
2022-3-5 arXiv roundup: 5-bit training, What pretraining data to use, Expanding training sets via ML

This newsletter made possible by MosaicML (look at our shiny new website).
Full Stack Optimization of Transformer Inference: a Survey
Besides having a ton of links to relevant papers like most surveys, this paper also does a lot of profiling of transformer inference as a workload.
E.g., here’s how the number of FLOPs and memory ops vary with sequence length for different architectures. “Memory ops” is defined as the number of bytes accessed.

Similarly, here’s how the arithmetic intensity varies with sequence length. Up to ~512 tokens, the individual attention heads and other ops are getting larger, improving utilization. But past that point, the attention matrix gets too big relative to everything else, and the memory-bound ops like softmax start to become bottlenecks.

Here’s a more detailed breakdown by module:

And a more detailed breakdown by operation:

The above are all hardware-agnostic metrics. Below is how much latency the different operations add on a CPU. For BERT-Base, activation-activation products (in attention) start to dominate around a sequence length of 2048. For GPT-2, attention only takes about half the total time even at a sequence length of 4096.

If you look at raw times rather than percent breakdowns, you see that GPT-2 is way slower than BERT. This is presumably because of serial decoding.

When you quantize the weights, you get large energy and die area savings. Addition ops seem to take energy and area proportional to the bitwidth, while multiplication ops ramp up superlinearly with bitwidth. Multiplies are >5x more expensive than adds even at small bitwidths. SRAM (cache) reads are a bit more expensive than even 32-bit multiplies, and DRAM (memory) reads are 100x more expensive than anything else.

Similarly, fusing different operations usually improves latency.

However, fusion sometimes hurts at large sequence lengths. The added tiling/scheduling constraints it imposes aren’t always worth it.

Switching gears, they spend a fair amount of time discussing accelerators and sweeping how different design parameters can affect latency. Among other findings, devoting less area to scratchpad and more to accumulators seems to help vs their baseline configuration.

When exploring the design space of matmul and convolution implementations, they find that the best loop ordering, tiling, etc. can get you way lower energy-delay product (EDP) than random configurations.

There’s a lot of content in this paper, and it’s worth a careful read if you care about transformer inference latency or deep learning hardware.
The Role of Pre-training Data in Transfer Learning
They did a ton of different experiments regarding how you should pretrain and finetune vision models.
One big finding is that which pretraining dataset you use matters less and less as the size of the finetuning dataset increases.

