
2023-2-5 arXiv roundup: ICML deluge part 1

This newsletter made possible by MosaicML.
There were over 800 arXiv papers this week thanks to the ICML deadline, so this one ended up a little delayed. We’ll likely have a ton of submissions next week also…
Are Diffusion Models Vulnerable to Membership Inference Attacks?
They propose an algorithm to figure out whether a given image was part of the training set for a diffusion model. It works really well on CIFAR-10 and Tiny-ImageNet.


It also works pretty well on Stable Diffusion. To assess this, they check how good the image looks after running only a small fraction of the diffusion steps (middle column). For an image in the training set (top), it already looks good. But for an image not in the training set (bottom), it’s all blurry.

This Stable Diffusion result is the most interesting to me since it uses a realistic model and a realistic (though not huge) finetuning set (COCO2017-Val). Between this and a similar paper last week, it looks like you can tell which samples a diffusion model trained on as long as the training (or finetuning) set isn’t too large. And even for larger sets, there could be new attacks that still work.
Extracting Training Data from Diffusion Models
Here’s an even stronger result than the above. They show that you can extract images from the training set given the final model.

And this is a strict definition of “extract”. E.g., just because it outputs a picture of Obama and the training set includes pictures of Obama, doesn’t mean the’ve extracted any training data.

Instead, they only call it “extracting” an image if they basically get all the pixels right.

To do this, they follow a two-step approach:
Sample a ton of images from the model
Use a membership inference attack to figure out which of the generated images are copied straight from the training data.
To do the latter, they find cliques of generated images that all have small distance to one another. It’s hard to define a good notion of “distance” for images, so what they do is split each image into patches and use the minimum L2 distance between any pair of patches in RGB pixel space as the distance between the images.

This approach lets them do membership inference reliably when finetuning on CIFAR-10.
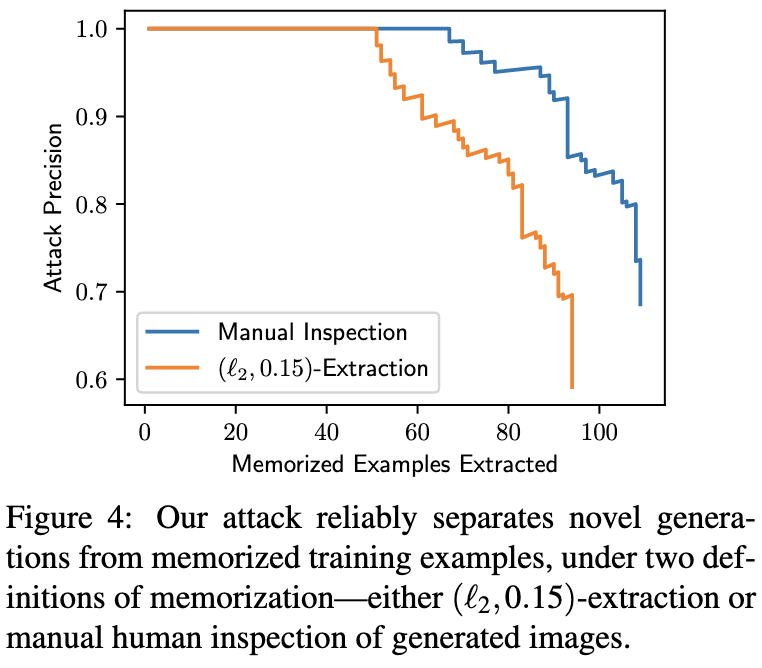
Images that show up in the training data many times are more likely to get leaked. This suggests that data deduplication is a useful mitigation strategy.

Worryingly, they find that better models are more likely to leak training samples. This is bad news, especially since future models will probably be better than current ones.

They also show that you can do targeted reconstruction attacks by setting some of the pixels and asking the model to fill in the rest. If the model hasn’t seen the image before, it might not do a great job. But if it has, it will likely reconstruct the original image.

These targeted attacks might be good from an auditing perspective. Like, if you wanted to know which training images your model had memorized, you could just try to get it to complete each one; if it doesn’t reconstruct any of them, maybe you’re in good shape.
Targeted attacks could also be bad though; imagine seeding it with an image of your face and having it reconstruct a photo of you that you didn’t know was on the internet.
Overall, really thorough and interesting work.
Understanding INT4 Quantization for Transformer Models: Latency Speedup, Composability, and Failure Cases
They quantize both weights and activations to 4 bits for inference in language models. This definitely causes some quality loss, even with quantization-aware training and knowledge distillation. But…

…it also speeds up inference, at least if the weight and activation matrices are large enough.


