
2023-1-22 arXiv roundup: Domain-specific pretraining is awesome, Removing skip connections

This newsletter made possible by MosaicML.
Looks like we’ve got a little bit of a pre-ICML lull this week. But next week might be crazy…
Learning Customized Visual Models with Retrieval-Augmented Knowledge
Suppose you have:
A pretrained image encoder
A pretrained text encoder
A big corpus of image-text pairs (e.g., LAION-400M)
A downstream task involving images that you can describe using text (e.g., by giving class names as text).
They propose a pipeline for making your image and text encoder work better for the downstream task by retrieving relevant images and their captions from your corpus.

First, before any extra training happens, they insert extra attention and FFN blocks throughout the image encoder. The parameters in these blocks are the only ones that will be trained.

Next, they generate embeddings for the whole corpus of image-caption pairs using the pretrained encoders. These embeddings can be computed once and reused for many downstream tasks.
Now, given a specified set of classes or other text representation of the downstream task, they retrieve relevant image-caption pairs. This is just a nearest neighbor search on the text and/or caption embeddings, with queries given by the embeddings of the task description text.
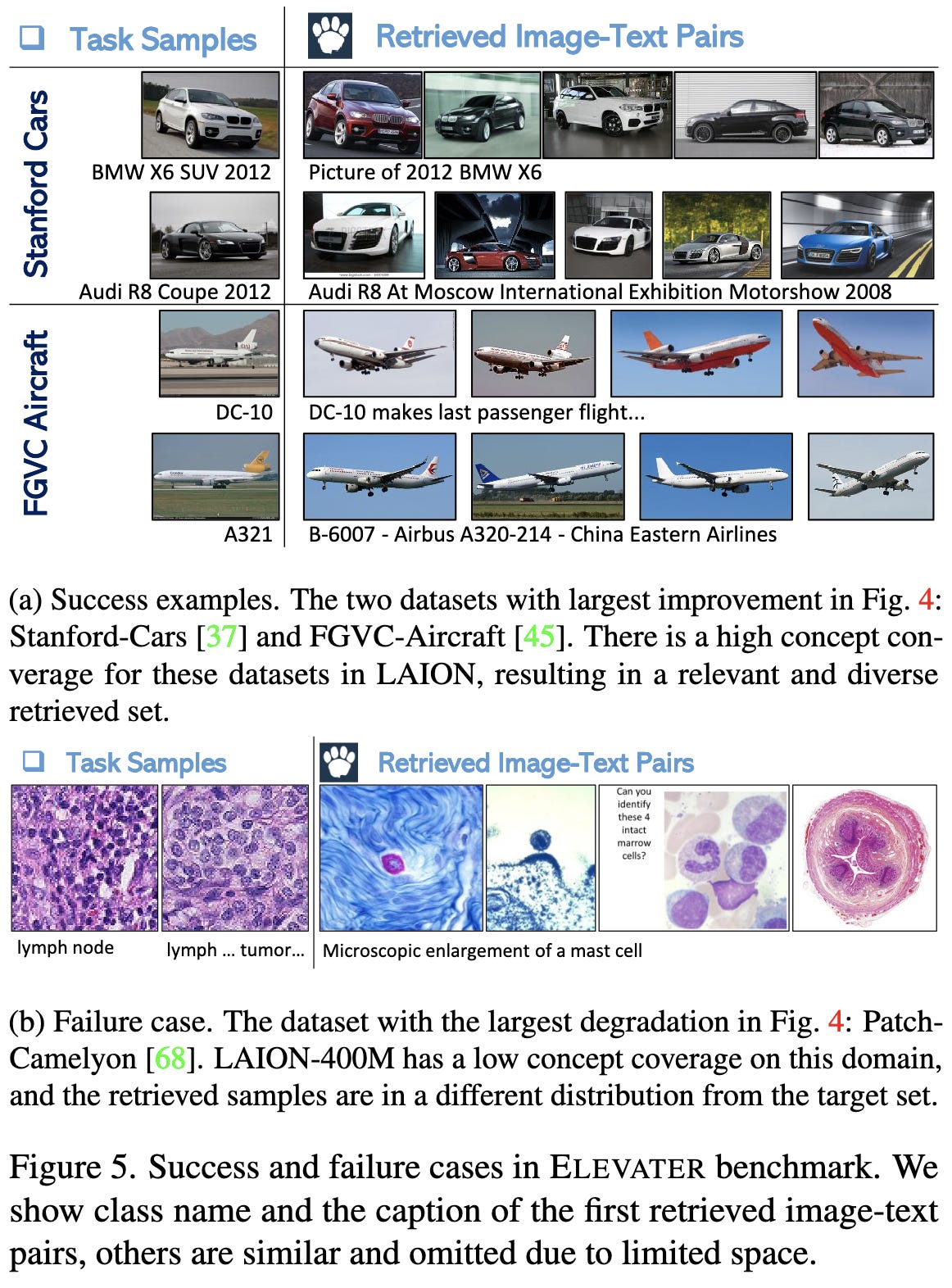
With the modified image encoder and retrieved samples in hand, the extra training can start. This is just more pretraining with a CLIP-like objective that makes the two encoders map each image and its caption to the same point in embedding space.