This holds not just in aggregate, but fairly consistently within individual tasks.
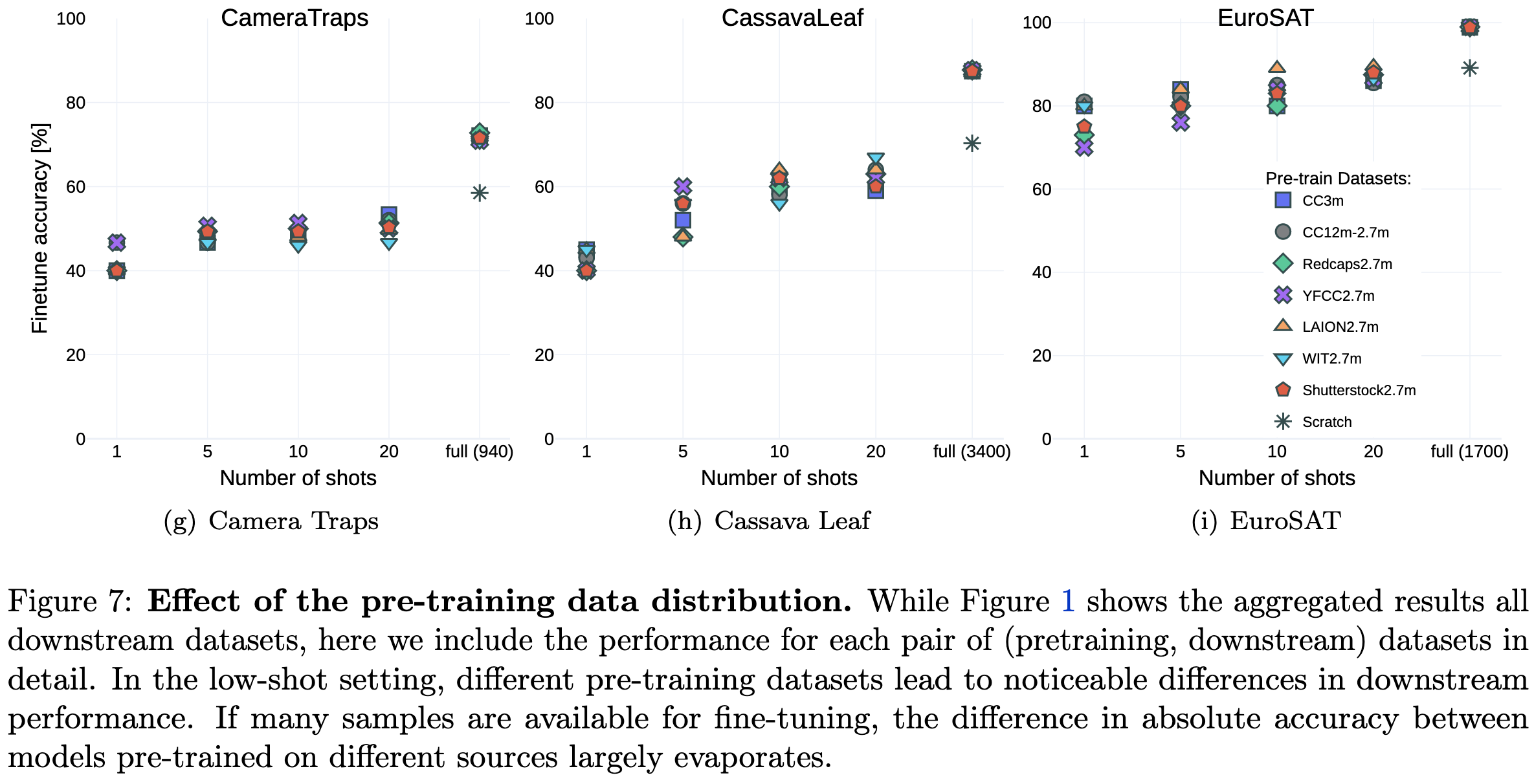
These diminishing returns also hold when pretraining with SimCLR rather than CLIP.

Although SimCLR pretraining seems to work better than CLIP at a given number of pretraining and finetuning samples.

Even the worst pretraining dataset still helps compared to just training from scratch on a smaller downstream dataset.

Supervised pretraining on clean-ish labels usually yields the best finetuned accuracy. Though contrastive pretraining with captions derived from these clean-ish labels does almost as well, or occasionally a little better. Contrastive pretraining on image-caption pairs scraped from the internet isn’t nearly as effective as supervised training when holding pretraining dataset size constant.

If you increase the size of the noisy image-caption dataset though, you sometimes do as well as using cleaner labels, or even better. It depends on the downstream dataset.

More generally, having a larger pretraining corpus tends to help in the few-shot regime, but not matter much when doing full finetuning.

A super thorough paper I’ll probably come back to whenever I think about pretraining.
ChatAug: Leveraging ChatGPT for Text Data Augmentation
Can you use ChatGPT paraphrasing to augment your training data for text tasks?

Yes. In fact, it seems to work a lot better than existing data augmentation approaches.


This might be because the ChatGPT-generated sequences tend to be exceptionally similar to the original data—although the correlation isn’t perfect.

