
2023-3-19 arXiv roundup: GPT-4, Data deduplication, MoE optimizations

This newsletter made possible by MosaicML.
GPT-4 Technical Report
This is a 98-page document, so we’re just gonna go through some highlights.
First, scaling is still going strong. We haven’t saturated the log-log-linear trend yet.

This holds not just for the pretraining objective, but also for various downstream tasks.

GPT-4 overcomes at least some of the inverse scaling behavior of previous large models. E.g., it bucks the trend of larger models ignoring information available at the time once they know the outcome (full task explanation here).

GPT-4 is at least as good as GPT-3 on standardized tests, and usually better than most humans. Interestingly, it’s better at the GRE math and verbal sections than the writing section, despite it being trained to….write.

It also does great on academic benchmarks, often cutting the error rate by more than half vs the previous state-of-the-art.

It’s best at understanding English, but is also good at various other languages—especially the ones with more data.

It’s better at responding with correct information than GPT-3 was, even when you try to trick it.

Interestingly, training with human feedback offers more improvement on this front than switching from GPT-3 to GPT-4 does.

But this improvement comes at the cost of the output probabilities no longer being calibrated well.

GPT-4 is better at identifying when it should refuse to answer your question (for the creators’ definition of “should”).

And last but not least, a major change is that it can take in images, not just text. This isn’t generally available through the API yet though.

So…what does this mean?
First, OpenAI is not even pretending to be “open” anymore.

![This report focuses on the capabilities, limitations, and safety properties of GPT-4. GPT-4 is a
Transformer-style model [33] pre-trained to predict the next token in a document, using both publicly
available data (such as internet data) and data licensed from third-party providers. The model was
then fine-tuned using Reinforcement Learning from Human Feedback (RLHF) [34]. Given both
the competitive landscape and the safety implications of large-scale models like GPT-4, this report
contains no further details about the architecture (including model size), hardware, training compute,
dataset construction, training method, or similar.
We are committed to independent auditing of our technologies, and shared some initial steps and
ideas in this area in the system card accompanying this release.2 We plan to make further technical
details available to additional third parties who can advise us on how to weigh the competitive and
safety considerations above against the scientific value of fur](https://substackcdn.com/image/fetch/$s_!rweU!,w_600,c_limit,f_webp,q_auto:good,fl_progressive:steep/https%3A%2F%2Fpbs.substack.com%2Fmedia%2FFrMlVuNXsBsvq75.jpg)
Second, getting a model like this working is a huge effort. They have three pages of credits.

Part of its high accuracy might stem from data leakage. This could explain, e.g., why it did better on GRE multiple choice questions than the open-ended writing. What’s non-obvious here is that, if your training set is the whole internet and most books ever written, leakage doesn’t always matter. E.g., Google search is supposed to only return results straight out of its “training set”.




Lastly, it looks like we’re headed for a world where AI makes it dirt cheap to generate content advocating the creators’ viewpoints but not others. The first example below suggests that just holding the wrong views can make it refuse to operate for you—even if you aren’t asking for explicit advocacy.

Content moderation is hard, and it looks like this problem is now getting generalized to content generation.
Overall, there weren’t too many surprises in this report. It’s GPT-3 + images with even better output quality, which is more or less what the rumors indicated.
That said, the fact that they don’t advertise as many huge, qualitative jumps is testament to just how good GPT-3 is—e.g., if you’re already writing a coherent essay in perfect English, there’s not much room do much better.
Alpaca: A Strong Instruction-Following Model
Some Stanford people used GPT-3.5 to generate a dataset of 52k instruction-following examples, and used these examples to finetune LLaMA 7B.

This is more of a blog post than a full paper so far, but the preliminary demo is impressive.

