


2022-9-4 arXiv roundup: Deep nets without multiplies, Transformer world models, How best to pretrain

This newsletter made possible by MosaicML.
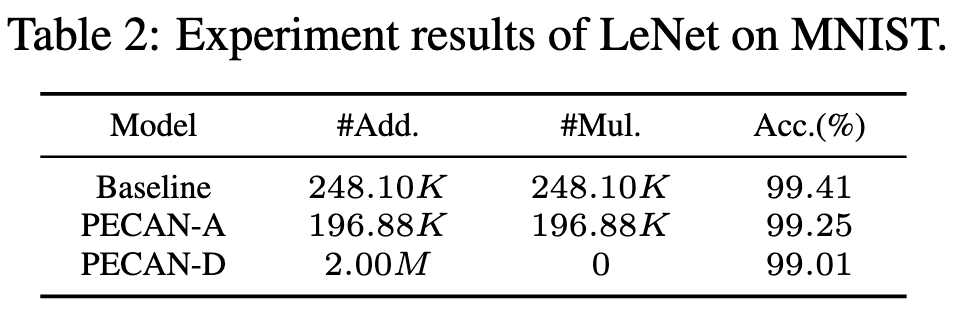
PECAN: A Product-Quantized Content Addressable Memory Network
They apply a variant of product quantization (PQ) to eliminate all the multiplies in a neural network during inference.

The basic approach is to just use PQ to approximate each of the matrix multiplies / convs. This part has been done various times over the years, but only recently did it become clear that you can use this approach to eliminate all of the multiplies.

Rather than use the hashing-based approach in that paper though, they choose PQ prototypes for each activation subvector by taking the most similar prototype as measured by L1 distance. So it’s like generic PQ, but with L1 distance instead of L2 distance. This eliminates multiplies since L1 distance just needs to subtract and sum absolute values.

In order to make the network differentiable, they approximate the hard argmax with a softmax in the backwards pass, and relax the L1 norm’s sign() function gradient to something smoother.

Their approach seems to work, though, unsurprisingly, not as well as the floating-point baseline. The zero-multiply variant (PECAN-D) seems to get hit especially hard from an accuracy perspective. You can see this both from the accuracy being lower and from the much higher add counts—the latter is a product of needing to increase the number of prototypes to get the accuracy anywhere close.

Their ablation experiments show that both optimizing the centroids and the network as a whole are important.

I suspect that most of the accuracy loss is from the difficulty of optimizing around L1 norms. If you look at the results for AdderNet (below), you see similar accuracy losses. Since AdderNet is just swapping out dot products for negative L1 norms in all the convs and linears (with no PQ, etc), it’s essentially isolating the optimization penalty from using L1 norms.


The way I think about this line of work is that:
Avoiding multiplication actually could yield huge power savings with the right hardware. If you look at the transistor counts of adders and multiplexers vs multipliers, it’s a huge difference.
But we don’t need to be purists. If you need some multiplies to make everything work, that could still be a big win.
Lookup-based approaches are strictly better than binarization. They subsume binarization as a special case, are more expressive, and, in most hardware, have no extra overhead. In fact, if you write a binary GEMM with a bunch of XNOR + popcount instructions, Clang and GCC will convert it to table lookups (source: I’ve done this and looked at the assembly).
So by the standards of preserving the original accuracy, this is a negative result. But by the standards of being a better alternative to binarization, this is a promising proof of concept.
Efficient Sparsely Activated Transformers
Neural architecture search for transformers that incorporates mixture of experts and an explicit latency target.

They start with a baseline network that they modify by swapping out the individual modules. Throughout the paper, the baseline networks they focus on are Transformer-XLs.

Each “super block” replaces an original block and can be one of a few different modules. Each candidate module is given some of the training data and has a learnable weight. At the end of training, the module with the highest weight is the one that’s used in the final architecture.

In case you don’t know how Mixture of Expert (MoE) layers work, you basically make E copies of some module and route each token to one copy. This gets you E times as many parameters but requires almost no extra FLOPs.

To ensure the model hits its latency target, they precompute estimated latencies for each module in each block and add a penalty term if the total estimated latency is too high. This can make the model select faster modules.
In terms of accuracy, this approach works at least as well as both the baseline model and existing alternatives.

In terms of latency, it beats the baseline model significantly and related work by a small but consistent margin.

Putting these results together, they get much lower perplexity at a given latency than their baseline.

