


2023-1-29 arXiv roundup: Diffusion, Watermarking, and societal implications

This newsletter made possible by MosaicML.
Training Stable Diffusion from Scratch Costs <$160k
We showed you could train your own Stable Diffusion model for way less than the ~$600k Stability AI originally reported. The full training code is open source.
Unlike our 7x faster ResNet result, this is almost entirely a product of system-level optimizations, not training recipe improvements. These optimizations include use of our high-performance Streaming Datasets, good datacenter design + cluster management in our cloud, and all the best practices baked into Composer.
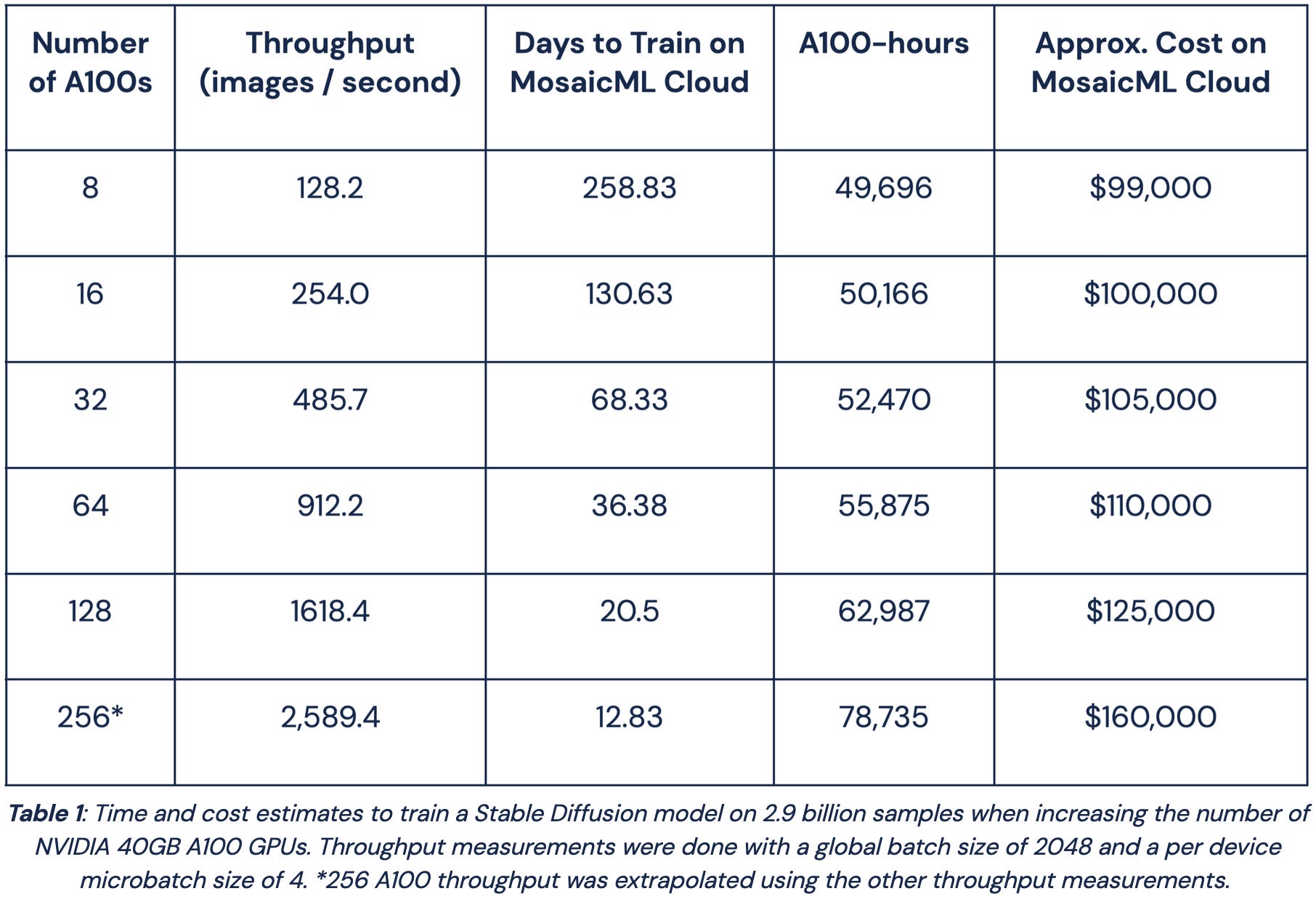
One of my favorite parts of this is that it isn’t a research prototype—it’s a quote. As in, for $160k, we’ll actually train this model for you (which you might want if you have domain-relevant data, copyright concerns, etc).
I’ve spent years being really frustrated with the incentives in the research world, and it’s great to be at a place where we have to put our money where our mouth is.
Membership Inference of Diffusion Models
Can you tell whether a diffusion model was trained on a given image?
Yes, if the model wasn’t trained on too much data.
In more detail, they find that looking at the loss or likelihood associated with an image is a good predictor of whether the model trained on it. Now this does break down if you add enough diffusion-style noise to the image (moving to the right in the below plots); but luckily you can just…not do that.
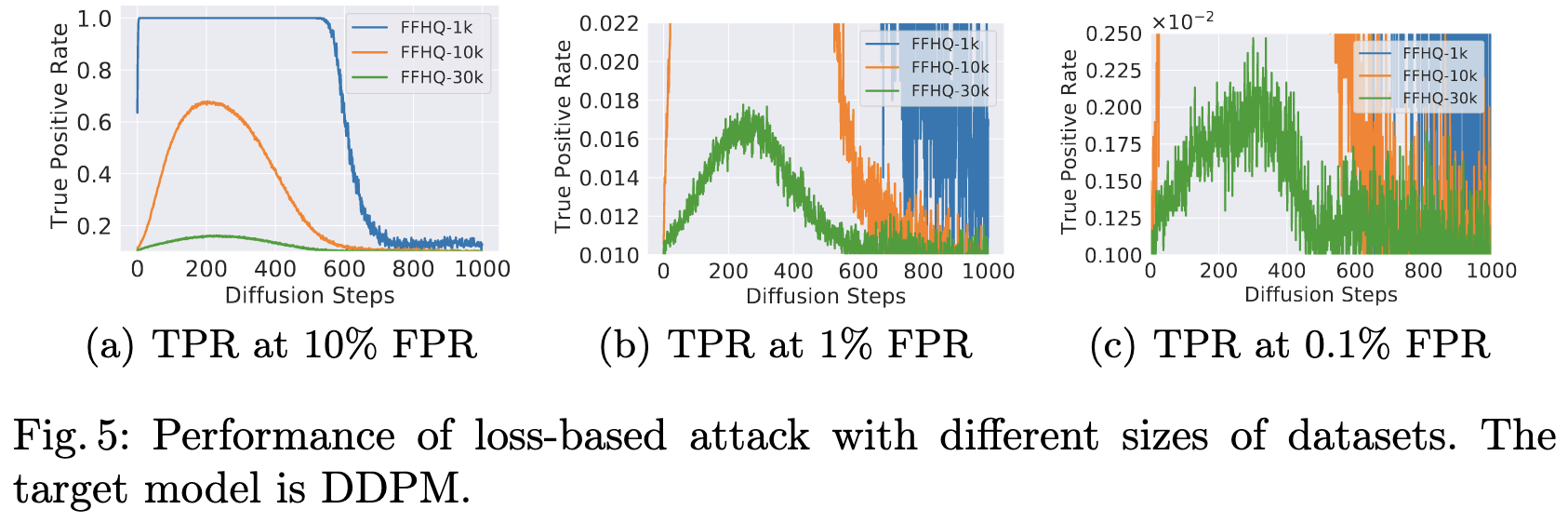
What sticks out to me is how low the lowest curve is in the leftmost subplot. With just 30k images in the training set, you only get like 10% true positives at a 10% false positive rate. Since most real-world diffusion models are trained on way more data than that, this suggests that it’s rarely possible to be sure a given image was part of the training set in practice.
