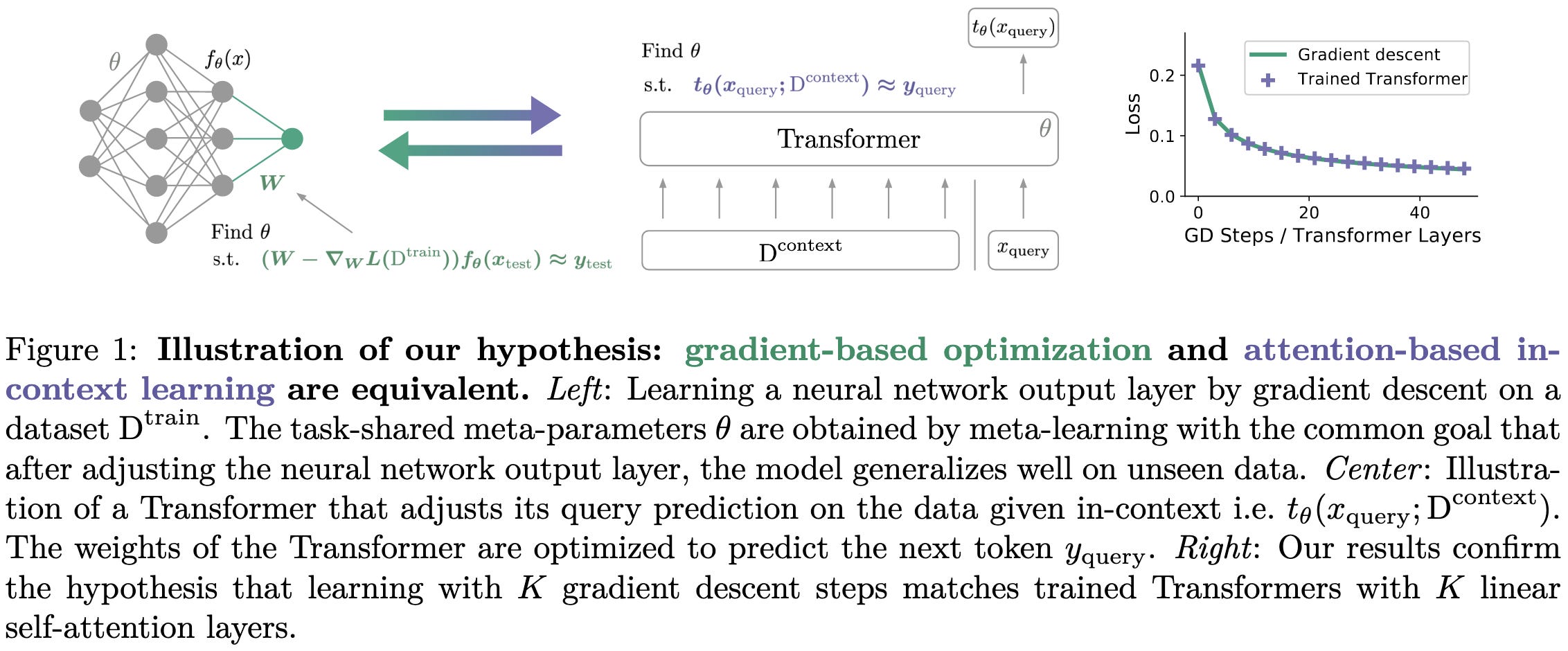
Transformers learn in-context by gradient descent
If you just stack a bunch of attention layers and feed in examples (as text) within the prompt, the forward pass of the model can implement gradient descent. If you add FFNs, it can go from linear to nonlinear regression.
Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints
You can initialize your MoE model with a dense model checkpoint. The experts in a given layer all get initialized with the values from the original FFN.
