
2023-1-15 arXiv roundup: Way faster BERT, Mechanistic interpretability

This newsletter made possible by MosaicML.
Progress measures for grokking via mechanistic interpretability
This paper is a win for mechanistic interpretability. If you haven’t heard that phrase, it means understanding the exact logic a model uses to map inputs to outputs.
In this case, they focus on a small transformer trained to do modular addition and find that it uses a particular algorithm to solve the problem. Namely, it turns each number into an angle, adds the angles via rotation, and then converts back to one-hot-encoded integers.
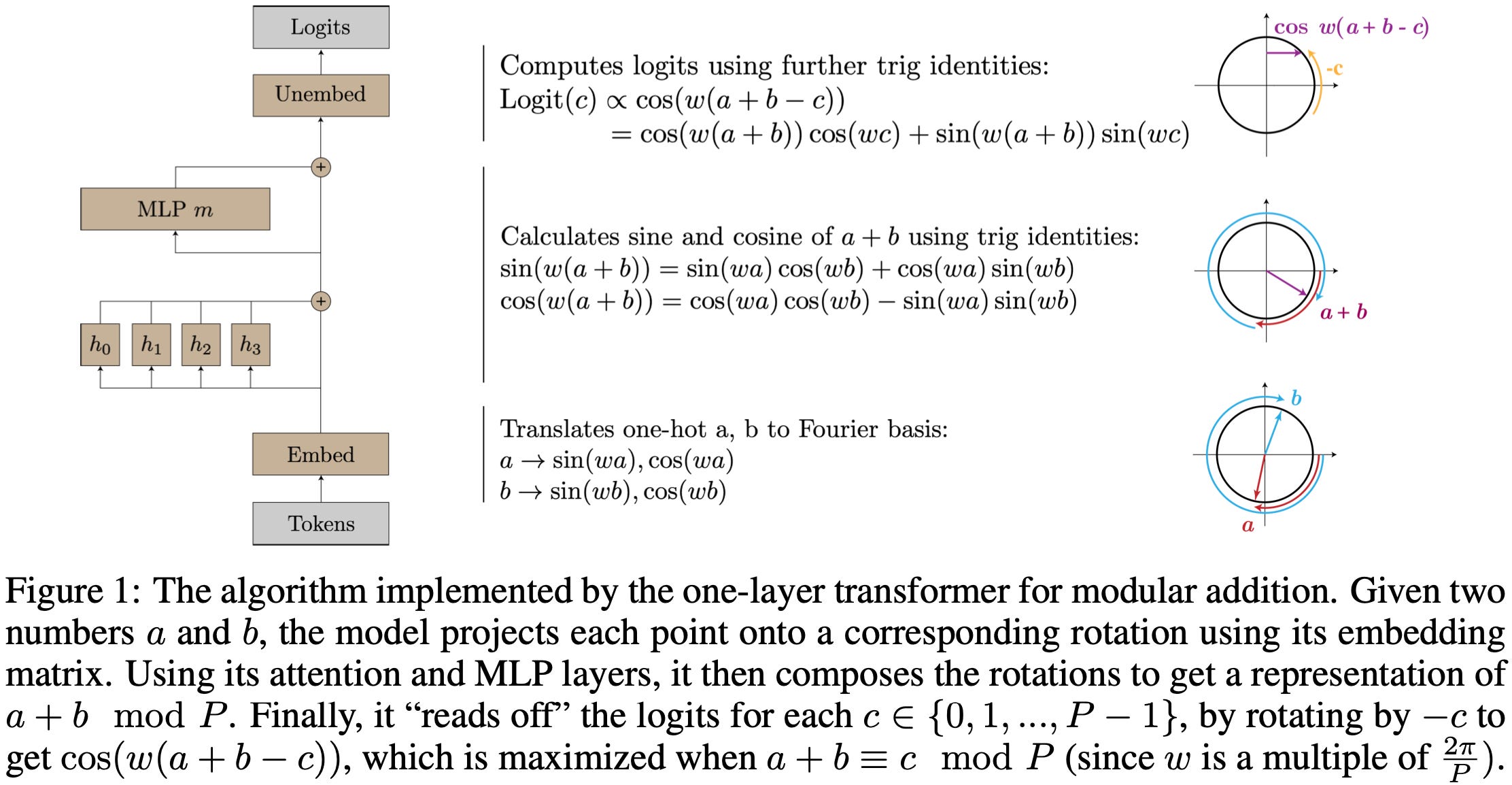
They can tell this is what’s going on because this algorithm has a simple formula for the weights, and what the formula says closely matches the empirical weights.
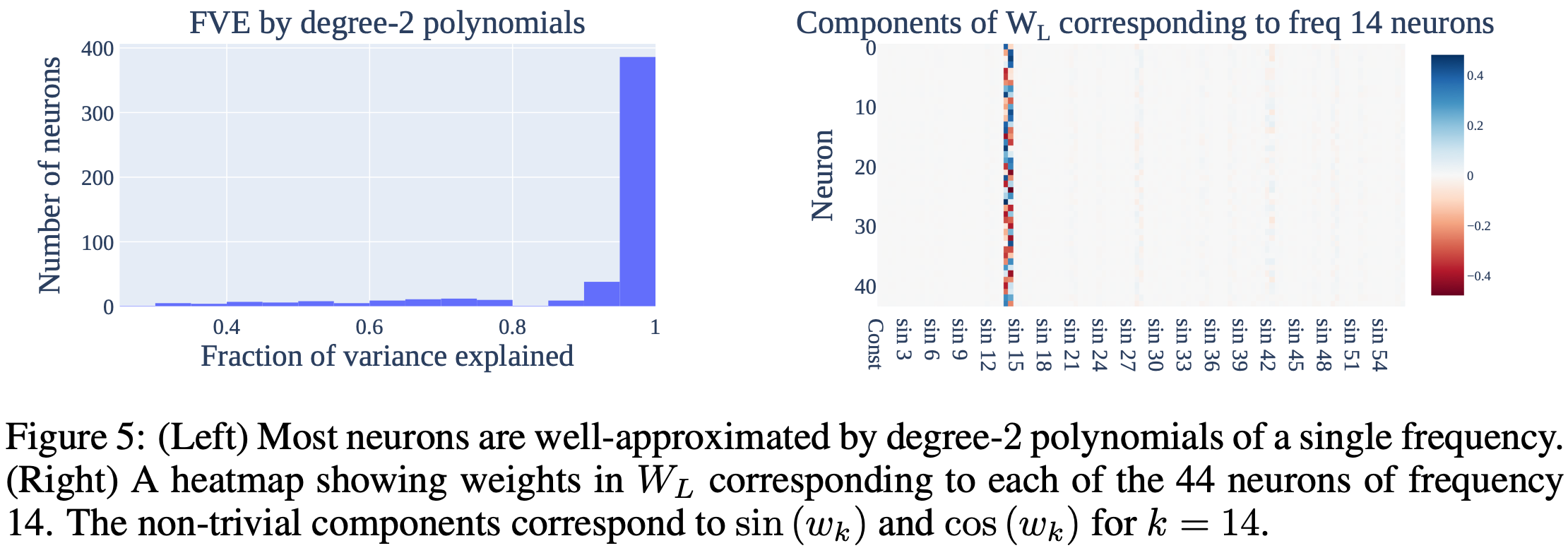

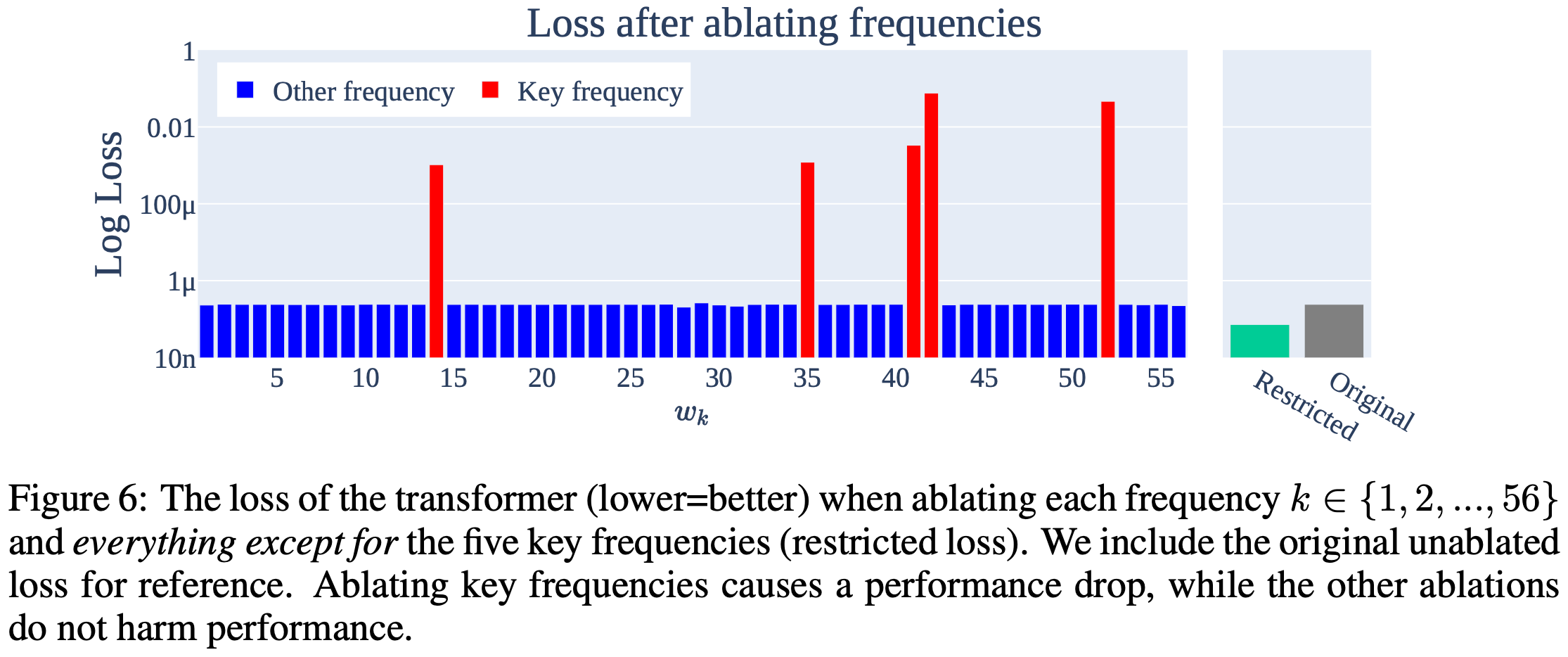
You can also spike the loss by removing the neurons that the formula predicts should matter the most.
As a somewhat separate thread, they find that this setup yields grokking—a sudden drop in eval loss way after the training loss plateaus.
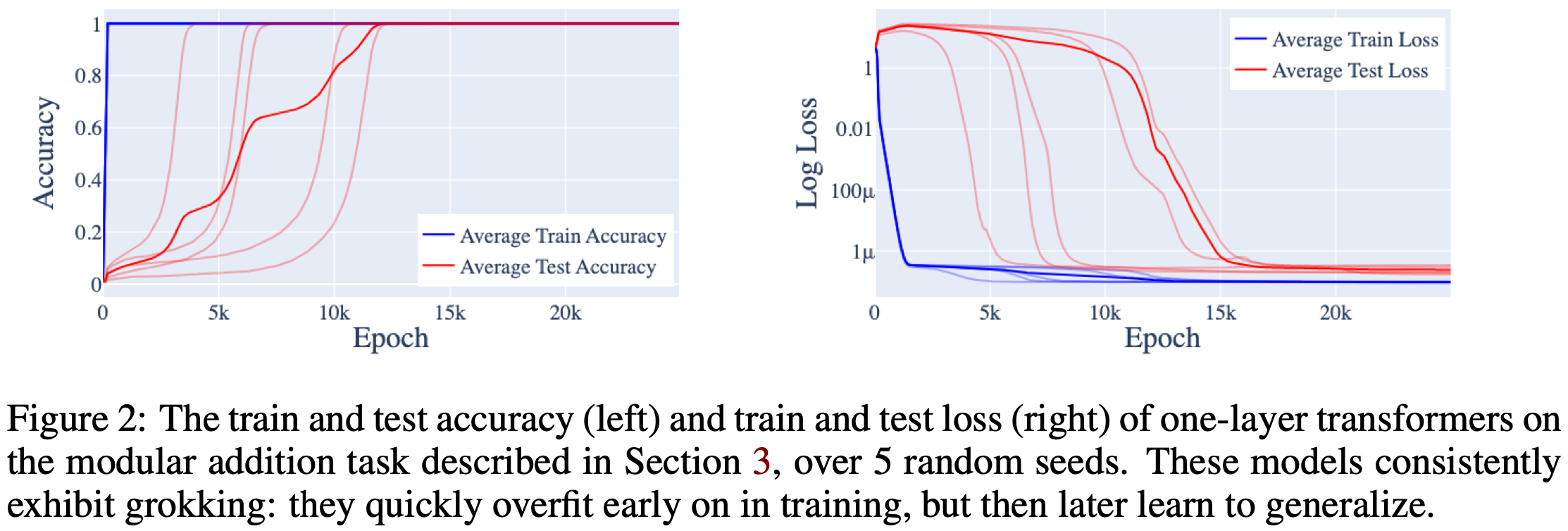
Consistent with other work, they find that grokking only happens when there’s weight decay or other regularization, and that less weight decay makes grokking take longer. They further find that grokking only happens when there’s not much training data.
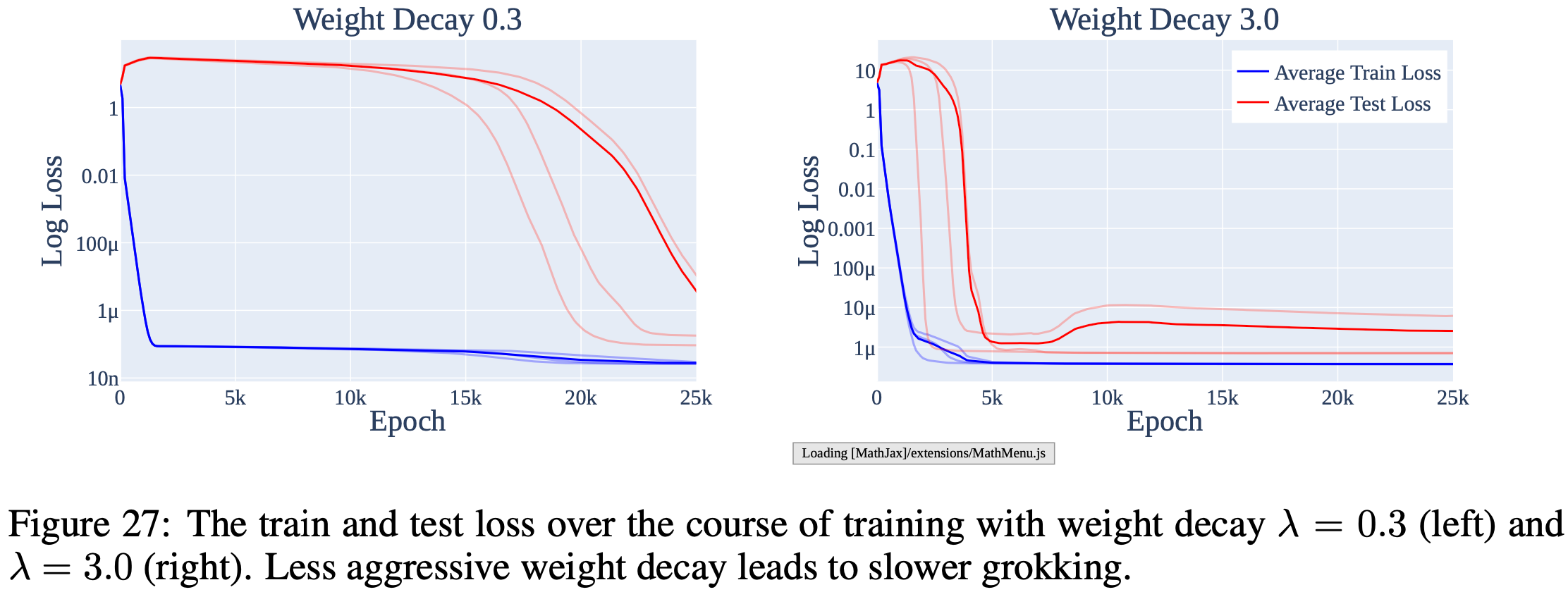
This paper makes me feel more optimistic about mechanistic interpretability. This was still a toy problem, but seeing a network naturally implement a non-trivial algorithm is reassuring and suggests we might be able to uncover more complex algorithms in more realistic models.
I’m more excited about the reverse direction though. Like, using a transformer is an incredibly inefficient and inaccurate way of implementing modular addition. Can we identify what algorithmic building blocks our models need and just bake those in directly? I know people have tried adding a calculator to help with math, but the idea seems more general—e.g., maybe we should help our networks with input deduplication?