I can’t tell if their method offers a better speed vs quality tradeoff than just using a smaller model, but I like seeing all this detailed profiling. Looks like int4 is 1.3-2x as fast as int8 in real networks, even for large problem sizes. Although you can get close to 2x for individual matrix products at realistic sizes.
Also, it looks like Pre-LN quantizes better than Post-LN:

SWARM Parallelism: Training Large Models Can Be Surprisingly Communication-Efficient
A well-known property of pipeline parallelism is that the computation grows cubicly in the feature dimension while the communication between stages grows only quadratically. Similarly, one can increase the depth of a given pipeline stage while holding the communication constant. What this means is that you can crank up your compute to communication ratio arbitrarily high by making each pipeline stage larger (up to RAM limits).

They propose to use this observation to do a variant of pipeline parallelism that allows heterogeneous, unreliable devices with super low bandwidth between them.
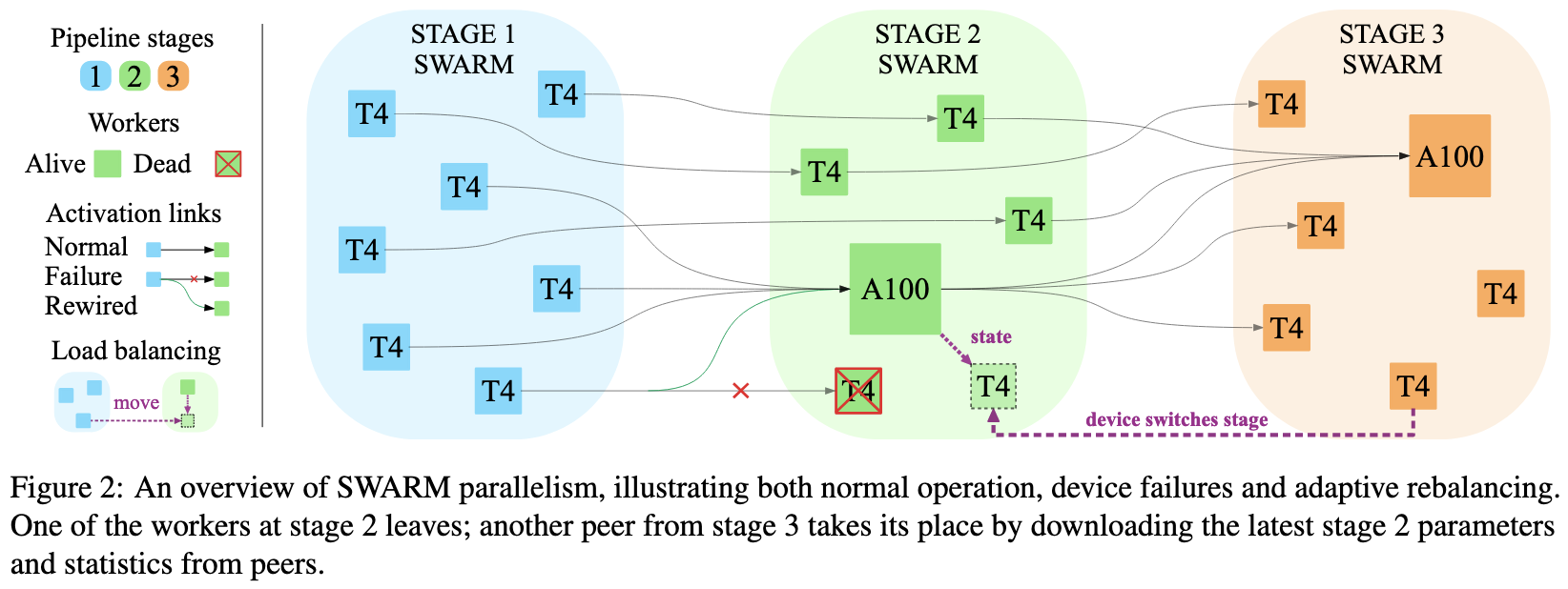
As long as each device has enough RAM to store a decent-sized pipeline stage, you can get solid utilization.

Their system is about as fast as some existing distributed training approaches when network latency is low, and much better when it’s 50-150ms.