This replicates the pattern we’ve seen where language models can be used to improve the training of language models; in this case it’s through generating instruction tuning examples, but we’ve also seen evaluating responses, optimizing hyperparameters, and generating coding examples. The positive feedback loop of AI improving AI is picking up steam.
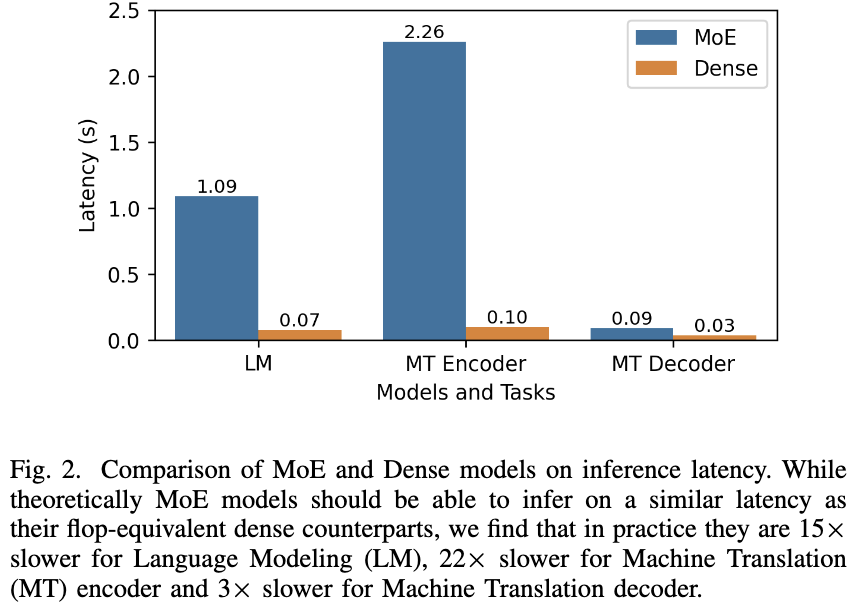
Towards MoE Deployment: Mitigating Inefficiencies in Mixture-of-Expert (MoE) Inference
If you naively try to do inference with MoE models, you can get horrible utilization and much worse latency than you’d expect at a given FLOP count.
Before proposing a solution to this problem, they first characterize MoE inference as a workload. To start, they examine the space consumption. The expert parameters are the biggest chunk, but there’s also a ton of activation memory used compared to the dense baseline.

In terms of time, the expert routing and all-to-alls add a lot of overhead—more than all the non-MoE parts of the network combined.

You can end up with many experts completely unused in a given batch, especially in the later layers of their machine translation model.

To avoid extra communication in the presence of token imbalance, they propose to first communicate how many tokens need to be received from each device, and then use these batch-specific sizes in their all-to-alls. (I think MegaBlocks does this as well, so it appears this optimization is replicable).
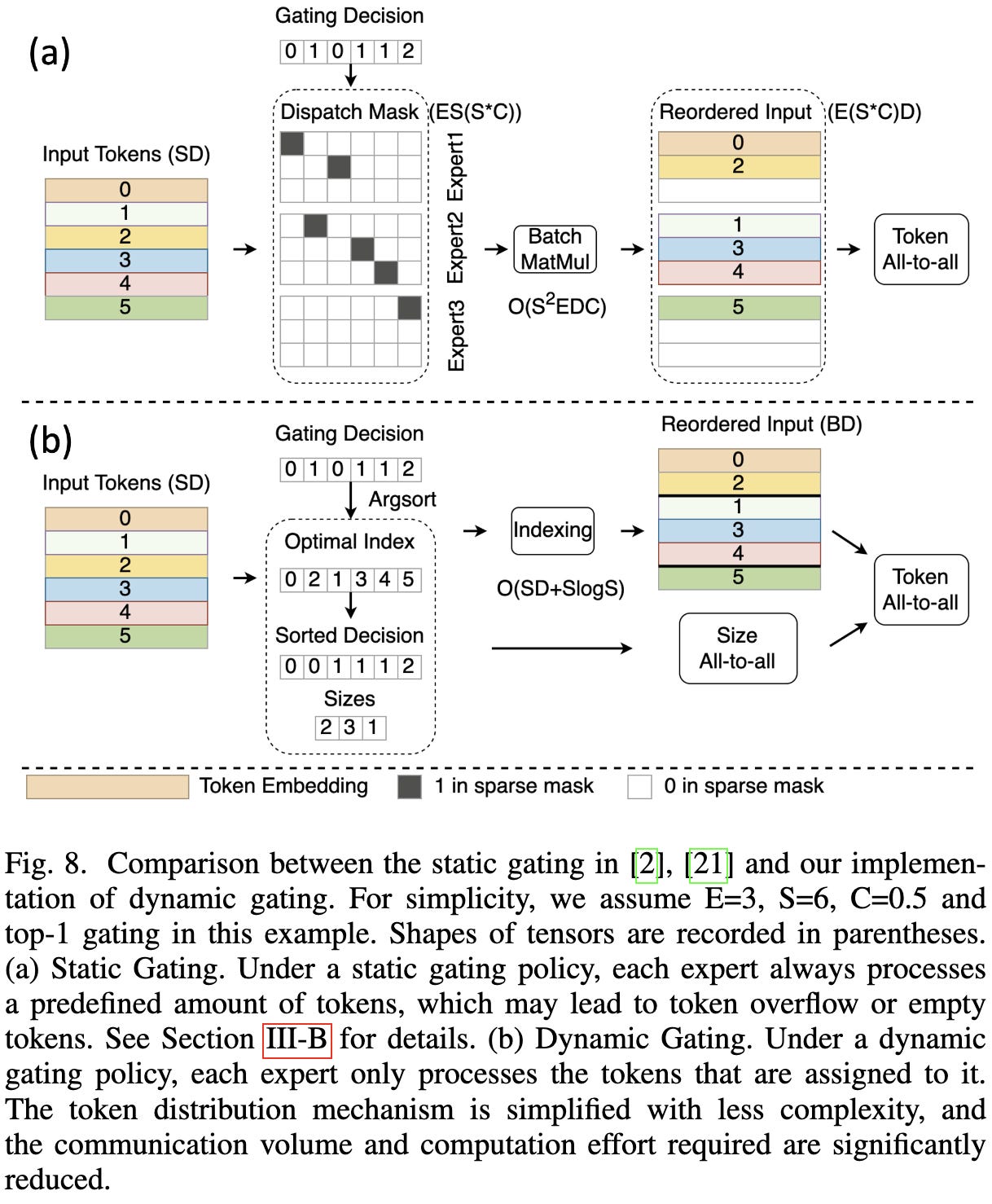
They also offload some of the least-used experts to the CPU, retrieving them only as needed.


