


2022-10-2 arXiv roundup: GPT-3 for $500k + Do we even need pretrained models?

Mosaic LLMs (Part 2): GPT-3 quality for <$500k
We showed that, based on the Chinchilla scaling laws, you can train a GPT-3-quality model for less than half a million dollars. This is around 10x cheaper than the original price, depending on whose estimates you believe.
Here’s a twitter thread about how we did it that I spent way too long polishing:


Oh, and one part I didn’t get to fit in the thread: this model is the baseline. We haven’t gotten to speed it up 5x+ yet like we did with ResNet-50. So the cost will soon be much lower than $500k.
Dilated Neighborhood Attention Transformer
Neighborhood attention is an elegant alternative to awkward overlapping-window schemes for vision transformers. It just has every pixel attend to a fixed-size neighborhood around it, which is kind of the obvious way to do local attention if you aren’t worried about shoehorning your code into existing CUDA kernels.
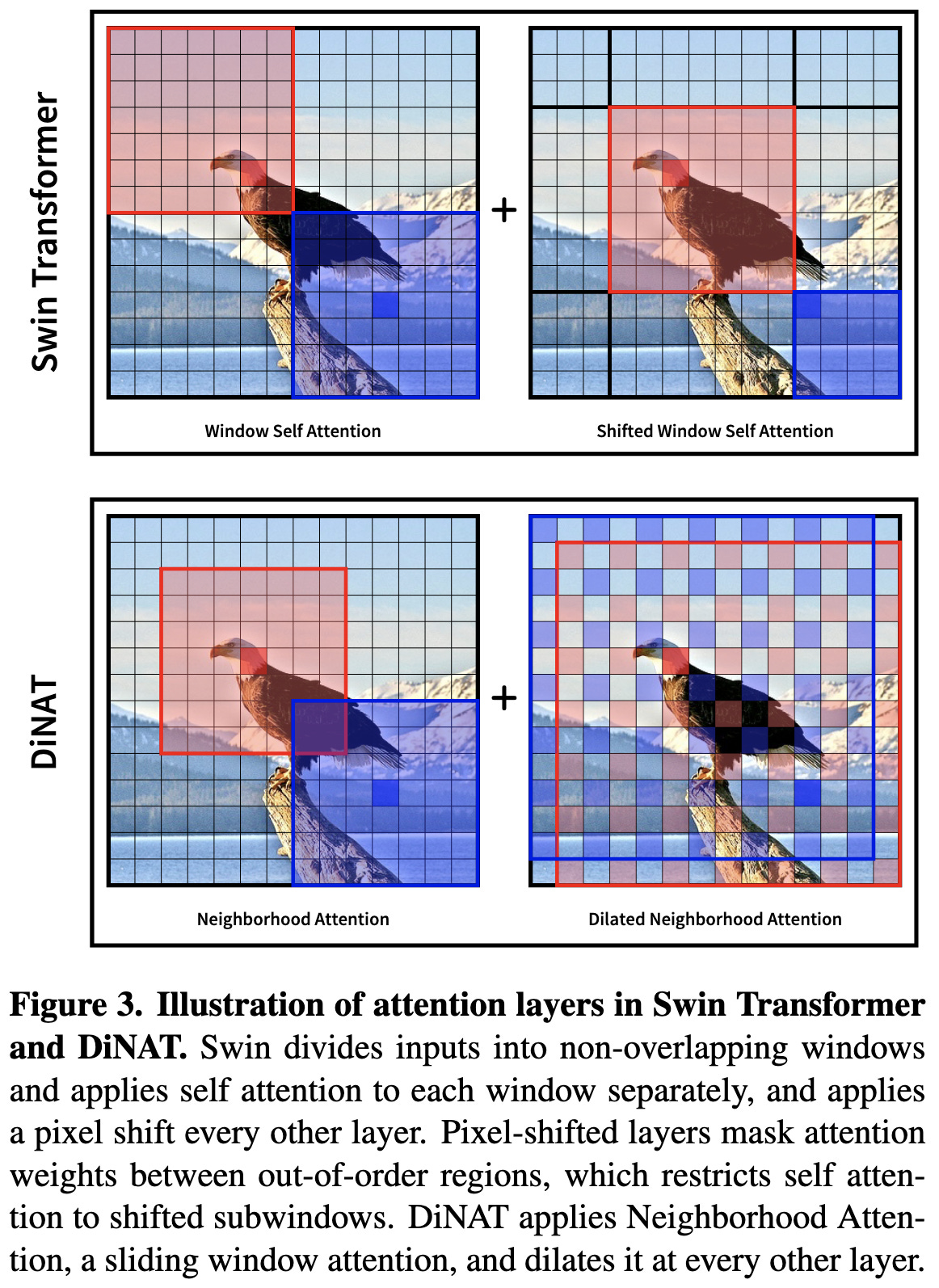
In this paper, the same authors generalize neighborhood attention to allow dilation.
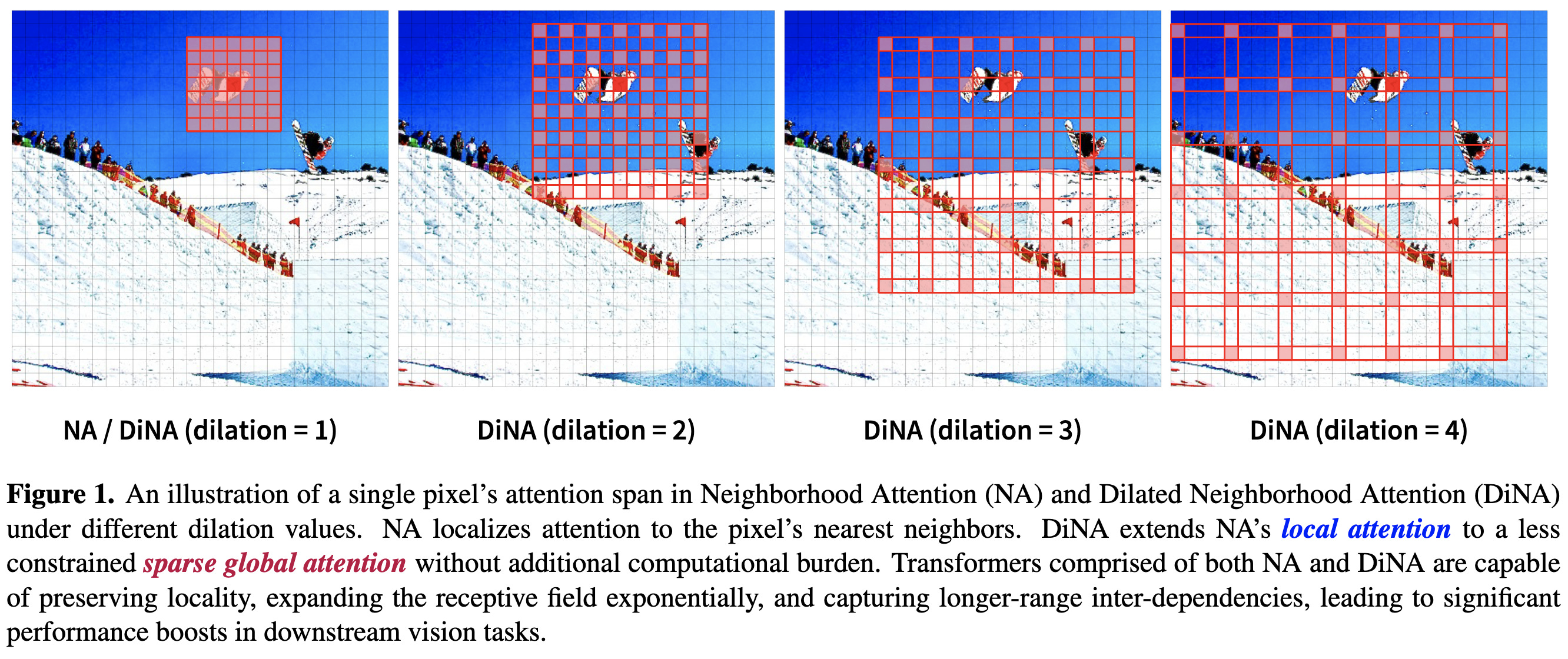
The inductive bias of dilation is that it mixes spatial information on much larger scales without downsampling or increased compute.