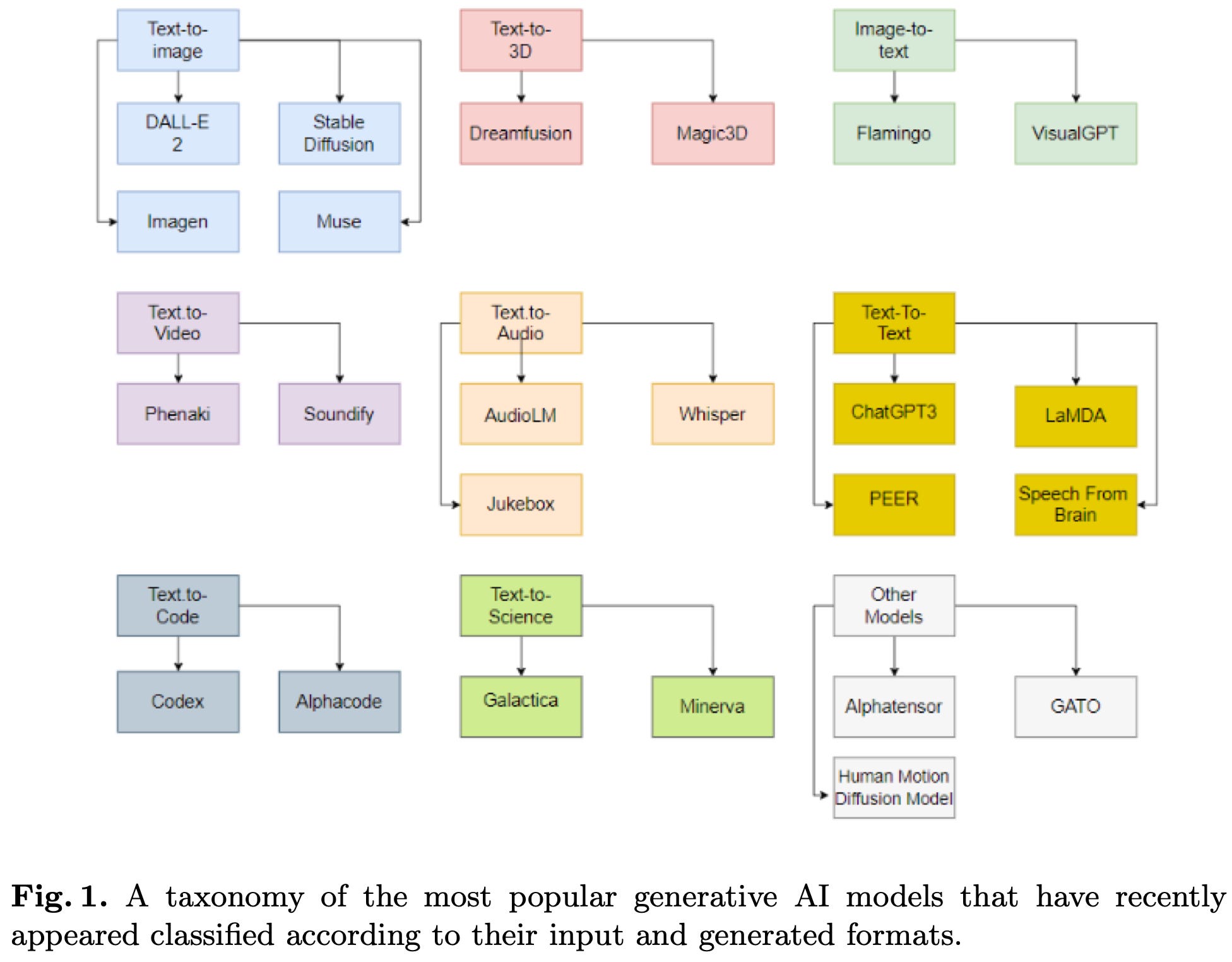
ChatGPT is not all you need. A State of the Art Review of large Generative AI models
A good overview of big generative models. This figure is a super valuable summary:
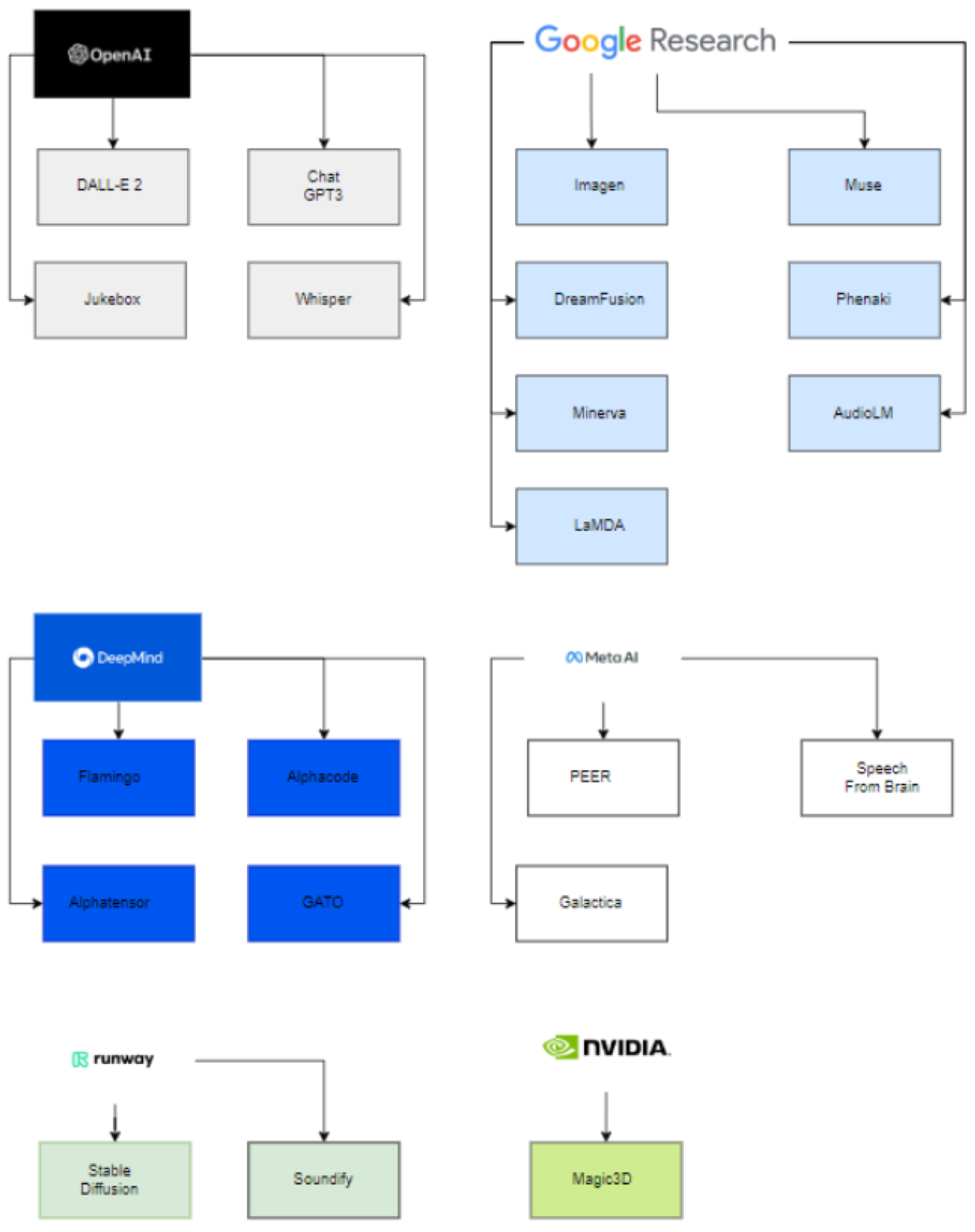
Here’s a different version where the models are grouped by company.
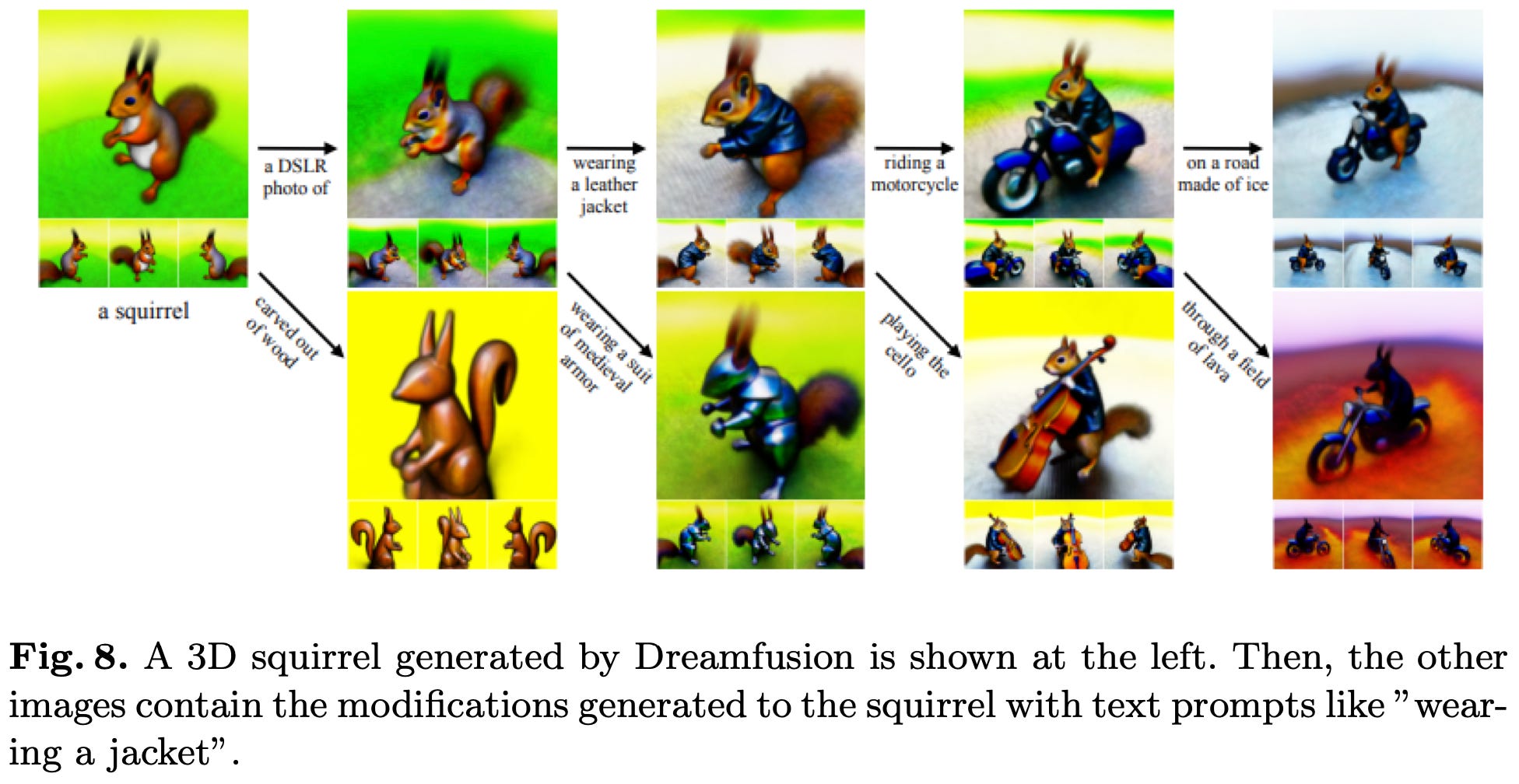
They also have a lot of figures comparing results across different models.

This feels like a great paper to forward to someone who’s curious about the space but hasn’t really followed it. I could see a lot of this content making the rounds on Twitter, LinkedIn, etc.
Improving Inference Performance of Machine Learning with the Divide-and-Conquer Principle
Many inference tasks, like optical character recognition, require different amounts of work for different inputs and/or stages of processing. E.g., OCR pipelines detect bounding boxes that might contain text, classify them as actually containing text or not, and then read the text in the chosen boxes. There can be a ton of load imbalance because different images can have different amounts of text on them.
They propose allocating threads to inputs and stages dynamically and in proportion to expected load when doing CPU inference.
Concretely, they add a parallel run (“prun”) function to the ONNX runtime that takes in a list of inputs to do inference on and returns a list of outputs—rather than the normal pattern of mapping inputs to outputs one sample or batch at a time. Under the hood, this function will, e.g., allocate an equal number of bounding boxes to each thread.
As you might expect, this can improve inference latency once you have a lot of threads to load balance across.
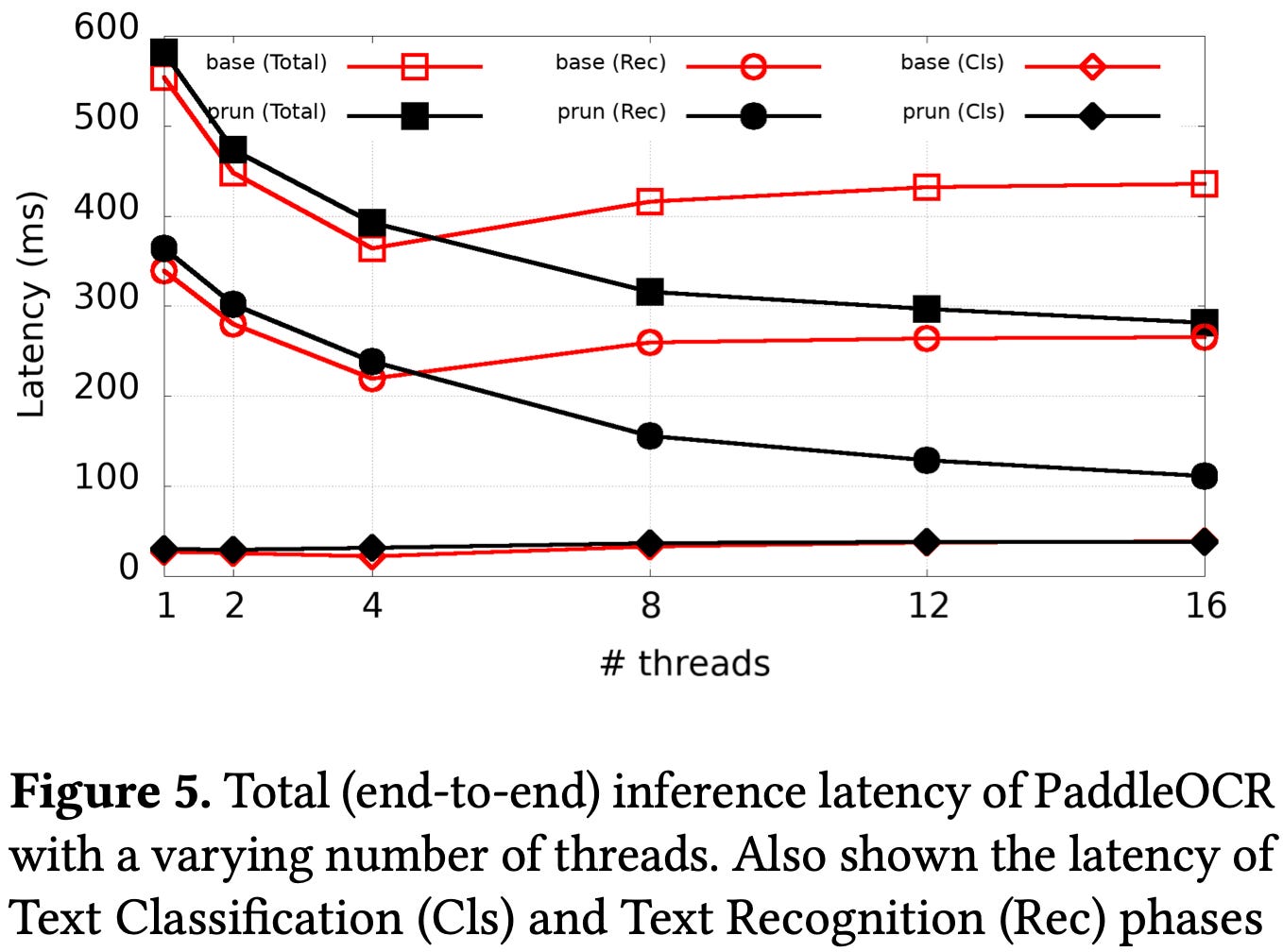
Another perk of this approach is that it makes inference on variable-length sequences easy—you can omit padding and still get good utilization, since longer sequences get assigned more threads.
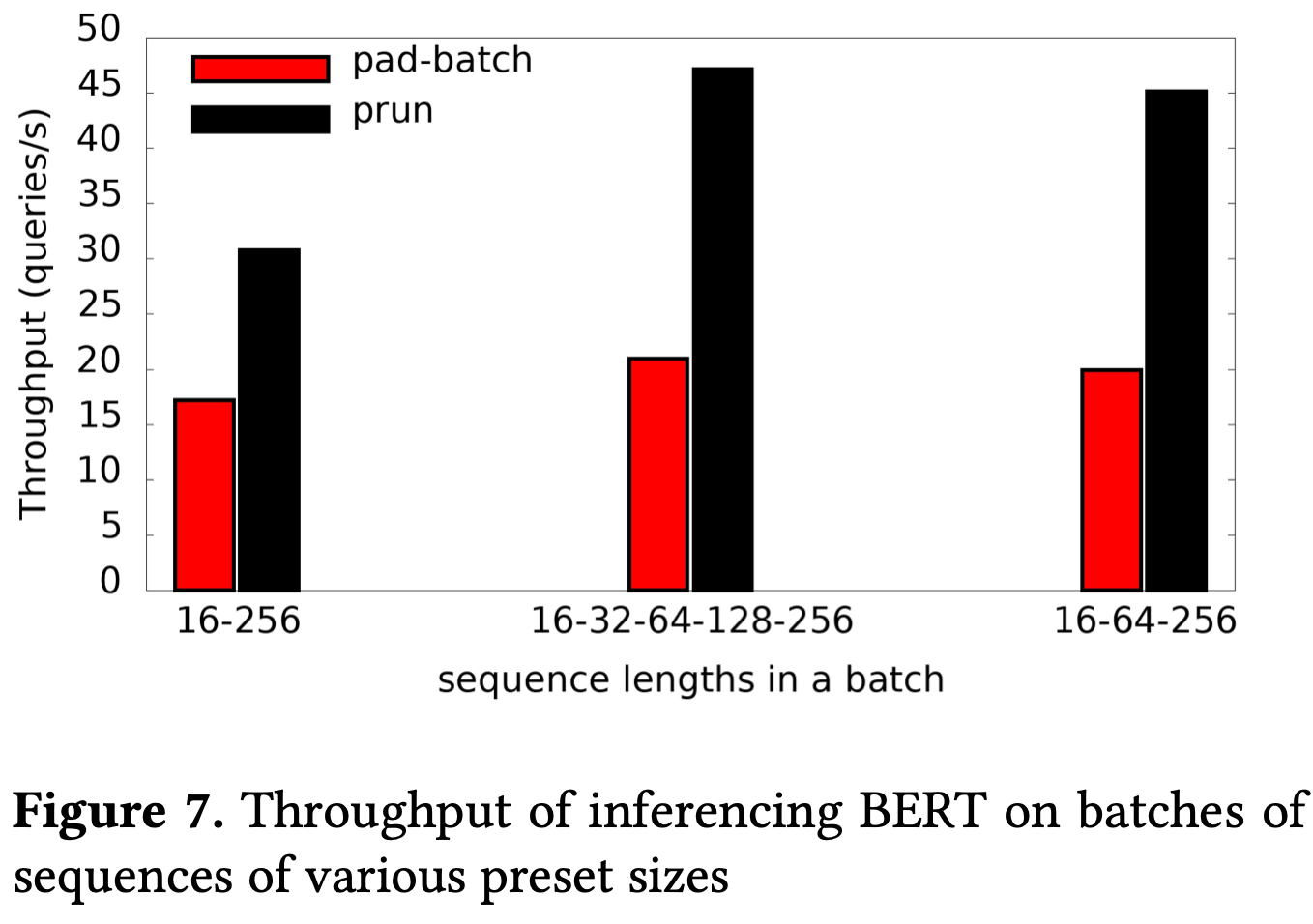
What I found surprising is that this approach of running on each input separately outperforms batching. And it does so even when the sequences are the same length. E.g., having 2 threads for each of 4 input sequences is apparently a bit faster than having all 8 threads tackle one batch of 4 sequences. I’d expect the former to have much worse cache behavior, but it looks like being able to use coarser-level parallelism (e.g., not having to synchronize all threads at the end of each matmul) gets you a win. Definitely curious under what circumstances this holds.