Their method seems to consistently improve the accuracy of existing image + text encoder models, often by large margins.
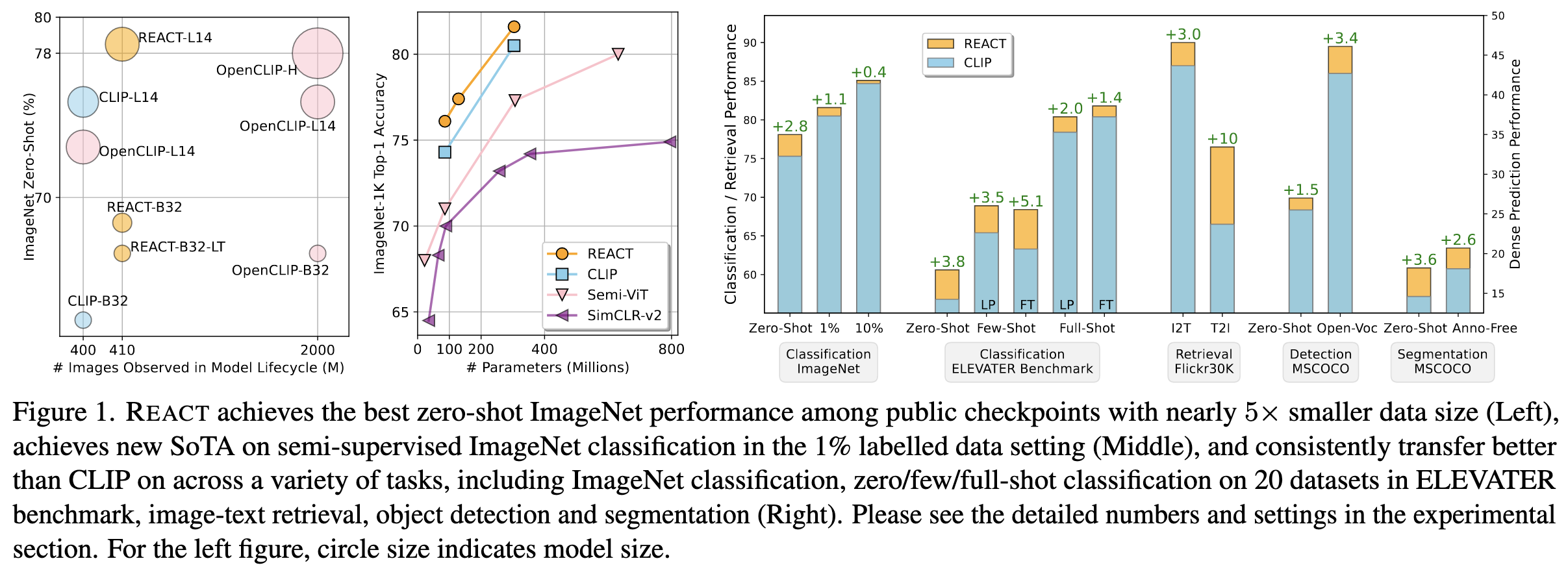

This holds not just for image classification, but also image-text retrieval, open-vocabulary object detection, and semantic segmentation.


