
2023-2-26 arXiv roundup: RLHF for diffusion, Multimodal chain of thought, Practical data poisoning

This newsletter made possible by MosaicML.
Poisoning Web-Scale Training Datasets is Practical
You can poison public datasets by buying domains / changing the content after the URL gets included in a dataset, or by transiently editing sites like Wikipedia right before they get scraped.
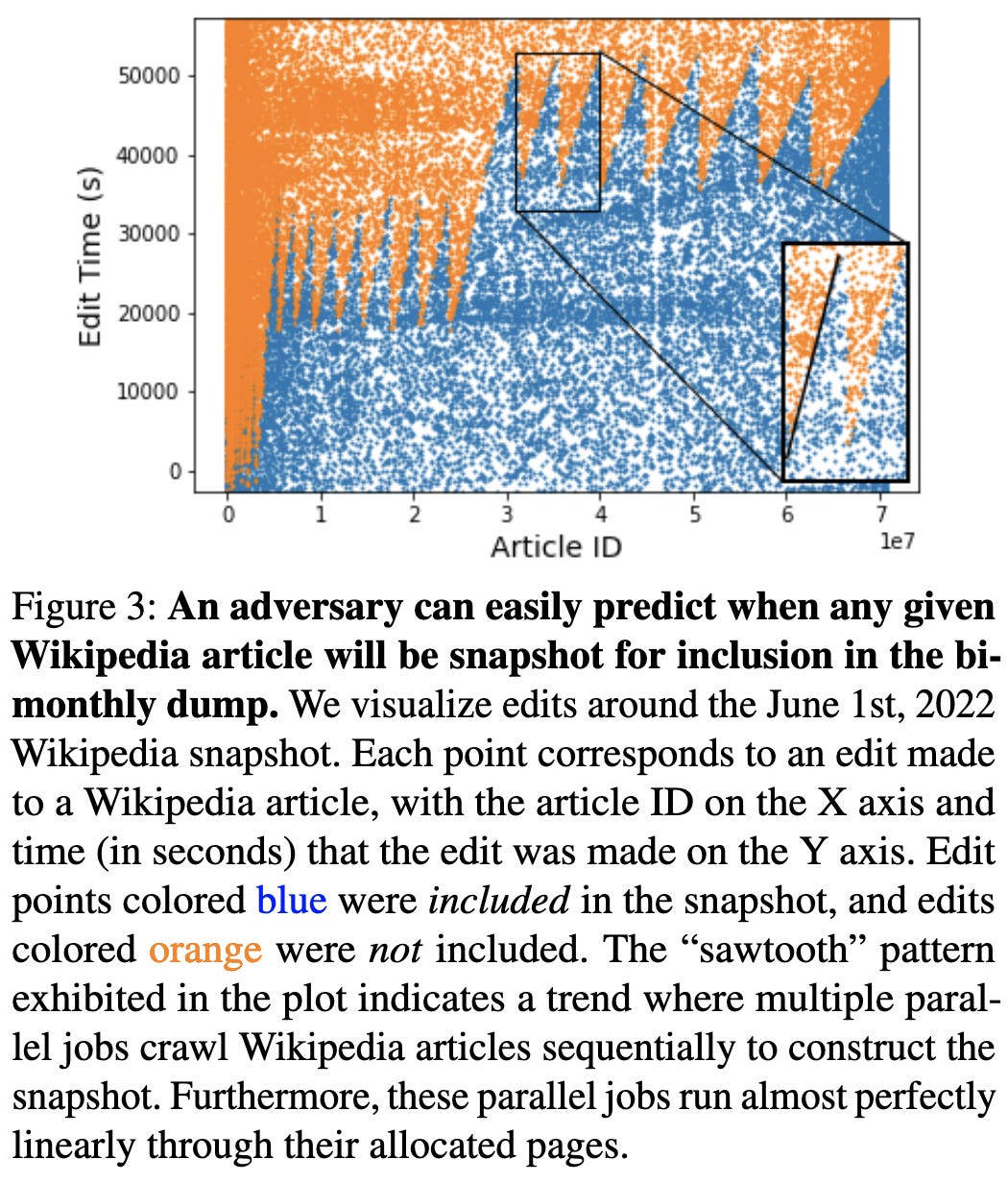
Using these “split view” and “frontrunning” poisoning attacks, you can cheaply compromise a decent fraction of some large-scale datasets.
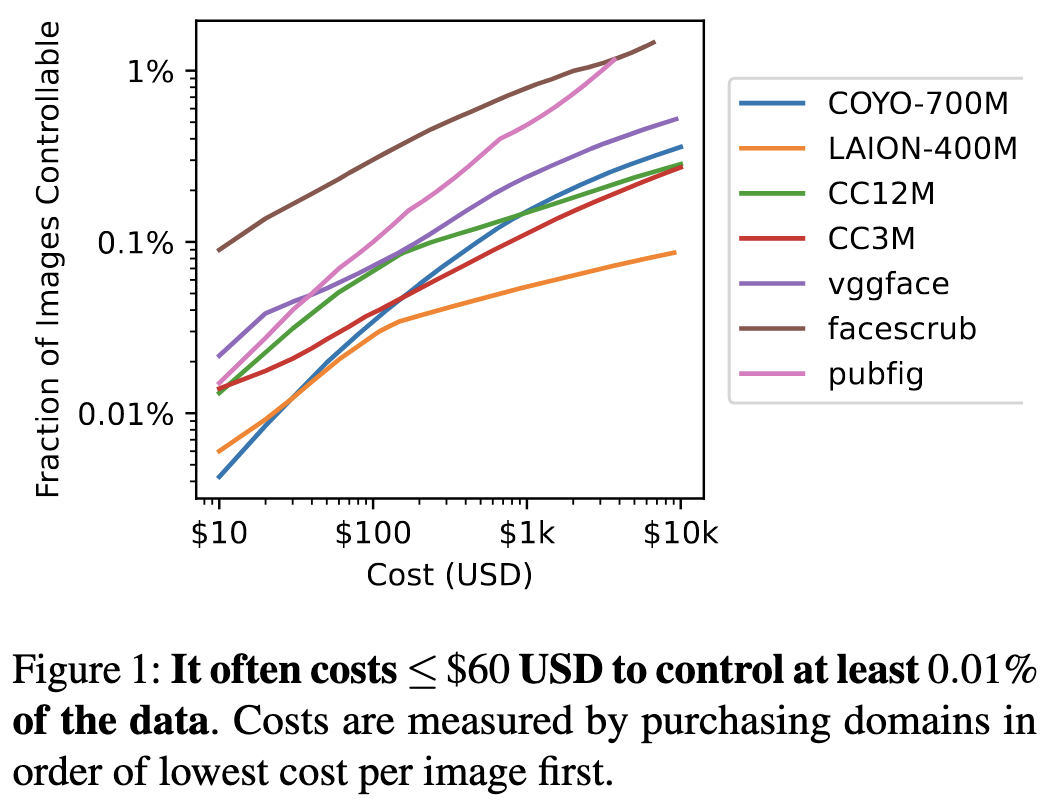
To avoid split-view attacks, you can store hashes of the content along with annotations. To avoid frontrunning attacks, you can revert malicious edits more quickly and/or randomize the times at which different pages get snapshotted.
Seems like yet another way in which the ML world is immature compared to most other industries. It also suggests some interesting incentive questions—e.g., even if Wikipedia knows their export procedure is vulnerable, will they pay the development costs to fix it? Is language model training a use case they care about? And what about Reddit, arXiv, PubMed, etc?
Scaling Laws for Multilingual Neural Machine Translation
They found clear power law scaling for translation.
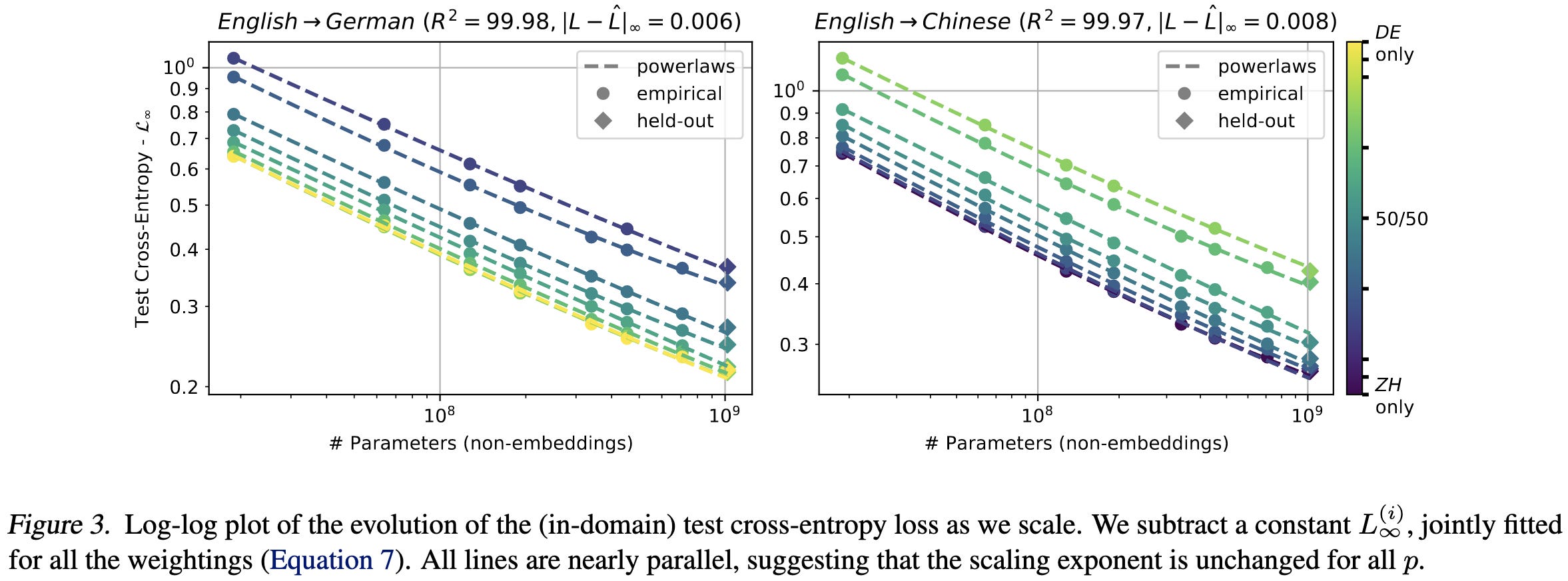
The scaling exponents seem to be insensitive to the weighting of languages in the corpus.
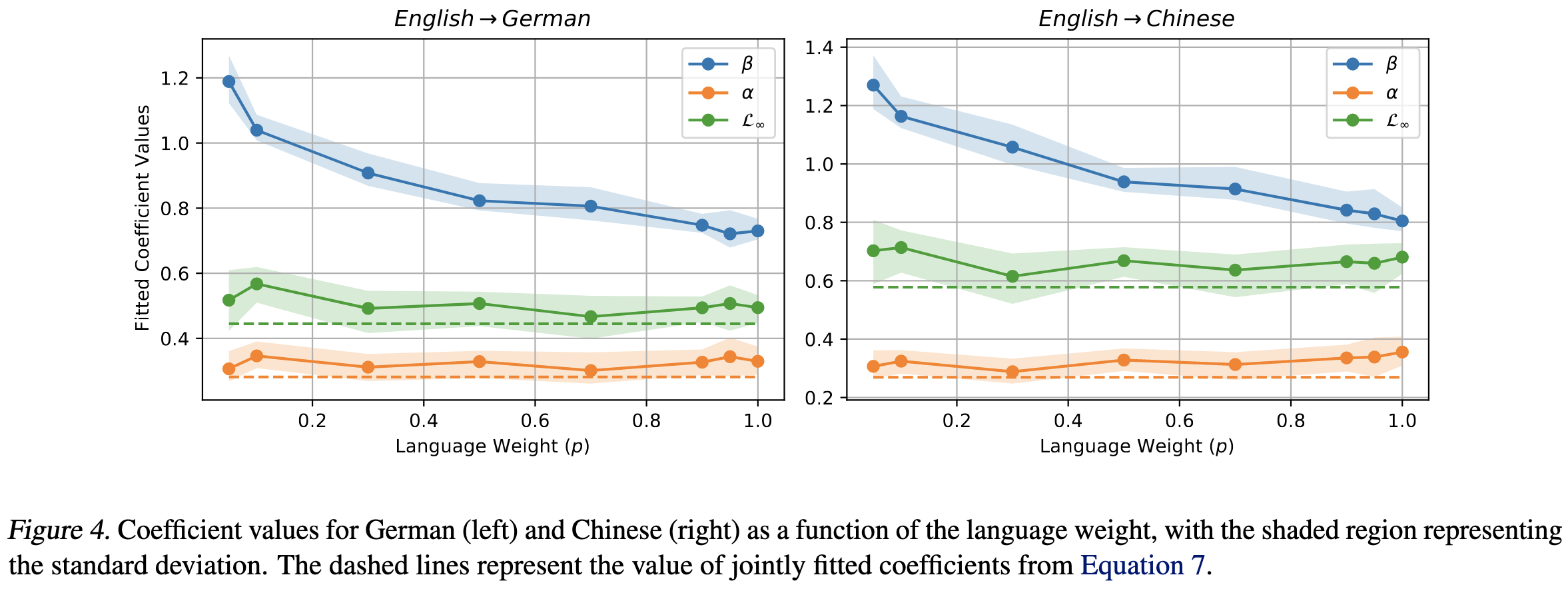
Similarly, the effective number of parameters allocated to a given language pair (computed using the fitted scaling formula) seems unrelated to the similarity of the languages.

Surprising to see language similarity not matter, but encouraging to see clean power law scaling yet again.
A Comprehensive Survey on Pretrained Foundation Models: A History from BERT to ChatGPT
A long paper offering a pretty comprehensive history lesson.
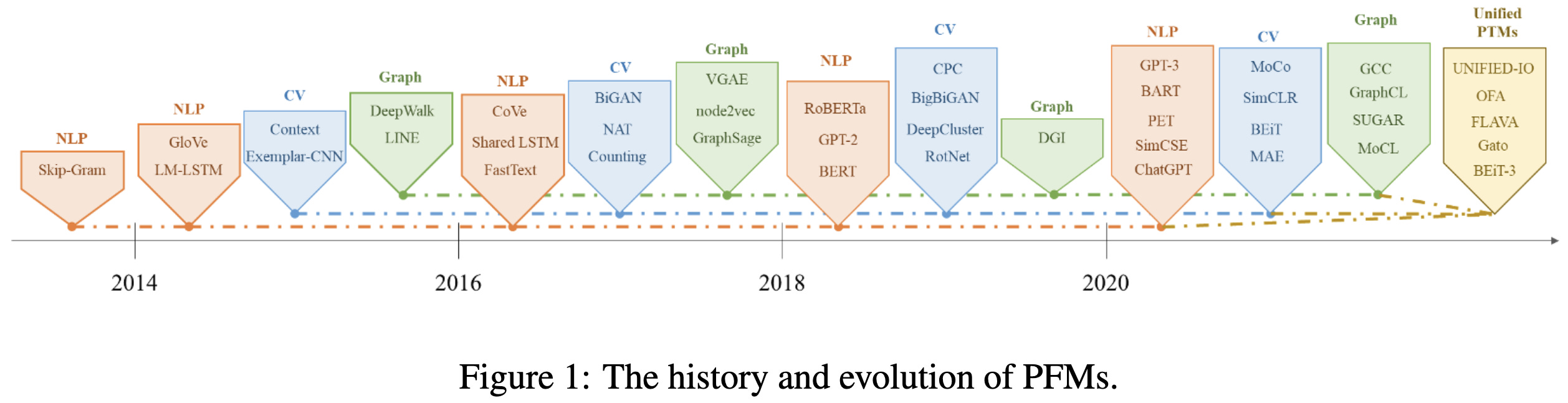
It also does a good job explaining basic concepts from anyone interested.
