
2023-10-16 arXiv roundup: Cornucopia of easy (claimed) wins for LLMs

Also, I was on the AI Stories podcast! In case anyone assumed I was incredibly handsome, this is the perfect chance to disillusion yourself.
This was a lot of fun and I’m definitely down to do more podcasts.
Side note: I’m super paranoid about exaggerating my similarity search contributions in this conversation, so see this footnote if you care.1
xVal: A Continuous Number Encoding for Large Language Models
They encode numbers as a single token, but with the embedding magnitude scaled by the number’s magnitude. At the decoder, they read the embedding scale whenever the token is predicted to be a number.

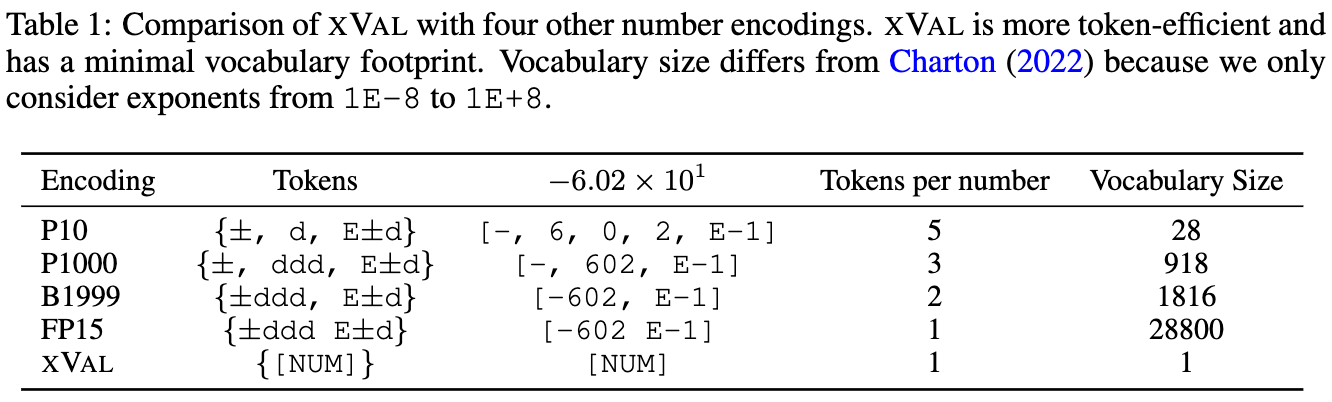
This approach often works better than alternatives for various regression tasks, despite adding fewer parameters to the embedding tables.



They also have a good discussion of limitations. You shouldn’t use this encoding when you need a huge dynamic range, or when you need many digits of precision. Although appropriate pre- and post-processing of numbers could help mitigate these limitations.
Maybe this is how we should all be handling numbers in LLMs?
Sparse Backpropagation for MoE Training
They did math to come up with better MoE routing, where “better” means higher accuracy in fewer training steps.

The math/notation is pretty dense and their Github repo is private, so here’s what I think is happening; apologies if I mess it up.
First, you can think of the MoE layer as “sampling” a subset of the experts. The sampling might happen to be a (noisy) top-k in practice, but it’s still sampling. So we want to minimize the expected loss over this sampling distribution.

Applying the product rule to the rightmost expression, we see that the gradient of the loss can be written as two summations. You can think of the first summation as requiring us to differentiate with respect to the sampling probabilities, and the second as differentiating with respect to the routing weights conditioned on the sampling distribution.

They observe that computing the second summation with backprop works great, but backproping through a sampling step is sketchy. So what most MoE models currently do is just ignore the first (sampling) term of the true gradient.
Before getting to their solution, let’s think about what we’d like to do. What we’d like to know are the outputs of all the experts, and therefore how the expected MoE layer output changes as we increase the probability of sampling a given expert.

But computing the average output under the current distribution requires us to route every token through every expert, which kinda defeats the point of sparse MoE. So instead of using the true average output as the baseline, we could instead just use all zeros as our baseline. With a lot of experts and no nonlinearity at the end to add bias, this is a sane approximation of the true average anyway.

This lets us approximate the gradient using only the experts we actually select in our top k, instead of all of them. But it still requires us to run an all-zeros activation tensor through the rest of our network. And ain’t nobody got time for that. So we’re going to introduce a first-order approximation to this difference: we’ll compute the slope (gradient wrt the actual expert output, provided by backprop) and scale it by the distance (expert output minus zero = expert output).

You can do a little bit better by computing the gradient halfway between the expert output and zero, instead of all the way at the expert output. In practice, they just halve the expert output in forward and double the gradient in backward.

This halving introduces a train vs test discrepancy though, so they only use the midpoint method…during training, maybe? They might be varying whether they sample from the softmax distribution or use hard top-k during training.

They also mask out all but the top-k entries before computing the softmax and add a trainable, token-independent scale factor for each expert.

This masking is apparently really important. So are the learnable scales and only sometimes using the midpoint version, although those ablations are shown in the figure at the top.

In terms of wall time, their method adds no measurable overhead, which is awesome.