You could probably incorporate dilated neighborhood attention into almost any vision transformer, but they just add it to the simple transformer they used in their previous work.

This model beats ConvNext variants at iso FLOP and param counts, but fares the same when holding throughput constant. It beats Swin by ~1% at iso throughput. It’s not clear that their added dilation helps, but it is cool that their CUDA library can do the dilation with no throughput hit.

ConvNext seems to just plain be better than their model at high resolutions, though maybe using smaller window sizes would help.

I really like that they have controlled comparisons between progressive downsampling and isotropic (fixed spatial size) networks. I’ve been wondering for a while whether gradually downsampling throughout a model is just cargo culting + intuition, and it looks like the answer is no; downsampling buys 1-2% more accuracy at iso throughput.

Interestingly, among isotropic architectures, ViT actually does the best, even holding throughput constant.

It also appears to be the case that dilation (as embodied by their method) helps a lot more for object detection and instance segmentation than image classification.

Dilation also helps for semantic segmentation.

There’s some evidence that you should gradually increase dilation values up to the maximum allowed by your spatial size, doubling every layer whenever possible.

Overall I really like this paper. The model isn’t clearly a new SoTA for vision tasks, but it’s super simple and they have tons of careful experiments answering lots of questions I’ve been curious about for a long time.
Scaling Laws For Deep Learning Based Image Reconstruction
They investigate scaling with respect to dataset and model size for image denoising and compressed sensing. They find that, at small scales, there does seem to be a fairly steep power law. But at larger scales, this power law plateaus or goes away.

This holds even with a state-of-the-art transformer model for this task, suggesting it isn’t a CNN vs transformer disparity.1

The question is why they aren’t seeing clean scaling laws that hold over many orders of magnitude. Some possible explanations:
It’s an artifact of not including an irreducible loss term in the scaling formula.
The PSNR and SSIM metrics mess it up. E.g., if you have power law scaling in -log(p), you won’t see power law scaling in p.
Quirks of their experimental setup.2 E.g., they use learning rate decay-on-plateau, which eventually yields tiny learning rates.
The clearest lesson from this paper is that power law scaling isn’t always present, even for transformers. A lot of us have seen this in practice, but there aren’t many papers to cite that back this up.
This paper is even more valuable though as raw data to be explained in our quest to understand neural net scaling.
In-context Learning and Induction Heads
They present various forms of evidence that “induction heads” are much of the mechanism underpinning in-context learning (i.e., using examples baked into the prompt).

Induction heads are heads within pairs of self-attention layers that learn to complete the next token in a sequence.
The first layer copies part of the next token’s embedding into the current token. E.g., for the substring “AB”, it would mash up the A and B embeddings such that A’s represents “current: A, next: B”.
The second layer, when trying to figure out what should come after a later occurrence of A, 1) finds a previous occurrence of A, and 2) attends to whatever comes after it. I.e., it sees the embedding encoding “current: A, next B” and uses that to conclude that, for this new A, the next token should be B.

This paper is long, super thorough, and careful about exactly what it claims based on the experiments. It mostly made me want to sit down and think about what sorts of functions I could express with and without attention layers.
Two-Tailed Averaging: Anytime Adaptive Once-in-a-while Optimal Iterate Averaging for Stochastic Optimization
Normal weight averaging has these awkward hparams for when in training you start the averaging, which time steps you use in the average, etc.
They propose a simple and theoretically-grounded algorithm that avoids setting these hparams.

I tried writing my own description of the algorithm but theirs is already great:

The evaluation isn’t super thorough, but it seems to work reliably:

Hebbian Deep Learning Without Feedback
They add some fancy tweaking on top of the SoftHebb algorithm to make it work better. In particular, they:
Use exotic, tunable elementwise activation functions,
Use learning rates that tend to keep a given neuron’s weight norm 1, and
Negate of the normal update rule for neurons other than the most active one within a given softmax.

Seems to yield the least bad biologically plausible learning rule:


Do Current Multi-Task Optimization Methods in Deep Learning Even Help?
Nope. Published MTO methods are never better than just using a convex combination of the losses from different tasks (“scalarization,” implemented as proportional sampling for NMT tasks).