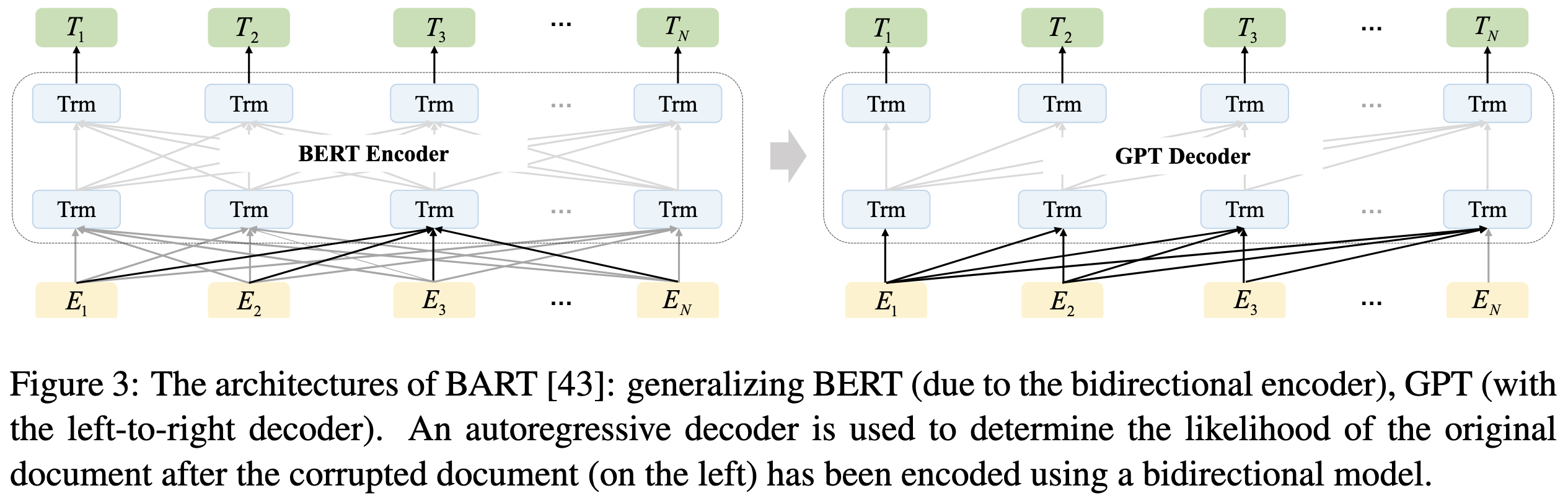
A thorough, accessible read for anyone interested in the history-of-technology angle or trend spotting.
PAC Prediction Sets for Large Language Models of Code
I saw Probably Approximately Correct (PAC) and neural nets together and immediately got curious, since usually deep learning and meaningful guarantees don’t mix.
The idea here is to:
treat the neural net as a black-box scoring function, and
use a theoretically-grounded algorithm to pick a score threshold 𝜏 such that the probability of the true output having a score above 𝜏 is at least ε.
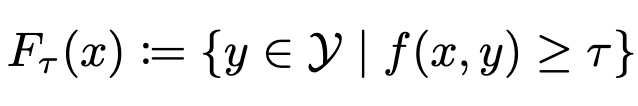
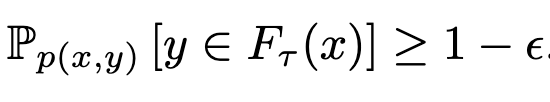
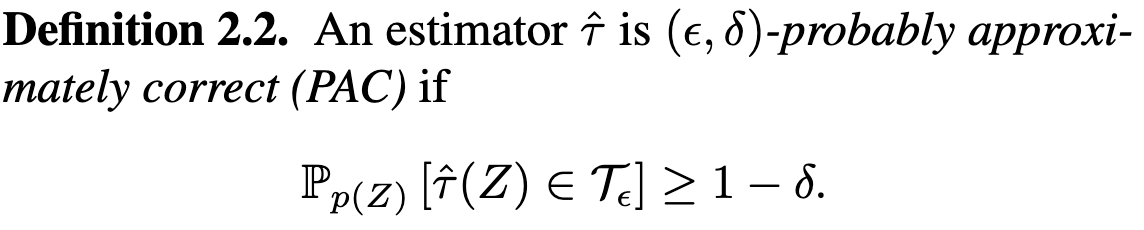
As long as you aren’t updating the neural net, I think this actually does probabilistically guarantee that the right answer is among the suggested options (with class probability above 𝜏) with high probability.
So it’s not a guarantee about the network’s generalization or anything, but it does let them prove some interesting stuff for code generation.
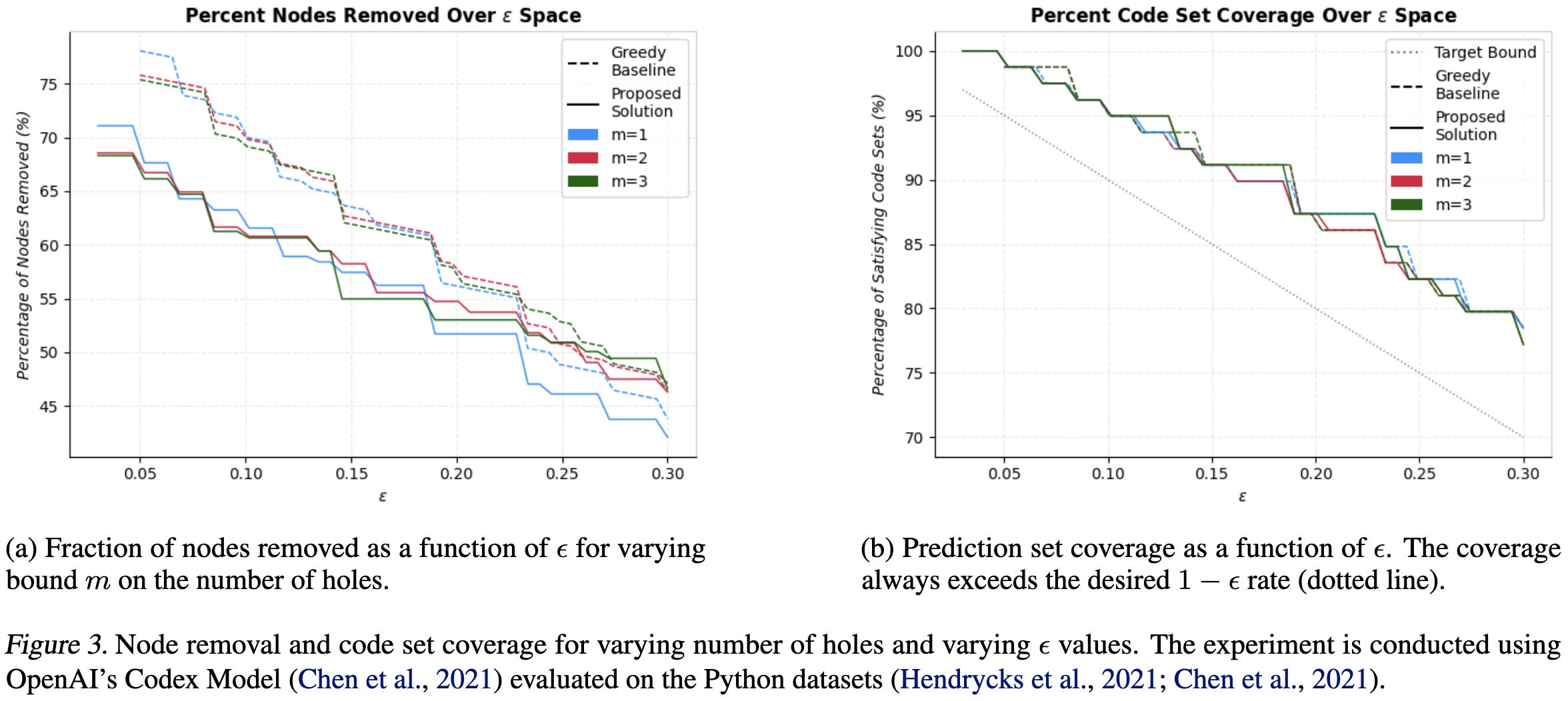
Unique Identification of 50,000+ Virtual Reality Users from Head & Hand Motion Data
10 seconds of motion data is enough to uniquely identify you in VR with 73% accuracy, and 100 seconds is enough for 94% accuracy.
There’s no anonymity in the metaverse.
TA-MoE: Topology-Aware Large Scale Mixture-of-Expert Training
They replace the normal routing loss with a different one that takes into account the network topology. The idea is to get the number of tokens routed from one GPU to another proportional to the bandwidth between them; this minimizes the maximum communication time across all the transfers, ignoring latency.
Using this loss barely alters the training curves when measured in terms of optimizer steps.
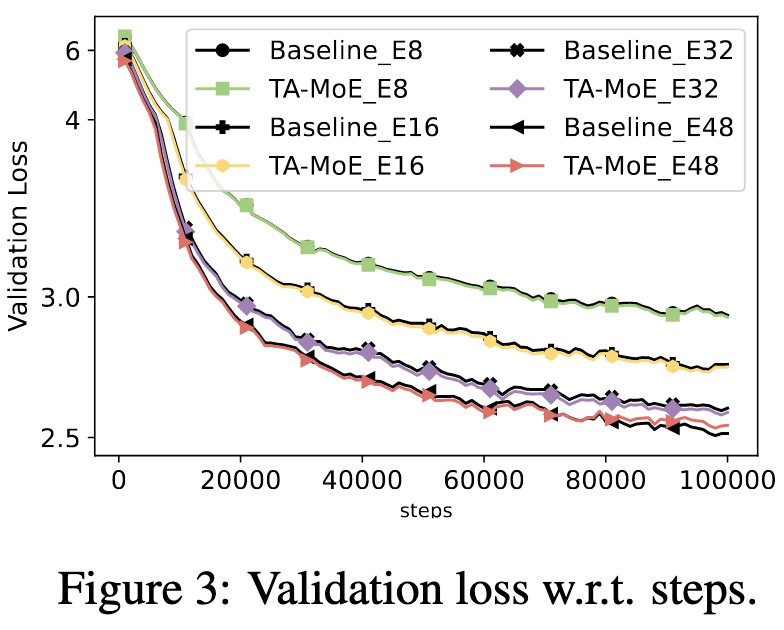
When measured in terms of time though, there’s a substantial improvement.
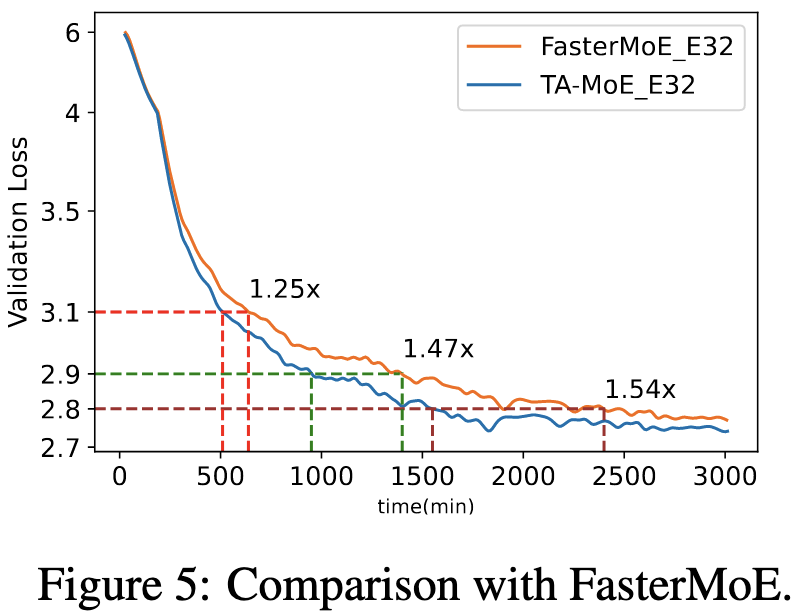
This is because their loss significantly reduces communication when added into an existing MoE implementation.
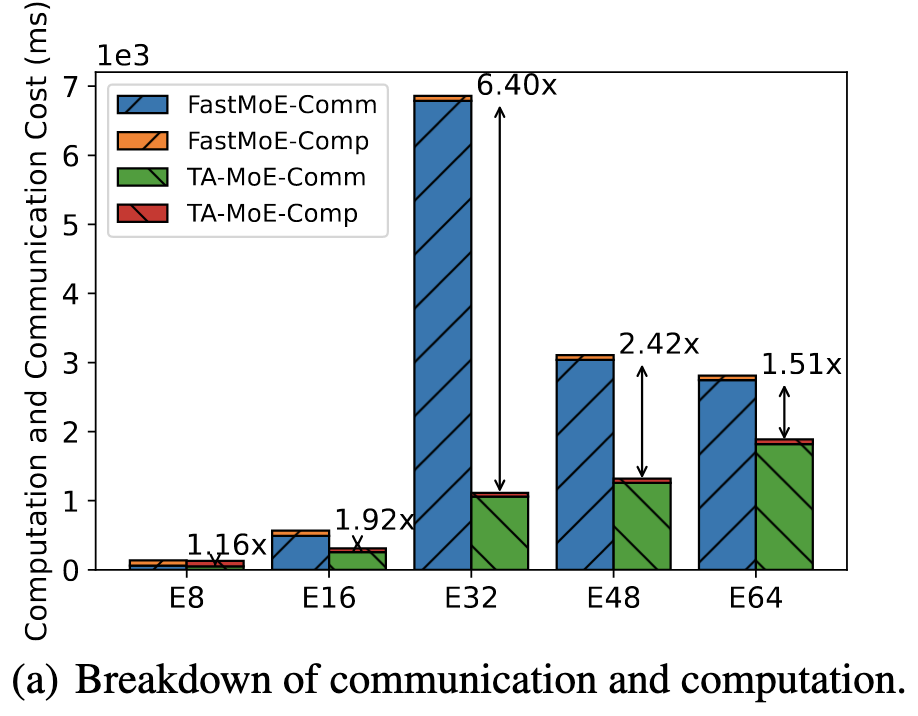
Might be a general-purpose win for MoE models, at least assuming you can measure (or assume?) the network topology.