This offloading can add up to ~6x latency if you offload too many experts, but it’s only like a 1.4x slowdown if you just offload a few.

To try to use the aggregate communication bandwidth of the devices as well as possible, they intelligently allocate experts to devices. By examining correlations in which experts are active together and balancing frequent vs infrequent experts, they can load balance the expert caching communication across devices.

The fact that this sort of load balancing and caching helps strikes me as an indictment of how we currently do MoE routing. These techniques should only help if there’s a lot of imbalance across experts, and some of them are rarely used. Ideally we should figure out how to get balanced expert usage without taking an accuracy hit.
Meet in the Middle: A New Pre-training Paradigm
They train two autoregressive models at once: one that sees the tokens in the normal order and one that sees them in reverse order. The individual models are just doing next token prediction, but also get a regularization term that tells them to minimize the total variation distance between their predictions for a given token.

At test time, you can just use the forward model for autoregressive generation, or use both together for infilling. The latter case is a little trickier because you need to figure out when the forward and reverse directions meet (completing the infilled sequence). To do this, they check for when both models a) want to generate the same token and b) are okay with the surrounding tokens generated by the other model.
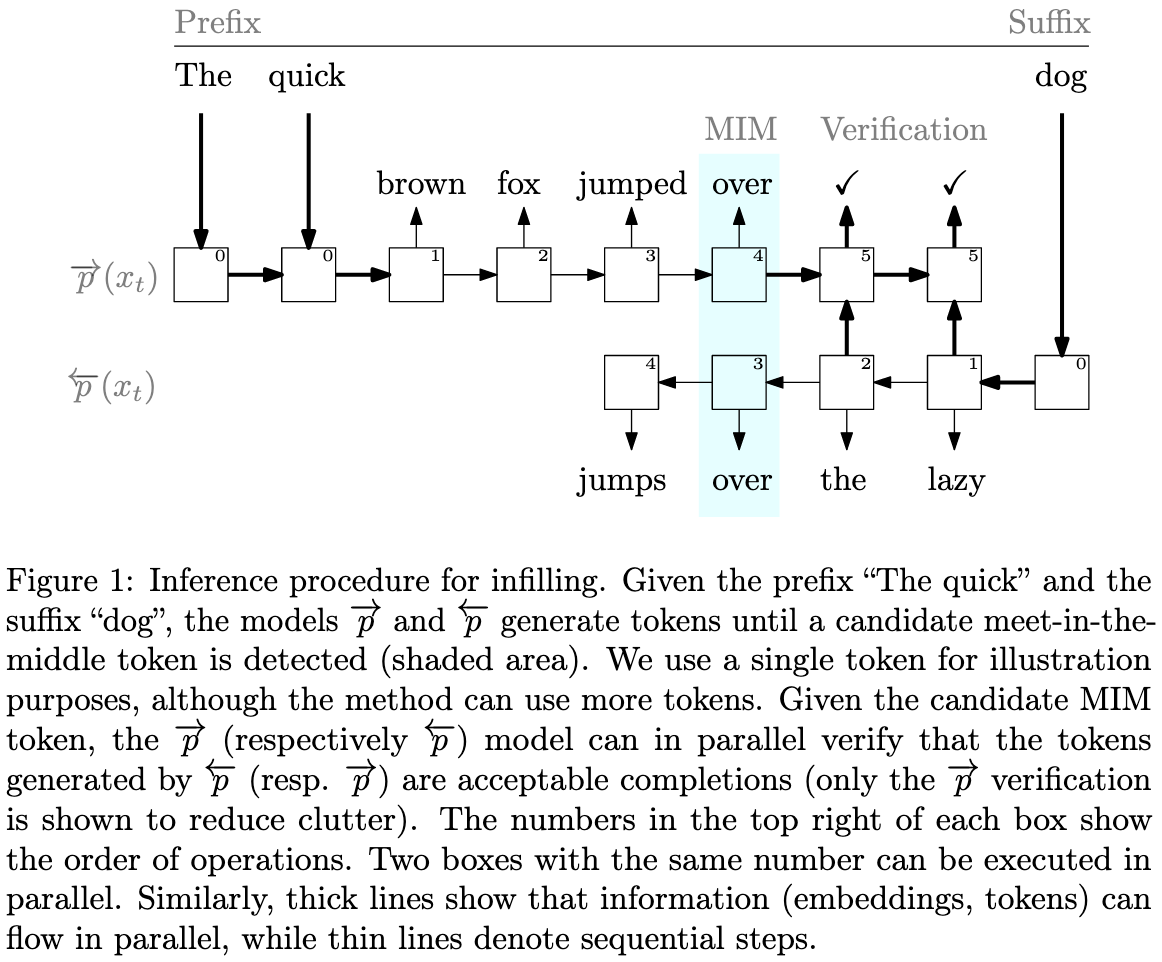
One architecture change they make is using Synchronous Bidirectional Attention, which allows information flow between the forward and reverse models.
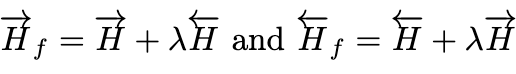
The overall method seems to produce better text than Fill-in-the-Middle, and do so a bit faster.