Does this mean we don’t need fast interconnect when training anymore?
Not quite. The above evaluation uses only 12 V100s, each in its own server. With this few devices, you can get away with a ton of sequential microbatches per optimizer step, which makes pipeline bubbles much less important. The eval also only goes up to 1B param models, which are small enough to fit in a single GPU’s RAM.
If you wanted to scale up to huge models and as many GPUs as possible, you’d start hitting issues with some combination of pipeline bubbles, poor compute utilization from tiny microbatches, OOMs in the early pipeline stages (if you increased the pipeline depth enough), and extra communication from intra-stage sharding.
That said, I’m a fan of this line of inquiry. Most work is trying to make standard practices a little bit better, and this is instead trying to upend the standard practices and enable new use cases (e.g., training on idle consumer GPUs). Testing the limits like this provides valuable information even for more traditional setups.
STEP: Learning N:M Structured Sparsity Masks from Scratch with Precondition
NVIDIA Ampere and Hopper cards can accelerate sparse matrix products as long as the sparsity has at most 2 nonzeros per 4 elements in each row. People call this 2:4 sparsity.
This paper tries to prune models such that they end up 2:4 sparse.
They start with two observations. First, N:M structured pruning with existing approaches works well with SGD, but not Adam.
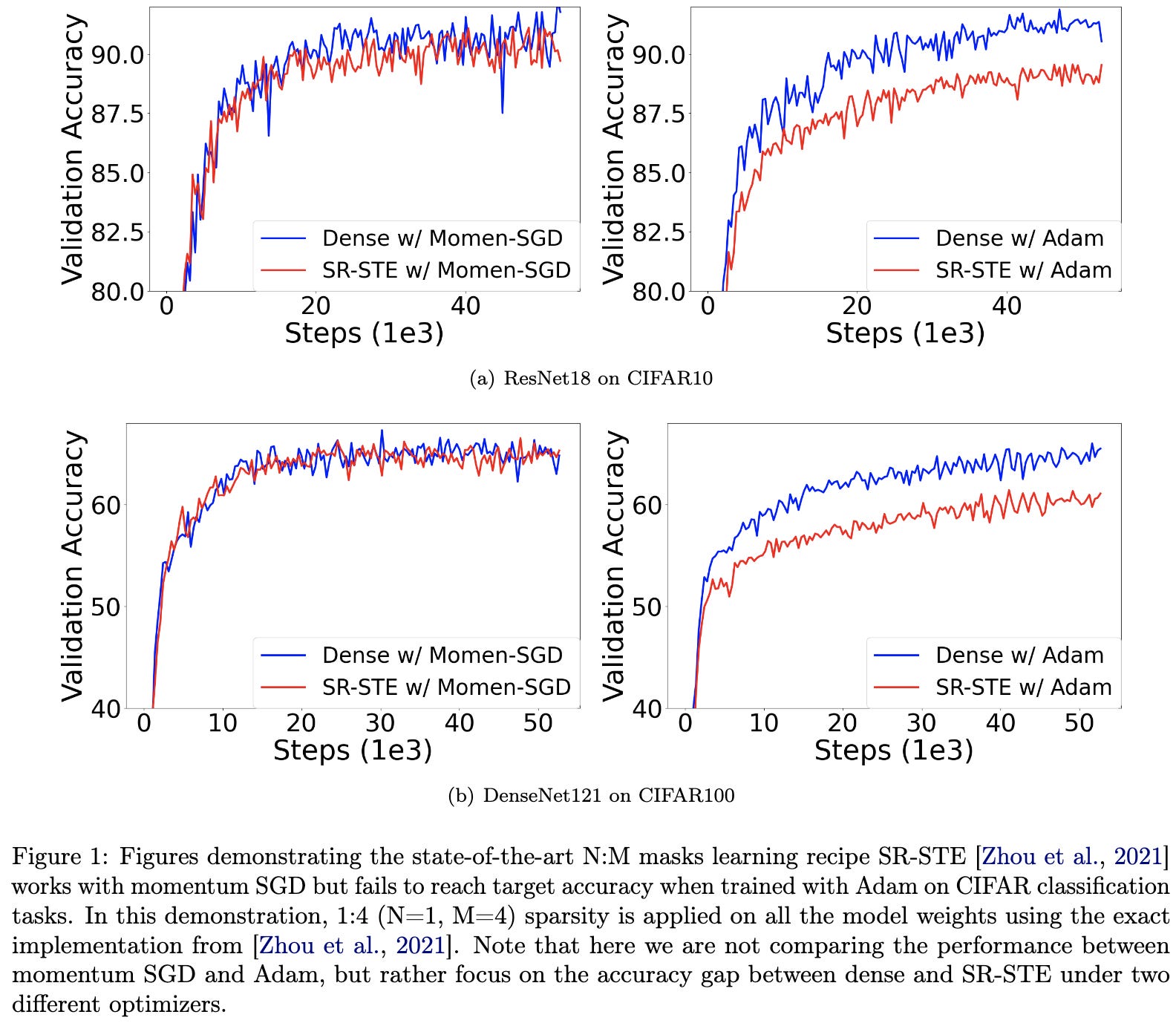
Second, pruning messes with the Adam running variance estimates over time.

