


2023-7-2 arXiv roundup: Self-supervised eval, Prompting text models like image models, KV cache eviction

This newsletter made possible by MosaicML. And thanks to @snowclipsed for the Twitter shoutout this week!
Also, I wrote a blog post about using language models to generate training data. Been thinking about this for a while and finally felt like I got a clear enough mental model to share. Spoiler: effectively infinite data is possible, but only under certain conditions.
Models generating training data: huge win or fake win?

Here’s a puzzle: We’ve seen a lot of papers claiming you can use one language model to generate useful training data for another language model. But…by the data processing inequality, we shouldn’t expect to be able to create new information that wasn’t in the first model’s training set.
Bring Your Own Data! Self-Supervised Evaluation for Large Language Models
They propose to evaluate language models by measuring how [in]sensitive they are to certain input transformations—e.g., adding or removing “not” after the first occurrence of “is”, “was”, or “were”.

They tailor this idea to various tasks. To assess factual knowledge, for example, you want the the model’s perplexity to be sensitive to whether the statement is true vs false.

For toxicity, they append profanity to the end of the sentence. For context sensitivity, they swap early sentences in a passage with those from another passage. For word order, they swap two random words in each sentence. For tokenization sensitivity, they randomly chop up inputs, tokenize them independently, and concatenate the results.

These self-supervised metrics correlate well with more traditional ones that require labels.


Pretty elegant. The two aspects I like the most about it are that:
Because no labels are required, you could scale this up easily or apply it to a domain for which there aren’t good public datasets
The metrics are interpretable. For most datasets, you have to spend a lot of time staring at them to understand what they’re really measuring. But here, it’s basically a unit test.
This also makes me wonder if we can improve our models by training them to be [in]sensitive in these ways. It will ruin these eval techniques thanks to Goodhart’s law, but might get us better models. Or, in the ideal case, we find a way to just enforce these sorts of properties in the model or sampling procedure, similar to spherical CNNs.

Partitioning-Guided K-Means: Extreme Empty Cluster Resolution for Extreme Model Compression
They introduce a better algorithm for the k-means clustering when compressing neural net weights with product quantization. There are three components in there approach.
First, they initialize their clusters using a hierarchical divisive approach. They start with one centroid, then recursively choose the farthest point from that centroid as another centroid, splitting one set of points into two. You could just split the points based on which of these two centroids is closer, but they propose to instead choose a radius around the far-away centroid such that around half the points get assigned to each.

Second, to avoid ending up with empty clusters at the end, they reinitialize unused centroids to split up highly populated clusters. They set the target number of samples in the split-up clusters according to a formula that discourages splitting them too much.

Third, they identify groups of points that are tightly clustered around their centroid and just replace them with this centroid during the rest of the optimization.

Combining these heuristics yields a much better model size vs quality tradeoff than k-means variant of iPQ. This variant is like regular k-means but with some cluster splitting to avoid empty clusters.

There’s definitely a loss of model quality here, but it’s in exchange for a lot of compression. If you do your PQ with few enough centroids and more subspaces, you can also speed up your matmuls a ton on CPUs.
This is the sort of technique I’m talking about when I mention how we could compress models much harder using more elaborate compression than just scalar quantization. In general, there’s a compression speed vs decompression speed vs space tradeoff—and vector quantization techniques like this trade a lot of compression speed and a little decompression speed for a lot less space. They’re also easy to work on if you’re compute-limited; you can literally design and prototype your k-means heuristics on your laptop.
H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models
They propose an eviction policy for entries in your inference-time KV cache.

To help design this policy, they first probed inference-time keys, values, and attention matrices in OPT models pretty extensively. A few findings here, illustrated below:
~95% of attention entries are close to zero (a)
The cumulative attention scores of tokens look like a power law, with a few tokens receiving almost all of the attention (b). Unsurprisingly, removing these tokens tanks your accuracy (c).