I really like all the profiling results they’ve included. I found it especially surprising how much latency the multiheaded attention adds, especially with 8+ heads.


There also seems to be a ~1.5x penalty in the MoE latency stemming from the lack of load balancing. Or even a 3.5x penalty at batch size 1.

Lastly, their simple module-by-module latency estimates correlate highly with true latencies—consistent with previous work showing that layerwise estimation of runtime tends to work well.

Overall, thorough work based on real-world profiling numbers that seems to outperform some solid baselines.
Visualizing high-dimensional loss landscapes with Hessian directions
Proposes looking at directions corresponding to largest and smallest eigenvalues of the Hessian. But mostly, I’m a sucker for loss landscape visualizations—anything that’s both an objective measurement and useful for intuition building is great in my book.

I find it especially interesting that, even along the most curved direction, the curvature isn’t monotonic (let alone constant) as you move towards the minimum. If it were monotonically increasing, we’d have an explanation for the edge of stability (see this paper). But it still might work as an explanation under some different assumptions—maybe something about different degrees of curvature acting as barriers to descent.

There’s also some cool math in this paper showing that you can, e.g, estimate the Hessian trace directly from the curvature in random subspaces without computing either the Hessian or Hessian-vector products.
Survey: Exploiting Data Redundancy for Optimization of Deep Learning
A nice survey paper on a subset of methods for speeding up deep learning. They have a good taxonomy for how to think about this area, and a nice overview of how various methods fit into that taxonomy.


I really like that they summarize the key ideas and results for each paper. This takes way more effort than just figuring out which taxonomy bucket to put the paper in.
I’m not convinced many of these approaches will actually give you a wall-time speedup (we’ve tried some of them, and gotten no wins so far…). But the survey itself seems well-executed and interesting.
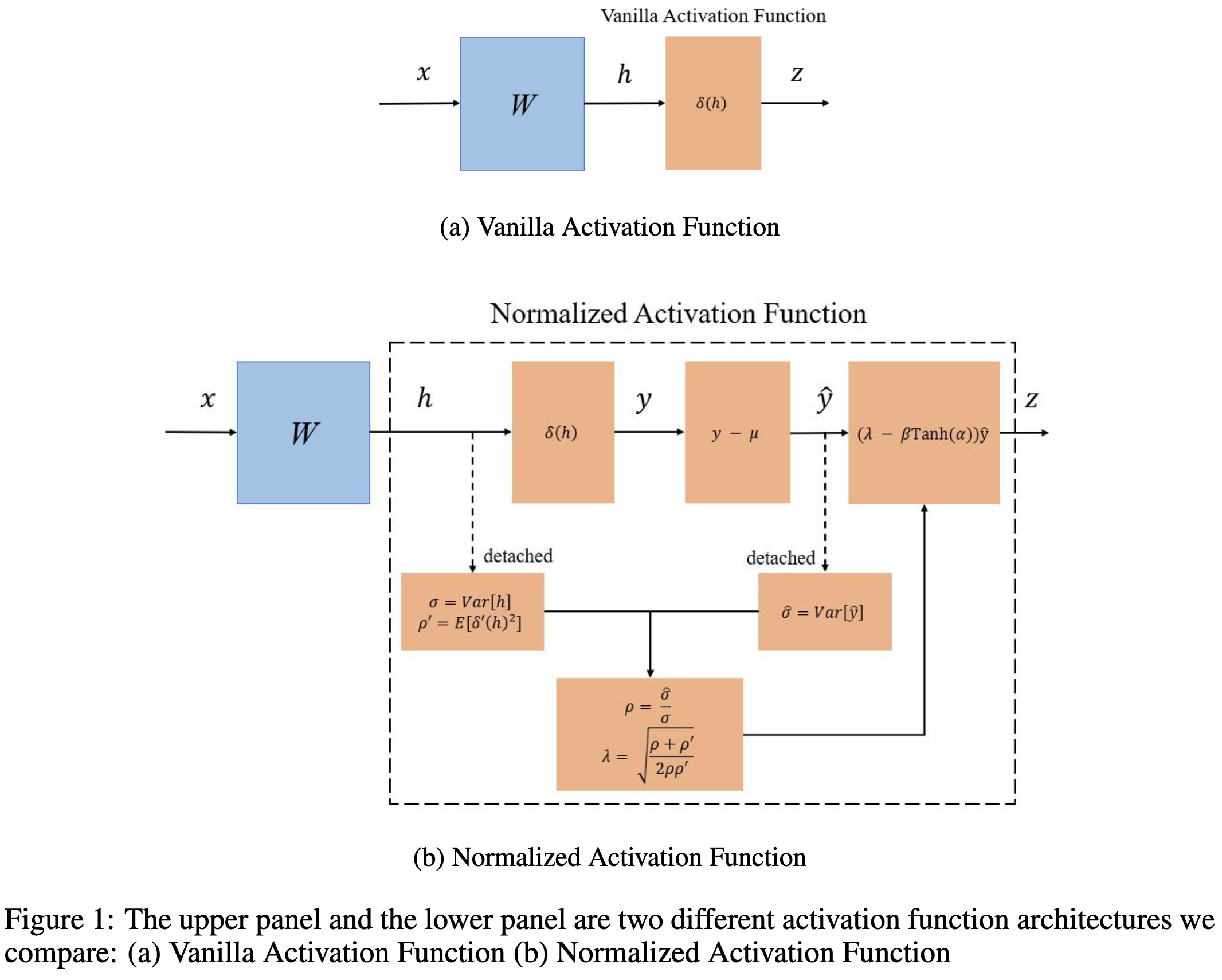
Normalized Activation Function: Toward Better Convergence
They add running statistics and an affine transform to each activation function to increase the model’s accuracy. They derive their equations from some Gaussianity assumptions and an analysis of the what it takes for the gradient variances to be the same at each layer.
Switching from the regular version of an activation function (e.g., ReLU) to their normalized version (e.g., NReLU) consistently lifts accuracy by at least 1% on CIFAR-100,

