

Here’s a puzzle:
We’ve seen a lot of papers claiming you can use one language model to generate useful training data for another language model.
But…by the data processing inequality, we shouldn’t expect to be able to create new information that wasn’t in the first model’s training set.
So how do we reconcile these observations? Is generating training data a nearly-free-lunch or an illusion?
The observations to explain
To solve this, let’s start by reviewing some representative evidence. Skip to the next section if you just want the punchline.
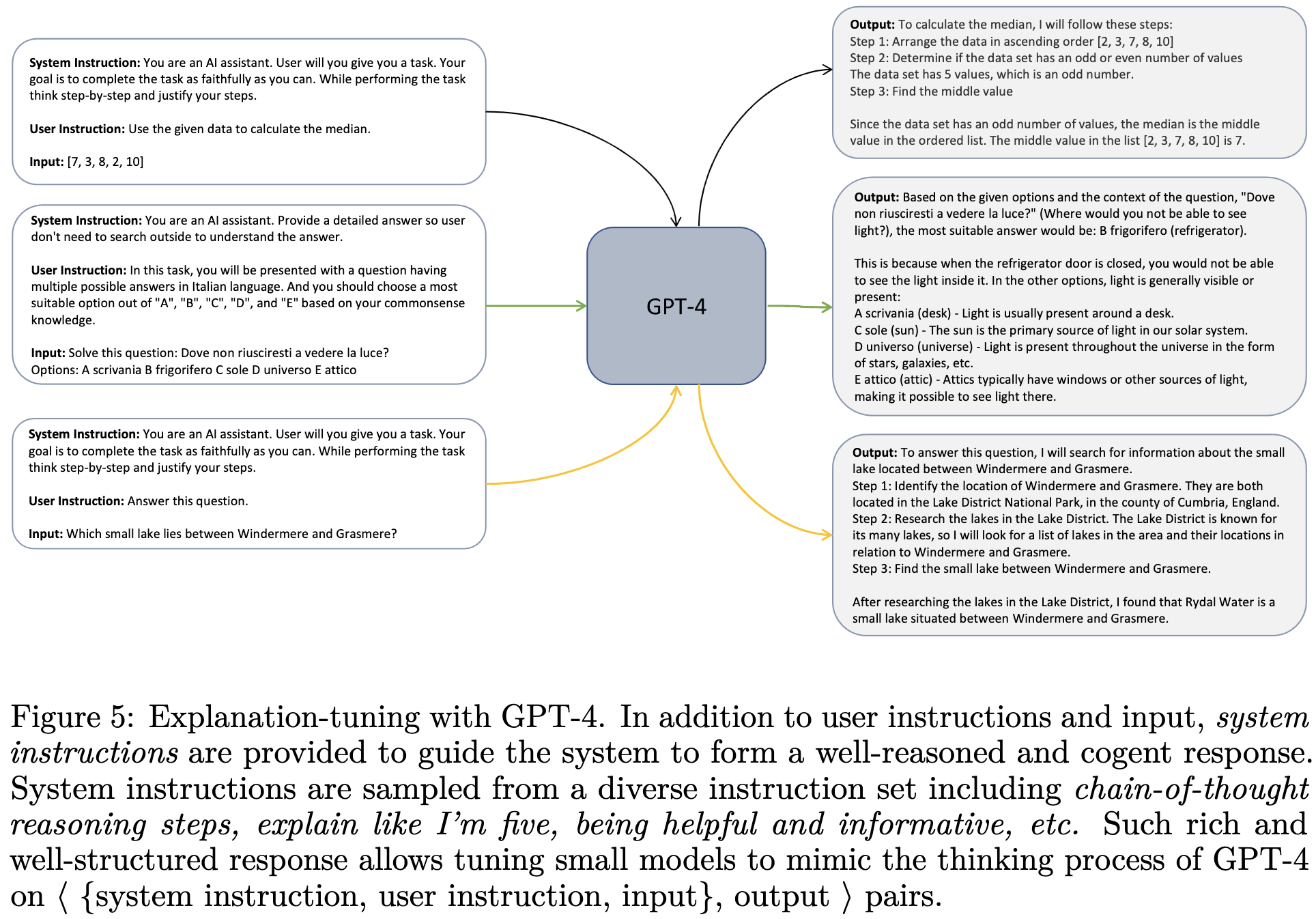
One of my favorite examples of generated training data seeming to help is Unnatural Instructions. This paper found that generating + finetuning on many instruction-following examples from an LLM could lift model quality a lot (orange dots). Not quite as much as human-generated examples (blue), but much more than the original models (see the positive slopes).