More evidence that using language models to generate data for language models works.
Decoupling the All-Reduce Primitive for Accelerating Distributed Deep Learning
They fix something that’s always bothered me about data-parallel training using a clever observation.
The part that bothers me is that we stuff all the communication into the backward pass, despite having plenty of time in the forward pass before most of the gradients are needed. E.g., we’re syncing the last layer’s gradients at the start of backward, even though we don’t need the last layer’s new weights until the very end of the next forward.
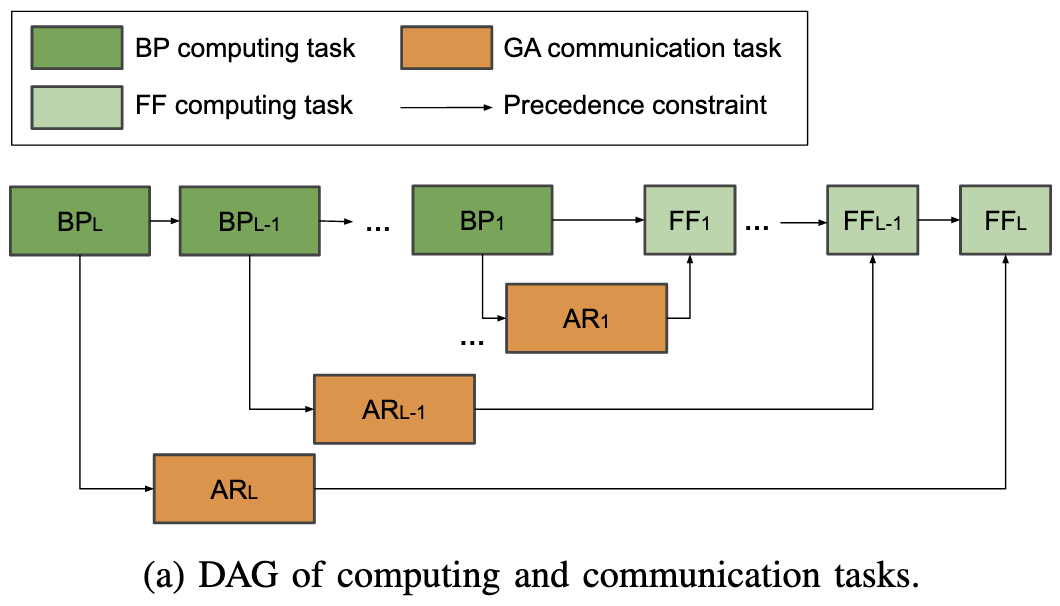
The way they fix this is by splitting the gradient allreduce into separate reduce-scatter and all-gather ops. They eagerly schedule the reduce-scatters in backward, but try to schedule the all-gathers after those complete in the order the layers are used and, if necessary, during the forward pass.

They also coalesce the gradient tensors from adjacent layers until they reach a certain size in order to maximize communication throughput. They use bayesian optimization to tune this size.

Other than the intelligent buffer sizes / tensor fusion, this approach is probably not too complicated (a good thing).

With slow enough interconnect, their method can speed up training 10%-25% vs vanilla PyTorch DDP.

We don’t have this idle communication time when using fancier forms of parallelism, but this intelligent scheduling makes a lot of sense for pure data-parallel training.
MUX-PLMs: Pre-training Language Models with Data Multiplexing
They do something kind of crazy: they fuse multiple inputs into a single input, then split the output up into separate predictions for each input. They actually introduced this idea in their previous paper, and this one just extends it to work when pretraining BERT variants.

To make this work, they add more sophisticated multiplexing and demultiplexing modules to the model.