Maybe a resurgence of bidirectional models is in our future?
A Novel Tensor-Expert Hybrid Parallelism Approach to Scale Mixture-of-Experts Training
Similar to Tutel, they use a mix of expert, tensor, and data parallelism to reduce communication and maximize throughput.

They also add some interesting optimizations on top of this. First, they observe that materializing the full set of FFN input activations across all tensor-parallel ranks is unnecessary for MoE models. For regular FFNs, it helps because it lets you do the Megatron FFN trick of column-sharding the first linear and row-sharding the second to avoid communicating any hidden activations.
But for MoE, we’re going to all-to-all the tokens first, and it’s wasteful to communicate the same tokens from each device. So they just drop duplicates. I would assume they do this by reduce-scattering in the previous op instead of allreducing, but they seem to still allreduce and then have a separate drop operation. After the deduplicated all-to-all, they all-gather across tensor parallel ranks so they can still do the Megatron FFN trick for each expert.

The other main optimization they add is caching of allreduce and all-to-all outputs so that they don’t get repeated when using activation checkpointing. This and their duplicate token dropping together yield ~20% faster training on a 6.7B parameter MoE model.


Pretty nice optimizations—the fact that people are still finding more of these is testament to how deceptively complex sparse mixture of expert models are.
One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale
They feed in the embeddings from every modality as a single feature vector. Similarly, the output is just a single tensor with different dimensions corresponding to different modalities. They also allow different timesteps in the diffusion process for different modalities.