as well as ImageNet.

I’m not positive that adding all these memory-bandwidth-bound ops will be worth it from a time vs accuracy perspective, but if they’ve actually shown that normalizing gradient variance across layers significantly helps optimization, that’s an interesting result that one could exploit in all sorts of ways.
The alignment problem from a deep learning perspective
A readable essay on the alignment problem. It breaks down AI progression into three phases:
Ability to solve a range of goals. The problem here is that the reward function will never be perfectly specified, so the AI’s policy will partly do bad things.
Situational awareness. The AI knows that it’s an AI, understands its training setup, can guess about what the experimenters want, etc. This gets harder to reason about, interrogate, and reliably control.
Generalizing goals. Instrumental convergence / trying to accumulate resources, acquiring its own training data, inventing new technology, and more.
A good introduction to the topic that also discusses concrete research directions in the literature.
Generative Personas That Behave and Experience Like Humans
They develop agents with different personas to help them test game worlds. Basically, they have a dataset recording both player behaviors and “arousal” throughout play, and they use a variant of the Go-Blend algorithm to train their agents. Their variant is guided by distinct player personas rather than the full population.

Zooming out a bit, it’s interesting that they managed to train agents to be “happy” when humans would be happy. Getting large-scale datasets with these annotations will probably be hard, but I’d bet that data collection + supervised learning is more promising in the long run than, e.g., inverse RL.
Self-Supervised Pretraining for 2D Medical Image Segmentation
How should you pretrain your model if your goal is maximizing downstream segmentation quality? In particular, 1) should you do supervised or self-supervised pretraining on a general-purpose corpus like ImageNet, and 2) should you bother doing self-supervised learning on domain-specific data?

The short answer is, you should do self-supervised learning on both ImageNet and your downstream dataset. In their experiments, SSL on both datasets made the downstream supervised learning phase converge ~5x faster, and to higher accuracy.

How does this result change as a function of how much labeled data you have? With really few labeled samples, they did best with just SSL training on ImageNet. But with enough samples, anything works well except a) just doing SSL on the downstream task, and b) mixing supervised ImageNet with SSL on the downstream task.