Of course, the failure of one membership inference algorithm doesn’t prove that membership inference is impossible—for that, we need tools like differential privacy.
But even without mathematical proof, empirical findings that diffusion models don’t leak much info about their training sets could have economic and policy implications. E.g., if you can’t tell whether the model even saw each image, can you still call it “a collage tool, only capable of producing images that are remixed and reassembled”?
Also, legal rulings might not matter if people know they can train on whatever they want and no one will be able to prove it…
A Watermark for Large Language Models
Can you modify how language models write text such that it’s possible to tell whether a human or a model wrote it?
Yes, and they have a clever algorithm for doing so.
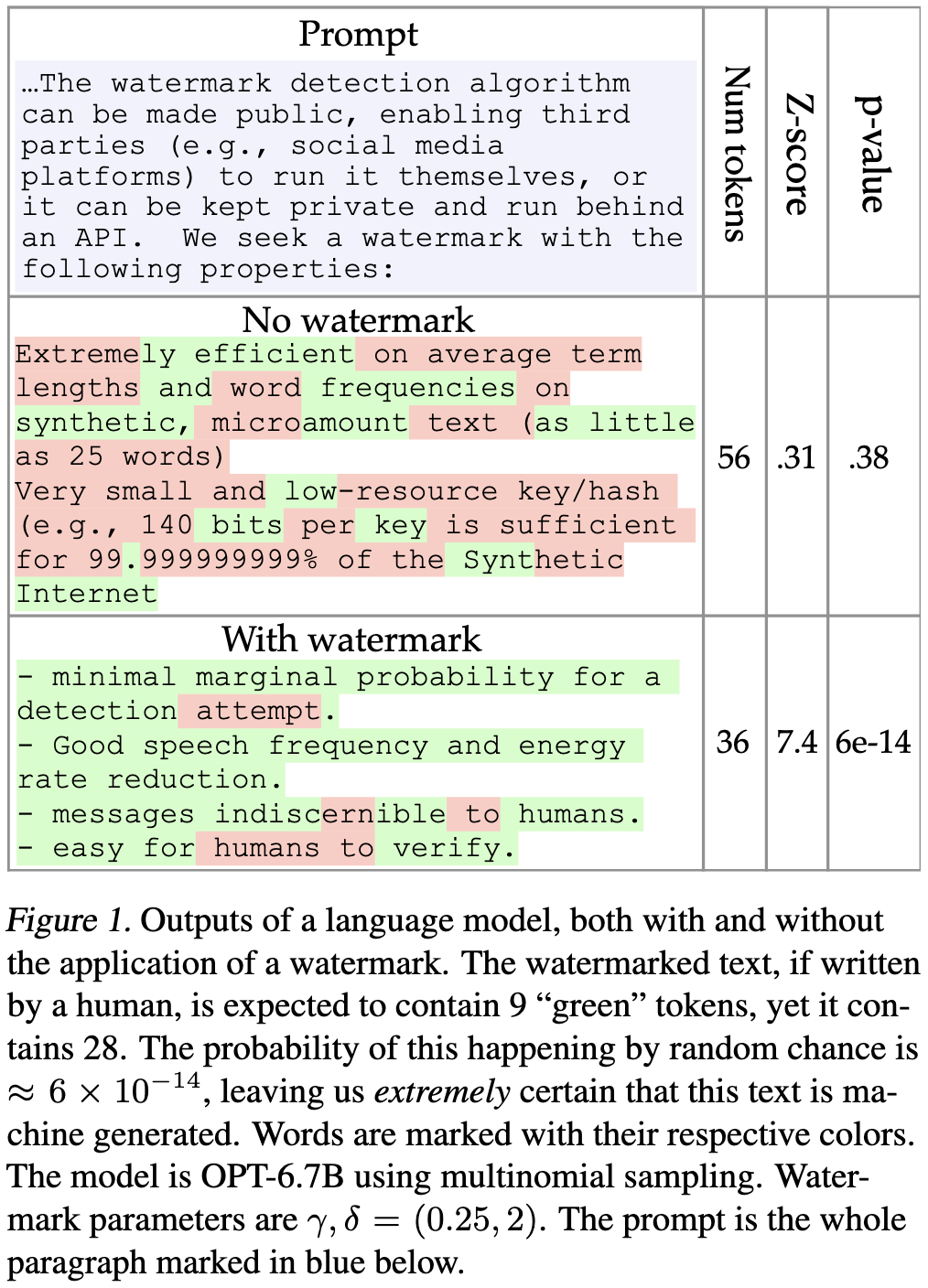
The idea is that you split all the possible tokens into a whitelist and a blacklist. The model is only allowed to output tokens from the whitelist. This makes it so that the resulting text contains many more tokens from the whitelist and many fewer from the blacklist than would happen by chance.

Of course, doing this naively can cause a few problems. For one, couldn’t someone notice that a document never contains certain words? Or figure out that other words are part of the whitelist and get your text flagged as AI-generated?
To avoid both of these problems, we can generate a new whitelist and blacklist [pseudo-]randomly before every token. This makes all tokens equally likely to be part of each list over the course of a whole document.
A subtler challenge is dealing with the case where there are only a few sensible options for the next token, but they’re all on the blacklist. E.g., “President Barack Ob” kind of needs to be continued with “ama”.
The solution to this is to switch from hard blacklists and whitelists to a soft biasing of the output distributions. Concretely, tokens in the whitelist get a bonus to their logits in the softmax used to compute token probabilities. This doesn’t change the output when a certain token should clearly come next, but does it change it when there are many possible continuations. As an example of the latter, consider how many ways you could complete “The dog was”.

Another problem is that an attacker might be able to remove the watermark by, e.g., swapping out whitelisted words for blacklisted ones. This could be easy since, given the random seed, they can compute the whitelists and blacklists.
To prevent this, you can keep the initial seed a secret and use a cryptographic hash function / block cipher to compute the whitelist and blacklist at each position. The significance of the cryptographic algorithm is that you can’t reverse-engineer the random seed, like you can with the Mersenne Twister and other non-cryptographic RNGs.

How well does the proposed method let you detect model-generated text in practice?
Give a long enough passage and no attempts to subvert it, it works extremely well.