They also have some good ablations for various design choices. First, they find that adding in extra modules and only tuning those works better than locked image tuning and other alternatives.

They also observe that retrieving more images + captions from your database tends to help. This is unsurprising since it gives you a larger training set for the domain adaptation / continued pretraining step.

Lastly, it’s important to retrieve based on not only the image embeddings (T2I), but also the text embeddings (T2T). This might be because the query is an embedding of a text description of the task (or, e.g., one of its classes), so the retrieval quality is higher for text.

This is even more evidence that task-relevant pretraining is extremely effective.
Tailor: Altering Skip Connections for Resource-Efficient Inference
When doing inference, skip connections require you to keep around old activations for a while, increasing memory usage and memory bandwidth. They propose to gradually remove the skip connections in a trained network, or at least shorten them to reduce the lengths of dependencies.

To try to preserve accuracy, they use the unmodified model as a teacher and do distillation.

Thanks to the accuracy lift from distillation, they can roughly preserve the original accuracy with the skip connections removed or shortened.


The lack of skip connections lets them codesign more efficient hardware.

This plus RepVGG make me suspect that removing skip connections for inference might become a best practice, at least if the architecture is designed to facilitate this.
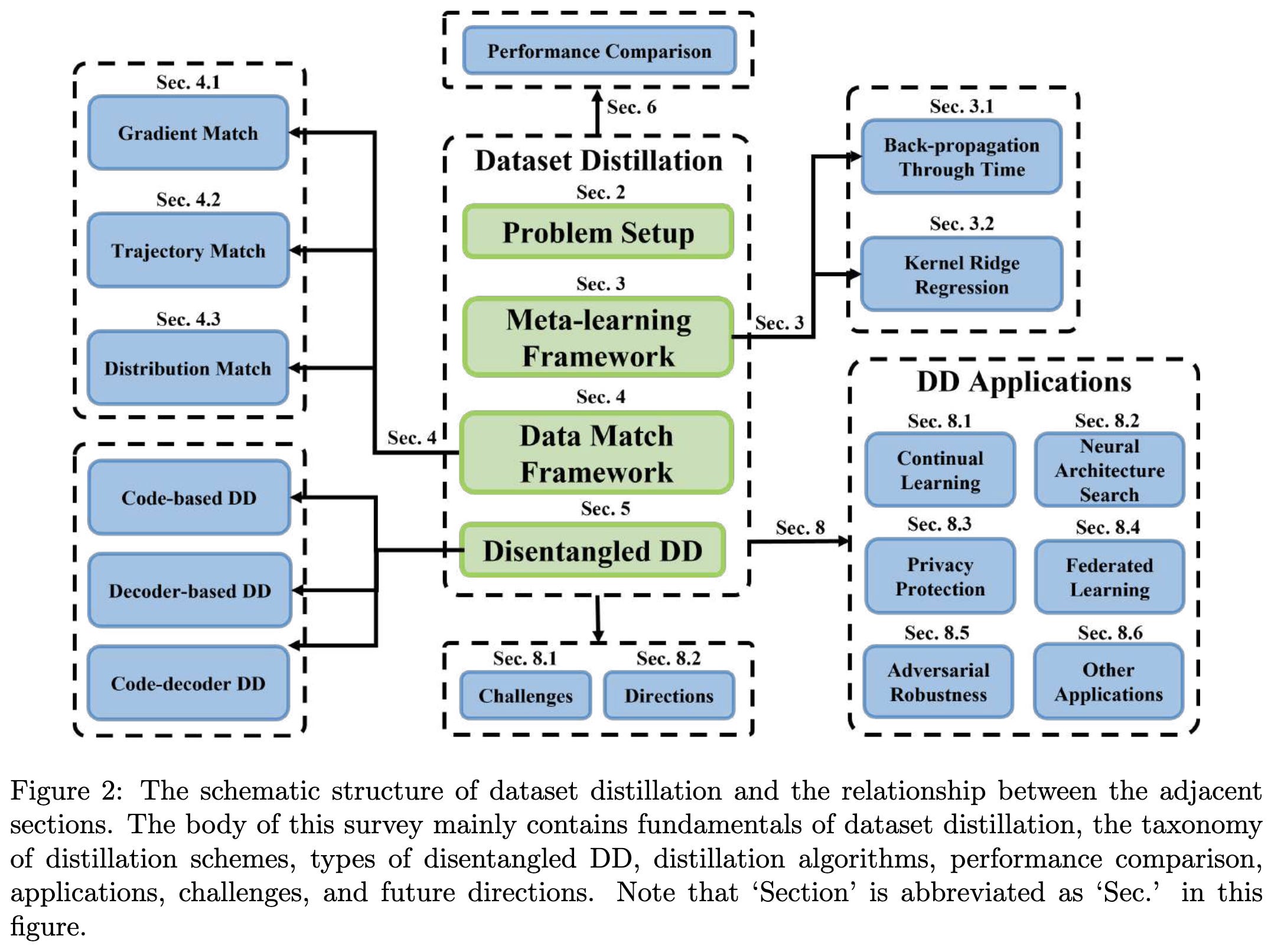
Dataset Distillation: A Comprehensive Review & A Comprehensive Survey to Dataset Distillation
We got two dataset distillation survey papers this week.
Both have nice taxonomies of existing methods,

