

Besides getting to cover unusually interesting work, the upside of having a big backlog is that you can group your coverage thematically. This week’s themes are data, scaling curves, and data scaling curves.
How to Train Data-Efficient LLMs
They explore how to do pretraining data curation well and use their findings get much better pretraining data.
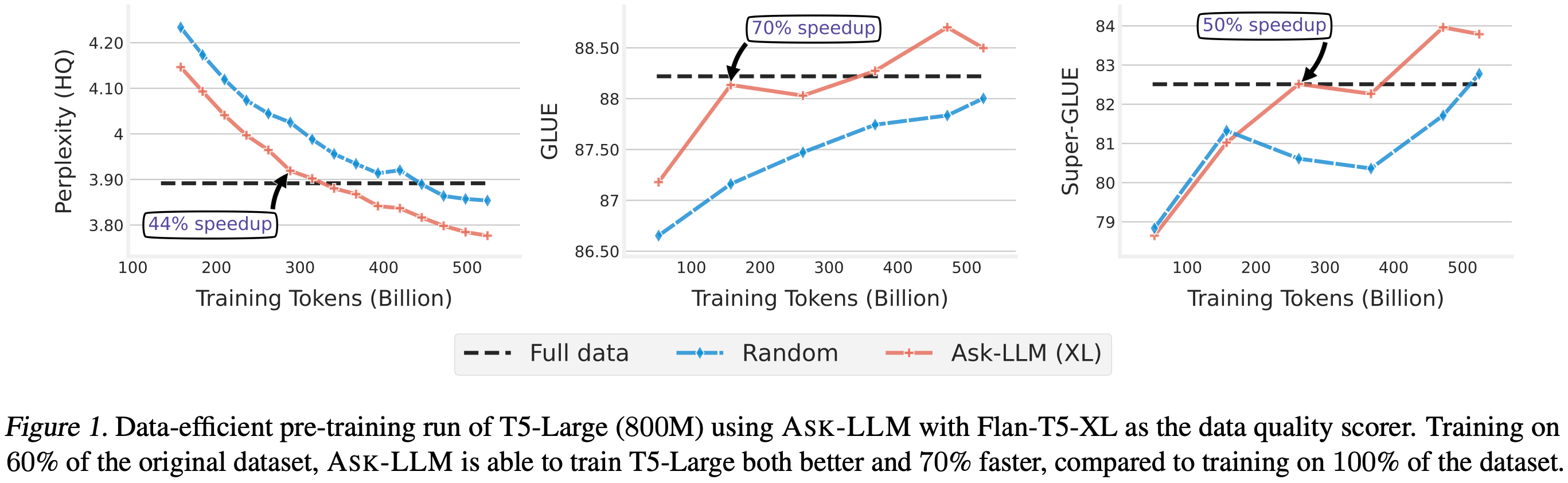
The main tradeoff they explore is that of quality vs diversity. I.e., do you want only the cleanest samples, or samples that cover everything, even if they’re uglier? To explore this, they introduce two methods at the extreme ends of these tradeoffs: Ask-LLM and Density.

Ask-LLM feeds each passage into a pretrained LLM and asks it whether it looks like good pretraining data. The probablity assigned to the “yes” response is the passage’s quality score.

Density uses kernel density estimation to score passages, and then does Inverse Propensity Sampling to upsample passages in less dense parts of the distribution.

So how do these (and other filtering heuristics) work when holding dataset size and training hparams constant? For ~1e20 to 1e21 FLOP training runs, Density and and random subsampling consistently offer some of the lowest perplexities. When evaluating perplexity on high quality data rather than everything (middle subplots), Ask-LLM often does even better. The “overscaling” metric on the right is a normalized score across 111 downstream evaluation tasks, and shows Ask-LLM, Density, and sometimes K-means-prototype-based deduplication doing the best.

When looking at perplexity on high a quality eval set as a function of training time, Ask-LLM consistently works better than perplexity-based sample filtering.

Digging into what’s going on under the hood, they find that Ask-LLM yields nearly uncorrelated sample scores when asking different LLMs, while perplexity-based scoring has high correlation across all LLMs. The latter result isn’t that surprising since perplexity estimates should all converge to the true conditional token distribution. But the lack of score correlation for Ask-LLM is pretty surprising. It also suggests that maybe one could ensemble the different predictions to do even better (or that all of these models are too small, since the two largest models start to become correlated).