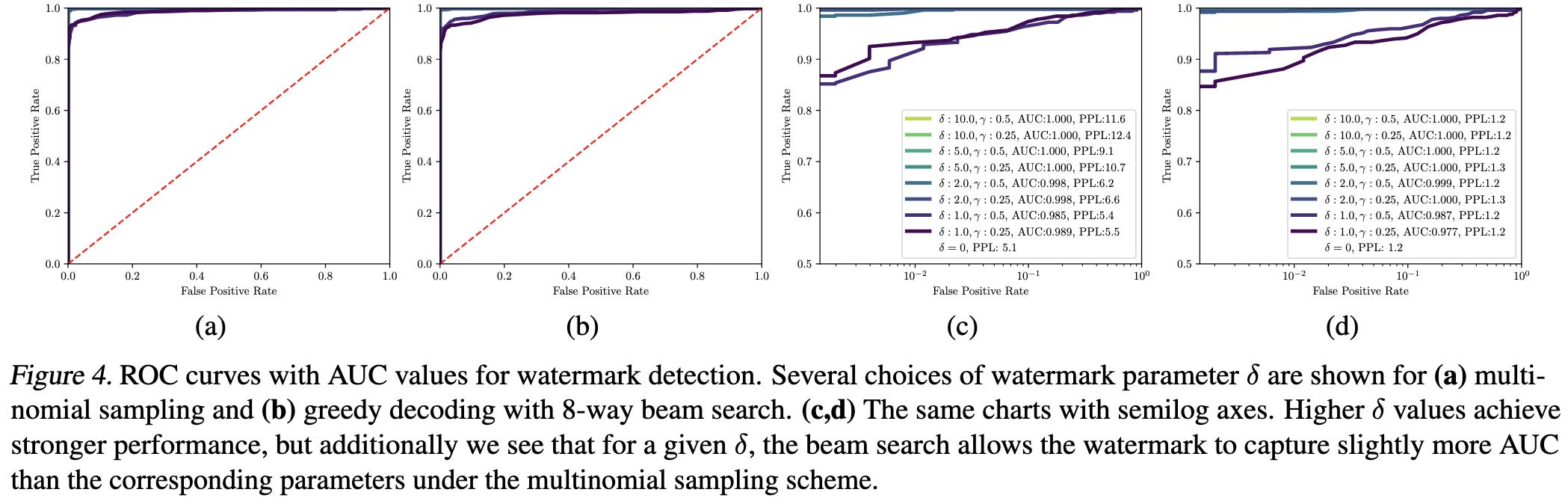
If you want it to work on short passages, you can crank up the bias towards the whitelist in exchange for worse perplexity.
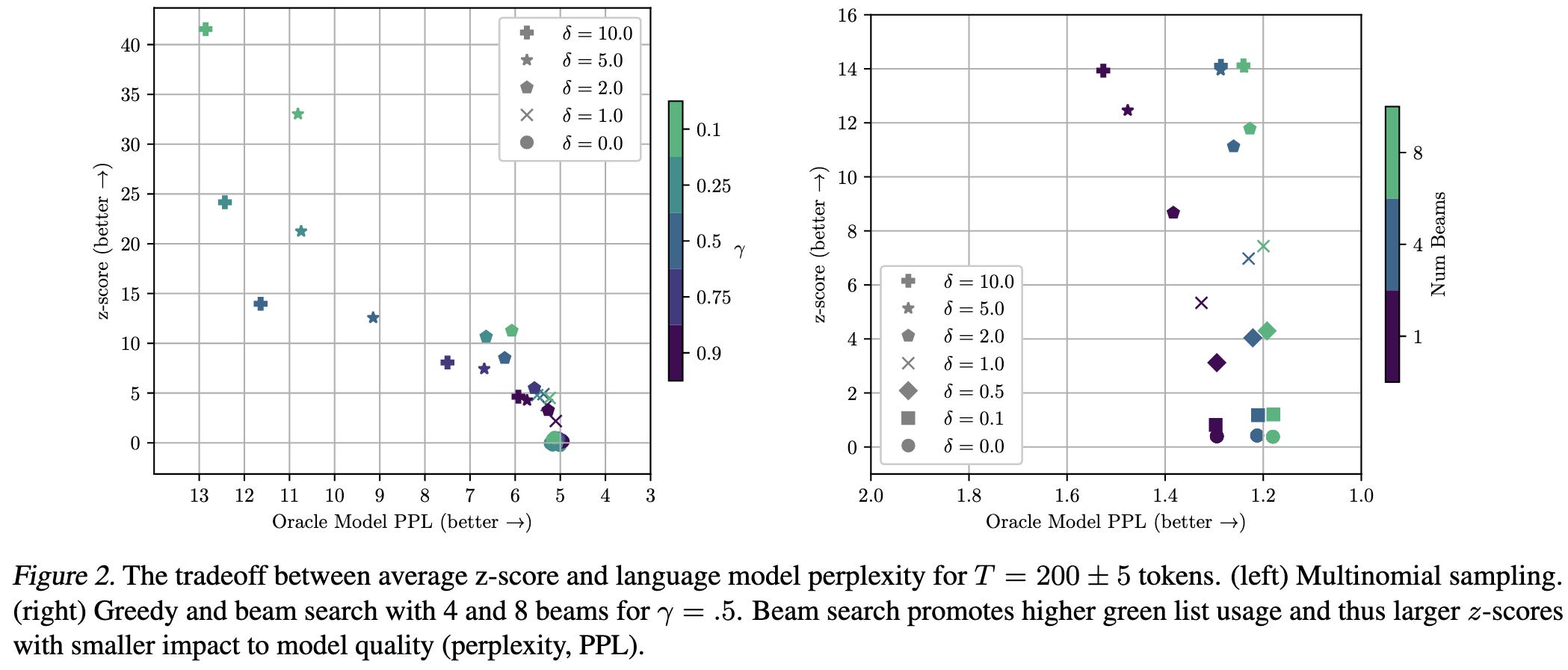
What happens when you try to fool their method through various means?
It depends on the attack. The first attack they consider is using a prompt that alters the text in a systematic way you can easily undo. E.g., telling the model to insert extraneous characters or swap certain letters. This gives you useful text after simple post-processing, but causes the watermark checking to use different whitelists and blacklists than the model generating the text did. This will make the watermark check see no correlation between the text and its whitelists.

Another attack is using a different model, like T5, to replace spans of the generated text after the fact. This can make watermarking much less effective, but it also tends to degrade the text. Plus, it makes the attacker pay the extra inference cost of running another model.