explanations of different approaches,
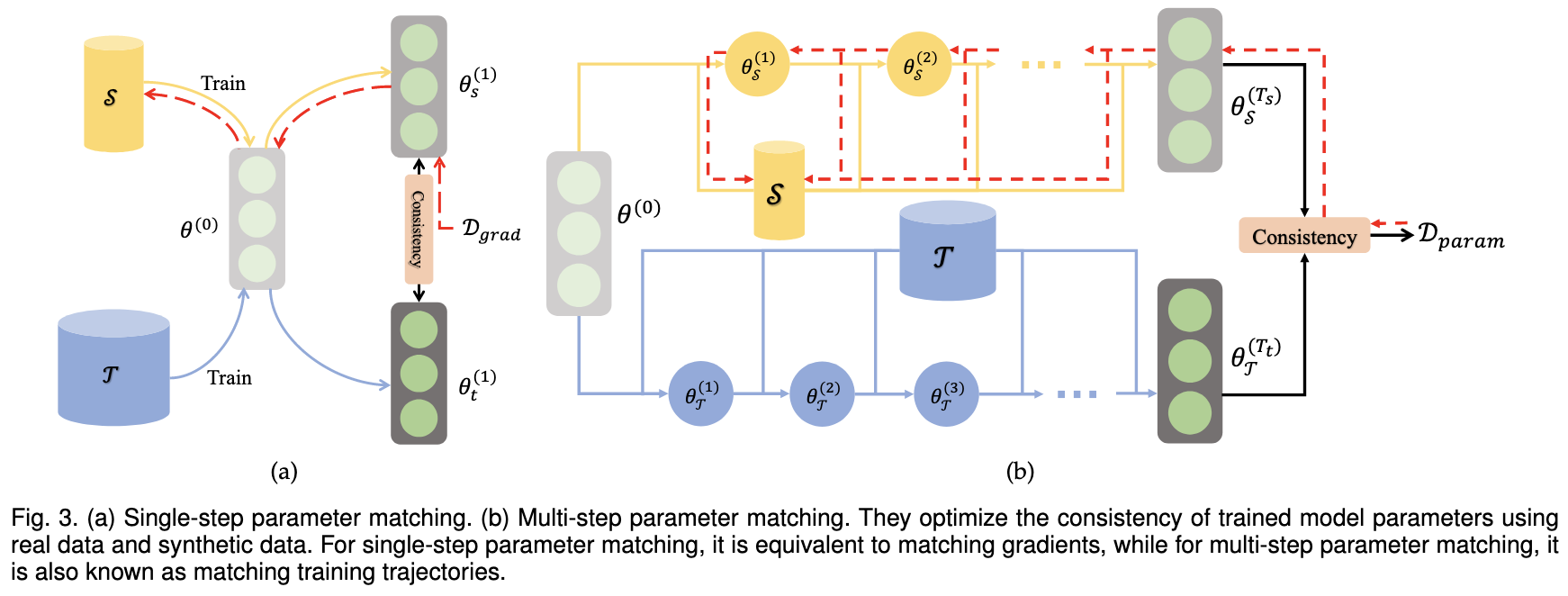

and overviews of results from published methods.


It doesn’t seem like dataset distillation is working super well yet on large datasets, although there also aren’t that many results even trying it; papers mostly seem to target the few-shot regime on small datasets. I’m most curious about whether we can get smaller gains on bigger tasks—e.g., ripping out 25% of the training steps on ImageNet without accuracy loss would be a nice win.
Masked Vector Quantization
They use a more complex VQ setup to improve image generation quality with VQ-VAE variants.

In a VQ-VAE, you map your input to a discrete latent code. Normally, this code consists of a vector of categorical random variables, with each variable termed a “codebook.” Instead of having one encoder and a single latent code, this work has two encoders and three latent codes.