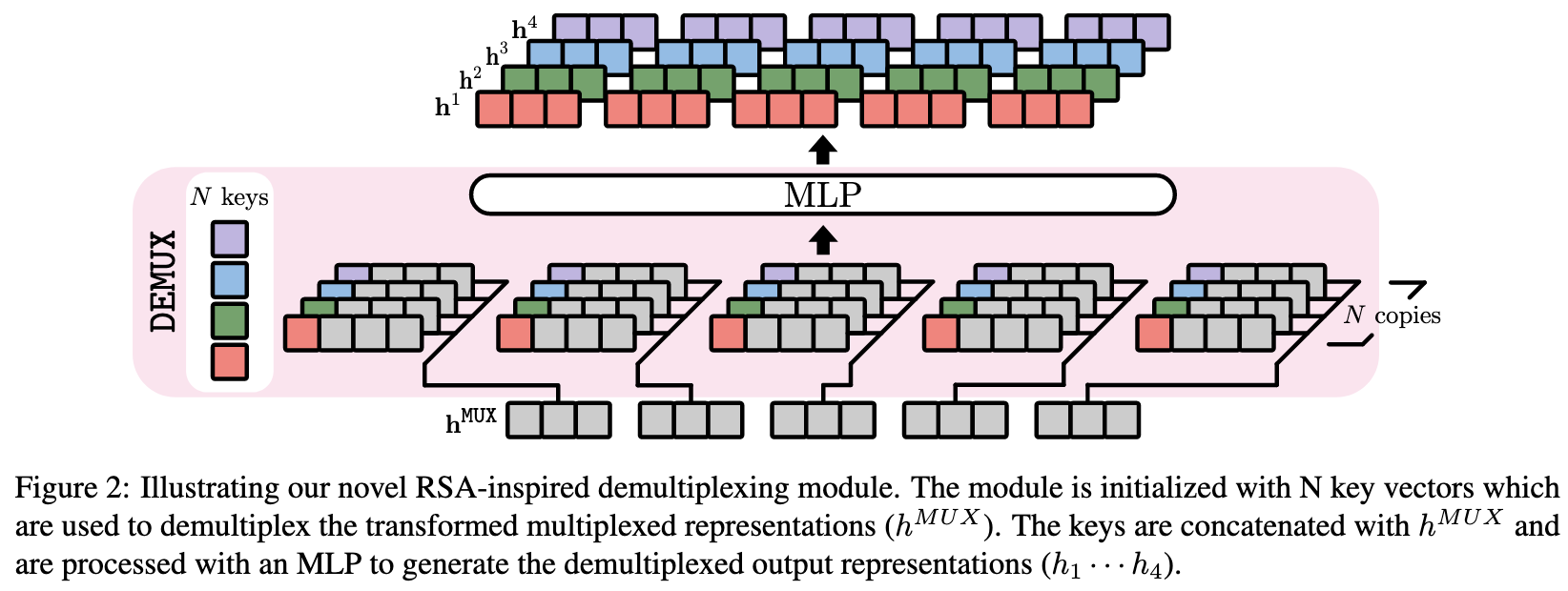
They also use a three-stage training process. The latter two stages are pretraining and finetuning, but the first is a “token retrieval” task that basically teaches the network to multiplex and demultiplex.

Multiplexed models end up on or near the speed vs accuracy Pareto frontier when compared to just using a smaller model.

Definitely interesting—data multiplexing is one of the crazier ideas in deep learning right now, which is a good thing. Methods that are weird and different teach us far more than slight tweaks to existing approaches do.
Do Machine Learning Models Learn Common Sense?
They generate “common sense rules” algorithmically from datasets.

These rules can help you understand your data or model. E.g., your object detector probably shouldn’t predict that the back of a car is 3x wider than it is tall.

The rules they generate are based on quantiles of various statistics. You kind of have to define the available statistics (e.g., “aspect ratio”), though you can also just use features directly (e.g., the “height” column in a tabular dataset).

You can also use violations of these rules to finetune a model without any labels. You train it to only violate the rules about as much as you’d expect from the training set, instead of way more.

Seems useful—machine learning pipelines are always desperate for tests, and anything that can give us sensible logical predicates is great on that front.
Why (and When) does Local SGD Generalize Better than SGD?
Performing model updates locally and only averaging across workers sometimes acts as a form of regularization. When you need more regularization due to low learning rate and long training duration, this can improve accuracy.

Benchmarking Deepart Detection
They built a dataset of human- and AI-generated images so you can benchmark AI art detection methods.

They use this dataset to benchmark various detection methods, including a couple they propose.