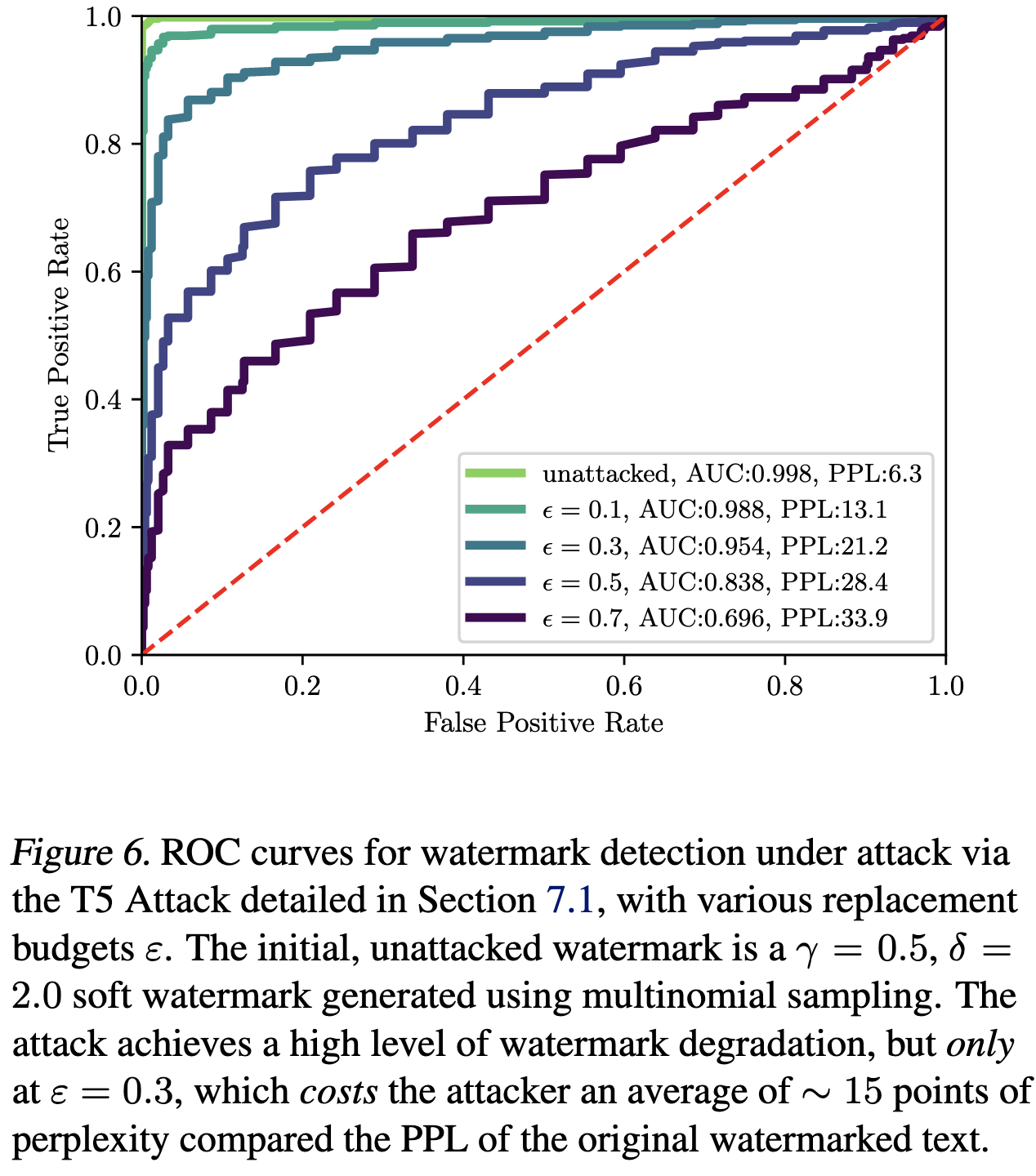
I thought this was a really clever paper, plus a fun excuse to put on your crypto1 hat. It's not clear yet how well watermarking techniques will work in production, but there a bunch of interesting business/societal possibilities here:
If watermarking works super well, companies like OpenAI may have a compounding structural advantage as more and more AI-generated text shows up on the internet. This is for two reasons:
While no one else can tell the difference between human and AI content, they’ll easily be able to filter for the former. Assuming human text is better training data, this would give them an advantage in training models, which could let them generate an even higher fraction of the world’s text, and so on.
They can expand into the new product category of AI-generated text detection. E.g., if I’m a social media site, I might pay for the privilege of detecting spam accounts.
We could see even more centralization of messaging. E.g., what if spam email gets 10x more sophisticated and letting OpenAI read your emails is the only way to filter it well?