Also, the appendix is full of tons of examples of good and bad samples, along with the percentile of quality that both Ask-LLM and perplexity filtering assign to each. If you’re serious about understanding LLM data quality, this is pure gold and I would literally go through all 31 examples.

Besides showing the raw text and scores in this appendix, they also have analysis of the different trends and failure modes. E.g., it often takes a big LLM to recognize when high-perplexity passages are high quality but just talking about obscure topics.

A final interesting point they highlight in the discussion is that Ask-LLM is really expensive as filtering heuristics go. This is because it involves inference in a large LLM for every passage. Depending on how much data you filter vs train on and your training vs inference utilization, this could make your data filtering cost more than your pretraining.
Along with the growing importance of synthetic data, this suggests that inference compute will come to dominate training compute even more in the coming years. Although they do note that data filtering can be a one-off operation that gets amortized over many pretraining runs.
Overall, this is one of those papers to study in detail and come back to repeatedly if you care about LLM data quality.
Scaling Laws For Dense Retrieval
They found power law scaling for retrieval metrics with respect to model size and other factors. Here it is for model size:

And here it is for dataset size:

They also find that, when labeling ground truth (query, passage) pairs, different annotation approaches have different results. The highest-quality automated approach has the steepest slope, but, interestingly, all other methods have similar slopes.
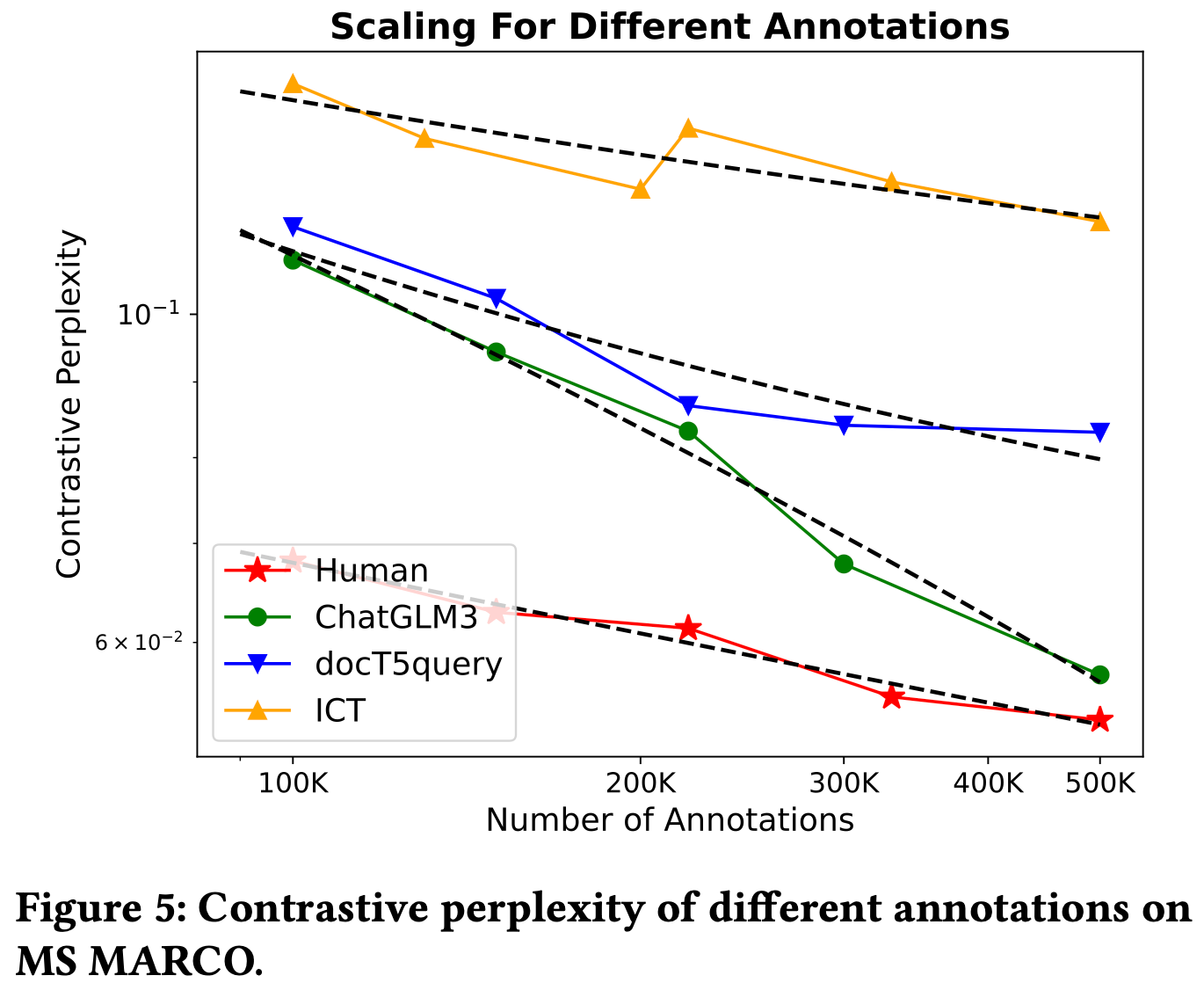
When combining their different results, they get reasonably accurate predictions for what loss you’ll get with larger numbers of annotations at a given model size.