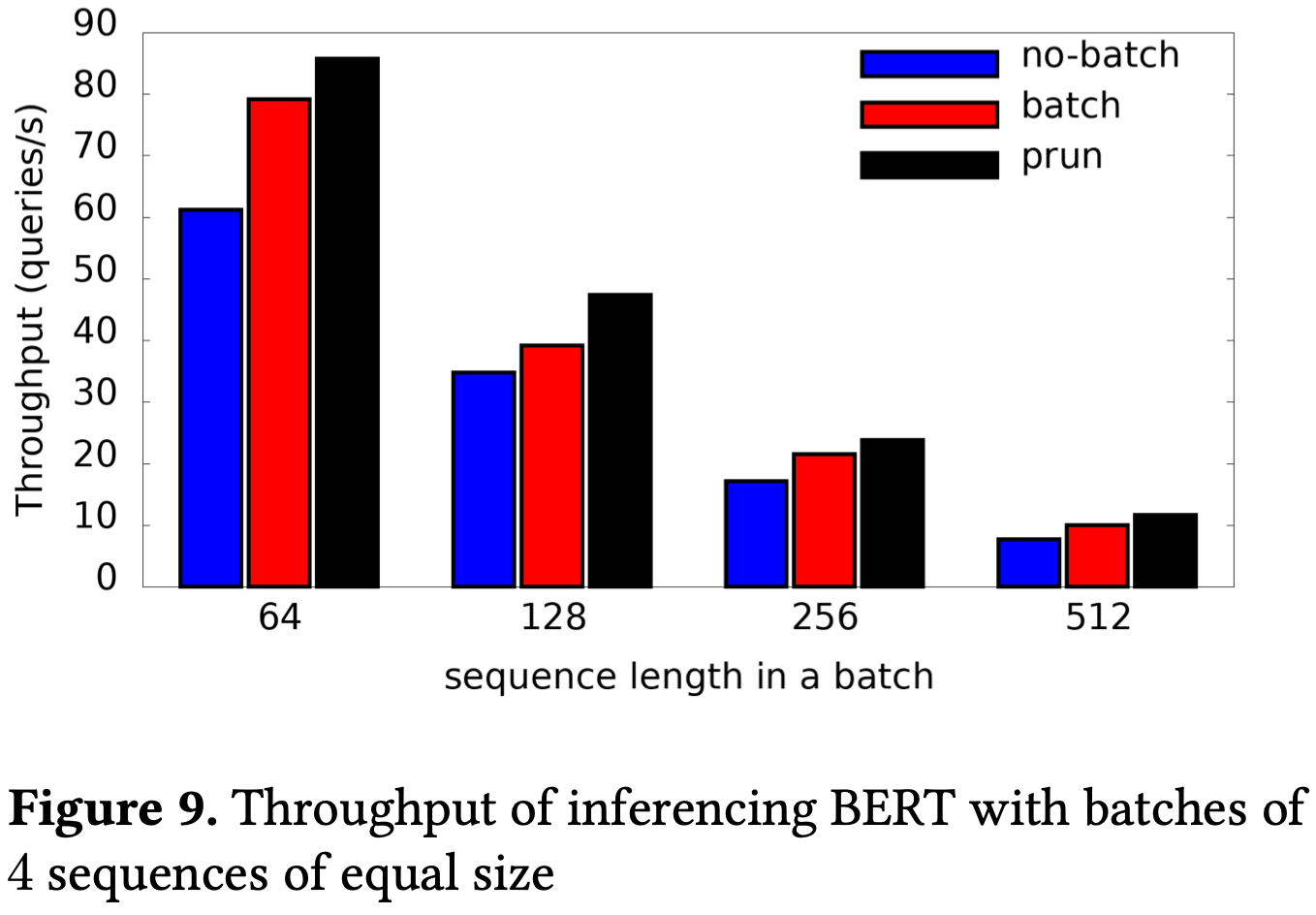
Mostly I like that this paper forced me to think about imbalance in inference workloads in new ways.
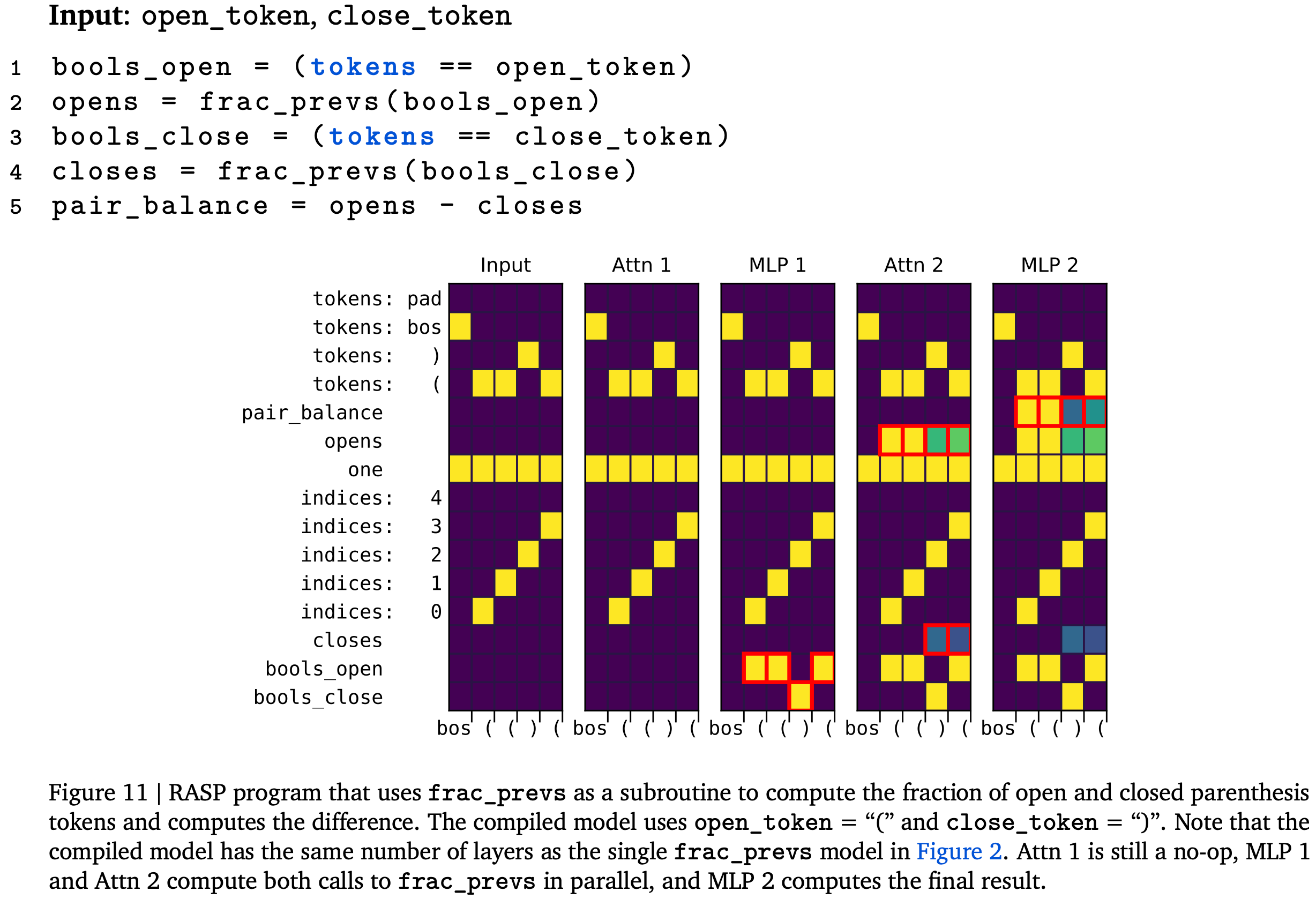
Tracr: Compiled Transformers as a Laboratory for Interpretability
They turn programs written in a certain domain-specific language (DSL) into equivalent transformer models.

The hope is to facilitate mechanistic interpretability research by making it easy to see what a transformer would look like if it actually implemented the algorithm you think it implements.
To get from program to transformer, they follow a few steps. First, they use a simplified parameterization of scaled self-attention. I’m a big fan of this because it’s always bothered me that we have separate query and key projection matrices (rather than the below W_qk matrix, which is equivalent modulo regularization).
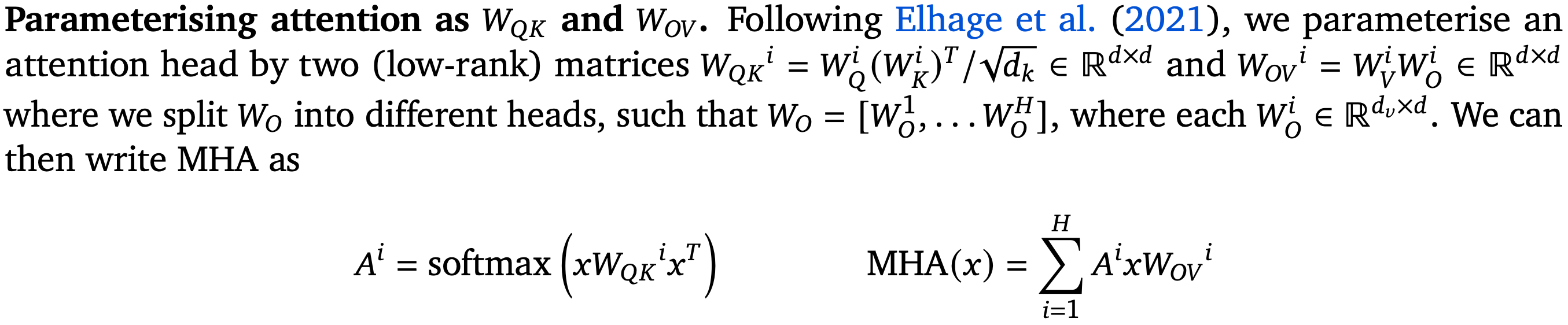
Using this formulation, you can do:
Any elementwise operator using the MLP (thanks to single-hidden-layer MLPs being universal function approximators)
Select-aggregate operations, which do weighted sums of elements in the sequence. This subsumes counting, permuting, replicating, and more as special cases.
There are a couple subtleties that required them to modify the original DSL, but the bulk of the contribution is their pipeline for compiling it all the way to a runnable model.
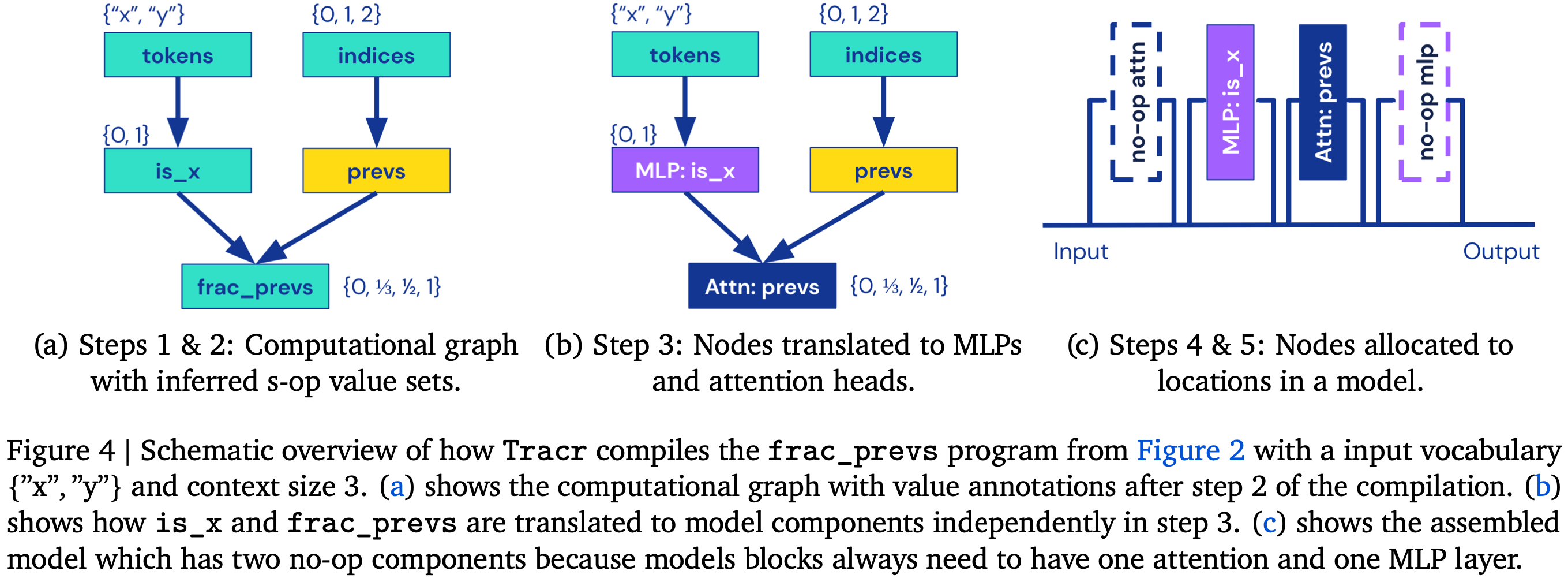
The biggest thing I liked about this paper, aside from the cleaner attention parametrization, is that it just gives you a bunch of examples of programs that can be implemented as compact transformers. If you want to level up your intuition for what sorts of functions these things can compute, stare at Appendix D for a while.
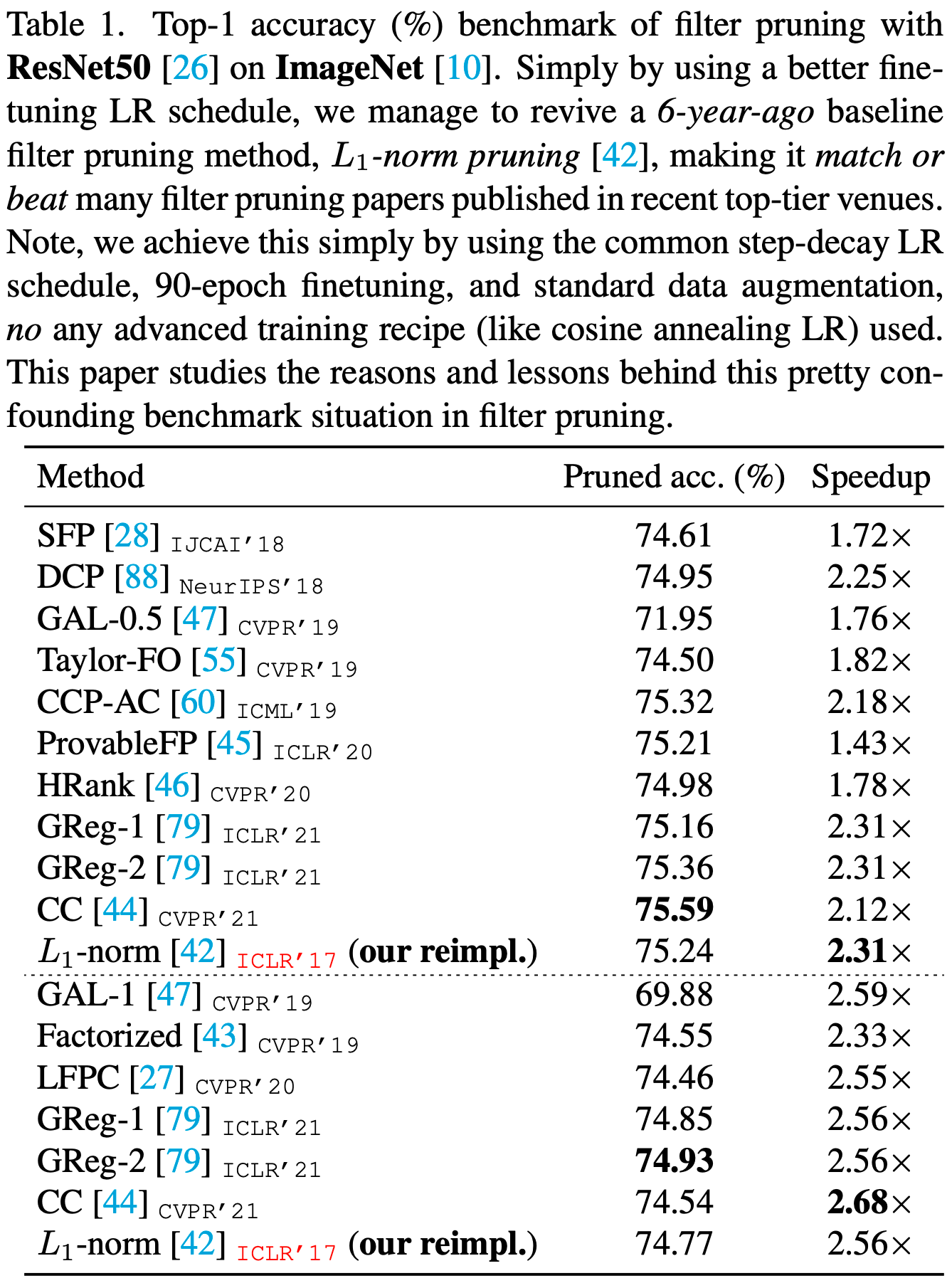
Why is the State of Neural Network Pruning so Confusing? On the Fairness, Comparison Setup, and Trainability in Network Pruning
They investigate the factors that affect the efficacy of filter pruning methods and discuss why it’s so hard to make apples-to-apples comparisons.