So what they propose to do is freeze the Adam variance estimates partway into training, based on a heuristic.

This lets them largely close the accuracy gap between dense and N:M sparse models in some cases.

Mostly this makes me wonder if freezing Adam variance estimates is just plain a good idea; it seemed to help with 0/1 Adam also.
Mnemosyne: Learning to Train Transformers with Transformers
A learned optimizer paper in which they feed a history of gradients or other statistics into a transformer with a subquadratic attention variant and have it output model weight updates.

Seems to do better than other optimizers, at least on some small-ish problems.

Scale up with Order: Finding Good Data Permutations for Distributed Training
They try to intelligently permute examples in multi-epoch training in order to accelerate convergence. The basic formulation is that they want to order examples such that the accumulated gradient within an epoch never deviates too far from the true, full-batch gradient.

They do this with a parameter-server-like training setup that tracks past and average gradients.

One cool property of this algorithm is that it provably accelerates the convergence rate even for non-convex problems.
In practice, it balances out gradients from different examples better when operating across all workers in the distributed training job, rather than within each worker.

At least for small tasks, the method often improves accuracy compared to random reshuffling within each worker (D-RR). As a result of this accuracy lift and sufficiently low overhead, it can also improve time-to-accuracy.


Not sure it will work at scale, but really interesting. I would never have guessed that one could provably change the scaling exponent in the optimization from 1/3 to 2/3 by permuting samples.

This is consistent with claims of improved scaling via data pruning, though seemingly a much stronger result.
Dual PatchNorm
When using ViTs, they find that you should add LayerNorms before and after the patch embedding layers. This works better than any other LayerNorm placement strategy they found after a lot of experimentation.

This result seems to hold across a bunch of different tasks.



Plus their ablations show that adding the LayerNorm both before and after the embedding really is necessary.

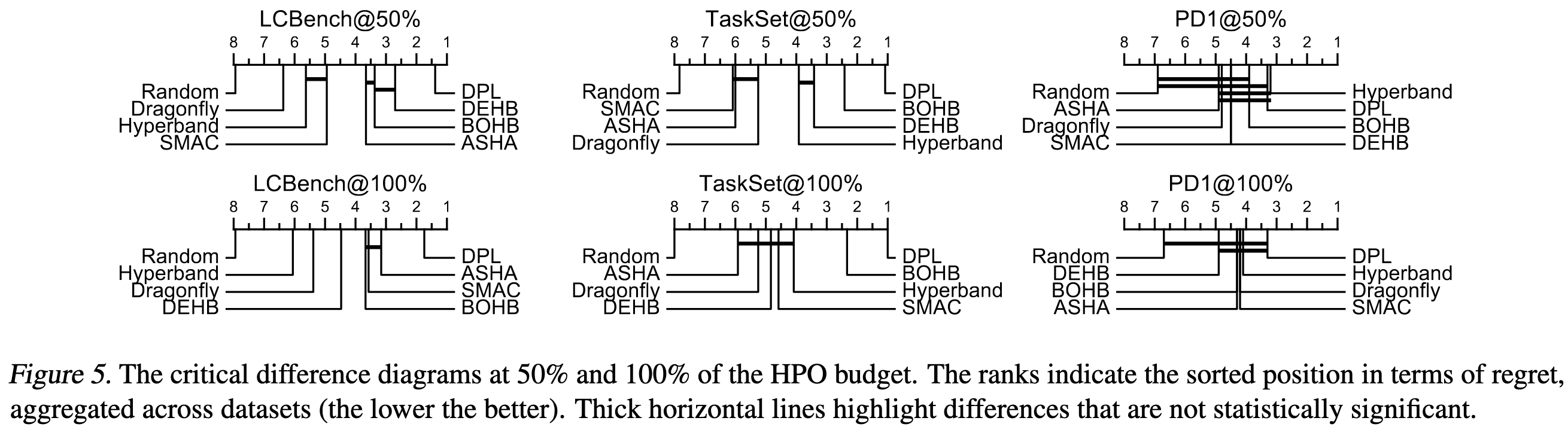
Deep Power Laws for Hyperparameter Optimization
When doing hyperparameter optimization, you can abandon training runs early if you can forecast the rest of the training curve. They find that using an ensemble of neural nets and assuming that the curve follows a power law works better than alternative approaches.