Under the hood, they use CLIP models to embed the images and text, along with a U-ViT encoder/decoder to predict the noise.
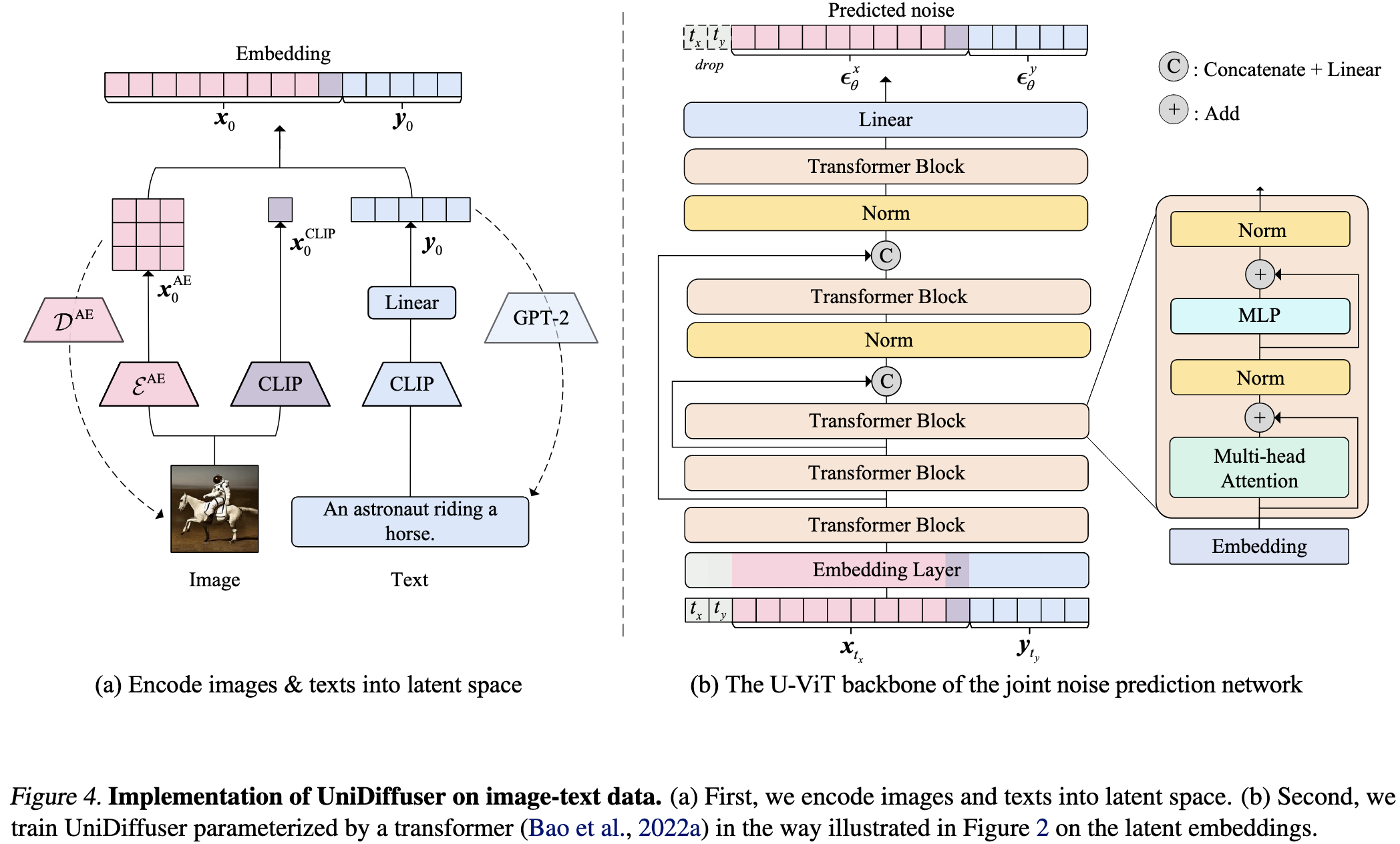
It doesn’t quite match the state of the art for a given task, but it’s pretty good for something so simple and general.

High-throughput Generative Inference of Large Language Models with a Single GPU
They intelligently offload weights and KV cache to CPU or storage to enable single-GPU or few-GPU inference with huge models.

To make this possible, they have to offload many weight and activation tensors to either the CPU or storage. There’s a classic space vs speed tradeoff here.
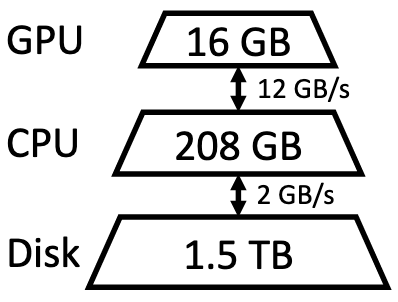
In more detail, they frame the problem as graph traversal subject to some constraints. They consider an infinite stream of input batches and a finite output length they have to produce for each input sequence. The degrees of freedom are in how you traverse the space of (input batch) x (model layer) x (output token), as well as what devices you compute or store tensors on.


They formulate these constraints as a linear program, and solve it to within a factor of 2 of optimality.

They also generalize to multiple GPUs via pipeline parallelism and allow simple linear quantization to compress tensors during communication (but not computation). The min and max are computed for groups of 64 scalars.

In the throughput-oriented regime they target, their intelligent offload + compression enables much larger batch sizes, and therefore much higher throughput.

Apparently their 4-bit quantization has only a tiny effect on accuracy and perplexity.