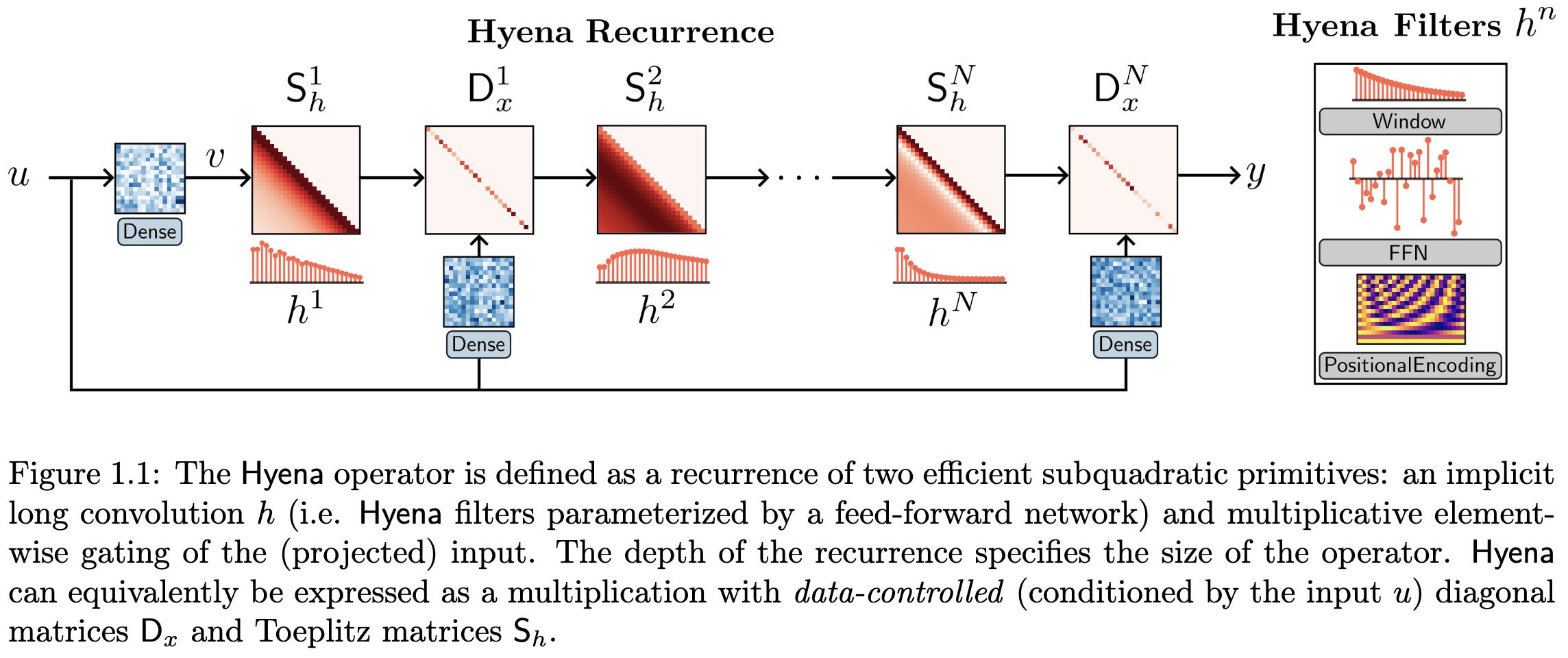
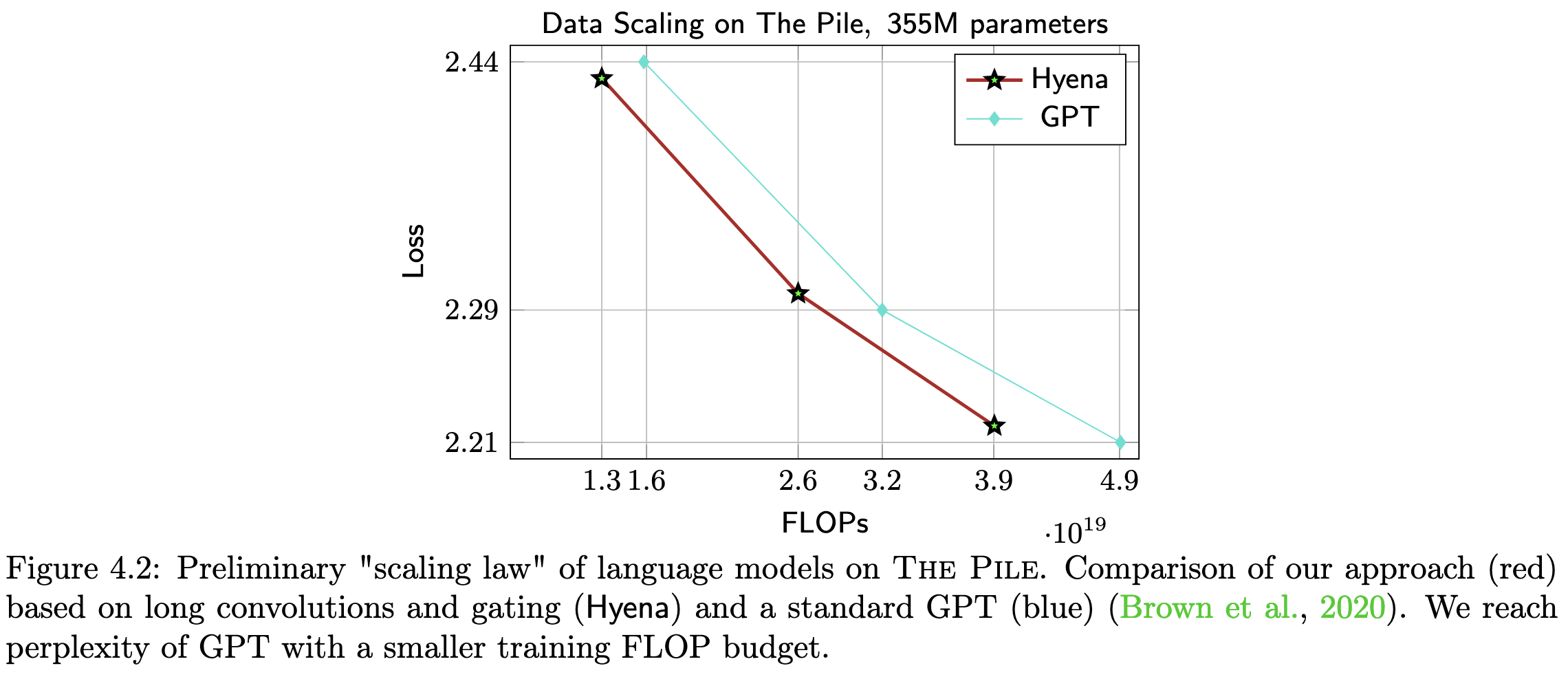
Hyena Hierarchy: Towards Larger Convolutional Language Models
They introduce a subquadratic attention variant based on long convolutions computed in the Fourier domain, along with data-dependent gating.
Does about as well as a GPT model on The Pile when comparing loss vs FLOPs.
In terms of zero-shot and few-shot accuracy at fixed parameter count, does about as well as various baselines on SuperGLUE as well.


Where it really shines is when using longer sequence lengths, thanks to its subquadratic complexity.
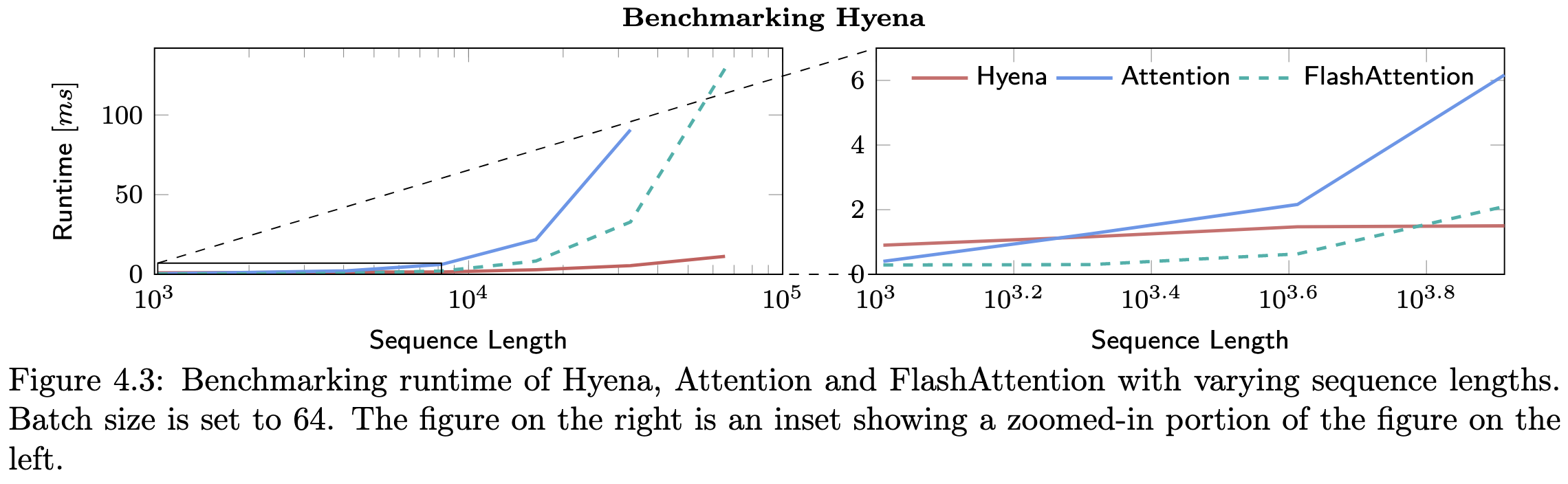
Seems to be further evidence that you just need token mixing and multiplicative interactions, not attention per se.
ChatGPT: Jack of all trades, master of none
How does ChatGPT do on various NLP benchmarks?
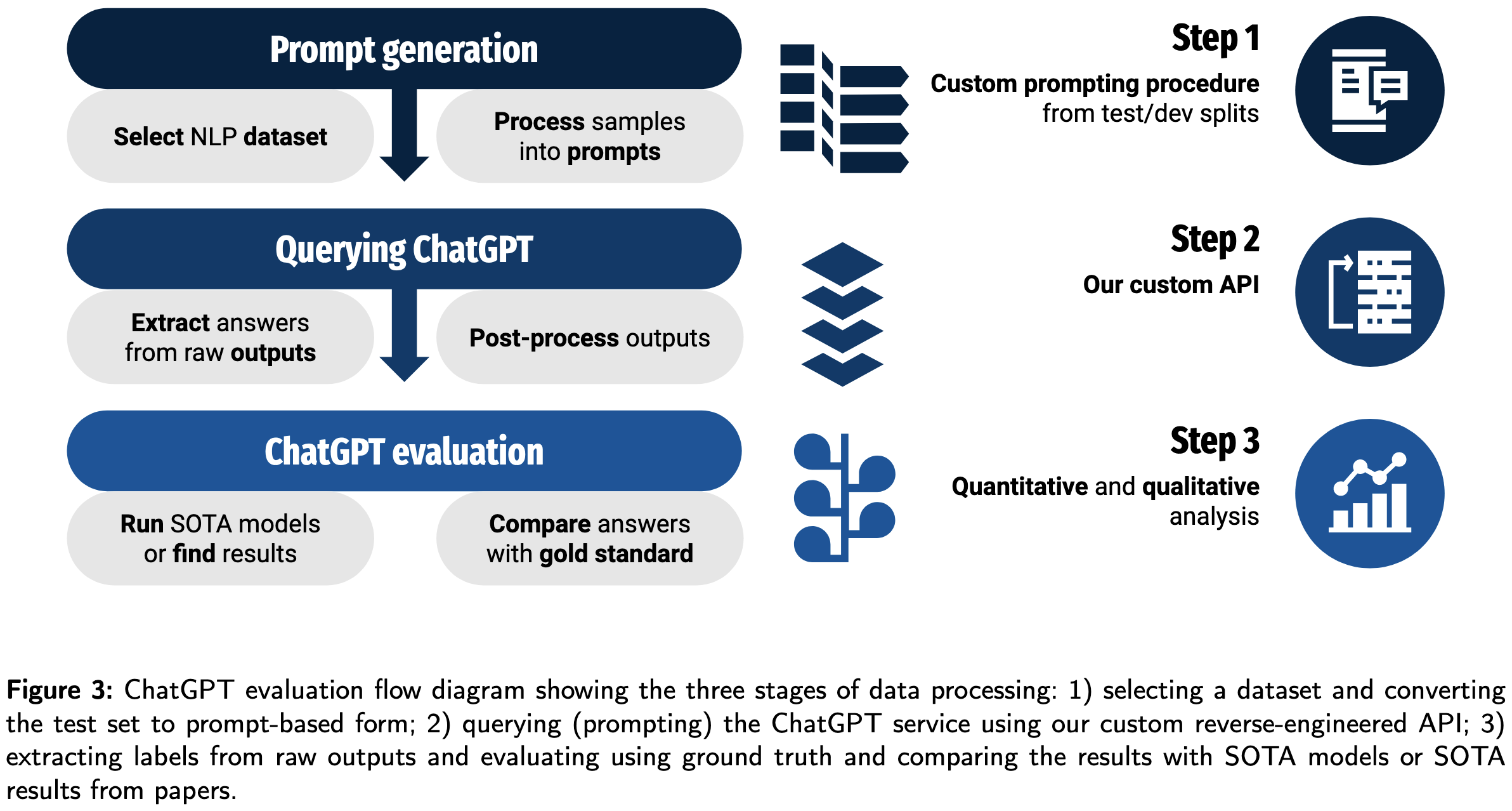
It usually does okay, but never matches the current state-of-the-art for any task.