Along the same lines, we have Language Models Can Teach Themselves to Program Better. This paper iteratively generates + trains on programming puzzles to make their model better at programming.

More recently we’ve seen Textbooks Are All You Need get nearly state-of-the-art code generation from a small model using a small-but-high-quality dataset generated in part by GPT-3.5.

Impossible Distillation also got huge accuracy lifts with a small, domain-specific model. In their case, they iteratively generated data with this model and then finetuned on that data.

And lastly, the Orca paper got huge accuracy lifts by extracting + training on entire explanations from GPT-4, rather than just answers.
On the other hand, The False Promise of Imitating Proprietary LLMs found that training on outputs from another model lets you copy the form of the outputs enough to fool various eval metrics, but doesn’t really add capabilities.

Similarly, The Curse of Recursion: Training on Generated Data Makes Models Forget shows both in theory and practice that iteratively bootstrapping your generative model on its own outputs causes the tail of the distribution to get thrown away.

So what’s going on?
In a couple cases, our apparent tension between empirical gains and the data processing inequality is easy to resolve:
If you use a great model like GPT-4 to generate examples for a worse model, you can just explain accuracy gains as knowledge distillation.
No information needs to be created. The GPT-4 training set is just better than yours. Or your model is just undertrained regardless.
If you only see a small gain, you can call it “regularization”1, data augmentation, or imposition of an informative prior.
E.g., you can turn an ordinary linear regression into a ridge regression by augmenting the dataset with Gaussian-noised copies of itself. No information added, but you can still do better.
But I claim that there’s a complementary and more general explanation. The key is not the model generating the data. The key is the filtering. Here’s how to think about it.
You have some target distribution you’d like to generate samples from, probably resembling a cleaned version of your training distribution. There are a few cases for how these distributions overlap.
If your target and generated distributions are disjoint, you’re out of luck.
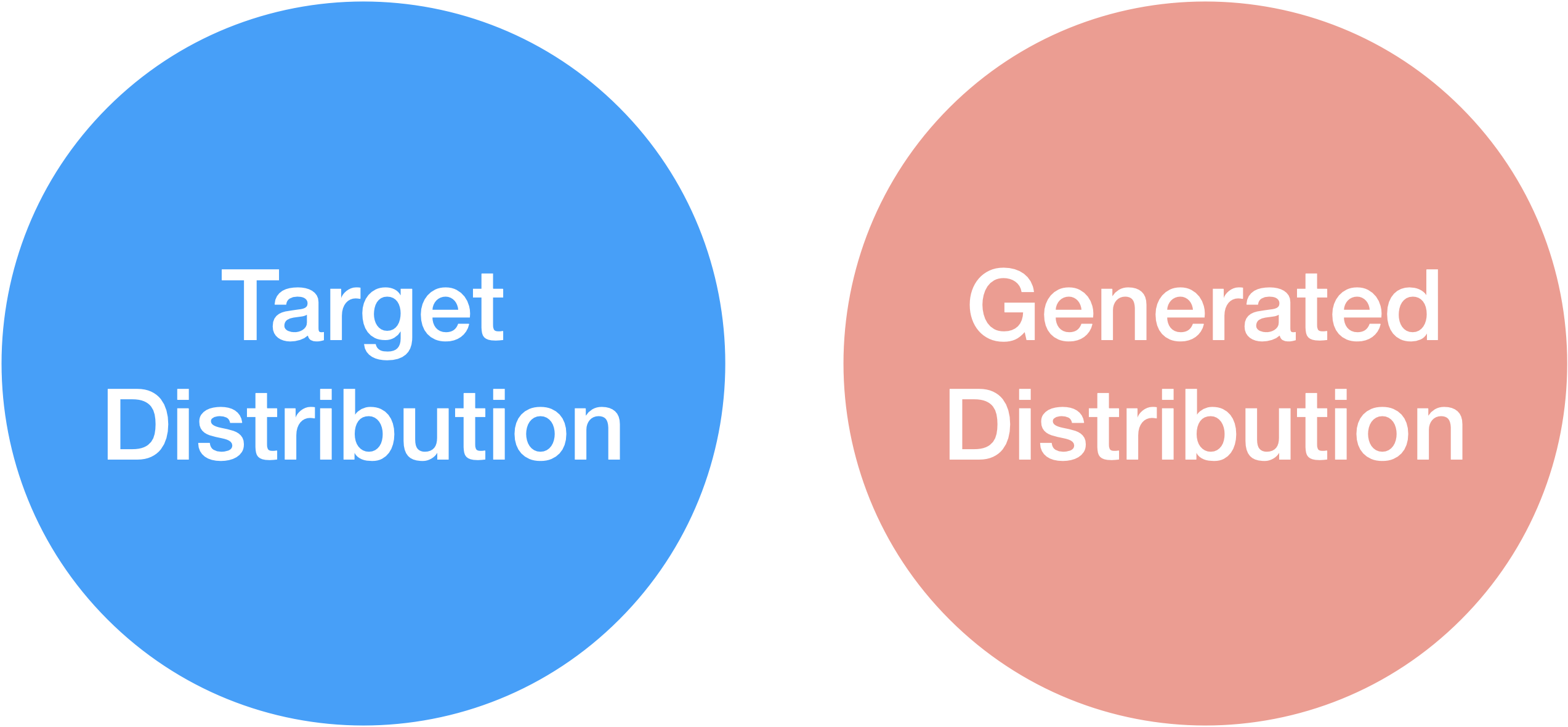
If there’s some overlap, you can at least generate some useful samples. But you won’t get full coverage and you’ll end up with a bias-variance tradeoff. The tail collapse from the The Curse of Recursion is one way to get this.

