
2022-7-31 arXiv roundup: Transformer vs CNN showdown, 1000x smaller DLRM, ELECTRA improvements

This newsletter made possible by MosaicML.
An Impartial Take to the CNN vs Transformer Robustness Contest
A robustness throwdown featuring {ViT, Swin} vs {BiT, ConvNeXt} evaluated on various tasks.

First, they measure the learning of spurious features using datasets designed to assess simplicity bias, background bias, and texture bias. The transformers and the CNNs behave similarly.

For OOD detection, transforms and CNNs again work equally well. They also point out that the area under the precision-recall curve (AUPR) can be a misleading metric because it depends on whether you call in-distribution or out-of-distribution “positive.”

What about calibration? Similar story. Which model does better depends on the task. If you’re looking for a clear pattern in this table, there isn’t one—and that’s the point.

And what about detecting misclassifications? Yep, same deal. And they also point out that some models do well on calibration but are super overconfident sometimes, suggesting that both metrics are helpful.

Overall, they find no evidence that vision transformers as a family are more robust than CNNs and therefore
“discourage the common trend in the literature to give unnecessary praise to the self-attention module of Transformers anytime these perform better against CNNs.” 1
Their conclusions are consistent with those of the MetaFormer and ShiftViT papers, so I’m starting to suspect that self-attention is more of an NLP inductive bias than a universal win. Though multiplicative interactions in general (which include, e.g., Squeeze-and-Excitation and Dynamic ReLU) do seem to be consistent wins as long as you can avoid being too memory-bandwidth-bound.
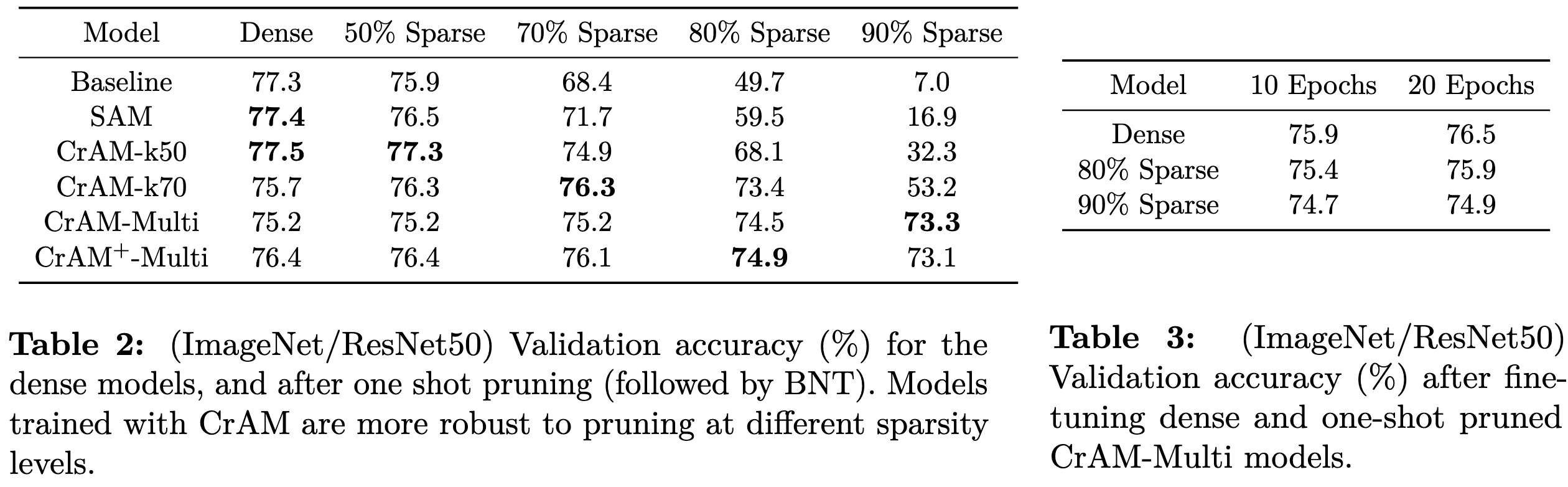
CrAM: A Compression-Aware Minimizer
They make pruning work better by altering the optimization. In particular, they adopt a loss similar to that of SAM:

This objective requires that the loss be robust to both the chosen compression mechanism and small perturbations of the weights. In practice, one uses the gradient direction as a tractable substitute for the max() over all directions, so that the update becomes:

They also consider a variant CRAM+ where the above loss is added to the original loss:

Which ends up just meaning that you sum the original and robustified gradients:

The overall algorithm is pretty simple. Its main downside is that it requires two backwards passes per iteration, plus the overhead of applying the compression operator to the whole network. Since the backward pass is ~2x the cost of the forward pass, I’d expect this to introduce at least a 1.67x step time slowdown.

Seems to increase the efficacy of one-shot post-training pruning at iso epochs. Helps more than SAM when fine-tuning after pruning.

Toward Transparent AI: A Survey on Interpreting the Inner Structures of Deep Neural Networks
A good survey on methods for probing what’s going on in models. I like both the quality of the figures and the fact that they create an informative taxonomy, rather than just dumping a semi-organized list of papers.

Here’s how they break down methods for understanding individual neurons:

And subnetworks:
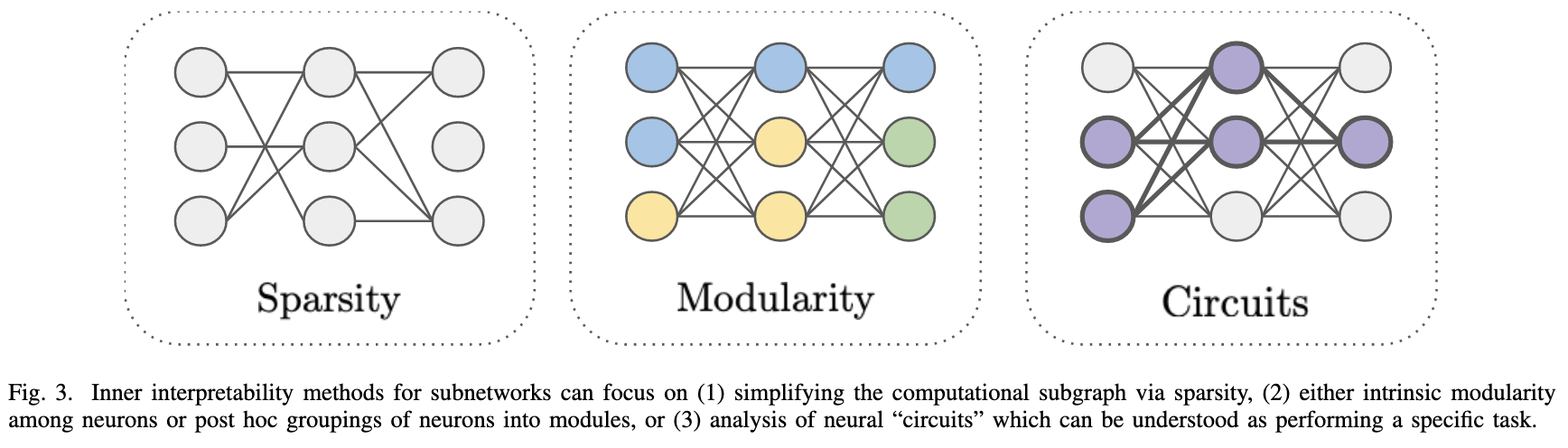
And neural representations:

RIBBON: Cost-Effective and QoS-Aware Deep Learning Model Inference using a Diverse Pool of Cloud Computing Instances
Suppose you’re trying to reduce your inference costs. Further suppose that:
Your queries arrive quickly enough that you can often batch them
You have a specific latency target and a specific fraction of the time you’re allowed to miss this latency target
You have access to a variety of different instance types through your cloud provider
Two or more instance types a) are fast enough to meet your latency requirements for small enough batch sizes, and b) have varying price vs batch size vs throughput characteristics.
In this scenario, it might make sense to use two or more different types of instances to handle your queries. E.g., in the below picture, they use the slack in their 1% latency failure target to use 3 fancy instances and 4 cheap ones (the square) rather than 5 fancy instances (the triangle). Since you seemingly can’t get away with just using more cheap instances (the star) at the same cost, I think there’s an underlying assumption about throughput varying with batch size.