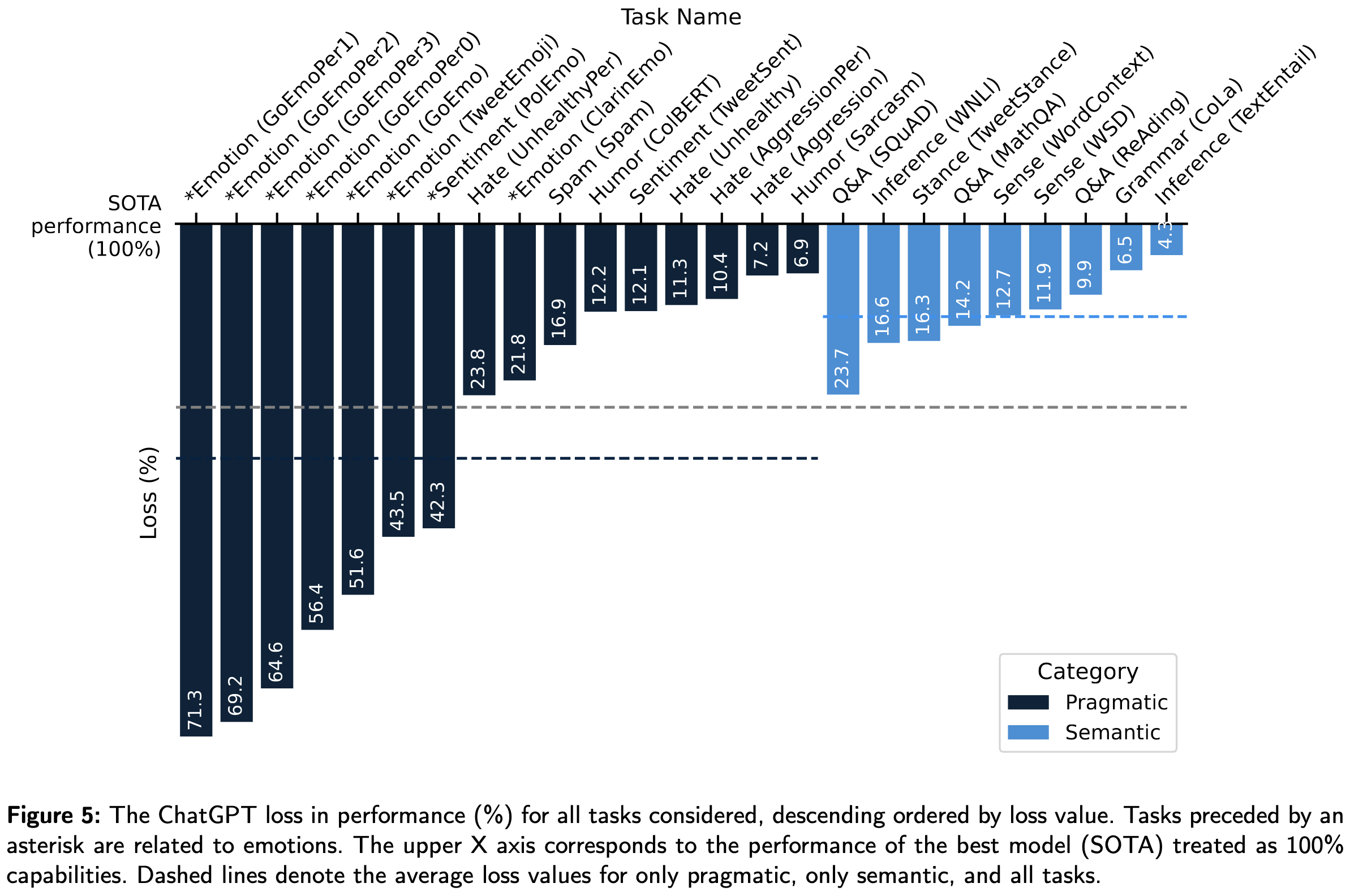
Comparing across papers is always hard, but overall this reinforces my belief that zero-shot or few-shot prediction will make sense for the long tail of low-effort use cases, but will never be the highest-quality solution; for the best model, you’ll need to train and/or pretrain it on a lot of task-specific data.
Benchmarking Interpretability Tools for Deep Neural Networks
How well do interpretability methods do when there’s a known giveaway of what the output should be?

The results are…hit or miss. Sometimes intepretability methods correctly find these dead giveaway features, but sometimes they don’t.
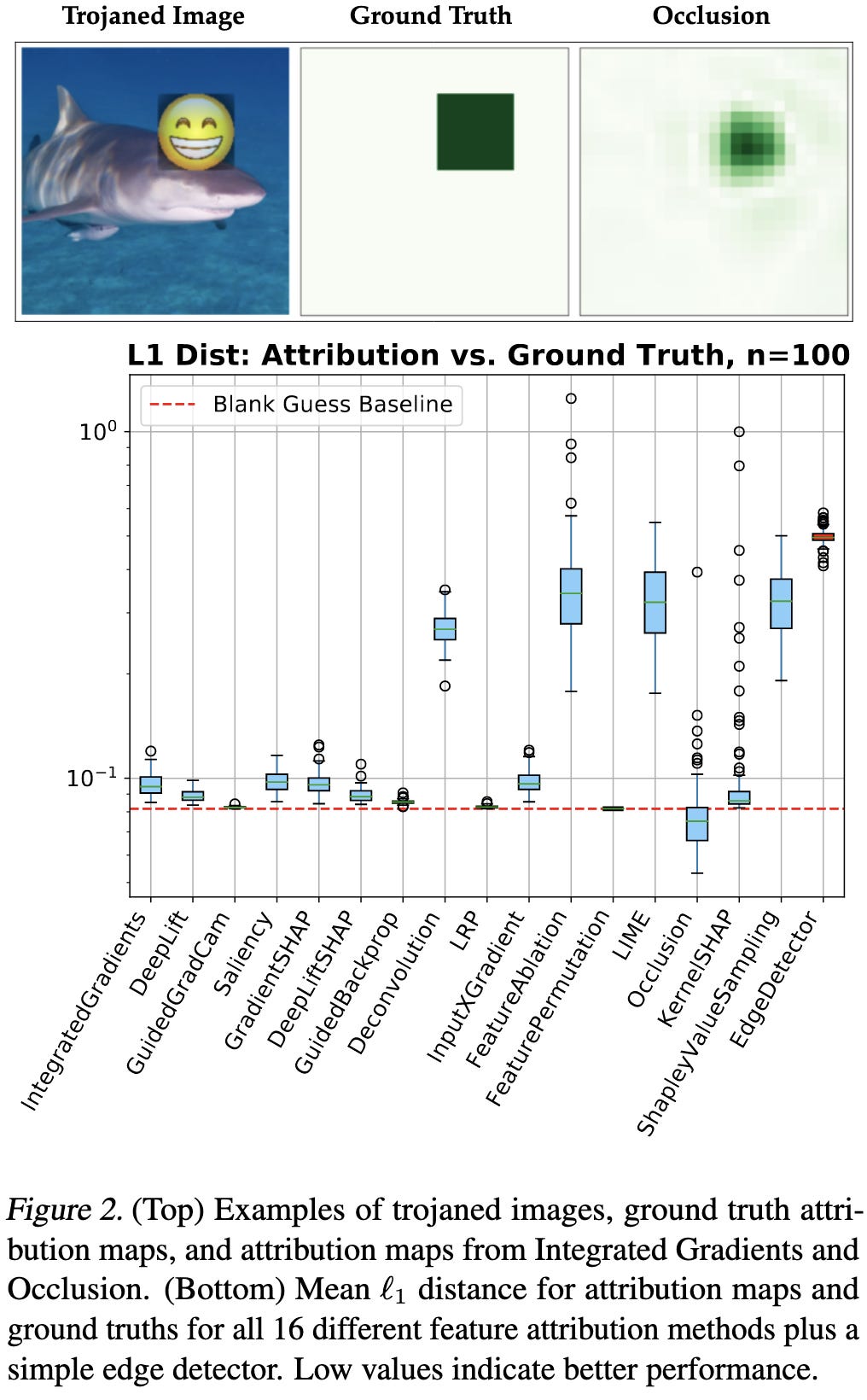
Many methods also have the ability to “synthesize” salient features. In theory, these synthesized features should offer insight into what’s driving a model’s predictions.

If you give these synthesized features to humans or CLIP, some of them definitely help find the salient features—but others don’t. (Here’s the survey they gave people.)
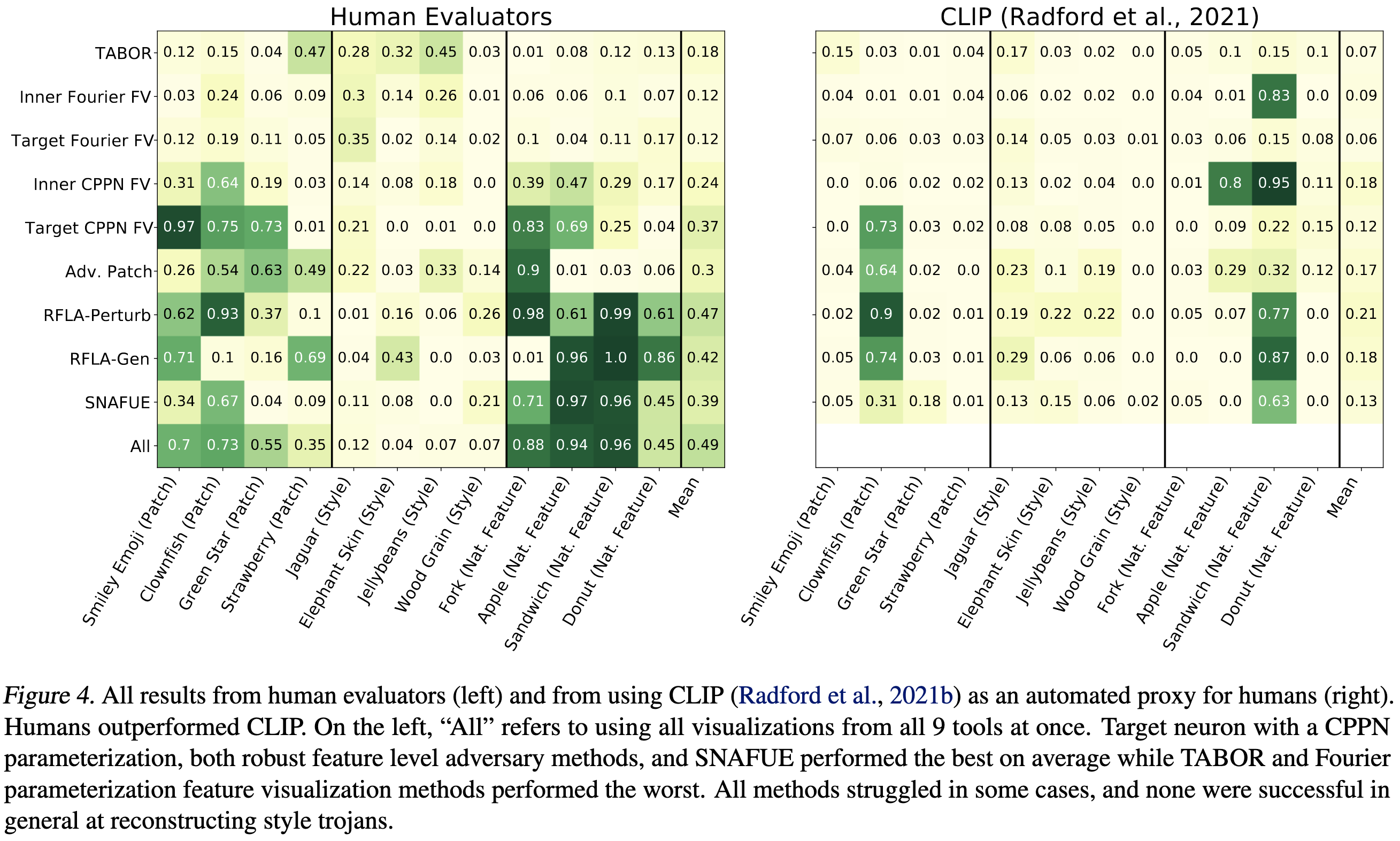
Always great to see independent, controlled comparisons across different methods. Added this to my big list of meta-analysis / independent benchmarks.
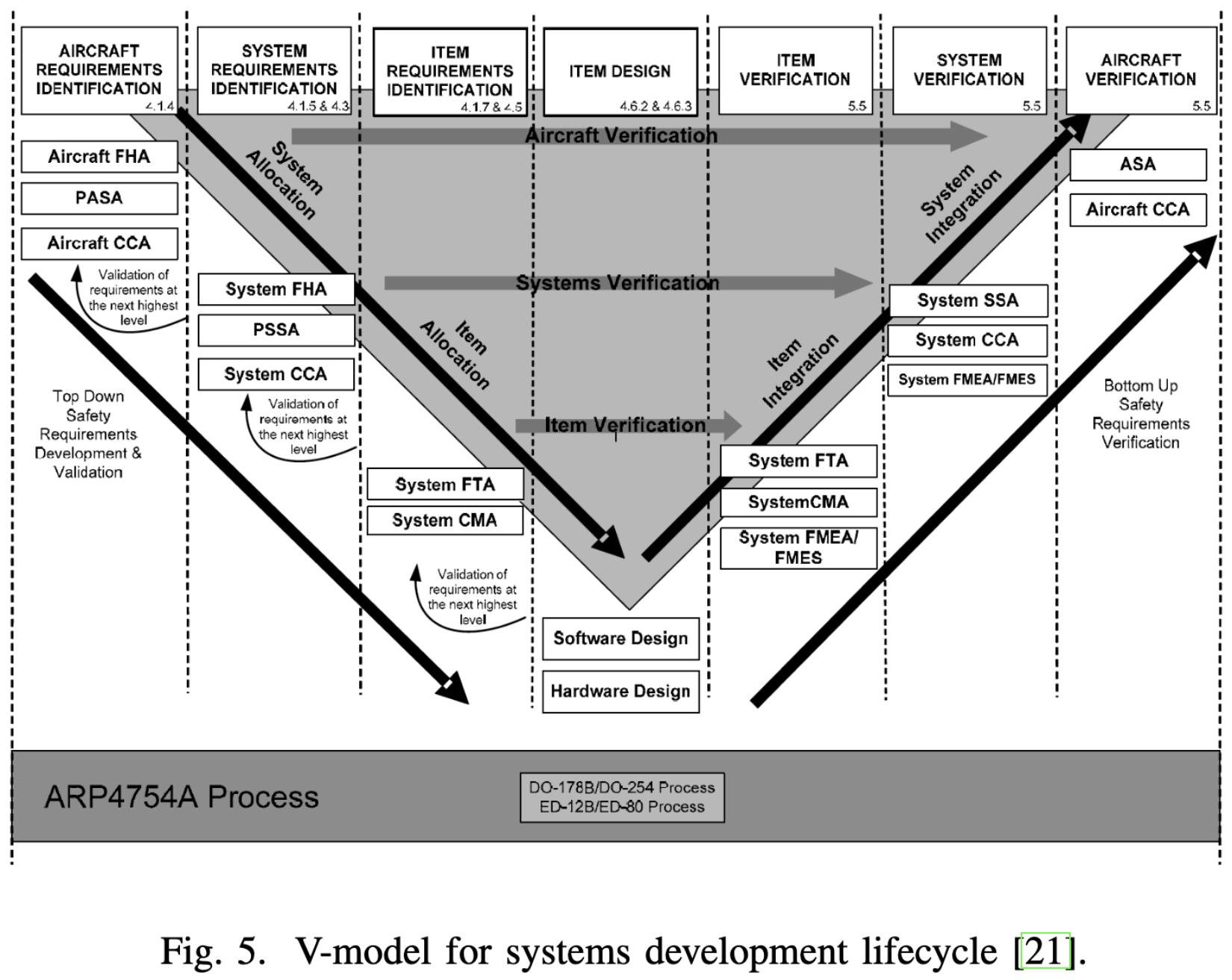
Framework for Certification of AI-Based Systems
I suspect most people working on machine learning have never worked in a heavily-regulated industry. If you want a taste of what a lot of enterprises have to think about, jump in the deep end with this paper by some aerospace people thinking about FAA certification.
We have carefully outlined design processes, distinguishing between such concepts as “system requirements identification” and “item requirements identification.”