Concretely, the neural nets in the ensemble take in the hparams as features and output estimated power law coefficients. They’re trained using the observed training curves so far.
They show that this improved forecasting can translate to better hparam optimization.

Side note: critical difference diagrams are great I’m amazed at how few ML researchers have read Statistical comparisons of classifiers over multiple data sets. We’d have so many fewer statistically meaningless “improvements” if only these were standard practice.
Mathematical Capabilities of ChatGPT
ChatGPT isn’t great at advanced math compared to trained humans. It’s pretty good at retrieving relevant theorems, definitions, etc, if you give it a good prompt though.



I’m just impressed that it’s anywhere near humans; if it’s already this close to us in the vast space of possible minds, ChatGPT’s successors will likely outperform humans in these pursuits pretty soon.
Training with Mixed-Precision Floating-Point Assignments
Which tensors should be in float8 vs float16 vs float32? A typical answer is something like “make everything but the norm ops float16”. But can we do better?

They propose a method that does.
To assign precisions to tensors, they:
Group together tensors involved in the same or adjacent GEMMs, giving all tensors in the group the same precision
Reduce precision for the largest groups first, where size is total number of elements in the group’s tensors. They stop reducing precision when some pre-defined threshold of size reduction is reached.
Increase the precision for tensors that have overflow too high a fraction of the time during training
This approach works a little better than common mixed precision practices.


It’s not a huge lift, but nice to see a fairly simple method offering a practical improvement.
Scaling laws for single-agent reinforcement learning
You don’t get power-law scaling with most RL evaluation metrics, but they found one where you do: the “Intrinsic Performance”.

This metric is defined as the minimum amount of compute required to attain a given value of some other, underlying metric.

The power law they fit decays with both model size and number of interactions with the environment, closely resembling language model scaling formulas.

Seems like this might be a general-purpose technique for getting power law scaling curves out of more models and metrics. Kind of a Doob martingale for scaling.
Looped Transformers as Programmable Computers
They feed a transformer’s output back in as input, with added structure to make it act like a computer.

First, by designing the weights in the transformer, they can implement various known functions.

They also add binary position embeddings to the input sequence, make one token act as a program counter, design a single-hidden-layer ReLU network that can increment the program counter, and structure the network such that it attends to whatever “command” is present at the program counter.
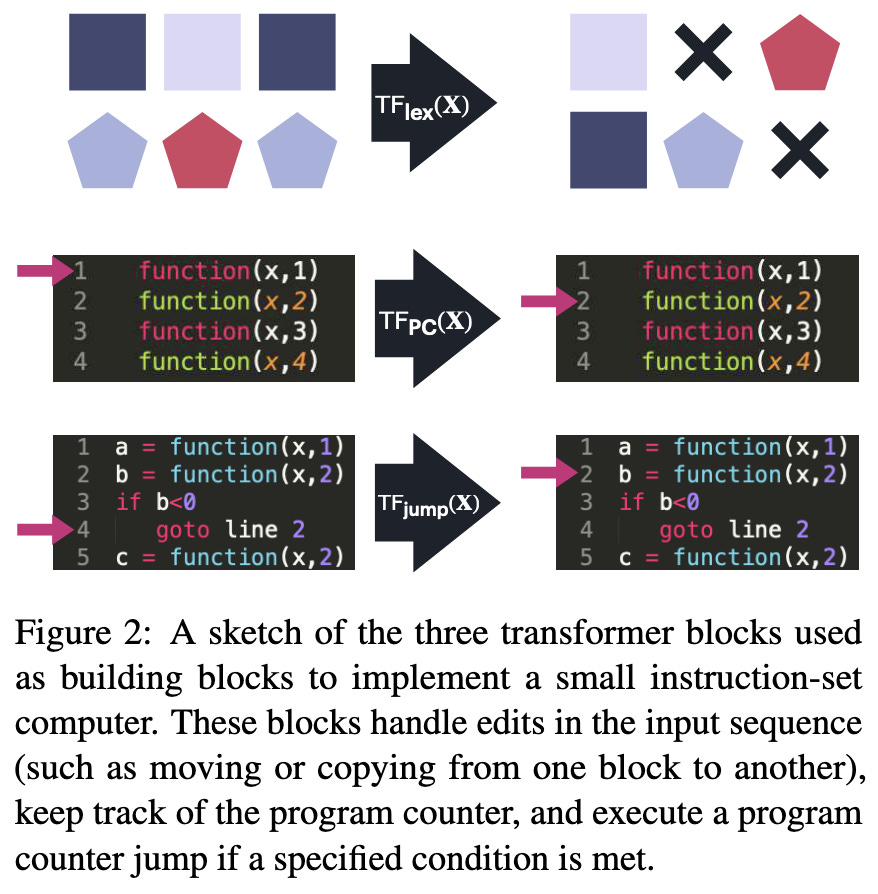
On top of this, they structure the network to perform reads and writes to a “scratchpad” section of the input.