Where you really get going is when your generated distribution assigns nontrivial density to your whole target distribution. In this case, we get to bust out one of our oldest friends from statistics: rejection sampling.

What we can do in this full-coverage case is use some filtering function to throw away all the generated samples that don’t look like our target distribution. As long as our filtering function is good enough, we can generate new data from (approximately) our target distribution.

To really do this right, you want your filtering function to account for the ratio of your target distribution to generated distribution at each point in the sample space and resample/reweight correspondingly. With bonus points if you somehow upsample the tails to mitigate the Curse of Recursion issue.
Besides (hopefully) making sense intuitively, this framing is also consistent with the results I’ve seen. E.g., in Language Models Can Teach Themselves to Program Better, they solve way more programming puzzles when they only train on samples where the generated solution actually works for the generated problem.
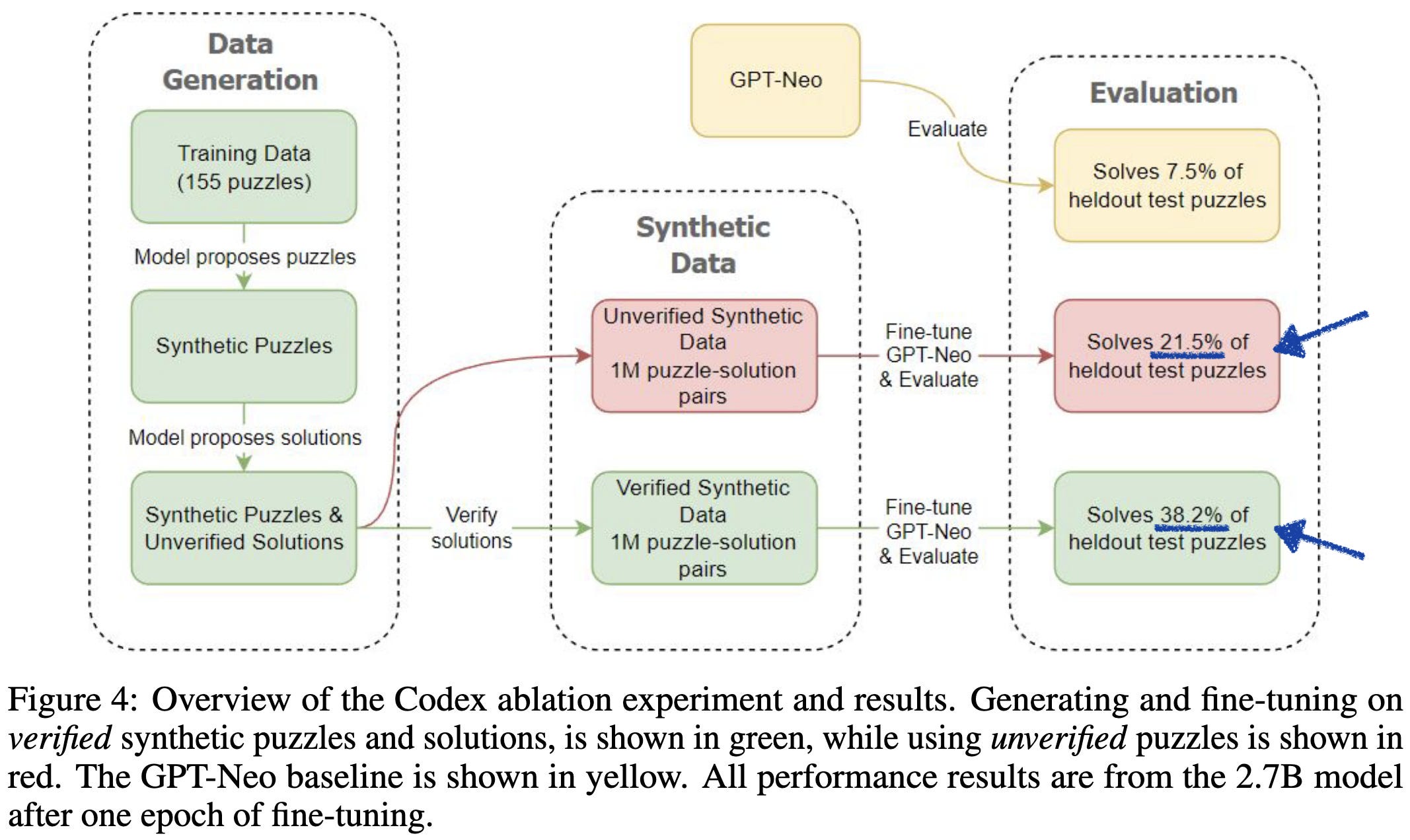
Filtering also seems to be a key component of Impossible Distillation, Orca, and Textbooks are All You Need.
This framing doesn’t explain the results in The False Promise of Imitating Proprietary LLMs, but can be reconciled with them. If the superficial alignment hypothesis holds, we would expect finetuning on GPT-generated data to not help that much—even if we’re doing a good job with the generation.
Testable predictions
Here are some findings we should expect if my rejection sampling framing corresponds to what’s actually happening.
Generating training data from too bad a model won’t work (efficiently) no matter how good your filtering function. This is because a bad model won’t generate good samples often enough.
Holding the generating distribution constant, making your filtering function better or worse should make models trained on the resulting data better or worse.
As your generated distribution approaches your target distribution, filtering should become less important.
Resampling / reweighting based on the ratio of proposal to target distribution will work better than taking all samples that have nontrivial probability under your target distribution.
We can generate infinite data from a target distribution provided that our generative distribution covers it and we can re-weight or reject samples appropriately.
Conclusion and implications
Given:
a model good enough to generate samples that resemble our target distribution, and
a filtering function that identifies (and reweights) these samples,
we can generate infinite data from our target distribution. We aren’t limited by the information processing inequality. Instead, we’re limited by our ability to cover and identify our target distribution.