This might be an immediate and large win for anyone training MoE models.
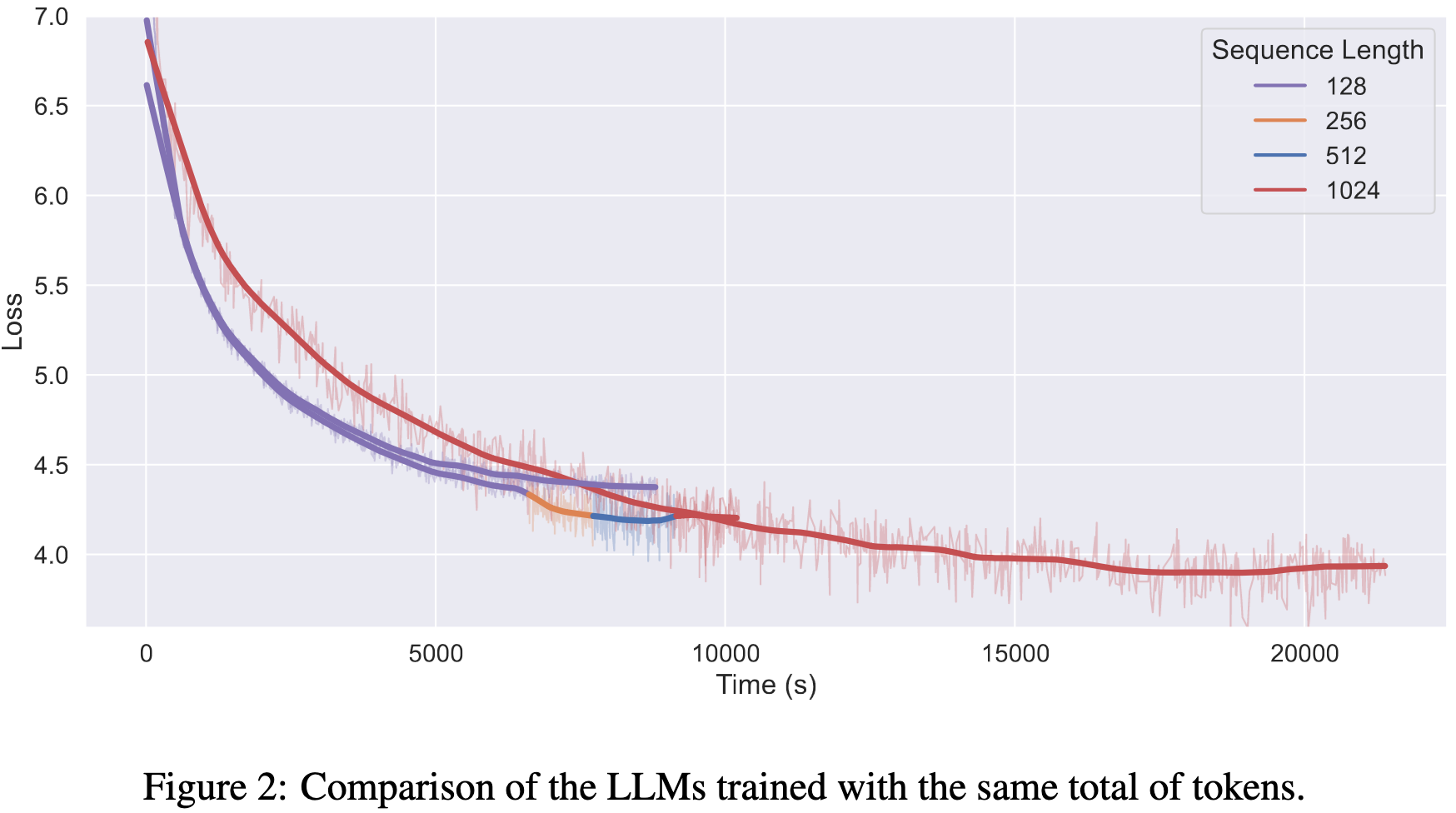
GrowLength: Accelerating LLMs Pretraining by Progressively Growing Training Length
Progressive resizing helped us set the ResNet-50 time-to-accuracy record, and it turns out it works for LLMs too. At least for sub-billion parameter models.
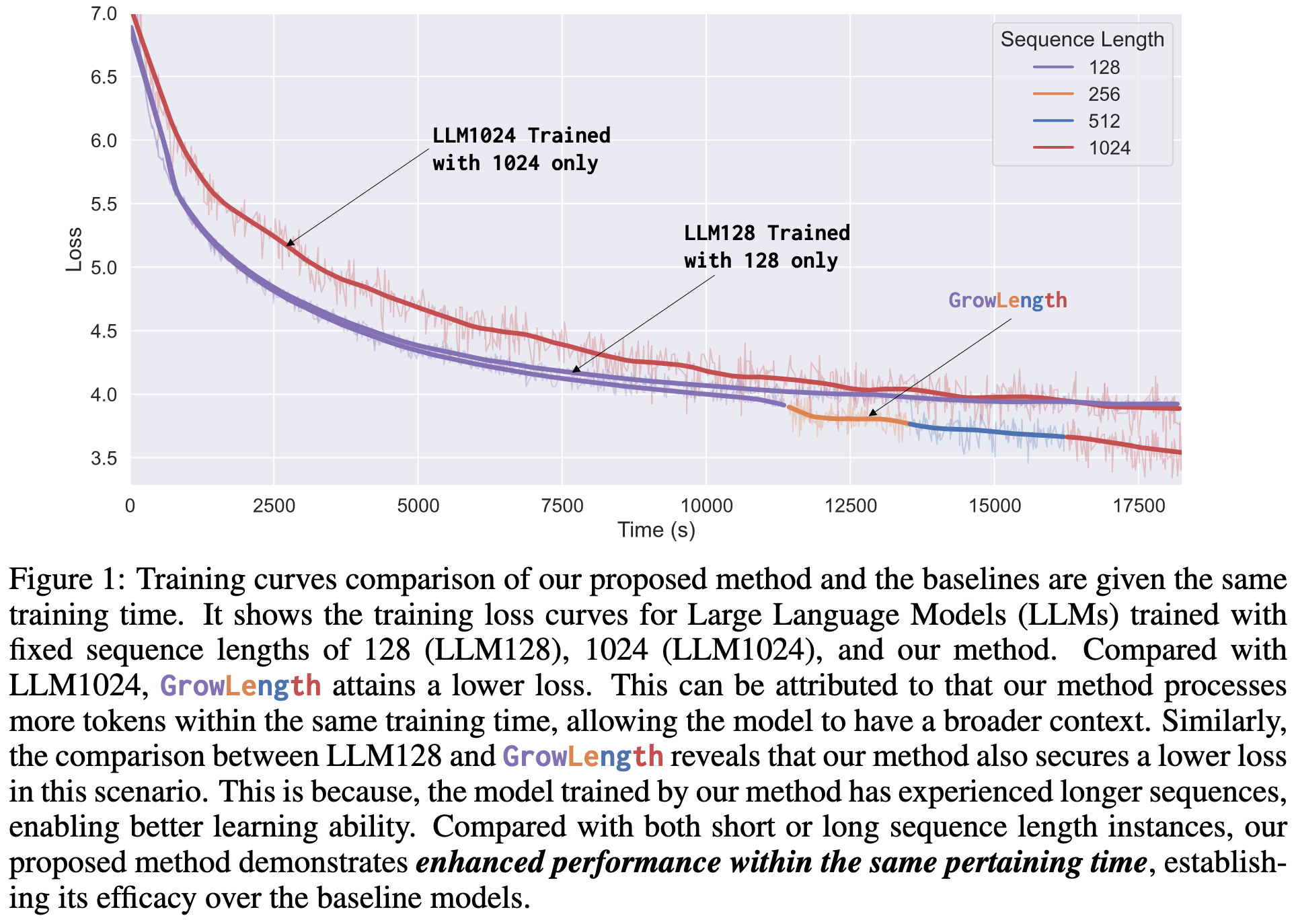