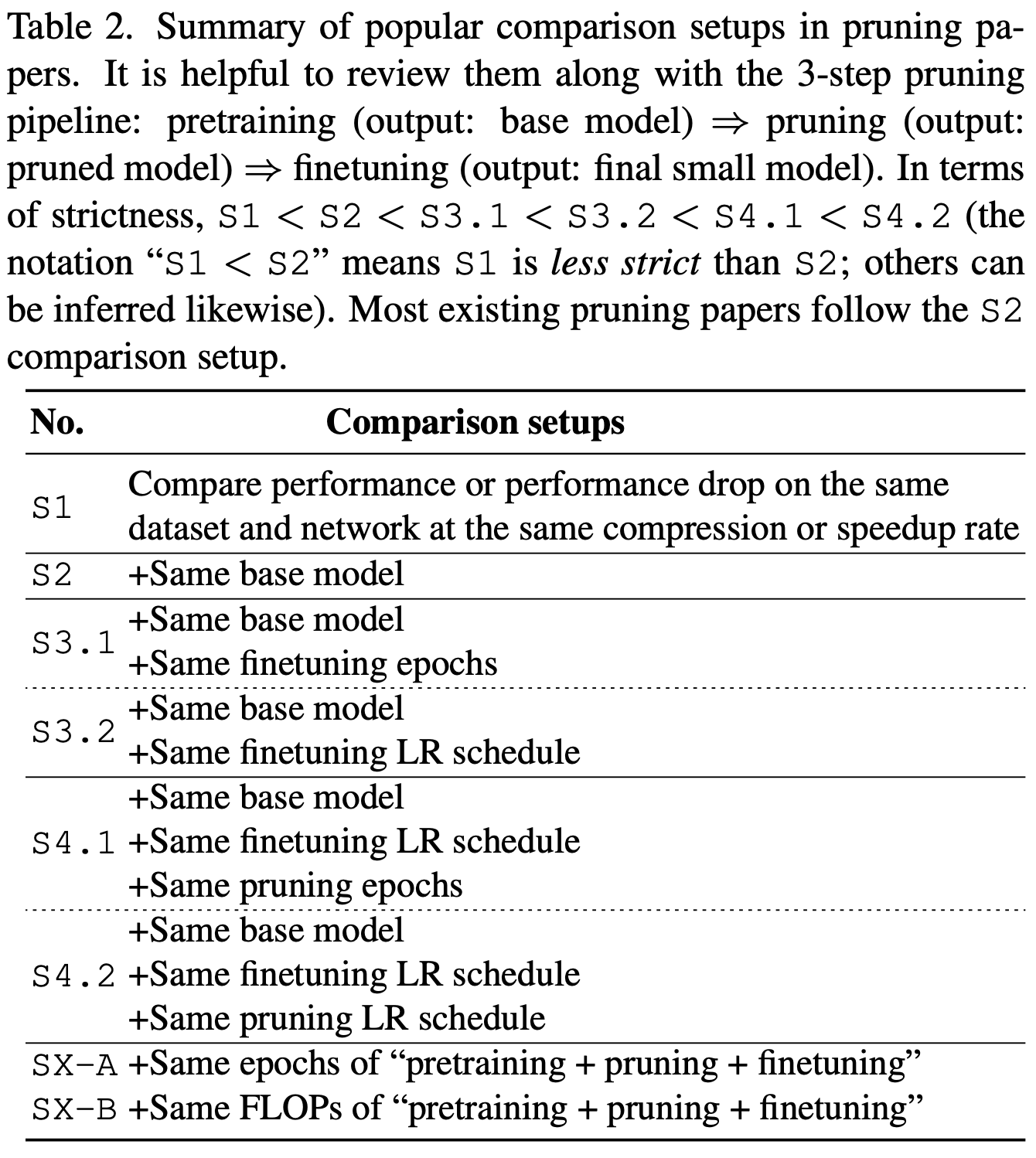
First, they introduce a taxonomy of different degrees of experimental standardization. Ideally you want “S4,” where basically everything is held constant.
They also describe two “mysteries” associated with filter pruning:
Large learning rates seem to boost finetuning accuracy.
Training from scratch works just as well as pruning + finetuning when the total training budget is held constant.

The answers they propose to these mysteries are that:
The pruning slows down the optimization, so the larger learning rate helps.
But, if you train for long enough, the final accuracy you reach is the same with or without the high learning rate.
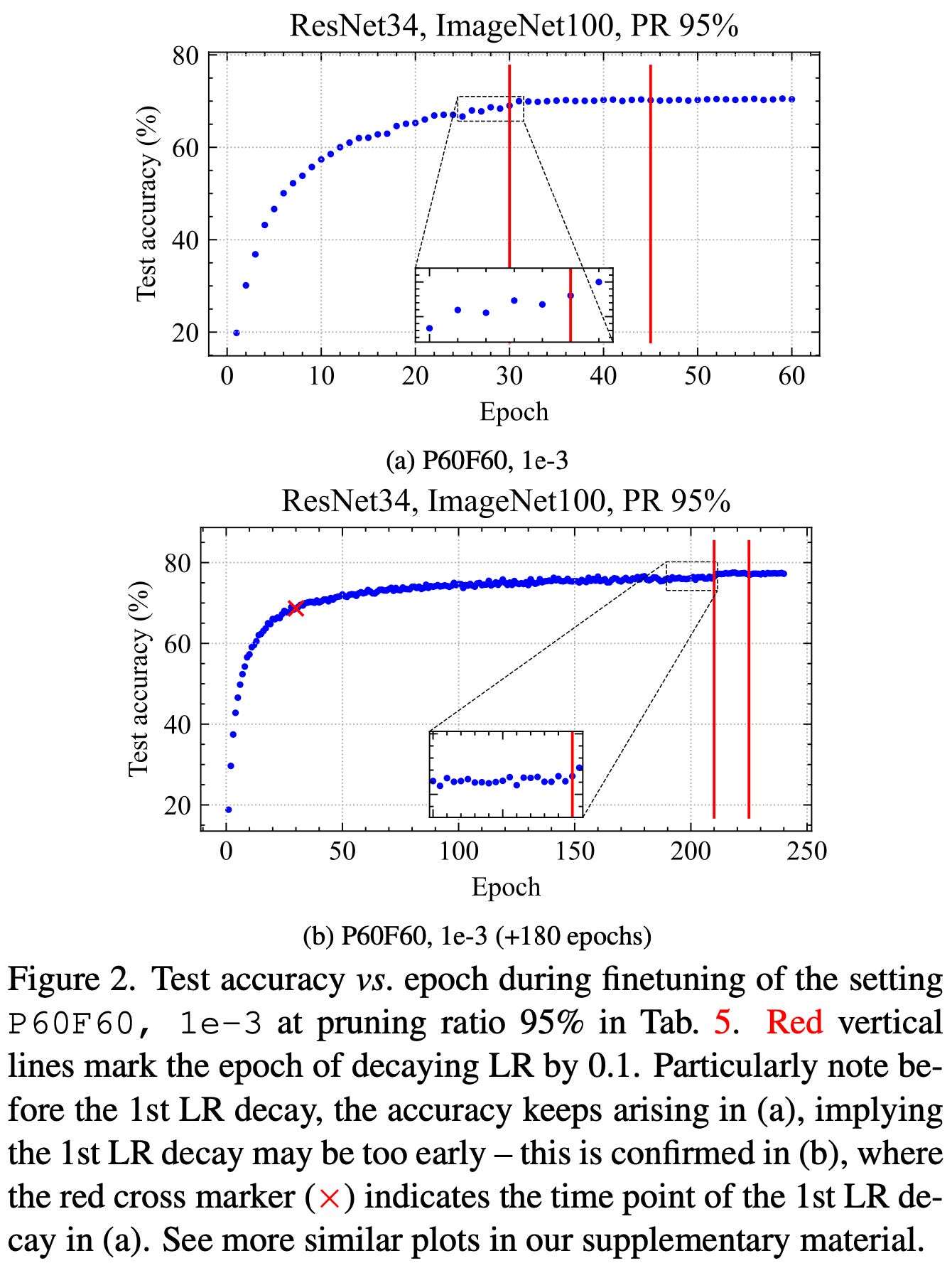
They have some really nice, standardized comparisons between different hyperparameters.
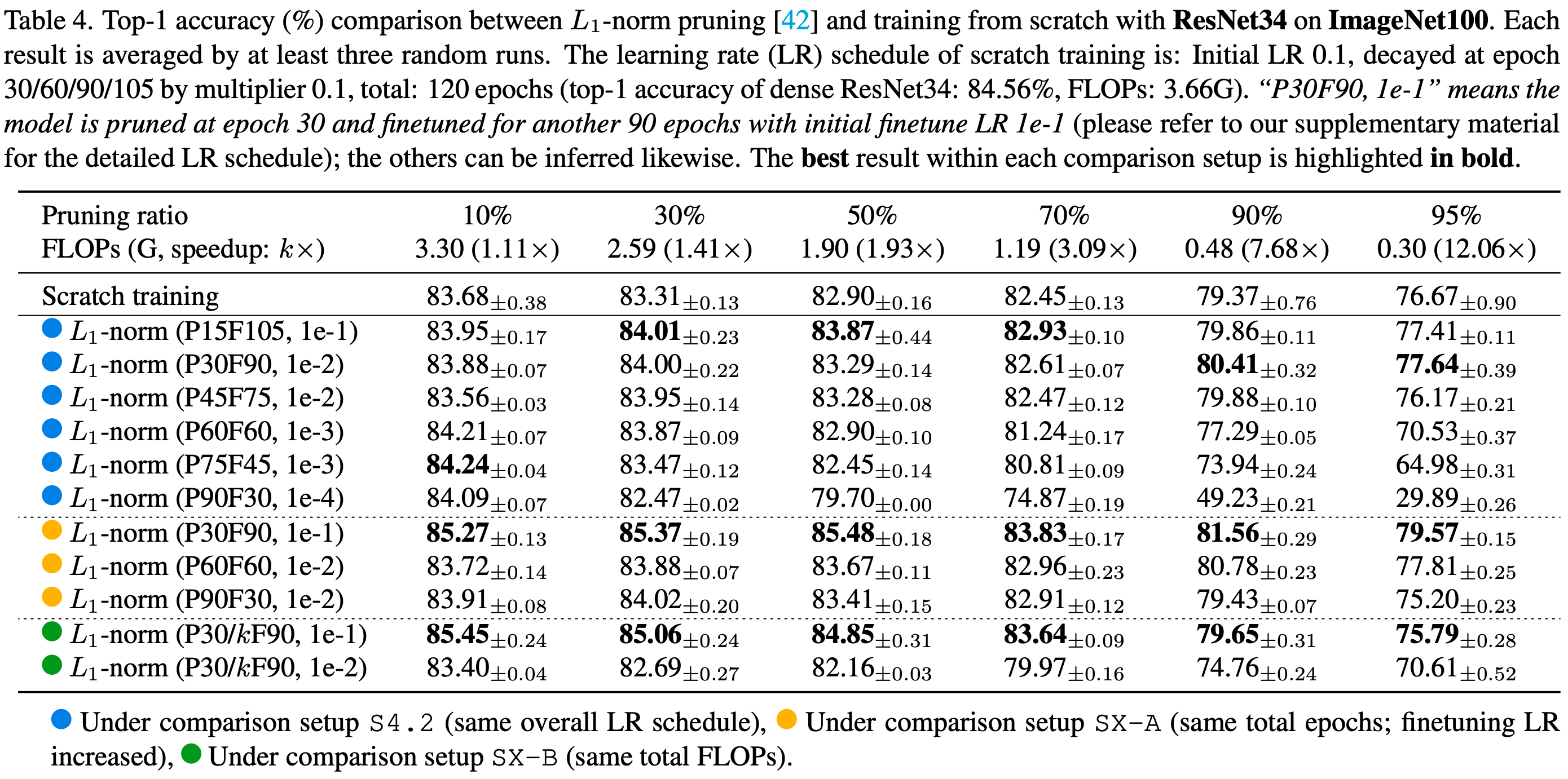
Great to see this sort of careful science.
Is Federated Learning a Practical PET Yet?
Not if the server is susceptible to (or can carry out) Sybil attacks. I.e., not if there can be fake, malicious users.
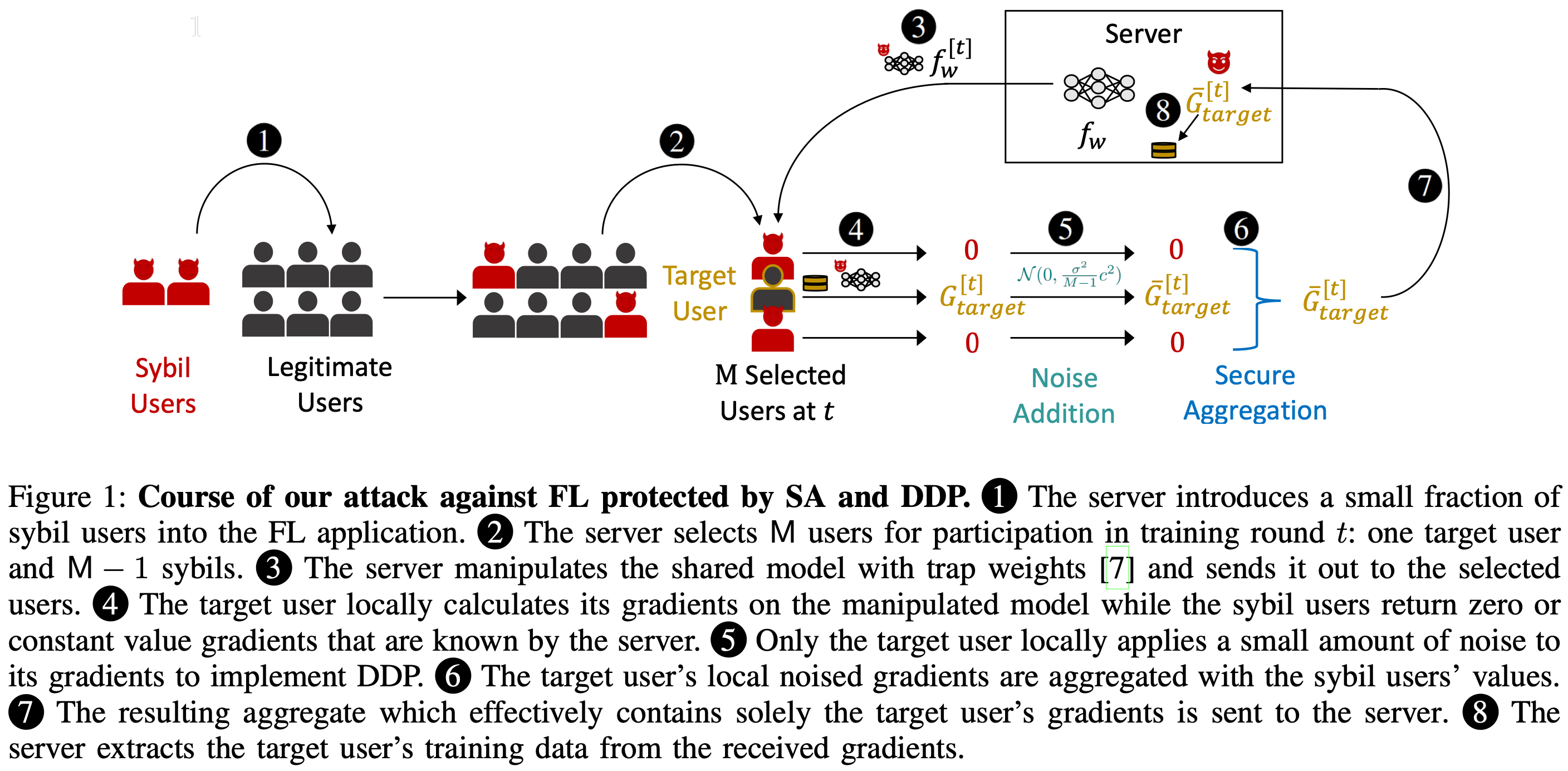
I’m still inclined to say that it can be a “practical [privacy enhancing technology” in the sense that companies have actually deployed it and it’s better than nothing, but I trust Nicolas Papernot’s take on these terms more than mine.
SantaCoder: don't reach for the stars!
A tech report detailing progress so far on an open code generation model; think BLOOM, but for code.
They have some interesting results trying out multi-query attention and fill-in-the-middle. These don’t play nicely together but multi-query attention on its own seems pretty good—though the effect sizes are small.
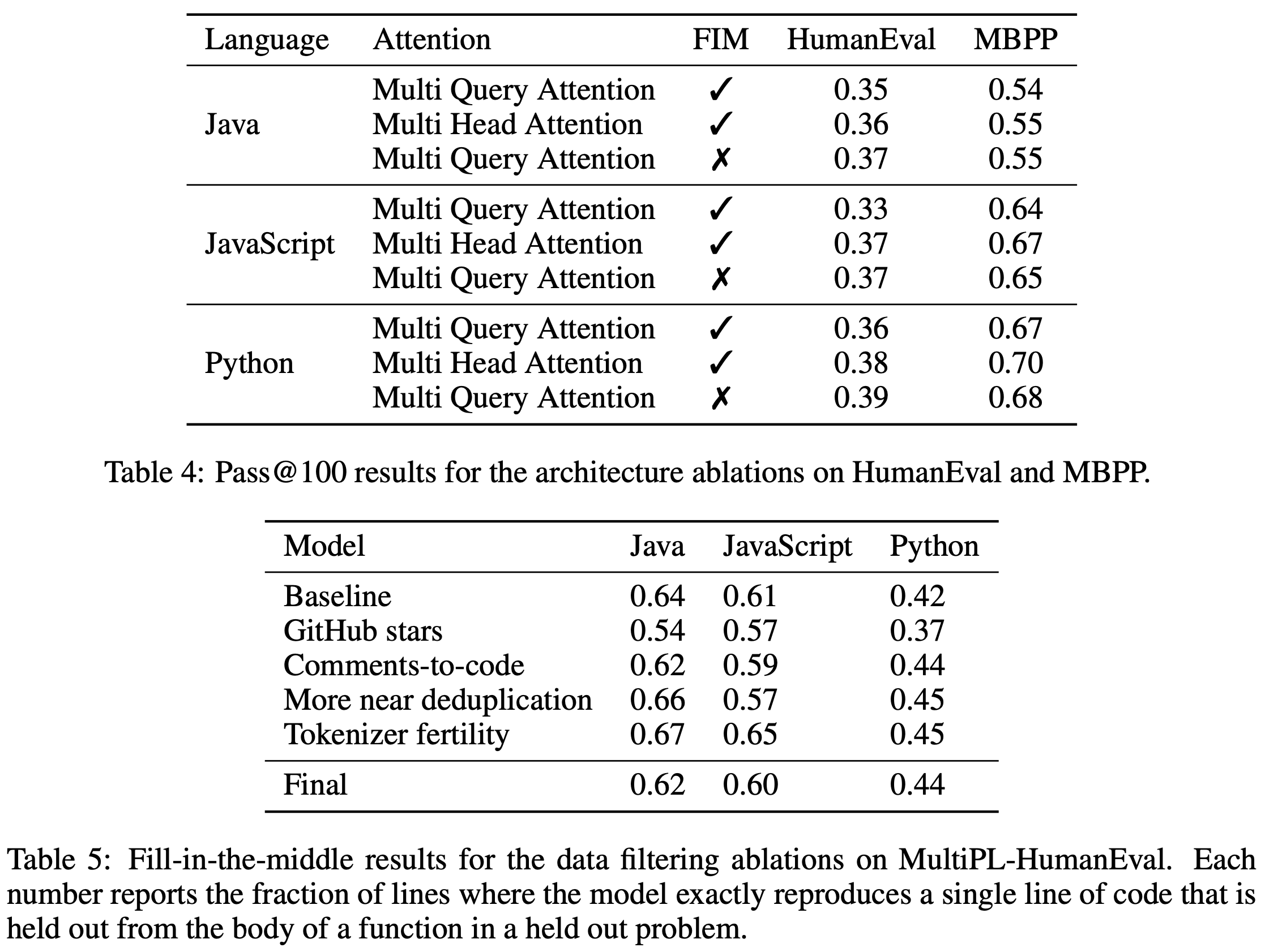
I also liked the discussion of their data pipeline—a bunch of actionable tidbits (e.g., the GitHub repos they used for various filtering steps) and some results on PII filtering. Removing personal information from datasets is hard.