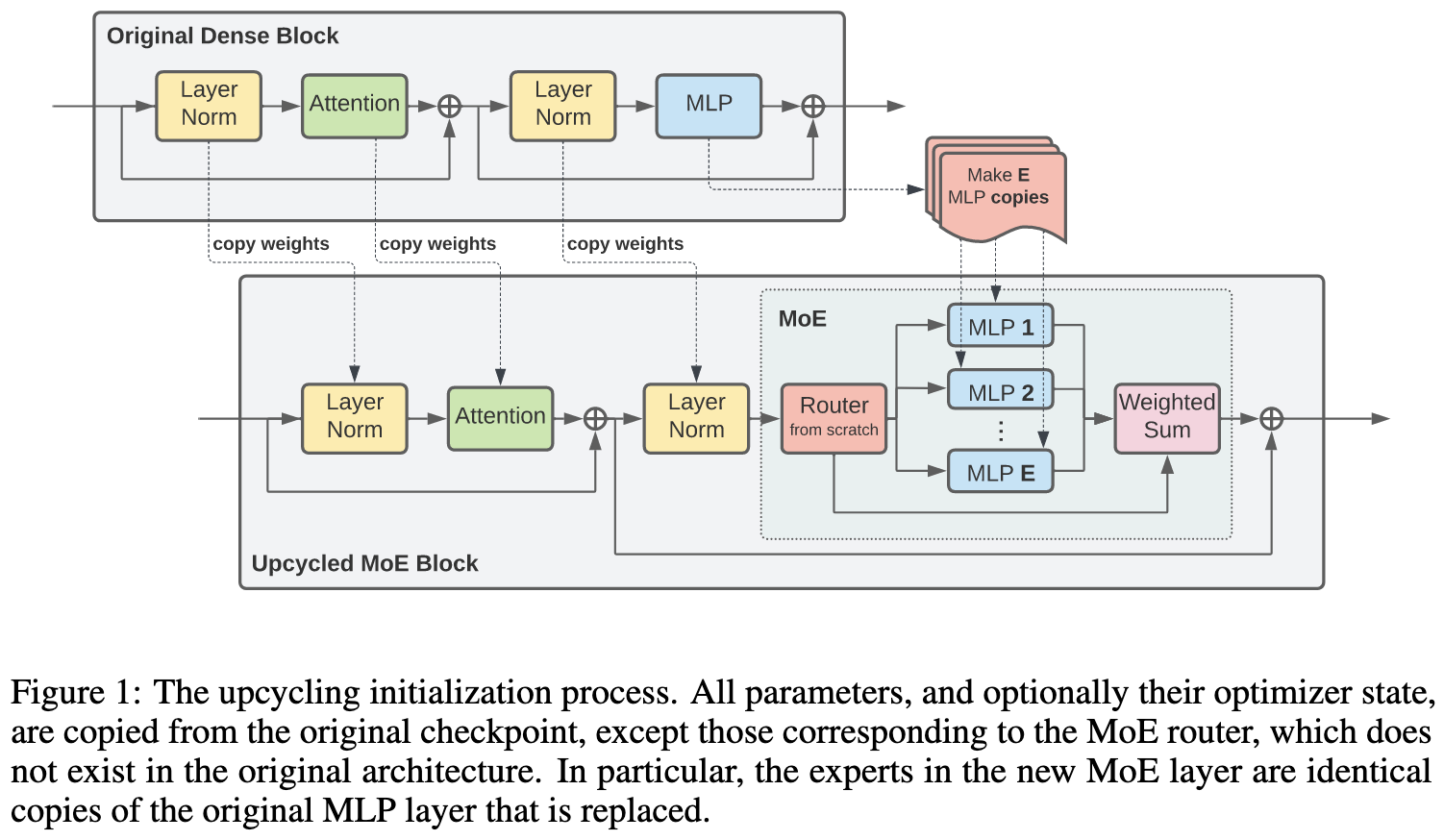
They use top-2 expert-choice routing with a capacity factor of 2. Since MoE models are slower than dense ones when