The first and second codes are the outputs of the two encoders.
The third code is a binary mask that zeros out some of the random variables in the second code. To get this code, they just try a lot of possibilities and take the best one for each input.

What defines the “best one”? To answer that, we need to look at how the three codes get combined. It’s basically this equation, where f is yet another neural network:

In short, by adding in a couple more neural nets and a randomized search, they find latent codes with (it seems?) really low quantization error. Plus there’s some amount of regularization from the third code masking out part of the second one.
In exchange for this extra compute and complexity, they get much better image generation:
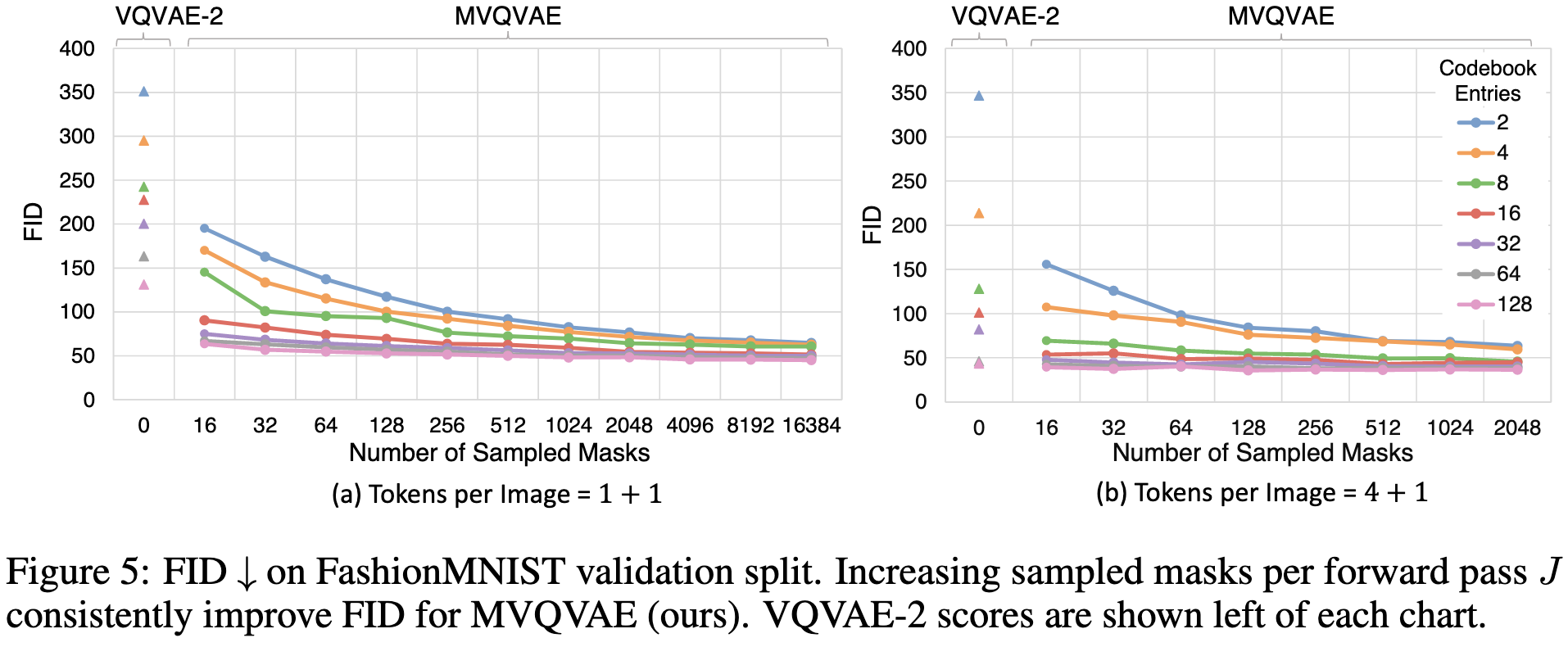