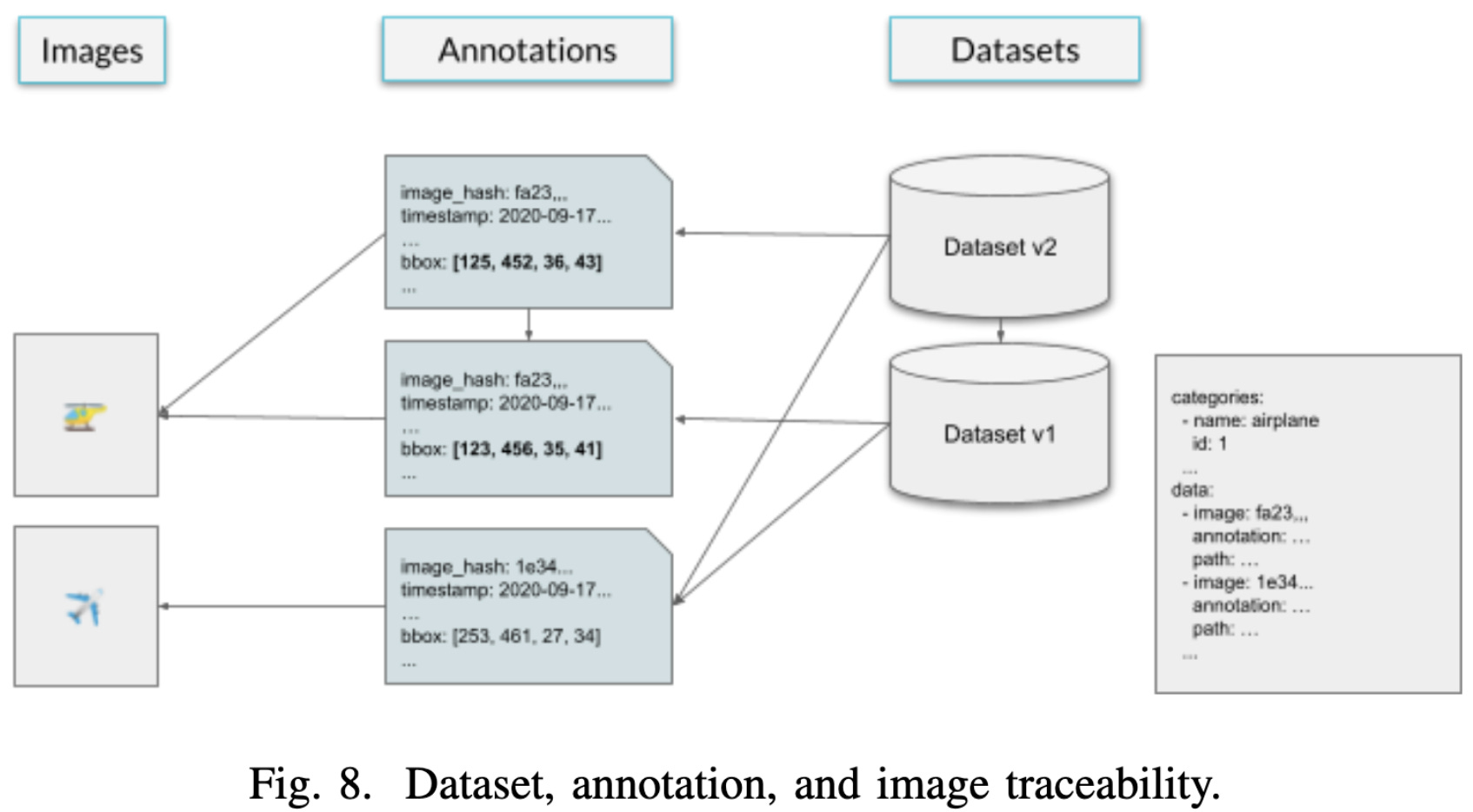
We have traceability considerations. If you’re not sure what “traceability” is, picture me as an intern signing and dating the row for requirement 8.1.17 in the Milestone C spreadsheet after checking that the associated tests T-1.12.13-15 & F-1.08.4 all pass.
We have countless three-letter acronyms for named processes, regulatory requirements, and compliance documents. And lastly, we have a side of innocuous-sounding phrases with great regulatory weight (ask me about our “design history file” for FDA clearance).
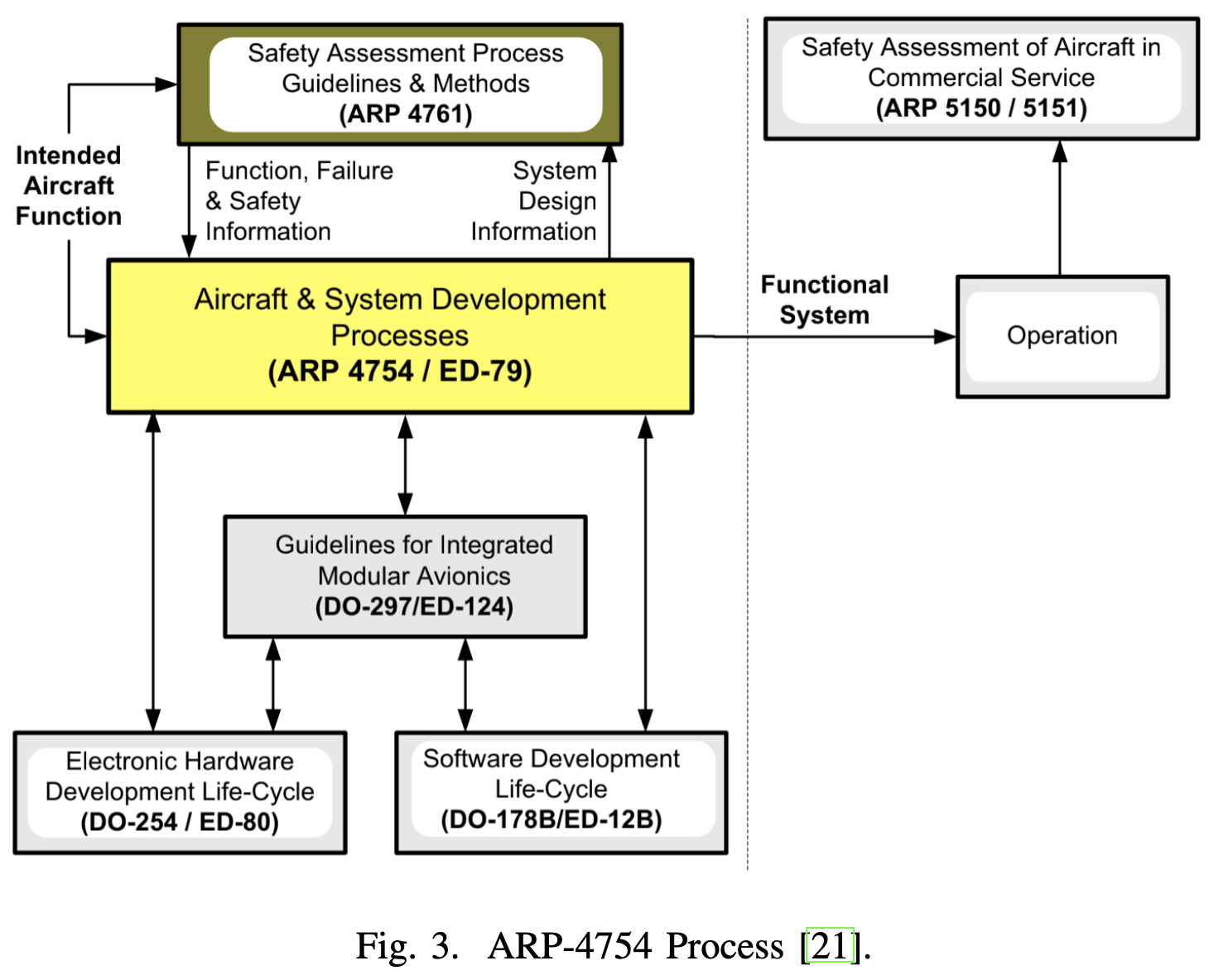
This paper is a methodical walk through the model development lifecycle, and boring in the best way possible.
It also serves as a friendly reminder that ensuring the safety of cyber-physical systems is a decades-old problem, not an avant-garde subfield of AI.
Modular Deep Learning
A long survey of attempts to make subnetworks removable, reusable, swappable, composable, etc. They highlight ideas like modularity entailing both the function(s) being computed and the routing/aggregation to determine which function(s) get applied, as well as the distinction between hard vs soft routing.
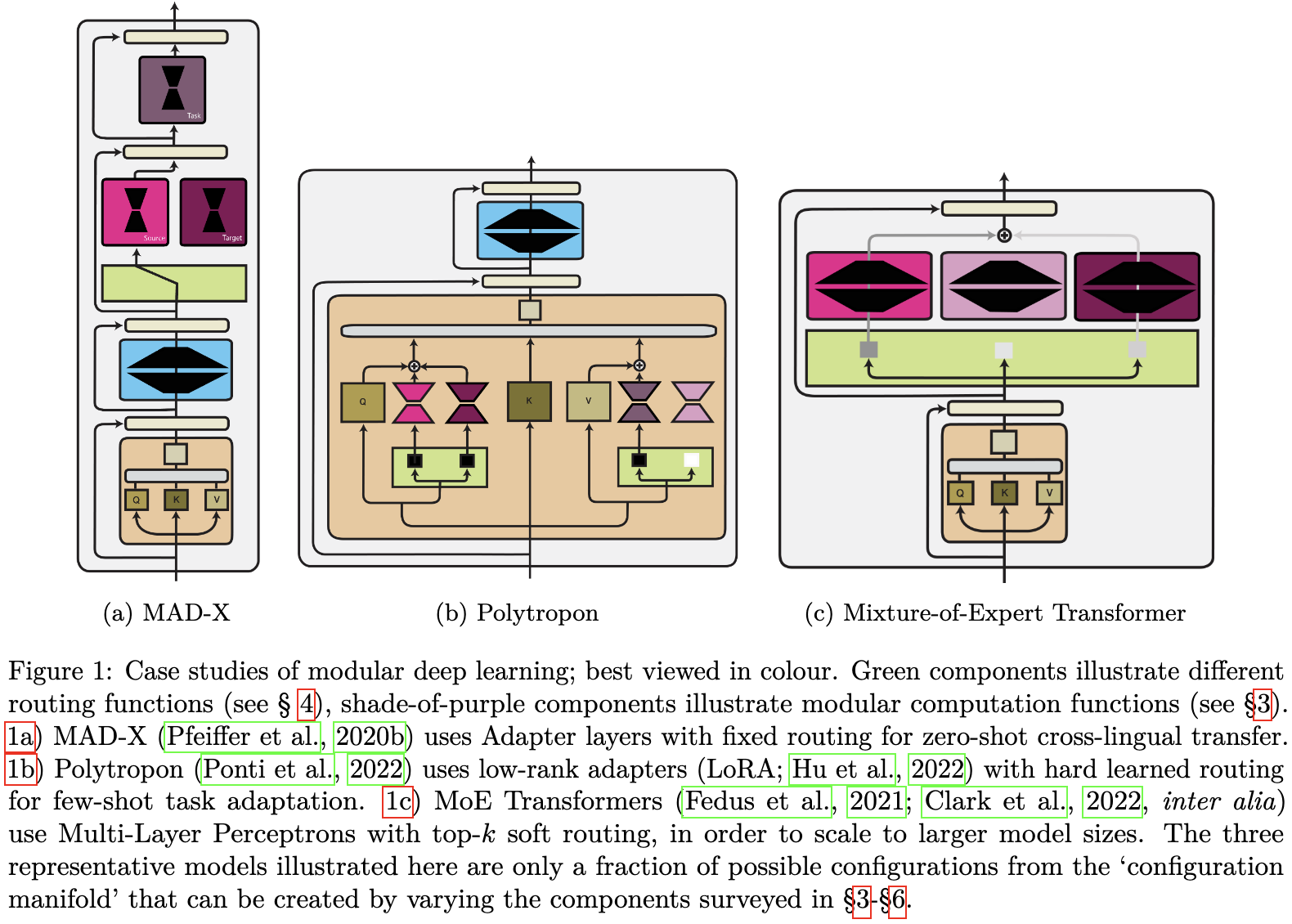
The summary on page 38 is pretty good if you want a shorter version (and already such concise bullets that I can’t really summarize it further).
Aligning Text-to-Image Models using Human Feedback
They basically did RLHF finetuning for text-to-image models.
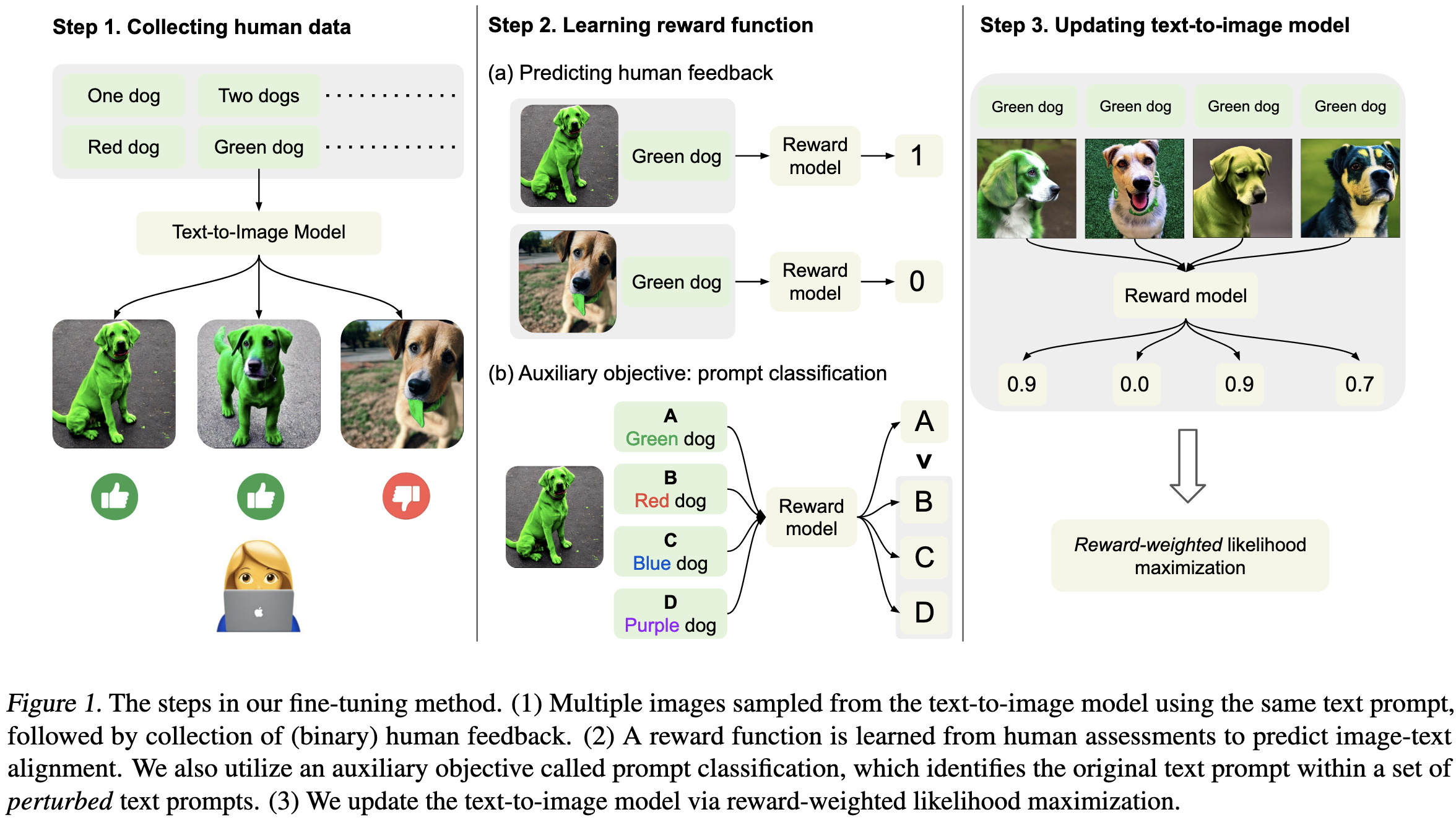
Though rather than having a fancy reinforcement learning algorithm, they just learn a reward function from human labels of “good” vs “bad” images and use the reward to weight samples.