routing to multiple experts and with capacity factor > 1, starting from a dense model saves training time overall.
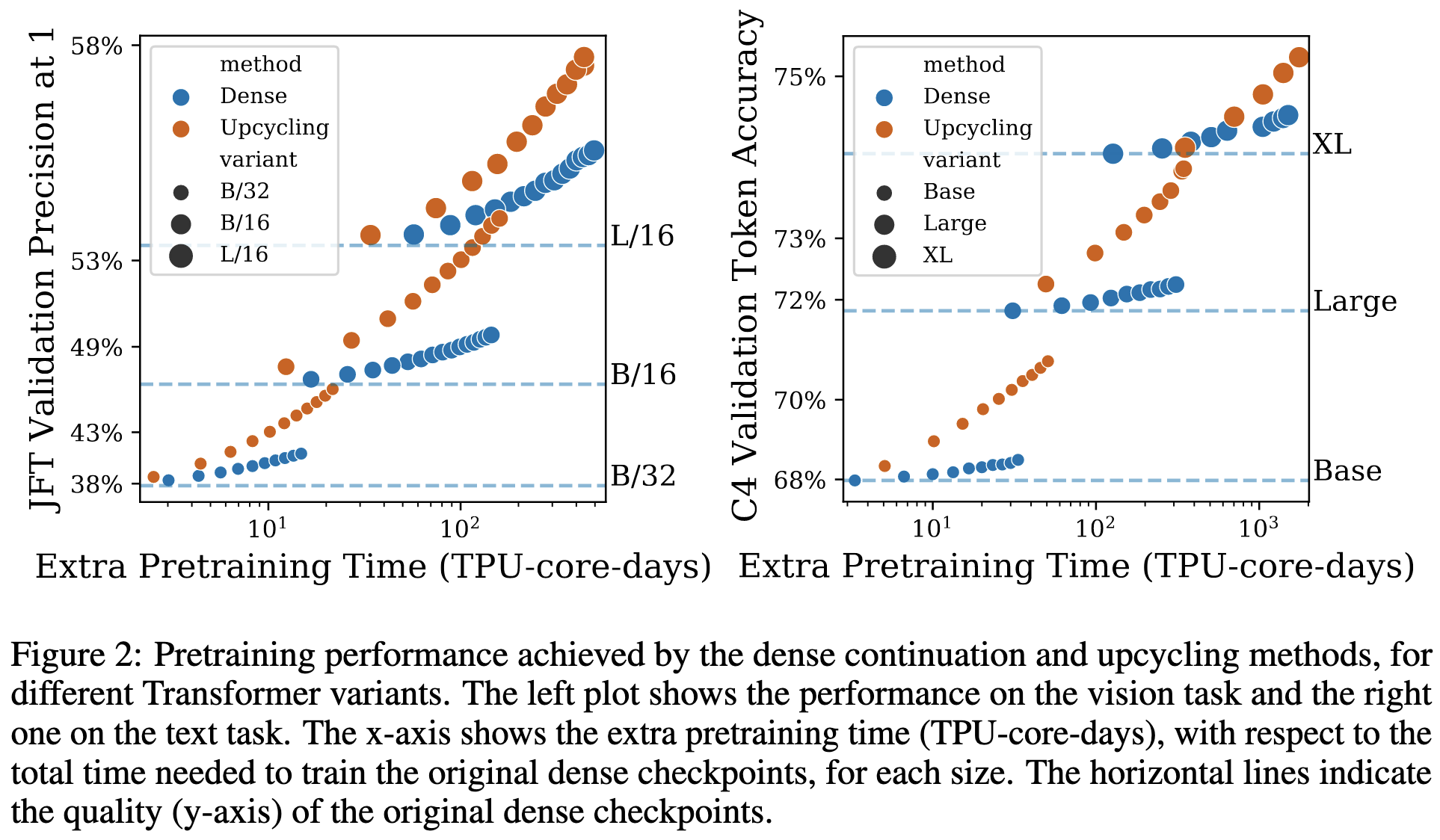