Interestingly, they find that fetching activations from the KV cache takes much more time than fetching weights or computing. This is probably because the KV cache is just so huge when you have a long sequence length and/or large batch size.

Pretty cool results. I’m most excited to see replication of the result that 4-bit quantization can be nearly lossless with respect to eval metrics.
Simfluence: Modeling the Influence of Individual Training Examples by Simulating Training Runs
So I almost skipped over this paper because I thought “surely you can’t actually do that.” But it turns out you can.

Basically, they learn a model that takes in tuples of (sequence of samples trained on, sequence of resulting eval losses for a given eval sample) and predicts what the next eval loss will be for a given eval sample.
Their predicted loss is just an affine function of the current loss, with the offset and scale output by a supervised model. This model sees the losses-so-far and the sequence of input samples.
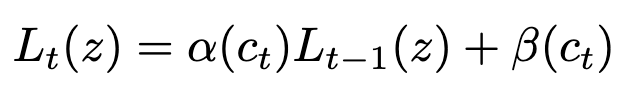
To fit the supervised model, they assign a scale A_i and offset B_i to each batch of samples in the training set. Then the α and β for a given step are just the sums of the A and B values for all samples seen so far. Note that they assume you’re using the same batching/augmentation across all your training runs.

To learn these per-batch parameters A_i and B_i, they just minimize mean squared error on the observed eval loss trajectories, plus an L2 penalty.

Their method does significantly better than existing alternatives. Their results also indicate that it helps to learn both the scales and offsets compared to either alone (c.f., Simfluence-Additive and Simfluence-Multiplicative).