Using these building blocks, they give a constructive proof that you can construct a Turing-complete computer using a nine layer transformer. The key observations are that a) the SUBLEQ instruction alone suffices for Turing completeness and b) transformers can implement the SUBLEQ instruction.

The constructions for all these functions are pretty detailed, but often look a lot like a traditional computer. E.g., they can encode instructions using a bunch of pointers and array sizes.

Putting it all together, they show that you can implement gradient descent, power iteration, approximate matrix inversion, and a simple calculator.
This is pretty cool, and seems like the ideal paper to study in depth if you want to build intuition for what functions one can compute with various numbers of self-attention layers.
It also feels like it might be a taste of what’s to come in the future—models that unify both traditional computational primitives and learned operations.
Operator Fusion in XLA: Analysis and Evaluation
A nice overview of what fusions and other optimizations are possible in XLA and when they can be applied.

Features the most thorough and concise list I’ve seen of tensor compiler passes/optimizations:


Knowledge Distillation ≈ Label Smoothing: Fact or Fallacy?
Knowledge distillation seems to be doing something different than label smoothing. Specifically, distillation tends to decrease output entropy compared to vanilla labels, while label smoothing tends to increase it. This suggests that distillation might be more about label denoising or knowledge transfer.

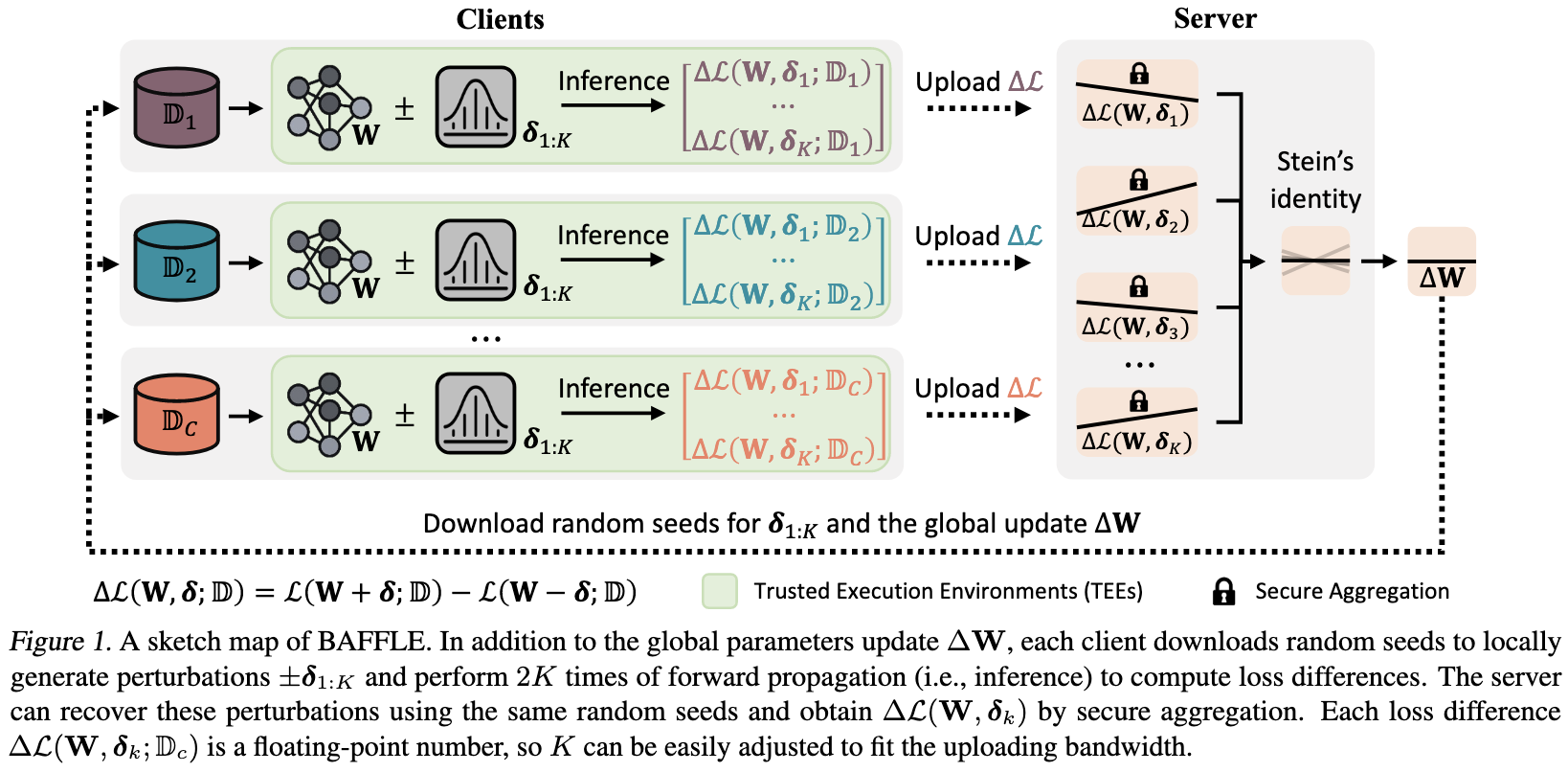
Does Federated Learning Really Need Backpropagation?
Kind of.
Like a lot of backprop alternatives, they propose to use random input perturbations and their associated loss gradients to numerically estimate the true gradient. This approach is basically screwed in high dimensions because:
Random vectors will have an inner product with the gradient direction drawn from 𝒩(0, 1/P) for P-parameter models.
The maximum of a bunch of Gaussian random variables increases logarithmically.
This means that, for models of a decent size, all your random perturbations are almost exactly orthogonal to your gradient—i.e., you don’t find any direction that significantly reduces the loss.
So usually I’m pretty pessimistic about these sorts of approaches.
But this one is interesting because it has a strong motivating use case and some nice systems optimizations.
The use case is federated learning. This provides decent motivation for avoiding backprop since:
You might want to keep the model a black box for clients (via, e.g., trusted execution environments). Backprop requires access to the full model weights and computation graph.
Clients might be wimpy IoT devices or smart phones with too little RAM to store many activations, as required by backprop.
We might be training a tiny model for privacy or inference cost reasons. With few enough parameters, random input perturbations actually can find good descent directions.
What this means is that, for small models and datasets, they can get decent training even with the clients only running forward passes and treating the model as a black box.