Power law scaling strikes again. This is more evidence that this scaling isn’t just a quirk of decoder-only models or next-token prediction. But since these results are still using text data, we don’t get evidence about which of {data distribution, optimization, transformer architecture, etc}, are necessary factors.
Learning to Generate Instruction Tuning Datasets for Zero-Shot Task Adaptation
High-quality Instruction tuning data is expensive—think tens of $$ per sample. What if we could generate these samples programmatically instead?

The idea here is to:
Gather a bunch of datasets from P3 that require a context to answer

Standardize them into a bunch of meta-templates that include a task type, context, question/prompt about the context, and correct answer.

Train a model on these standardized samples to go from {task type, context} to {question/prompt, correct answer}.

This lets you feed in regular old passages of text and get instruction + ground truth response pairs from them.
How well does it work? Holding dataset size and hyperparameters constant, using their generated samples works better than no instruction tuning and continued pretraining on the task data (TAPT).

You can also use to their generated data to instruction tune on top of already instruction-tuned models and consistently get further lift. This isn’t true of continued pretraining on task data.

Besides the technical impact of making instruction tuning data cheaper, there’s an interesting non-technical angle here around licensing. The pipeline of:
training a sample-creation model on non-commercial data and then
using that model to generate your own data
may be a workaround for non-commercial data licensing terms.1 This is because you’re getting value from the non-commercial data but technically not training your final, commercial model on it. In particular, this might let you indirectly train on outputs from other models that forbid this.

What I’m not sure about is whether this is just a temporary loophole that will get plugged in the next round of licenses or an arms race where people will always find a way to work around non-commercial licenses. I’m guessing it’s the former but we’ll see how it plays out. If it’s the latter, that’s a little bit bad for model providers, but mostly bad for training data providers like Scale, Surge, etc, who gain the most from these restrictive terms.
Toward Inference-optimal Mixture-of-Expert Large Language Models
Most work on LLM scaling has only considered training cost and dense models. What if you look at MoE models and take into account inference cost?

To figure out the best course of action, you first need to measure how MoE models’ loss varies with expert count E, base model param count N, and token count D:
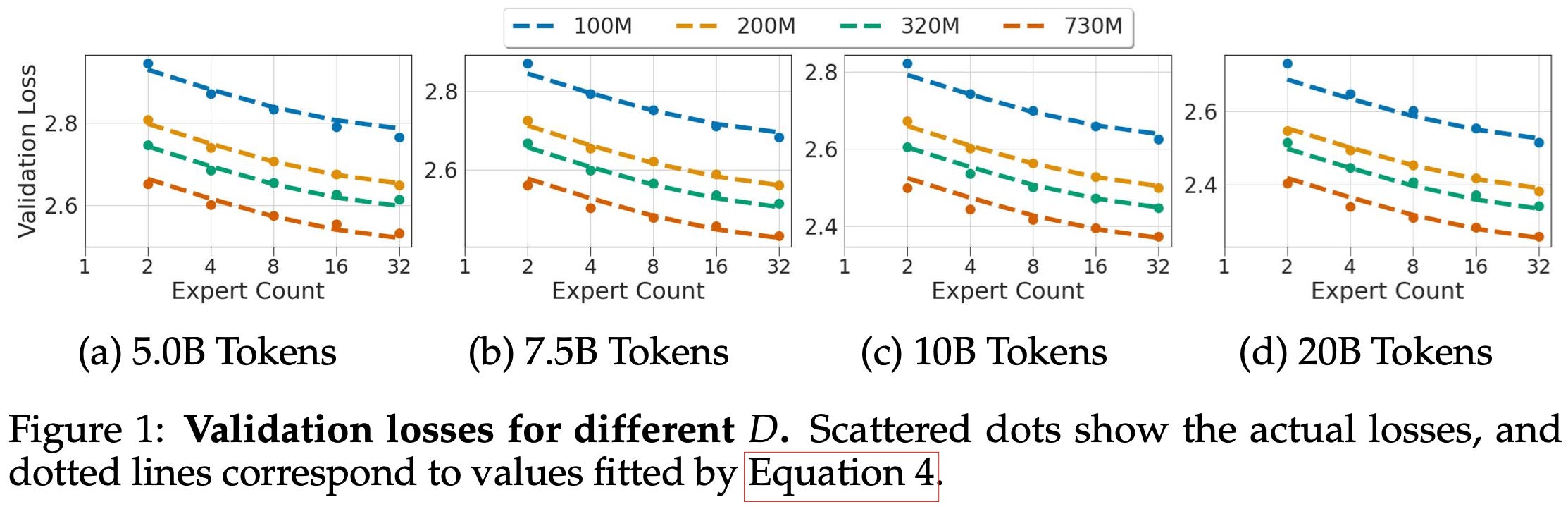