They propose to find a good combination of instances for a given workload using Bayesian optimization.

Their approach can save ~10% in cost across various representative computer vision and recommendation models.

Discrete Key-Value Bottleneck
They replace vectors in the latent space with their nearest centroids in disjoint subspaces. The centroids are learned using a moving average process similar to minibatch k-means.

The intuition here is that, when adapting to different input distributions, only certain combinations of codes will come up, so the codes corresponding to different input distributions will be unaffected.

They conduct a variety of experiments on CIFAR-{10,100} and TinyImageNet to show that their approach reduces catastrophic forgetting, helps the model integrate new information, and mitigates poor performance in the presence of non-i.i.d. training data.

Long story short, it works:


Similarity search, approximate matrix multiplication, VAEs, GANs, and now robustness to distribution shifts—what can’t product quantization help? I kind of mean this as a joke but I also kind of don’t.
The trade-offs of model size in large recommendation models : A 10000× compressed criteo-tb DLRM model (100 GB parameters to mere 10MB)
They compress the crap out of the embedding tables in recommender models by sketching them.

Their main theorem lets them sketch the N x D embedding tables in Dlog(N) space instead of the more obvious Nlog(D) space from a straightforward application of the Johnson–Lindenstrauss lemma.

In practice, their sketch matrix is random but uses chunks of 32 elements for efficiency, rather than individual scalars.
Consistent with previous work, they find that they can compress embedding tables for the Criteo dataset ~1000x before losing significant accuracy.

This compression also reduces inference latency:

The catch is that they need to train for longer when compressing the embedding tables more. Though this is mostly made up for by the iterations running faster.

The training time is actually so close to remaining constant that my inner scientist wonders if there’s some underlying theory to be had here—something about expressing learning in terms of total parameters * updates; or maybe the difficulty of optimization subject to random parameter sharing.
Overall, not super new methodologically, but has some interesting theory and encouraging results for recommender model compression. Also makes me wonder whether we should be sketching MoE layers…
Adaptive Second Order Coresets for Data-efficient Machine Learning
They select a subset of samples by formulating a submodular cover problem and selecting samples based on their preconditioned gradients.

The method has theoretical guarantees in the convex case stemming from the submodularity. It seems to do better than both random and other data pruning methods on CIFAR-10, CIFAR-100, and BDD100k. Not sure how applicable this is to neural nets and other non-convex problems since the datasets they use are small and the target accuracies used to evaluate speedup are fairly low.

Author’s note: arXiv was a little slow this week so the below papers are unusually good ones from past weeks (or years…) that I’ve been meaning to read.
Breaking the Softmax Bottleneck: A High-Rank RNN Language Model
This is one of only three modifications to transformers that a recent large-scale study found to be effective.
The authors point out the “softmax bottleneck,” which is that softmaxes use a fixed embedding dimension that might not be expressive enough. Of course, one could simply increase the dimensionality of the embedding, but that linearly increases both space and compute costs.
They propose to instead replace individual softmaxes with a convex combination of K different softmaxes. They all share the same weight matrix W but each have different input embeddings h.
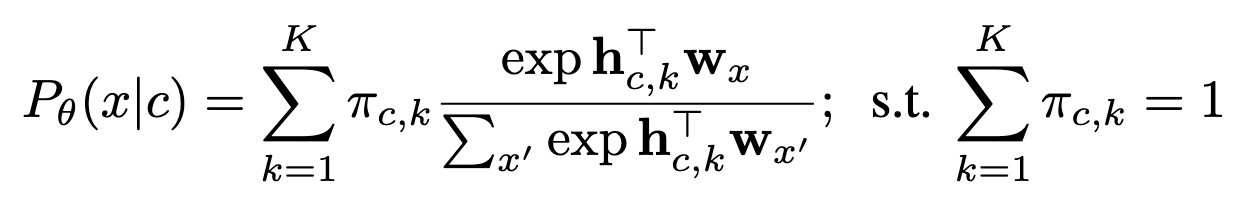
The different embeddings come from inserting another layer with a tanh activation and a unique weight matrix for each mixture element (note that g here is also an embedding, not a gradient):