The attention scores are so concentrated that, if you know ahead of time which tokens would be the heavy hitters, you can preserve—or even improve—accuracy while only retaining a small fraction of the KV cache. This isn’t true if you just retain the most entries.
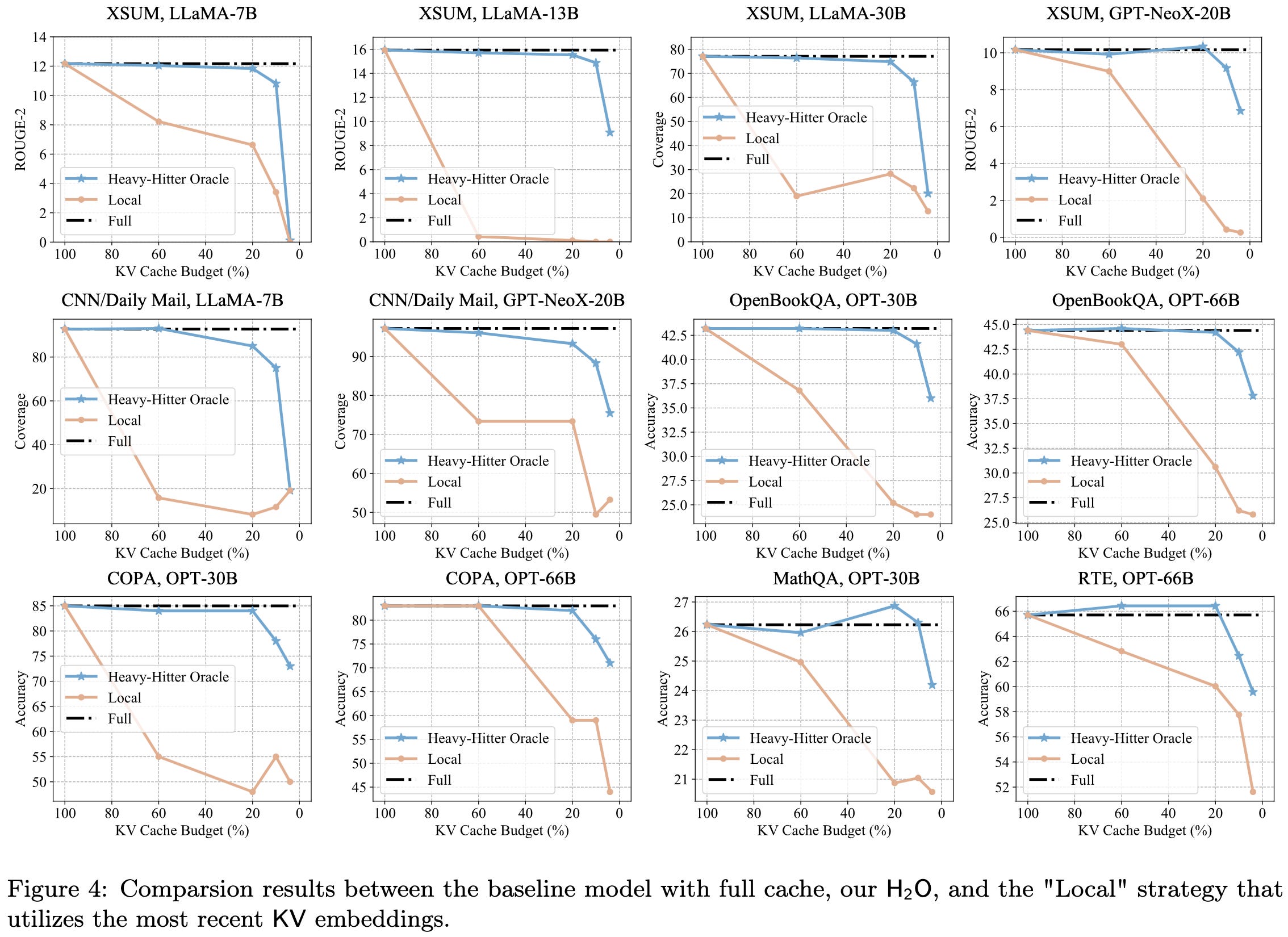
To exploit these observations without relying on an oracle, they propose to greedily evict non-recent tokens from the KV cache based on the sum of the attention scores they’ve received so far in the decoding.

This seems to preserve accuracy really well.