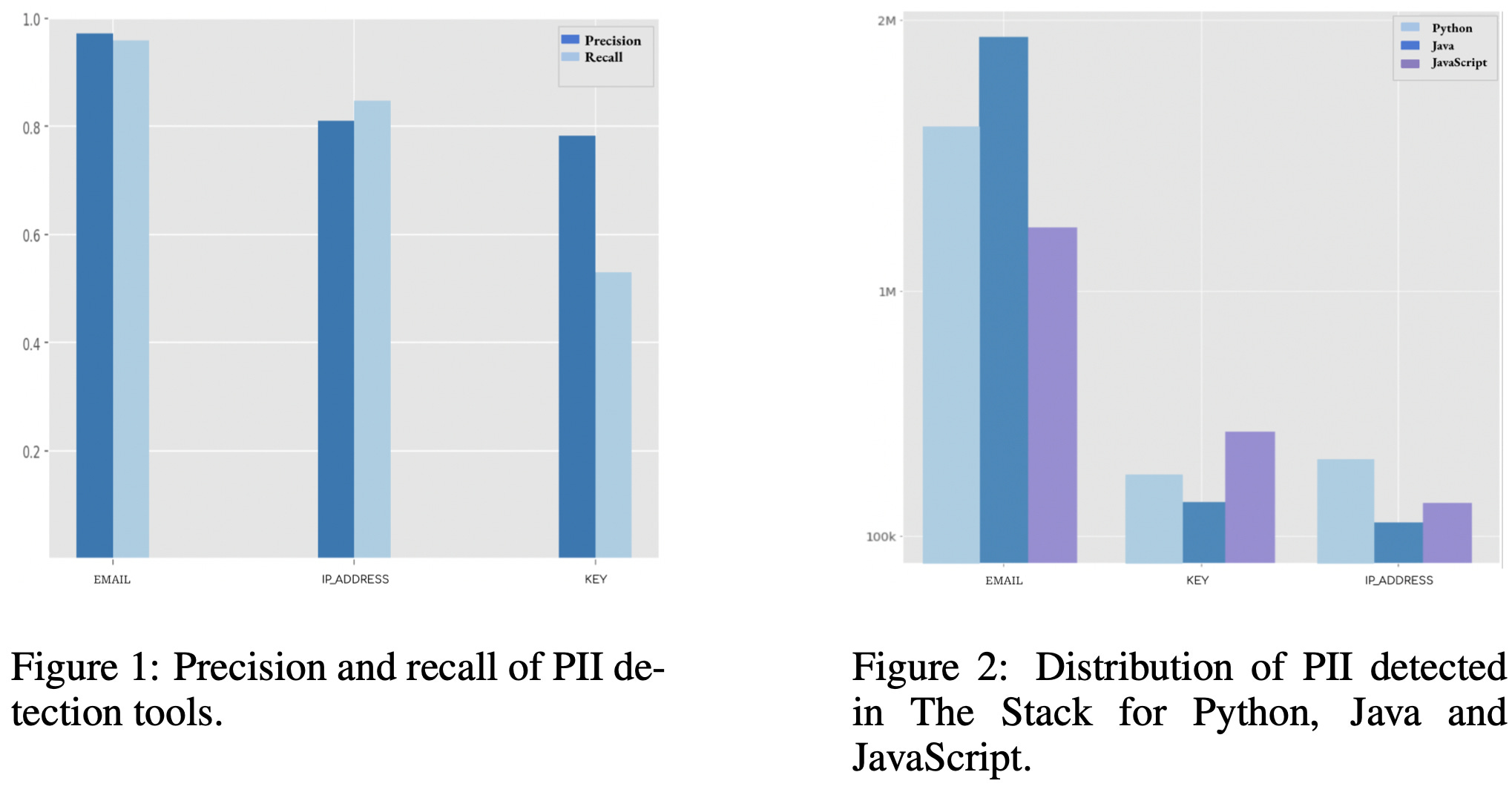
Coding is one of the few tasks I really hope AI doesn’t get great at, but if we have to work on this problem, it’s probably good to have this sort of open collaboration.
Scaling Laws for Generative Mixed-Modal Language Models
This gave me clearer thinking about multimodal models.
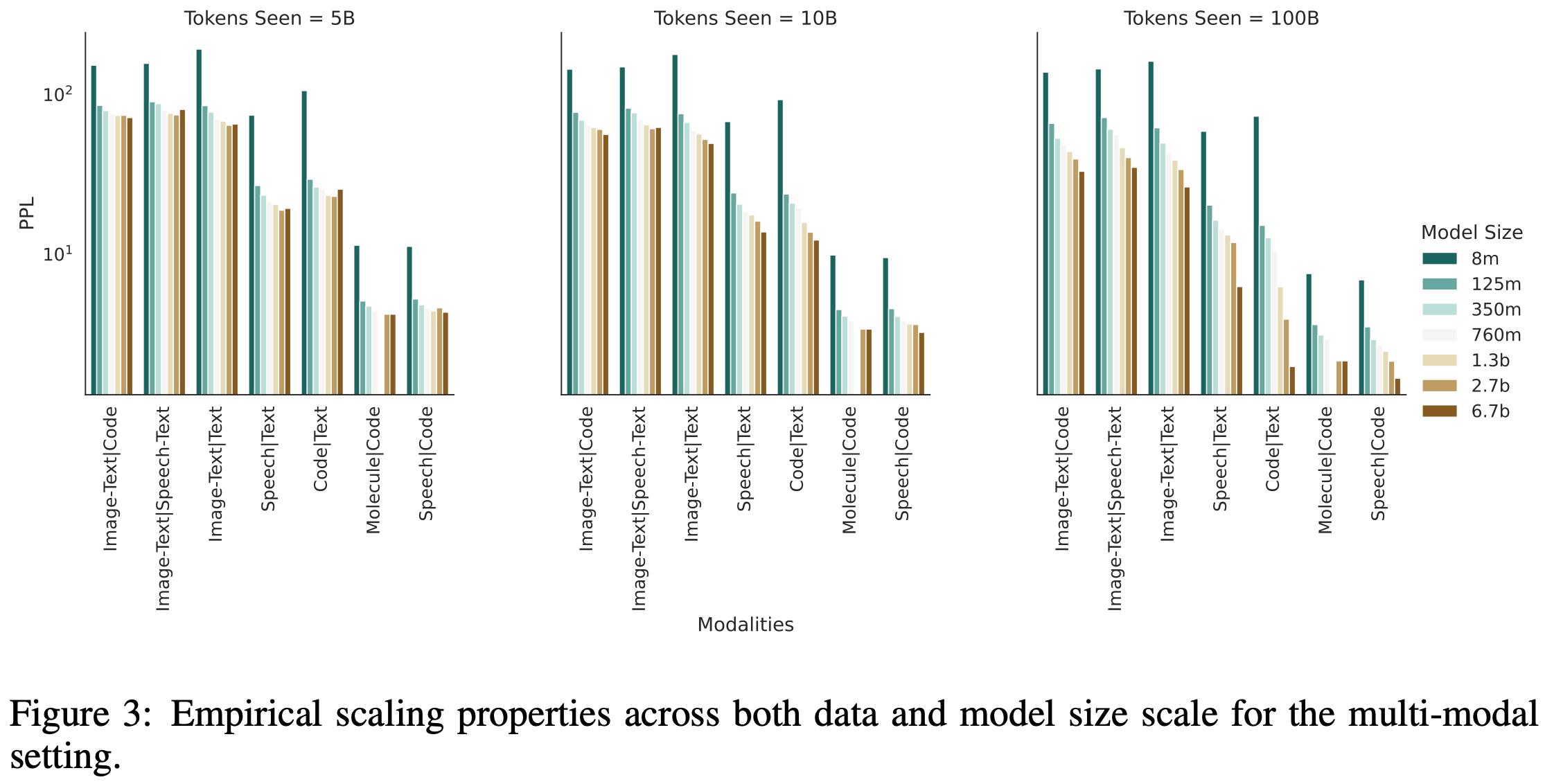
To begin, they discuss power law scaling within a single modality. They use a pretty typical scaling formula and fit the coefficients using the Huber loss + a generic optimizer.
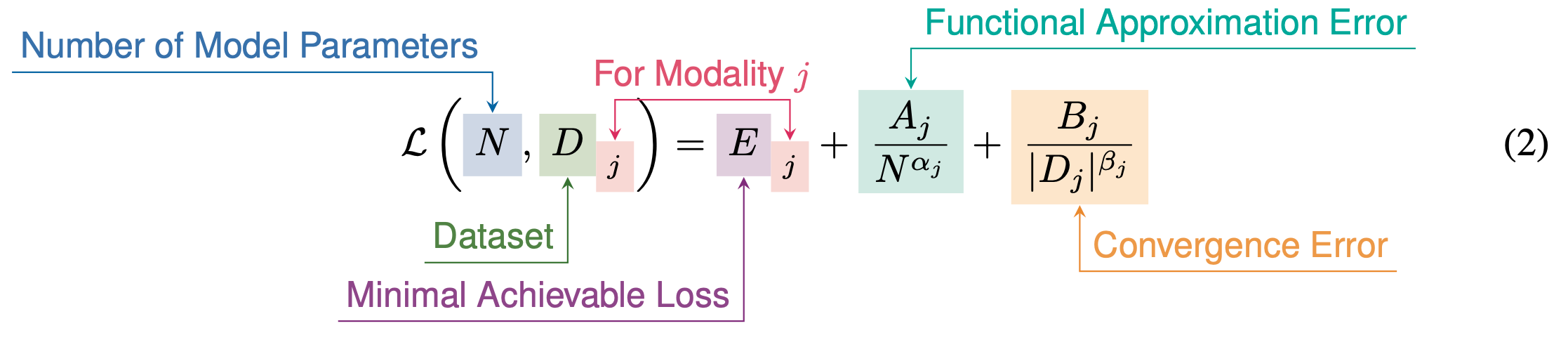
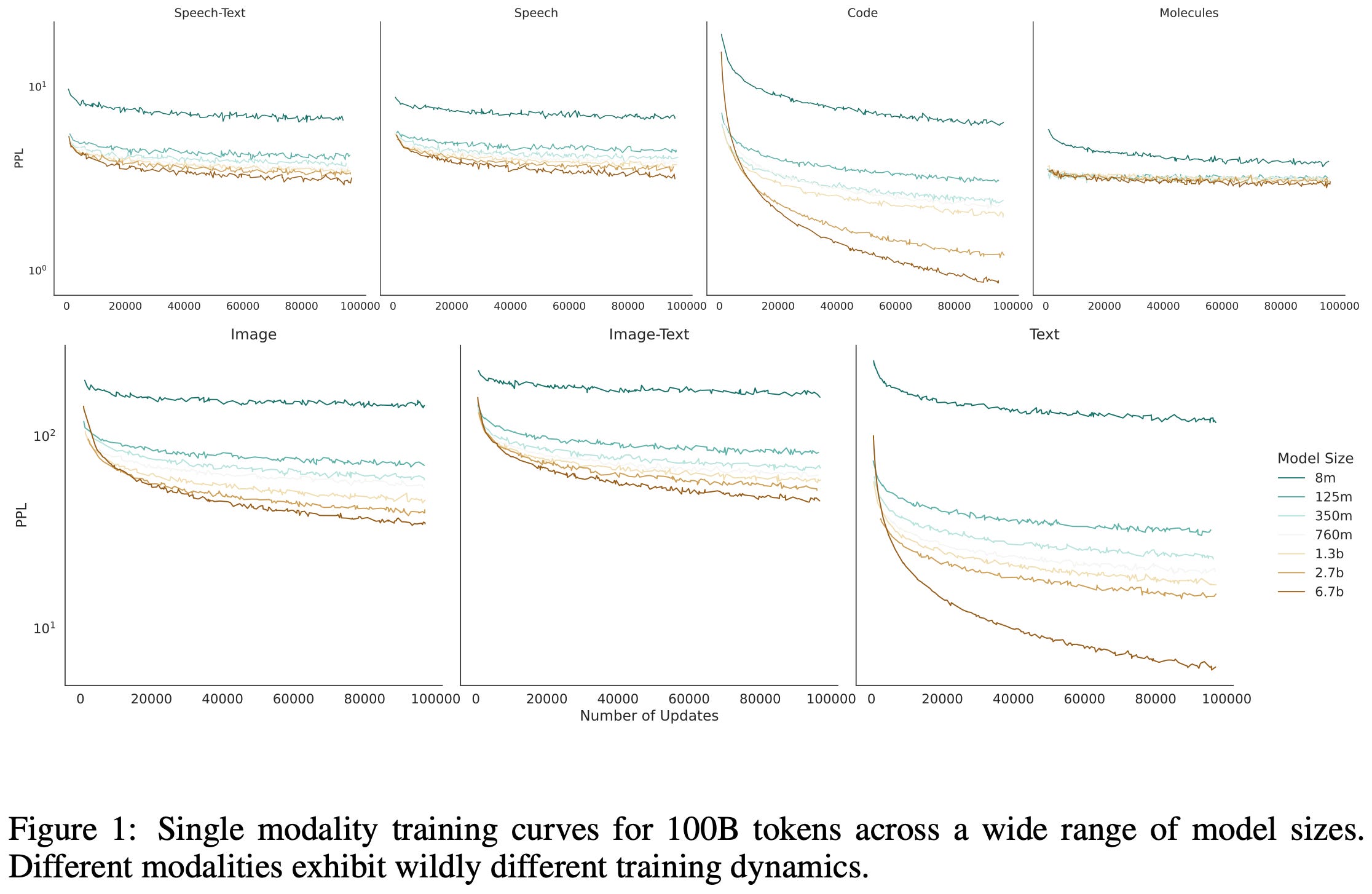
They find that different modalities end up with different training curves and different returns on model scale. It’s hard to know why exactly this is since you have to encode each modality differently. E.g., they use a VQ-VAE with some spatial downsampling to encode images, a HuBERT to encode speech, etc.
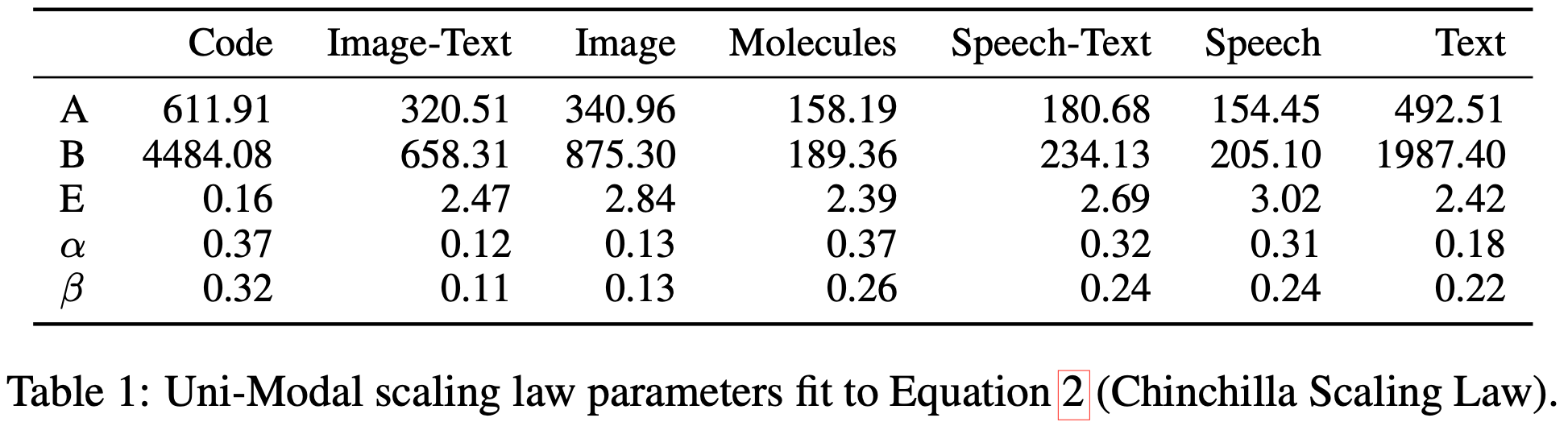
What really gets interesting are the multimodal scaling results. Here, they generalize the scaling formula by starting with the average of the losses across the pair of modalities in question, then adding terms to capture how well the modalities compete with vs benefit each other.

Using this formulation, they can derive a threshold for the point at which two datasets benefit each other more than they hurt.
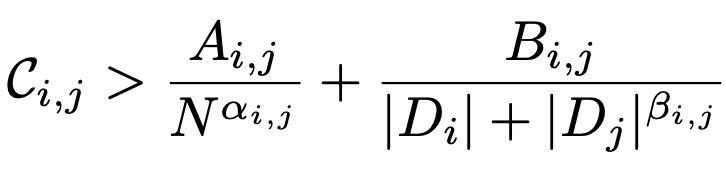
They find that, given enough data and large enough models, different modalities often benefit one another.