So you shouldn’t use this in a typical training setup, but it does show that there are design requirements for which backprop-free training might actually make sense (which AFAIK hasn’t been true before).
Open Source Vizier: Distributed Infrastructure and API for Reliable and Flexible Blackbox Optimization
Google open-sourced Vizier, their hparam optimization service. The most interesting aspect of Vizier to me is the OptFormer and its potential for recursive self-improvement, but it doesn’t look like they open-sourced this model.
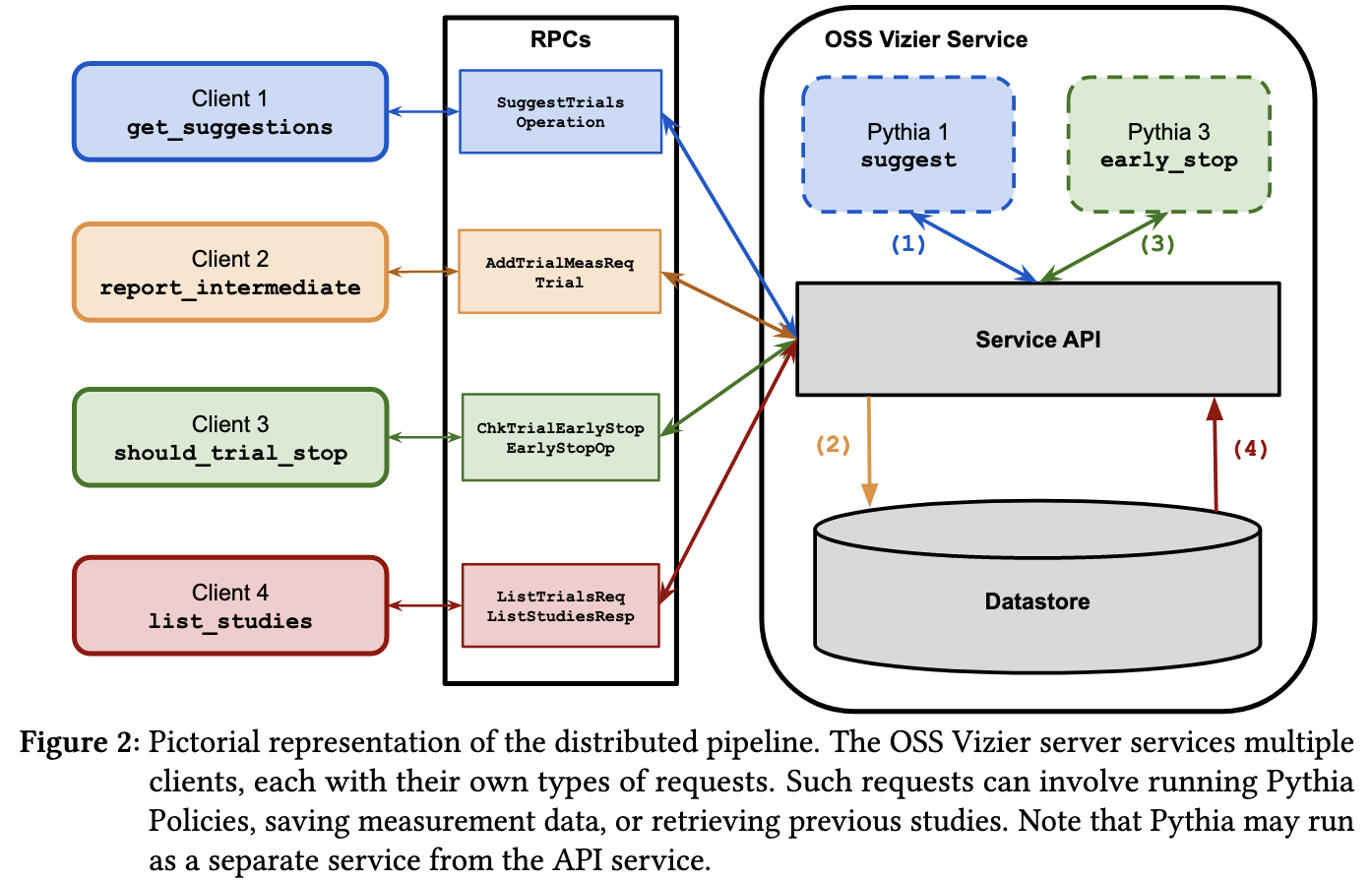

Seems pretty clean and usable; worth checking out next time you need to optimize some hparams.

The Flan Collection: Designing Data and Methods for Effective Instruction Tuning
What choices matter when carrying out instruction tuning? The FLAN-T5 team investigates through a series of ablation experiments.

First, training with both zero-shot and few-shot prompt templates helps, even for models with as few as 3B parameters. The difference between these two kinds of prompts is whether they include any example input-output pairs.

When evaluating the model on tasks it was trained on, the number of tasks doesn’t matter that much. Especially for small models, using too many tasks can hurt accuracy though. When evaluating on held-out tasks, more tasks is better (unless maybe you have a small model and a ton of tasks).

Which datasets you train on matters, as does how you weight them.

Even if you only care about one downstream task, starting with an instruction-tuned checkpoint is a good idea.

In fact, starting with an instruction-tuned checkpoint increases not only the accuracy, but also the speed of convergence.

Here’s a unified table of ablation results. Four techniques here are helpful: balancing different types of tasks, including chain-of-thought tasks, using both few-shot and zero-shot prompts, and swapping the roles of target output and prompt as a data augmentation. Also, as revealed by the lack of bold numbers in the bottom section, their collection of tasks is probably the best.

As a final note, they have a nice list of all the public instruction tuning collections, along with some metadata like whether they’re public or not.

Since instruction tuning seems to be one of the biggest wins in all of NLP right now, this detailed look into how to do it well is super valuable—as is their open source code.