It’s not as good as training at the full sequence length for a given token budget—but it is better for a fixed time budget, presumably because their workload is spending a lot of time in the attention ops.
Training and inference of large language models using 8-bit floating point
They show that simple scaling of the linear layers lets you convert them to fp8 with ~0 loss of model quality. The scaling is just coming up with a tensor-wide scale factor, and they explore both scaling adaptively for each tensor and via one overall exponent bias.


Apparently you can use the same exponent bias across all the weights and activations and preserve 99.5% of the accuracy across a pretty wide range of exponent values. The exact range varies by task, but just setting it to zero worked in every case; this held for both finetuning and inference.

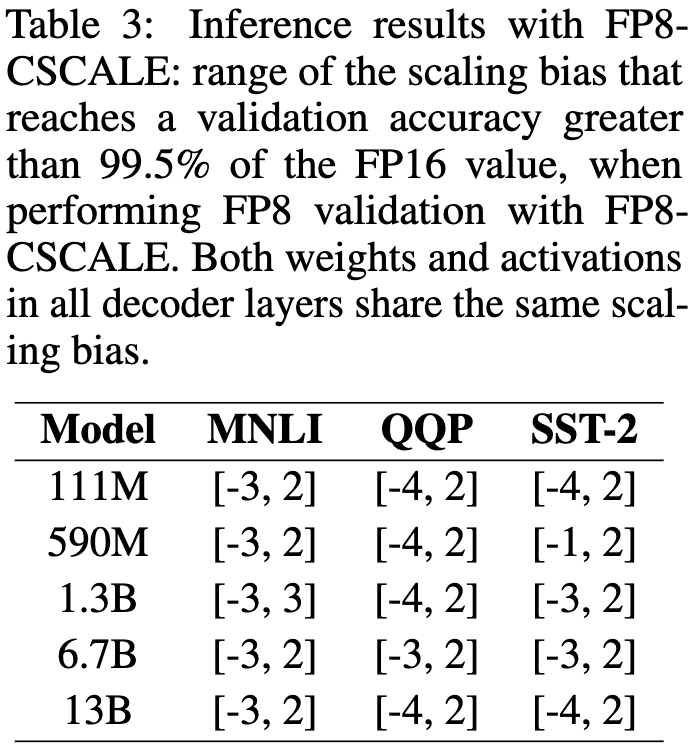
Graphcore’s been crushing it with fp8 work lately. Also, they actually trained these models on their hardware, which is impressive.
Soft Convex Quantization: Revisiting Vector Quantization with Convex Optimization
They do better vector quantization in a VQ autoencoder. In the forward pass, they try to get better (soft) centroid assignments by solving a convex optimization problem that treats the centroids as fixed. In the backward pass, they use the implicit function theorem + the fact that the solver converged to get gradients wrt the centroids.

This seems to work better than simpler vector quantization for a few image tasks.


Pretty cool application of implicit layers. Also might help us improve vector quantization as a model compression technique in general.
A Long Way to Go: Investigating Length Correlations in RLHF
Turns out RLHF is largely just telling models to produce longer outputs.



You can even get a lot of the RLHF benefits by just plain rewarding length.

LightSeq: Sequence Level Parallelism for Distributed Training of Long Context Transformers
First, they observe that standard gradient checkpointing plays poorly with Flash Attention. The problem is that Flash Attention throws away its intermediate outputs even if you’re already in the middle of rematerializing the attention block (when you’d rather keep the intermediate outputs to save compute).
“flash attention will not materialize the intermediate values during the forward, and will recompute it during the backward, regardless of the re-computation strategy in the outer system level.”
To mitigate this, they checkpoint the Flash Attention outputs. This means they don’t have to run another forward through Flash Attention, and therefore only end up rematerializing its intermediate outputs once.

This can improve training speed significantly at long sequence lengths.