Sometimes MTO methods are better than other MTO methods, but they’re never better than the simple baseline. This can give the false impression of progress when the baseline is omitted from papers.
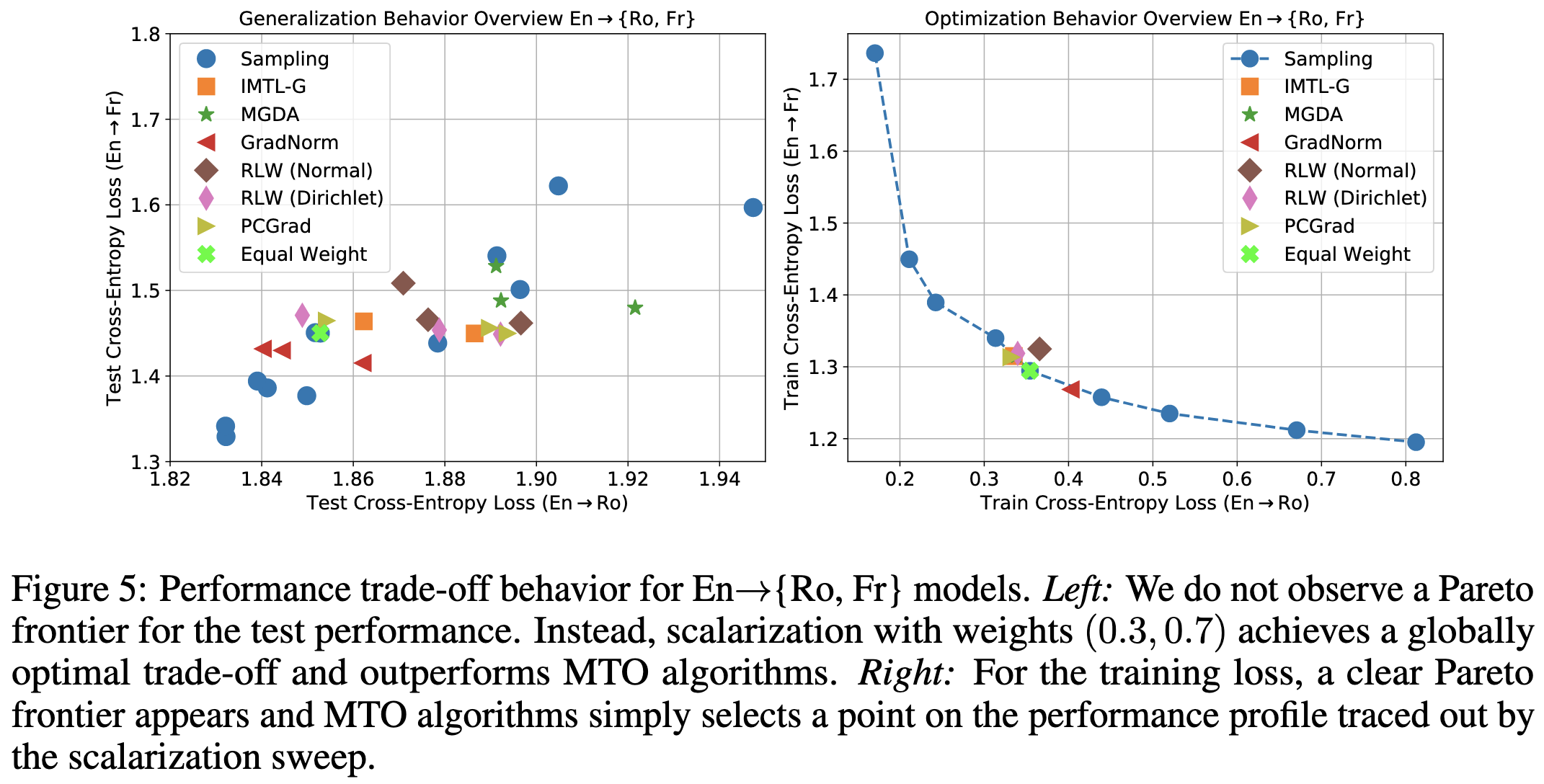
One big confounding factor in comparisons between MTO methods is that the hparams often matter much more than the method chosen.

Similarly, even if you hold the hparams constant across methods, different hparam settings will favor different methods.

Can you avoid these issues by just taking the results from other papers’ results tables? No; different papers often get really different results for what’s nominally the same setup.

Adding this as another entry in my big list of discouraging ML meta-analyses.
An Embarrassingly Simple Approach to Semi-Supervised Few-Shot Learning
Proposes to gradually label your samples by training your model to not predict the labels that the model is most confident aren’t the true class. So you iteratively blacklist classes, until eventually you have a label for each data point (the last class to not be ruled out).
I’m not sure how well it does when holding training time constant, but it seems to yield high accuracy in absolute terms:
Also, adding a properly-tuned “reject” threshold helps. This threshold is used to stop adding negative pseudo-labels to a sample when the least probable class doesn’t have low enough probability.

I’m not certain this method is “embarrassingly” simple since I’m still a little confused about the exact pipeline for using and updating the pseudolabels (e.g., is the training time proportional to the number of labels? When a sample’s least probable class is above the threshold, do we discard it, or just not expand the pseudo-labels this round? etc). But it is fairly simple and it seems to work well, which is always a good combination.
Efficient Non-Parametric Optimizer Search for Diverse Tasks
They’re trying to search for better optimizer update rules than Adam, SGD, etc. The core observation is that any practical program, including an optimizer, can be expressed as a parse tree.

So they construct one giant expression tree full of gradients and mathematical functions, and sample subtrees using Monte Carlo tree search.

Here’s what goes in their tree:

To quickly eliminate unpromising trees, they first sanity check whether the optimizer actually makes the loss go down.

They also compress subtrees whenever it’s possible to do so without changing the semantics.

It seems to maybe do better than alternatives based on small-scale experiments (e.g., CIFAR-10 with a two-layer network).

Probably the most compelling result is that it seems to beat AdamW for BERT finetuning on GLUE.

Their full approach does about 1% better than just sampling from their expression tree at random.

Mostly what I think is interesting here is the generality of treating a program as a parse tree and sampling from that tree; if we could figure out how to do this well, you could apply it to almost any part of a machine learning program.
Exploring Low Rank Training of Deep Neural Networks
They seem to show that initializing a factorized layer with the SVD of a regular layer helps accuracy. Although they never define “spectral ones” or what the baseline is, so I’m not how to interpret this.

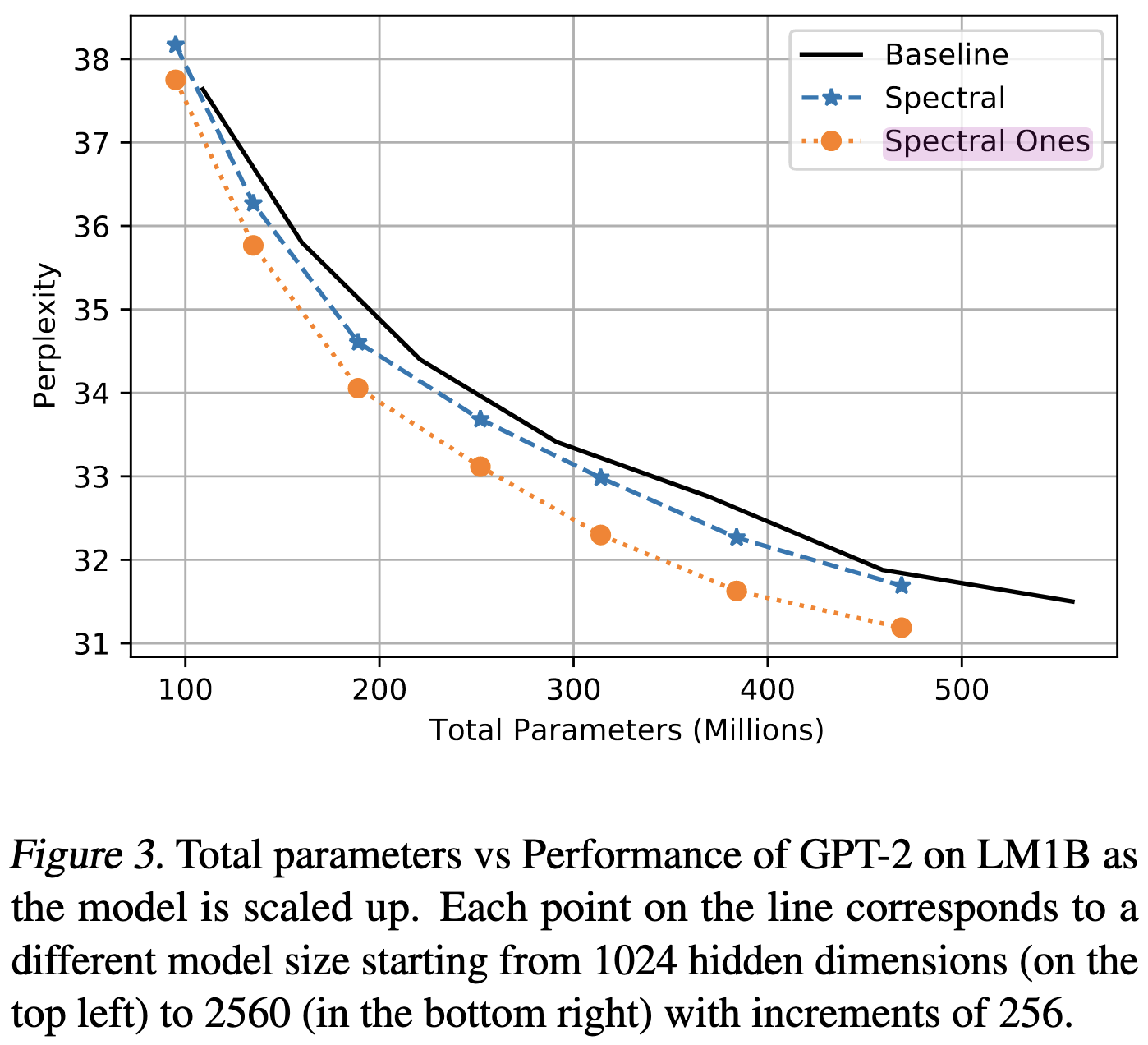
Also, “We find that pre-training does not offer improved performance compared to low-rank network trained from scratch in our vision experiments.” Unclear if this holds in NLP experiments.