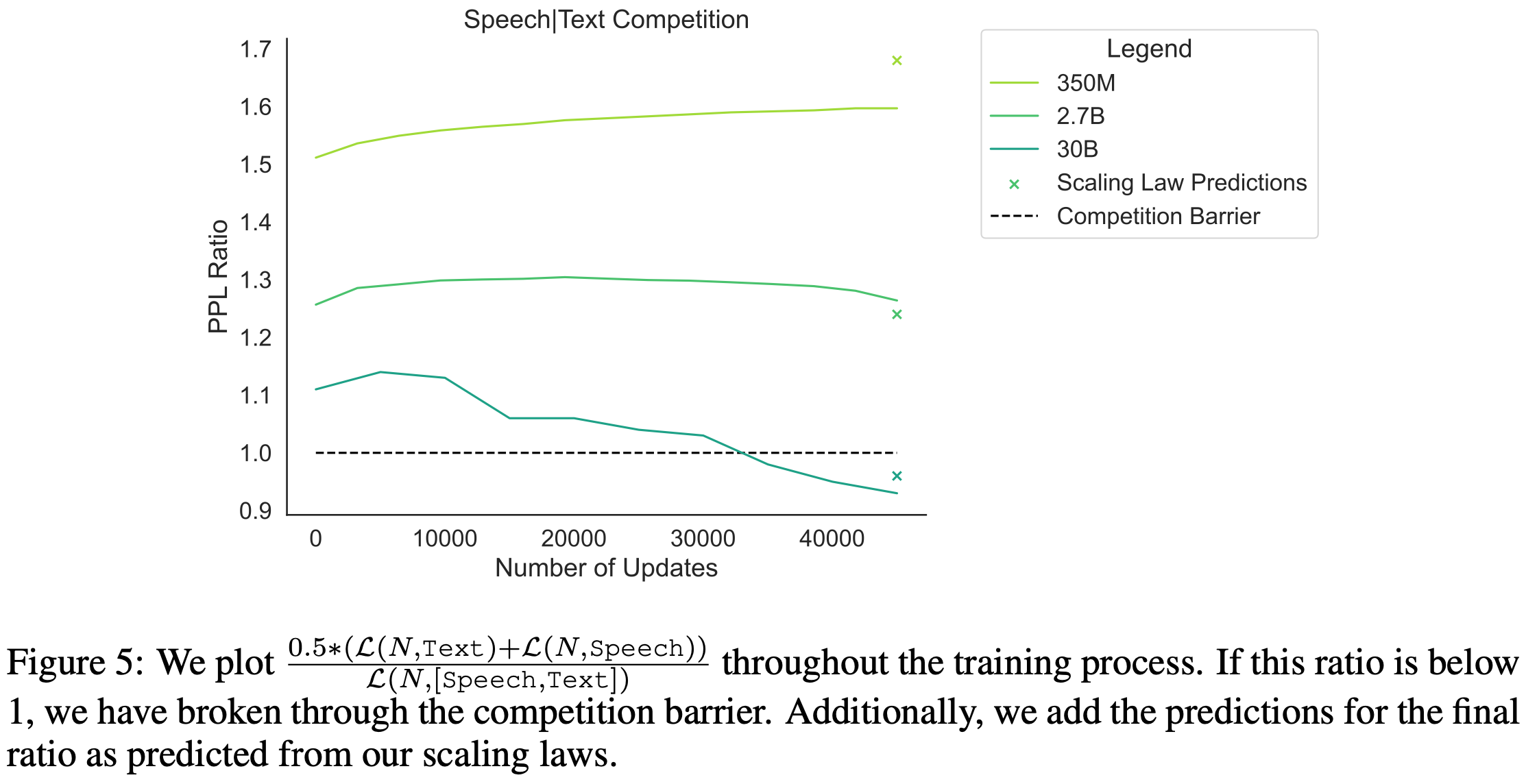
They also encounter some interesting phenomenon in multimodal training. For one, the loss often plateaus for a while on a given modality while improving on the other, resembling coordinate descent.
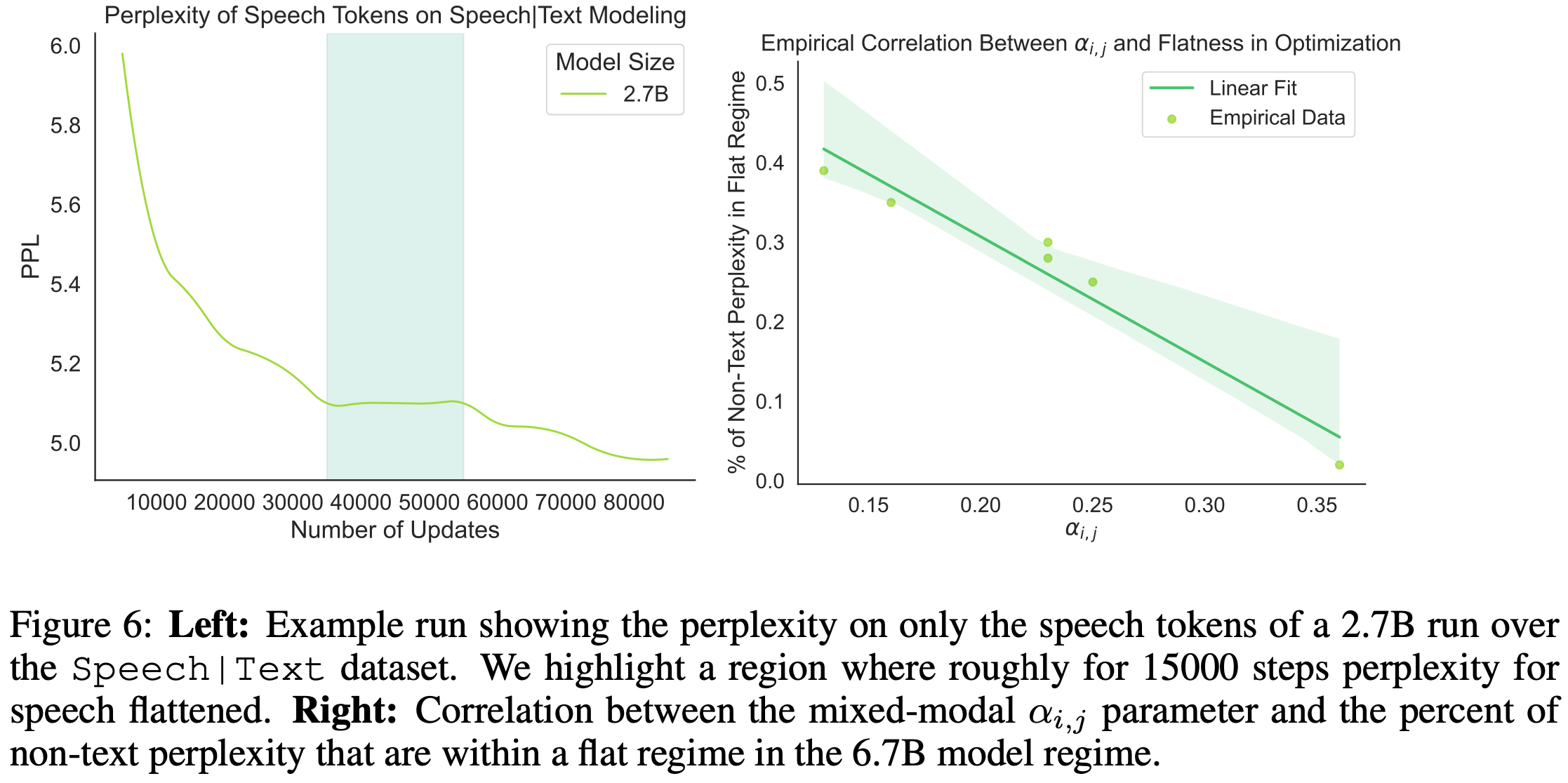
However, this alternating plateauing phenomenon happens less as you scale up.
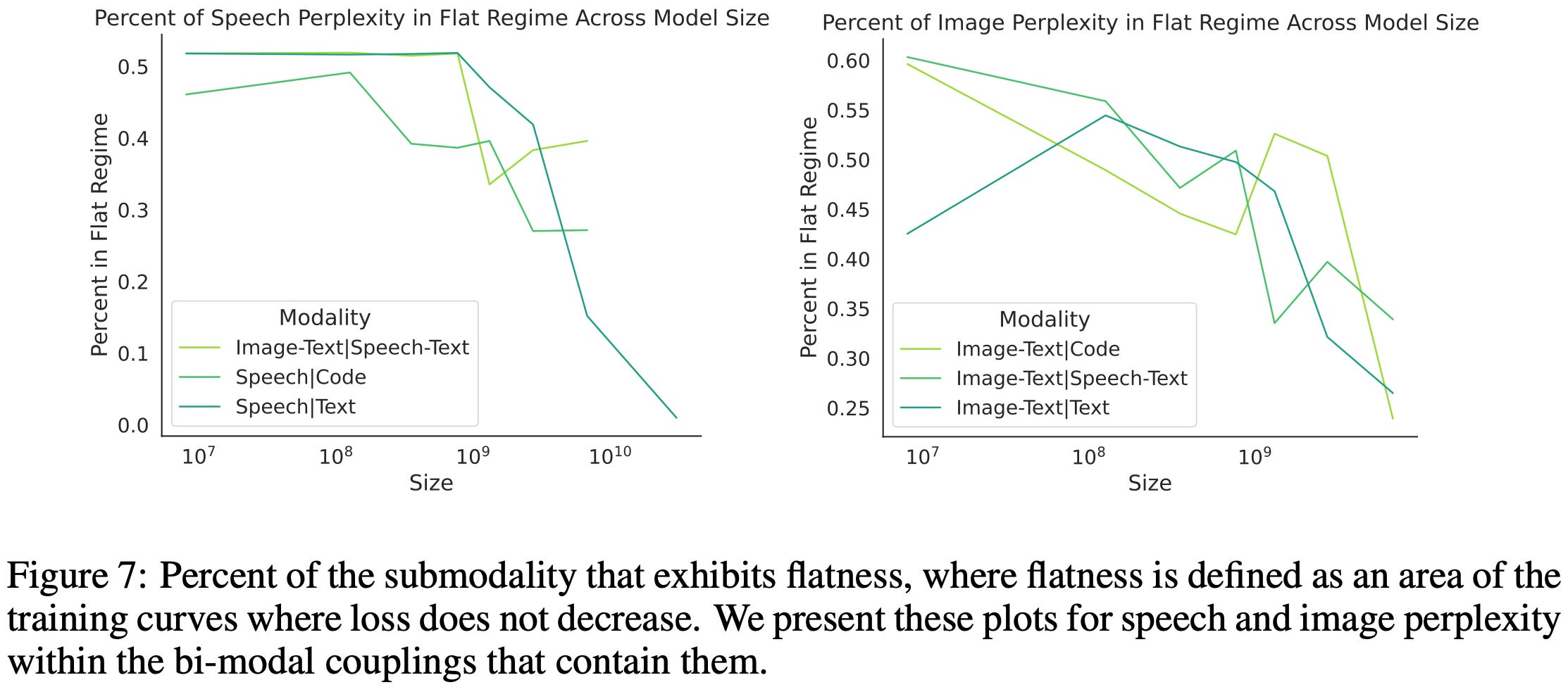
They observe some surprising correlations between the joint coefficients in their scaling formula and the training dynamics. E.g., the optimal batch size is correlated with the joint dataset size scaling.
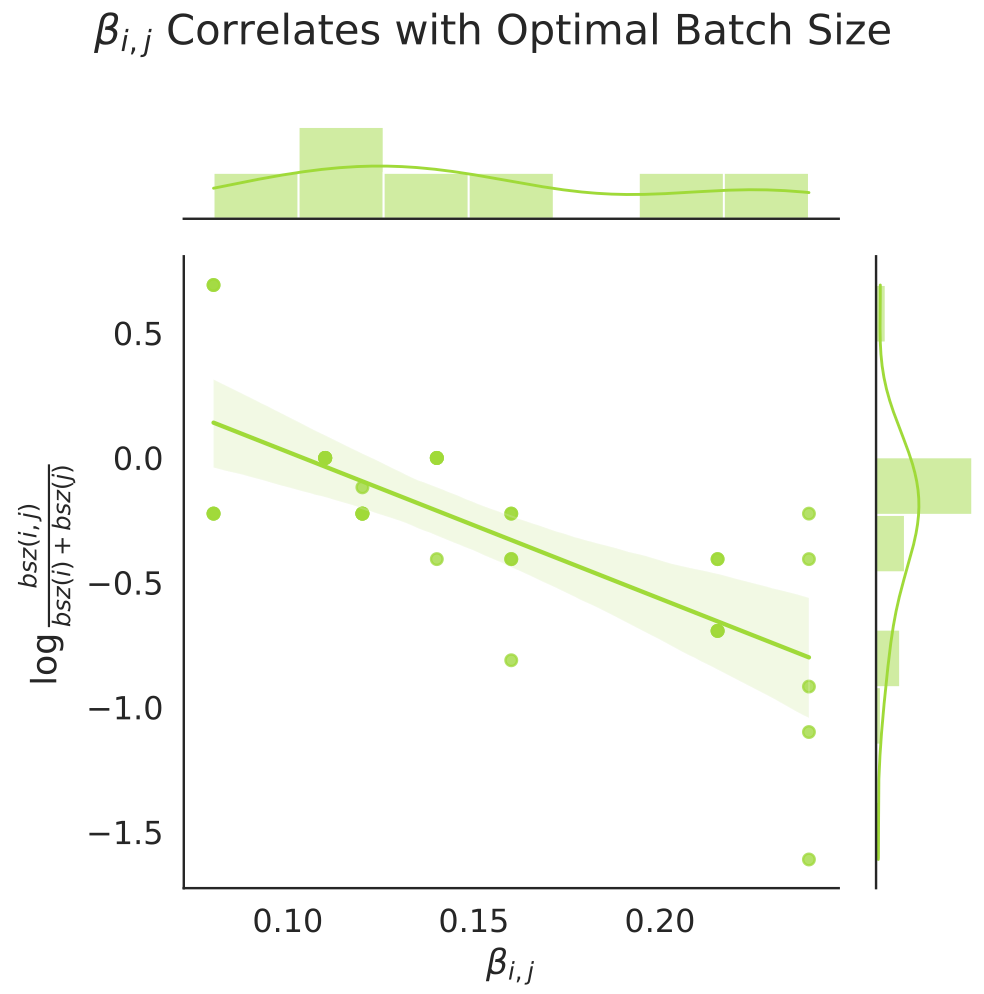
Similarly, the number of loss/gradient spikes correlates with the joint model size scaling.
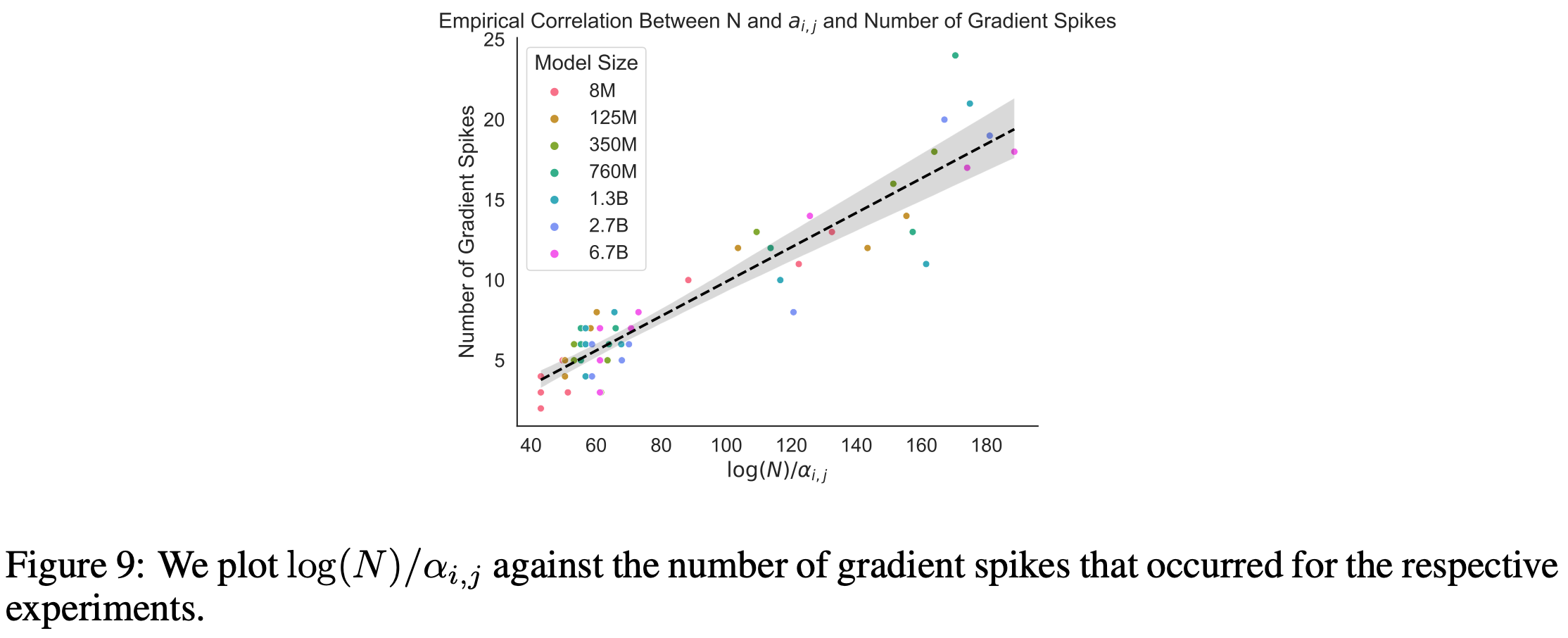
I don’t totally understand how they arrived at their joint scaling formula, but I get the sense there could be an elegant way of looking at arbitrary data subsets and their joint utility in there. This would be cool because it would be a new mental model for statistical learning in general—another tool for the toolbox even if you don’t care about multimodal ML.
Also, the fact that the synergy between modalities tends to increase with scale suggests that multimodal learning will get really important in the next few years.
ExcelFormer: A Neural Network Surpassing GBDTs on Tabular Data
They manage to beat highly tuned gradient boosting baselines across 25 tabular datasets.