These are strong gains, although it’s not clear to me what’s behind them. The method is kind of a mashup of Local Search Quantization and Additive/Residual Vector Quantization, with an extra neural net in there to really get the quantization error down. Maybe the lesson is that lower quantization error is super important for generation quality? Or maybe that stochastic encodings are a win?
I’m also curious how to reconcile this with other results that find that adding quantization (and therefore quantization error) to bottlenecks lifts accuracy.
First Three Years of the International Verification of Neural Networks Competition (VNN-COMP) & The Third International Verification of Neural Networks Competition (VNN-COMP 2022): Summary and Results
How good are we at proving properties of neural nets? Not too good, but at least we’re improving.
Some example “properties” here include robustness to L_inf perturbations of the input, regression results falling in a certain interval around the right answer, and monotonicity of outputs with respect to inputs.
Even in the latest iteration of this challenge, the models and datasets considered aren’t especially large. But they have been getting bigger over time, and this might also stem from the competition only allowing a small compute budget (think minutes on an EC2 instance).
The most successful approaches are currently based on propagating constraints with branch-and-bound algorithms, with some mixed integer linear programming and other techniques thrown in.
I’m kind of surprised we can formally verify neural net properties at all, so it’s cool to see that there are so many positive results and so much apparent progress.

EENet: Learning to Early Exit for Adaptive Inference
They obtain a better average inference latency vs accuracy tradeoff via early exiting.
If you haven’t seen early exiting before, it just means making predictions for some samples using only a prefix of the network, rather than the whole thing. The idea is that the network can get away with doing less work for easier inputs.

Compared to other approaches, theirs focuses less on specific models and early exiting heuristics, and more on constructing an exiting policy based on the utility of exiting at a given point and the probability of the exit ruining the prediction.

Their method seems to outperform at least a few baselines. I’m really happy they reported actual latency vs accuracy here.

This and other papers make me suspect that early exit is a worthwhile speedup technique, although the literature isn’t as clear as for, say, mixture of experts.
Mostly early exit just 1) makes so much sense intuitively, and 2) seems more general than fixed patterns of token dropping or merging, which already do pretty well. Although perhaps the constraint that you stop computing on a per-sample rather than a per-token basis is detrimental.
Hello Davis, thanks again for a great summary! I'm Dusan, Ops Director for PIBBSS - I've reached out to you on LinkedIn as I was unable to find an up-to-date email address on which to reach you. We'd like to ask you to promote the opportunity to attend the PIBBSS 2023 fellowship to your mailing list, as many people applied thanks to you last time! If you have any questions or would like to use the shareable snippets we have, please reach out, you can use the email I have here.
Best,
Dusan