Had a hard time making sense of this paper, but the finding that you can just factorize from the outset is valuable. This is a way simpler pipeline than trying to factorize partway through training. Trust me, I’ve tried it.
Outlier Suppression: Pushing the Limit of Low-bit Transformer Language Models
They decouple the layernorm scale parameters from the rest of the layernorm to help quantization, instead fusing the scale into subsequent ops.

Seems to beat the subset of other quantization methods they compare to:

The main thing I like about this paper is this next figure, which shows a histogram of (elementwise?) activation magnitudes. They can clip most of the extreme activations without any accuracy loss, though it’s not obvious how to find the exact threshold.

Liquid Structural State-Space Models
Like S4, but they use this state-space model, with x the latent state, u the input, and y the output:

They unroll this SSM in time to turn it into convolutions, truncating higher-order terms based on a “degree” hparam.

They then combine this with a bunch of math tricks taken from the S4 paper (normal plus low-rank matrices, Woodbury identity, etc).
Seems to beat every S4 variant on the long-range arena.

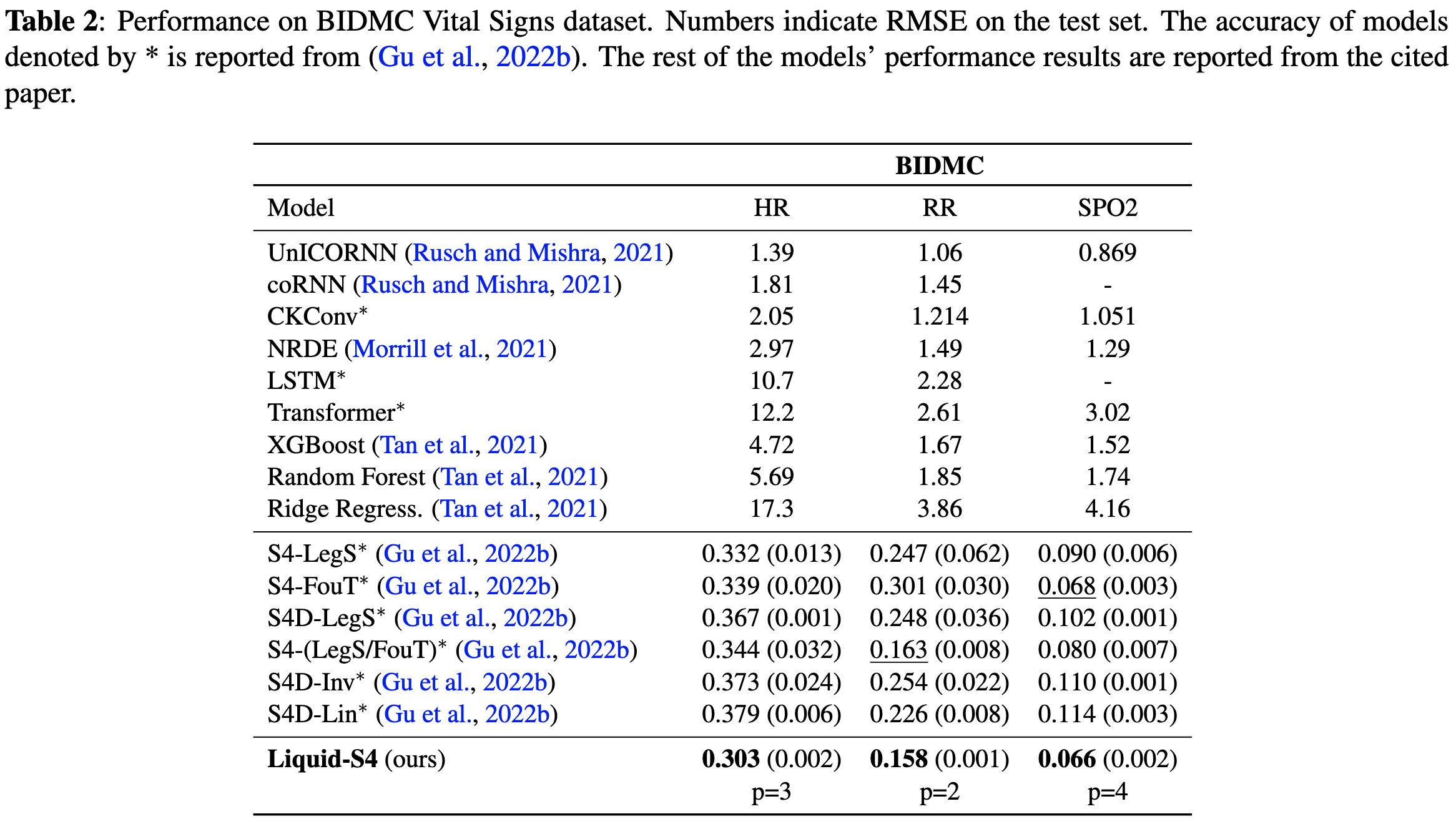
I kind of believe these results (though note there are no timing numbers…), but the recent uptick in SSM variants [1, 2] feels a lot like when there were tons of papers making up RNN cells.
It’s also weird to me that SSMs basically are RNN cells, but with some unrolling + esoteric math on top. What’s actually driving the improvements here? Did we just need to impose certain structure on our RNN state transitions this whole time? Is there a 10x simpler method to be had? I’d love to see someone lay out some clear thinking + ablations here.
Variance Covariance Regularization Enforces Pairwise Independence in Self-Supervised Representations
If you center and flatten the kernel matrices for two sets of observations X1 and X2, you can upper bound the correlation between them under any feature-wise transform. This upper bound is zero iff X1 and X2 are independent.