The reward function is just a regressor mapping pretrained CLIP embeddings to [0, 1].

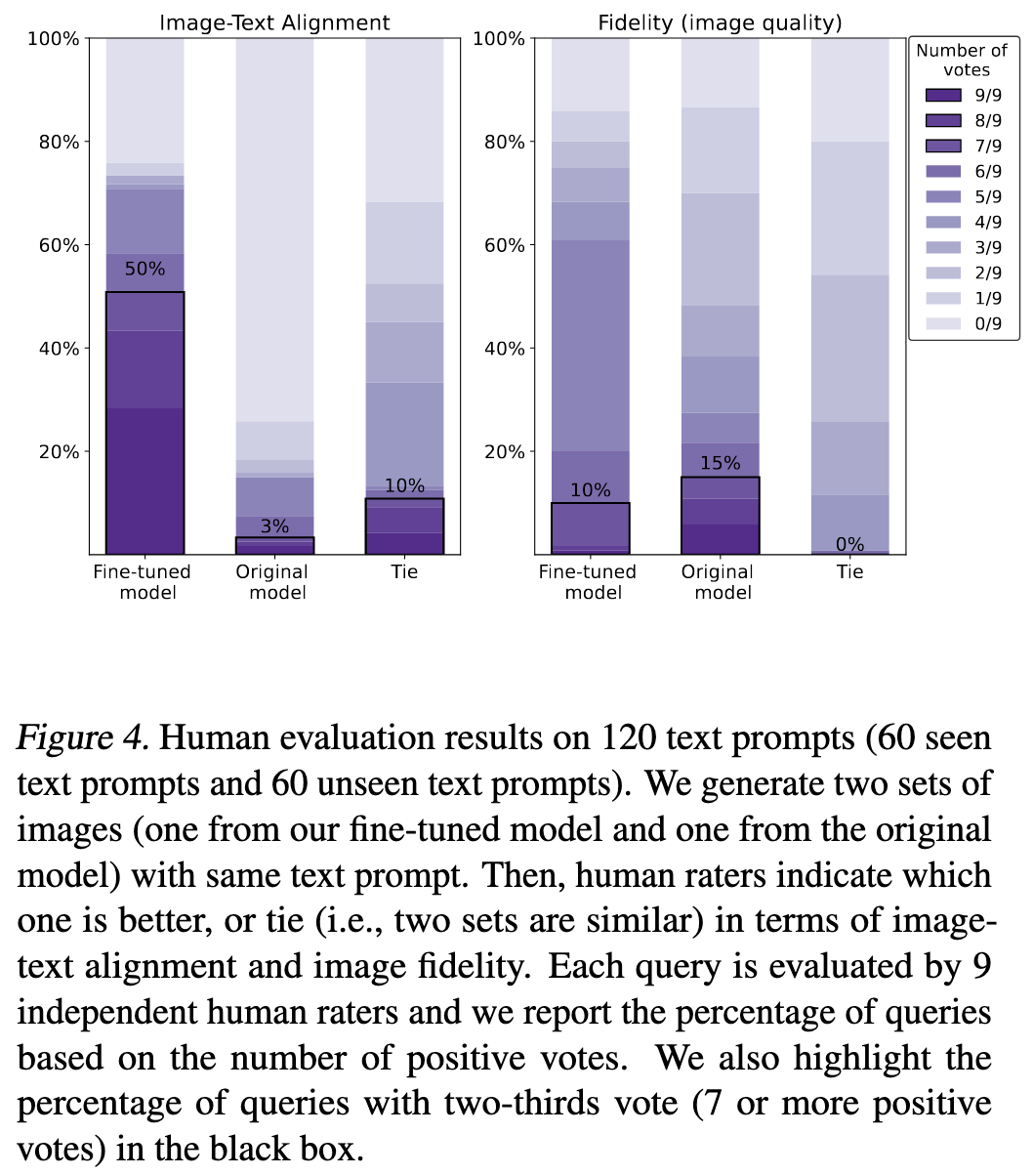
Their method seems to work really well for the target problem of controlling color, background, and object count.

This is true not just on cherrypicked examples, but also when systematically rated by humans.
An interesting ablation experiment they have shows that learning a reward function using their losses and binary labels captures human preferences better than CLIP score does. Not super surprising, but encouraging as far as direct human feedback being valuable.
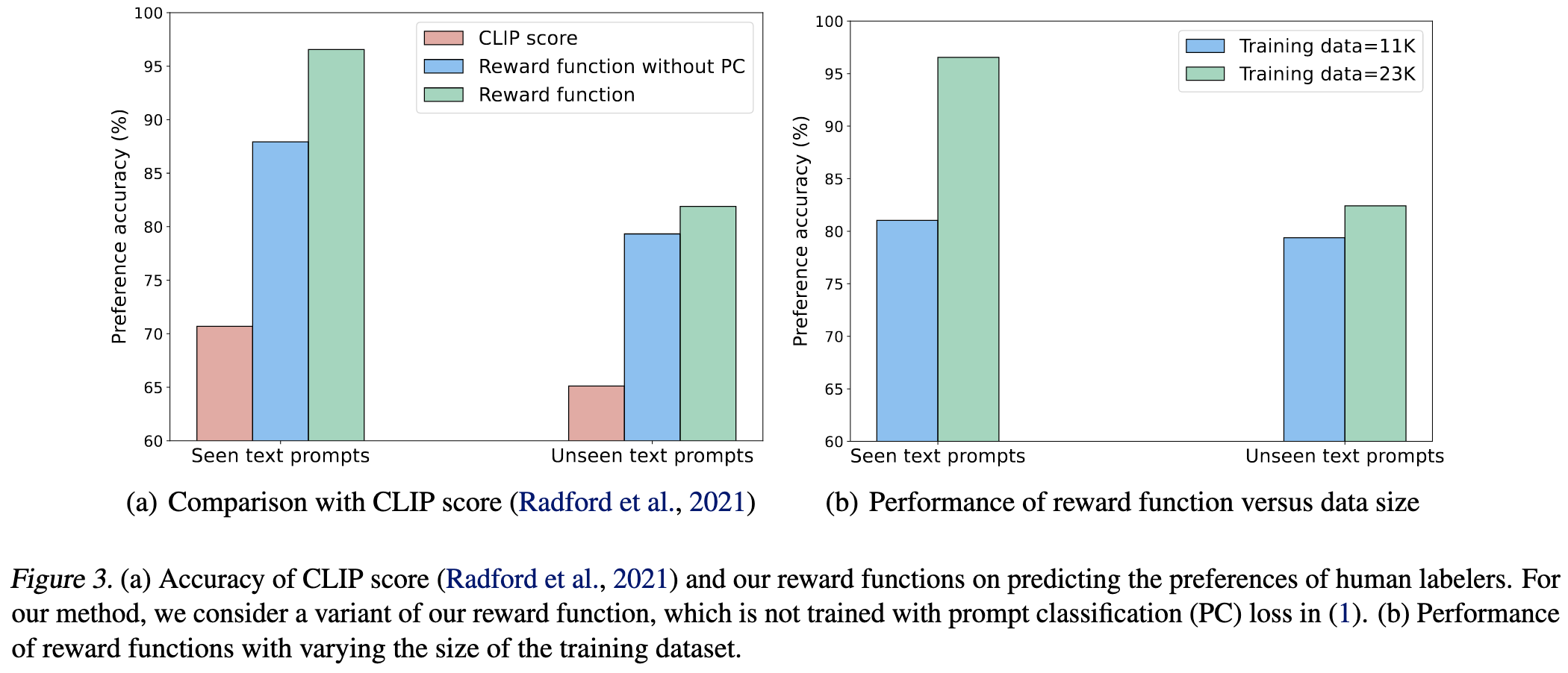
As is often the case in machine learning, there’s a tradeoff between label quality and quantity. If you only finetune on the dataset with human labels, you don’t do as well as if you add in unlabeled data.

If you’re willing to spend more on inference, you can improve the results even further by generating more images than you need and returning only the best ones (as estimated by the reward function).
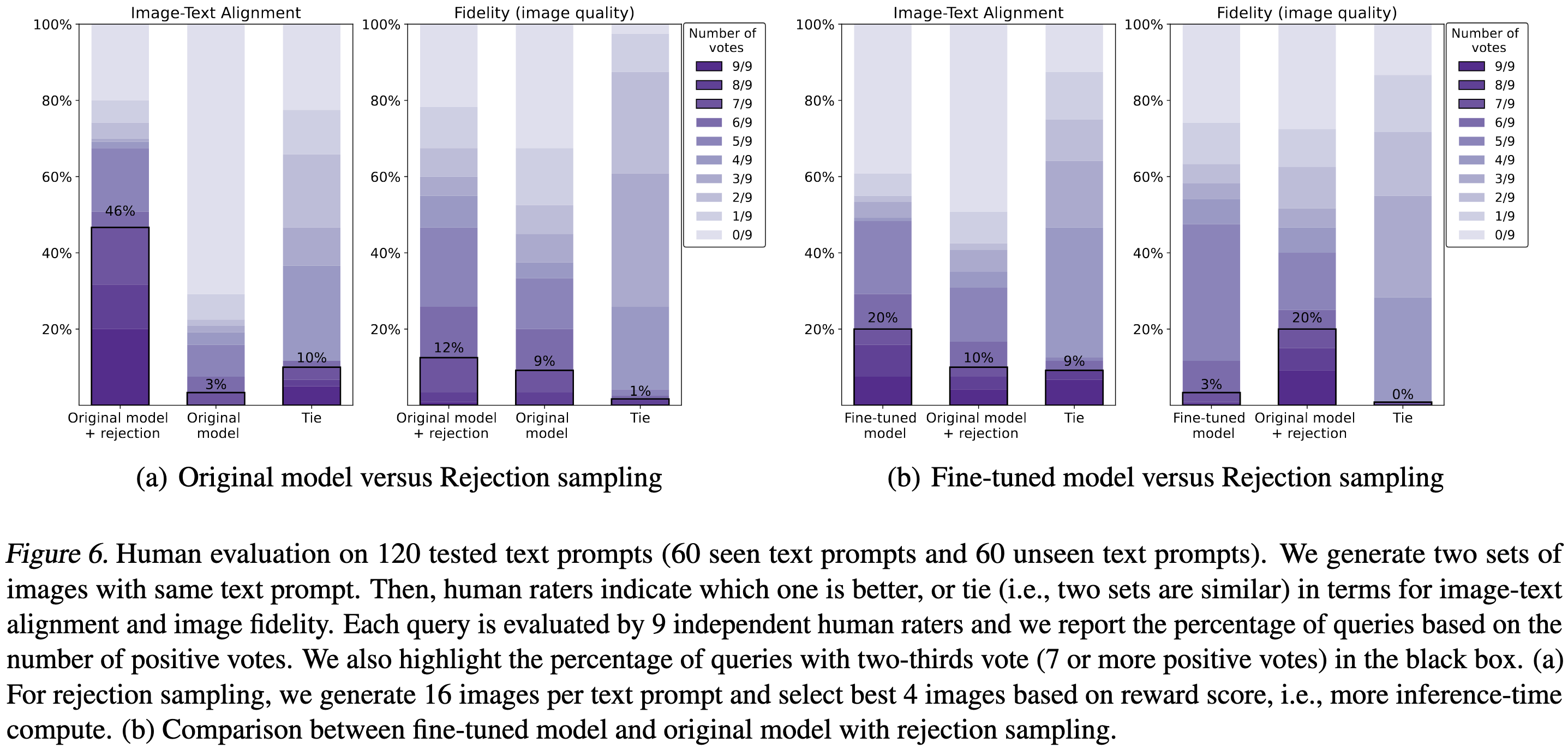
Another example of the unreasonable effectiveness of data—while algorithmic ideas did help, we yet again see the power of collecting a large number of task-relevant labels.
DoG is SGD's Best Friend: A Parameter-Free Dynamic Step Size Schedule
They propose to set the learning rate based on the largest distance to the initialization seen so far divided by the square root of the sum of all gradient norms seen so far.
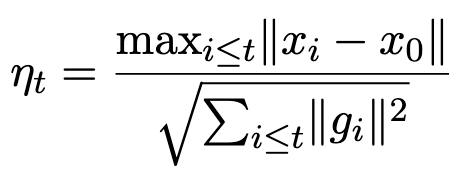
When used with SGD, this can eventually get you to a learning rate within an order of magnitude of the ideal learning rate found via hparam tuning.
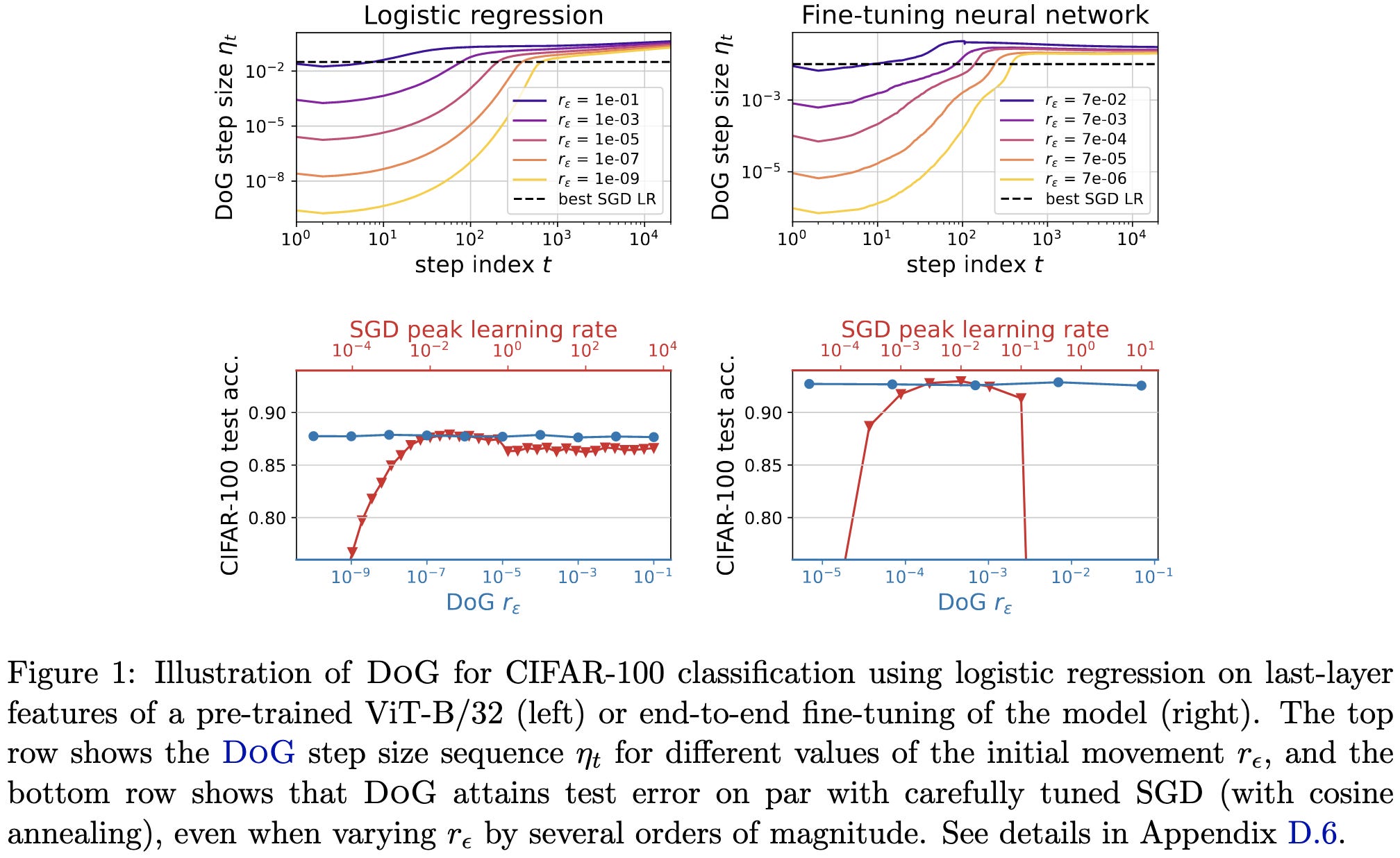
If you apply the formula to each layer instead of to the whole network’s parameters as one vector, you lose the theoretical guarantees but get results matching optimized Adam or SGD.