If watermarking gets good enough that bypassing it is expensive, we’ll see much less AI-generated spam than we would otherwise.
Watermarking incentives owning your own text model if you don’t want other people to know whether your text was generated by an AI (e.g., if you’re a reputable news site—or a spam operation).
If watermarking works so well that even motivated students can’t bypass it, we might still be able to have students write essays at home. I’d be really surprised2 if this happened though.
What are the Machine Learning best practices reported by practitioners on Stack Exchange?
Just a bunch of tactical nuggets. Nothing super surprising, but good to see lists of practices you might not think of.

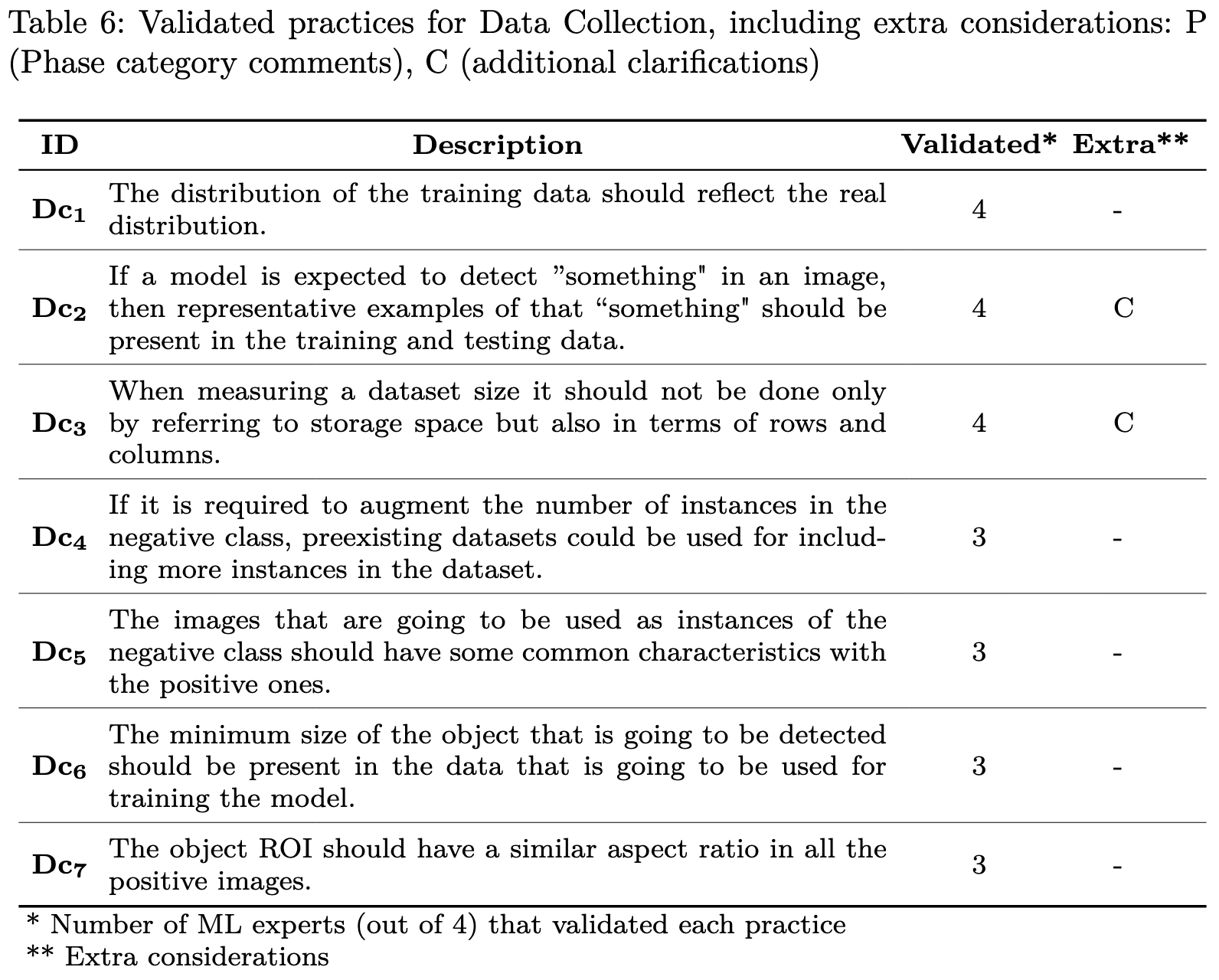
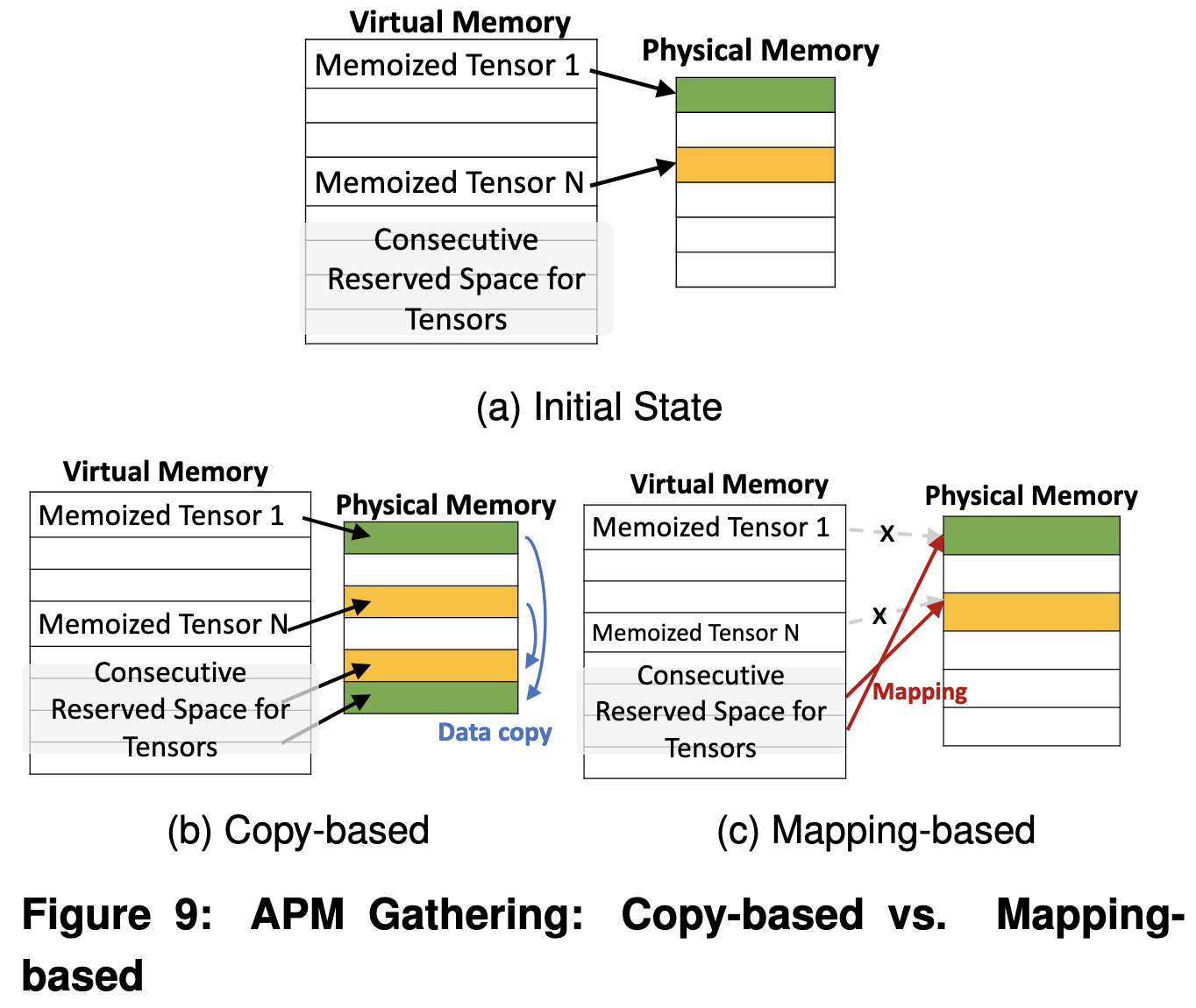
MEMO : Accelerating Transformers with Memoization on Big Memory Systems
They store hundreds of gigabytes worth of previous attention matrices and do nearest-neighbor lookups instead of computing the attention matrices for a given sequence.
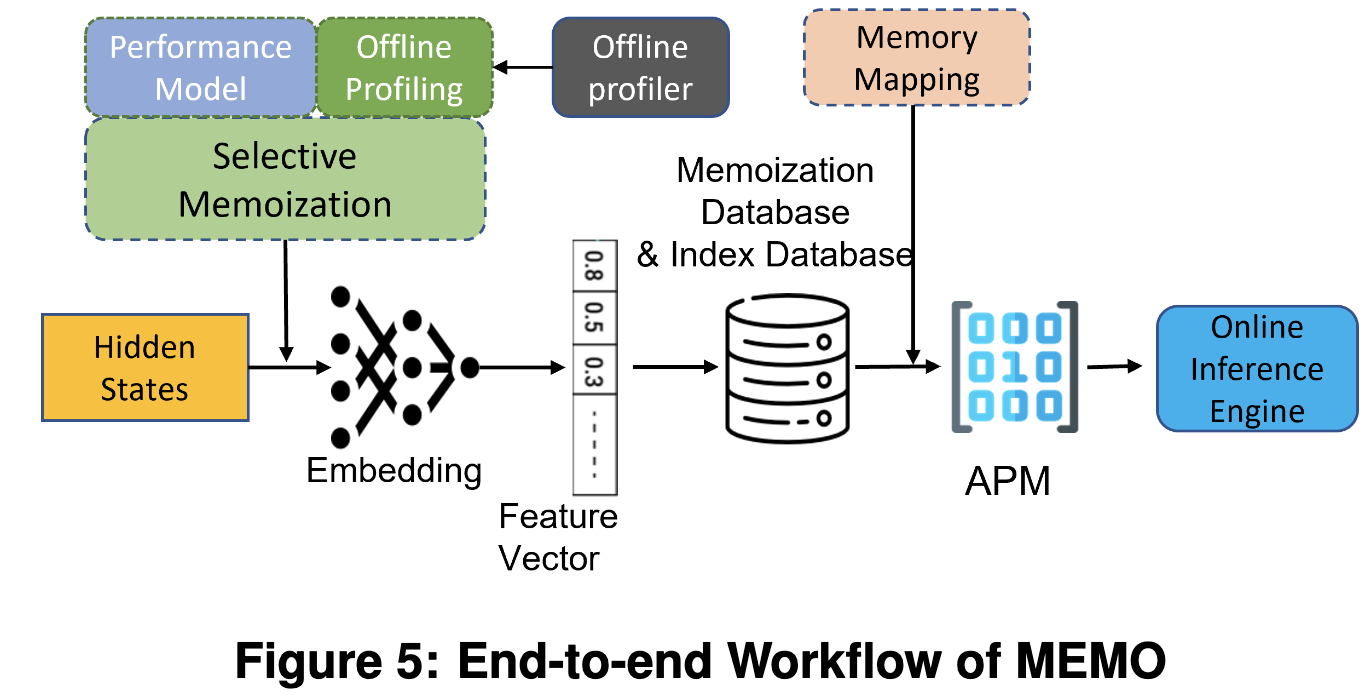
They do a bunch of systems work to avoid copies and make the system fast for their target use case of CPU inference.