You can then prove that VICReg, with some slight modifications to make the proofs work, learns pairwise independent feature representations. Modifications include, e.g., using random means and variances in the batchnorms to get something more closely resembling a kernel.
I already thought VICReg was one of the more elegant SSL methods, and having an efficient algorithm for independence estimation is a cool hammer for the toolbox.
Batch Normalization Explained
With piecewise-linear activation functions like ReLU variants, your whole neural net is a piecewise linear function. The way to think about this is that, unless it’s right at the boundary between two linear regions (which happens with probability 0), each activation is actually linear. So, locally, your network is linear. But when you move too far, some activations get perturbed to a different region and your linear function changes.

So what they argue in this paper is that batchnorm chops up the input space in a reasonable, data-dependent way. This argument is mostly math, but they also show that using batchnorm stats to offset + scale your initialization helps training a lot:

They also prove that batchnorm increases classification margins by randomly jittering activations.

I’d argue that “batch normalization explained” is perhaps too expansive a title, but this is definitely interesting work. Always nice to see alignment between theory and reasonable-scale experiments.
Re-Imagen: Retrieval-Augmented Text-to-Image Generator
They added an image retrieval mechanism to Imagen.

In a little more detail, they have a database of 50M clean image-caption pairs, and they use either BM25 or CLIP to retrieve neighbors from this database based on the textual input prompt.
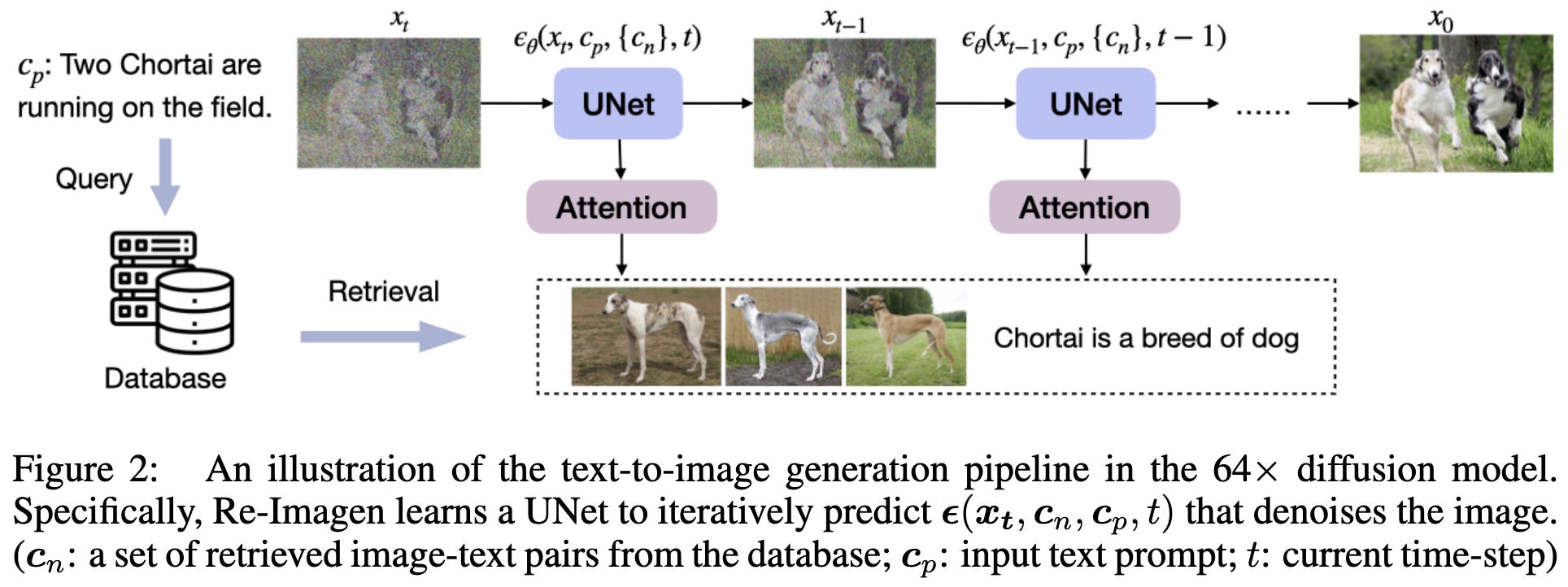
They then run the retrieved images through the encoder of their U-Net and use cross-attention to update the U-Net encoder’s representations for the image being generated.
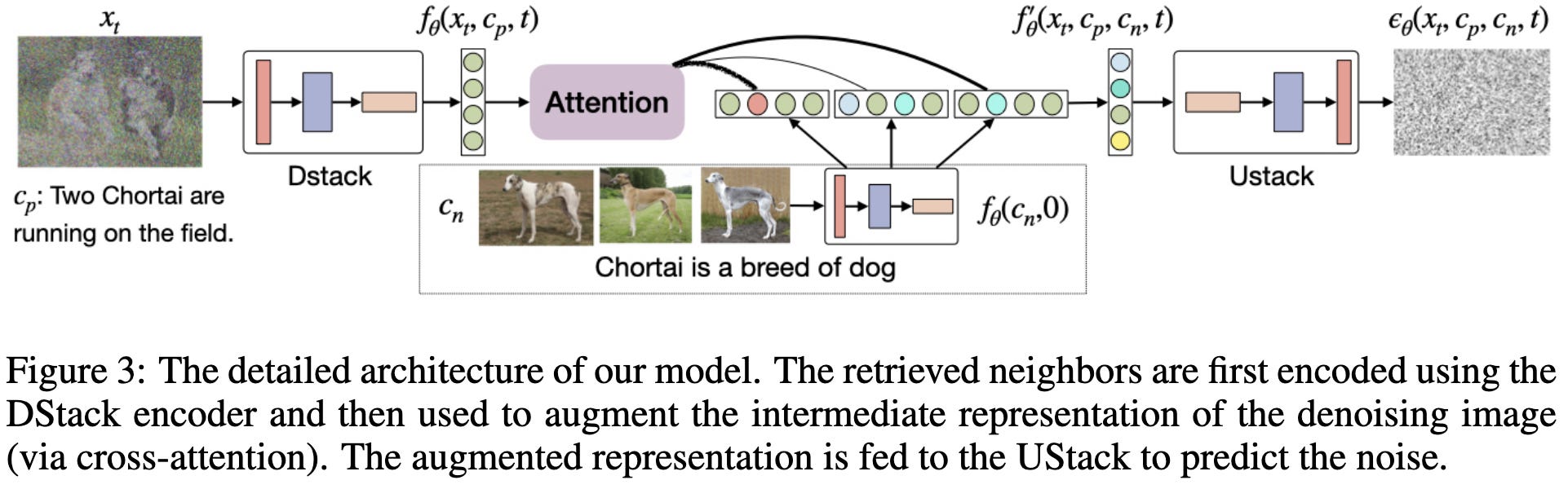
Seems to work better than the original Imagen.
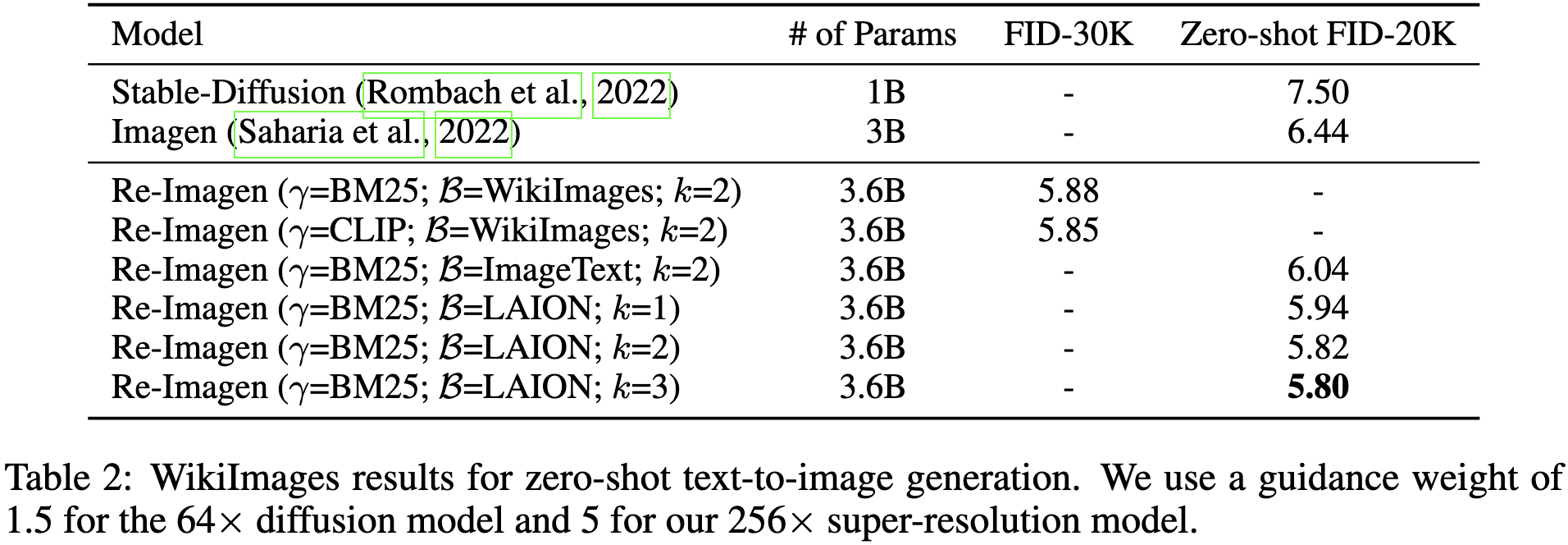
This is especially true when generating images of rare entities.