Second, they propose to use sequence parallelism for everything. This is nice in that it lets you do everything but the attention locally, and do tensor-parallel attention with more devices than attention heads. But it requires some complex compute + communication scheduling logic within the attention computation.


Their changes let them support much longer sequence lengths on a given GPU than Megatron,

and train faster in many cases.
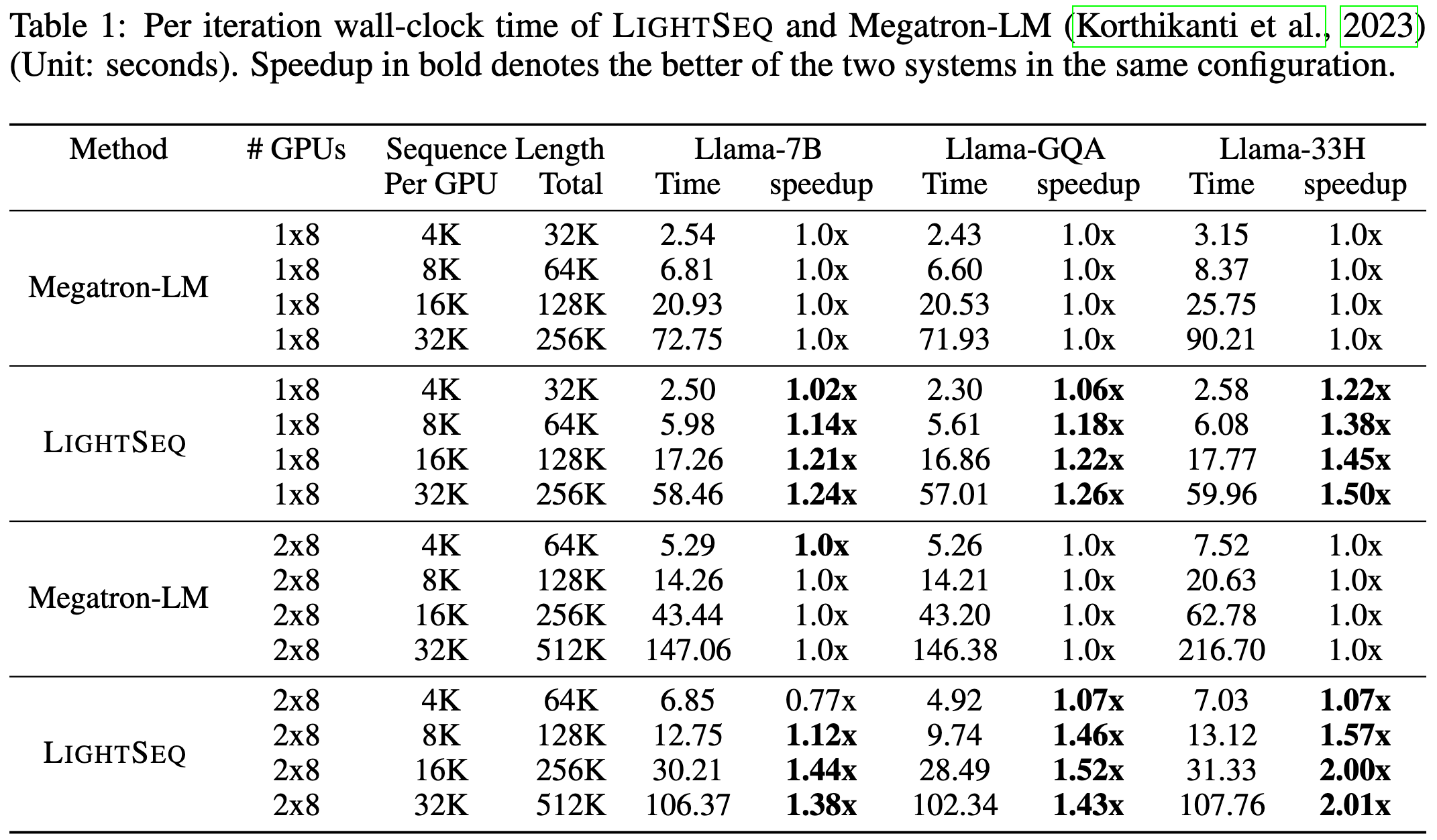
This made me spend a bunch of time thinking about the optimal way to parallelize attention, which is great. The improved Flash Attention checkpointing also seems like an easy win for anyone doing large-scale transformer training.
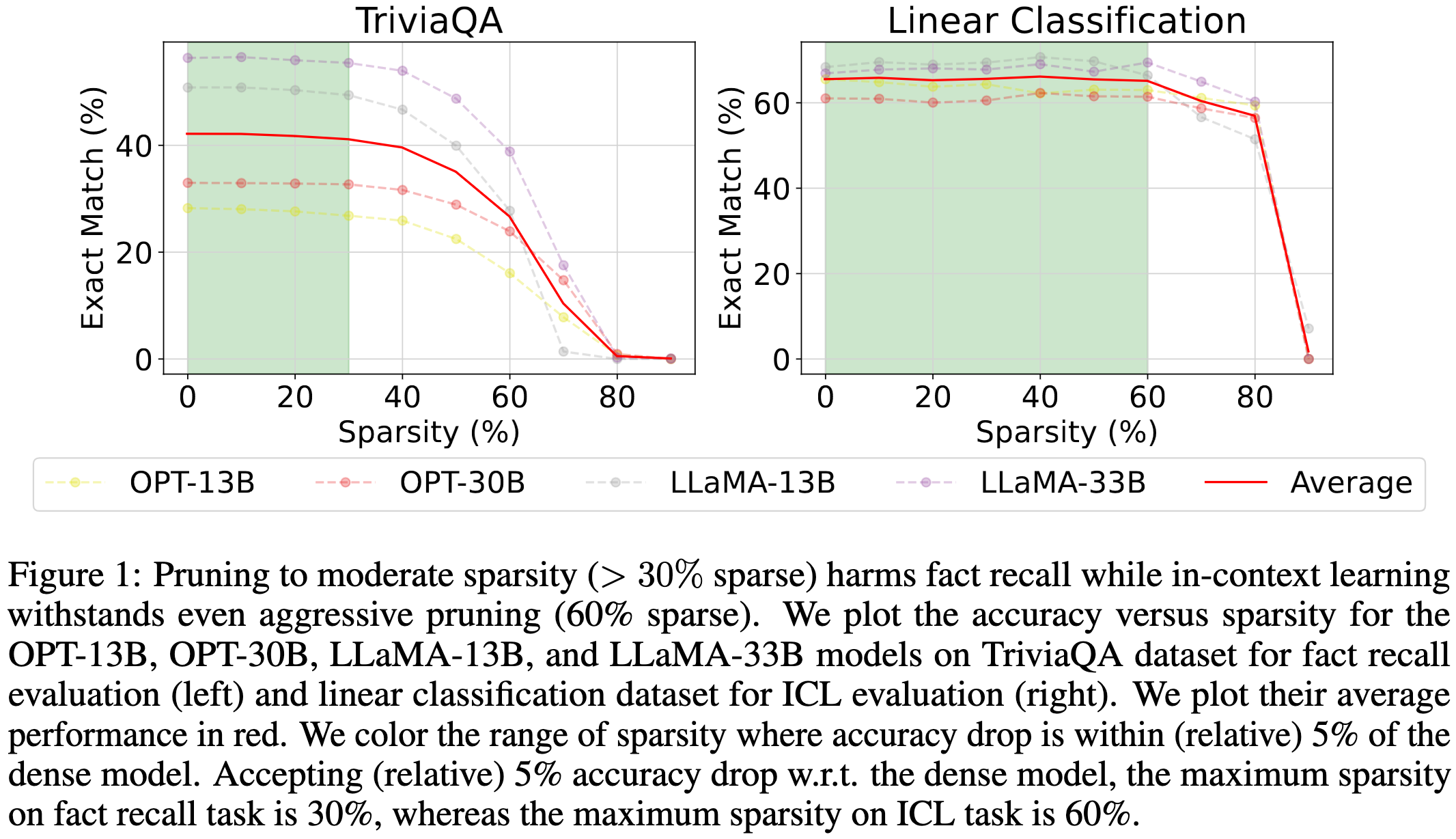
The Cost of Down-Scaling Language Models: Fact Recall Deteriorates before In-Context Learning
If you reduce the parameter count in an LLM, it tends to lose recall of facts before it gets worse at learning from examples in the prompt. This holds for parameter count reductions via both pruning and using a smaller dense model.
Mistral 7B
They highlight interesting aspects of what’s likely the best 7 billion parameter model right now.