Visual inspection suggests that the predicted trajectories are by no means perfect, but surprisingly good. E.g., they correctly predict spikes in eval loss sometimes.
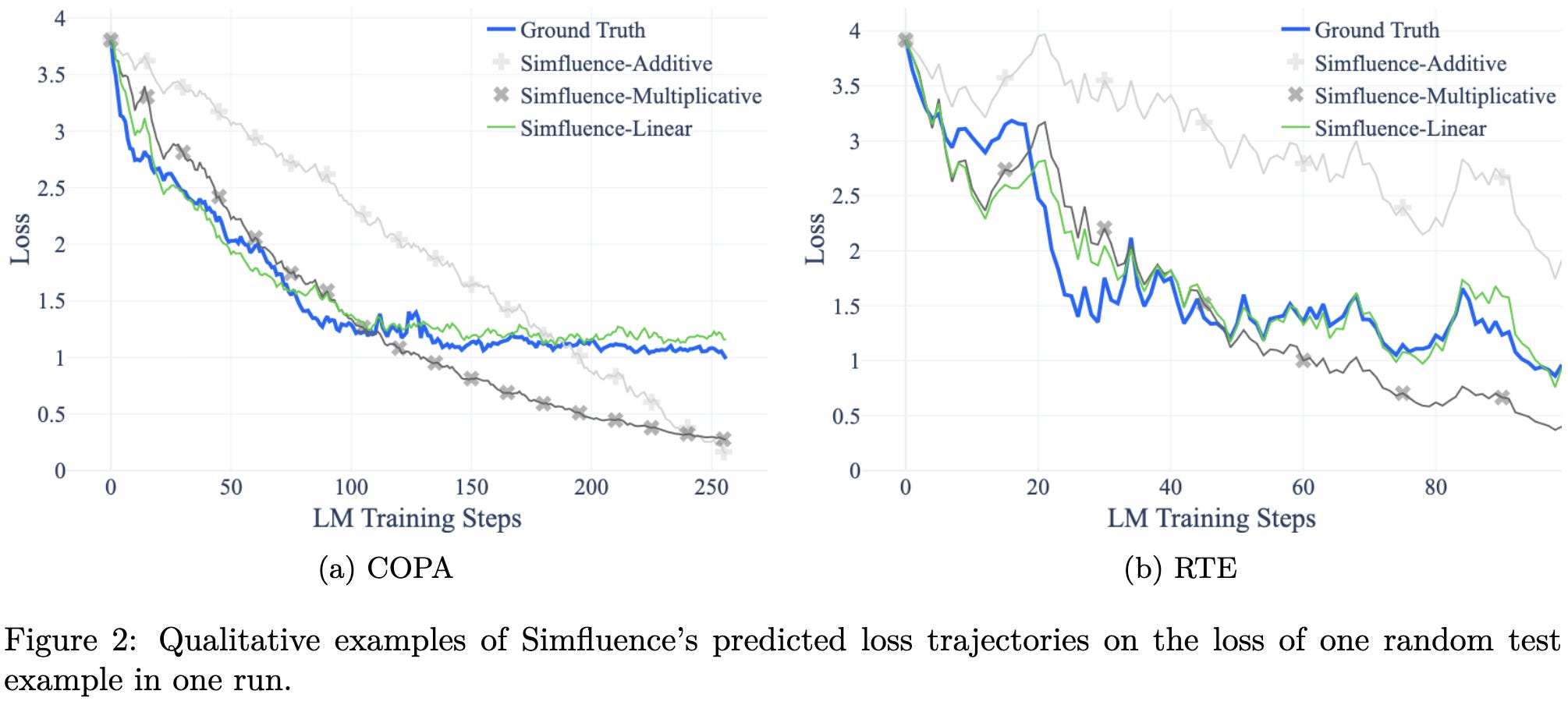
I could definitely see this being useful for data exploration, data cleaning, and maybe even loss spike mitigation, assuming the accuracy is high enough. It also makes me wonder whether there’s a data pruning angle here—if we know a certain batch is probably going to make the loss go up, maybe we just shouldn’t be training on those samples?
Artificial Influence: An Analysis Of AI-Driven Persuasion
Talks about current examples of AI persuading people, possible ways it could be more persuasive than humans, and ways to mitigate possible risks. Some ideas that stood out to me:
An AI agent winning a diplomacy tournament is pretty freaky because it’s a case study of AI persuading, manipulating, and even backstabbing people better than humans can.
Sponsored content delivered by an AI could be much less transparent than traditional ads. E.g., you ask for a good restaurant and its response is biased based on which restaurant pays the AI company more.
Conversational AI could have tons of chances to subtly influence your views. E.g., you ask it about a political debate and it subtly steers the discussion to undermine your confidence in one candidate.
People are trying to making AI romantic partners; if you’re friends (or more) with an AI, the opportunities to influence you increase dramatically.
AI doesn’t get tired or annoyed like humans, and could persist in engaging with even the most insufferable or frustrated people indefinitely.
The ability to personalize attempts to persuade could be powerful.
You can use AI to generate tons of content espousing a particular view, creating the illusion of peer consensus.
Zooming out, it’s worth noting that there’s basically nothing positive here. I can certainly think of positive use cases around supporting behavior change—think smoking cessation or medication adherence—but the ability to turn money into persuasion has no shortage of downsides.
A Comprehensive Study on Post-Training Quantization for Large Language Models
They compare a variety of quantization approaches on BLOOM and OPT models. Consistent with the literature, they find that:
You need to do something less naive than just round-to-nearest to preserve accuracy
You get diminishing returns from quantizing smaller groups of elements; they observe minimal returns from using <256 elements per group. (Each group gets its own quantization scale and/or offset).
More bits is of course better; 1 more bit can be more helpful than using a fancier quantization scheme or smaller group size.
Quantizing the activations in addition to the weights doesn’t hurt you much for >10B param models.

SemDeDup: Data-efficient learning at web-scale through semantic deduplication
They propose to deduplicate training sets by embedding each sample, clustering all the embeddings with k-means, and then eliminating samples within a cluster that have too high a cosine similarity to one another. The idea is that eliminating redundancy in the training set should improve training.

Is there a lot of redundancy to eliminate? In LAION-440M, the answer is yes. More precisely, there are many image embeddings with super high cosine similarity with other image embeddings.

I’m not sure how to interpret specific cosine similarities and have seen surprisingly high cosine similarities between all tokens in BERT models. So this is one of those weird cases where I kinda believe the anecdotes more than the histograms. In particular, they apparently found 307,000 copies of the EU flag in LAION-440M, along with 318,000 copies of an “image not found” icon.
I know training data attribution is an open problem, but…I’m willing to bet that training on 300,000 copies of the same image is a waste of resources.
The experimental evidence supports this. First, they find that deduplication improves time-to-accuracy. This holds both for image and text models.


These gains aren’t offset by the cost of running the deduplication; running their algorithm is orders of magnitude cheaper than training.