This is further evidence of the power of retrieval to lift accuracy, although their lack of timing numbers makes it unclear whether this is an improvement to the Pareto frontier. In particular, having to run more images through the encoder is a significant amount of overhead.3
Downstream Datasets Make Surprisingly Good Pretraining Corpora
You can get basically the same benefit from pretraining on just your “finetuning” dataset as from pretraining on a large, separate corpus.

This holds across a variety of different tasks with different training set sizes. In a majority of cases, pretraining on only the target task is better than pretraining on a separate corpus.
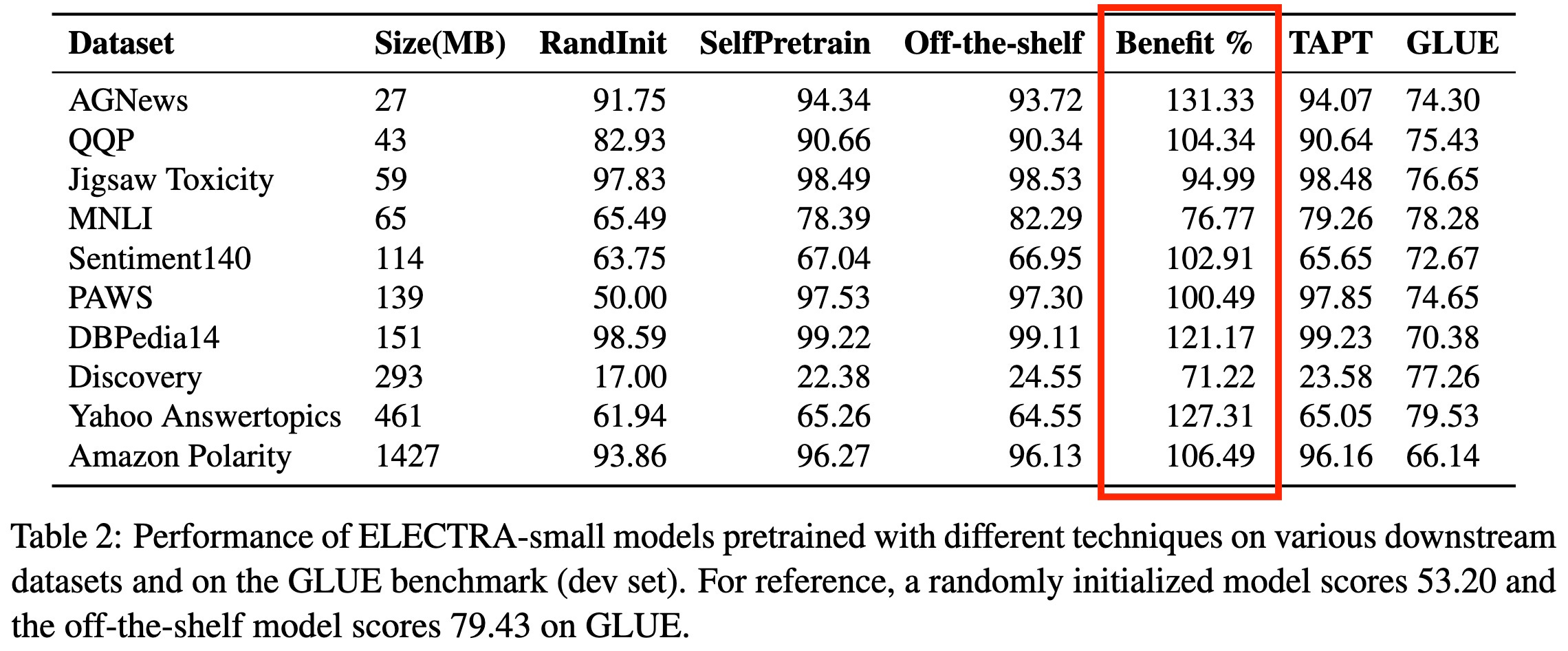
The other surprising finding here is that they often do better than TAPT from Don’t Stop Pretraining, which starts with an off-the-shelf pretrained model instead of a randomly initialized model. Sadly, no pretrain→finetune pipeline is always the best, so it looks like we’ve got another hparam to tune.
These findings seem to generalize to larger models as well. And, encouragingly, what pipeline works best is mostly consistent within a dataset.