How much does domain-specific pretraining improve supervised fine-tuning? Well, if you can’t fine-tune for long, it helps a lot (much higher curves in the upper left). But if you can fine-tune for long enough, the benefits diminish.
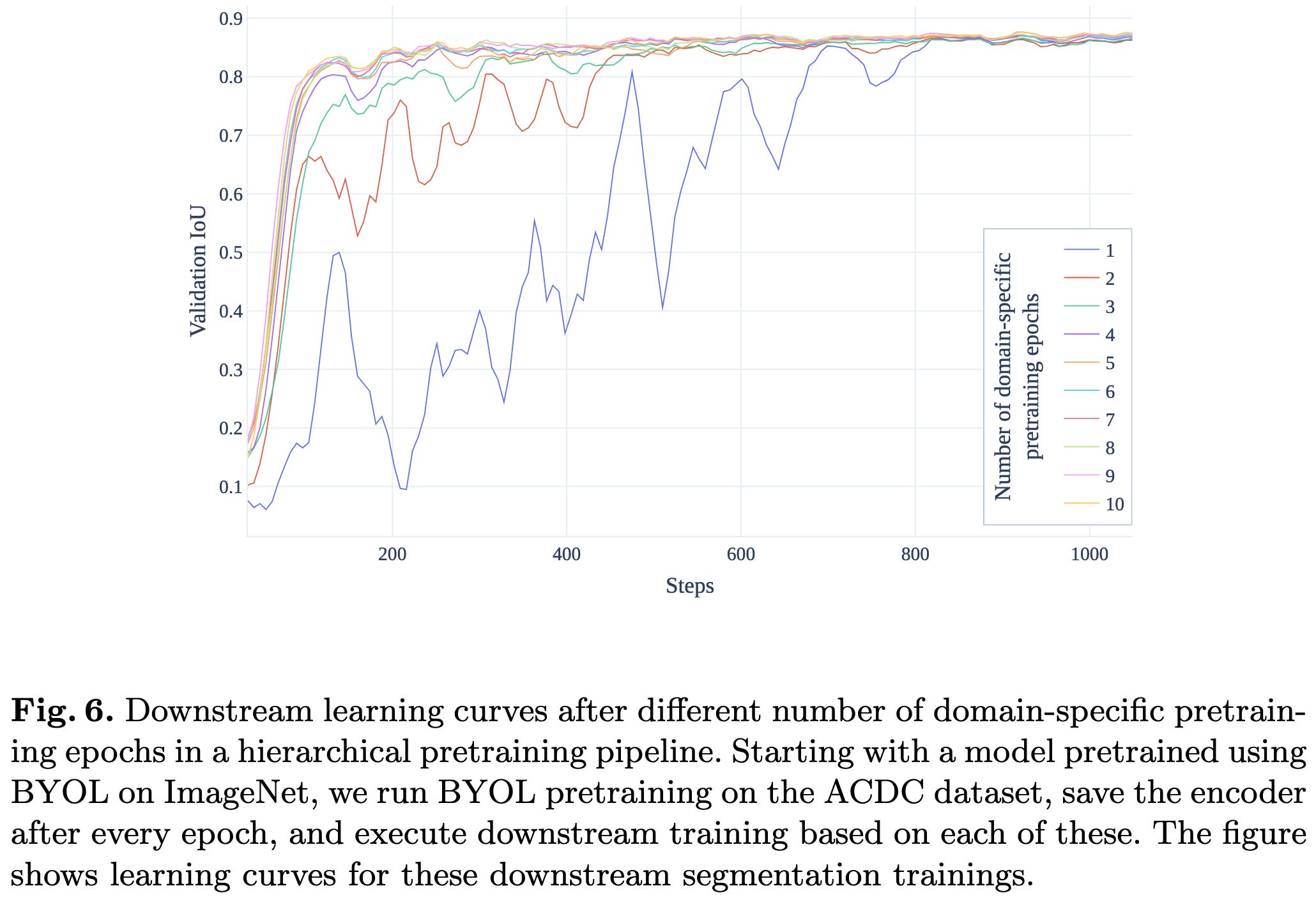
There are of course a bunch of questions about how well these results generalize across downstream tasks, pretrained models, SSL approaches, etc. But I like how thorough they were in probing the effects of different setups and answering their central questions. This work also reproduces the result from another paper that found adding an in-domain SSL step helps a lot for medical imaging.
Transformers are Sample Efficient World Models
So the problem with Atari games is that you can’t backprop through them. And for a lot of other environments (e.g., driving on roads), gathering observations is slow and expensive.

You can solve both these problems via a differentiable environment simulator—in this case, a transformer world model. Basically, they turn the Atari game state and reward into a sequence and just train the transformer to simulate the game given the agent’s actions.

The effectiveness of the transformer world model varies by game, but overall it’s pretty good. E.g., it learns the transition model of Pong perfectly after only 120 games.

Using this transformer world model lets them outperform humans on 10 of 26 Atari games after only two hours of gameplay.