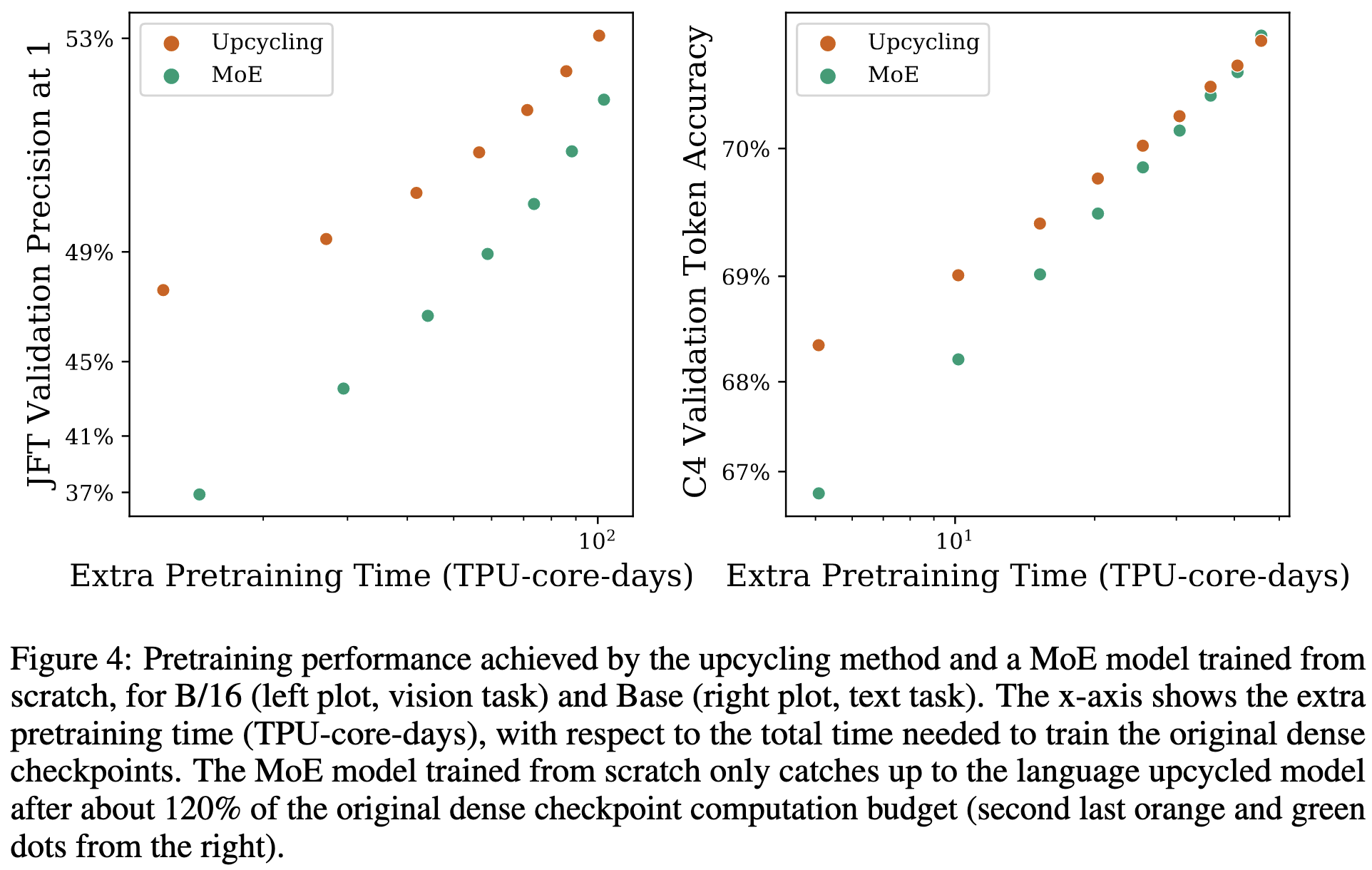
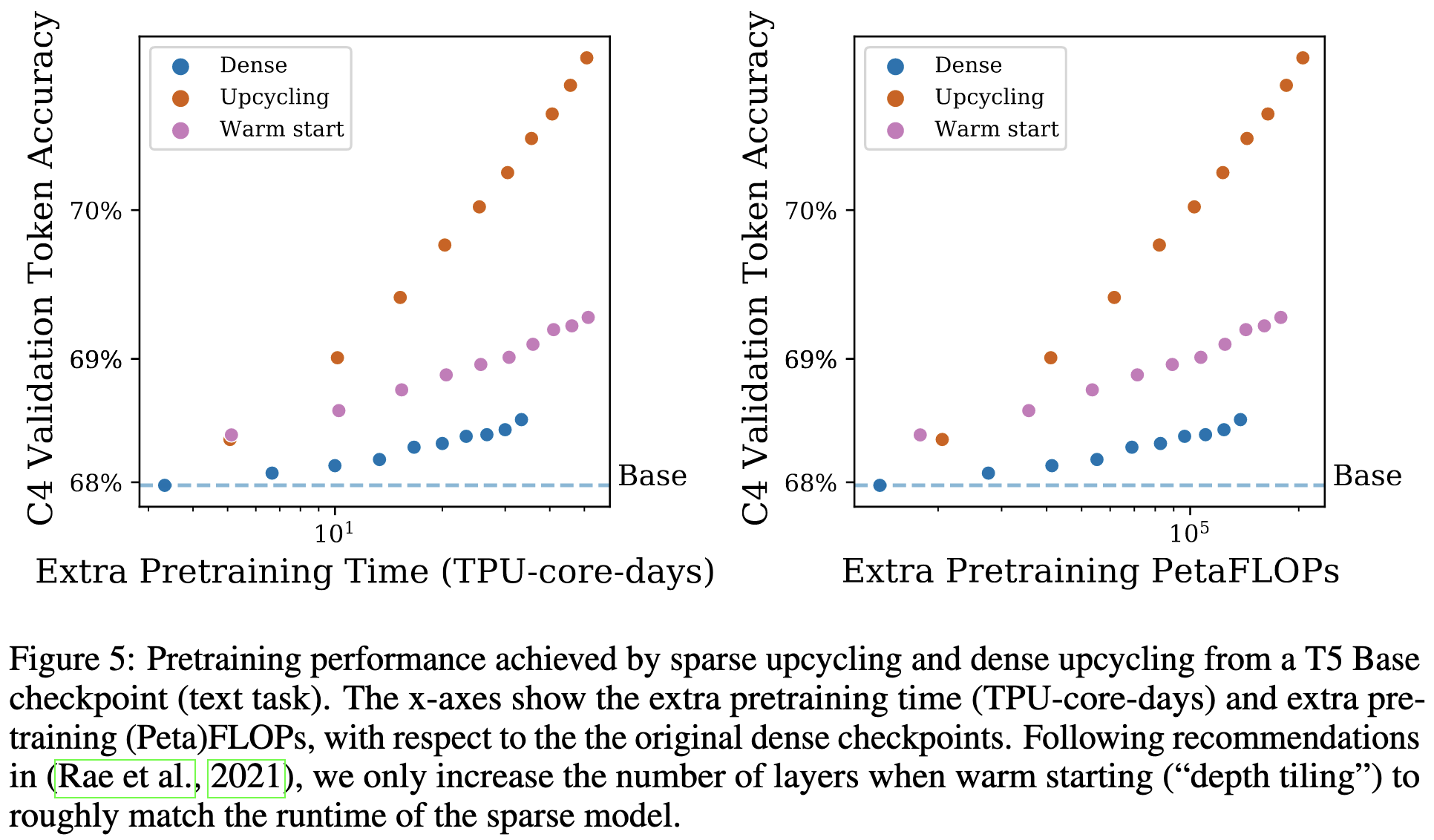
They also reproduced the superiority of expert choice routing vs top-k.