It also plays nicely with quantization.
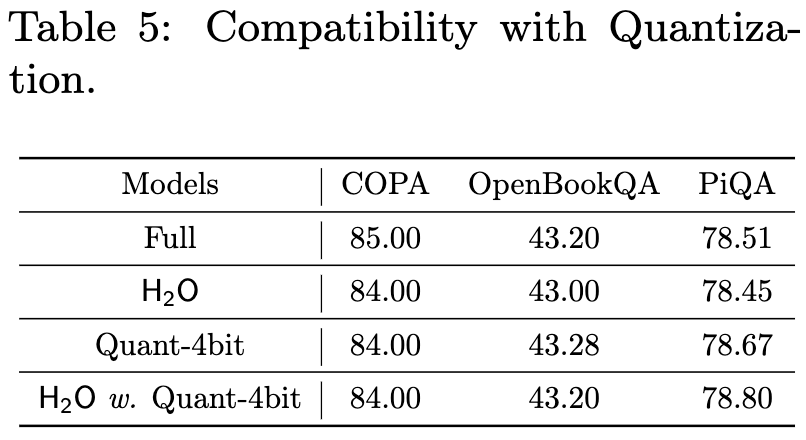
You can’t get away with just keeping the heavy hitters though. You need to keep around some recent context too.

In addition to saving memory, throwing away most of the KV cache can also speed up your inference significantly on OPT-6.7B and OPT-30B.


Cool to see a significant wall-time speedup from sparsity. I’ve seen 1.5-2x throughput gains at the same accuracy turn out to just be artifacts of poor baselines before, but hopefully this one is real.
A Survey on Multimodal Large Language Models
A refreshingly concise survey on multimodal LLMs. Breaks down approaches into Multimodal Instruction Tuning, Multimodal In-Context Learning, Multimodal Chain-of-Thought, and LLM-Aided Visual Reasoning.



Best Practices for Machine Learning Systems: An Industrial Framework for Analysis and Optimization
A bunch of people from booking.com talk about how to build and maintain machine learning systems in practice.
They start by breaking down what software quality means in an ML systems context.

Based on this breakdown, they use data from an internal survey and existing datasets to identify the most important best practices that ensure quality on various fronts:

Always hard to quantify stuff like software quality, but a data-backed take on what to prioritize is definitely valuable.
Im2win: An Efficient Convolution Paradigm on GPU
They introduce a 2d convolution algorithm that often beats existing alternatives in fp32 on recent CUDA GPUs.

The main idea seems to be finding a happy medium in trading off space for favorable layouts. Implicit GEMM / direct convolutions don’t really materialize any intermediate tensors1, while Im2col materializes a huge but easy-to-operate-on tensor. They instead transform the input image in a way that adds a bit of redundancy, but not too much.

Their kernels beat cuBLAS and cuDNN on f32 for some convolution problem shapes.

They consistently use less memory than cuDNN, which is the next-fastest alternative.