This is a cool result that suggests much faster and more sample-efficient RL training might be possible. I’m not sure that’s a good thing—we just saw papers about how RL can model human behavior and emotion, as well as how RL agents could go horribly wrong given models of themselves and their creators. But it’s certainly interesting.
A Constructive Prediction of the Generalization Error Across Scales (2019)
An early paper on scaling laws using moderate-scale experiments on vision and NLP datasets.

They find clear power laws with respect to both model and dataset size.

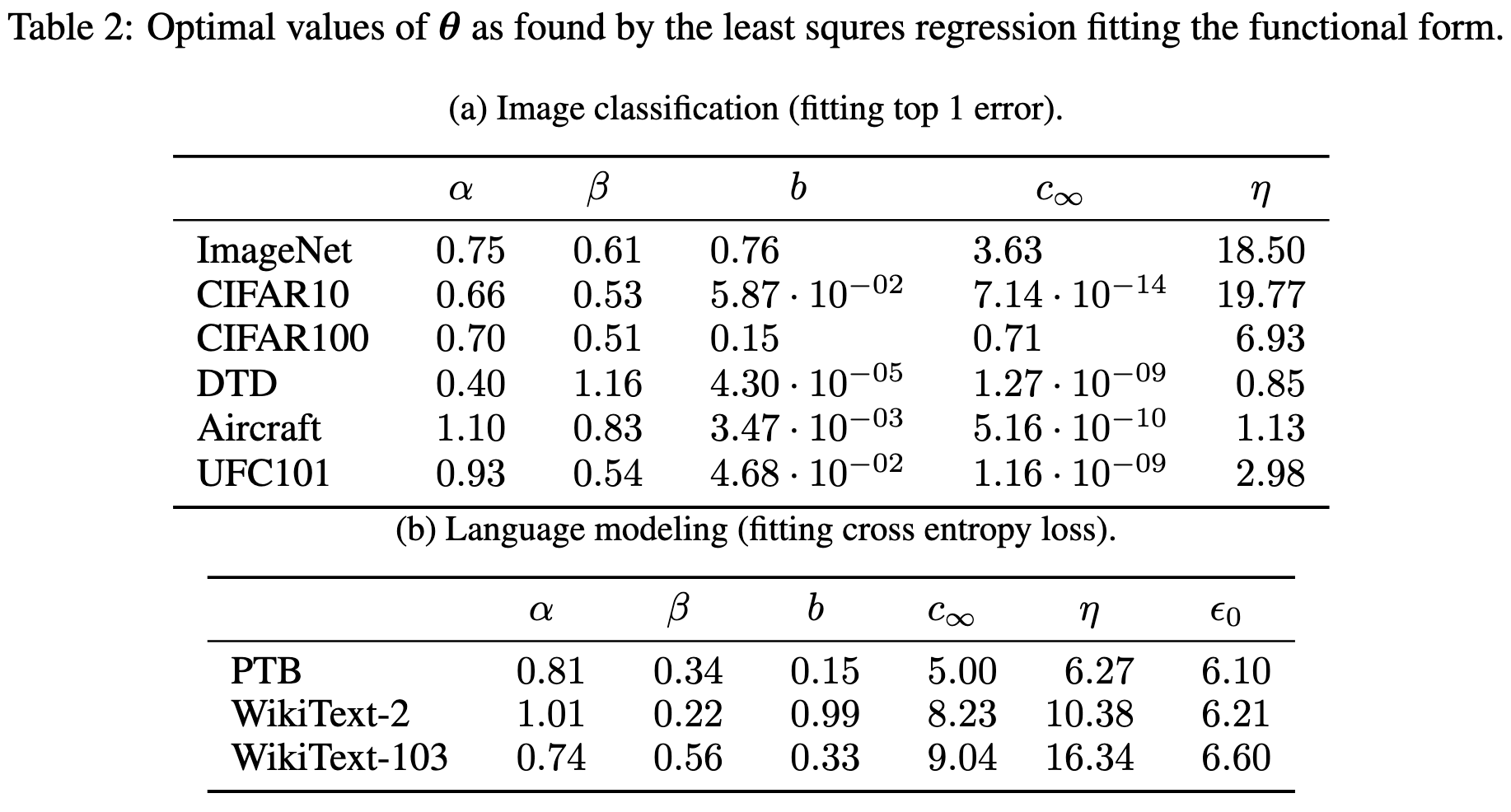
These power laws account for almost all of the variance across different configurations,