This lets you estimate the loss for a given set of architecture hyperparameters. But if we want to minimize inference cost subject to a quality constraint, we also need to know how these architecture hparams map to inference cost.

Under the assumption that you can use whatever inference batch size and device count you want, this is a reasonably straightforward profiling problem (at least with various inference configuration + runtime choices fixed).

Putting these curves together with the training curves, you can derive tradeoffs between training FLOPs, loss, and inference cost.

Of course, getting these exact curves for a real-world MoE deployment is much more painful. The main issue is that you have to characterize your workload and SLAs in a lot more detail. What’s your query arrival rate? What’s the biggest burst in queries you have to be able to handle? Do you need both latency and throughput guarantees? Are these guarantees per user, per organization, or aggregate? Etc. And you also have to think about training utilization in addition to FLOPs.
But that said, this sort of detailed characterization is exactly what people end up needing in practice, and it’s great to see papers doing systematic studies of important questions.
Blending Is All You Need: Cheaper, Better Alternative to Trillion-Parameters LLM
They find that a simple mechanism for combining the outputs from different pretrained models lifts user engagement + retention metrics significantly on their chat platform.

What’s crazy is that the method of combining outputs is to just choose a model from a fixed set uniformly at random for each response. So after each time you type something as a user, you have a 1/N chance of getting a response from each of the N pretrained models.