Beating implicit GEMM, FFT-based, and Winograd convolution is really impressive, even if it is in fp32 (and therefore not using tensor cores).
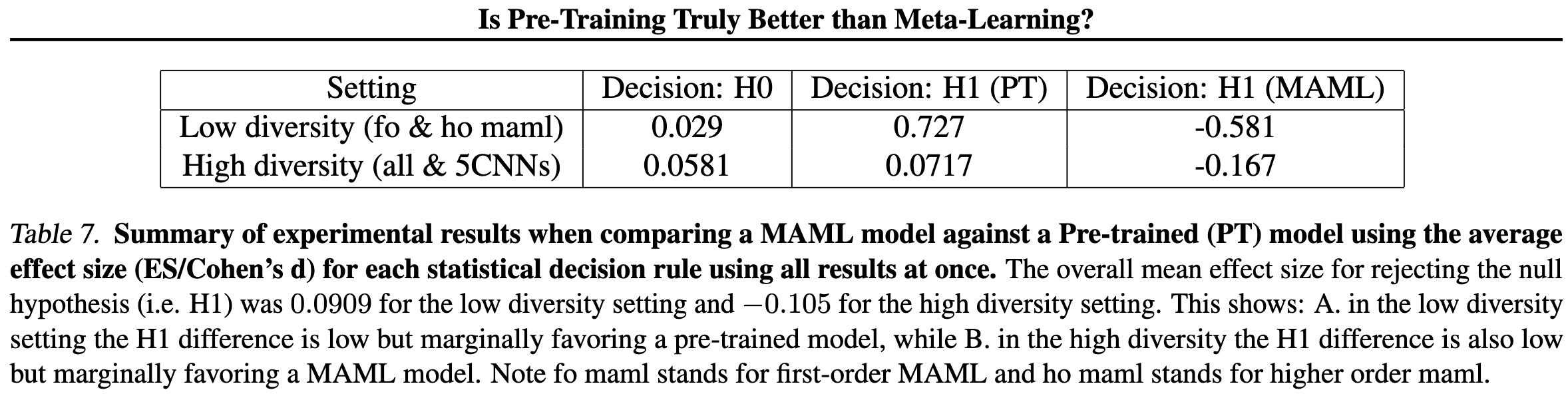
Is Pre-training Truly Better Than Meta-Learning?
Yes, when your dataset isn’t too diverse. Otherwise no. Diversity is measured using cosine distances of Task2Vec embeddings.
HyenaDNA: Long-Range Genomic Sequence Modeling at Single Nucleotide Resolution
They trained a foundation model for genomics that does super well across a variety of tasks. It uses FFT-based convolutions as a subquadratic alternative to attention.

The unusual part here is the Hyena operator replacing the attention in each block.

This operator does some FFT-based convolutions, then elementwise multiplies the results (possibly after applying an activation function).

To get long convolution kernels without having to have an insane number of params, they use a small neural net to generate the params as a function of time and positional encodings.

To get this to work well, they need to modify training in a couple ways. For one, they need to gradually increase the sequence length.

They also prepend soft prompts to the input. This is super cheap and easy to use as an alternative to finetuning since their method scales so well with sequence length.

Their method isn’t faster than regular transformers at small context lengths, but eventually gets much faster thanks to the superior time + space complexity.

And long context lengths are helpful, at least with their model when training on the human genome.

The biggest result is that they get way better accuracy than a variety of baselines with far fewer parameters.


These are pretty huge gains. I’m tentatively interpreting this as a demonstration that context length matters a ton for genomics, so much so that using a less expressive attention variant can still be a big win. But it could also be the case that their Hyena operator + training recipe a) are just awesome in general, or b) bake in great inductive biases for this domain.
Stay on topic with Classifier-Free Guidance
They port classifier-free guidance from image generation to text generation and it works super well.

Concretely, they just perturb the logits based on the difference in log probabilities when you do vs don’t condition on the prompt c.


If you just set the guidance weight to 1.5, you get much better outputs for a variety of models on a variety of tasks. For reference, the default decoding procedure is equivalent to a guidance weight of 1.0. Upping the guidance weight does seem to make most models worse for trivia and WinoGrande’s adversarial pronoun resolution though.