Various methods are getting >50% accuracy even with this small dataset, so it might be possible to get much higher accuracy with more data.
Internet Explorer: Targeted Representation Learning on the Open Web
They automatically find more task-relevant training images from the internet without any labels.

To do this, they maintain a distribution over WordNet concepts and iteratively query Google image search for the top 100 results for a given concept. They then use self-supervised learning to update a model on the retrieved data, and finally update their query distribution based on which images seemed similar to the known training set.

They define similar based on cosine similarity to the 15 nearest neighbors, since that seems to work better than using the SSL loss or 1nn.

Updating the query distribution involves some heuristic grouping and thresholding of the raw probability distribution.

The whole procedure looks like this:

As you’d hope, it does seem to retrieve increasingly relevant images across iterations.

You can even quantify this improvement by looking at the cosine similarities of retrieved images with the training images. Interestingly, it sometimes diminishes past ~10 iterations if they don’t use GPT-J to tweak their queries each time (“ours++”). Maybe this is because they’re just retrieving the same images repeatedly for a given WordNet concept?

Using the resulting augmented dataset can get you a much better model. This is especially true if you search for the labels themselves sometimes instead of the WordNet concepts.

Another example of using machine learning to get more training data—though this time it’s finding existing examples rather than generating them. They also have a good website and YouTube video.
Dropout Reduces Underfitting
They argue that you should do dropout early in training when the model is underfitting and late in training when the model is overfitting.

They provide some evidence for this on ImageNet.


You do need to tune the hparams properly, but there’s a fairly wide range of values that still help.


Looks like early/late dropout might be easy wins in a lot of cases.
Ultra-low Precision Multiplication-free Training for Deep Neural Networks
They got 5-bit training-from-scratch working with <1% accuracy loss. Their format is fp1-4-0 (1 sign bit, 4 exponent bits, 0 mantissa bits) for the gradients, weights, and activations, and their accumulators are 32-bit ints with separate floating point scale factors.

This format is nice because you can store the values as separate arrays of sign bits and 4bit ints, with multiplication consisting for XOR for the sign bit and addition for the ints.
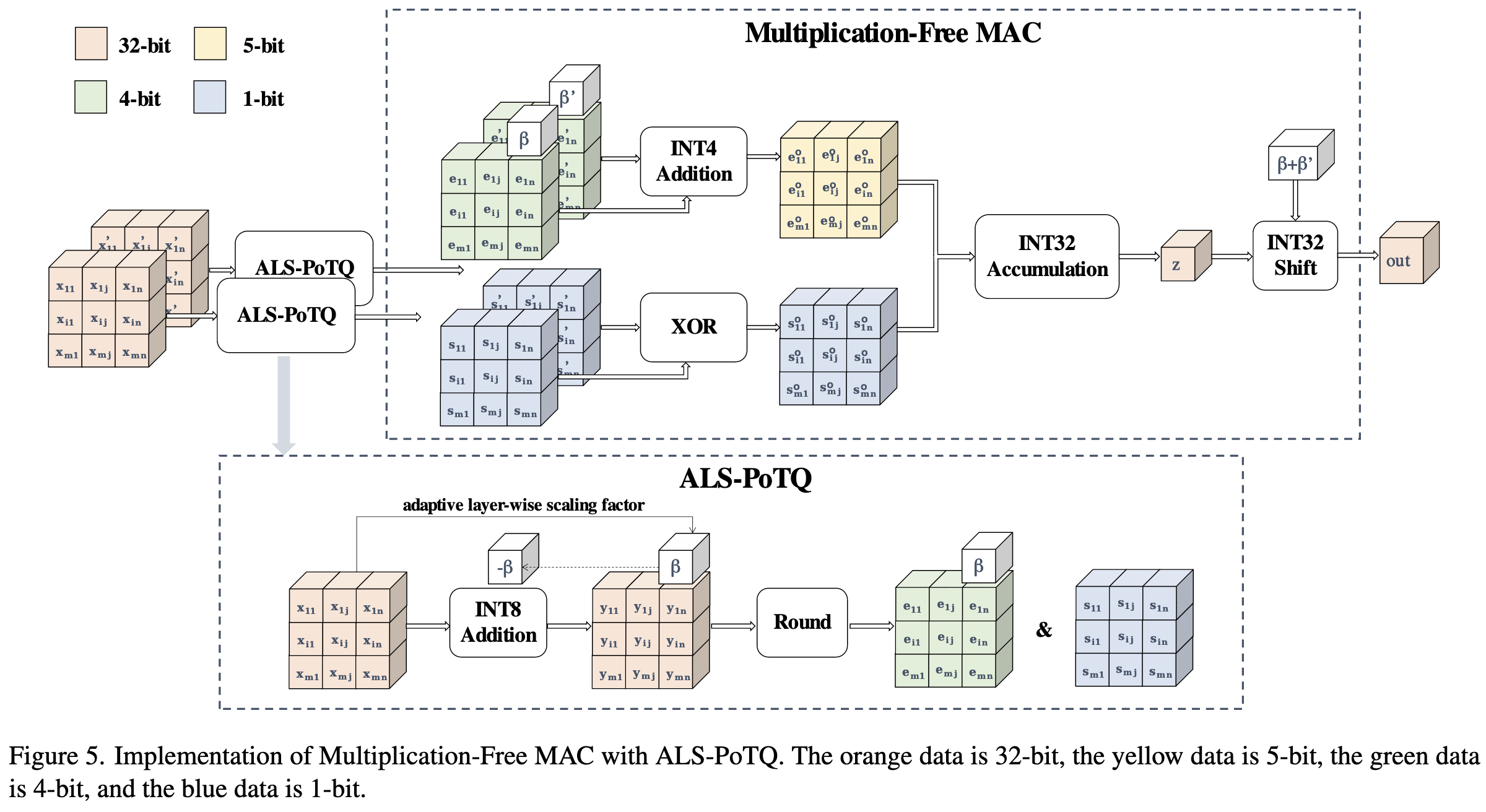
There are three components to get training with this data type to work. First is power-of-two (PoT) quantization, meaning they round values to the nearest power of 2.