This suggests that domains where coverage and filtering are tractable will be much less limited by training data in the future.
Coverage will be easier in domains with (effectively) low-cardinality input spaces. I would expect many time series, some tabular, and perhaps some image datasets to be in this camp.
Filtering will be easiest when samples have testable properties. Code generation is the standout here since programs have formal grammars and we can objectively assess correctness. Theorem proving also seems conducive to filtering. Natural language is less clear, but it at least has grammar rules and decent heuristics for assessing quality.
The speculative implication here is that training data generation could be the tightest positive feedback loop in machine learning. With better models, we could not only generate samples from our target distribution more often, but also learn to identify these samples more reliably.
So tl;dr, training data generation:
Can be understood as rejection sampling
Might create a tight positive feedback loop in which better models get us better data and vice-versa
Could let us get nearly infinite data in some domains in exchange for a bit of distribution shift
Thanks to my awesome coworkers2 for helpful discussion on this topic.
In the context of deep learning, “regularization” is defined as anything that improves generalization even though we have no idea why.
Mostly Daniel King, Tessa Barton, and Matthew Leavitt. Mistakes mine, good ideas theirs. This post also inspired by seeing Cameron Wolfe and Horace He crush it with blog posts.
I like this analysis. The story in ImpossibleDistillation is a bit more complex than simple generate-and-filter. ImpossibleDistillation is combining information from four models:
1. The initial generation model L_LM
2. The keyword extraction model (KeyBERT)
3. The Natural Language Inference model (RoBERTa-Large fine-tuned on WANLI)
4. The model L_0 that is fine-tuned (T5-large)
Items 2 and 3 form part of the filter chain which includes additional encoded knowledge defining the task (summarization vs. paraphrase, compression, etc.). Viewed abstractly, this shows that we can use initial LMs in both the generation and filtering phases combined with additional human input to create a target system that is better constrained to the specific task.
We are paying for the "free lunch" in many ways (training corpora for the various models, human-provided task definition, etc.). If we iterate the process, the gains will diminish once we have fully incorporated the constraints from the various input models into the target model.
Although your weekly summaries are essential reading, this analysis is among the best I've read in ages. Keep up the fantastic work!