The mixing weights are chosen dynamically using a softmax over the original embeddings (before the tanh layer):

The main result is that this approach reduces perplexity quite a bit.

It also succeeds in increasing the effective rank of the softmax, meaning their intervention does what it’s intended to do, rather than just helping through some unrelated mechanism.

The downside is that it slows down training quite a bit. I can’t figure out if these numbers are for just their layer vs vanilla softmax or for the model as a whole though.

I’m reading this as another win for multiplicative interactions (in the form of the mixing weights) and mixture-of-experts-like modules.
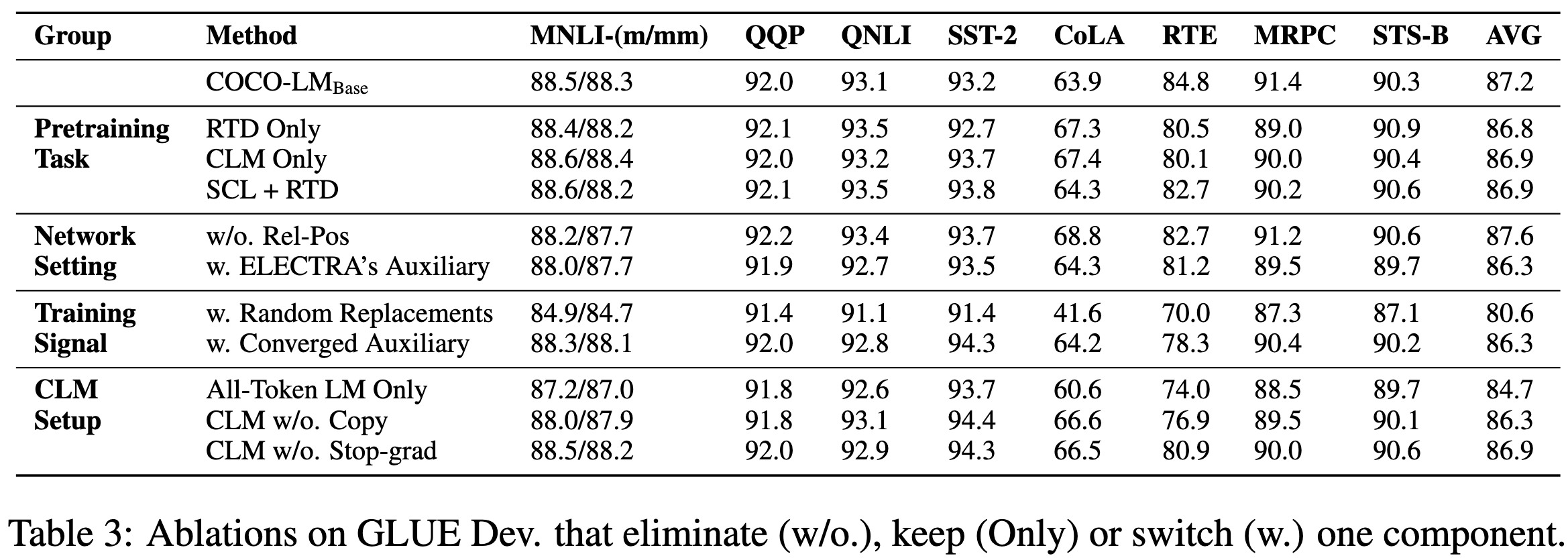
COCO-LM: Correcting and Contrasting Text Sequences for Language Model Pretraining
They propose an improved version of ELECTRA, in which a smaller auxiliary model helps generate corrupted inputs for the main model being trained.