The main thing they talk about is adding a sliding window restriction to grouped query attention. This just means that each token can attend only to the W-1 previous tokens for some constant W.
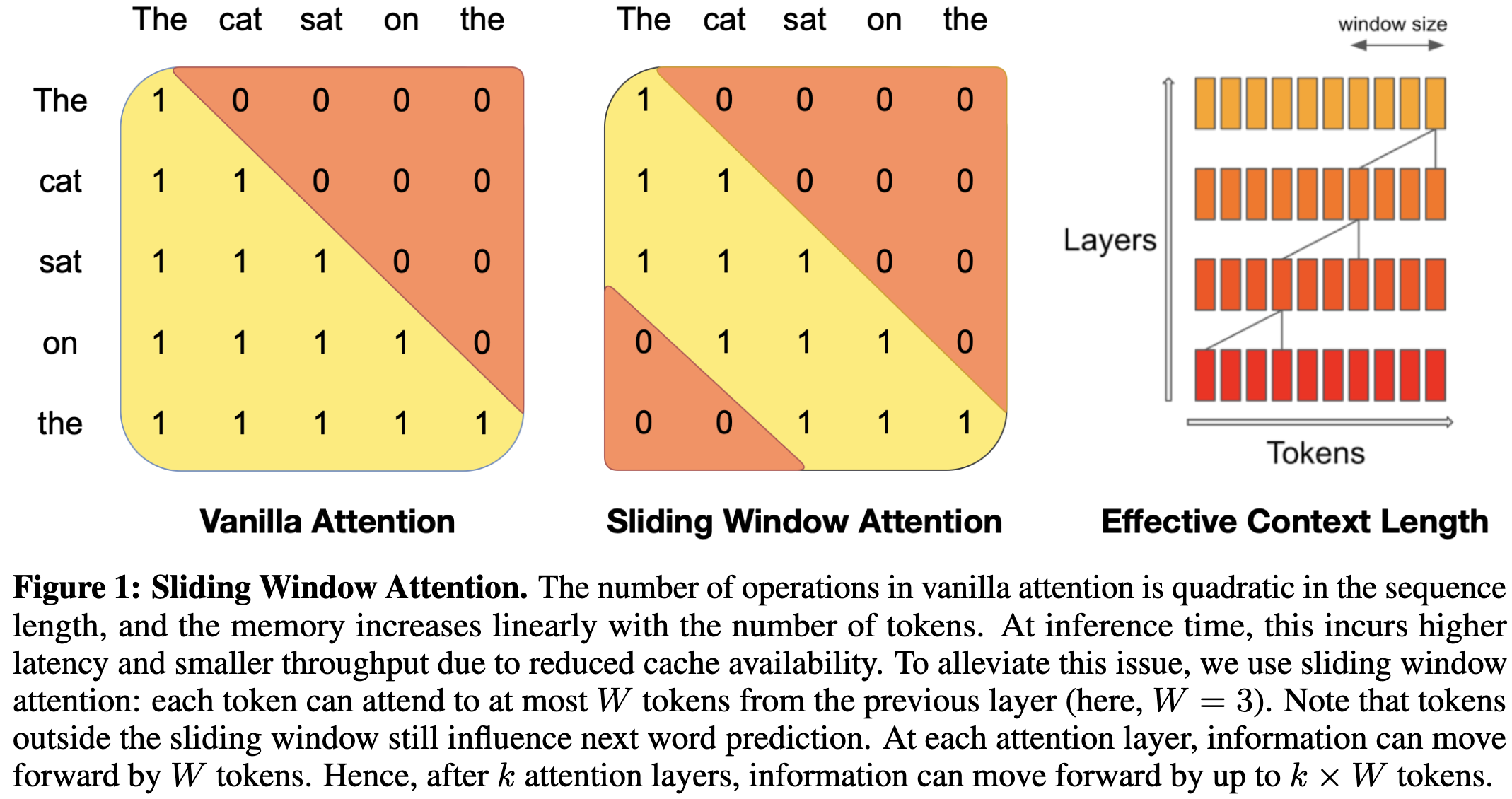
This restriction enables some cool systems optimizations, including allocating a fixed-size circular buffer for the KV cache.