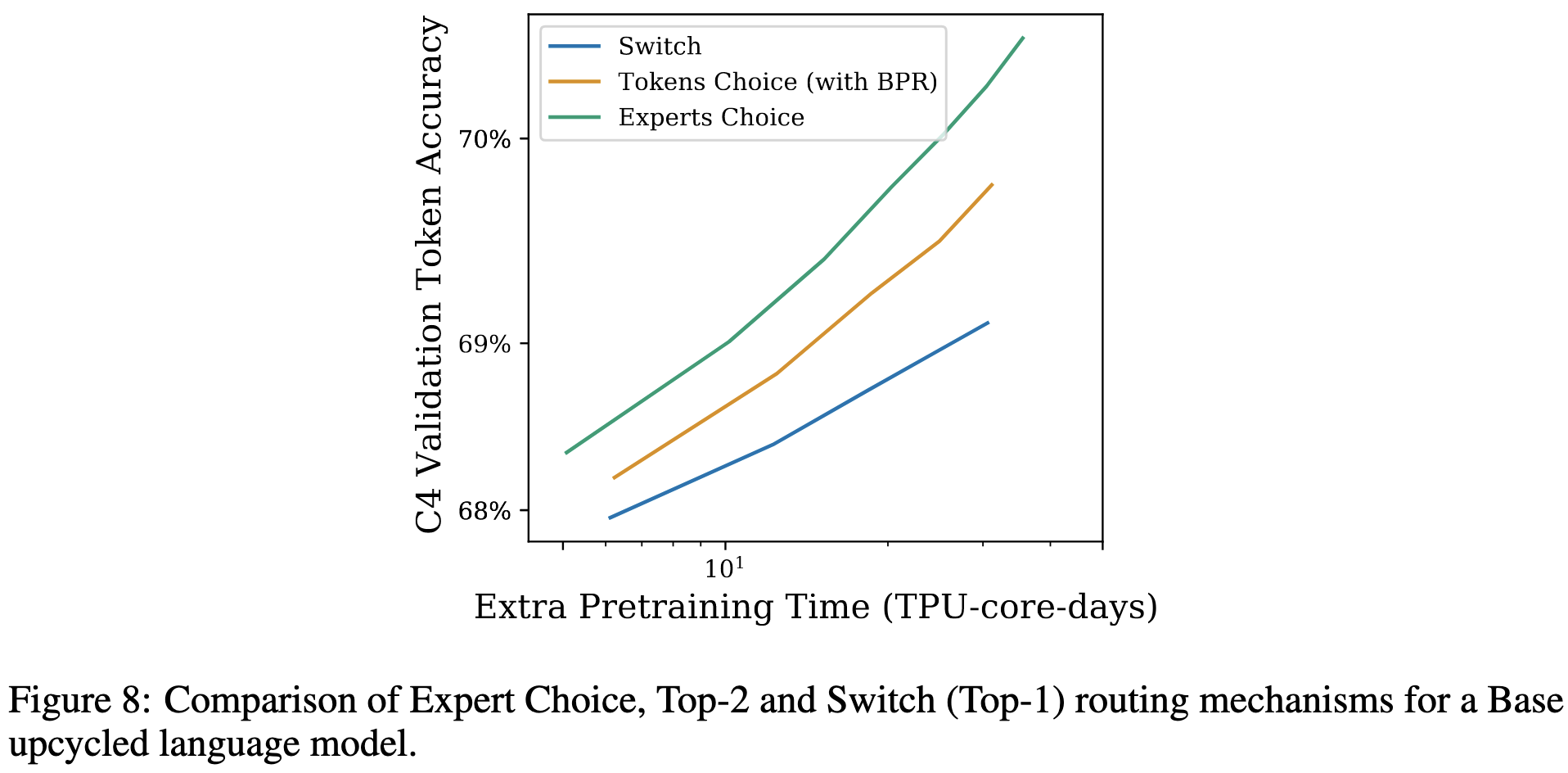
Cool stuff. Seems like a significant and consistent improvement in time-to-accuracy.