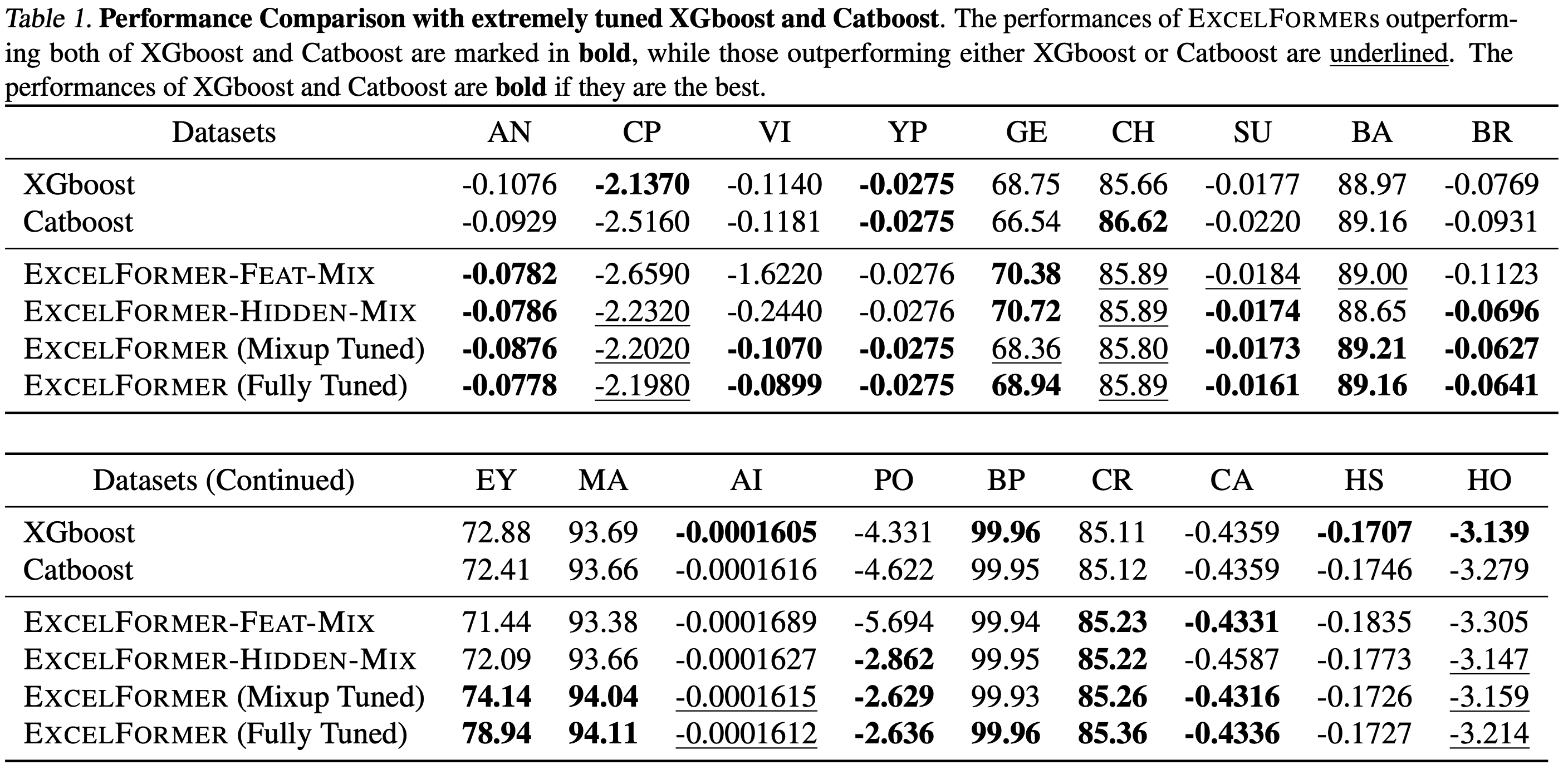
Their model is a transformer, but modified to better capture tabular feature interactions.
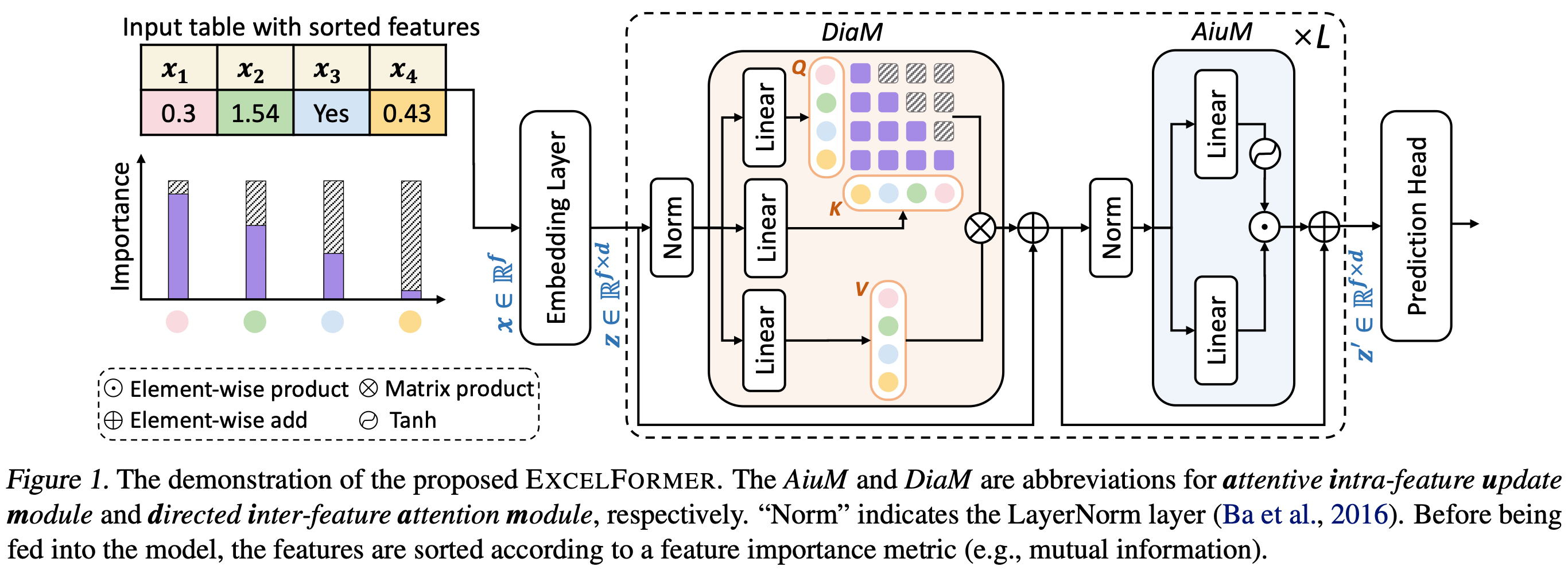
Since tabular datasets are a huge fraction of all datasets, this could be a great tool.
Also, I’m just always looking for an excuse to remind us all that deep learning is just one part of ML and gradient boosting + other techniques are used even more often1.
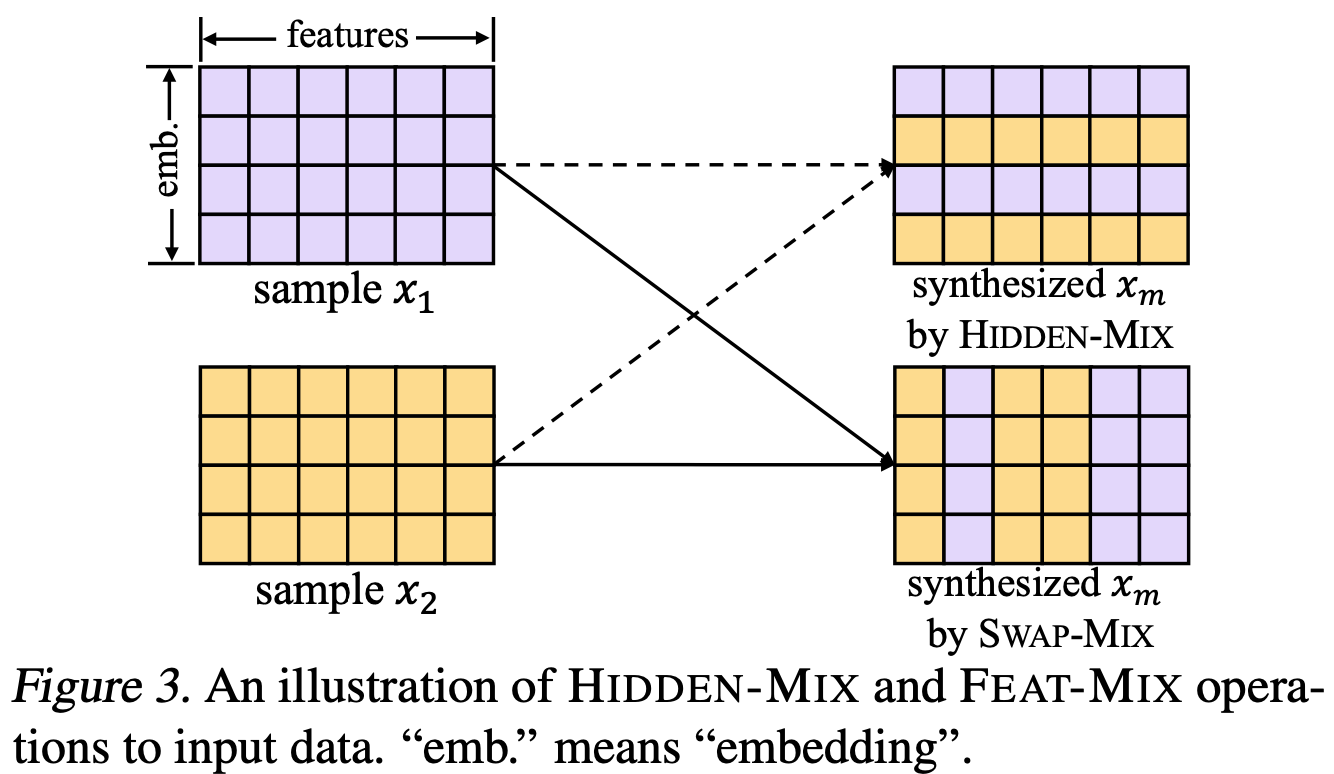
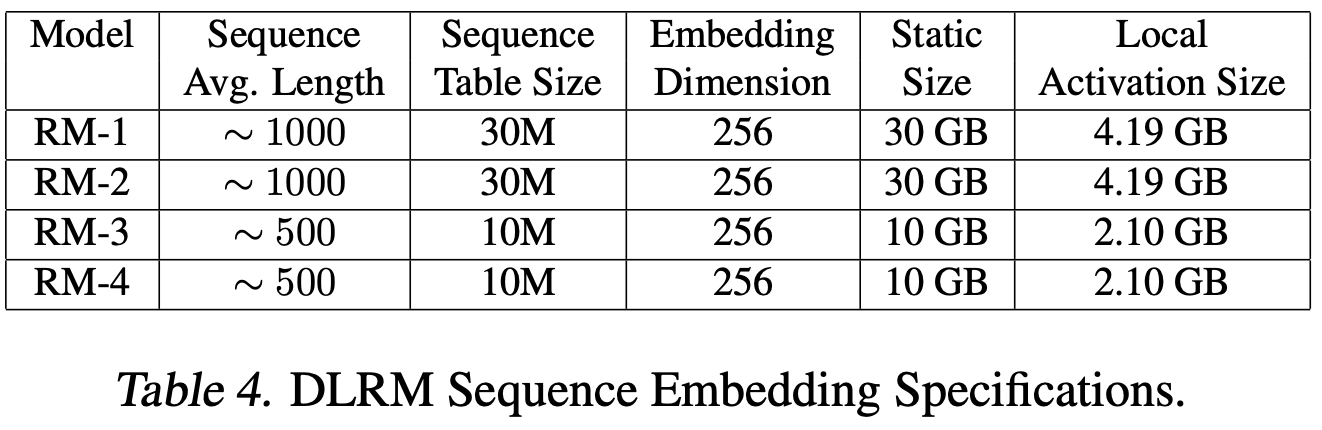
FlexShard: Flexible Sharding for Industry-Scale Sequence Recommendation Models
Recommender system models often have categorical features with tons of categories—e.g., a one-hot indicator for which of the millions of YouTube videos the user just watched. To turn these indicators into reasonable neural net inputs, you have huge embedding tables that you do lookups in to get the dense vectors.
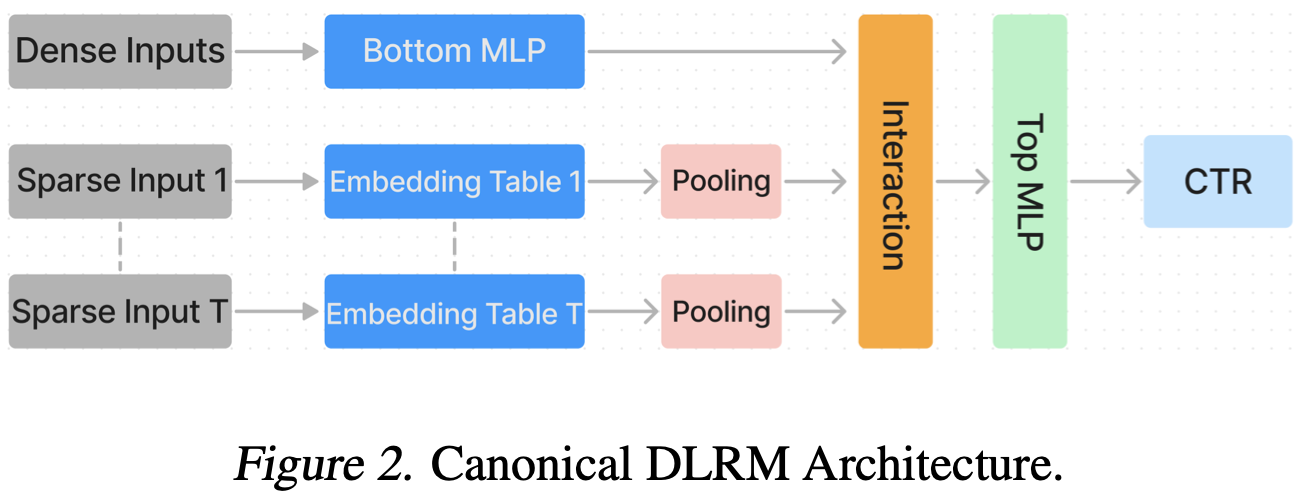
This is hard because:
The tables are too big to fit in GPU RAM
There’s a ton of load imbalance. Some indices are looked up way more often than others.
You don’t want to communicate the whole table (or its gradients) if you can avoid it.
The access patterns are irregular.
They consider an even harder version of the problem where you might do many lookups per table and aren’t allowed to aggregate the results before sending them to whatever GPU requested them. E.g., there might be one embedding associated with every video on YouTube, and you want to fetch the embeddings for each video the user watched today. This adds challenges like:
The amount of data a given GPU has to send varies across batches (based on which embeddings are in its shard of the table and which ones happen to get used).
Consequently, the memory consumption associated with a given shard varies across batches.
To address these challenges, they start with a bunch of analysis of different data- and model-parallel sharding schemes.
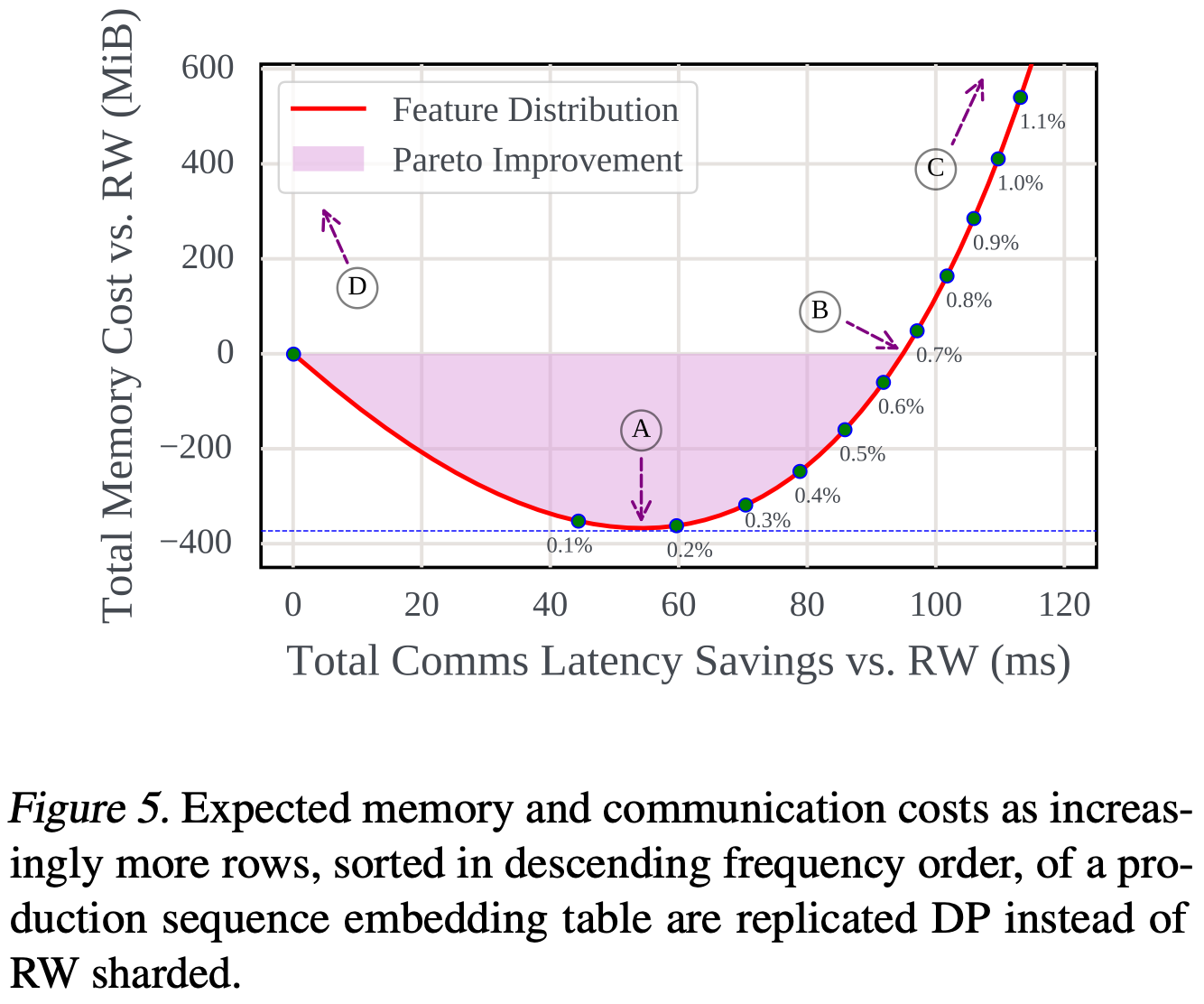
Then they introduce FlexShard, their system that for optimizing embedding table sharding/replication. FlexShard analyzes both the distributions of accesses and the interconnect between nodes to choose a sharding scheme. As a simple example, it might be worthwhile to replicate the most frequently accessed embeddings in every machine so that they don’t require any network traffic except a once-per-step allreduce of their gradients.