It also lets them skip a lot of the regular N^2 computation during prefill (i.e., processing the prompt in parallel before sequential decoding begins).

They also talk a bit about their system prompt and how they can query the model itself to determine whether it should refuse to answer a given prompt.



They don’t really say anything about the data or how the model was trained, but apparently it beats LLaMA 2 13B across a variety of benchmarks.



There’s not much detail here besides their system prompt and the sliding window attention, but at least that’s something—it’s certainly more than what many of the big labs are releasing about their models.
Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models
They propose to have language models ask themselves (and answer) a more general question than the prompt, and use the results to refine their initial answer.
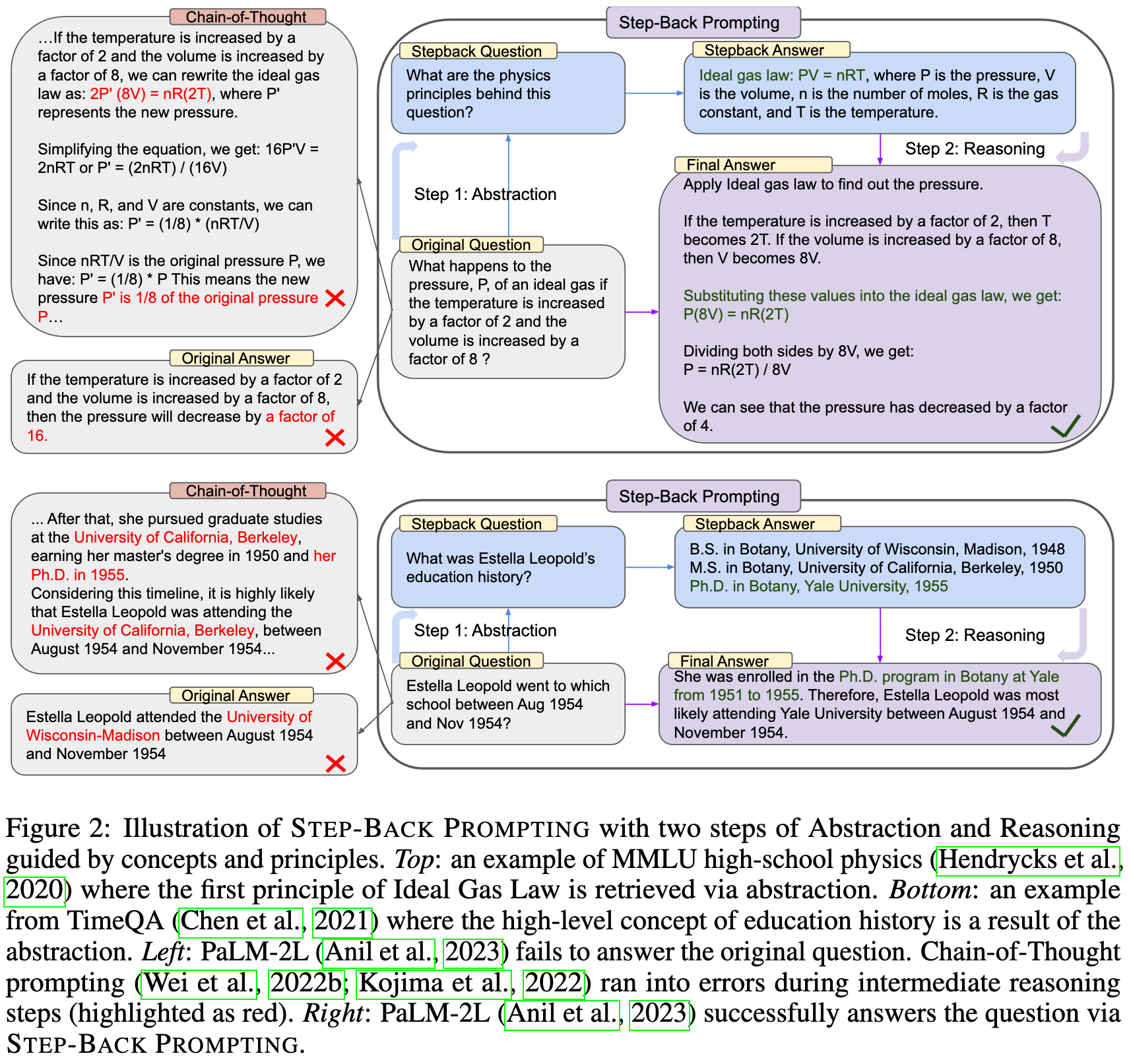
This apparently increases accuracy a lot across a variety of knowledge and reasoning tasks.