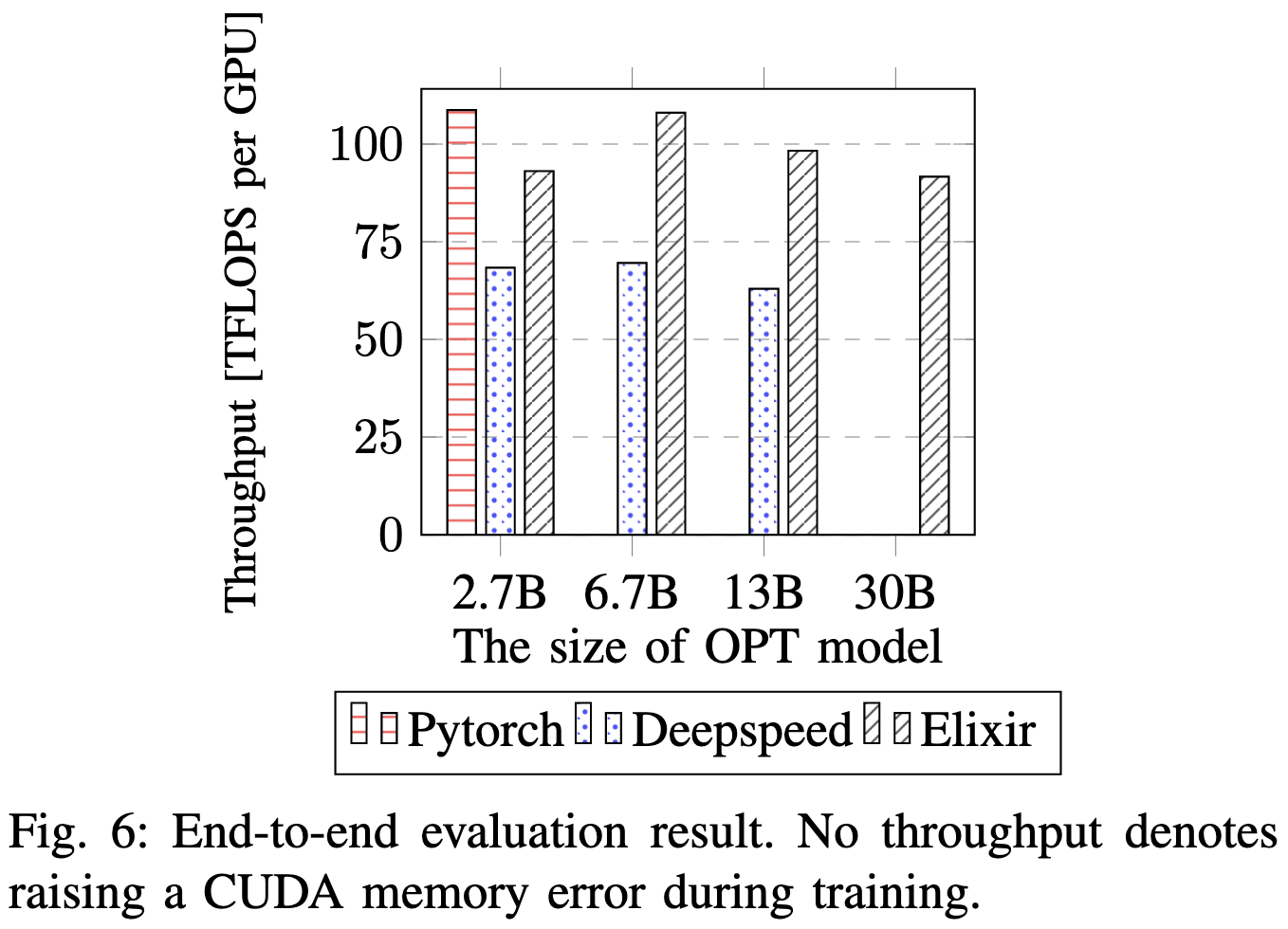
Elixir: Train a Large Language Model on a Small GPU Cluster
They implemented really flexible parallelization that allows different process groups and sharding for different parameter tensors..