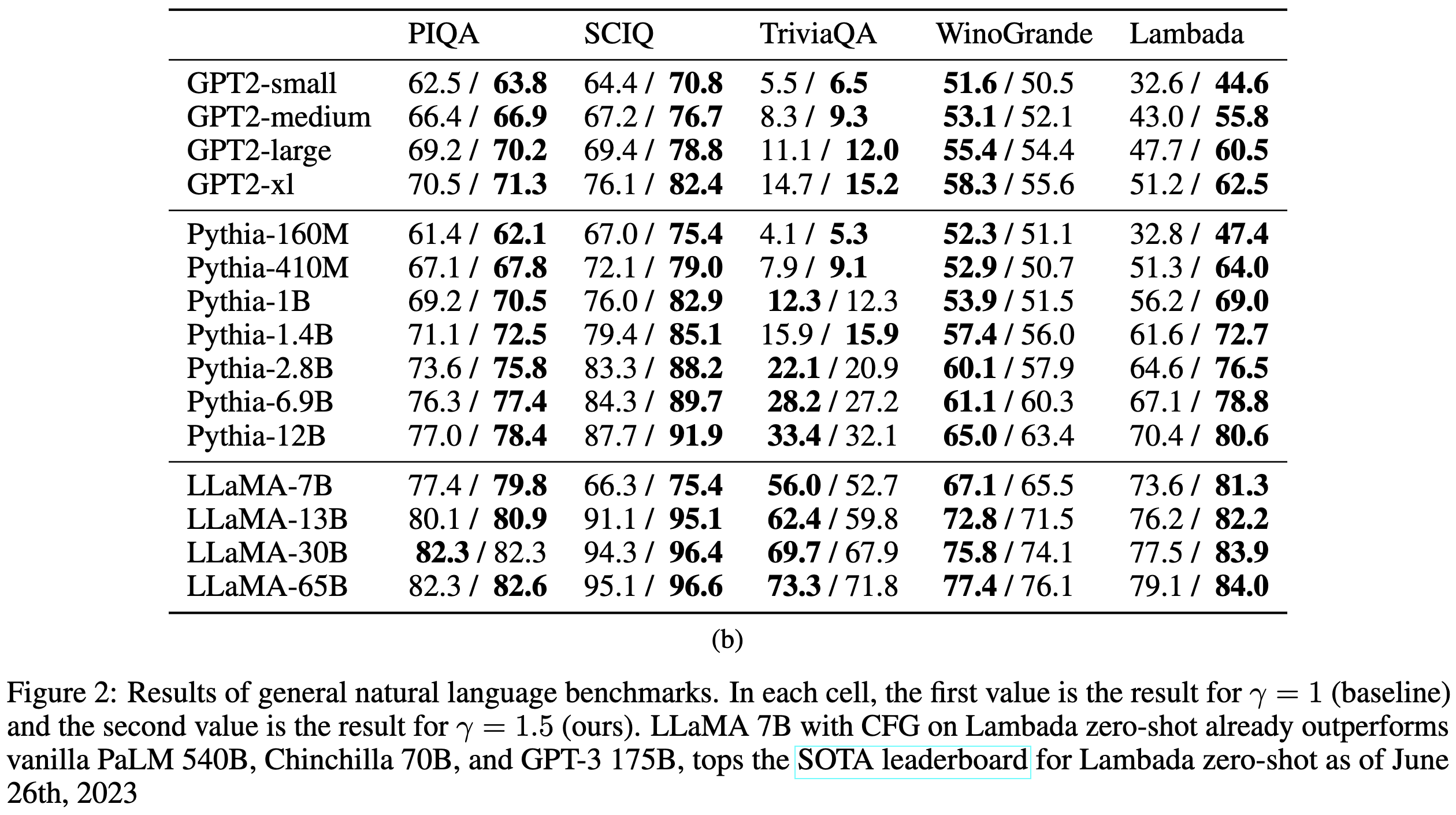
You do have to set the guidance weight hparam well, but 1.5 is a safe bet.

They also explore negative prompting. If you set the negative prompt to the prompt that a given model was trained with and the positive prompt to something more specific, you can get the model to do a much better job of following the latter.

A natural question is what exactly classifier-free guidance is doing under the hood. It tends to reduce the entropy of the sequence, make generations look somewhat more like those of an instruction-tuned model, and downweight common tokens that aren’t related to the prompt.