I’m pretty baffled as to why this works so well. I was expecting to read a positive result for ensembling the logits or something, which would already be interesting because there’s been limited work on ensembling LLMs. But this result is even stronger because it just chooses one model at random without even conditioning on the input or trying to intelligently select which one to use.
My best guess is that there’s some property of how people use chat interfaces that makes diversity of responses really important. Maybe one model refuses to answer, but then the user insists and the next model agrees to answer?
Whatever’s going on, this is a bizarre datapoint, and that’s often the most valuable kind in science.
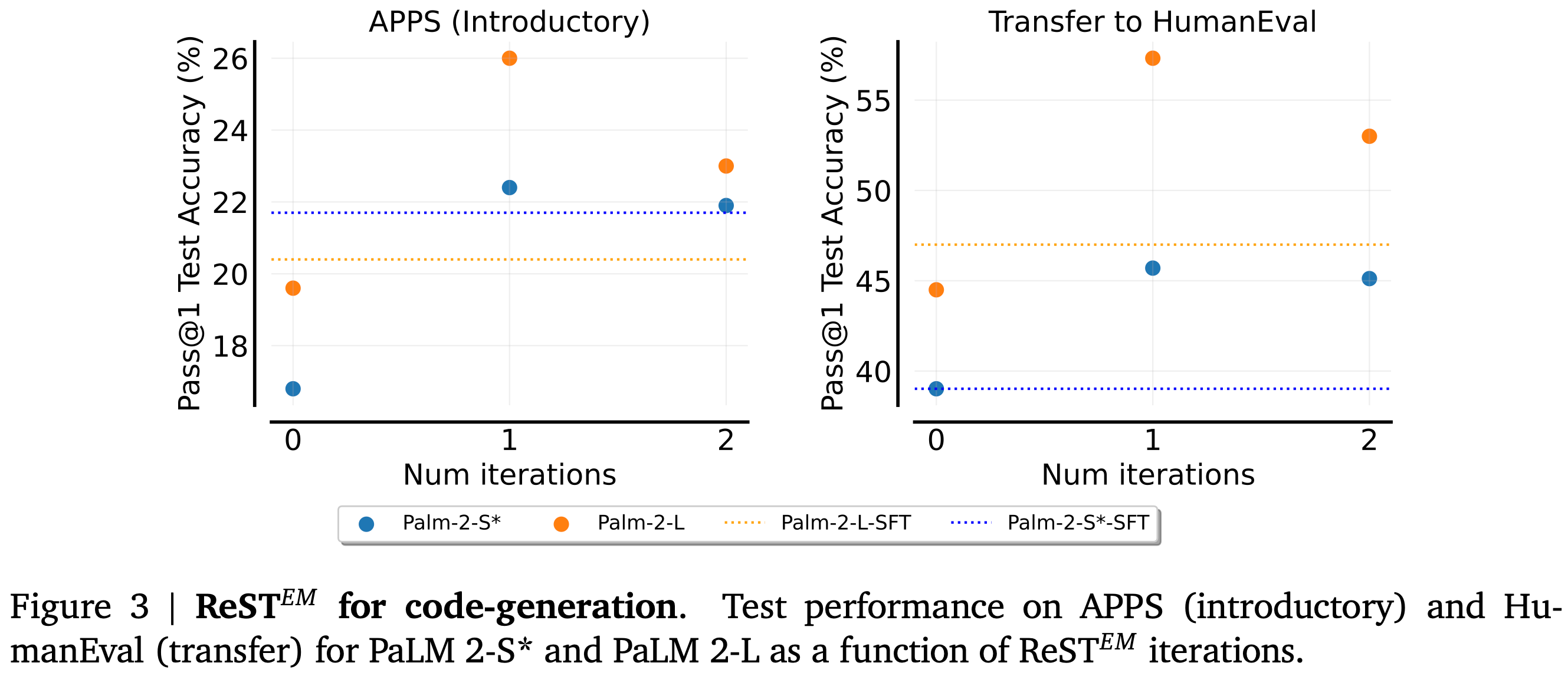
Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models
They propose to alternately sample new data from their model and then finetune the model using the new data, with the finetuning continuing as long as the metrics keep going up on a held-out eval set.

To ensure they’re getting good samples, they:
filter out generations that yield incorrect solutions (doable because they focus on math and coding tasks),
use real problems from the dataset as prompts and only generate solutions,
take at most 10 passing solutions per problem so that easy problems don’t get overrepresented, and
treat the problem as the prompt and the solution as the target sequence, so that they teach the model to generate solutions given problems but not to generate problems.

Despite its simplicity, their method can lift math and coding accuracy significantly if run for 1-3 iterations. Each iteration here includes both sample generation and finetuning.


A Tale of Tails: Model Collapse as a Change of Scaling Laws
Is power law scaling going to go away as more of the world’s text gets generated by LLMs?

First, why would this happen? The problem is that, with a finite number of samples, you end up losing the tails of your distribution (illustrated below with original Wikipedia vs samples from a model trained on Wikipedia).

They study this problem both in theory and practice, and arrive at a mix of good and bad news. As they show in a simplified model:
If the tail of the training distribution gets narrowed, you end up with test error that saturates instead of going down (left).
If you feed a model’s generations back into it multiple times, you get additive degradation in the test error proportional to the number of cycles of self-consumption (middle).
If you include even a little bit of real data in the training distribution, so that the tails just get downscaled and not cut off completely, you end up with a long plateau followed by a scaling exponent that looks like the one you’d get on the original data (right).

The results on real LLMs aren’t quite as clean, but do show similar sorts of degradation.

Especially interesting is their demonstration that having just 2% of the data come from the non-AI-generated distribution can significantly (though not completely) mitigate the damage for a LLaMA 2 model.