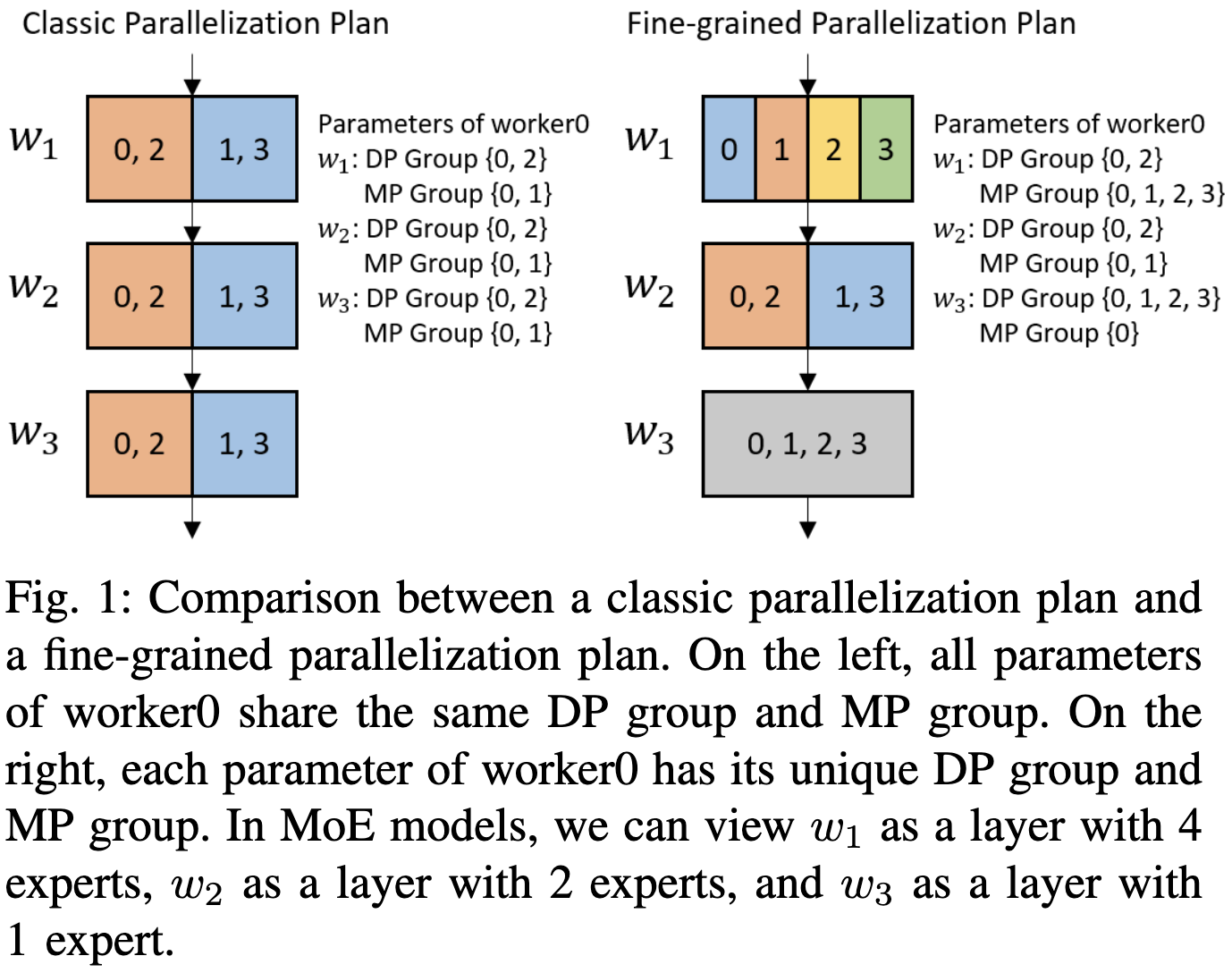
There’s an elegant observation here that you can pretty much just attach pre- and post- hooks in forward and backwards.
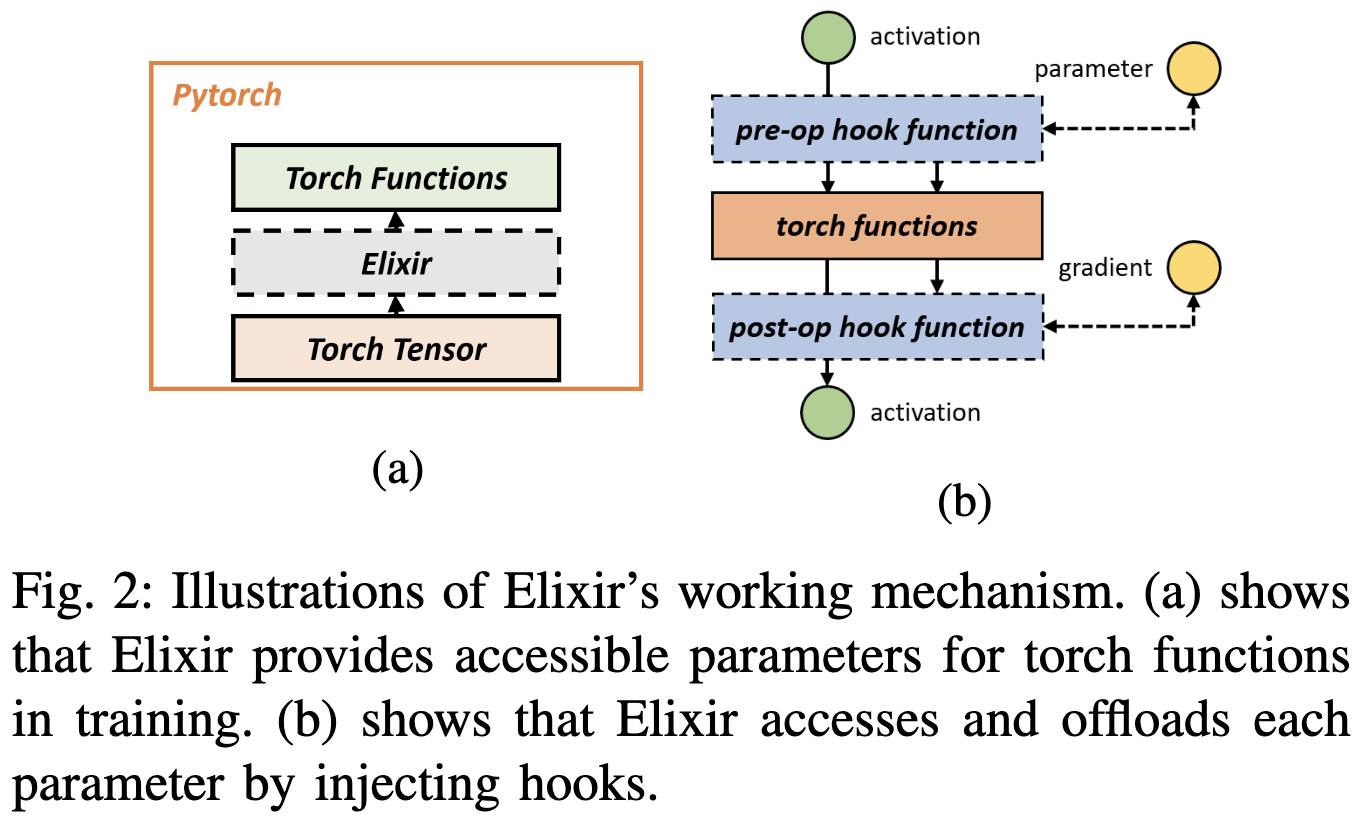
The crazy part here is that they built a hierarchical distributed caching scheme. They treat the CPUs and GPUs as a coherent memory space and cache the