Their system successfully reduces communication up to 6x.
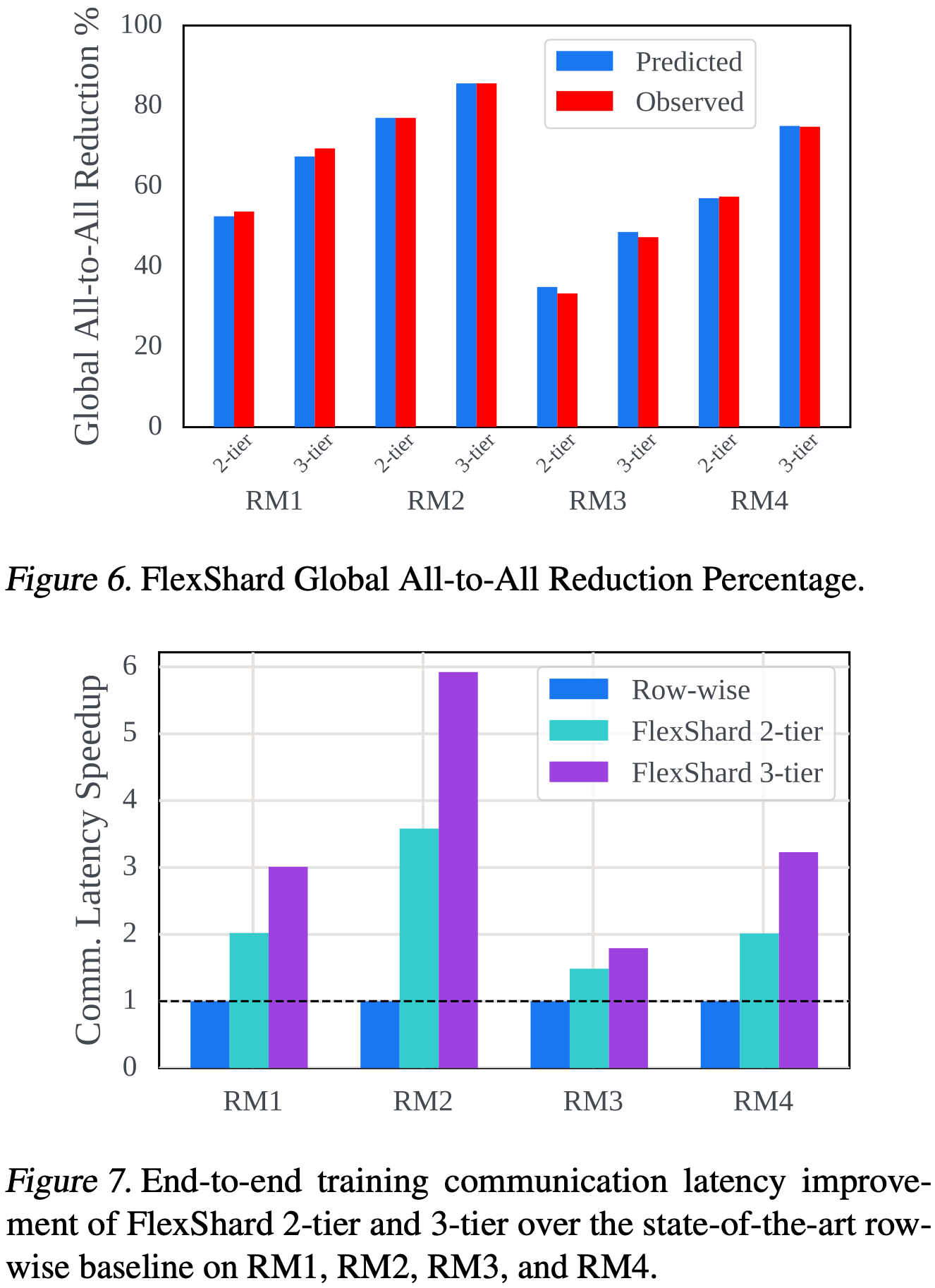
An interesting systems problem and solution—I got pretty nerd sniped thinking about how to optimally solve this.
NarrowBERT: Accelerating Masked Language Model Pretraining and Inference
They consider two BERT variants designed to run way faster.
In the first variant, they reorder the attention and MLP blocks such that all but one of the MLPs come at the end. Since there are no longer any interactions between tokens after the last attention block, this lets them drop all the tokens except the masked tokens, avoiding most of the computation.
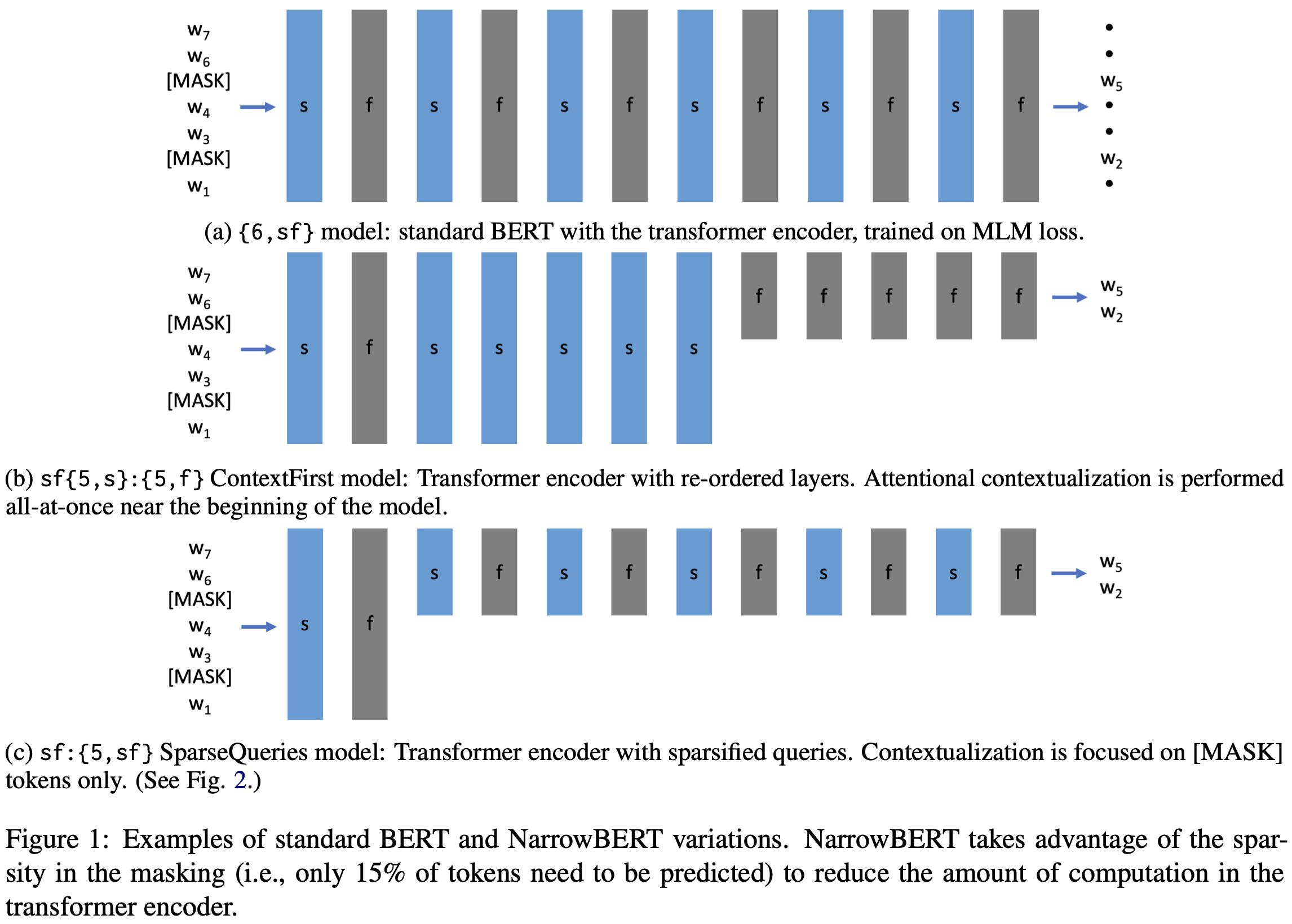
In the second variant, they keep the ordering of attention and MLP blocks the same, but only generate attention queries for the masked positions.
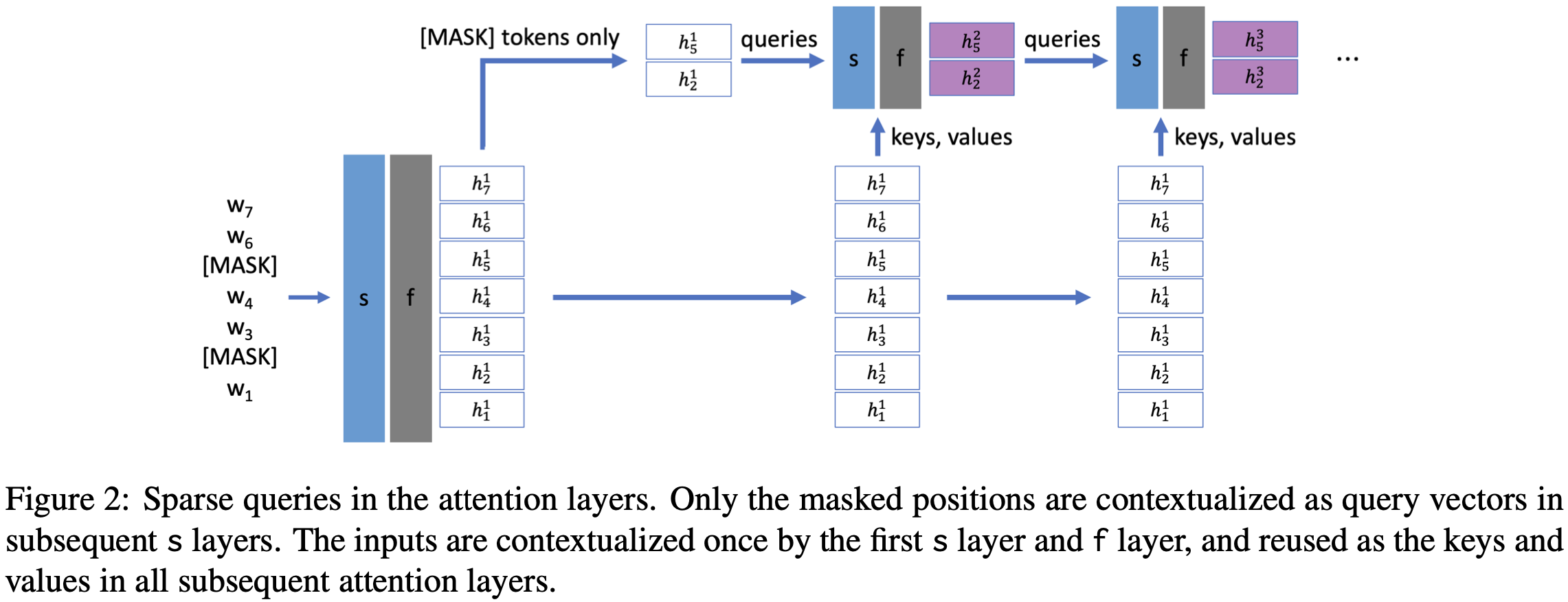
These variants reduce accuracy, but given the huge time savings, seem to be net wins a lot of the time.
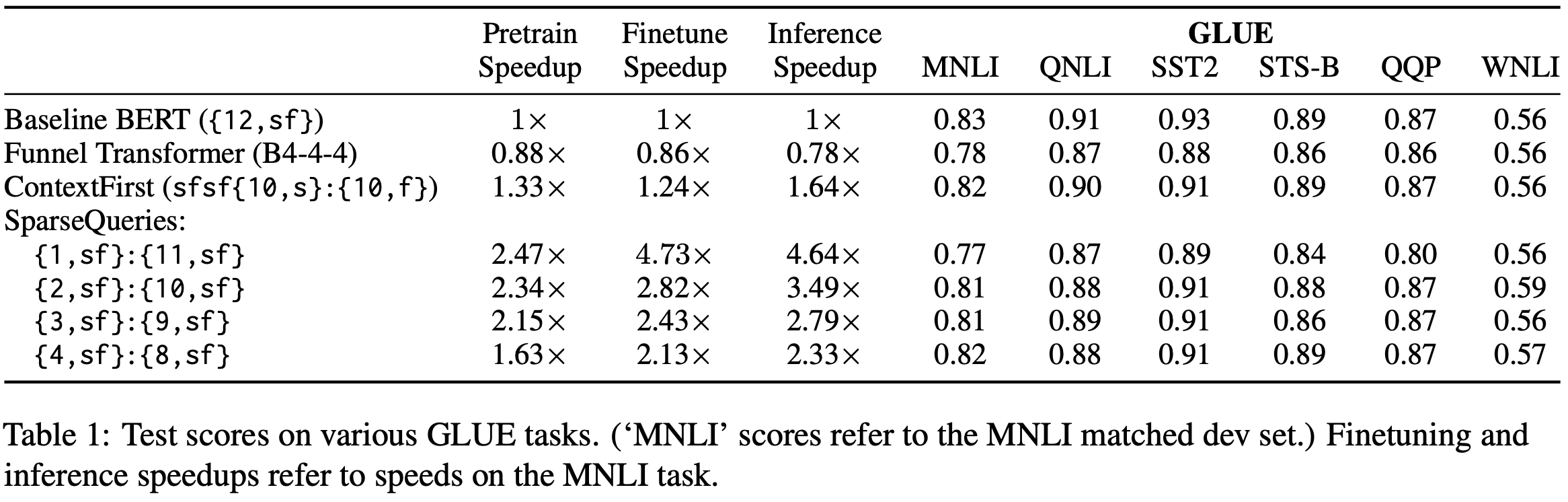
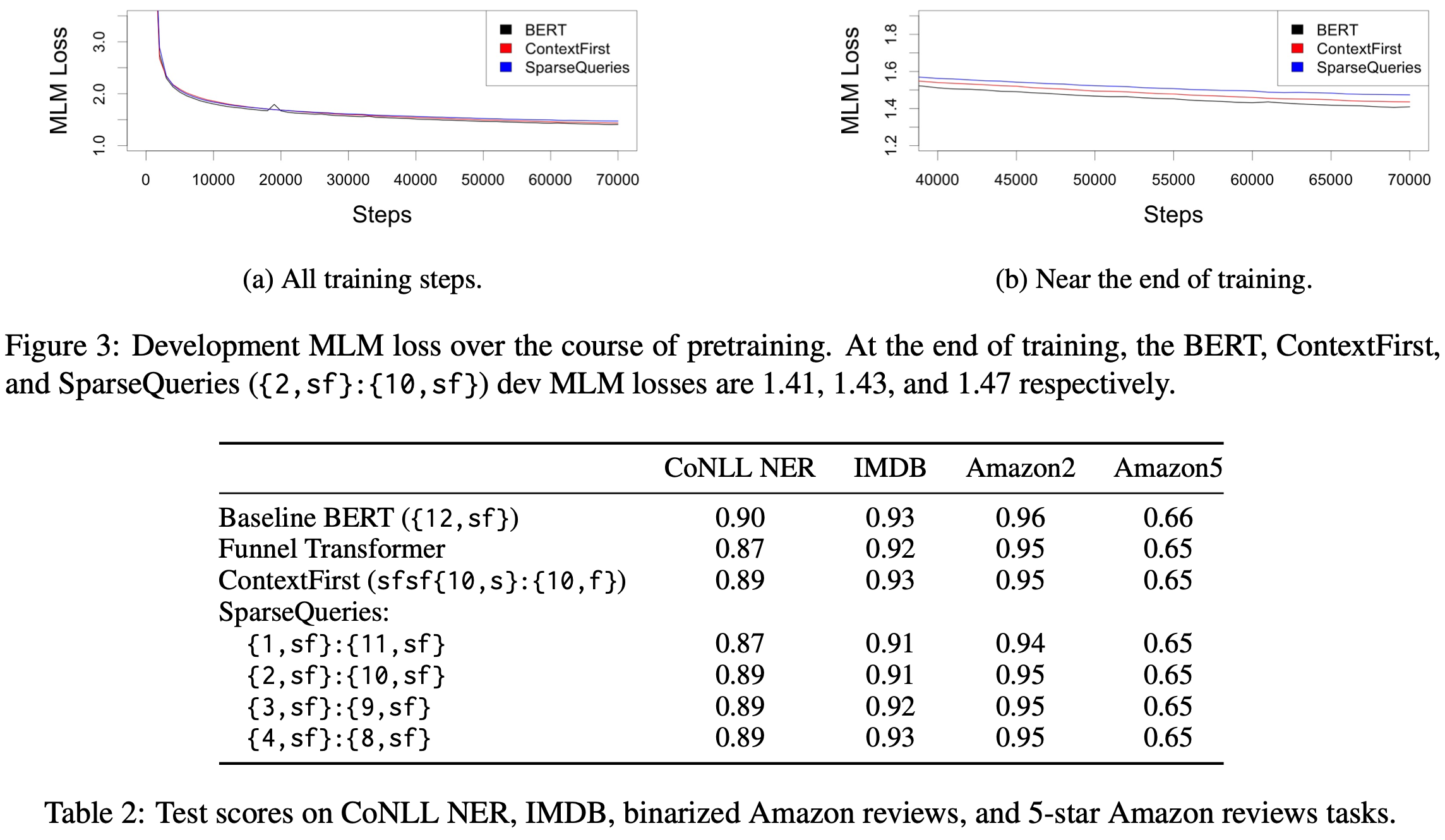
It’s a short paper without a ton of results yet, but if this reproduces, I could totally see it becoming a standard practice.
See slide 19 of Kaggle’s 2022 data scientist survey.
Hi David,
If you liked the parametrisation in the Tracr, you'll LOVE Anthropic's "A Mathematical Framework for Transformer Circuits". This is where I've first seen this parametrisation, and it also contains some other nuggets for describing transformers in more intuitive and useful terms.
https://transformer-circuits.pub/2021/framework/index.html
Best,
Jan
Hi David,
Thanks for your newsletter. I had one piece of feedback, is there a way to add a table of contents at the top in substack? Line or breaks betweenpapers are very hard to see in substacks at the moment.
Thanks