It doesn’t seem like they’re getting a great speed vs quality tradeoff, but…
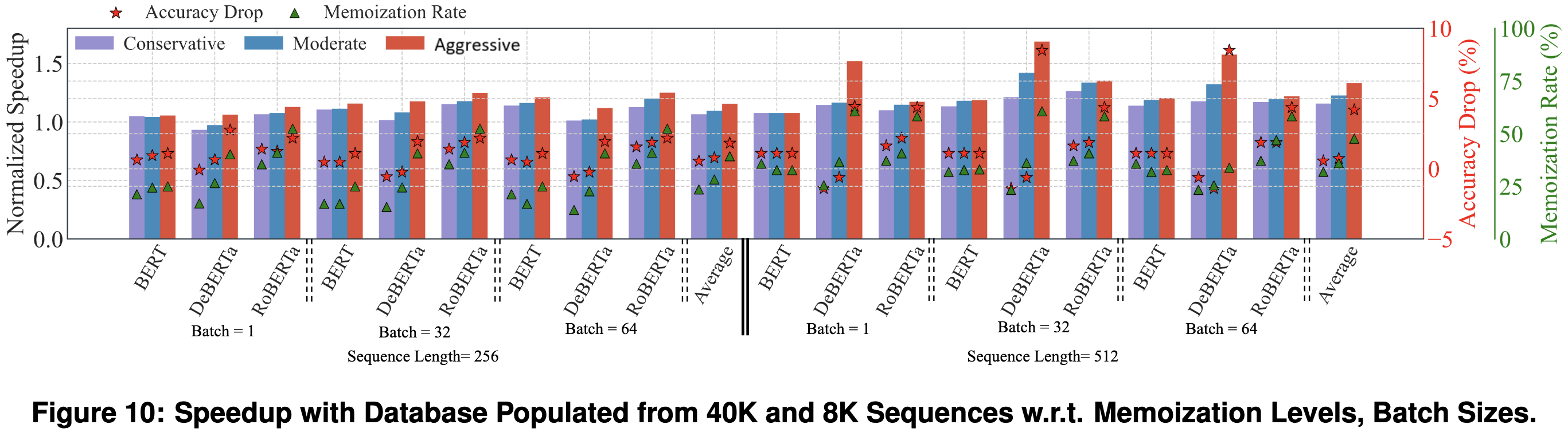
…I still kind of like this because it’s a paper where the main idea has never even occurred to me. There’s previous work on freezing prefixes of the network and caching those activations, but I’ve never seen someone be bold enough to say, “screw it, we’re just gonna replace this whole block of computation with a nearest-neighbor lookup and it’ll be fine.”
Of course, replacing individual ops with lookups works super well for approximate matrix products and similarity search. But doing it for this big a block of computation is ambitious and interesting.
It might not be ready for production yet, but a scalable way to turn more CPU RAM into more speed and accuracy would be a big deal for how we design ML systems.
Neural Architecture Search: Insights from 1000 Papers
A big survey paper of the many NAS methods from the past few years.
They do a good job of organizing the various approaches,
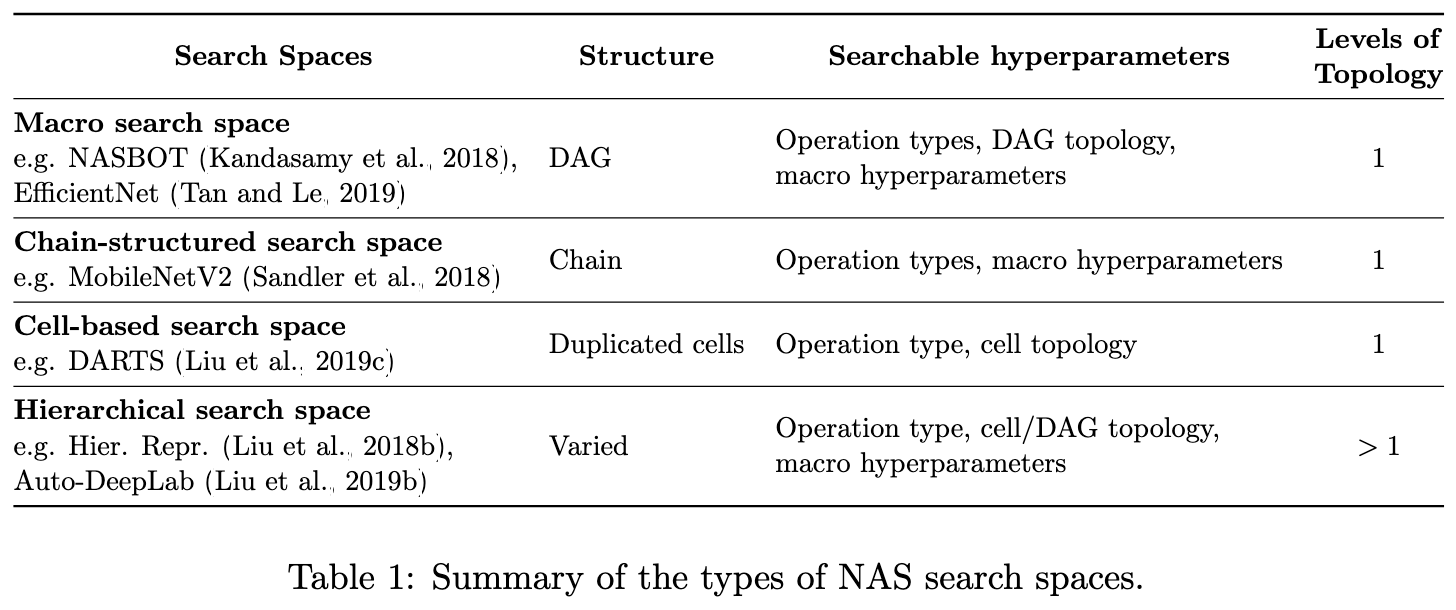
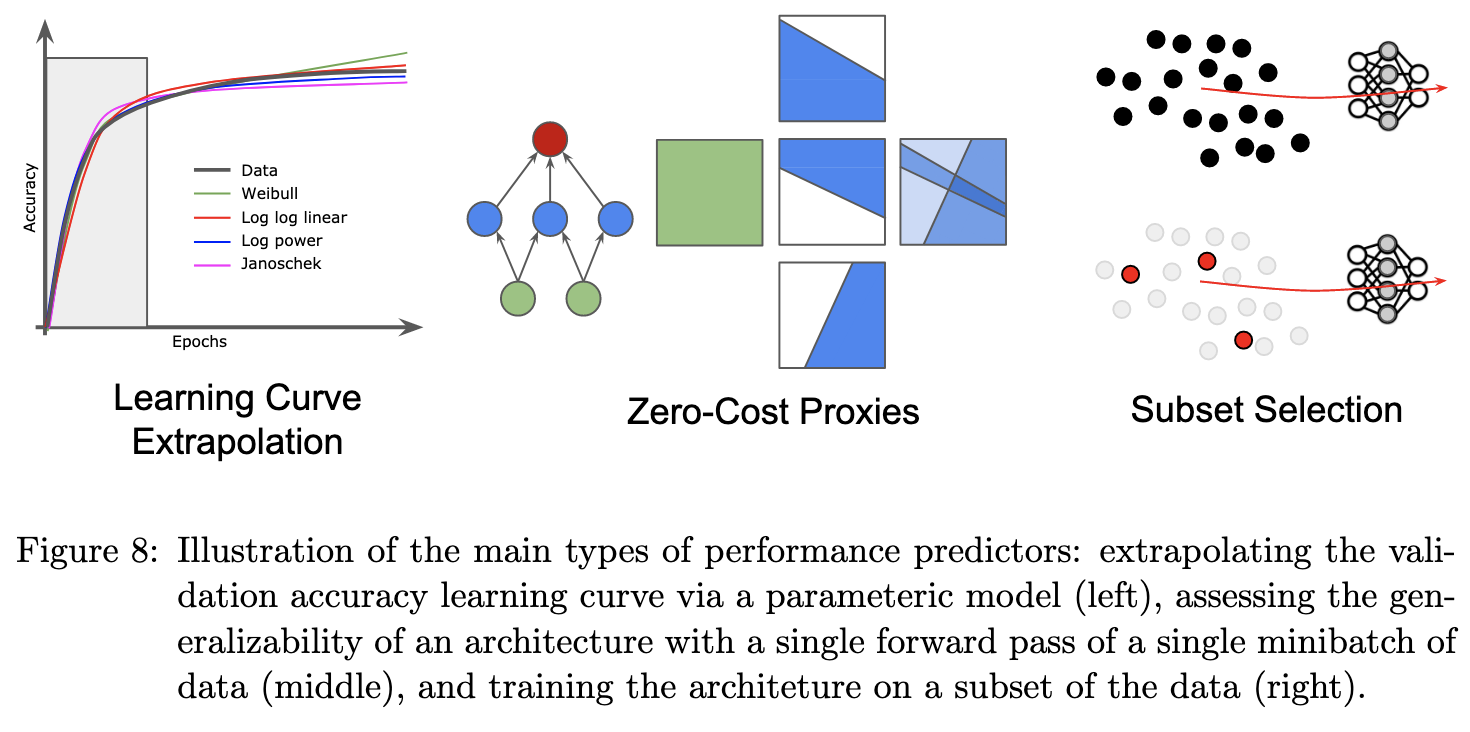
and illustrating different techniques.