traversal order across steps to optimize the loading and eviction policy. They also point out that you can get DDP, Zero-2, and Zero-3 as particular cache policies.
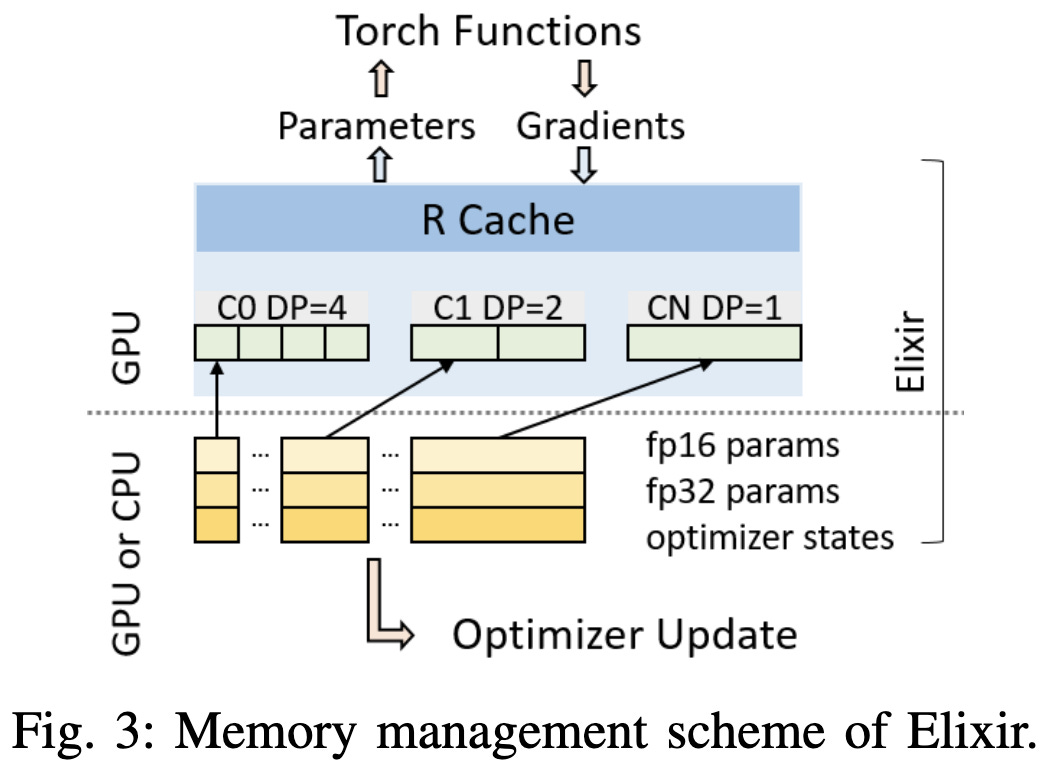

This approach maybe seems to do better than a simple Pytorch baseline and DeepSpeed. Mostly avoid avoids OOMing when you have a large model and few GPUs.