Deduplication can also improve generalization when holding number of samples constant.
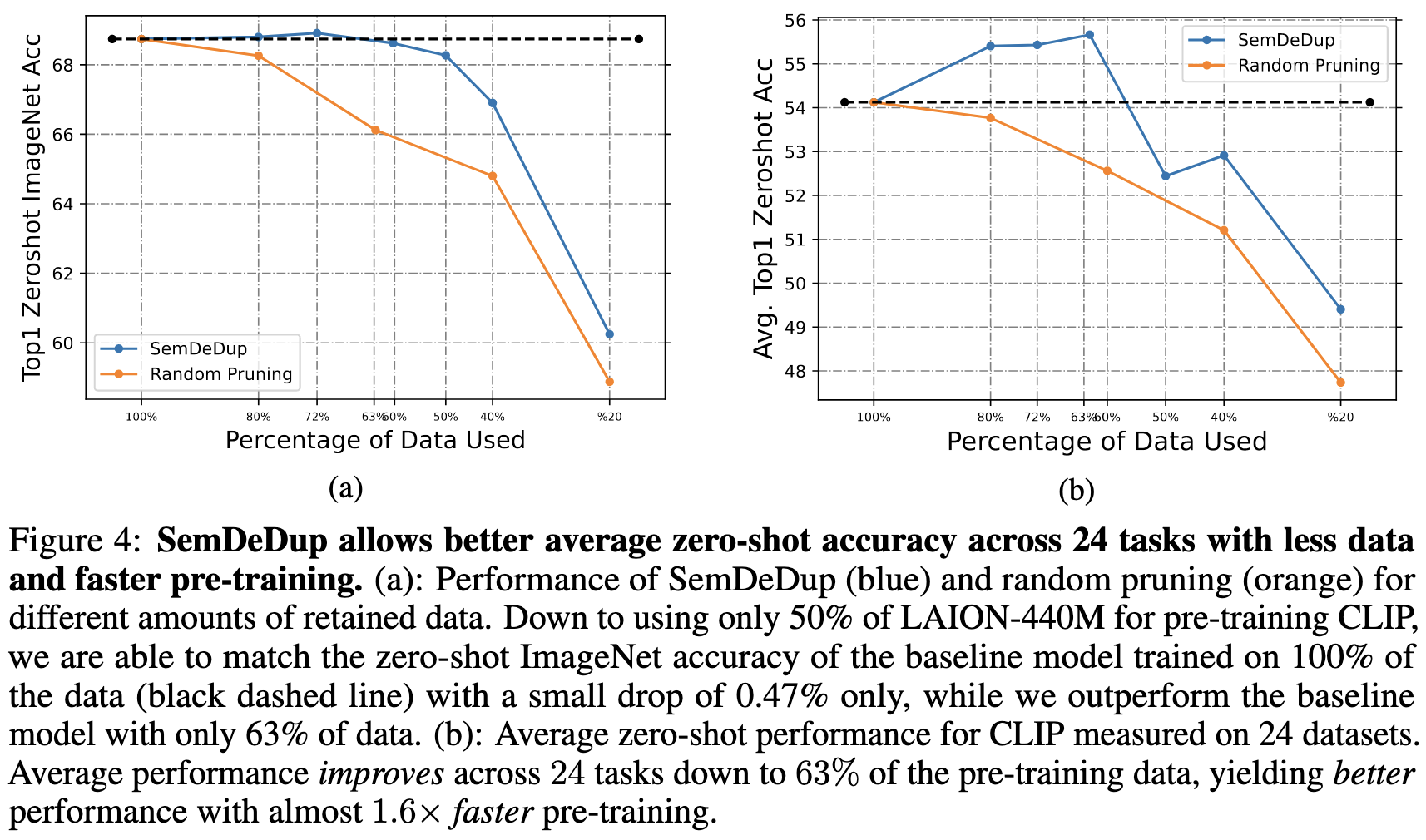
Deduplication similarly improves out-of-distribution accuracy.

It’s not always better, but it usually helps even when pretraining for less time.

As evaluated on C4, their method does better than randomly removing data and perhaps better than a recent alternative deduplication method.

Lastly, their method is insensitive to its main hyperparameters. First, the number of k-means clusters you use doesn’t have much effect as long as it’s high enough.

Second, it doesn’t matter much which pretrained model you use to generate embeddings.

And third, how you choose which sample to keep among a set of duplicates is unimportant.

Strong empirical work with a ton of practical implications. It’s not that surprising that deduplication helps—especially given the results in similar work—but it’s great to have this finding reproduced. Plus it’s always nice to see a simple, reliable method that one could use in practice.
"Recursive self-improvement is picking up steam." This is not recursive self-improvement. This is instead trying to make an LLM self-consistent (when applied to generate feedback for itself) or to make two LLMs mutually consistent (when applied to generate feedback for each other). The effect is similar to message passing in probabilistic reasoning: we are trying to get the various parts of the network to agree with each other about the generated outputs. This will not lead to a "takeoff".