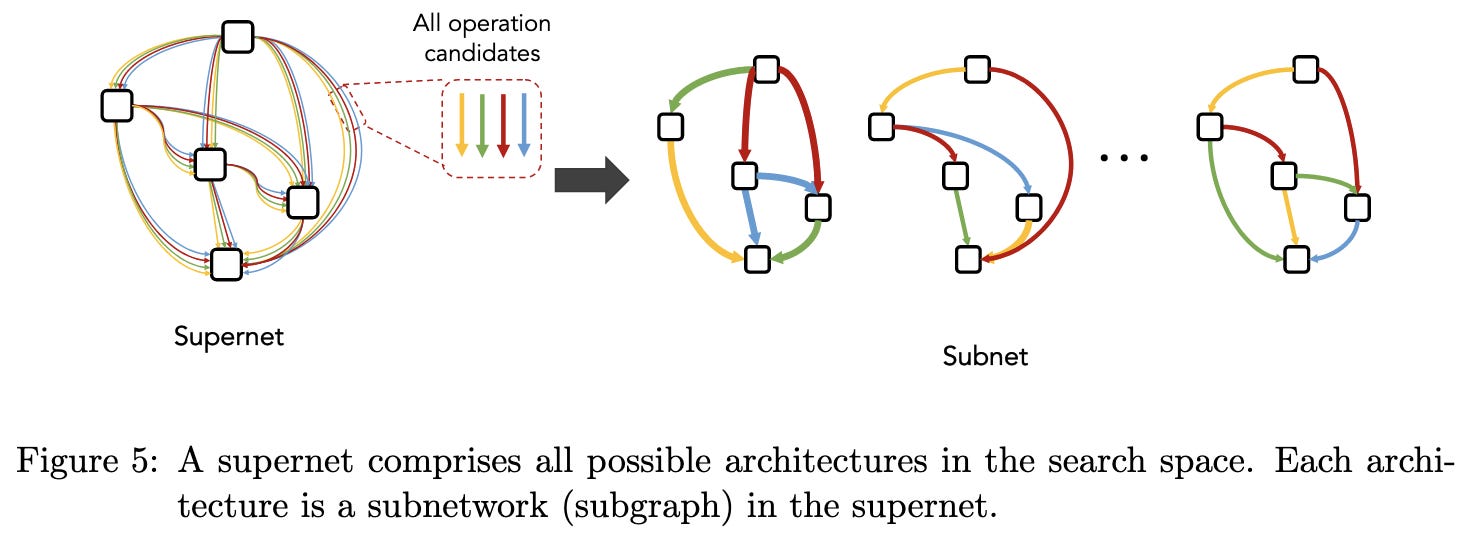

Definitely worth a look if you’re interested in neural architecture search.
On the Mathematics of Diffusion Models
Diffusion models explained in five pages of math. They frame them in terms of both variational autoencoders and the Fokker-Planck equation.
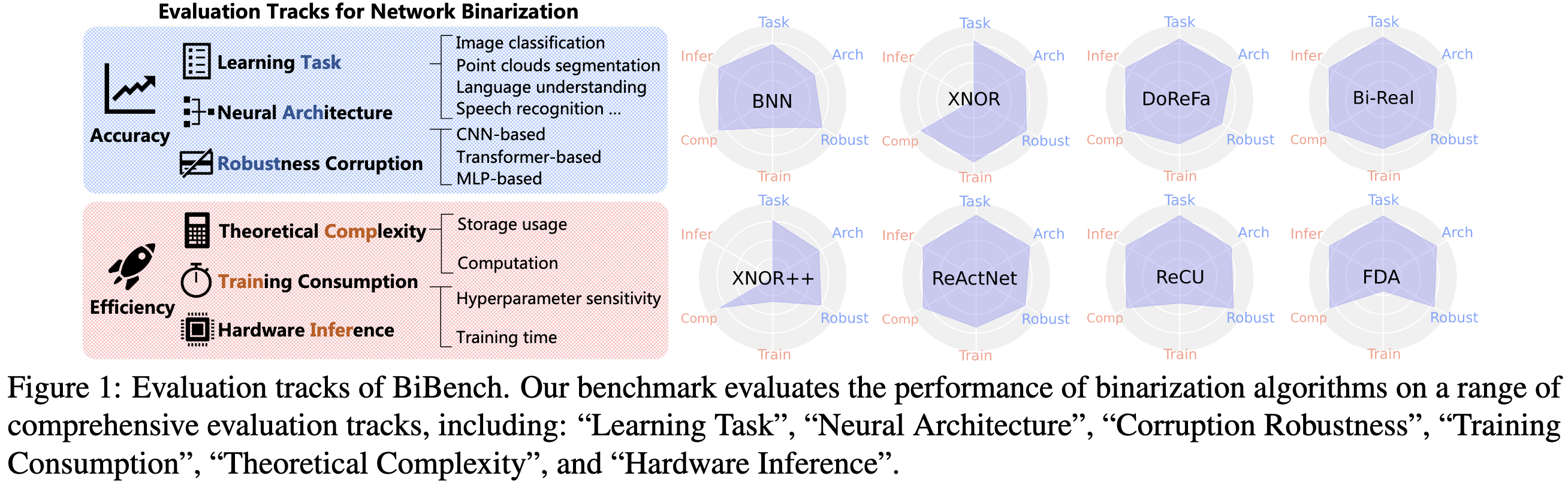
BiBench: Benchmarking and Analyzing Network Binarization
They introduce a benchmark for network binarization techniques and show results using some representative methods from the literature. As you might expect, no single method is the best at everything.