and even work when extrapolating to much larger models / longer training.
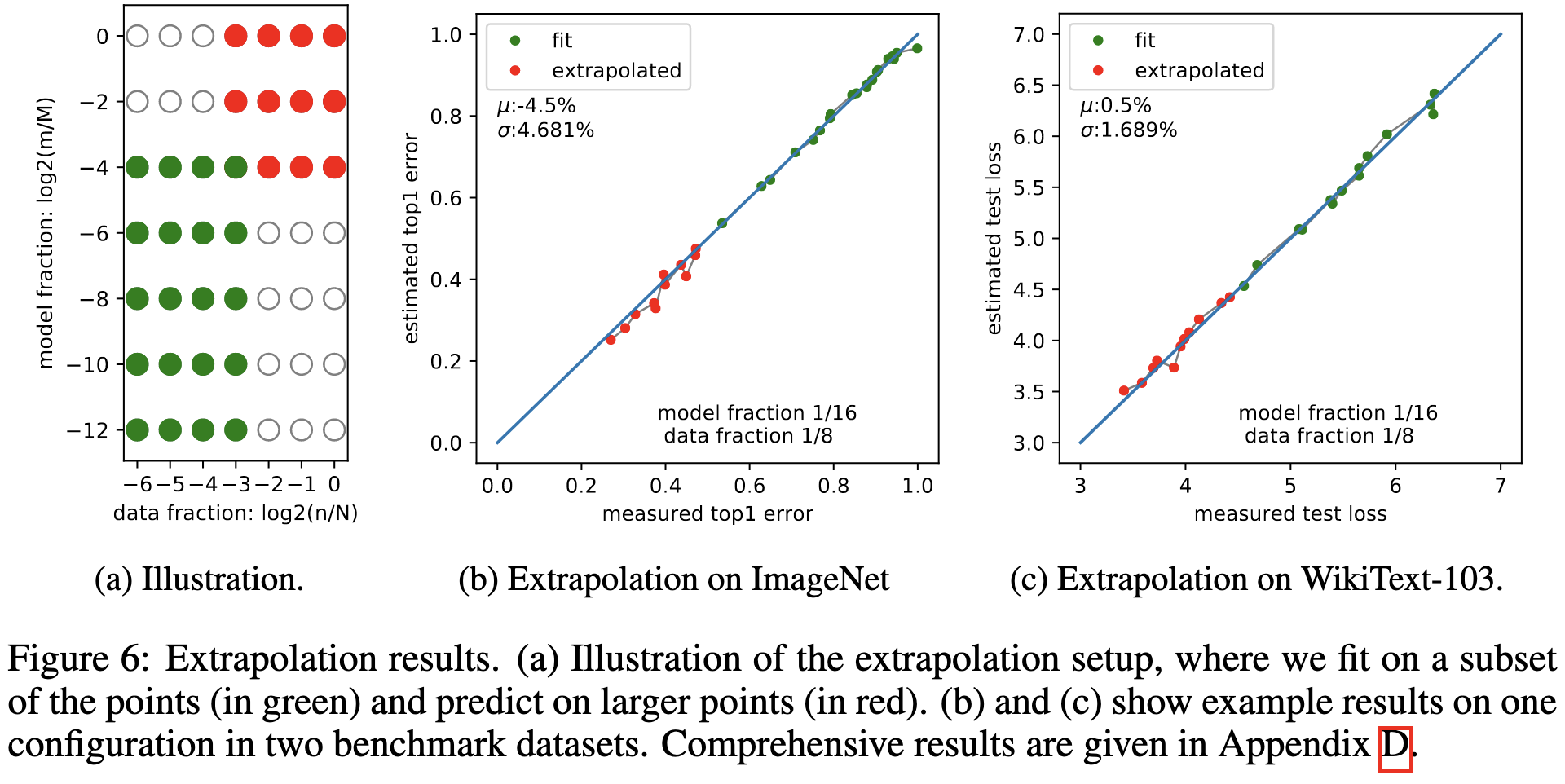
Unlike other papers, they also note that this power law relationship doesn’t work in the limit of no parameters or no data. They propose a simple extension to smoothly transition from chance-level accuracy to the power laws, although they only choose this exact functional form for “convenience.”

Great to go back and look at early work in this space (they also have a great related work section). I’ve been thinking about scaling a lot and it’s cool to see consistent findings across papers.