Pushing their results further, they find that models pretrained on one target task also transfer pretty well to other tasks. The exact efficacy varies based on the task pair. Although these pretrained models don’t transfer as well as off-the-shelf models pretrained on a more general corpus (which would obtain a value of 1.0 below).

Putting all this together, it sounds like:
Pretraining on a large, general-purpose corpus helps when
a) the pretrained model is good enough with just in-context learning that you can avoid finetuning entirely, or
b) you care enough about downstream accuracy to finetune, but not enough to do unsupervised pretraining on your target task. I’m not sure when this would be—maybe if you’re just rapid prototyping? Or just want to quickly eval on all of GLUE or SuperGLUE?
This seems to contradict OpenAI’s Scaling Laws for Transfer. If irrelevant data just has some “conversion rate” to relevant data, starting with a pretrained model on a larger corpus should never be worse. I.e., TAPT should always beat both other approaches.
Seems like further evidence for Quality not Quantity with respect to data size vs relevance.
I don’t get how it’s ever better to start from a random init than a general-purpose pretrained model. You’d think cranking up the learning rate enough to escape your local minimum should suffice to never do worse (maybe it is and they just didn’t try this).
From now on, you have to determine for a given task a) whether to start with a general-purpose pretrained model, and b) whether to do unsupervised pretraining on your target task. Not getting both of these decisions right can have a large accuracy impact.
This feels like a really important paper. The field has slowly come to assume that an unsupervised pretrain→supervised finetune pipeline is the right way to do things—and, consequently, that we need giant pretraining corpora that only a few companies can get. If that’s not true and a small amount of task-relevant data suffices, this implies a world with way less centralization of AI4. E.g., companies can just pretrain models on their own data and not bother starting with someone else's pretrained model.
Bonus content: I thought the above paper was so interesting that I decided to go through some of the related work, so that’s the next few summaries. See also my past summaries of:
Insights into Pre-training via Simpler Synthetic Tasks (summary)
Branch-Train-Merge: Embarrassingly Parallel Training of Expert Language Models (summary)
And, to a lesser extent:
Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time (summary)
Patching open-vocabulary models by interpolating weights (summary)
Are Large-scale Datasets Necessary for Self-Supervised Pre-training? (2021)
They find hugely diminishing returns to self-supervised pretraining on ImageNet with respect to both sample count and number of epochs.

Although this level of insensitivity varies based on your pretraining dataset and objective.

Also you don’t need a fancy tokenizer for your vision model.

They also propose an SSL method similar to a typical masked autoencoder, but probably more efficient because it uses all the image patches.

Mostly they argue that their method works better on the most task-relevant data (COCO), and using the most task-relevant data helps.

So in vision too, the task-relevance of the pretraining data matters a lot. Though this is maybe a weaker result than some of the NLP papers, since they still do a large amount of pretraining (no 10x+ compute savings). It’s a little hard to tell though because they also get accuracy gains, rather than just preservation. Plus, as they show, the exact SSL objective you use is an important confounder.
Does Pretraining for Summarization Require Knowledge Transfer? (2021)
They generate nonsense sentences and pretrain models to complete elementary text manipulation tasks on these sentences.

Here are the elementary tasks they use:

With a T5-small, pretraining on this nonsense works just as well for downstream summarization tasks as pretraining on a real summarization corpus.

Pre-Training a Language Model Without Human Language (2020)

They use synthetic languages sampled such that they end up with sensible parse trees and similar unigram statistics as a target language.

Using variants of this artificial language, along with other “text” like amino acid sequences, can sometimes do as well as pretraining on English text for GLUE tasks.

They also claim that having the pretraining and downstream vocabulary sizes match up is important (I think vocabulary sizes are the numbers in parentheses in the bottom section of the table). Interestingly, the unigram statistics (uniform vs. Zipf) don’t seem to matter.
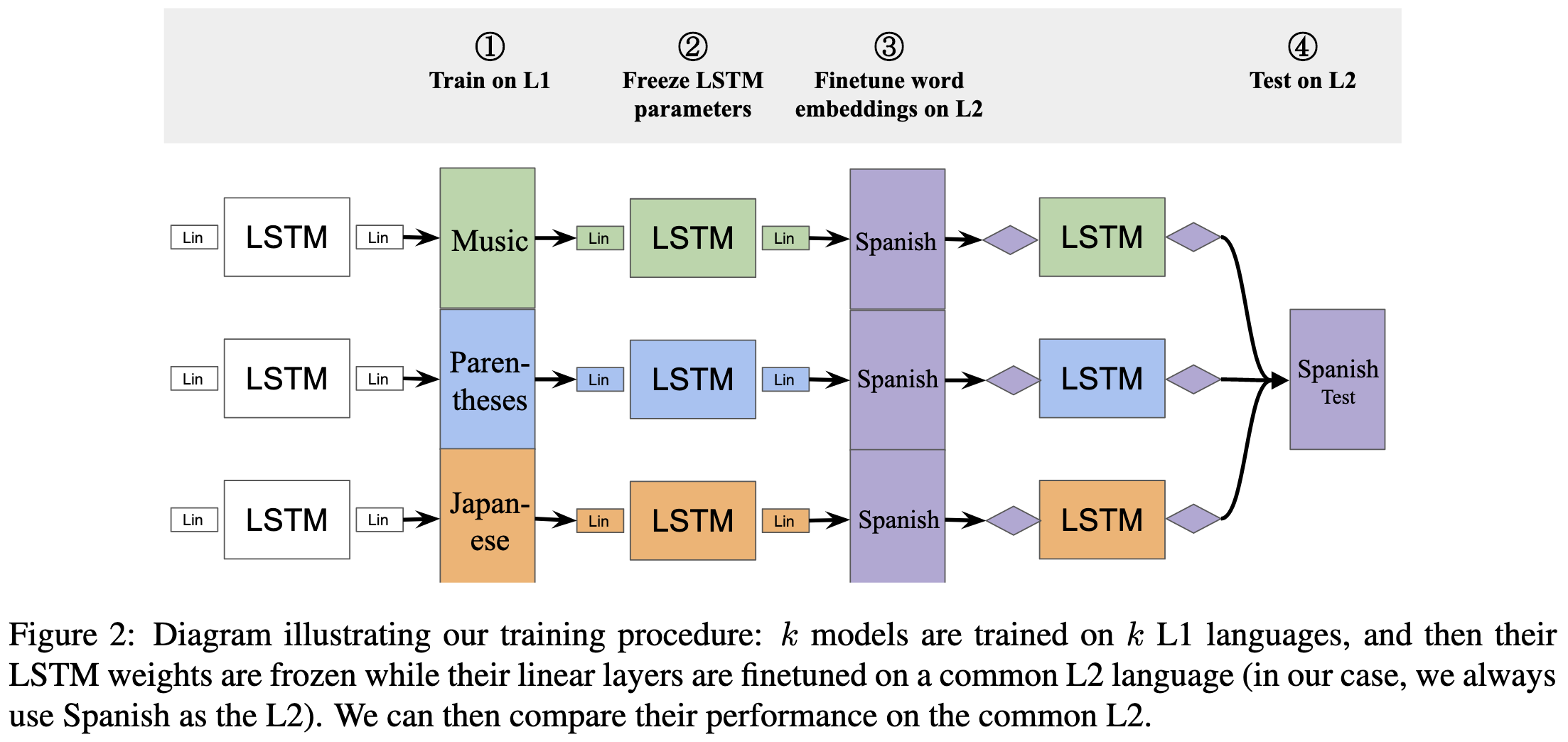
Learning Music Helps You Read: Using Transfer to Study Linguistic Structure in Language Models (2020)
Pretraining on more relevant text tends to improve downstream accuracy. But even pretraining on something like music, which has no syntactic or vocabulary overlap with your target language, can still help.