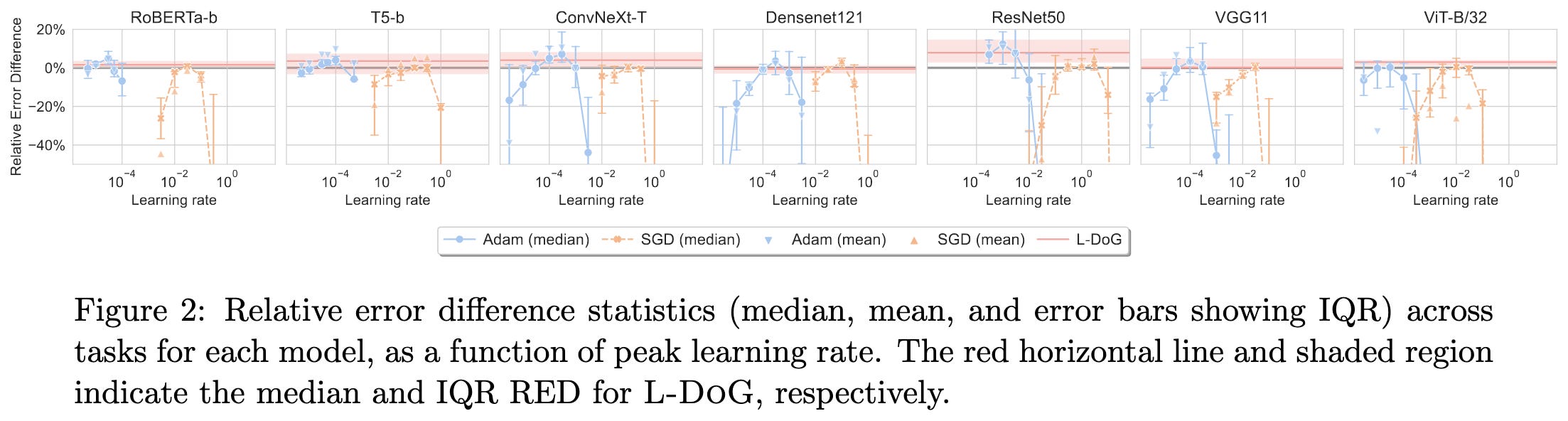
I’m always skeptical of papers with yet-another-deep-learning-optimizer. But the results seem solid and it would be really cool to eliminate learning rate as an hparam.
I’m also wondering if this would offer systems wins—you can rematerialize the initialization based on the random seed instead of storing it, and the sum of gradient norms seems to just be a per-tensor scalar; this means it might require almost no memory to maintain this algorithm’s state.
As a result, even if this is merely as good as existing optimization practices, it could still be a big efficiency win.
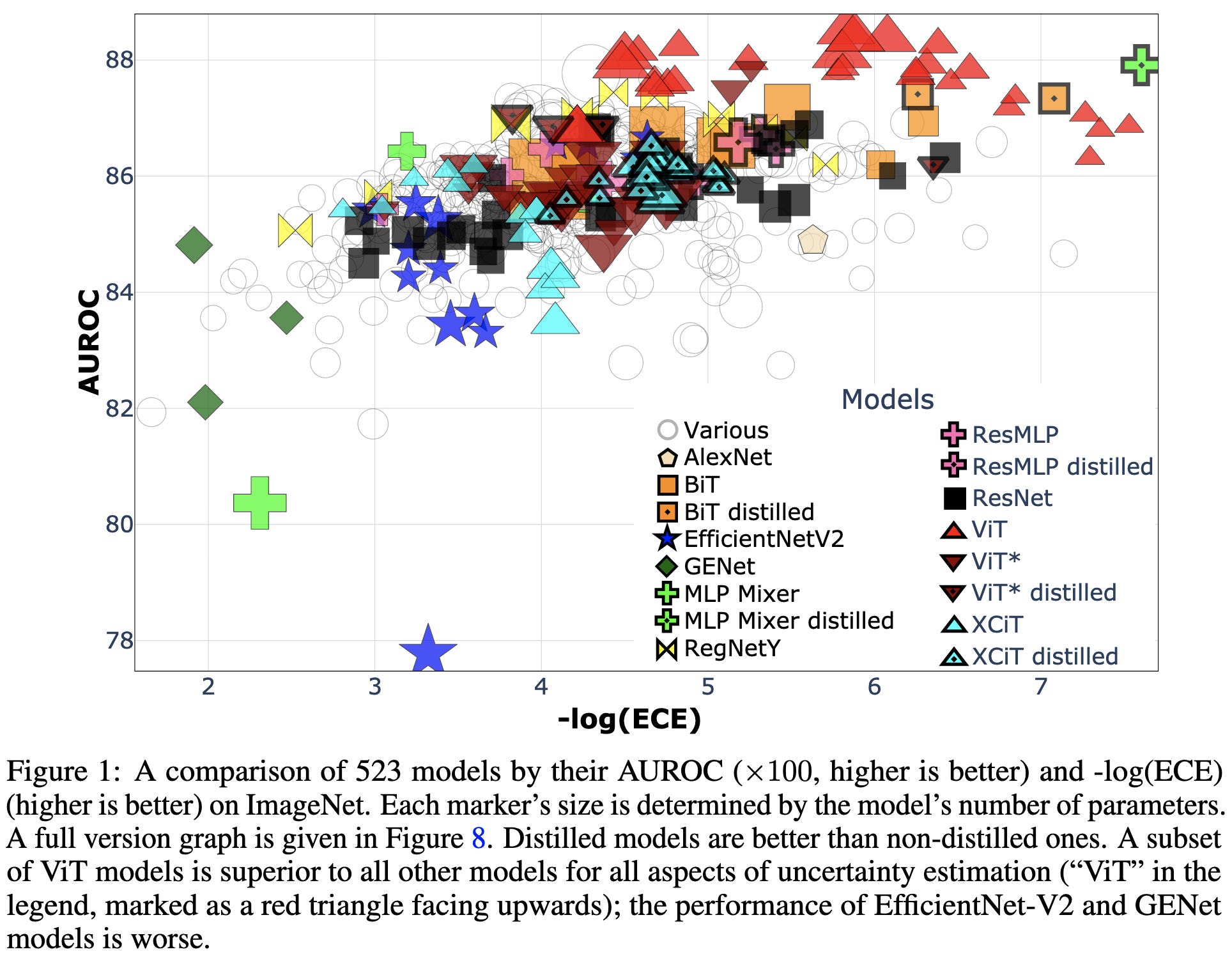
What Can We Learn From The Selective Prediction And Uncertainty Estimation Performance Of 523 Imagenet Classifiers
A few findings regarding calibration / uncertainty estimation:
Some architectures work better or worse than others. In particular, there are certain ViT training recipes that do really well.
Knowledge distillation helps
Temperature scaling the softmax post-training helps
The correlations between different metrics like expected calibration error and AUC vary across architectures
Multimodal Chain-of-Thought Reasoning in Language Models
They get big accuracy lifts by extending chain-of-thought reasoning to multimodal models.
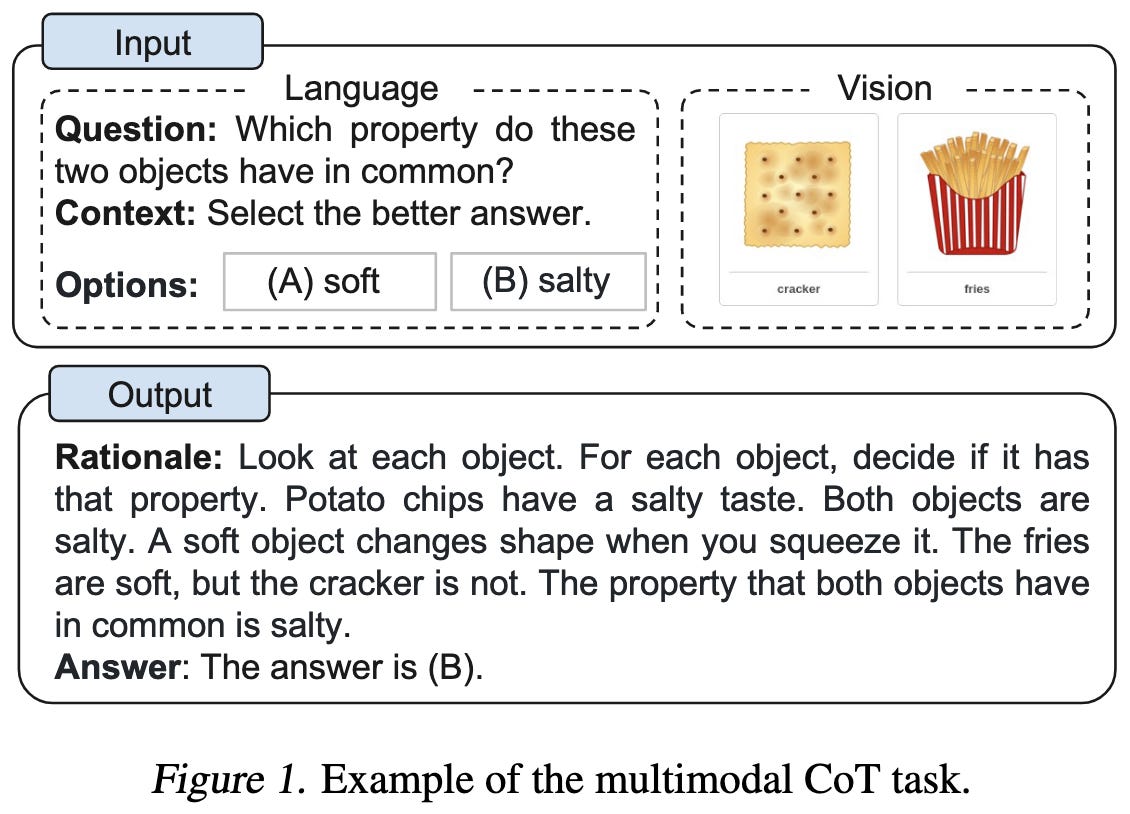
In more detail, they feed in both an image and a text prompt, and have the model generate an answer in two stages. First, it has to generate a textual “rationale.” Second, it generates the final answer, with the rationale fed in as extra input.
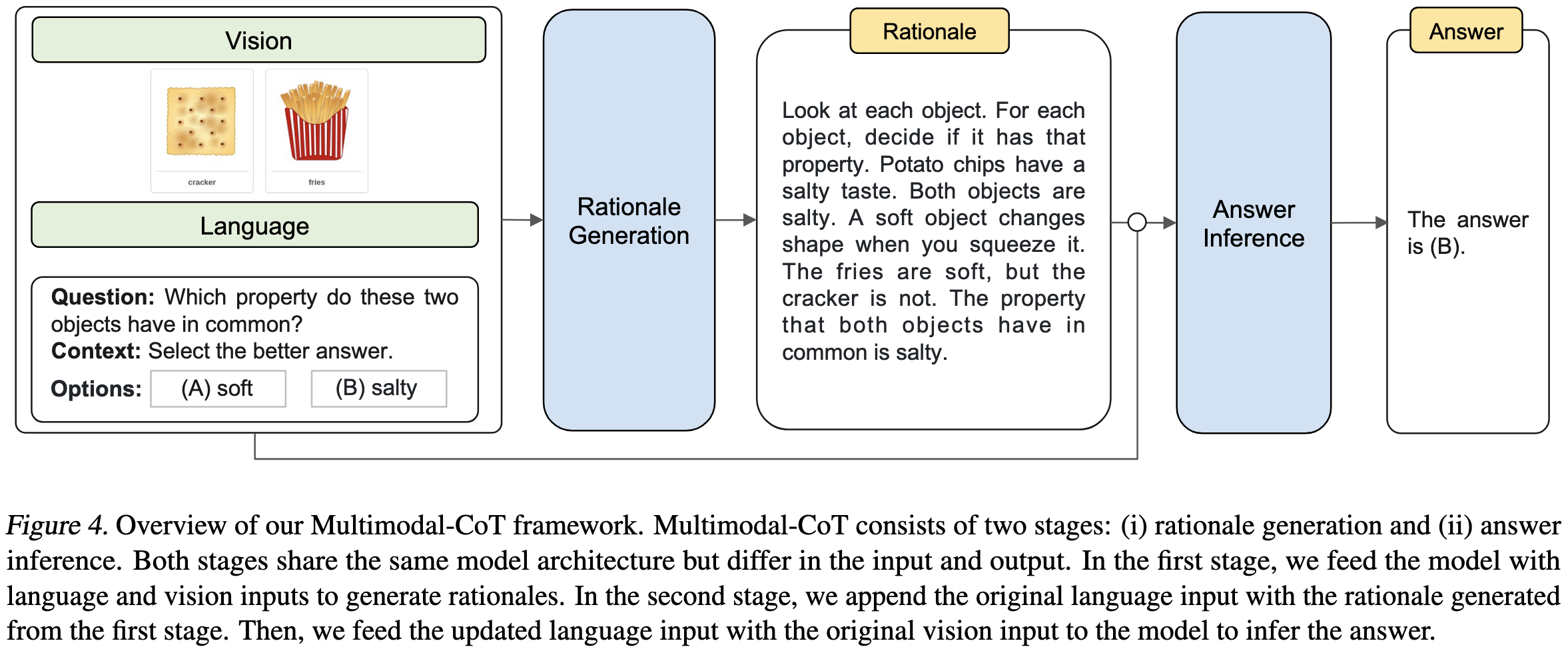
They fuse the information from the two modalities by embedding each separately and then having these embeddings interact via attention and a gating mechanism.

The gating mechanism is just taking a convex combination of the two modalities’ representations, with the coefficient being the output of a trainable softmax.

Using both modalities can get you much higher final accuracy, plus faster convergence to this high accuracy.