Besides the above, they have a bunch of theorems characterizing all of this behavior much more precisely.
What I’m most curious about regarding AI-generated data contamination is the extent to which this is best understood as a technical problem vs a linguistic non-problem.
Like, if I grow up with 80% of what I read generated by LLMs, is it wrong for new LLMs to match that distribution? If this new distribution is now what I think of as natural, why should models seek to replicate some other “clean” distribution? Plus, given how poorly written a lot of content on the internet is compared to LLM outputs, is having more of the latter a bad thing?
On the other hand, having a few LLMs generate a huge share of the world’s text gives a small number of companies + data annotators disproportionate power over common language. This might grant them influence in other ways too.
So depending on how it all plays out, the increasing prevalence of LLM-generated text could simply be a case of linguistic evolution. Like the emergence of new slang with each generation, it might be neither good nor bad, but just different.
Language models scale reliably with over-training and on downstream tasks
The Chinchilla scaling curves suggest you should train your model with a token to parameter ratio around 20. What happens if you use a larger number?

They show that, whatever ratio you use, you still get a power law with the same exponent as optimal scaling; using a sub-optimal token to parameter ratio only worsens the leading constants. Or at least this holds when the token and parameter scaling exponents are the same, as happens in practice.


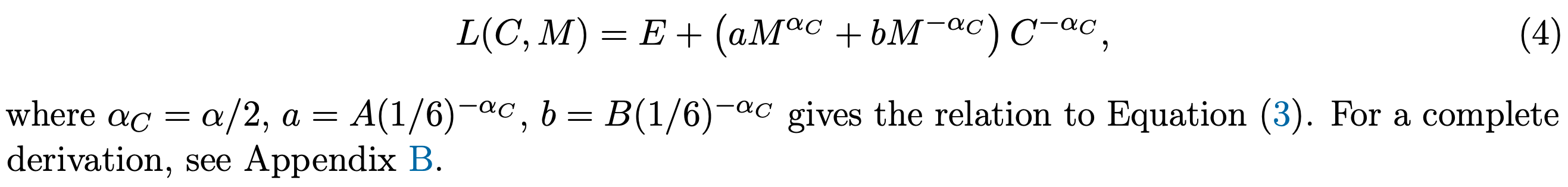
Empirically, they also observe that there’s an exponential relationship between accuracy on downstream tasks and the validation loss typically described by power laws.

You can plug these relationships together to get an exponentially decaying scaling curve for downstream error rate. They fit the decay constant, initial error, and final error parameters to observed error rates.

Fitting these curves lets them accurately predict the downstream error rates of larger models and training budgets.

Note that the error rates they’re predicting are averages across various downstream tasks. Individual tasks can be high-variance.

A really thorough and practically relevant study. I’d never worked through the math for the scaling exponents at different token to parameter ratios, so it’s interesting to see that it’s just naturally the same with no assumptions needed on top of the standard power law scaling formula. As far as the part about curve fitting eval suite averages and extrapolating…I’ll just say I’m unusually confident these findings will replicate.
No "Zero-Shot" Without Exponential Data: Pretraining Concept Frequency Determines Multimodal Model Performance
Let’s say you have a pretrained image + text model and you ask it to classify some new images with no finetuning or in-context examples—i.e., you do zero-shot classification. If it works well, is this because the model “generalized” really well to these novel classes, or because it actually just saw a ton of examples of these classes during pretraining?
To answer this question, we need some generalization of “classes” that works across different datasets and tasks. Our generalization will be “concepts,” where concepts are nouns that show up anywhere in the pretraining data and at least five times in the eval set.

It turns out that, across a ton of models, downstream datasets, and tasks, there’s a clear log-linear relationship between how many times the concept shows up in image-text pairs during pretraining and how well the model does on the downstream task. That is, you need a multiplicative increase in pretraining concept frequency to get an additive increase in downstream metrics.

This log-linear trend holds even when you filter out the samples in the pretraining data that are most similar to the downstream samples (left) and when you artificially mess with the pretraining concept distribution so that it differs from the downstream concept distribution (right).