They optimize a masked language modeling (MLM) objective for the auxiliary model and two objectives for the main model:
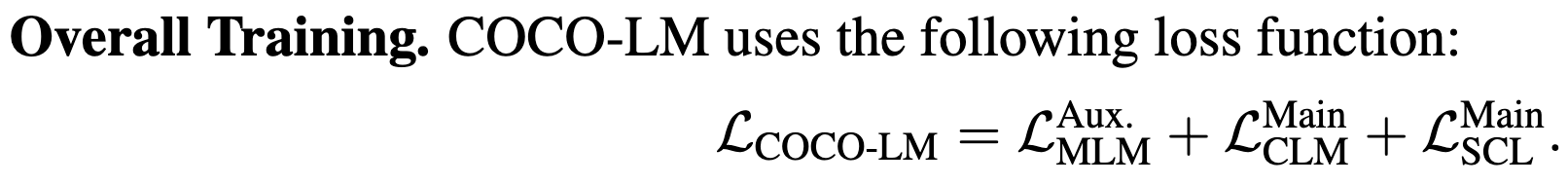
The MLM objective for the auxiliary model is exactly what it sounds like. They mask out tokens in its input and train it to predict what was masked.
The first objective for the main model is “corrective language modeling,” meaning they have it predict what the original sequence was after the auxiliary model replaces some of the tokens.

This prediction decomposes into predicting whether a token was copied from the true input or corrupted, and then predicting what the original token was if it was corrupted. This is nice because the model gets to train on all the tokens, but also gets to predict words instead of just a binary classification.
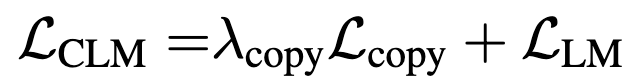
The second objective, “Sequence Contrastive Learning,” trains the model to output the same representation for a cropped version of the sequence and the corrupted version of the sequence, with a penalty for resembling other sequences in the batch.
In terms of results, COCO-LM appears to significantly increase both final accuracy and time-to-accuracy.

Though note that you need to get hparams like the amount of cropping right:
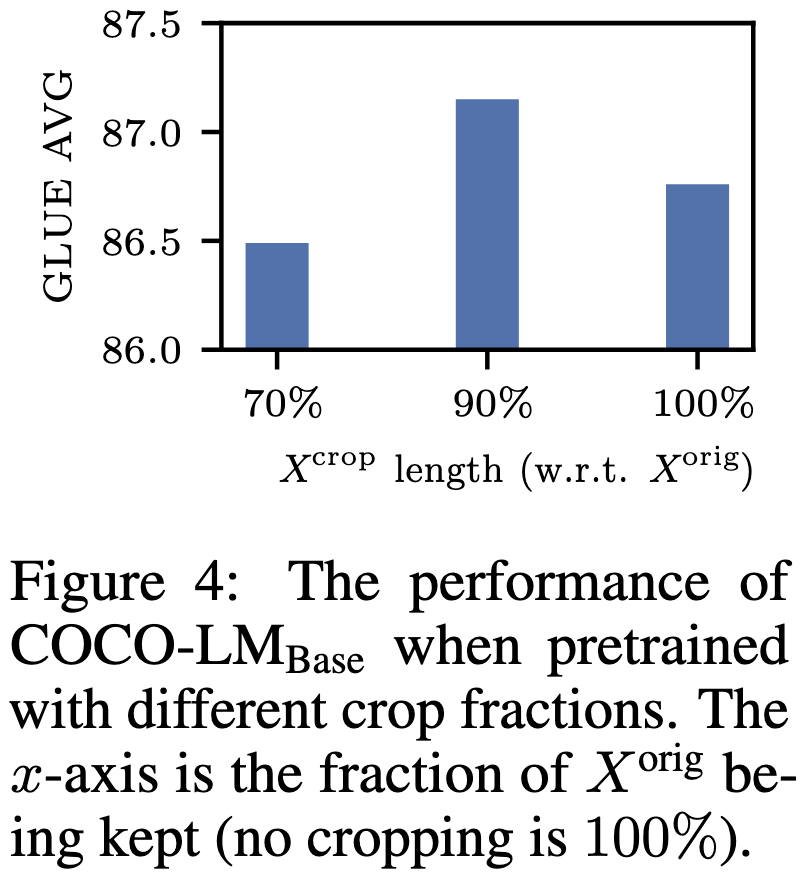
They also have a lot of good ablations and exploration of what’s really going on with and without their changes.
One result I found especially interesting is that cosine similarities between nearly all sequences tend to be high without their method.