The only subtlety in their setup is that they use LSTMs and finetune just the last layer, as used to be the standard practice.
If you generate a synthetic language, adding more structure to it doesn’t help. Using a Zipf distribution for unigram probabilities helps slightly compared to a uniform distribution.

Languages that are more similar in terms of established linguistic features tend to have better transfer between them.
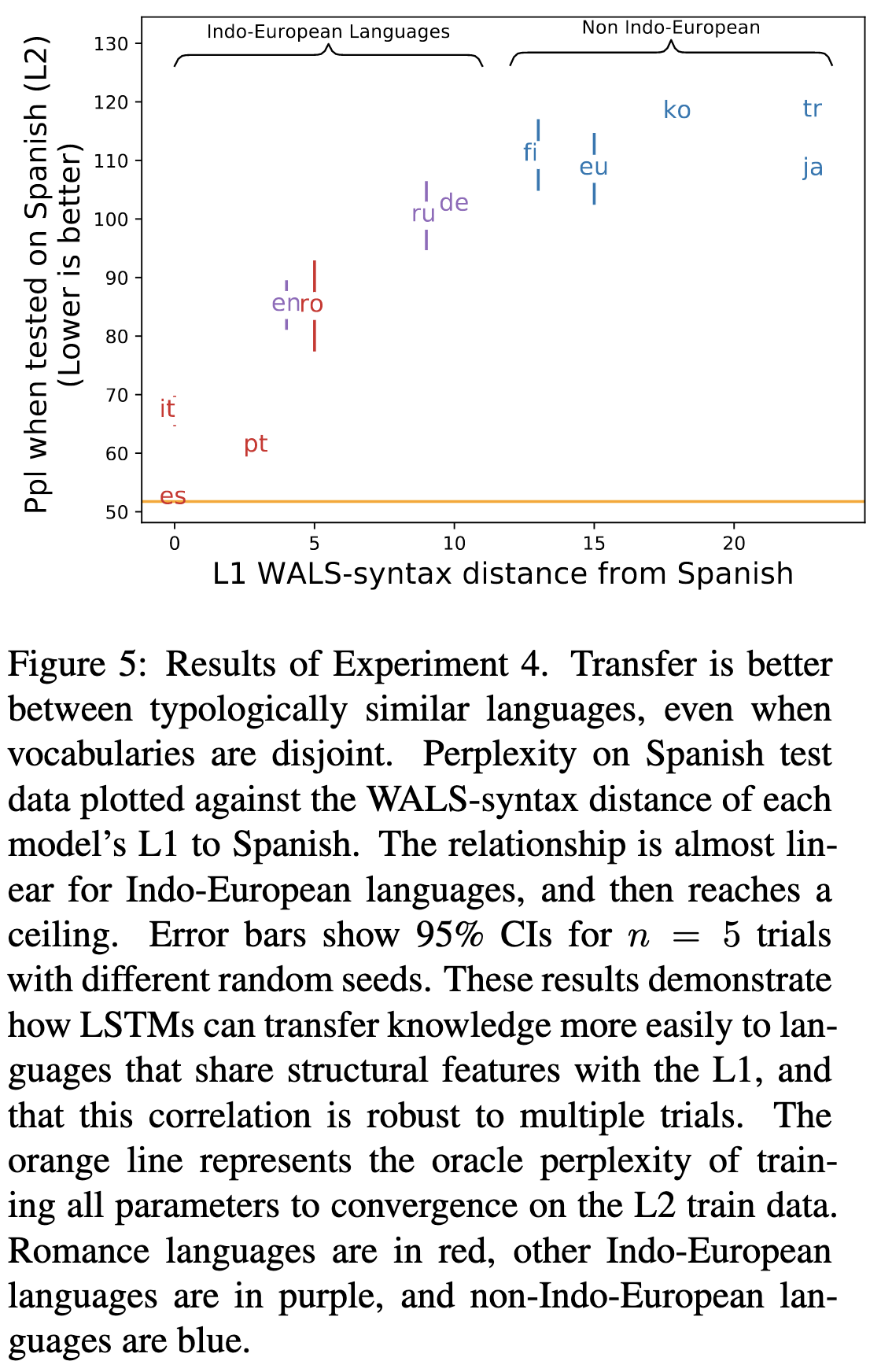
So putting these results together, I see two main findings:
There’s better transfer between more similar domains
Even simple languages with almost no overlap can still be useful for pretraining
Both of which are consistent with what we’ve seen in later work.
Yet again we fail to see evidence of transformers beating CNNs for vision when other variables are held constant.
They train U-nets and SwinIRs of sizes .1M to 500M parameters to denoise images with training set sizes of 100 to 100,000 samples. They use different optimizers for different tasks, all with some variant of learning rate decay-on-plateau (as opposed to a fixed learning rate schedule). They highlight that once the learning rate gets low enough, they see almost no further gains.
Their scaling is all width scaling—i.e., giving the layers more channels. The EfficientNet results suggest that pure width scaling isn’t the best strategy.
They also have some heuristic differences in setup across scales, like different initial learning rates and rates of learning rate annealing, but these to be products of genuine efforts to make each scale work as well as possible.
For the SwinIR experiments, they also reduce the epoch count as the model size and sample count grow. This is interesting because it decouples sample count from number of optimization steps, although it does couple number of optimization steps and model size.
Anyway, this one gets a more detailed experiment writeup than usual because one of these days I’m going to go back and try to reconcile all the scaling law papers.
Imagen uses an 11B parameter T5-XXL to encode the input prompt and a 2B parameter U-Net. So maybe running 2-3 more images through the U-Net doesn’t matter too much?
Even more grandly, that narrow intelligences will be just as good as general intelligences.