They use task-specific prompt templates to generate the “step-back” questions and the final answers.


I never find prompting methods intellectually satisfying, but this does seem like an easy accuracy lift for a well-defined class of problems.
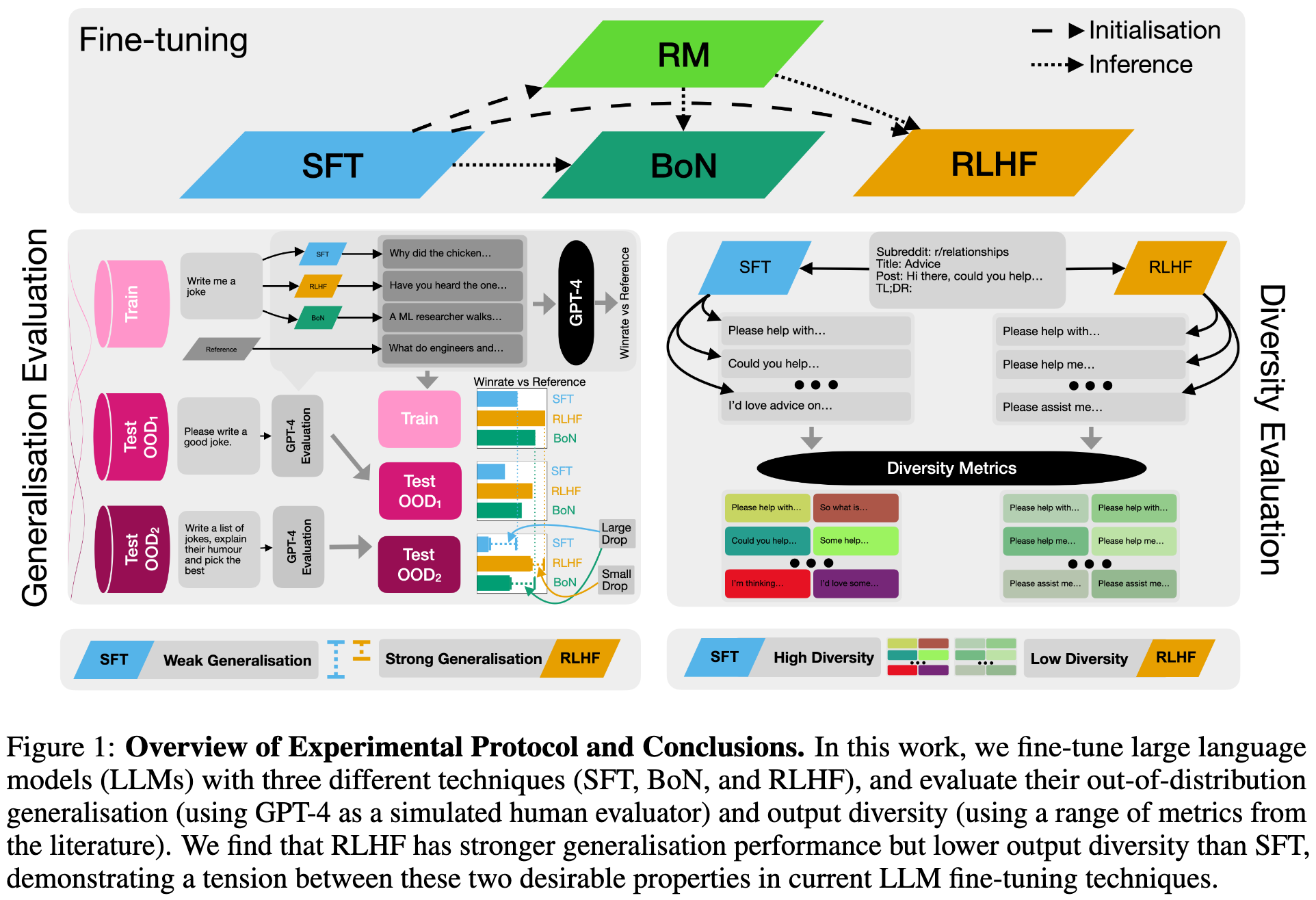
Understanding the Effects of RLHF on LLM Generalisation and Diversity
They find that RLHF generalizes better out-of-distribution than supervised finetuning, but the latter yields more diverse generations.


Fast-ELECTRA for Efficient Pre-training
Instead of jointly training the auxiliary model that populates the mask tokens in an ELECTRA setup, just use a pretrained model. But to make this work, you need a softmax temperature curriculum to progressively increase the difficulty for the main model (as the sampled tokens get more and more plausible according to the auxiliary model’s output distribution).

Online Speculative Decoding
When speculative decoding, you have a small draft model that predicts the next token. If the main model assigns this token high enough probability, we accept this prediction and move on.
They propose to do continual learning in the draft model, recording predictions that weren’t accepted and doing knowledge distillation when the inference machines are under low query load.