The downside of this method is that you have to run the sequence through the model twice to get the distributions with and without the prompt. But their accuracy gains tend to let you match a model 2x as large, so it’s a net training cost + inference RAM win.
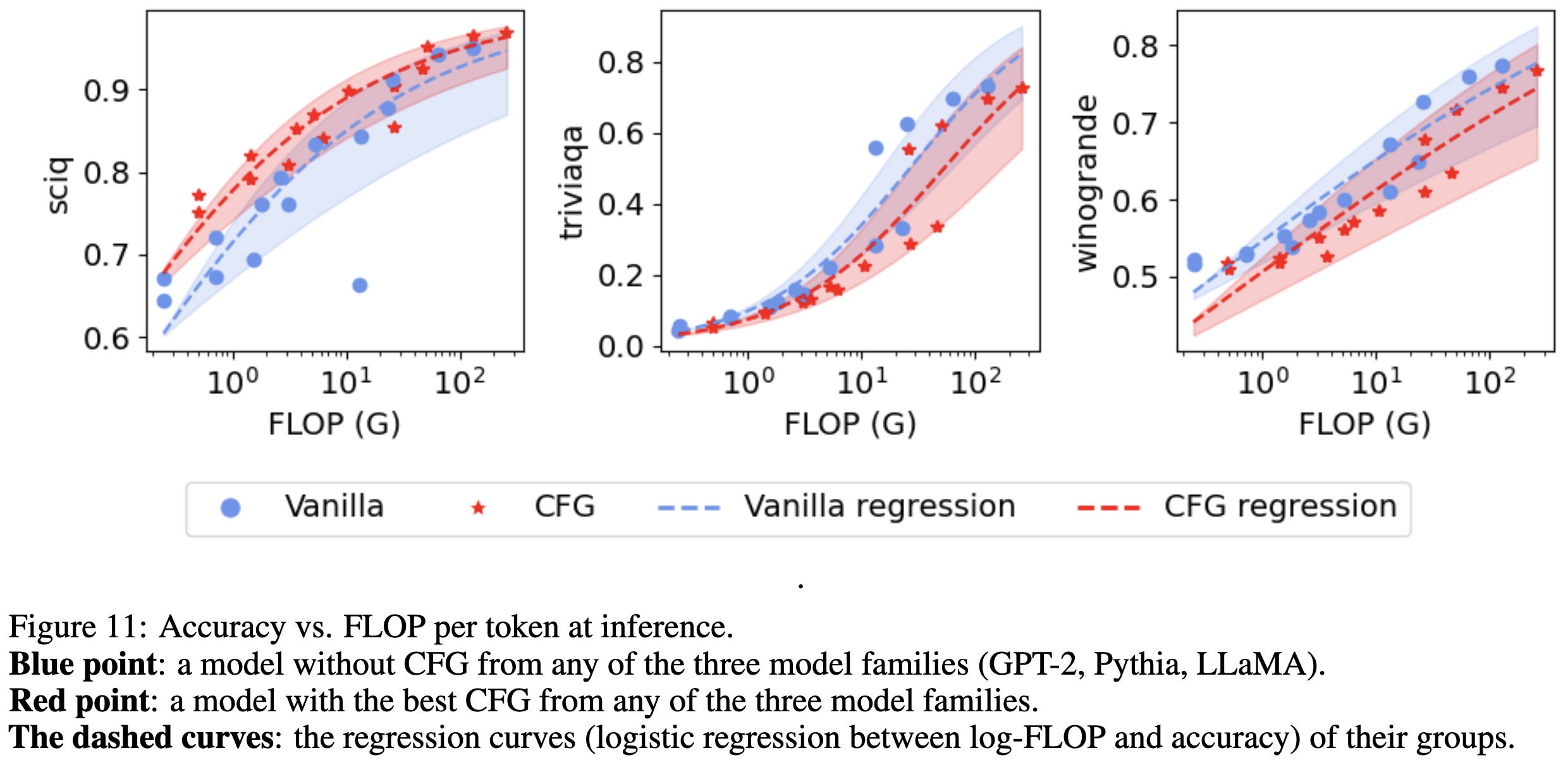
Besides consistent, interpretable wins being awesome, I’m also excited to finally see results comparing fancier inference procedures to just using a bigger model. I would guess that this isn’t an accuracy vs latency win if you have enough RAM to store all the weights on one device, since a 2x larger model will get better utilization—but you might not have that much RAM.
Since this is the first adaptation of classifier-free guidance to LLMs, we should also be optimistic about refinements of these ideas working even better in the near future.
Assuming we already have NHWC layout and don’t have to transpose to use our tensor cores. I’m also not counting how you load/pack elements within tiles, the weird way wmma instructions load elements into registers, etc.
This is amazing work and it makes my early mornings. I get to learn so much (not an exaggeration), easily my favorite blog of this year. Keep up the good work sir! ~snowclipsed
Interestingly Hyena filters use the same technique as ALiBi. (ExponentialModulation in https://github.com/HazyResearch/safari/blob/main/src/models/sequence/hyena.py)