Before applying this quantization, they first scale the tensor based on its largest value (below, F is a set of 32-bit floats and b is the bitwidth). This scale factor is rounded to the nearest power of two to avoid floating-point multiplies during quantization.

The second component is mean-normalizing all the weights. This seems to be within a tensor, and takes place before the quantization.

The third component is clipping the largest activations according to some hyperparameter.

Putting it all together, it looks like this:

These are really good accuracy results. I wasn’t sure it was possible to get <1% accuracy loss vs a strong ResNet-50 ImageNet baseline with everything in 5-bit precision.

Apart from image classification, they also get minimal BLEU loss for machine translation:

A lot of the accuracy seems to come from ensuring the weights are zero-mean, at least when the more aggressive clipping is enabled. Each component seems to help though. (It’s not clear what 12.0/74.2 means).

Also, their histograms of weight and activation distributions offered an interesting insight. At first, it looked to me like their quantization had distorted the weight distribution, making it bimodal instead of unimodal (lower left vs upper left).

But what’s actually happening here is that the density of quantization bins increases exponentially as we approach 0—so the frequency of weights ending up in a given bin diminishes, even though the density of small weights increases. This suggests that quantization error in the smallest bins might matter less than I’d previously thought.
Overall, these are pretty amazing results. And according to Appendix D, they got them without fidgeting with the hparams except for using 6 bits instead of 5 for the final layer. You always need to be skeptical of awesome results until you see them reproduced a couple times1, but this, LUQ, and this Qualcomm paper together suggest that 4 or 5-bit training to nearly full accuracy might be a real thing.
A paper recently won best paper at a top ML conference on the basis of its claimed 2x training speedup at the same accuracy. Turns out it’s no faster at all when you microbenchmark it, and the “speedup” is entirely from the baseline model being a slow HuggingFace implementation vs their method being inserted into a fast NVIDIA implementation. Science is hard and independent reproductions are vital.