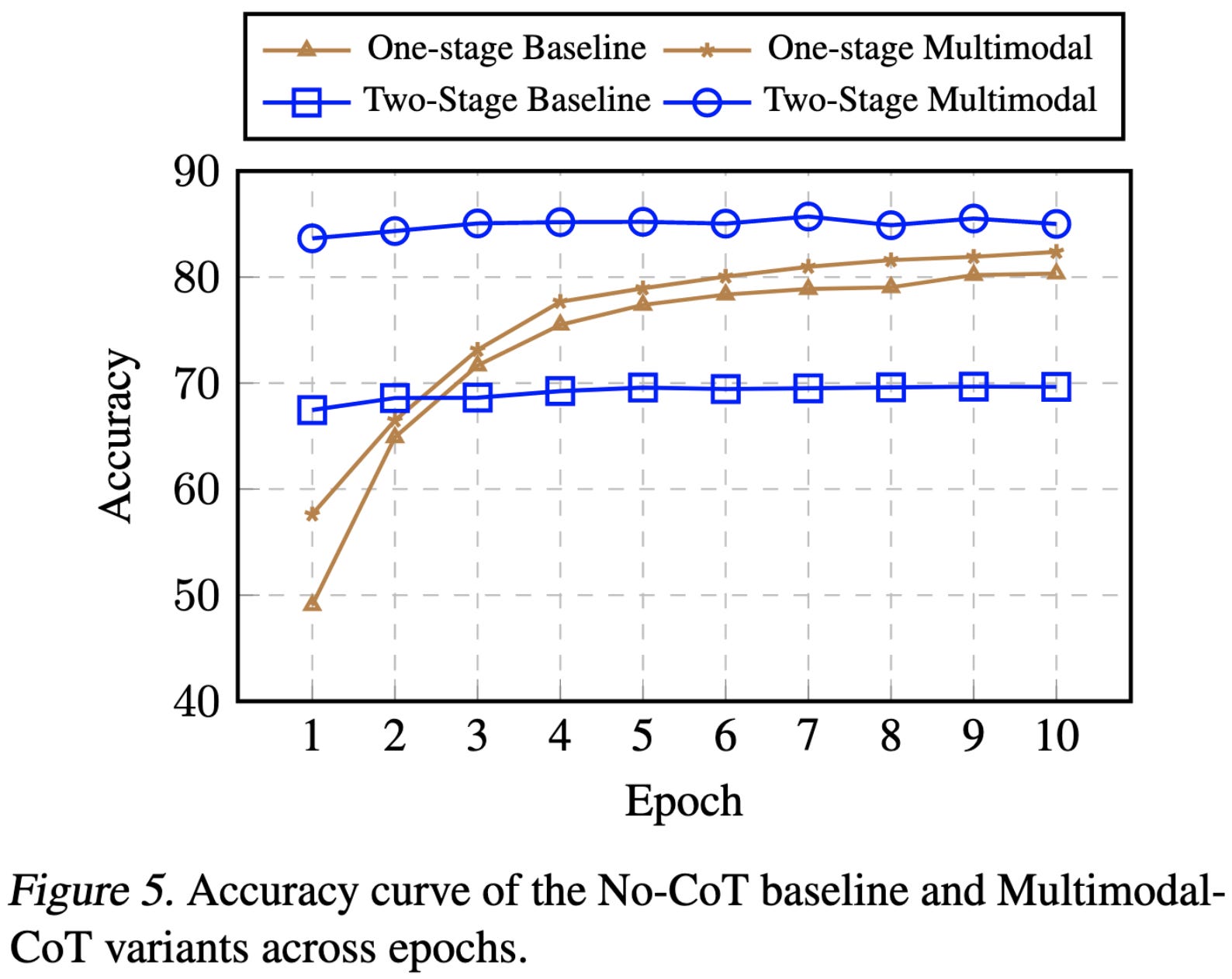
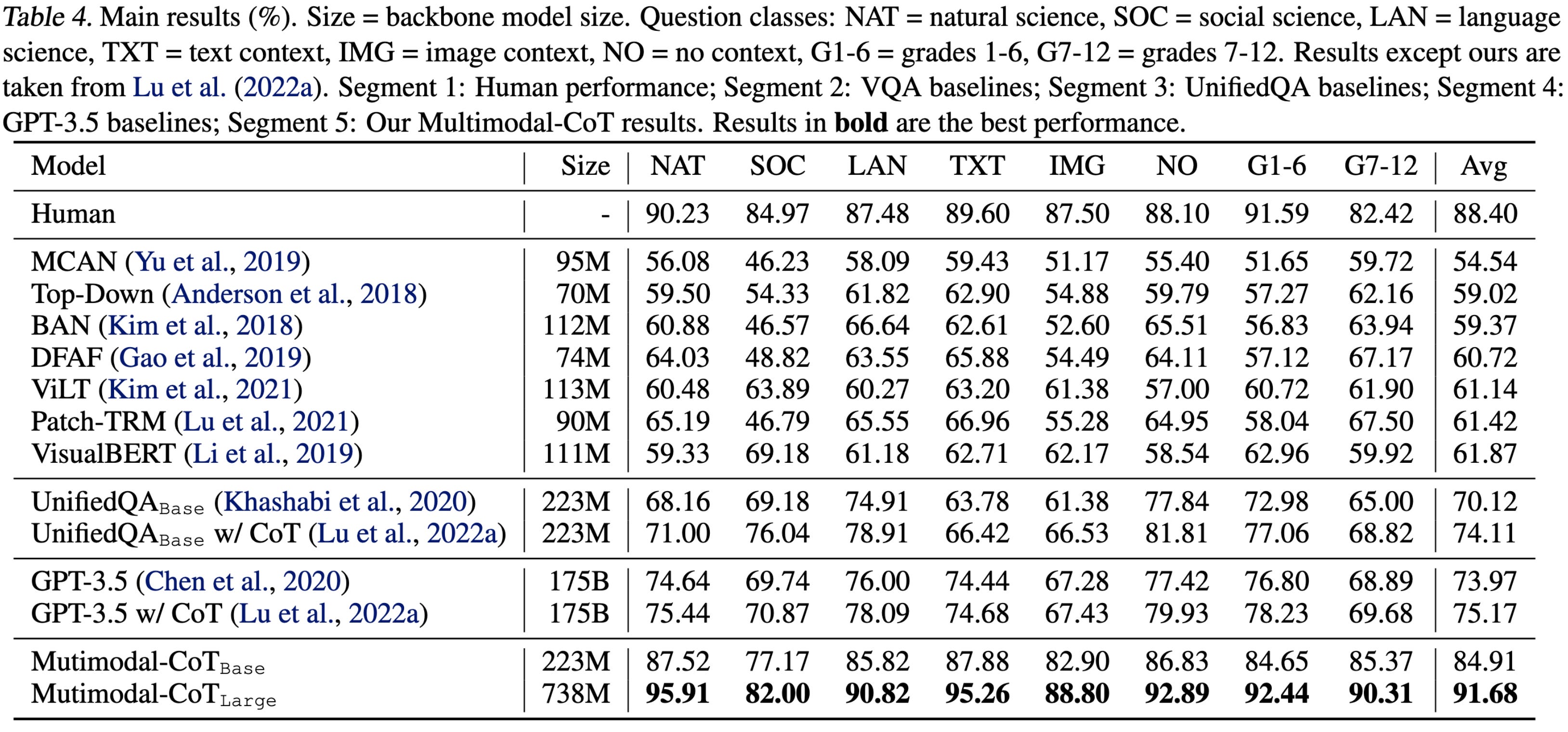
These gains hold even across different models.
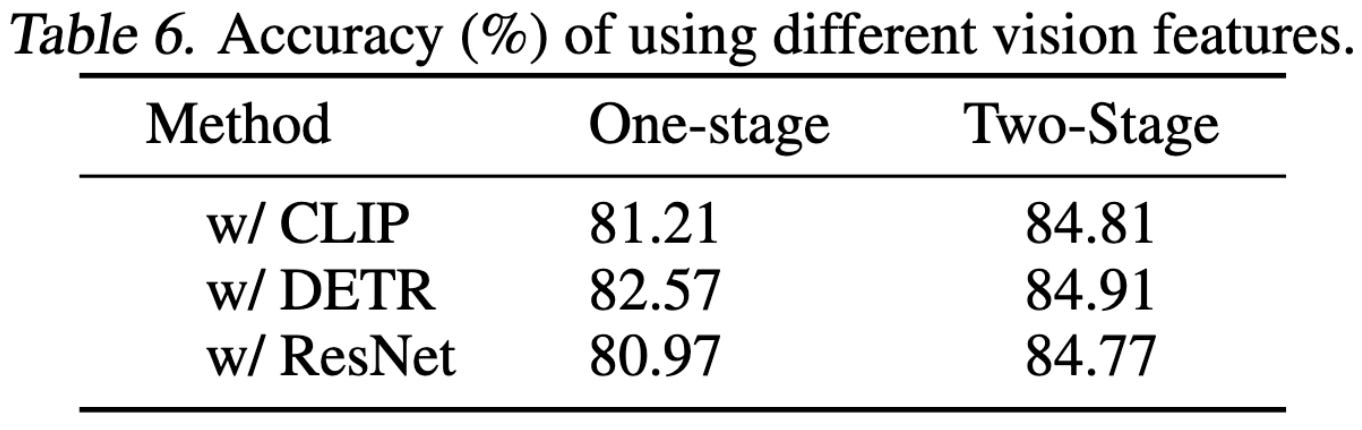
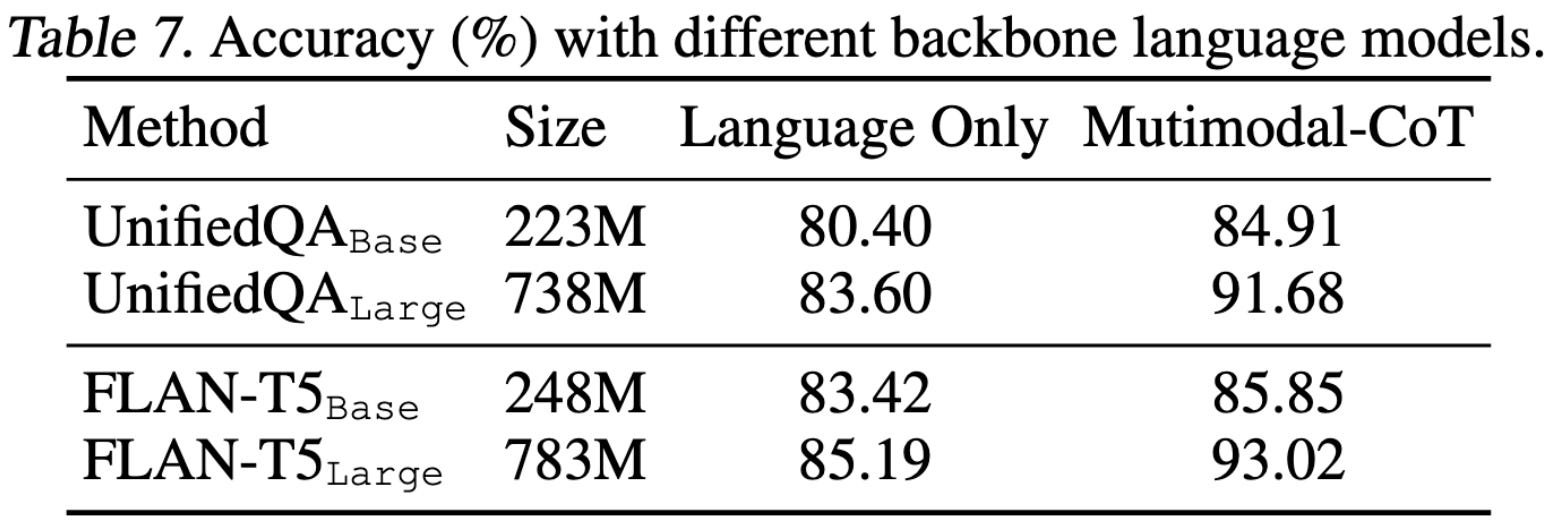
When their approach does make mistakes, they tend to be errors of commensense reasoning, or occasionally logic errors.

Also, they have a nice overview of existing chain-of-thought work; look at all those papers just from 2022…
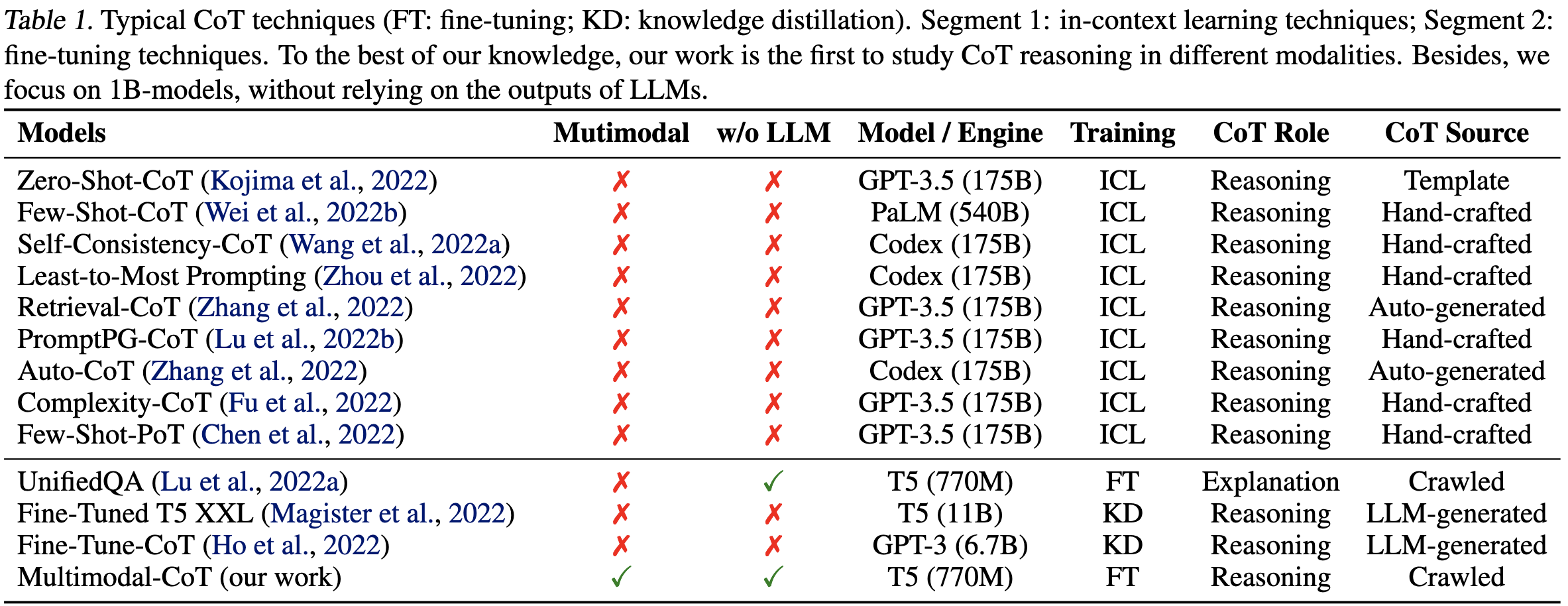
This is a super cool set of results that solidifies my conviction that we’ll all move to multimodal models in the next few years. It’s just hard to argue with the idea that seeing an image of, e.g., a duck can help you answer questions about ducks. And that’s not even including data quantity considerations—there’s essentially limitless video online, but only so much human-generated text…
Another paper that makes me feel like we’re living in the future.
Man people always forgetting ELMo (in the figure from the pretrained models history paper). It even started the muppet trend!