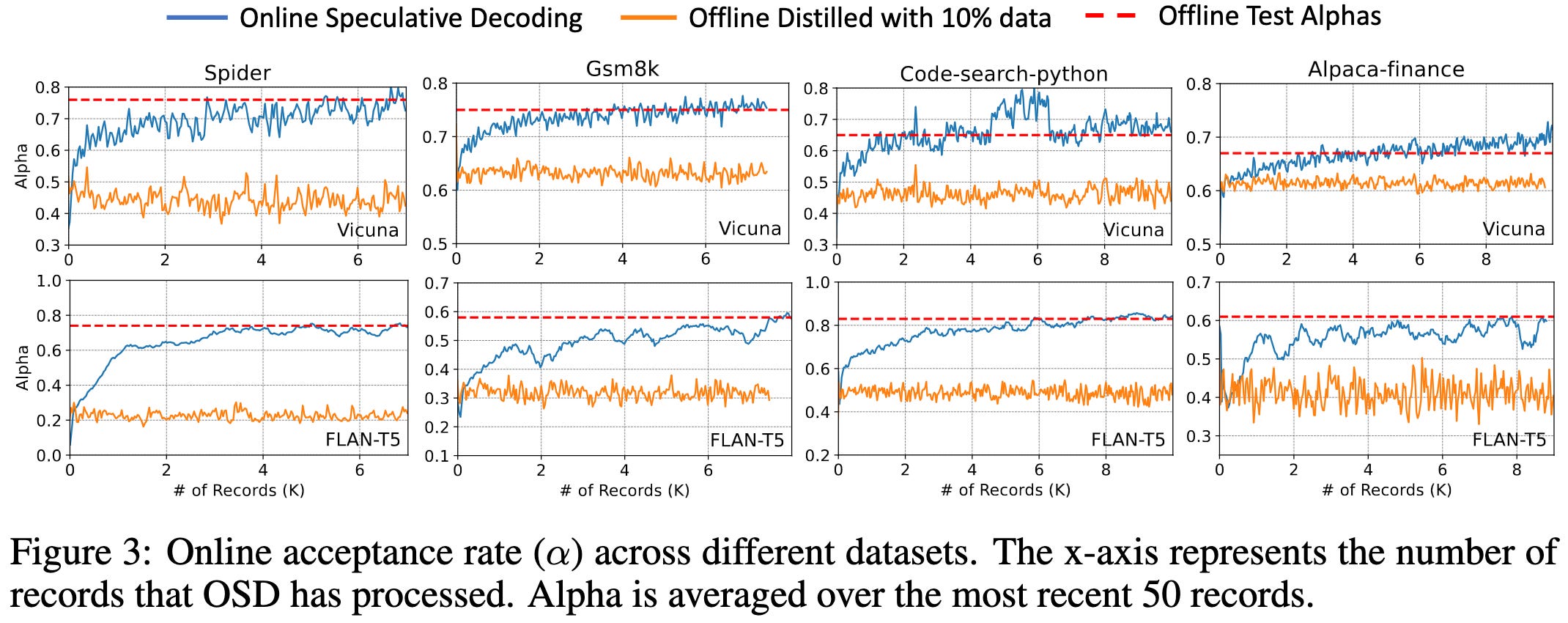
This is gonna be super hard to put in production from an ops perspective, but I really like the idea of sneaking in some useful work while the inference machines are underutilized.
NEFTune: Noisy Embeddings Improve Instruction Finetuning
Apparently just adding appropriately-scaled noise to the token embeddings makes instruction finetuning work way better.


Based on a lot of the eval using LLMs as raters, I was worried that this might be just increasing the length of outputs. But they actually looked into this and found that increased generation length isn’t enough to explain the gains.

Not sure why this works, but hey, I’ll take it.
So I wrote this paper in 2017 where we showed you could do crazy fast approximate Euclidean distances and dot products with vector quantization. This basic idea is incorporated in FAISS and ScaNN on CPUs. This result was legit, but there are a couple reasons it’s less cool than it sounds:
This paper simultaneously came up with roughly the same thing. Our data layouts are different but the big hammer is fitting stuff in SIMD registers, and we both do that. They also have a nicer way of setting the upper bound for the lookup table quantization in the case that you’re using it for large-scale similarity search.
It also seems like some Google people came up with roughly the same idea because Google papers never cite either of us. In particular, the ScaNN paper cites this, although that paper doesn’t actually mention SIMD or 16-bit representations and they specifically say “the codebook size for each subspace, C, was fixed to be 256, leading to a 8-bit representation of a database vector in each subspace.” (You needed C=16 to fit in SIMD registers at that time.)
Using 4-bit codes is way faster on CPUs when you’re compute bound but not when you’re memory bandwidth bound. This is because 4-bit codes are less space efficient than 8-bit codes. Also, 8-bit code lookups should hit L1 cache, so even loading in codes from L2 cache could be the bottleneck. This means that you should only expect 4-bit codes to actually be faster when you can keep a lot of the database in cache; this mostly becomes possible when you batch a lot of queries relative to your dataset size to get data reuse, or when you, uh, run a bunch of microbenchmarks right before the KDD deadline and don’t worry too much about cache effects.
Where 4 bit codes really shine is with approximate matrix multiplication, since you can get fat enough tiles to actually hit L1/L2 cache most of the time.
So what I said about the basic idea being incorporated in popular libraries is about right, but I think my wording around how often it’s useful on CPUs was off.
re: sparse backprop, do you not find it odd that they report their switch transformer baseline as underperforming the dense model baseline in BLEU score under all circumstances?
I don't believe this is the expected outcome based on the original switch transformers paper.
Regarding the Downscaling paper, the authors' take is weird. My conclusion from their work is that downscaling LLMs retains learning ability even though it scrubs facts. This seems super useful if one wants to stop a system regurgitating training set data, prior to finetuning it on a different training set which it is OK to remember. In other words: build a large model with lots of low quality data, make it smaller, then finish training the small model on highly curated data. The point here is to use an existing system as the basis, saving the initial training phase of the new system, and allowing reuse of large training runs instead of starting from a random set of weights.