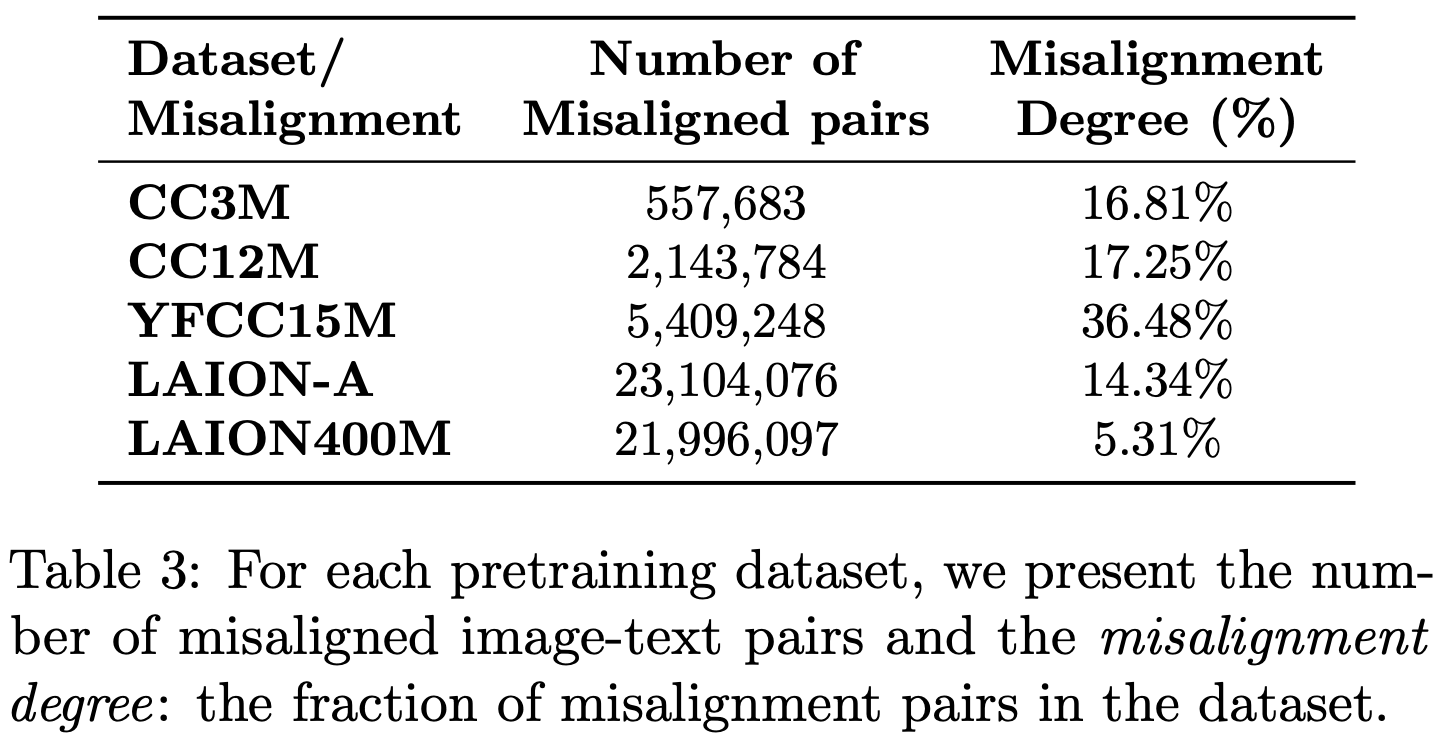
Since they have rich concept annotations for tons of image-text pairs across a variety of datasets, they also do some exploratory data analysis. First, they find that a ton of image-text pairs are “misaligned” in common datasets, as defined by having no shared concepts in the image and text.
They also find that the concept distributions across different datasets are correlated. YFCC15M is especially similar to everything else.

Finally, they create a dataset (“Let it Wag!”) from the image-text pairs corresponding to the rarest concepts and evaluate how well various models do on it. Short answer: not so well.

While the results of this paper are scoped to image-text models, this makes me super curious whether this log-linear relationship holds for text and other models. If so:
It makes LLM “zero-shot” results seem much less impressive
It makes LLM zero-shot efficacy more predictable a priori
It bodes well for the de facto strategy of various model providers: avoid the need for out-of-distribution generalization by just training on everything ever, so that everything is in-distribution.
But even if this result doesn’t generalize to other model and data types, it’s still super interesting. We usually see power law relationships in deep learning, in which a multiplicative change in input gets you a multiplicative change in output. Seeing instead an additive change in output is surprising, and I’d love to know what the root cause of this is.
> While the results of this paper are scoped to image-text models, this makes me super curious whether this log-linear relationship holds for text and other models.
You may be interested in Kandpal et al., which this paper cites but does not thoroughly discuss. https://proceedings.mlr.press/v202/kandpal23a/kandpal23a.pdf
You may also be interested in https://arxiv.org/abs/2404.01413 regarding
> Especially interesting is their demonstration that having just 2% of the data come from the non-AI-generated distribution can significantly (though not completely) mitigate the damage for a LLaMA 2 model.