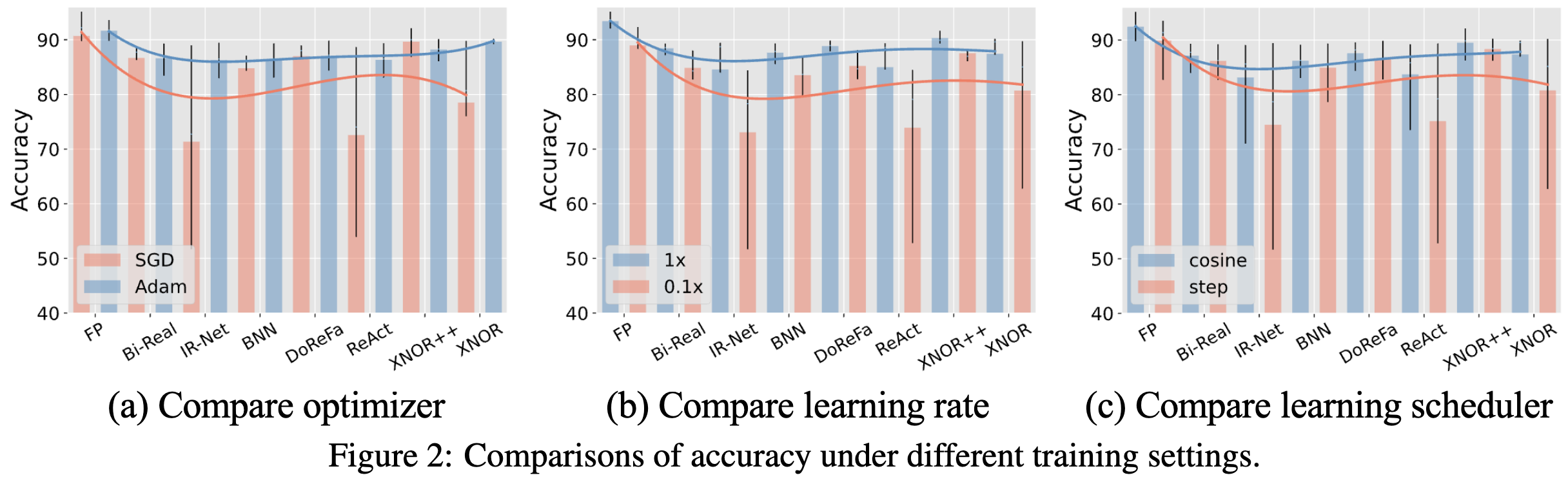
They also find that different methods have different sensitivities to hyperparameters, as measured on CIFAR-10. Having channel-wise scale factors and some sort of continuous approximation (to not screw up the gradients too badly) seems to be helpful on this front.
One interesting finding is that binarization offers more speedup on hardware with less compute. I’m not totally clear on why this is; I guess even hardware with terrible multiplication throughput tends to still have decent xnor + popcount throughput?
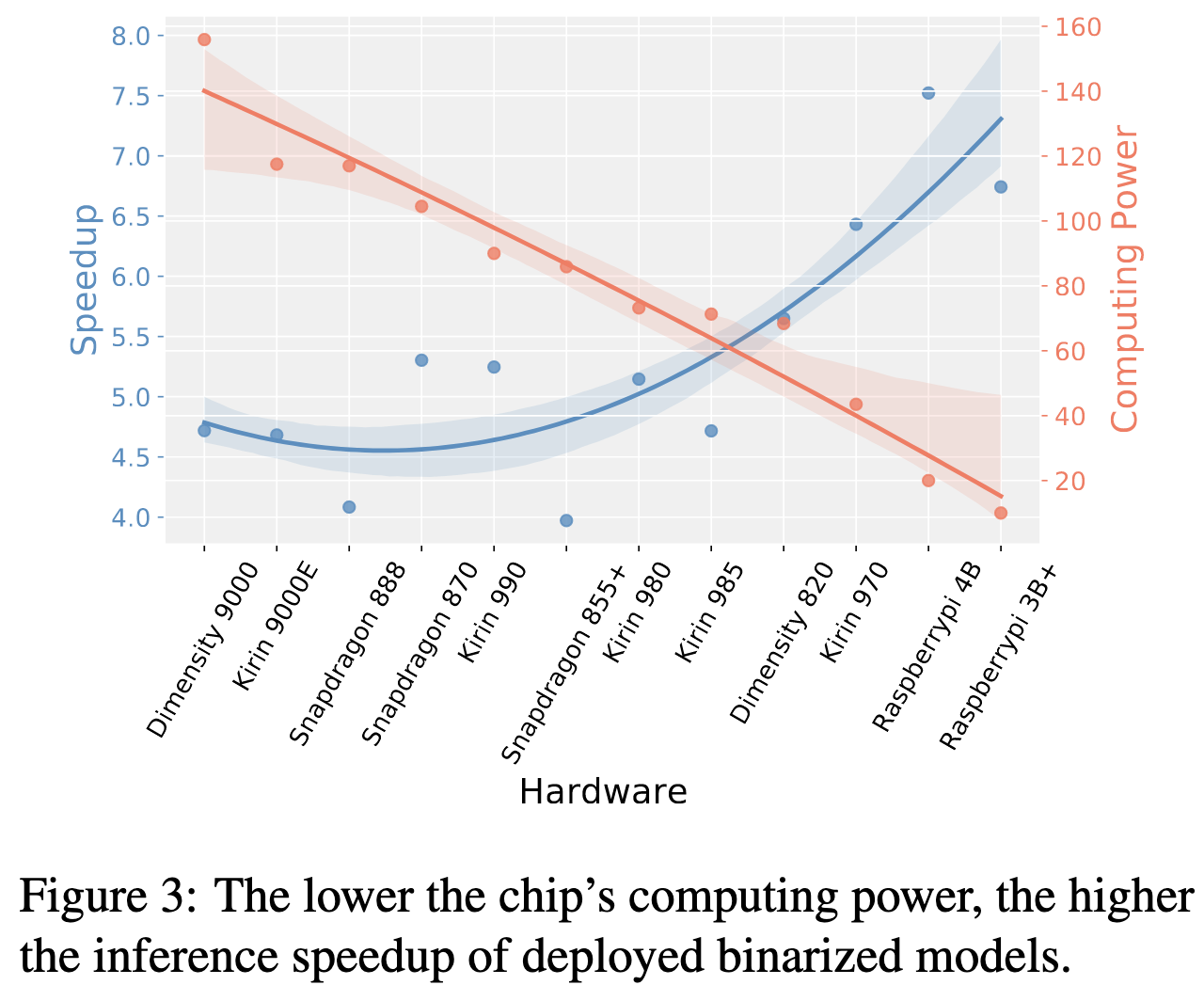
Overall, this seems like a great contribution. The literature is always desperate for apples-to-apples comparisons, and it seems like they did a ton of work making it easy to evaluate methods across different datasets, architectures, inference libraries, and hardware.
One of the best shibboleths in computer science is whether you use “crypto” as the abbreviation for “cryptography” or “cryptocurrency.”
And disappointed, to be honest.