This paper seems to present a (rare!) wall-time training speedup for NLP, as well as a thorough and insightful evaluation.
METRO: Efficient Denoising Pretraining of Large Scale Autoencoding Language Models with Model Generated Signals
A big systematic study of ELECTRA-style training of transformers. By ELECTRA-style, I mean some sort of denoising where the corruptions are generated by an auxiliary model.

First of all, I’m so happy they spell out all their speedup techniques in a nice table. Digging through the combined text of the method, results, and appendix sections to figure out what’s behind the numbers is a huge pain.

They start by replacing various design decisions in their baseline, including making the auxiliary model shallow rather than narrow, using T5 relative position embeddings, using a larger vocabulary of 128K tokens, and respecting document boundaries when constructing sequences.

From there, they try a host of other techniques, mostly from the existing literature. For example, using the loss terms introduced in COCO-LM, using a simplified variant of COCO-LM’s corrective language modeling loss, and removing dropout from the auxiliary model to avoid separate passes for training and sampling corruptions.
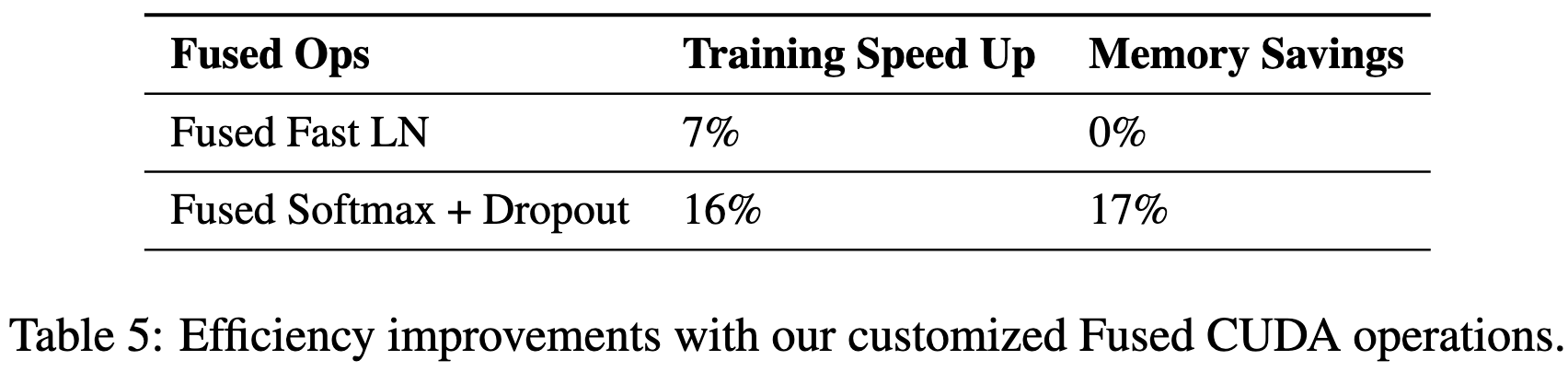
They also wrote some fused CUDA kernels and found that they speed up training and save some memory.
By considering these many interventions and composing together those that work, they’re often able to outperform existing approaches:



Definitely a paper worth studying in detail if you care about maximizing the efficacy of your language model pretraining.
I want to paint this quote on a billboard at NeurIPS.